










一文看懂推荐系统:物品冷启06:冷启的AB测试
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
【20】一文看懂推荐系统:物品冷启02:简单的召回通道
【21】一文看懂推荐系统:物品冷启03:聚类召回
【22】一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
【23】一文看懂推荐系统:物品冷启05:流量调控
提示:文章目录
物品冷启动:AB测试
前面的文章,我介绍了很多冷启动的技术,
想要上线新的模型或者策略,需要做ab测试。
冷启动的ab测试特别复杂,远比正常推荐系统ab测试麻烦,
所以我要用一篇文章来专门讲冷启的ab测试。
这节内容比较烧脑,适合有推荐系统经验的工程师看,不适合初学者。
看在小红书的场景下,我们做新笔记冷启的ab测试,
既要看作者测指标,也要看用户测指标,

作者测指标也叫发布测指标,最核心的是发布渗透率和人均发布量,
这些指标可以反映出作者的发布意愿,如果冷启做的好,可以激励作者发布渗透率和发布量增长,
用ab测试去考察作者侧指标是比较困难的。
后面我会解释为什么
ab测试还需要考察用户测指标,也叫消费测指标。
新笔记的点击率和交互率都算是用户测指标,
如果冷启的推荐做的越精准,用户对推荐的新笔记越感兴趣,
那么,新笔记的点击率和交互率就会越高。
除此之外,还要看大盘的消费指标,比如消费时长、日活月活,我们不希望冷启推荐的新笔记引起用户反感。
导致用户不活跃,大盘指标下跌。
推荐系统标准的AB测试
标准的ab测试通常只测这种用户测指标,实验比较好做,
而冷启的ab测试需要测很多指标,很麻烦。
我画了一下推荐系统,标准的ab测试,
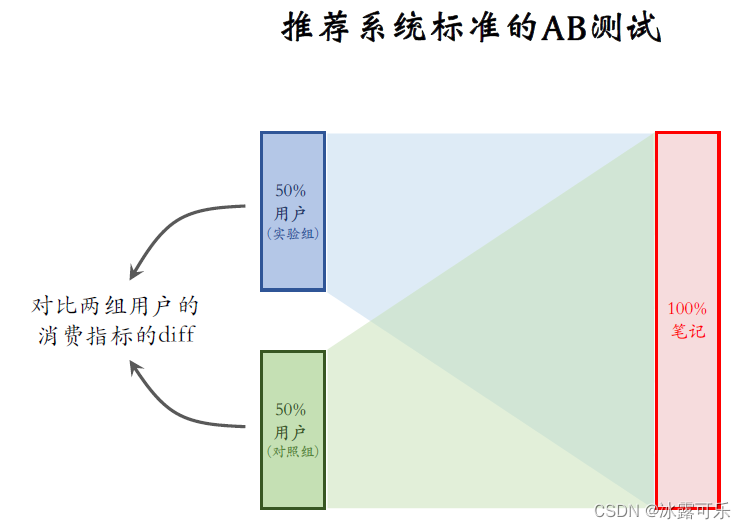
把用户随机分成两组,每组有50%的用户,
上面那组是实验组,下面那组是对照组,当然也可以分成很多组。
这里我只是举个最简单的例子,
右边是全体的笔记部,分组给实验组用户做推荐。
会从全量的笔记池中选出最合适的笔记,
当实验组用户发起推荐请求的时候,会用新的策略给对照组用户做推荐,
也是从全量的笔记池中选取最合适的笔记。
如果一个用户属于对照组,给他做推荐的时候用旧的策略。
在实验的过程中对比两组用户消费指标的difference【差异】,
比如考察用户消费推荐内容的时长,发现实验组比对照组高了1%。
这个ab测试要测两类指标,
一类是用户测的消费指标,
另一类是作者测的发布指标。
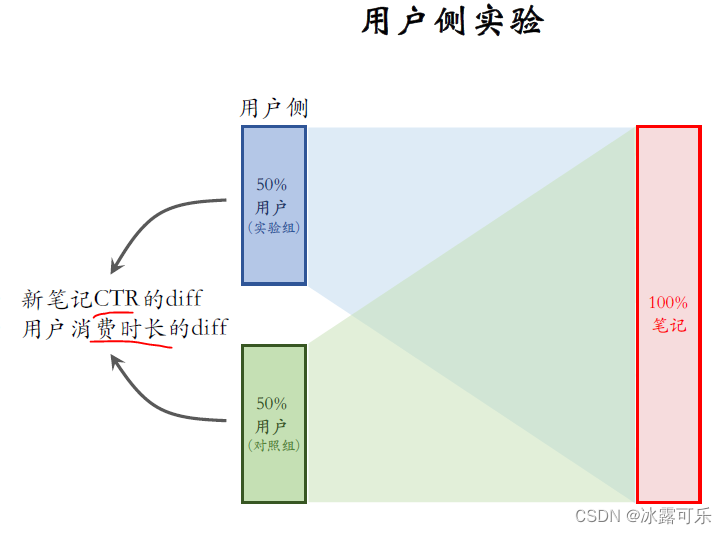
先来看用户测,试验推荐系统标准的ab测试的方法可以用于冷启考察用户测的消费指标,
比如考察策略对新笔记点击率的影响,对用户消费时长的影响。
但这种ab测试的设计有不足之处,下面我会解释,好在问题不严重,这种ab测试的结果还算可信。
刚才介绍了用户测的ab测试方法,这种方法有个缺点,我解释一下,我们做个假定
假设冷血流量调控机制要求做保量,要尽量给新笔记100次曝光。
我们还做个假设,新笔记曝光越多,用户使用APP的时长就会越低。
这个假设挺合理,通常来说,新笔记推荐不够准,新笔记太多会影响体验。
现在我们实验一个新策略,在排序的时候给新笔记提权,让权重增大两倍,
这样会让新笔记有更多的机会曝光。
很显然,这个新策略会伤害用户体验,导致消费指标变差。

如果只看消费指标,那么ab测试的结果是**负向的,**策略组不如对照组,也就是说观测的D是个负数。
如果把实验推全,也就是对所有的用户都上新策略,difference会缩小。
也就是说,新策略对用户体验的伤害,没有ab测试观测到的那么严重。
比方说ab测试观测到的D是负的2%,可能推全之后,消费指标只跌了1%。
为什么会发生这种现象?大家自己去思考,我只简单提示一下,
给实验组提权两倍,那么实验组用户看到的新笔记就会变多。
实验组的消费指标会变差,保量100次的曝光是确定的。
既然新笔记从实验组那里得到更多的曝光,
那么从对照组得到的曝光就会减少,对照组的消费指标会变好,
实验组变差,对照组变好。
这就导致ab测试观测到的difference很大,
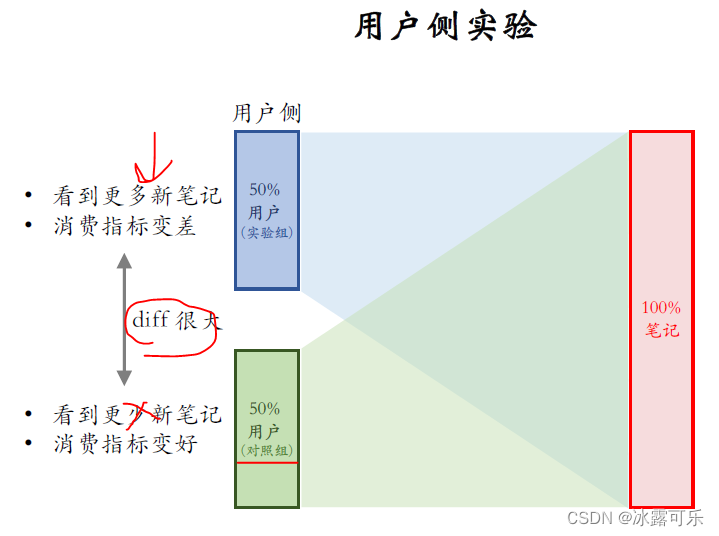
但推选后消费指标实际跌不了那么多。
这个不太好理解,需要大家仔细去琢磨。
冷启的ab测试还需要考察别的指标。
比如发布渗透率、人均发布量,
作者侧的实验不太好做,没有很完美的实验方案。
先看作者侧实验的第一种方案,中间这些是全体用户,
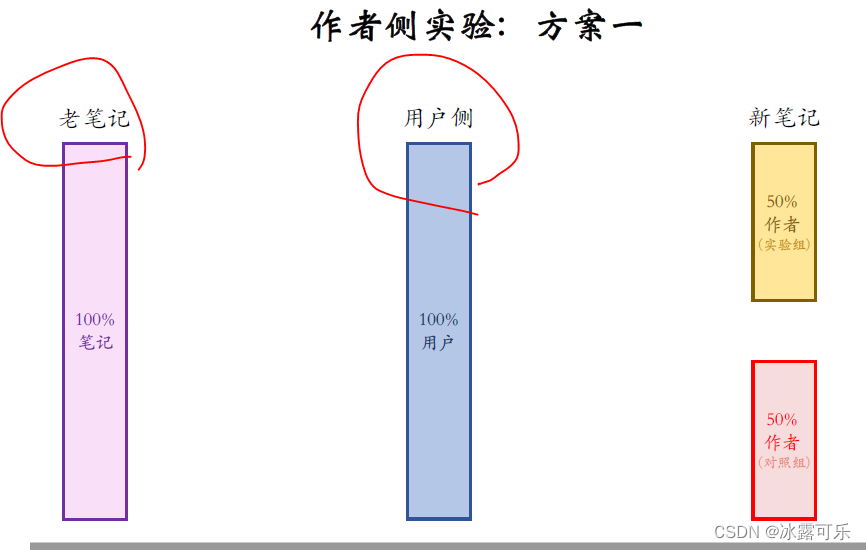
不对用户做分组,
左边这些是全体的老笔记,我们也不对老笔记做分组,
但我们要区别对待新笔记和老笔记,
右边这些是新笔记,按照作者随机分成两组,这样可以对比作者的发布积极性,知道新的策略能不能极力发布。
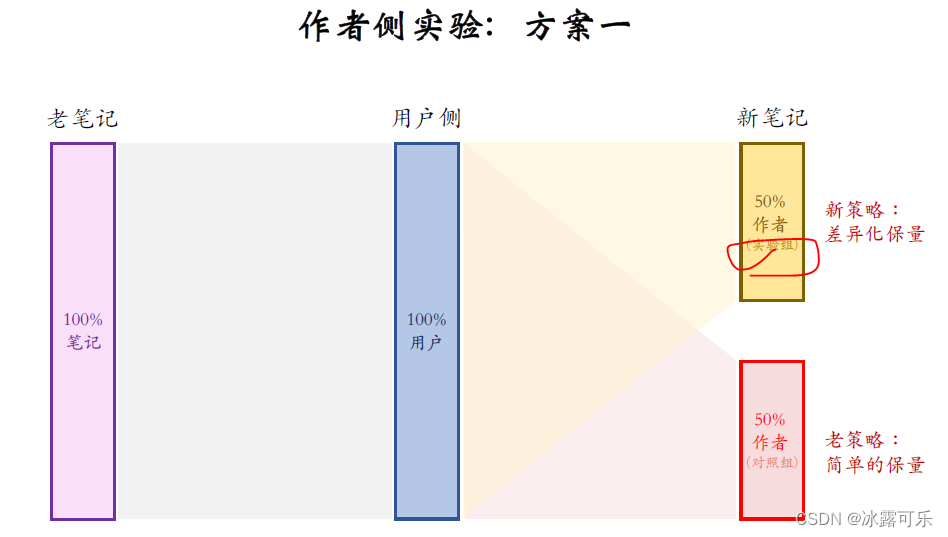
上面这组作者是实验组,会用新策略,
下面这组作者是对照组,用旧策略,
老笔记完全是自然分发,不受新旧策略的影响。
从全量的老笔记中选出用户最喜欢的推荐给用户。
这些是实验组的作者,他们发的新笔记都用旧策略,
这些新笔记有机会触达全体用户,
这些是对照组的作者,他们发的新笔记,在推荐的时候都用新策略,
这些新笔记也有机会被任何一个用户看到。
我再解释一下,把新笔记分成两组是什么意思?
举个例子,对照组是简单的保量,不论笔记好坏都保200次曝光,
实验组是差异化保量,有100次曝光的基础保量,外加给优质内容和优质作者的额外保量,最多给500次曝光,
最后对比这两组作者的发布指标,就知道哪种策略对发布更有利。
这种作者测的ab测试方案,有个严重的缺点,

主要问题在于两组新笔记之间会抢流量,存在这种可能性。
实验关系到B,比方说作者发布指标涨了2%,
但是推选之后发布指标没有发生任何变化。
我举个例子解释为什么会出现这种现象。
我们做这种设定,新老笔记做各自的队列,各自做排序,各自做阶段,
新老笔记之间没有竞争,重排分配给新笔记,1/3流量,分配给老笔记2/3流量,
两者的曝光占比是固定不变的。
现在上一个新策略,把新笔记重排式的权重增大两倍,
在我们的设定下,这种新策略不会产生任何影响,为什么?
新笔记只跟新笔记竞争,不跟老笔记竞争。
如果把所有的新笔记权重都乘以二,那么新笔记之间还是公平竞争,跟原先没有区别。
新笔记的曝光占比还是1/3,所以新策略不会极力发布,不会改变发布侧指标,】
但是ab测试的结果显示有正向收益。
如果看发布侧指标,比如看发布渗透率,发现实验组优于对照组,这是不合理的。
为什么会出现这种不合理的现象?
实验组给新笔记提权,对照组没有提权,实验组提权的新笔记会抢走对照组的曝光,
那么实验组的发布指标会涨。
对照组的发布指标会跌,这样就产生了difference。
从ab测试的结果来看,新策略有正向收益,
但是在我们的设定下,给新笔记提权乘以二是不会影响发布指标的。
很显然,把新策略推权之后发布的指标跟以前相比还是完全一样。
我用这个例子说明,方案已有严重缺陷,
Ab测试观测到的difference是不可信的,
推权之后可能会消失,这种缺陷是新笔记之间抢流量造成的。

如果给实验组新笔记提权,那么实验组就能抢到更多的曝光机会,
相应的对照组新笔记得到的曝光就会减少,这样两组的发布指标就会产生difference,
如果把新策略推全给所有新笔记都提权,那么就不存在两组新笔记之间抢流量的情况,就不会出现difference。
这种方案还有一个缺点,就是新笔记和老笔记可能会抢流量,
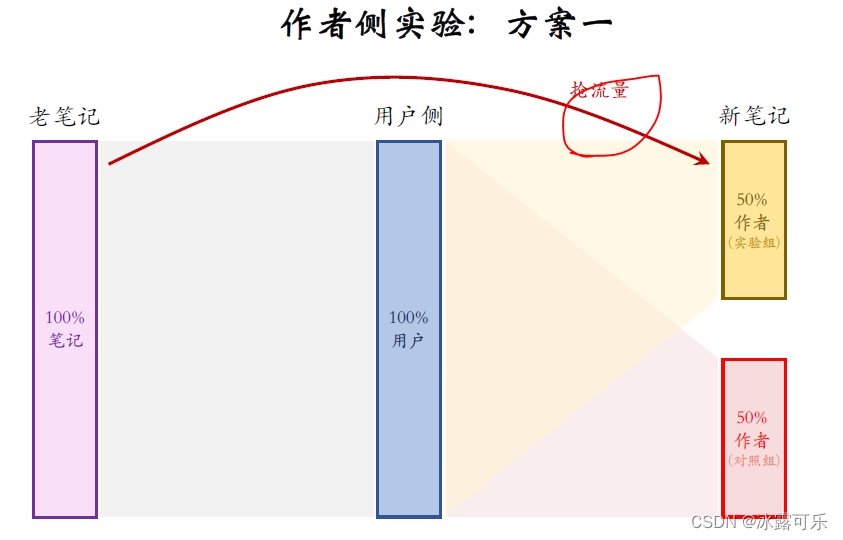
如果让新老笔记自由竞争,那么50%的新笔记齐全之后会抢100%老笔记的流量,
平均一份新笔记抢走两份老笔记的流量,如果推全
那么就是100%的新笔记抢100%的老笔记的流量,
一份新笔记只抢走一份老笔记的流量。
也就是说,推全之后,新笔记更难抢到流量。

前面说过,方案一的第一个缺点是两组新笔记会抢流量。
现在讨论方案一的第二个缺点就是新笔记和老笔记会抢流量。
新老笔记抢流量不是问题,问题在于,Ab测试和推全之后的设定发生了变化,导致ab测试的结果不准确。
我举个例子来解释为什么ab测试的结果不准确。
这里的设定是让新老笔记自由竞争,不控制新老笔记的曝光占比。
这里的设定跟前面不一样,新的策略是把新笔记排序时的权重增大两倍,让新笔记更有优势。
ab测试的时候,50%的新笔记跟100%的老笔记抢流量,
这50%的新笔记带策略,提权系数乘以二
一份新笔记可以抢走两份老笔记的流量。
推全之后设定发生了变化,所有的新笔记都带策略,跟所有的老笔记抢流量,
一份新笔记,只能抢走一份老笔记的流量,
由于设定发生了变化,Ab测试的结果与推全之后的结果是有差异的。
比如ab测试的结果是发布渗透率涨了两个百分点,推全之后,
可能大盘的发布渗透率只涨了一个百分点。
这是作者侧实验的方案二,跟上一种方案的区别。
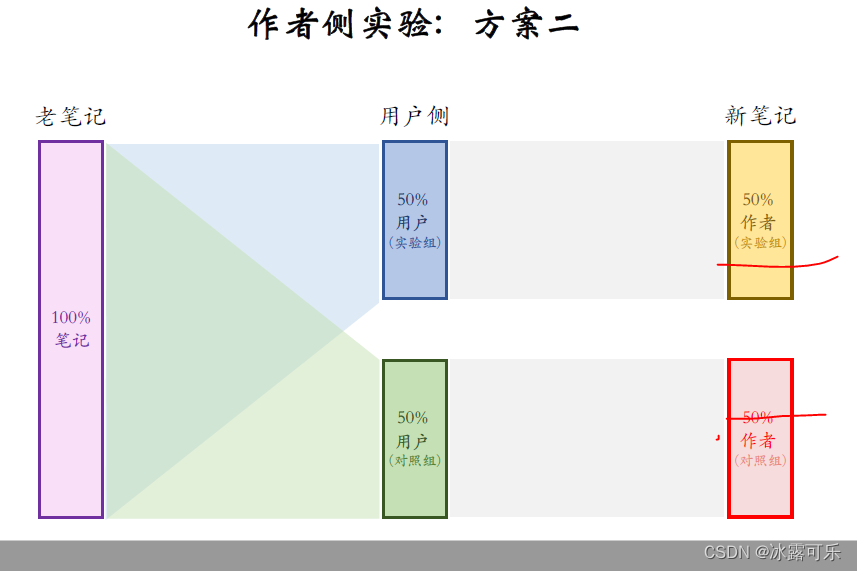
在这里,用户被分成了两组,上面是实验组,下面是对照组。
实验组的用户只能看到实验组的新笔记,
对照组的用户只能看到对照组的新笔记。
这种设计的目的是避免两组新笔记抢流量,因此这种方案比方案一的结果更可信。
这种方案也有缺点,最大的问题在于内容池减小了
这50%的用户只能看到50%的新笔记。
大家想一下这有什么危害?
原本一个用户在刷小红书的时候,推荐系统会从选取的新笔记中选出100篇最符合用户兴趣的,
现在新笔记的内容只小了一半,100篇最符合用户兴趣的笔记只剩了50篇,
要从差一些的笔记中再选出50篇补上来。
这肯定会影响用户体验,造成消费者指标下跌。
也就是说,为了做个ab测试,导致大盘变差,公司业务会受损失。
概括一下方案二比方案一的优势和劣势。

方案二的优势是同时隔离作者和新笔记,这样做的话,新笔记的两个桶不会抢流量,这样会让作者做的实验结果更可信。
如果ab测试官司的发布指标有difference,那就说明确实有difference推全之后会消失。
两个方案共同的缺点是新笔记和老笔记抢流量,
Ab测试的时候,50%的新笔记跟100%的老笔记抢流量,
一份新笔记抢走一份老笔记的流量,这会导致ab测试的结果与推前之后的结果有差异。
跟方案一相比,方案二有个缺点,做隔离之后,每个用户对应的笔记池都小了一半,
这会让推荐的结果变差,对用户体验造成负面影响。
这是方案,三更极端一些,把老笔记分成两个组,如果这样做,小红书就像是切成了两个APP,
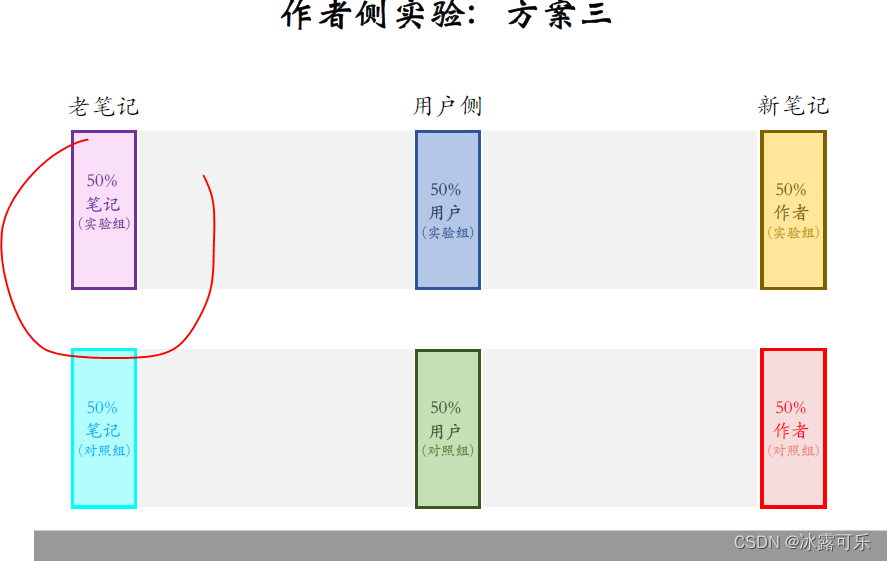
如果希望实验结果精准,这种方案是最优的。
如果ab测试发现指标涨了,提权之后也会涨那么多。
但这种方案不太实际可行,把小红书切成两个APP,
内容只小一半,会严重损害用户体验,消费指标一定会大跌。
为了作为ab测试,严重损害了公司业务,这个代价不太划算,
最后总结一下这节的内容。

这节介绍冷启动的ab测试,
我们既要做作者侧试验、观测发布指标,
也要做用户侧实验,观测消费指标。
这是因为冷启至少有两个目标,一个是激励作者发布,另一个是让用户满意。
我讲了好几种ab测试的设计方案,每种方案都有缺点,
我们团队的同学设计了更好的方案。
按出显而易见的原因,我不能在这里讲,但我们的方案也不完美,也有缺点,
恐怕世界上根本就没有完美的实验方案。
设计ab测试方案的时候,要问自己几个问题。
从而判断自己的实验设计有没有缺陷。
第一个问题,新笔记分为实验组和对照组,这两组新笔记会不会抢流量?
第二个问题,新笔记和老笔记是怎么样抢流量的,Ab测试的时候是怎么抢的,推权之后是怎么抢的?
如果ab测试和推权之后抢流量的方式发生了变化,那么ab测试的结果可能会不准。
第三个问题,如果同时隔离笔记和用户,会让内容数变小,如果变小,肯定会影响推荐效果,让用户体验变差。
也就是说,为了做个ab测试,影响大盘,损害了公司业务。
第四个问题,如果对新笔记做保量,比如保100次曝光会发生什么?
如果笔记从实验组用户那里获得了很多曝光,比如获得了80次曝光,
笔记就不容易出现在对照组用户那里,因为只需要从对照组用户那里获得20次曝光而已,就能达到保量目标。
如果有保量,你得仔细思考一下,你的实验准确性会不会受保量的影响。
这节内容比较烧脑,一时半会儿想不明白也没关系,可以多想想。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:这是因为冷启至少有两个目标,一个是激励作者发布,另一个是让用户满意。


















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











