







前言
借鉴了图像分割和识别网络那边的Unet运用到图像恢复领域上,主要包括图像降噪、运动去模糊、失焦模糊和去雨四个任务。
创新点:
①提出了一种新的基于Transformer结构的自注意力模块,类似于SWIR。
②提出了一种可以学习的多尺度调制器嵌入到解码器中。
网络结构
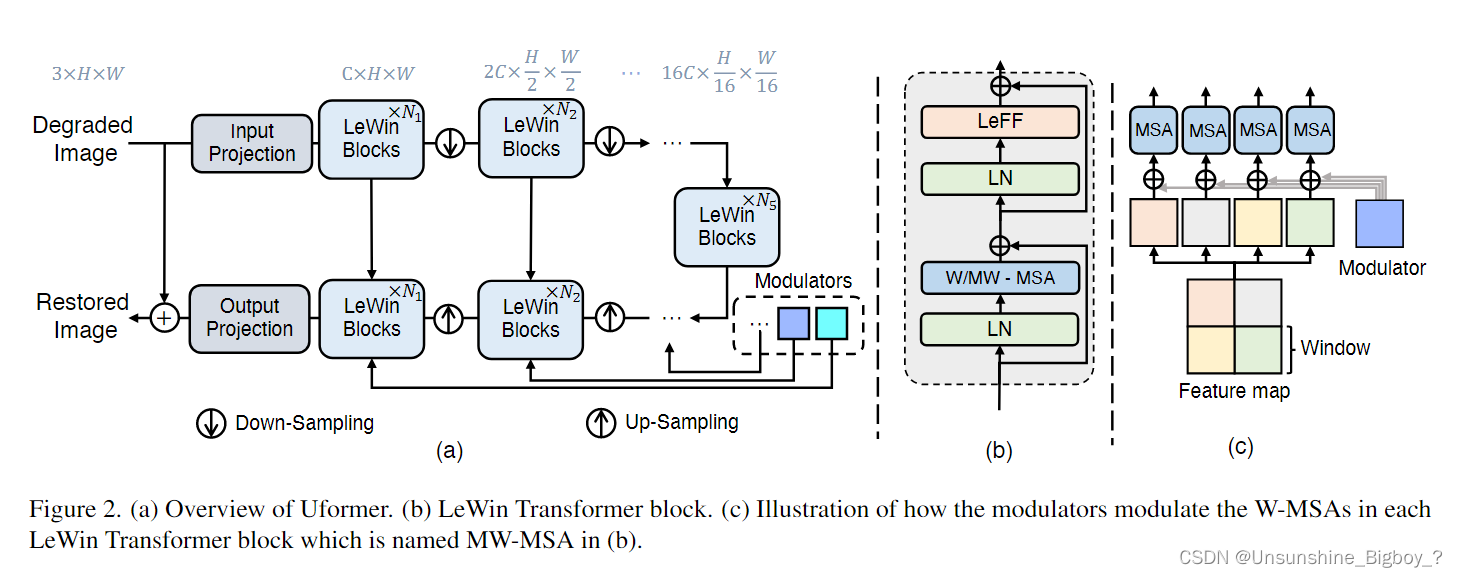
整体网络结构其实就是Unet,但是里面的模块不一样。
首先,输入时一个3×H×W的图像,然后经过一个3×3的卷积核和LeakyReLU激活函数组成的卷积层提取特征,即为图中的Input Projection,输出为C×H×W的特征层。然后进入网络前半部分,编码器,是由K个LeWin Blocks组成的(实验结果显示K=4结果较好),每一层都是先经过LeWin模块后再经过一个下采样层,通道数翻倍,长宽减半,与解码器后面对应相同大小的特征进行叠加。
LeWin Transformer模块
这个模块在论文中说的目的是为了增强局部特征,减少计算量。这个计算量是相对整幅图像进行注意力计算,只不过将图像分成很多子图像进行注意力计算。但是,本质上来说其实就是局部注意力机制,将图像分成M×M个子图像,然后分别对每个子图像内部进行注意力计算,存在的问题其实是子图像和子图像之间没有信息交互。其实SWIN Transformer 就是在做这样一件事,但是还加上了移动的窗口,所以效果会更好。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









