







一、安装 AlterManager
- 如果没有安装 Prometheus 以及监控客户端的话,可以看博主前面的文章:Prometheus(普罗米修斯)监控系统
[root@k8s-master01 ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
[root@k8s-master01 ~]# tar xf alertmanager-0.24.0.linux-amd64.tar.gz
[root@k8s-master01 ~]# mv alertmanager-0.24.0.linux-amd64 /usr/local/alertmanager
[root@k8s-master01 ~]# nohup /usr/local/alertmanager/alertmanager &
配置文件说明:
- 全局配置
global:用于定义一些全局配置; - 模板
templates:告警时的通知模板(如果没有配置,将自动使用默认的模板) - 告警路由
route:通过标签匹配的方式,确定当前告警应当如何处理; - 接收人
receivers:配合告警路由使用,定义了接收人的通信方式; - 抑制规则
inhibit_rules:合理设置抑制规则可以减少垃圾告警的产生;
global:
[ resolve_timeout: <duration> | default = 5m ]
[ smtp_from: <tmpl_string> ]
[ smtp_smarthost: <string> ]
[ smtp_hello: <string> | default = "localhost" ]
[ smtp_auth_username: <string> ]
[ smtp_auth_password: <secret> ]
[ smtp_auth_identity: <string> ]
[ smtp_auth_secret: <secret> ]
[ smtp_require_tls: <bool> | default = true ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ]
[ wechat_api_secret: <secret> ]
[ wechat_api_corp_id: <string> ]
[ http_config: <http_config> ]
templates:
[ - <filepath> ... ]
route: <route>
receivers:
- <receiver> ...
inhibit_rules:
[ - <inhibit_rule> ... ]
二、配置邮件告警
1)修改 AlertManager 配置文件
[root@k8s-master01 ~]# cat <<END > /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 3m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'ChenZhuang1217@163.com'
smtp_auth_username: 'ChenZhuang1217@163.com'
smtp_auth_password: '邮件授权码'
smtp_hello: '163.com'
smtp_require_tls: false
route:
group_by: ['env','instance','type','group','job','alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: default
routes:
- receiver: email
group_wait: 10s
match:
severity: Error
receivers:
- name: 'default'
email_configs:
- to: '2085077346@qq.com'
send_resolved: true
- name: 'email'
email_configs:
- to: 'ChenZhuang1217@163.com'
send_resolved: true
END
配置说明:
resolve_timeout:在定义的时间内,若没有继续产生告警,才会发送恢复消息;smtp_require_tls:是否使用 TLS 协议;group_by:将具有相同属性的告警进行分组聚合;group_wait:发送告警前的等待时间;group_interval:发送告警的时间间隔;repeat_interval:分组内 发送相同告警的时间间隔;receiver:指定的接收器(和receivers配置里的名字匹配)routes:子路由,通过 匹配告警规则中的标签,来发送到指定的接收人;send_resolved:是否通知已经解决的告警;
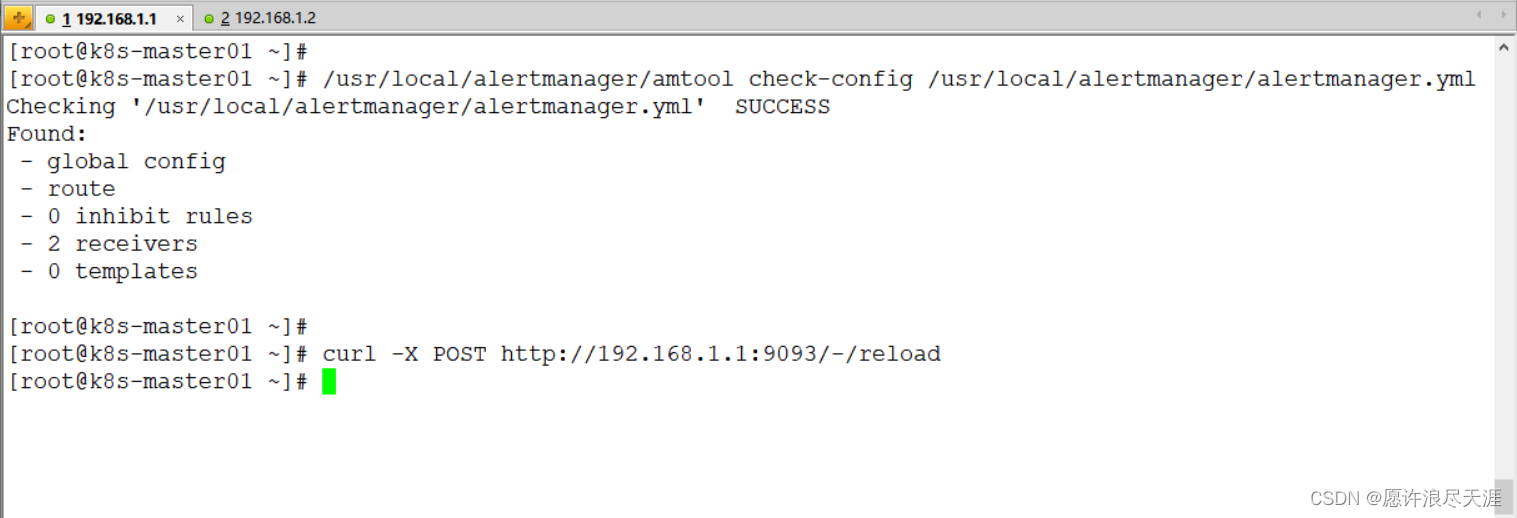
[root@k8s-master01 ~]# /usr/local/alertmanager/amtool check-config alertmanager.yml # 检查配置
[root@k8s-master01 ~]# curl -X POST http://192.168.1.1:9093/-/reload # 加载配置文件
2)修改 Prometheus 配置文件
[root@k8s-master01 ~]# cat <<END > /usr/local/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.1:9093"]
rule_files:
- "/usr/local/prometheus/rules.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "Linux"
static_configs:
- targets: ["192.168.1.1:9100"]
END
3)编写告警规则
alert:告警名称;expr:PromQL 查询语句,查询是否满足告警条件;for:评估等待时间,当条件成立一段时间后,才会发送告警(在此期间处于告警处于 Pending 状态)labels:自定义标签,用户可以通过该标签进行路由匹配、告警展示等功能;annotations:附加信息,只能用于告警展示;
[root@k8s-master01 ~]# cat <<"END" > /usr/local/prometheus/rules.yml
groups:
- name: 主机监控
rules:
- alert: TargetDown
expr: up{job="Linux"} == 0
for: 15s
labels:
severity: Error
annotations:
summary: "{{ $labels.job }} 主机已经超过 15s 未响应"
description: "{{ $labels.instance }} 主机宕机"
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: Warning
annotations:
Summary: "Instance {{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用率过高"
Description: "{{ $labels.instance }}: {{ $labels.mountpotint }} 分组使用大于 80% (当前值: {{ $value }})"
END
- 上面定义的那些告警规则,其实都是通过 PromQL 语句在 Prometheus 里查询出来的结果。
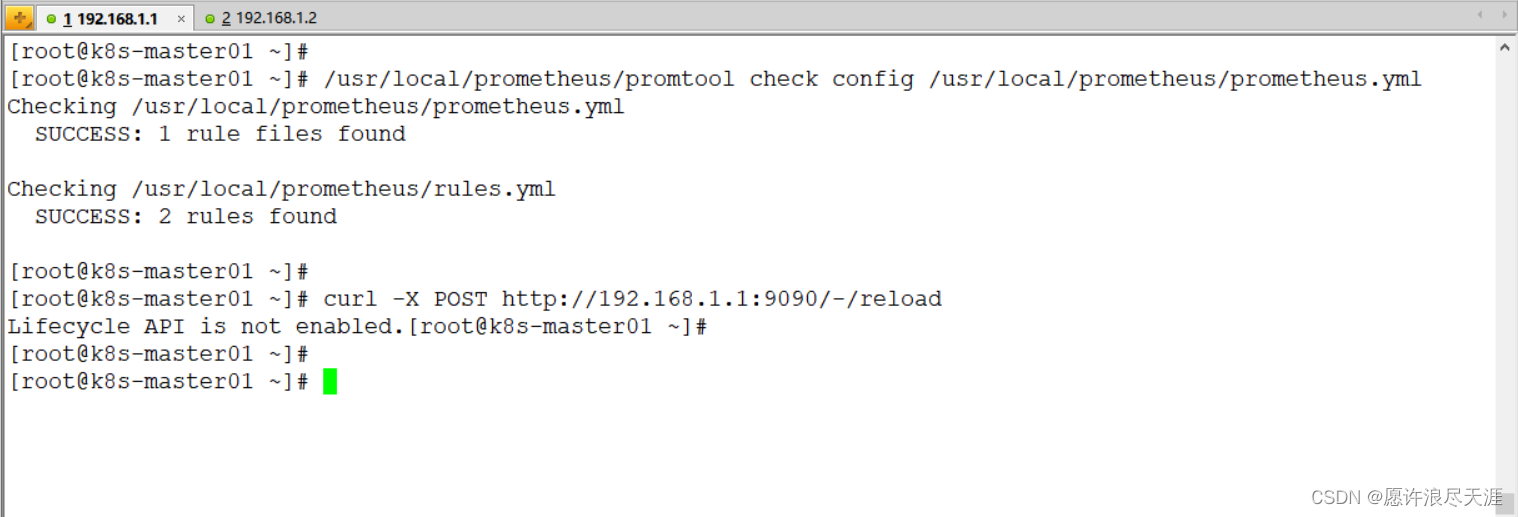
[root@k8s-master01 ~]# /usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml
[root@k8s-master01 ~]# curl -X POST http://192.168.1.1:9090/-/reload
验证:
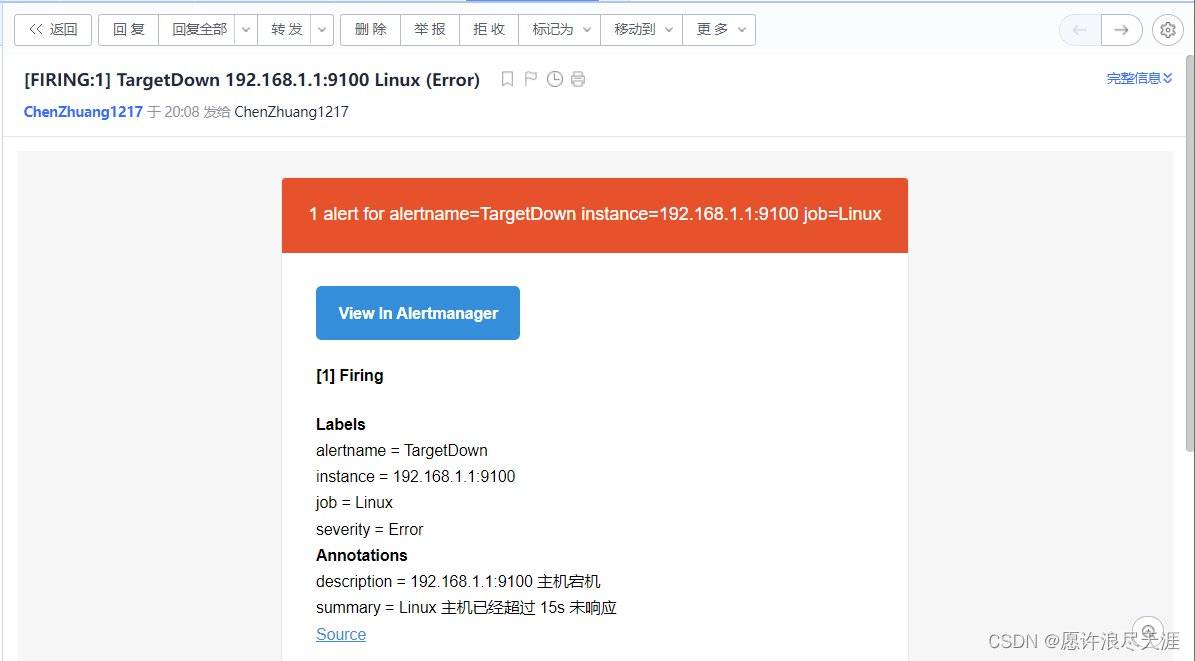
1)验证时,我们只需要将 node_exporter 关闭即可。
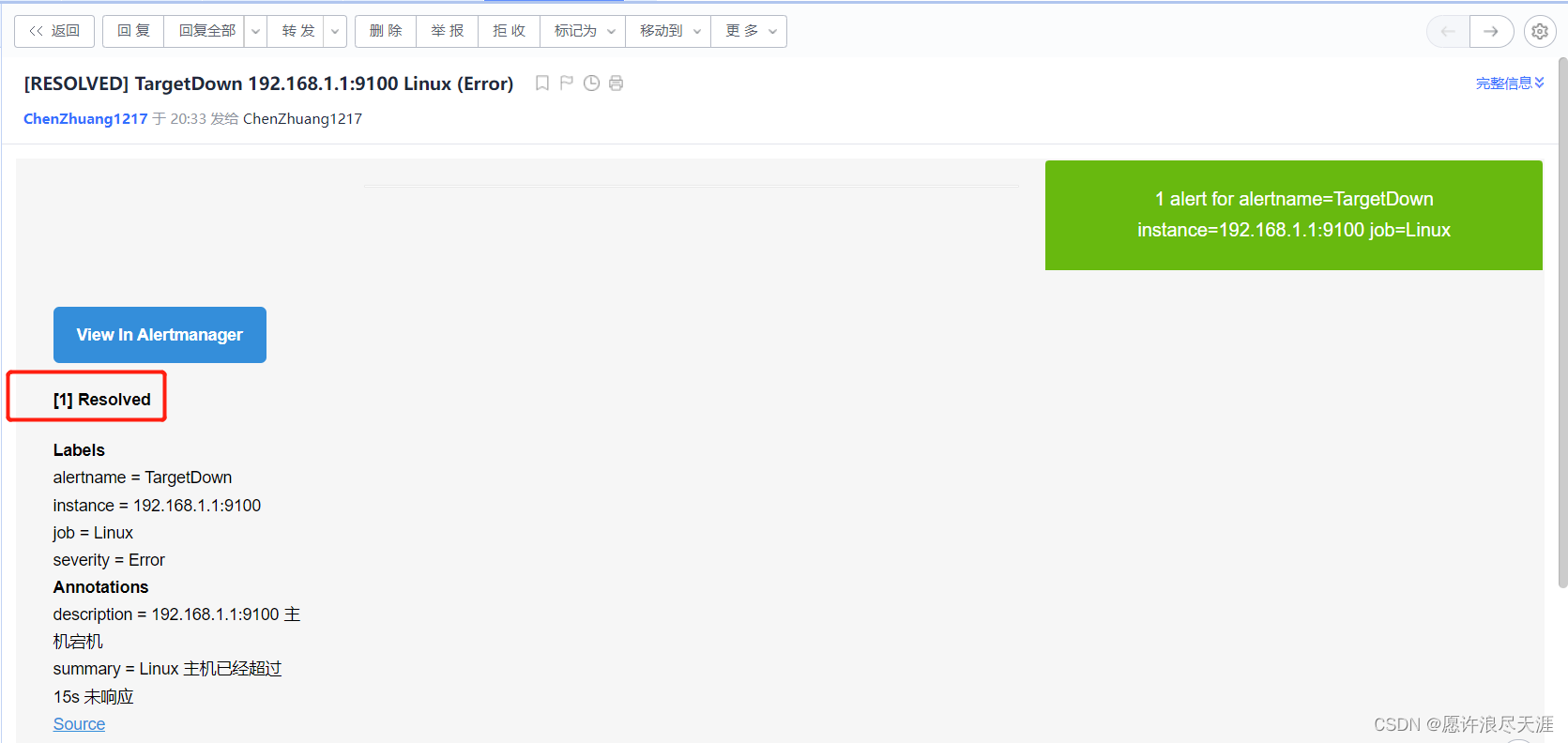
2)再重新打开 node_exporter
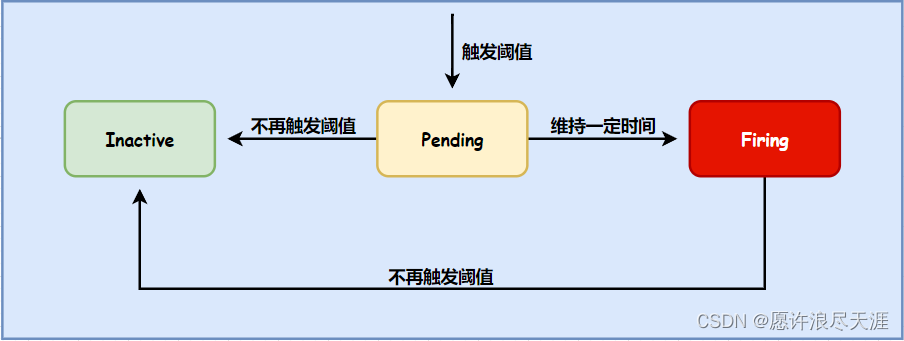
Prometheus Alerts 三种状态:
Inactive:正常状态,表示还未产生告警。Pending:等待状态。Firing:告警状态,通过 AlertManager 配置文件中定义的信息,发送给指定的接收者。
三、配置企业微信告警
1)注册企业微信:地址
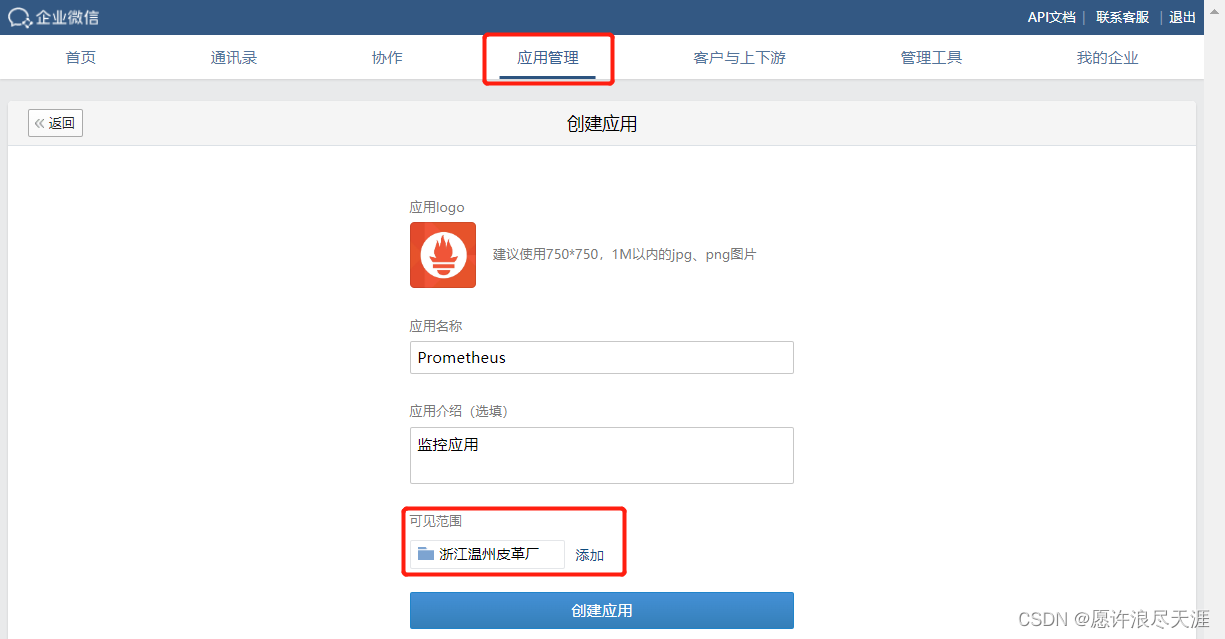
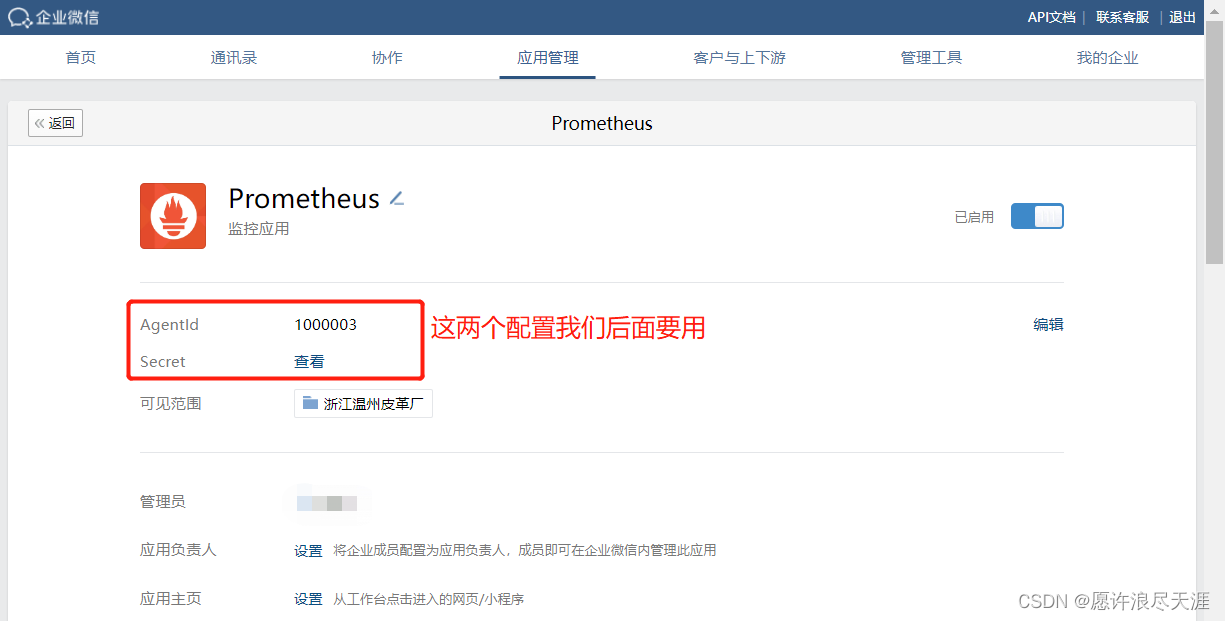
2)创建应用
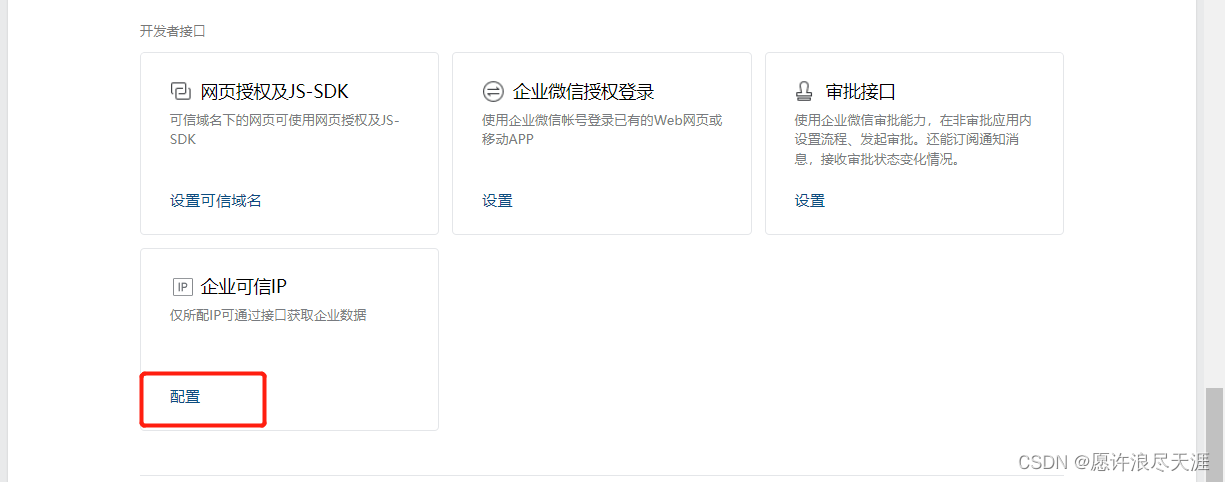
3)配置可信 IP(如果不配置可信 IP 的话,将导致无法发送告警消息)
[root@k8s-master01 ~]# curl httpbin.org/ip # 获取当前主机的公网 IP
4)查看企业ID

1)修改 AlertManager 配置文件
[root@k8s-master01 ~]# cat <<END > /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 3m
wechat_api_url: "https://qyapi.weixin.qq.com/cgi-bin/"
wechat_api_secret: "Secret"
wechat_api_corp_id: "企业微信ID"
templates:
- '/usr/local/alertmanager/wechat.tmpl'
route:
group_by: ['env','instance','type','group','job','alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: wechat
receivers:
- name: 'wechat'
wechat_configs:
- agent_id: "AgentId"
to_party: "部门ID"
message: '{{ template "wechat.default.message" . }}'
send_resolved: true
END
- 因为上面我们在配置邮件告警的时候,已经将告警规则配置上了,所以下面我们直接配置告警模板即可。
2)配置告警模板
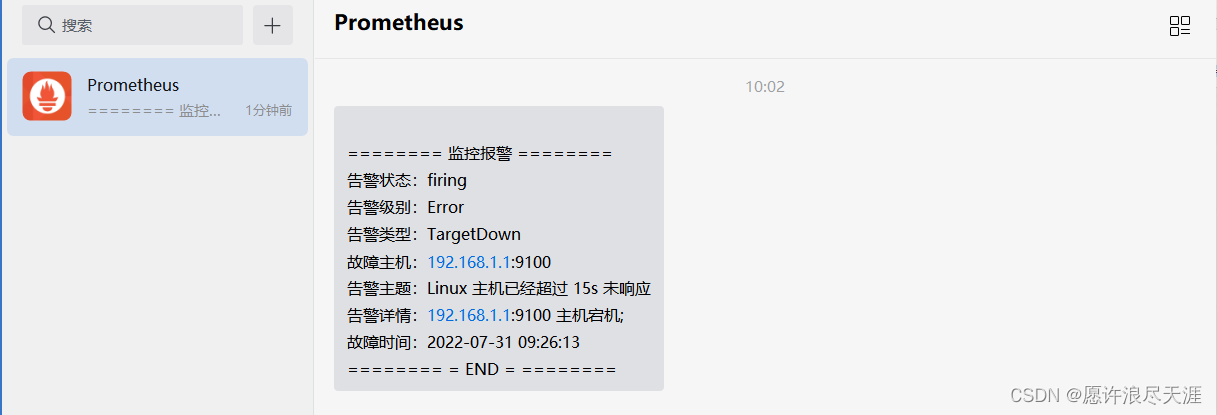
[root@k8s-master01 ~]# cat <<"END" > /usr/local/alertmanager/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
======== 监控报警 ========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ .Labels.alertname }}
故障主机:{{ .Labels.instance }}
告警主题:{{ .Annotations.summary }}
告警详情:{{ .Annotations.description }};
故障时间:{{ .StartsAt.Format "2006-01-02 15:04:05" }}
======== = END = ========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
======== 异常恢复 ========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题:{{ .Annotations.summary }}
告警详情:{{ .Annotations.description }};
故障时间:{{ .StartsAt.Format "2006-01-02 15:04:05" }}
恢复时间:{{ .EndsAt.Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息:{{ $alert.Labels.instance }}
{{- end }}
======== = END = ========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
END
- 如果告警时间显示的是 UTC 时区,可以将其配置为
{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
3)验证
[root@k8s-master01 ~]# curl -X POST http://192.168.1.1:9093/-/reload
重新打开 node_exporter

















 6233
6233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











