









数据挖掘:关联规则
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
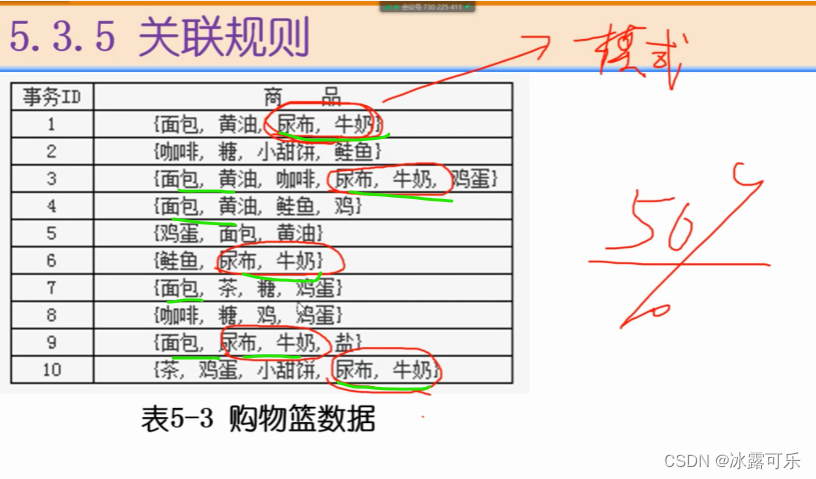
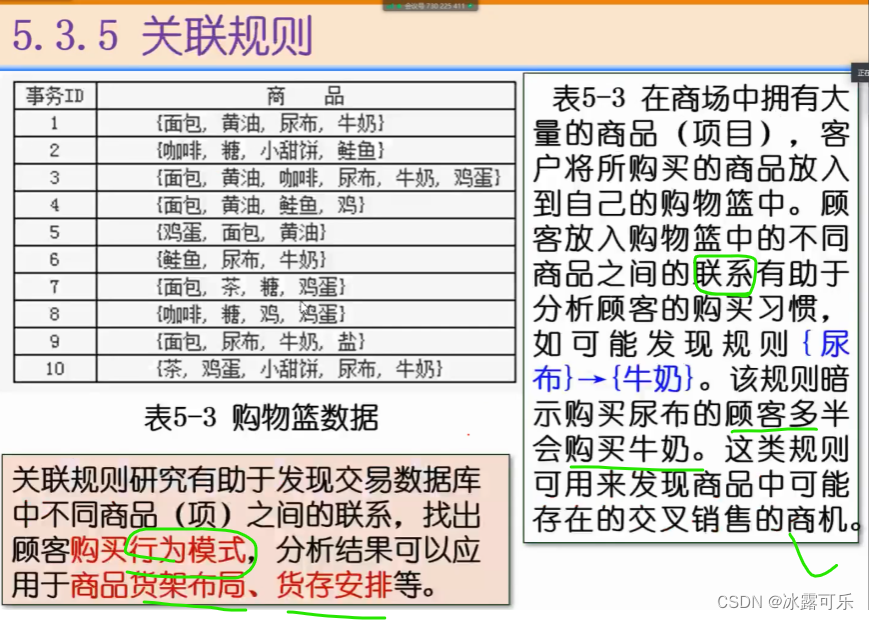
关联规则
如果相关性很大,那就可以去掉其中一个属性

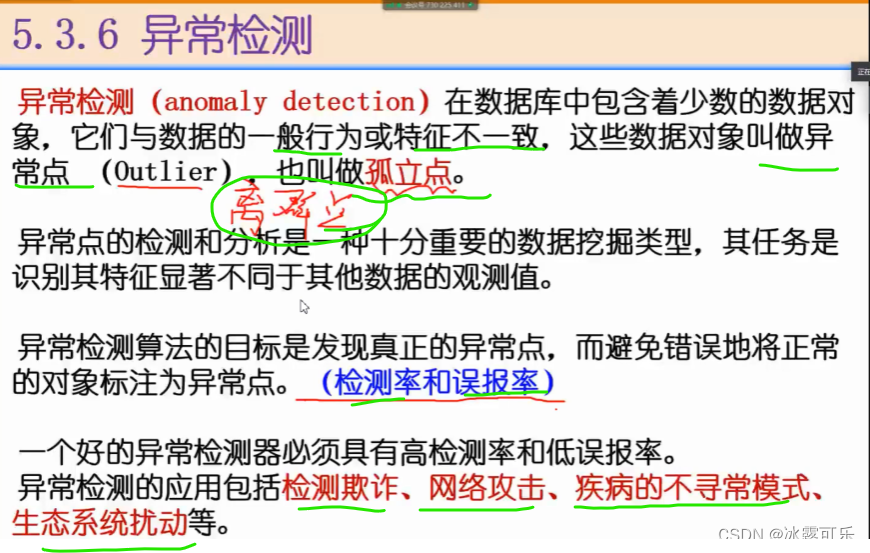
异常检测
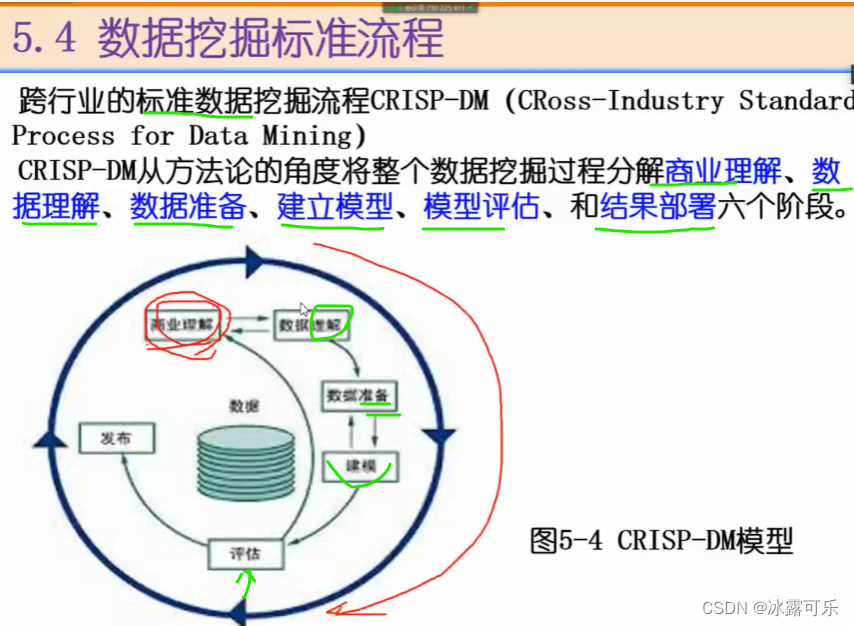
数据挖掘的标准流程



这些不仅是理论,更是实际业务会遇到的东西




NLP






长尾问题
数据挖掘的经典算法
这些可能会考的
去年就考了聚类哦


TP:实际为正,预测为正
FP:实际为负,预测为正
FN:实际为正,预测为负
TN:实际为负,预测为负
准确率acc,是TP和TN的在所有情况中的占比
recall,数据中所有正类中,真正被预测为正类的比例。就是被真的召回的正类比例
precise,在所有被预测为正类中,实际正类的比例【精确是正类的】这俩别混了

ROC是pr的曲线

检测出来了,但是你也不能误报
往往希望,recall高一点,而误报也要小
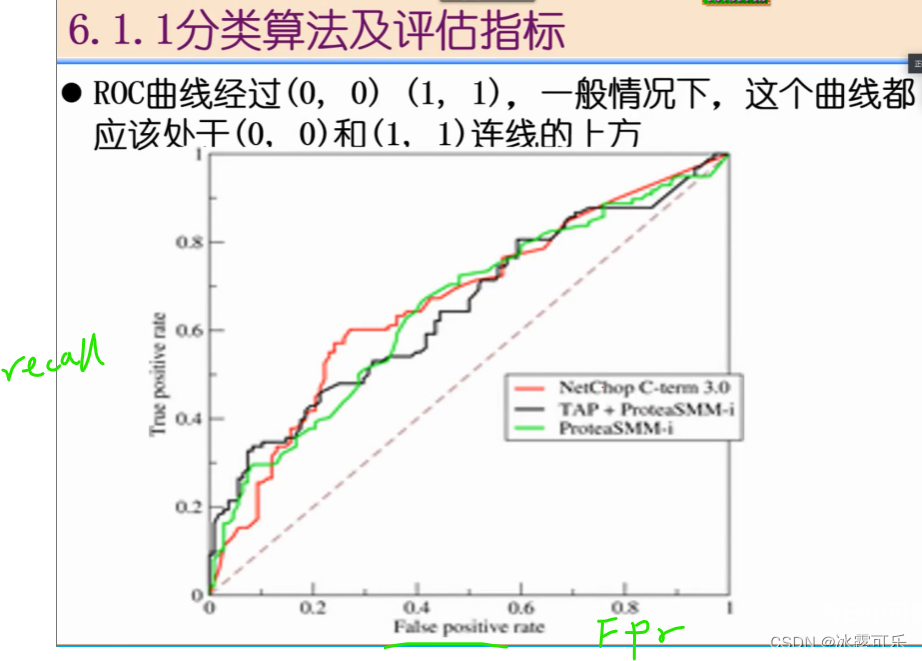
误报了
误报率是负样本认为正了

召回是1000个中的5个,好low
训练误差和泛华误差

分类算法评估指标:hold-out method
train和test,随机分组的交叉验证
k-fold,k组,但是每次k-1个为训练集,而剩下一组为训练集
轮番高k次
k一般是10,叫十指交叉验证

留一验证
当数据量很小,就留一个样本作为测试集

骚
分组,组元素个数为1
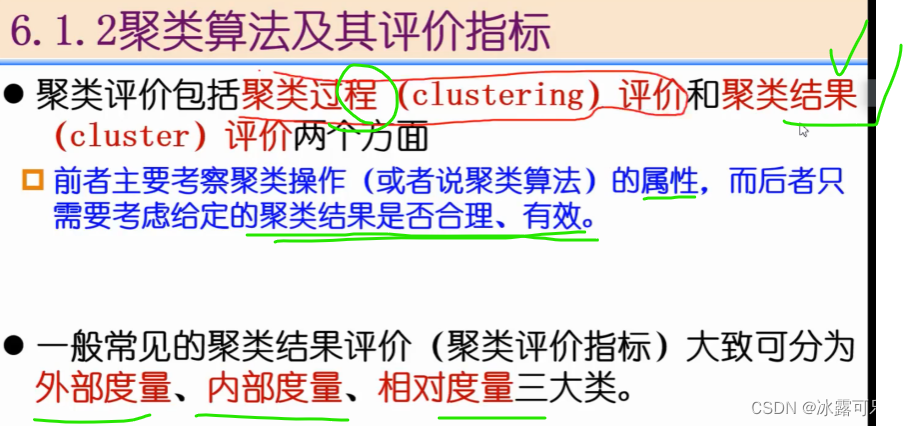
聚类方法

先了解,后面会详细讲解的
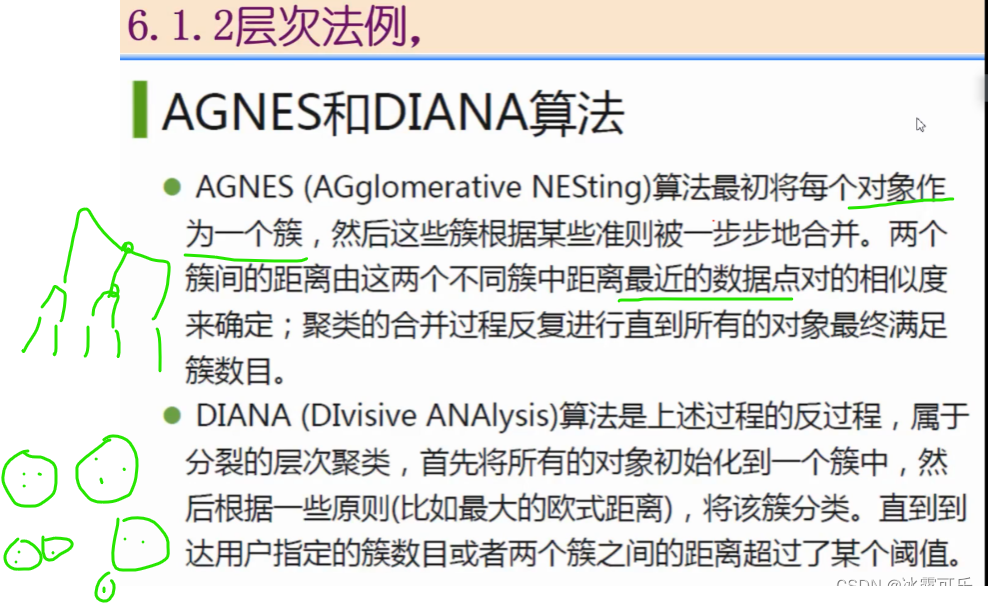
看层次


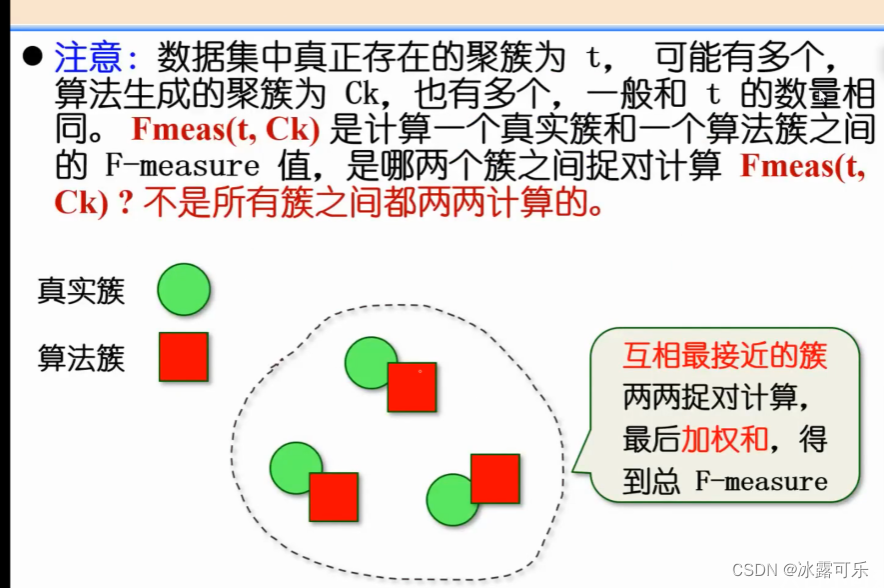

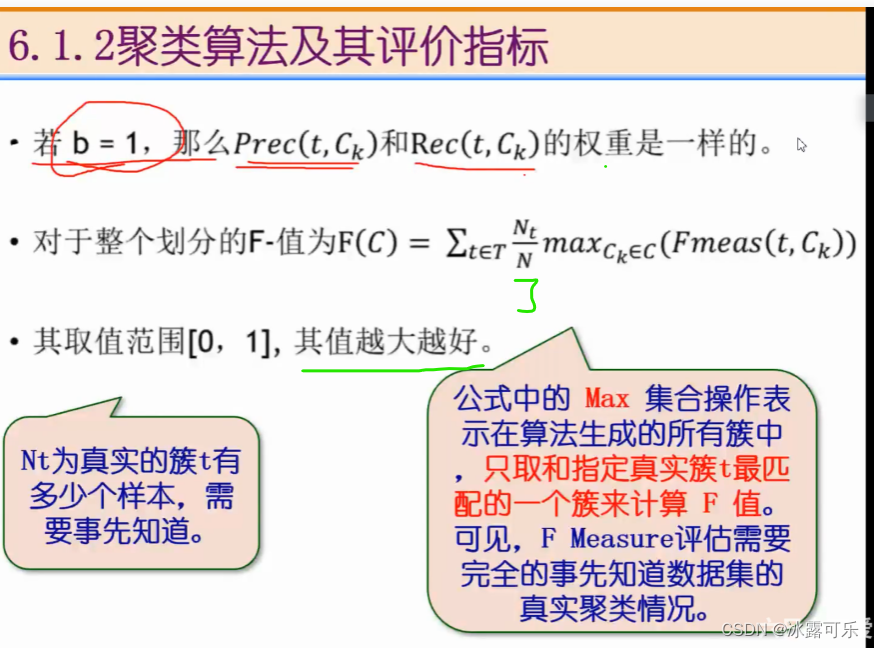
Nt就是正类
Ntk是确实是真的正类
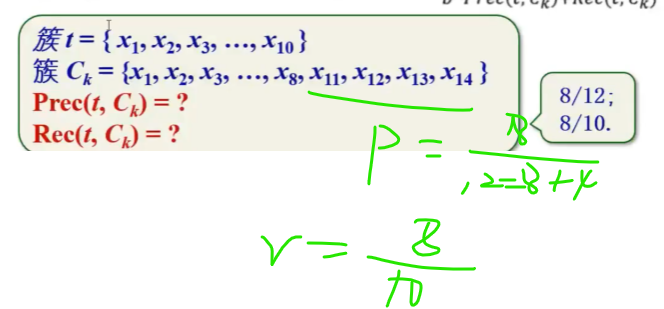


离差
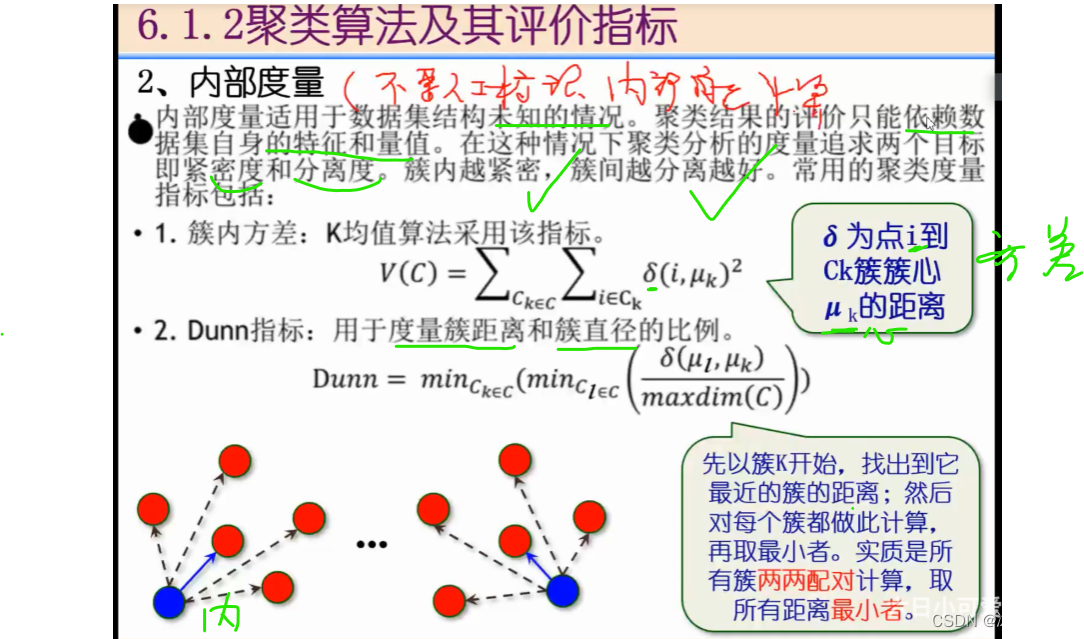
Ck中的i与中心u的距离
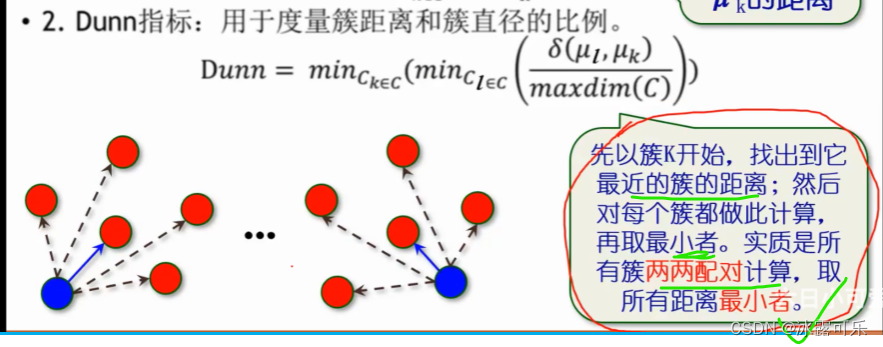
l簇和u簇的中心距离,越远越好
C4.5算法
开始具体的算法了
总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











