






前言
生成模型主要分为两类方法,一种是基于GAN模型的生成方法,另外一种是基于对数似然模型,例如VAE、DDPM等。GAN方法在FID、Inception Score(IS)、Precision等指标上取得不错的效果,但是在生成图片的多样性上有所欠缺,而基于对数似然的方法在多样性上效果更好。另外,GAN的缺点很明显,训练困难;而对数似然模型的缺点就是生成速度慢,并且在生成质量上不如GAN。于是,论文提出生产样本的多样性和质量是一个值得权衡的问题。所以,论文希望改善DDPM这种基于对数似然的生成方法,通过分类器引导来减少样本多样性而改善生成图像的质量,使得其在FID等指标上达到GAN的效果。
创新点有三个:①通过消融实验改进了DDPM的模型结构;②提出了一种分类器引导的方法来改善扩散模型的生成质量;③发现可以调整单个超参数,即分类器梯度的比例,以牺牲多样性来换取保真度。
以往DDPM改进方法
论文先介绍了之前的improve DDPM和DDIM工作,是在这个之上进行改进的。对于improved DDPM,主要是提出了可学习的方差和新的混合损失函数,作者也同意这个改进是有效的。至于DDIM,作者认为只有当使用少于50个采样步骤才是有效的。
其次,论文用Precision和IS作为衡量保真度的指标,用Recall去衡量多样性。
Architecture Improvements
主要做了如下改动:
①增加模型的深度和宽度,使得模型大小保持相对恒定。
②增加了注意力机制的heads
③使用32×32、16×16和8×8的分辨率进行注意力计算
④使用BigGAN的残差模块进行上采样和下采样
⑤残差连接系数改为
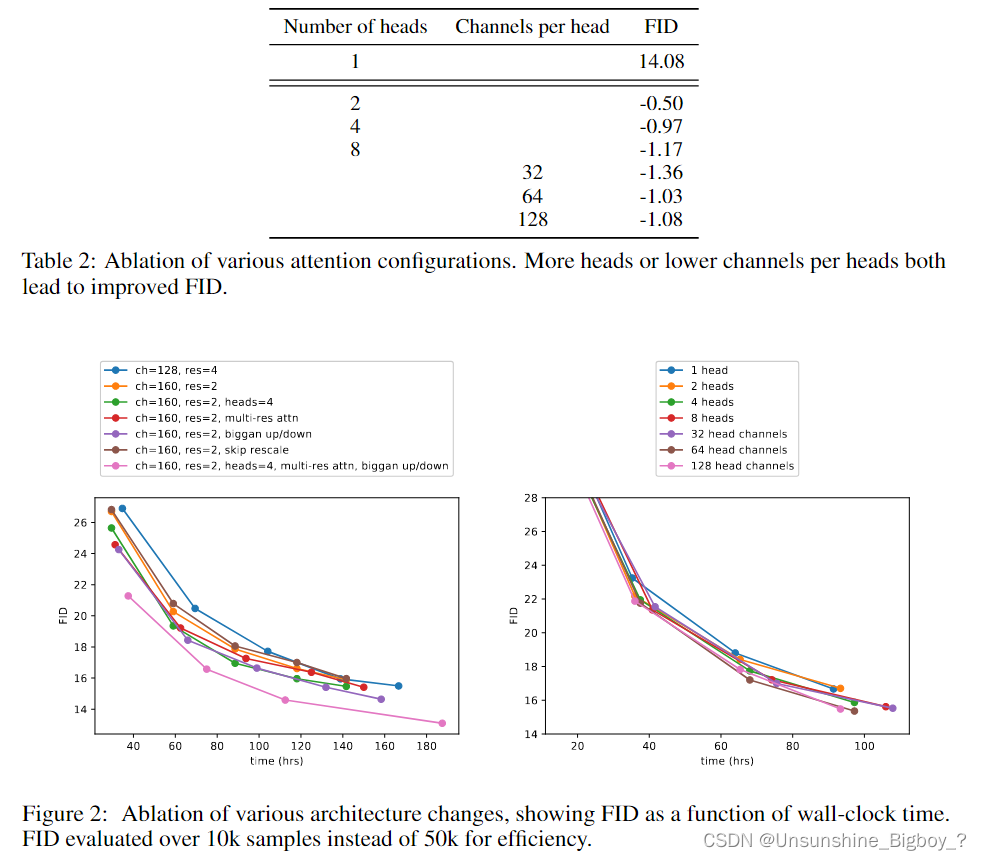
上图所示就是消融实验的部分,通道数更多虽然效果更好,但是时间也会更加长。于是,最后选择的128个基础通道,每个分辨率上两个残差块,多分辨率注意力机制,BigGAN的上下采样,每个head64个通道。
此外还加入了Adaptive Group Normalization,在Group Normalization后将时间步长和类别嵌入到每个残差块中,计算方式如下:AdaGN(h, y) = ys GroupNorm(h) + yb,h是第一次卷积之后的残差块的中间激活层,y=[ys,yb]是从时间步长和类嵌入的线性投影获得的。

Classifier Guidance
探索用一种分类器去改进DDPM的生成。通过在噪声图中训练一个分类器,然后使用梯度∇xt log pφ(y|xt, t)去引导扩散模型的采样。
条件逆扩散过程

上述就是逆扩散过程中加入分类器之后的推导,最后相比原来改变了均值加上了g,C4可以忽略。下面是伪代码,只是在训练过程对每个图像加入了label y,在逆扩散过程中改变了均值。

条件DDIM

在条件引导的DDIM中,改变了噪声的预测方式,减去了一个和label相关的值。下面是伪代码:

系数s对结果的影响
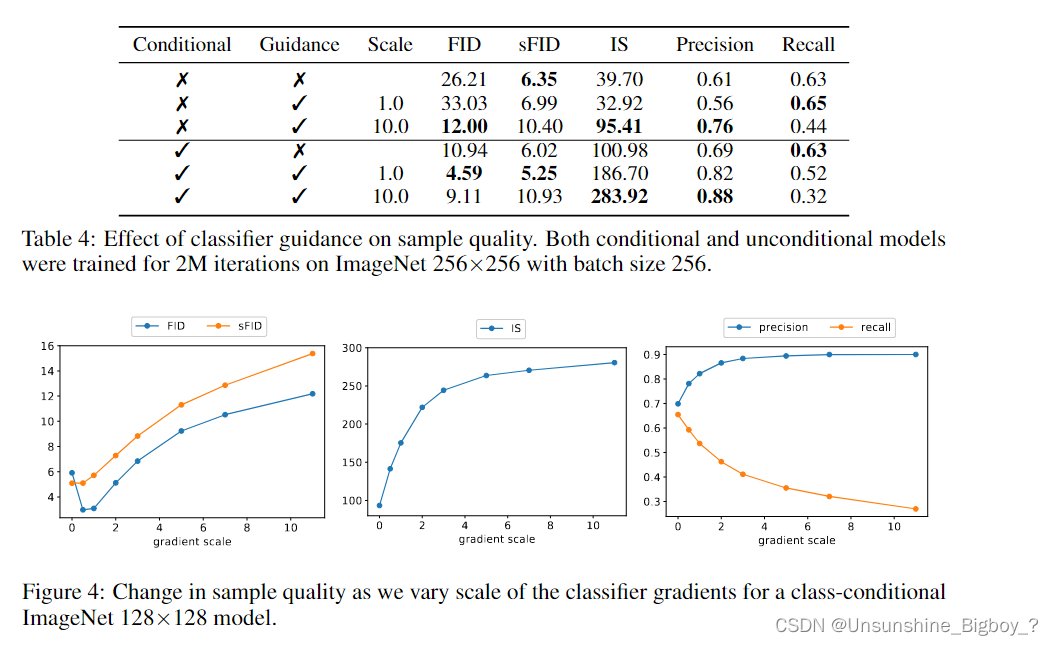
 可以观察到系数s无论是对条件生成和无条件生成都会有影响。其次就是和bigGAN的对比试验,可以看到在Recall还是有所欠缺,但是在FID上确实达到不错的效果。
可以观察到系数s无论是对条件生成和无条件生成都会有影响。其次就是和bigGAN的对比试验,可以看到在Recall还是有所欠缺,但是在FID上确实达到不错的效果。
实验结果
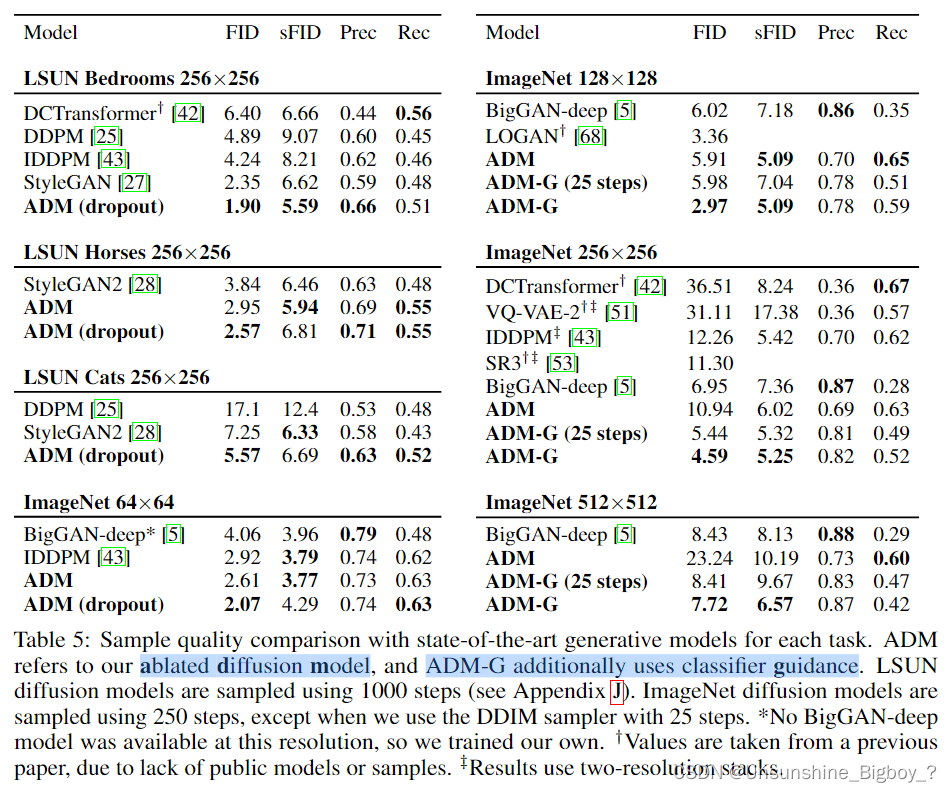
从上图的结果可以观察到,ADM-G确实对于GAN来说在FID上效果更加显著,其次另外一个结果就是与DDIM结合的ADM-G(25)也取得了非常不错的效果,而且只使用了25个steps。在下图的生成图像的多样性上来说,改进后的DDPM优于BigGAN。

最后,在Table5中的ImageNet256×256的实验中,对比了其他的条件DDPM扩散模型,例如SR3这种先经过双三次线性插值上采样和噪声拼接作为条件再进行扩散生成,可以看到论文提出的分类器引导的方法可以取得更好的FID。
其次就是下面
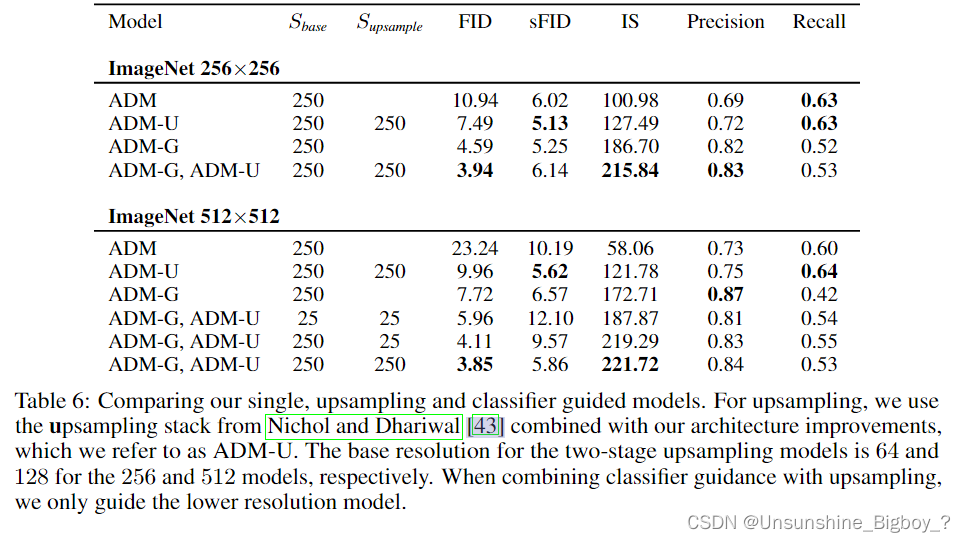
上采样作为条件的方法在一定程度上也能提高FID,说明这些方法是可以互补的。
总结
基于DDPM后续任务improved DDPM和DDIM上进行了改进,更加详细地优化了DDPM的结构,从而生成质量更高的图像;其次提出分类器引导的思想,更好地引导DDPM的条件生成,从而超越GAN模型。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









