







复盘:反向传播算法的过程及公式推导,小白也能看懂的Backpropagation过程
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
基础知识:
【1】深度学习机器学习面试题——损失函数
【2】深度学习机器学习笔试面试题——激活函数
【3】深度学习机器学习笔试面试题——优化函数
互联网大厂的算法岗面试题:请你手动推导反向传播算法的过程
自己学习机器学习,深度学习也有好长一段时间了,
经常看公式,一头雾水,也不想自己推导,太繁琐了,虽然自己天天用CNN,
你可能大概率跟我差不多,虽然一直在用深度学习,
但是对神经网络的“反向传播”机制不是很理解
就是理解也仅仅是“反向传播算法那不就是链式求导法则吗?”,这种模糊的概念
今天,看到了百度深度学习面试官的问题:请你手动推导反向传播算法的过程
我下定决定一定要自己手动推导一波BP的公式,
本文争取生动、简单地讲解一下BP算法!让自己理解透彻,你看了希望你也下定决定自己推导一波
看别人捋清楚都没用的,还得自己亲自动手搞定这个事情,否则永远都是悬在空中迷迷糊糊的
反向传播的定义
首先来一个反向传播算法的定义
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,
是一种与最优化方法(如梯度下降法)结合使用的,
用来训练人工神经网络的常见方法。
该方法对网络中所有权重计算损失函数的梯度。
这个梯度会反馈给最优化方法,
用来更新权值以最小化损失函数。(这个过程就称之为误差的反向传播)
BP算法讲解(耐心看)
可能面试官问一下了解BP算法的人“BP算法怎推导?”,
大概率得到的回答是“不就是链式求导法则嘛”,
我觉得这种答案对于提问题的人来说没有任何帮助。
BP的推导需要链式求导不错,但面试官往往想得到的是直观的回答,毕竟理解才是王道。
你想要直观的答案,给面试官讲清楚,那就需要图解莫属了。
注:下图的确是反向传播算法,和DNN中的backward的大体思想是一样的,
毕竟误差没法从前往后计算啊。【误差就是从后往前算】
下面通过两组图来进行神经网络:前向传播和反向传播算法的讲解,
第一组图来自国外某网站,配图生动形象。
如果对你来说,单纯的讲解理解起来比较费劲,
那么可以参考第二组图——一个具体的前向传播和反向传播算法的例子。
通过本篇博客,相信就算是刚刚入门的小白(只要有一点点高等数学基础知识),也一定可以理解反向传播算法!
CASE 1(图示讲解,看不太懂没关系,看第二组图)
首先拿一个简单的三层神经网络来举例,如下:
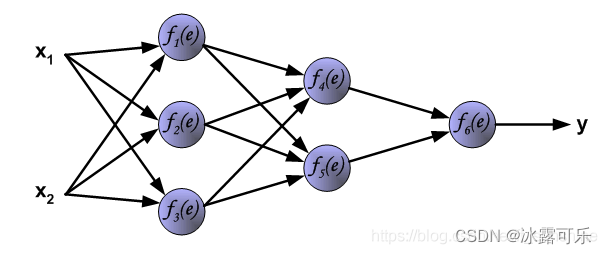
每个神经元由两部分组成,
第一部分(e)是输入值和权重系数乘积的和,【你可以看到经常有人把e写成z,这都没关系,你反正知道咱们就是用符号表示计算公式而已】
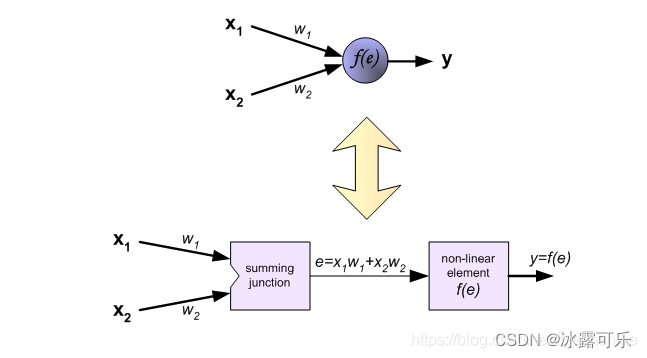
第二部分f(e)是一个激活函数(非线性函数)的输出,
y=f(e)即为某个神经元的输出
经常我们也可以这么写

sigma就是sigmoid激活函数,非线性的
它长这样,下图左上角
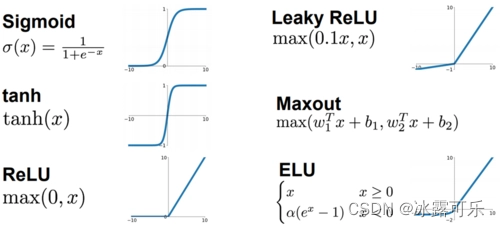
咱们今天就用sigmoid函数将返乡传播的过程
上面所有的激活函数,目标就是把z所在的自定义域,映射为特定的值域
比如sigmoid就把z从负无穷–正无穷,整体映射为0–1之间的值
这么做就是非线性变化
目标就是让神经网络有一个关闭功能【值为0:死区】和开启激活的功能【值为1:激活了】
okay,继续说BP
下面是把x经过w,再经过z,在经过f,前向传播过程:
y1,y2,y3怎么求?
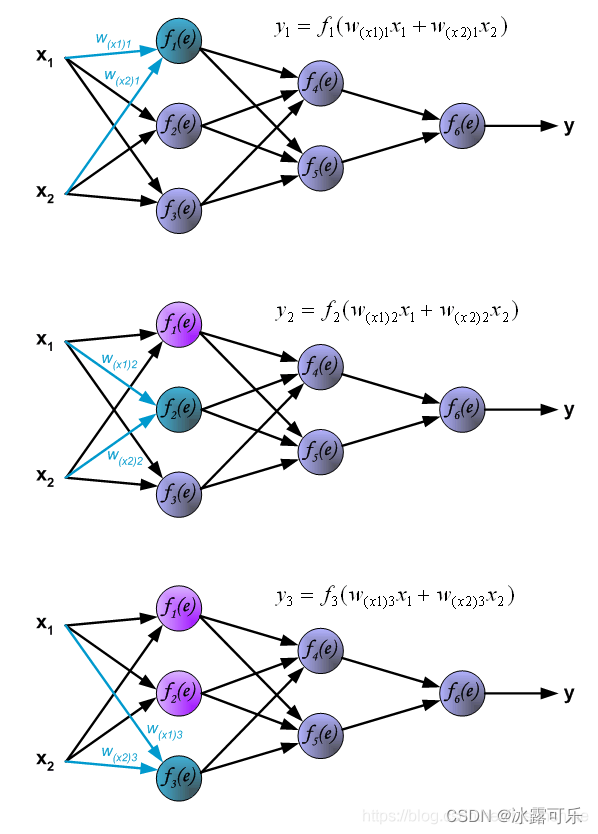 -----------手动分割-----------
-----------手动分割-----------
然后求y4和y5
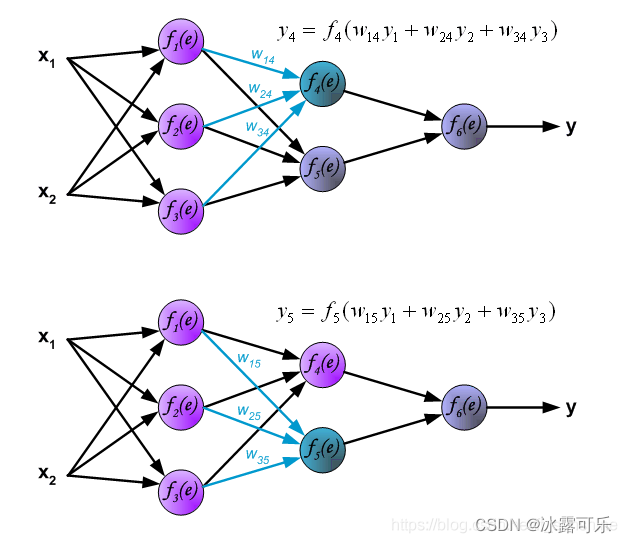
-----------手动分割-----------
然后求最后一个输出层的y6
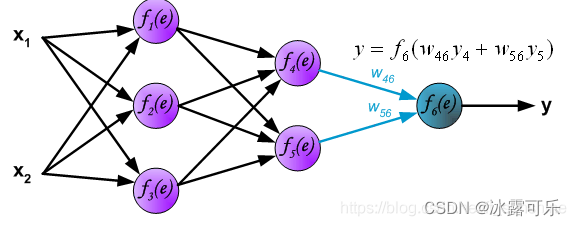
对于一层神经元的输出,无非就是上一层的输入yi
经过一些w加权求和得到z(或者e)
然后我们用激活函数f(sigmoid)激活这个e,得到y输出
到这里为止,神经网络的前向传播已经完成,
最后输出的y就是本次前向传播神经网络计算出来的结果(预测结果y^),
——从现在开始,你就就不要用z表示e了,咱直接用e就行,它表示加权就和的结果
——从下面开始,我们把ground truth写作z,一般来说,预测结果我们应该写y_hat,而真实值写y,但是本文懒得写那个帽子hat了,就把预测值写成y,而真实值写z得了
但这个预测结果y不一定是正确的,它要和真实的标签(z)相比较,
计算预测结果和真实标签的误差(δ)delta,如下:
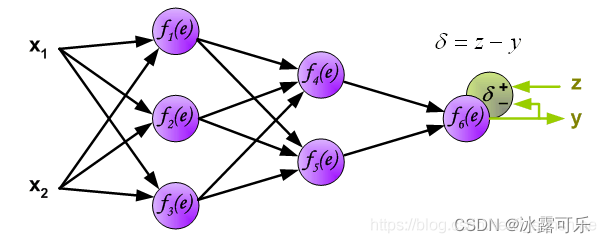
其实,对于每一个神经元,它的输出,都会存在误差,
而当初咱们前项传播时,每一个神经元的输出,都与前面所有的神经元有关系,因此
最后一个输出的误差,返过去,也会影响所有的神经元他们的误差
下面开始计算每个神经元的误差(δ delta)
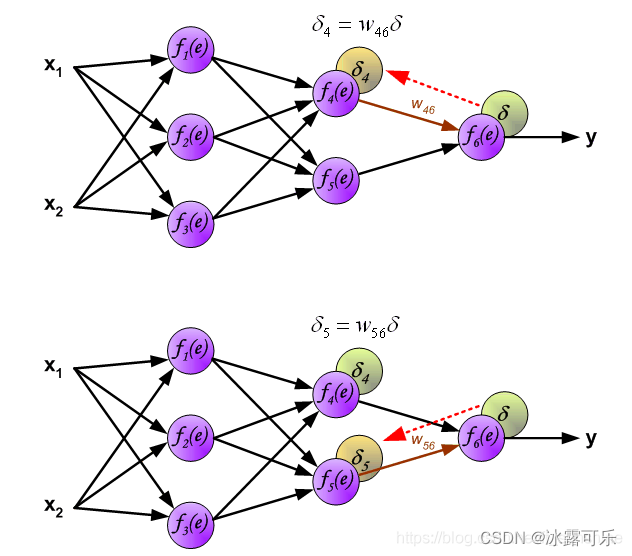 当初,我一个神经元去影响了谁?
当初,我一个神经元去影响了谁?
我现在的误差,就应该被他们影响,
因此,我的误差传播来自后方我曾经影响过的几个数神经元,也是沿途加权给我。 图示如下
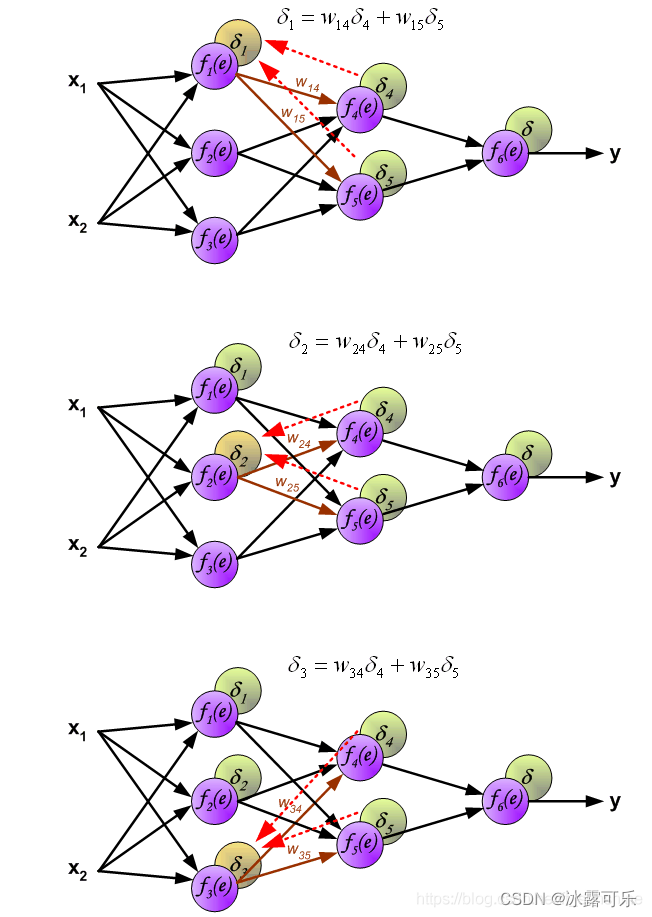
有误差,我们的目标就是求这些误差对权重w的梯度
方便拿着个梯度更新w
从而达到学习的目的
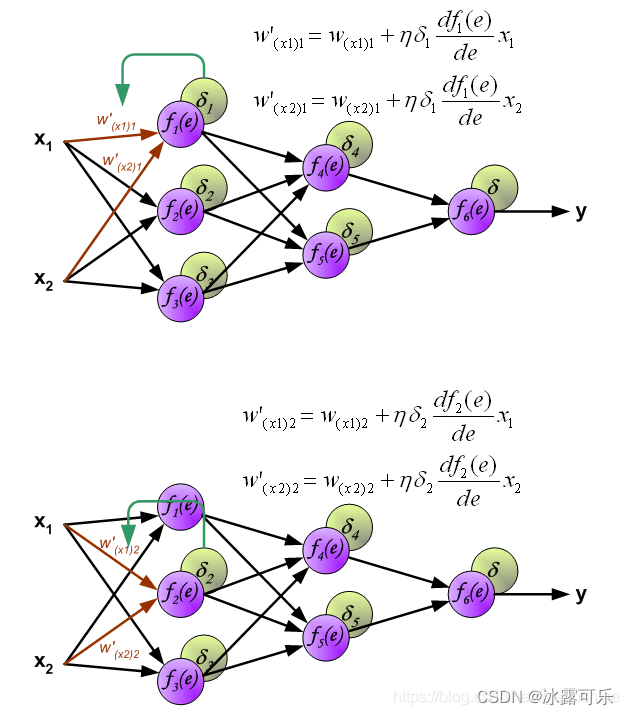
下面开始利用反向传播的误差,计算各个神经元(权重)的导数,开始反向传播修改权重

英文说啥意思呢?
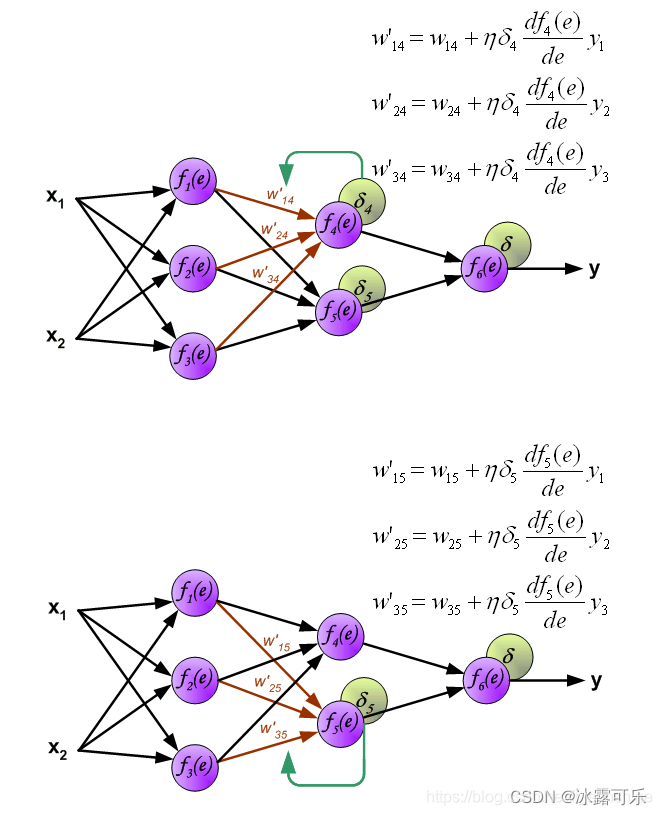
经过误差传播之后,咱们要更新w为w’,下图看看
咋更新呢?
用原始w+学习率lr×误差delta对w的梯度
误差delta对w的梯度咋求呢,其实链式求导来求
误差delta对w的梯度 =
误差delta对f(e)的梯度
×
f(e)对e的梯度
×
e对w的梯度

上图式子左边是误差,中间是sigmoid对e的倒数,x1是e对w的倒数
为啥呢,因为e=w*x1,把x1其实是已知的量,w是自变量,对w求导自然是x1了
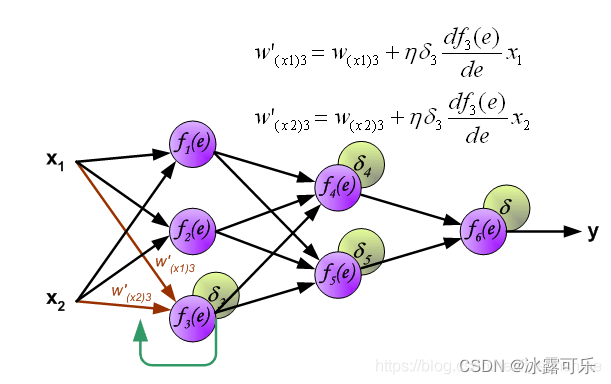
常规来说,我们以往认知的函数是:y=kx,k已知,x位置
y对x求导就是k
但是现在神经网络,往往x已知,而k却位置【k=w】
y对k=w求导就是x
一个道理,就是数学公式而已
-----------手动分割-----------
----------手动分割-----------
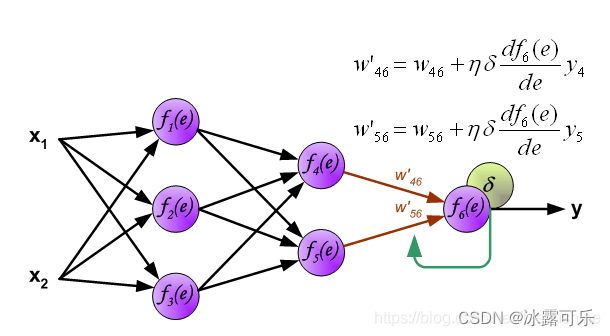
到此为止,整个网络的前向,反向传播和权重更新已经完成,
当然,如果对纯理论讲解较难接受,没关系,强烈推荐第二组图的例子!!!
CASE 2(具体计算举例,嫌麻烦的可直接看这个,强烈推荐!!!!!)
首先明确,“正向传播”求损失loss,
“反向传播”回传误差loss——目标就是为了把w更新了,使得神经网络达到学习的目的。
同时,神经网络每层的每个神经元都可以根据误差信号修正每层的权重,
只要能明确上面两点,那么下面的例子,
只要会一点链式求导规则,就一定能看懂!
BP算法,也叫δ 算法,下面以3层的感知机为例进行举例讲解。
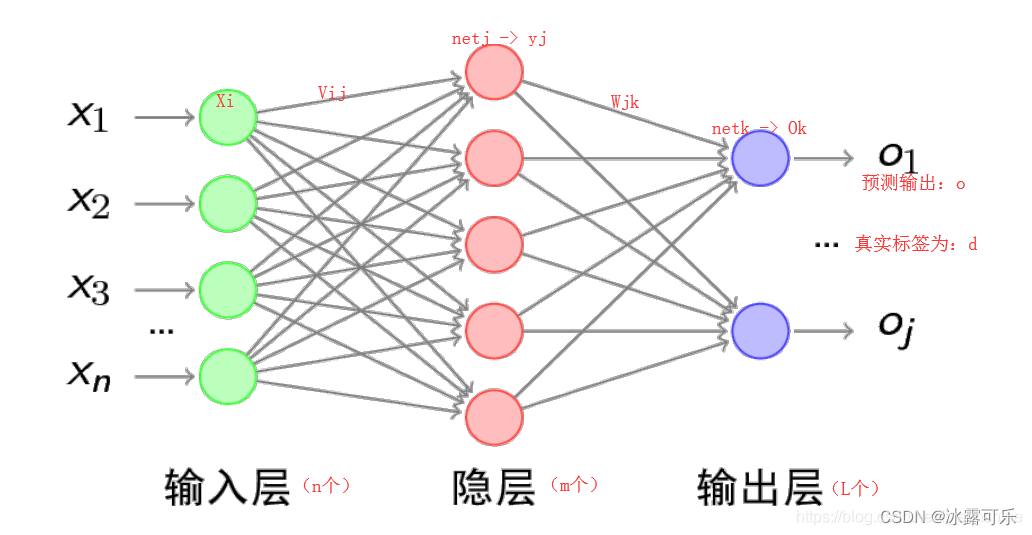
上图的前向传播(网络输出计算)过程如下:
此处为网络的整个误差的计算,误差E计算方法为mse

上面的计算过程并不难,只要耐心一步步的拆开式子,逐渐分解即可。
你可以看到无非就是ok怎么来呢?
通过f(netk)来的
netk又咋来的?
通过wjk和yj加权求和来的,上一层的输出,这一层j的输入
yj又是咋来的?
无非就是通过f(netj)及哦豁来的
netj咋来的
通过原始输入的xi通过vij加权来的
很容易的一个前向传播过程
现在还有两个问题需要解决:
(1)误差E有了,怎么调整权重让误差不断减小?
(2)E是权重w的函数,何如找到使得函数值最小的w。
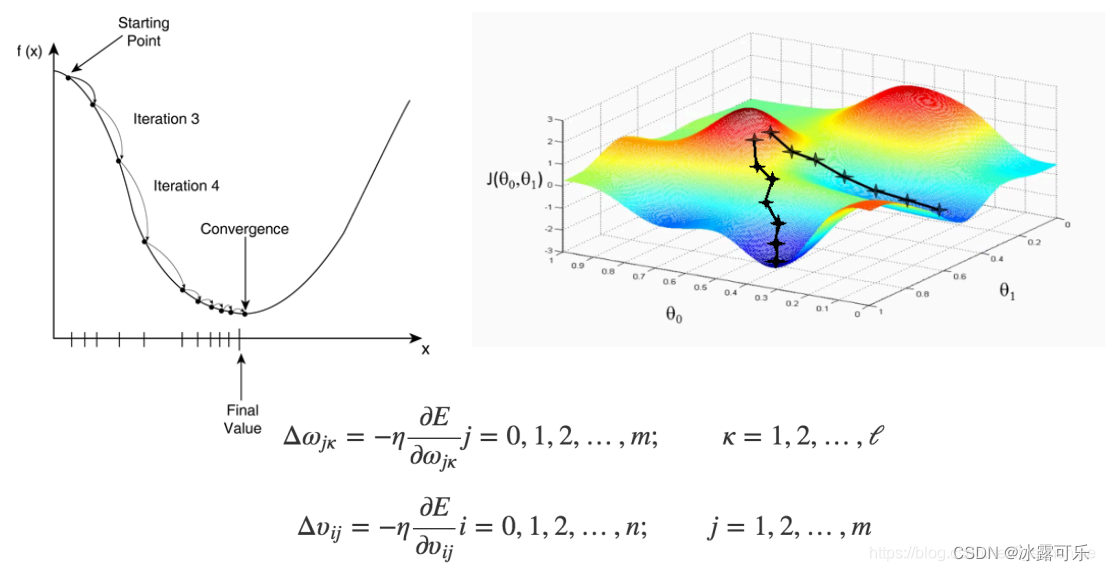
解决上面问题的方法是**梯度下降算法(**简单图示如下),
大家如有不太懂的可先行查阅别的资料,
只要能达到理解线性回归梯度下降算法的水平即可,这里不再赘述。
就是说e是w的函数,x是已知的
往往e–w函数就是一个平方函数,有一个e的最低点
咱们要的就是想尽一切办法,不断更新e,使得e到极小值点,这样误差就是最小的
神经网络的预测就是准确的
划重点,划重点,划重点!!!BP算法的具体例子来喽!!
就算上面的所有东西你都看的迷迷糊糊,
通过下面的例子,相信绝大多数人也能很轻松的理解BP算法。
如图是一个简单的神经网络用来举例:
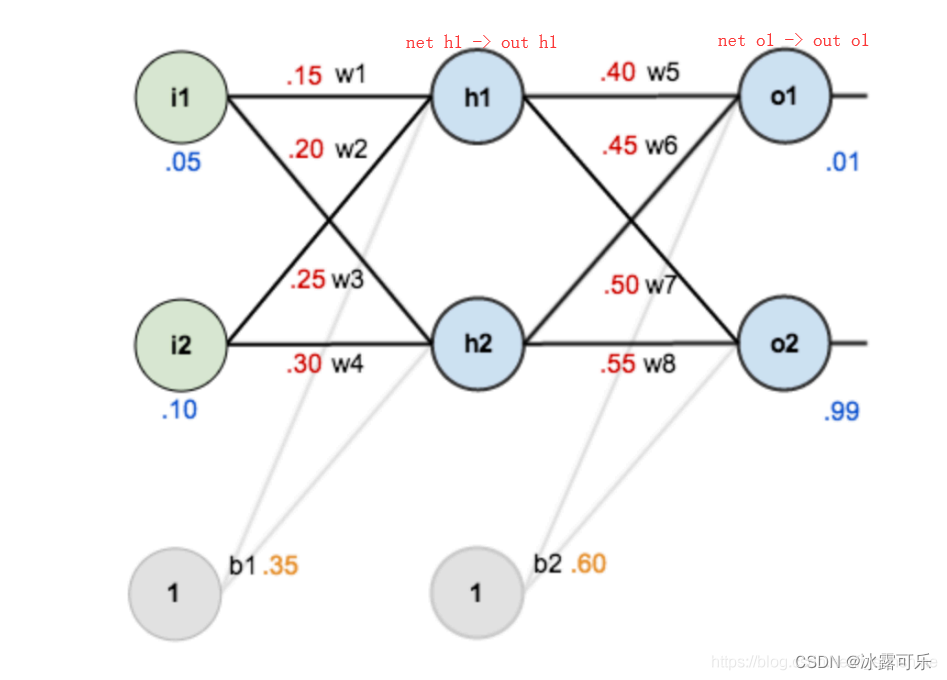
下面是前向(前馈)运算(激活函数为sigmoid):
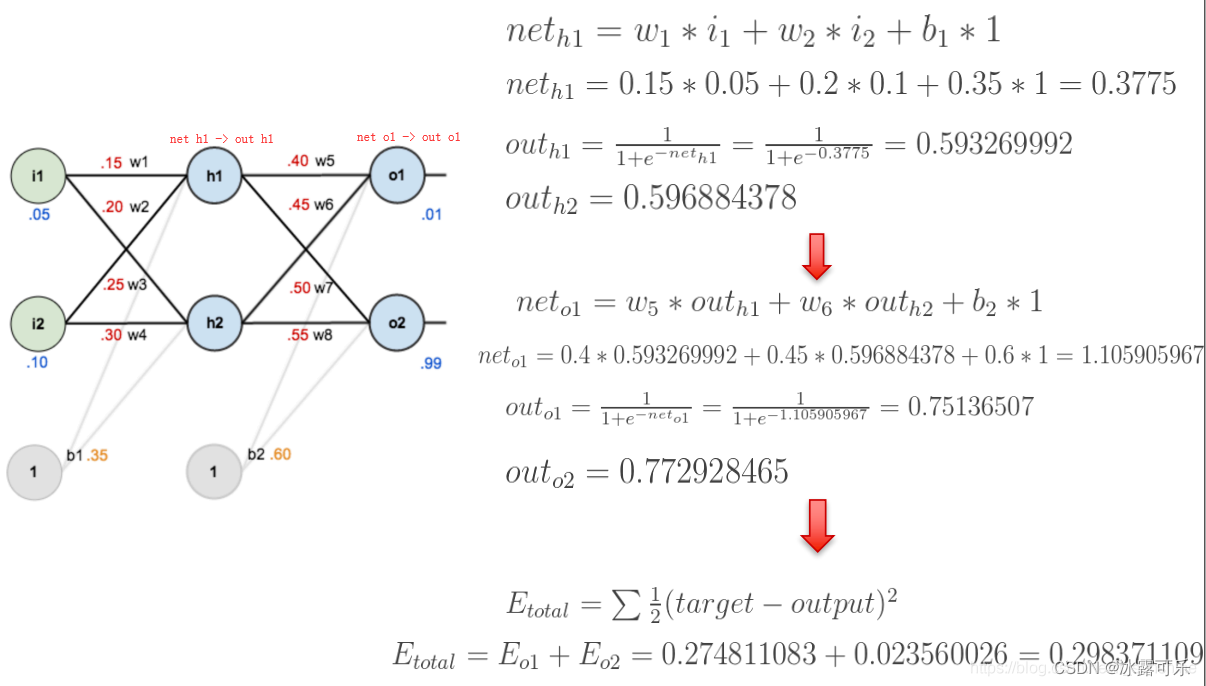
有了误差e
下面是反向传播(求网络误差对各个权重参数的梯度):
我们先来求最简单的,求误差E对w5的导数。
首先明确这是一个“链式求导”过程,
要求误差E对w5的导数,
需要先求误差E对outo1的导数,
再求outo1对neto1的导数,
最后再求neto1对w5的导数,
经过这个链式法则,
我们就可以求出误差E对w5的导数(偏导),如下图所示:

E对outo1的导数计算过程中,你会发现实际上,与outo2没关系,它求导被干废了,为0
而
outo1对neto1的导数,实际上就是对sigmoid函数的求导
我们熟悉sigma的倒数=sigma*(1-sigma)
带入公式就能求得梯度是多少
neto1对w5的导数计算很简单了,对其他的w没啥关系,咱们只跟w5有关系
求完之后,仨连成链式,就是e对w5的梯度
导数(梯度)已经计算出来了,下面就是反向传播与参数更新过程:

把经典的w更新的式子中的梯度替换了就是
w5已知,lr已知
上面的图已经很显然了,
如果还看不懂真的得去闭门思过了(开玩笑~),
耐心看一下上面的几张图,一定能看懂的。
如果要想求误差E对w1的导数,
误差E对w1的求导路径不止一条,这会稍微复杂一点,
但换汤不换药,计算过程如下所示:
只是咱们求e对w1的梯度时
咱们需要明白一件事,当年outh1其实通过2条路去影响了误差loss E
因此,E回传,也需要经过两条路回传影响w1
整体来说,E对w1求导,是三个公式相乘:
Etotal对outh1的梯度
×
outh1对neth1的梯度
×
neth1对w1的梯度
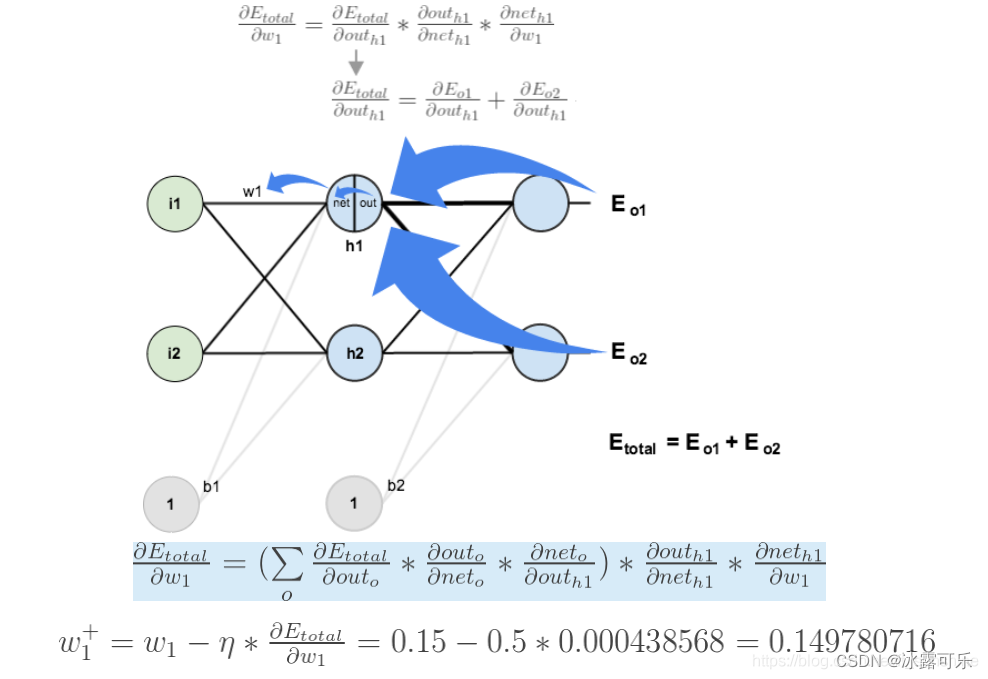
而:Etotal对outh1的梯度
又又两条路径影响
第一条:Etotal对out0的梯度×out0对net0的梯度×net0对outh1的梯度
第二条:Etotal对out2的梯度×out2对net2的梯度×net2对outh1的梯度
因此俩的和,就是Etotal对outh1的梯度
有了E对w1的梯度,那就可以更新w1了
带入上图的公式,复杂是复杂,但是原理就是这么简单
至此,“反向传播算法”及公式推导的过程总算是讲完了啦!
希望你也能自己推一把,透彻地理解这个BP是啥东西
我们为啥要学习这个反向传播的过程呢????
一切的一切,就是为了让神经网络输出预测y准确
让损失函数loss降到极小值点
方法,就是loss返乡传播,优化更新w,从而达到让神经网络学习的目的
咱们干这几件事,扩展开,上面说了是mse损失,那你还了解别的损失函数吗???
神经网络前向传播过程中的除了sigmoid,还有哪些激活函数??
如何优化神经网络,除了直接用梯度下降法更新w,还有别的更新方法吗?优化方法设计的优化器,还有哪些??
我都一并给你准备好了,你需要展开了解,然后更加深入地学习今天BP的本质,BP的作用,BP的操作有哪些
【1】深度学习机器学习面试题——损失函数
【2】深度学习机器学习笔试面试题——激活函数
【3】深度学习机器学习笔试面试题——优化函数
总结
提示:重要经验:
1)一句链式求导法则还不够,还需要公式推导,或者实际的例子举例说明——做这一切都是为了优化神经网络更新参数,使得误差最小化
2)最重要的就是误差E对w的梯度,实际上就是E对f(e)的梯度×f(e)对e的梯度×e对w的梯度,目标就是把这个梯度拿去更新w
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











