







 本文介绍了统计学中的Kolmogorov-Smirnov检验(KS检验)和QQ图两种非参数方法。KS检验用于判断两分布是否相同,而QQ图则通过比较两组数据的分位数来评估分布一致性。Python中可使用`scipy.stats`库进行相关计算和图形绘制。此外,讨论了可扩展性在分布式系统中的重要性,理想的可扩展系统应能随着计算资源的增加而线性提升性能。
本文介绍了统计学中的Kolmogorov-Smirnov检验(KS检验)和QQ图两种非参数方法。KS检验用于判断两分布是否相同,而QQ图则通过比较两组数据的分位数来评估分布一致性。Python中可使用`scipy.stats`库进行相关计算和图形绘制。此外,讨论了可扩展性在分布式系统中的重要性,理想的可扩展系统应能随着计算资源的增加而线性提升性能。
1.KS检验
Kolmogorov-Smirnov test(KS检验)是一种重要的非参数检验方法,应用非常广泛,比如之前介绍的数据库CMap,其核心算法就是借鉴KS检验。
KS检验是一种统计检验方法,其通过比较两样本的频率分布、或者一个样本的频率分布与特定理论分布(如正态分布)之间的差异大小来推论两个分布是否来自同一分布。
from scipy import stats
stats.kstest(rvs, cdf, args=(),…)
#其中rvs可以是数组、生成数组的函数或者scipy.stats里面理论分布的名字
#cdf可以与rvs一致。若rvs和cdf同是数组,则是比较两数组的分布是否一致;一个是数组,另一个是理论分布的名字,则是看样本是否否和理论分布
#args是一个元组,当rvs或者cds是理论分布时,这个参数用来存储理论分布的参数,如正态分布的mean和std。
from scipy import stats
stats.kstest(data_, 'norm',args=(test.mean(),test.std())
# KstestResult(statistic=xxxx, pvalue=xxxx)
2. qq图
版权声明:qq图部分内容转载自https://blog.csdn.net/weixin_40076694/article/details/80048105
为CSDN博主「星碎夜雨」的原创文章,遵循CC 4.0 BY-SA版权协议。
qq图有两个作用:1、检验一组数据是否服从某一分布。2、检验两个分布是否服从同一分布。qq图全称是quantile-quantile plot,从名称中可以了解到是和分位数相关的图。由于最近在做数据分析时用到了,然而看了一些博客,要么是qq图讲解的比较详尽但是没有使用Python;要么是使用Python语言但是没有讲清楚原理。基于此,想写一篇博客尽量讲清楚原理并且用Python实现出来。
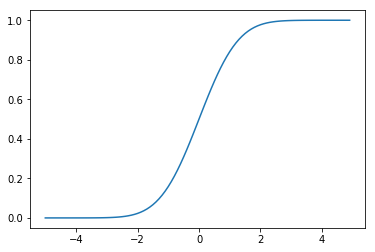
qq图原理是比较两组数据的累计分布函数来判断两组数据是否是服从同一分布,所以第一步我们应该做两组数据的累计分布。首先,作为对比我们看一下标准正太分布的累计分布图。
from scipy import stats
import numpy as np
x = np.arange(-5, 5, 0.1)
y = stats.norm.cdf(x, 0, 1)
plt.plot(x, y)
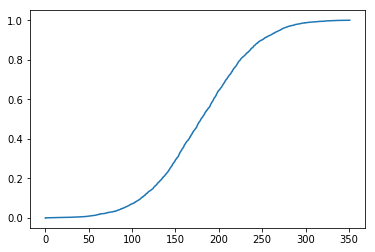
然后,绘制目标数据(这里使用UCI机器学习数据库中的churn数据集)的累计分布函数图。
import pandas as pd
churn_raw_data = pd.read_csv('churn.txt')
day_minute = churn_raw_data['Day Mins']
sorted_ = np.sort(day_minute)
yvals = np.arange(len(sorted_))/float(len(sorted_))
plt.plot(sorted_, yvals)
直观上对比,目标累计分布函数图和标准正太累计分布函数图差异不大,事实是不是这样呢?最后我们就可以做qq图做对比。
x_label = stats.norm.ppf(yvals) #对目标累计分布函数值求标准正太分布累计分布函数的逆
plt.scatter(x_label, sorted_)
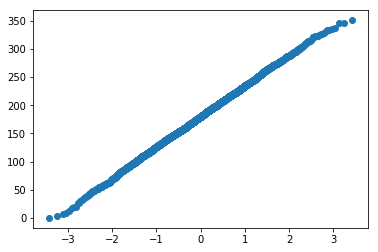
既然做对比那么对比的标准是什么呢,我们说如果所有点基本上在一条直线上,我们可以说这两个分布是同一分布。所以根据qq图,我们得出结论目标数据组服从正太分布。
上面是为了说明qq图的原理以及怎么使用pyhton进行手动操作,作为数据分析领域里比较全能的Python,它当然也是有包可以直接绘制qq图.
stats.probplot(day_minute, dist="norm", plot=plt)
plt.show()
还是比较方便就可以绘制的,那么比较两幅 qq图发现我们的理解是没有问题的。 qq图可以比较直观的比较两个分布是否相同的,在数据分析时也是比较常用。
参考文献:
https://stackoverflow.com/questions/3209362/how-to-plot-empirical-cdf-in-matplotlib-in-python
https://stats.stackexchange.com/questions/139708/qq-plot-in-python
https://docs.scipy.org/doc/scipy-0.16.0/reference/generated/scipy.stats.probplot.html
3.可扩展性(Scalability)
通常来说,构建分布式系统的目的是为了获取人们常常提到的可扩展的加速。所以,我们这里追求的是可扩展性(Scalability)。而我这里说的可扩展或者可扩展性指的是,如果我用一台计算机解决了一些问题,当我买了第二台计算机,我只需要一半的时间就可以解决这些问题,或者说每分钟可以解决两倍数量的问题。两台计算机构成的系统如果有两倍性能或者吞吐,就是我说的可扩展性。
这是一个很强大的特性。如果你构建了一个系统,并且只要增加计算机的数量,系统就能相应提高性能或者吞吐量,这将会是一个巨大的成果,因为计算机只需要花钱就可以买到。如果不增加计算机,就需要花钱雇程序员来重构这些系统,进而使这些系统有更高的性能,更高的运行效率,或者应用一个更好的算法之类的。花钱请程序员来修补这些代码,使它们运行的更快,通常会是一个昂贵的方法。我们还是希望能够通过从十台计算机提升到一千台计算机,就能扛住一百倍的流量。
所以,当人们使用一整个机房的计算机来构建大型网站的时候,为了获取对应的性能,必须要时刻考虑可扩展性。你需要仔细设计系统,才能获得与计算机数量匹配的性能。
参考资料:https://zhuanlan.zhihu.com/p/168757826

















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









