







该问题主要是深拷贝下对random的处理
方法一 链表的拼接与拆分
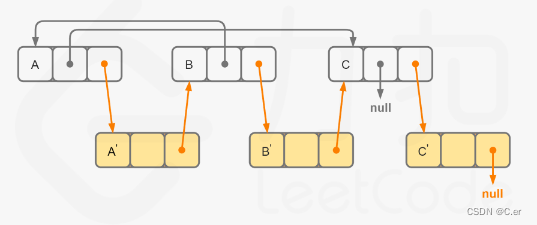
如图,新链表的random就可以处理了,如A’的random为A的random的下一个。
class Solution {
public:
// 深拷贝
Node* copyRandomList(Node* head) {
//情况1:如果头结点是空,直接返回空
if(!head)return nullptr;
//定义三个指针,p为处理原来的链,q为处理新加的链,copy指向新处理的链的头部
Node* p = head,*copy,*q;
//在原链表的基础上间隔添加新结点(这样方便后续random的操作)
while(p){ //遍历整个原链表
q = new Node(p->val); //创建新结点
q->next = p->next;
p->next = q;
p = q->next;
}
p = head; //p和q从各自的队头开始
q = head->next;
while(p){ //如果两队遍历完了
q->random = p->random?p->random->next:nullptr;//注意这里要判断random是否是空
p = q->next;
q = p?p->next:nullptr; //注意这里要看p是否为空
}
q = copy = head->next; //p和q从各自的队头开始
p = head;
while(q->next){ //如果两个队列都有下一个的结点的话(即不是最后一个结点)
p->next = q->next;
p = q->next;
q->next = p->next;
q = p->next;
}
p->next = nullptr; //尾结点处理
q->next = nullptr;
return copy;
}
};
注意事项:写的过程中容易出现member access within null pointer of type,要考虑空指针的情况。
递归处理
这个代码挺容易理解的,利用了哈希表
class Solution {
unordered_map<Node*,Node*> umap;
public:
Node* copyRandomList(Node* head) {
if(head==nullptr){
return nullptr;
}
if(!umap.count(head)){
Node* p = new Node(head->val);
umap[head] = p;
p->next = copyRandomList(head->next);
p->random = copyRandomList(head->random);
}
return umap[head];
}
};
注意事项:别忘了unordered_map::count()函数
由于unordered_map不允许存储具有重复键的元素,因此count()函数本质上检查unordered_map中是否存在具有给定键的元素。
另外的理解
其实这到题也可理解成copy一个图,把上述代码中的umap换成visited,就类似与我们求深度优先遍历的图的代码(想起来了有没有)
class Solution {
unordered_map<Node*,Node*> umap;
public:
Node* copyRandomList(Node* head) {
if(head==nullptr){
return nullptr;
}
if(!umap.count(head)){
Node* p = new Node(head->val);
umap[head] = p;
p->next = copyRandomList(head->next);
p->random = copyRandomList(head->random);
}
return umap[head];
}
};















 81
81











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









