







python概率分布实现
概率分布内容涵盖:
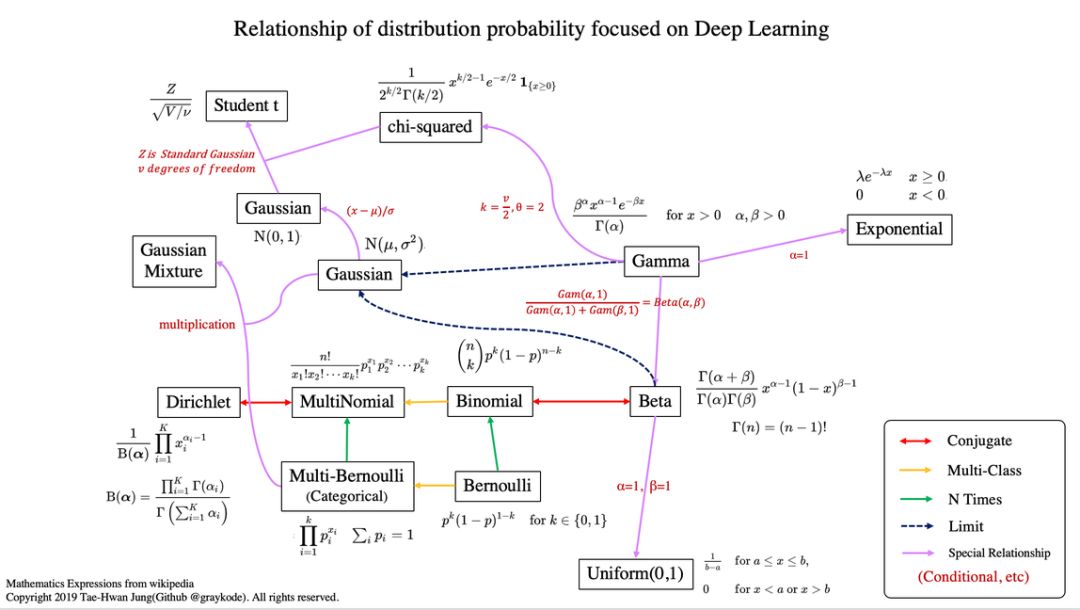
概率分布之间有联系:
伯努利分布重复几次就是二项分布,如果再扩展到多类别,就成为了多项式分布。注意,其中共轭(conjugate)表示的是互为共轭的概率分布;Multi-Class 表示随机变量多于 2 个;N Times 表示我们还会考虑先验分布 P(X)。
在贝叶斯概念理论中,如果后验分布 p(θ | x) 与先验分布 p(θ) 是相同的概率分布族,那么后验分布可以称为共轭分布,先验分布可以称为似然函数的共轭先验。
离散型
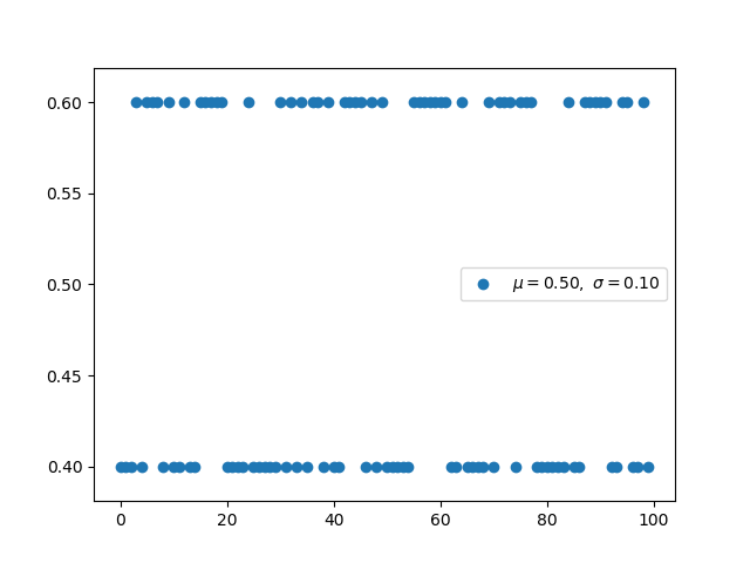
1. 伯努利分布(离散型)
伯努利分布并不考虑先验概率 P(X),它是单个二值随机变量的分布。它由单个参数φ∈ [0, 1] 控制,φ 给出了随机变量等于 1 的概率。我们使用二元交叉熵函数实现二元分类,它的形式与对伯努利分布取负对数是一致的。
随机变量X只取0和1两个值,并且相应的概率为:

则称随机变量X服从参数为p的伯努利分布.
import random
import numpy as np
import matplotlib.pyplot as plt
def bernoulli(p, k):
return p if k else 1 - p
n_experiment = 100
p = 0.6
x = np.arange(n_experiment)
y = []
for _ in range(n_experiment):
pick = bernoulli(p, k=bool(random.getrandbits(1)))
# random.getrandbits(k)返回一个不大于K位的Python整数(十进制),比如k=10,则结果是0~2^10之间的整数。
y.append(pick)
u, s = np.mean(y), np.std(y)
plt.scatter(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f$' % (u, s))
plt.legend()
plt.show()
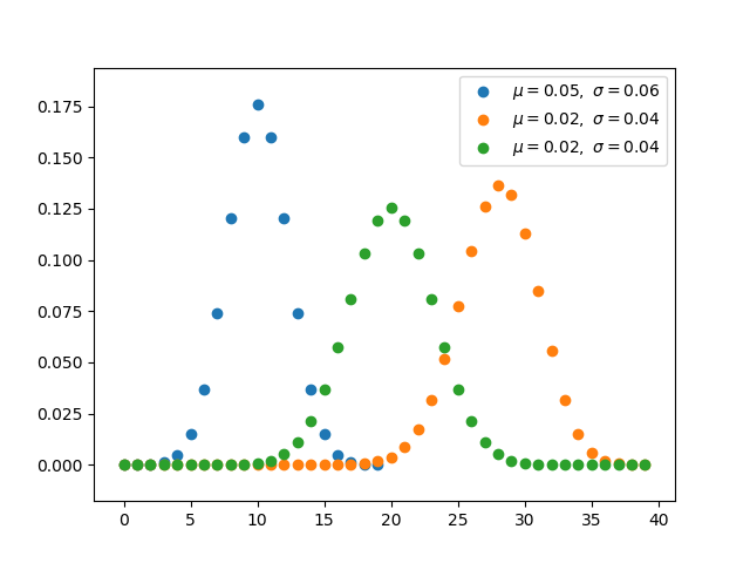
2. 二项分布(离散型)
二项分布是由伯努利提出的概念,指的是重复 n 次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立。
把关于X的二项分布写成X ~ B(n, p)。对应的概率质量函数如下。

这里k = 0, 1, 2, …, n,并且原括号是组合的表示形式,组合的计算公式如下:

import numpy as np
import matplotlib.pyplot as plt
import operator as op
from functools import reduce
def const(n, r):
r = min(r, n-r)
numer = reduce(op.mul, range(n, n-r, -1), 1) # op.mul返回a*b,a与b都为数字。
denom = reduce(op.mul, range(1, r+1), 1) # reduce()函数——阶乘(对参数序列中元素进行累积)
# reduce(function, iterable[, initializer])function -- 函数,有两个参数;iterable -- 可迭代对象;initializer -- 可选,初始参数
return numer / denom
def binomial(n, p):
q = 1 - p
y = [const(n, k) * (p ** k) * (q ** (n-k)) for k in range(n)]
return y, np.mean(y), np.std(y)
for ls in [(0.5, 20), (0.7, 40), (0.5, 40)]:
p, n_experiment = ls[0], ls[1]
x = np.arange(n_experiment)
y, u, s = binomial(n_experiment, p)
plt.scatter(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f$' % (u, s))
plt.legend()
plt.show()
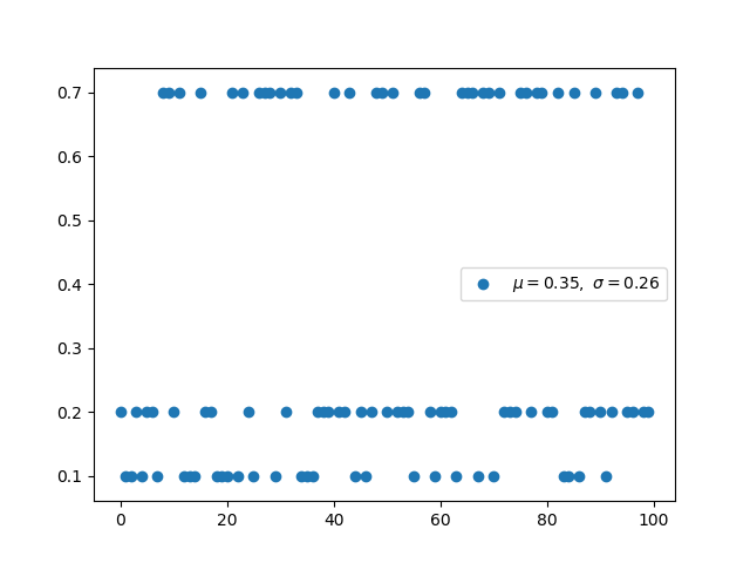
3.Multi-Bernoulli 分布(离散型)
Multi-Bernoulli 分布又称为范畴分布(Categorical distribution),它的类别超过 2,交叉熵的形式与该分布的负对数形式是一致的。
import random
import numpy as np
from matplotlib import pyplot as plt
def categorical(p, k):
return p[k]
n_experiment = 100
p = [0.2, 0.1, 0.7]
x = np.arange(n_experiment)
y = []
for _ in range(n_experiment):
pick = categorical(p, k=random.randint(0, len(p) - 1))
y.append(pick)
u, s = np.mean(y), np.std(y)
plt.scatter(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f$' % (u, s))
plt.legend()
plt.show()
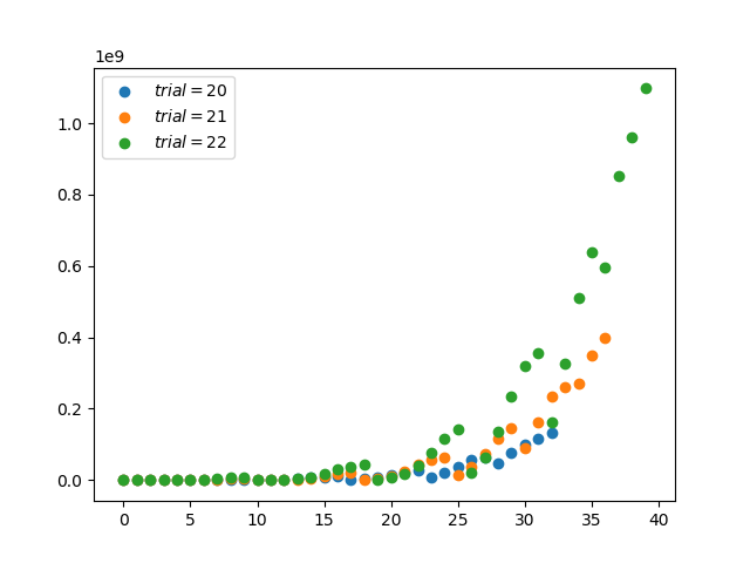
4. 多项式分布(离散型)
多项式分布(Multinomial distribution)与范畴分布的关系就像伯努利分布与二项分布之间的关系。
import numpy as np
from matplotlib import pyplot as plt
import operator as op
from functools import reduce
def factorial(n):
return reduce(op.mul, range(1, n + 1), 1)
def const(n, a, b, c):
# return n! / a! b! c!, where a+b+c == n
assert a + b + c == n
numer = factorial(n)
denom = factorial(a) * factorial(b) * factorial(c)
return numer / denom
def multinomial(n):
"""
:param x : list, sum(x) should be `n`
:param n : number of trial
:param p: list, sum(p) should be `1`
"""
# get all a,b,c where a+b+c == n, a<b<c
ls = []
for i in range(1, n + 1):
for j in range(i, n + 1):
for k in range(j, n + 1):
if i + j + k == n:
ls.append([i, j, k])
y = [const(n, l[0], l[1], l[2]) for l in ls]
x = np.arange(len(y))
return x, y, np.mean(y), np.std(y)
for n_experiment in [20, 21, 22]:
x, y, u, s = multinomial(n_experiment)
plt.scatter(x, y, label=r'$trial=%d$' % (n_experiment))
plt.legend()
plt.show()
连续型
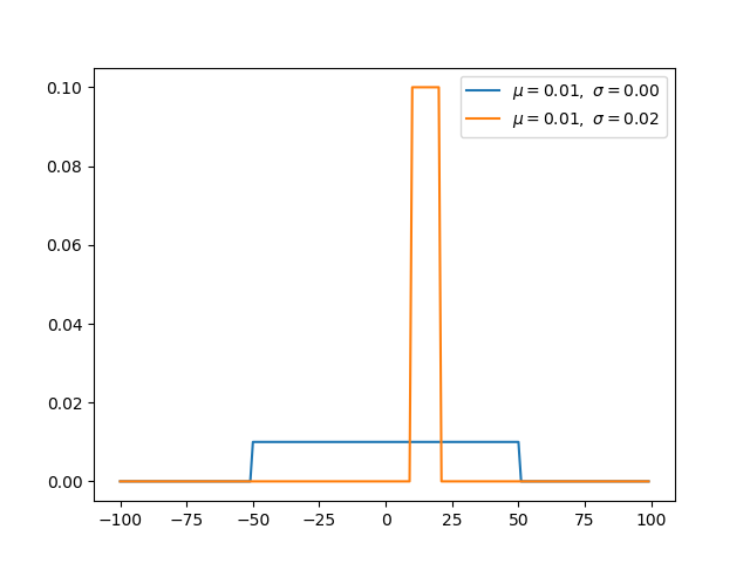
1.均匀分布(连续型)
均匀分布是指闭区间 [a, b] 内的随机变量,且每一个变量出现的概率是相同的。

import numpy as np
import matplotlib.pyplot as plt
def uniform(x, a, b):
y = [1 / (b - a) if a <= val and val <= b
else 0 for val in x]
return x, y, np.mean(y), np.std(y)
x = np.arange(-100, 100) # define range of x
for ls in [(-50, 50), (10, 20)]:
a, b = ls[0], ls[1]
x, y, u, s = uniform(x, a, b)
plt.plot(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f$' % (u, s))
plt.legend()
plt.show()
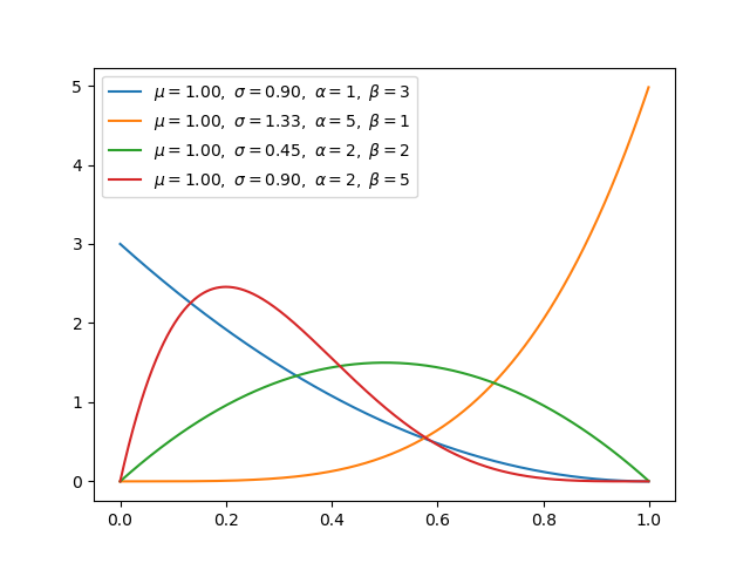
2.Beta 分布(连续型)
贝塔分布(Beta Distribution) 是一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,它指一组定义在 (0,1) 区间的连续概率分布。均匀分布是 Beta 分布的一个特例,即在 alpha=1、 beta=1 的分布。

import numpy as np
from matplotlib import pyplot as plt
def gamma_function(n):
cal = 1
for i in range(2, n):
cal *= i
return cal
def beta(x, a, b):
gamma = gamma_function(a + b) / (gamma_function(a) * gamma_function(b))
y = gamma * (x ** (a - 1)) * ((1 - x) ** (b - 1))
return x, y, np.mean(y), np.std(y)
for ls in [(1, 3), (5, 1), (2, 2), (2, 5)]:
a, b = ls[0], ls[1]
# x in [0, 1], trial is 1/0.001 = 1000
x = np.arange(0, 1, 0.001, dtype=np.float)
x, y, u, s = beta(x, a=a, b=b)
plt.plot(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f,'
r'\ \alpha=%d,\ \beta=%d$' % (u, s, a, b))
plt.legend()
# plt.savefig('graph/beta.png')
plt.show()
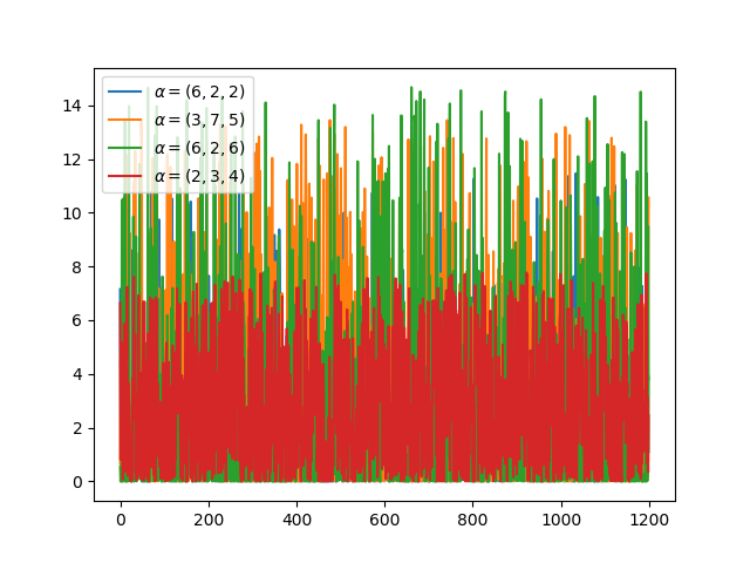
3. 狄利克雷分布(连续型)
狄利克雷分布(Dirichlet distribution)是一类在实数域以正单纯形(standard simplex)为支撑集(support)的高维连续概率分布,是 Beta 分布在高维情形的推广。在贝叶斯推断中,狄利克雷分布作为多项式分布的共轭先验得到应用,在机器学习中被用于构建狄利克雷混合模型。

from random import randint
import numpy as np
from matplotlib import pyplot as plt
def normalization(x, s):
# return: normalizated list, where sum(x) == s
return [(i * s) / sum(x) for i in x]
def sampling():
return normalization([randint(1, 100),
randint(1, 100), randint(1, 100)], s=1)
def gamma_function(n):
cal = 1
for i in range(2, n):
cal *= i
return cal
def beta_function(alpha):
"""
:param alpha: list, len(alpha) is k
:return:
"""
numerator = 1
for a in alpha:
numerator *= gamma_function(a)
denominator = gamma_function(sum(alpha))
return numerator / denominator
def dirichlet(x, a, n):
"""
:param x: list of [x[1,...,K], x[1,...,K], ...], shape is (n_trial, K)
:param a: list of coefficient, a_i > 0
:param n: number of trial
:return:
"""
c = (1 / beta_function(a))
y = [c * (xn[0] ** (a[0] - 1)) * (xn[1] ** (a[1] - 1))
* (xn[2] ** (a[2] - 1)) for xn in x]
x = np.arange(n)
return x, y, np.mean(y), np.std(y)
n_experiment = 1200
for ls in [(6, 2, 2), (3, 7, 5), (6, 2, 6), (2, 3, 4)]:
alpha = list(ls)
# random samping [x[1,...,K], x[1,...,K], ...], shape is (n_trial, K)
# each sum of row should be one.
x = [sampling() for _ in range(1, n_experiment + 1)]
x, y, u, s = dirichlet(x, alpha, n=n_experiment)
plt.plot(x, y, label=r'$\alpha=(%d,%d,%d)$' % (ls[0], ls[1], ls[2]))
plt.legend()
# plt.savefig('graph/dirichlet.png')
plt.show()
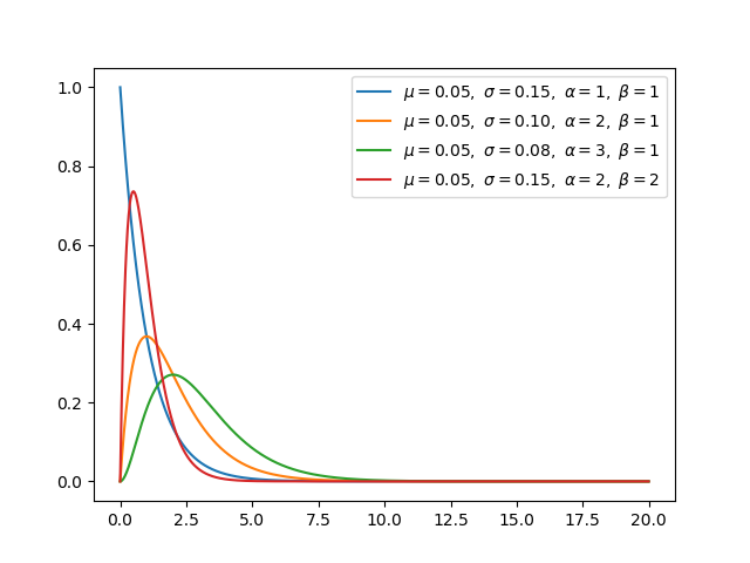
4.Gamma 分布(连续型)
Gamma 分布是统计学中的常见连续型分布,指数分布、卡方分布和 Erlang 分布都是它的特例。如果 Gamma(a,1) / Gamma(a,1) + Gamma(b,1),那么 Gamma 分布就等价于 Beta(a, b) 分布。

import numpy as np
from matplotlib import pyplot as plt
def gamma_function(n):
cal = 1
for i in range(2, n):
cal *= i
return cal
def gamma(x, a, b):
c = (b ** a) / gamma_function(a)
y = c * (x ** (a - 1)) * np.exp(-b * x)
return x, y, np.mean(y), np.std(y)
for ls in [(1, 1), (2, 1), (3, 1), (2, 2)]:
a, b = ls[0], ls[1]
x = np.arange(0, 20, 0.01, dtype=np.float)
x, y, u, s = gamma(x, a=a, b=b)
plt.plot(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f,'
r'\ \alpha=%d,\ \beta=%d$' % (u, s, a, b))
plt.legend()
# plt.savefig('graph/gamma.png')
plt.show()
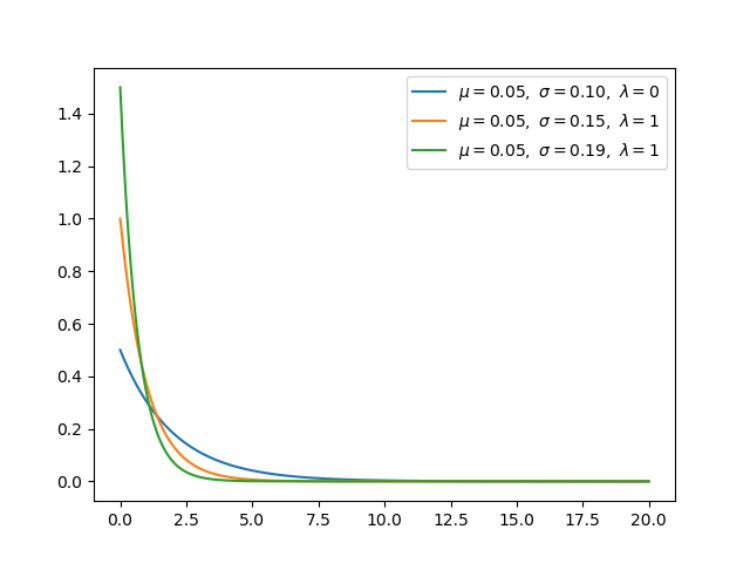
5. 指数分布(连续型)
指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进入机场的时间间隔、打进客服中心电话的时间间隔等等。当 alpha 等于 1 时,指数分布就是 Gamma 分布的特例。
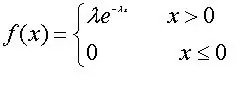
import numpy as np
from matplotlib import pyplot as plt
def exponential(x, lamb):
y = lamb * np.exp(-lamb * x)
return x, y, np.mean(y), np.std(y)
for lamb in [0.5, 1, 1.5]:
x = np.arange(0, 20, 0.01, dtype=np.float)
x, y, u, s = exponential(x, lamb=lamb)
plt.plot(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f,'
r'\ \lambda=%d$' % (u, s, lamb))
plt.legend()
# plt.savefig('graph/exponential.png')
plt.show()
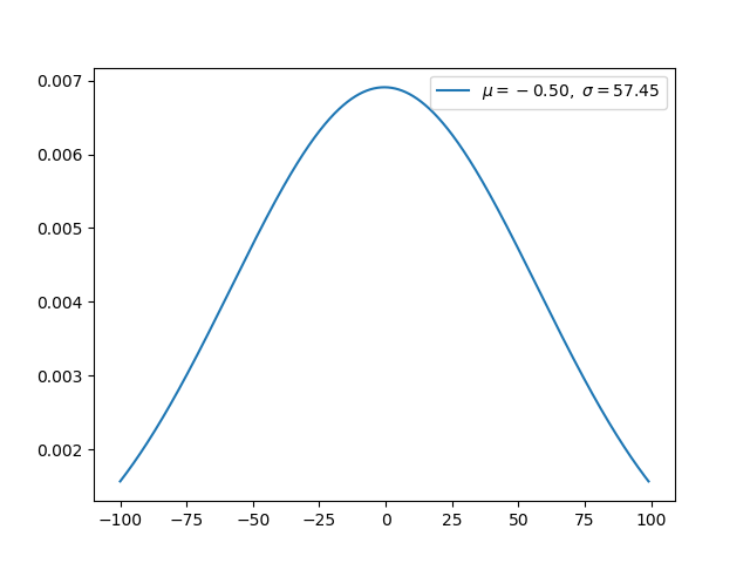
6.高斯分布(连续型)
高斯分布或正态分布是最为重要的分布之一,它广泛应用于整个机器学习的模型中。例如,我们的权重用高斯分布初始化、我们的隐藏向量用高斯分布进行归一化等等。

import numpy as np
from matplotlib import pyplot as plt
def gaussian(x, n):
u = x.mean()
s = x.std()
# divide [x.min(), x.max()] by n
x = np.linspace(x.min(), x.max(), n)
a = ((x - u) ** 2) / (2 * (s ** 2))
y = 1 / (s * np.sqrt(2 * np.pi)) * np.exp(-a)
return x, y, x.mean(), x.std()
x = np.arange(-100, 100) # define range of x
x, y, u, s = gaussian(x, 10000)
plt.plot(x, y, label=r'$\mu=%.2f,\ \sigma=%.2f$' % (u, s))
plt.legend()
# plt.savefig('graph/gaussian.png')
plt.show()
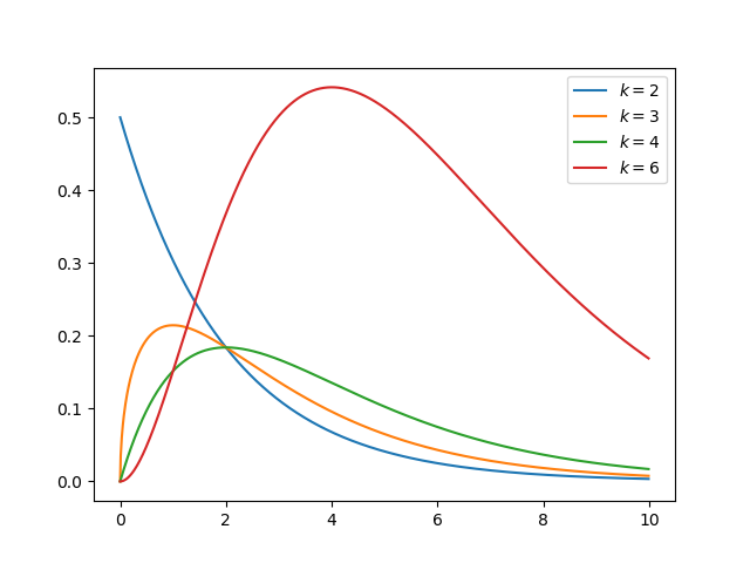
7.卡方分布(连续型)
简单而言,卡方分布(Chi-squared)可以理解为,k 个独立的标准正态分布变量的平方和服从自由度为 k 的卡方分布。卡方分布是一种特殊的伽玛分布,是统计推断中应用最为广泛的概率分布之一,例如假设检验和置信区间的计算。

import numpy as np
from matplotlib import pyplot as plt
def gamma_function(n):
cal = 1
for i in range(2, n):
cal *= i
return cal
def chi_squared(x, k):
c = 1 / (2 ** (k/2)) * gamma_function(k//2)
y = c * (x ** (k/2 - 1)) * np.exp(-x /2)
return x, y, np.mean(y), np.std(y)
for k in [2, 3, 4, 6]:
x = np.arange(0, 10, 0.01, dtype=np.float)
x, y, _, _ = chi_squared(x, k)
plt.plot(x, y, label=r'$k=%d$' % (k))
plt.legend()
# plt.savefig('graph/chi-squared.png')
plt.show()
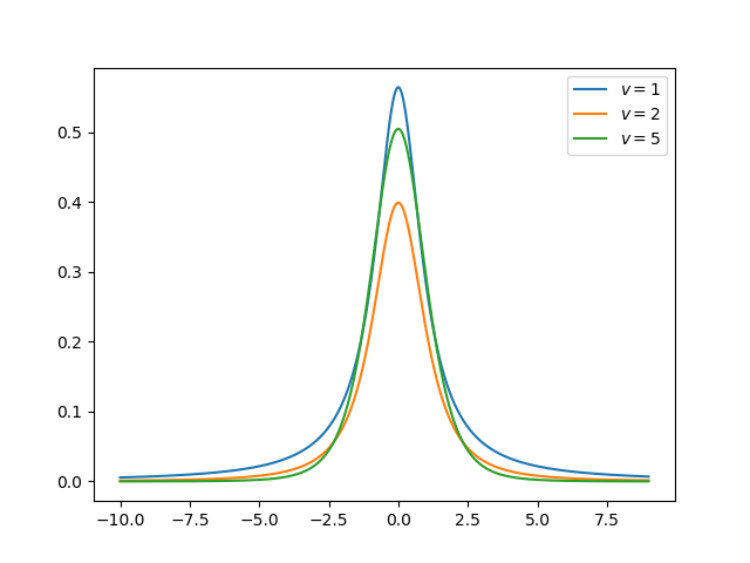
8.学生 t-分布
学生 t-分布(Student t-distribution)用于根据小样本来估计呈正态分布且变异数未知的总体,其平均值是多少。t 分布也是对称的倒钟型分布,就如同正态分布一样,但它的长尾占比更多,这意味着 t 分布更容易产生远离均值的样本。

import numpy as np
from matplotlib import pyplot as plt
def gamma_function(n):
cal = 1
for i in range(2, n):
cal *= i
return cal
def student_t(x, freedom, n):
# divide [x.min(), x.max()] by n
x = np.linspace(x.min(), x.max(), n)
c = gamma_function((freedom + 1) // 2) \
/ np.sqrt(freedom * np.pi) * gamma_function(freedom // 2)
y = c * (1 + x**2 / freedom) ** (-((freedom + 1) / 2))
return x, y, np.mean(y), np.std(y)
for freedom in [1, 2, 5]:
x = np.arange(-10, 10) # define range of x
x, y, _, _ = student_t(x, freedom=freedom, n=10000)
plt.plot(x, y, label=r'$v=%d$' % (freedom))
plt.legend()
# plt.savefig('graph/student_t.png')
plt.show()














 1305
1305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









