










哈工大操作系统公开课
操作系统需要有计算机组成原理基础和汇编语言基础
如果是开发的小伙伴想快速补课,可以看这个文章,写的很好
从系统启动到多进程
学习任务
操作系统的概念
什么是操作系统
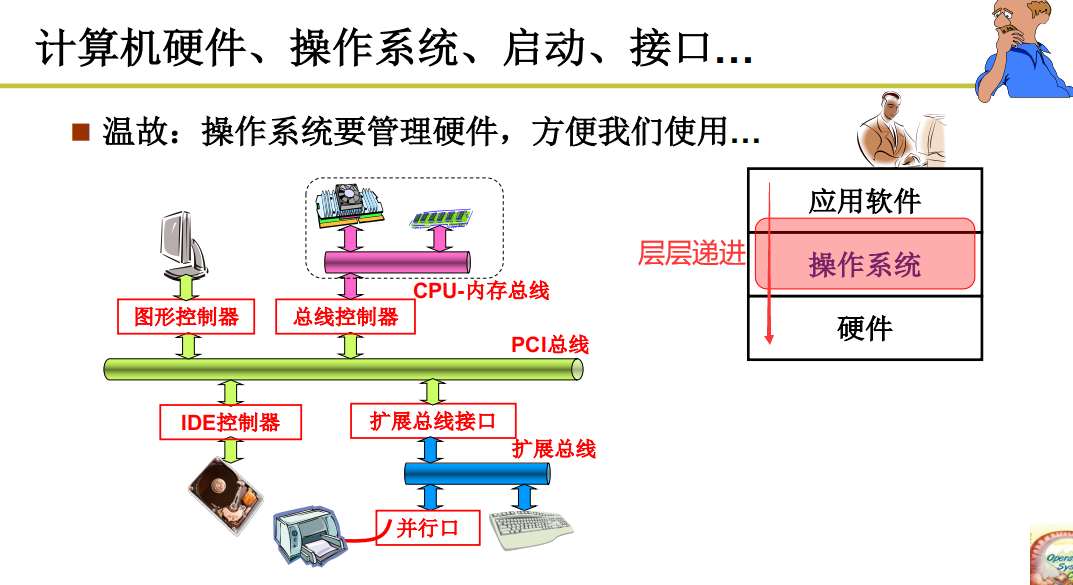
操作系统时硬件和应用直接的一层软件
方便我们使用硬件,比如使用显存
高效的使用硬件,比如开多个端口(窗口)
操作系统管理哪些硬件呢?

这里我们学习不管是学习如何调用操作系统的API,更多的是去学习API在运行的时候背后发生的原理以及一些背后的流程。这个课学完,最少可以做到改动,扩充操作系统。

从启动开始看操作系统

计算机架构进化史
图灵机
从基础的图灵机看起,图灵机只能做最基础的工作,只能做这种加和的单一运算模式
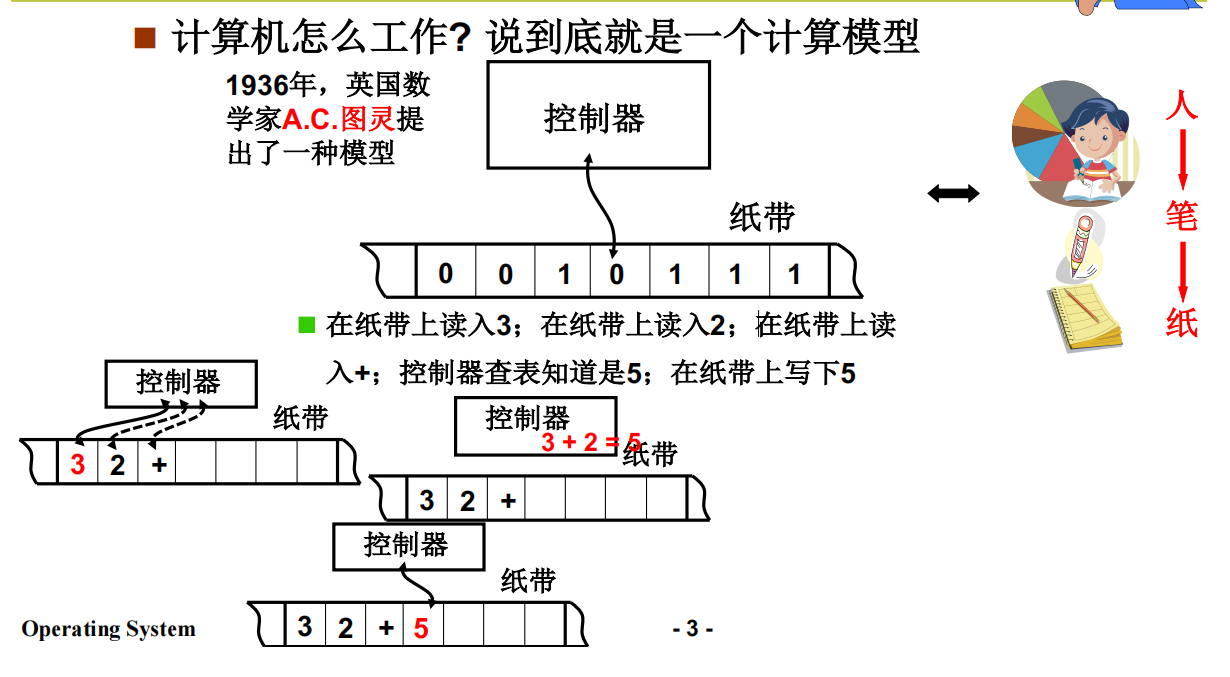
图灵通用机
从图灵机进化到图灵通用机,把图灵机的操作步骤抽离出来,只负责运算
为什么叫通用?读取到什么指令就做什么指令的动作。
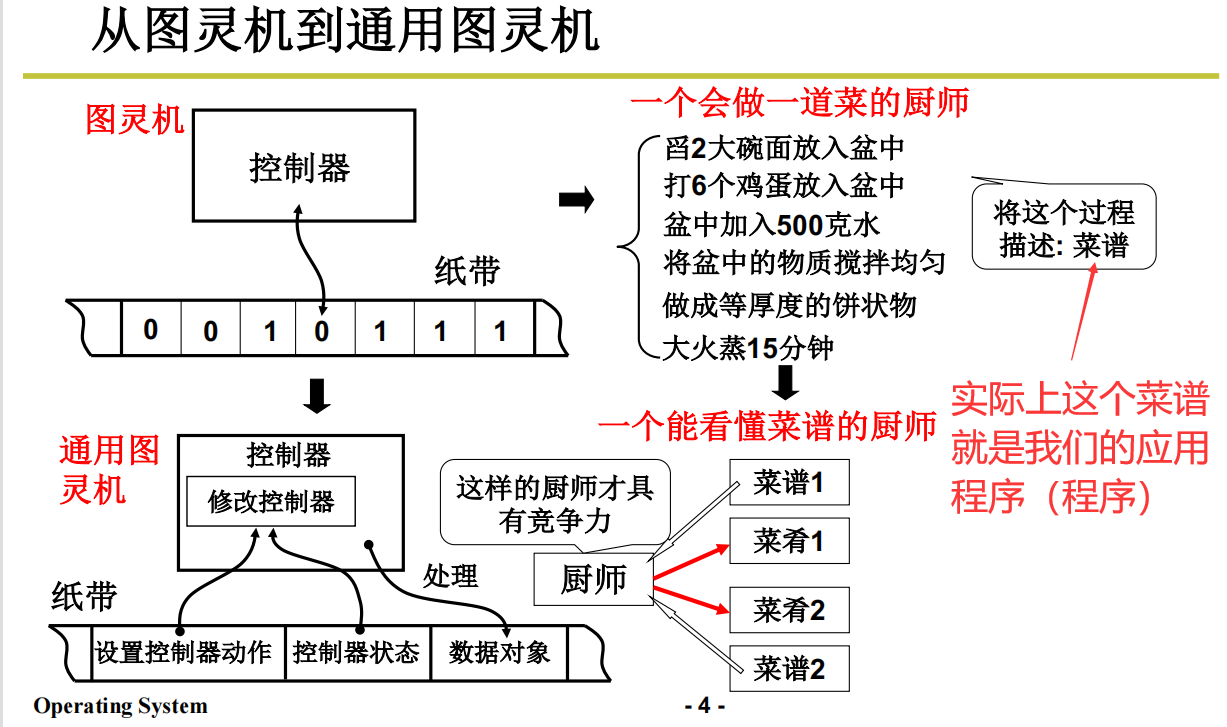
冯诺依曼把这个思想进行进一步的抽离,得出了冯诺依曼架构
冯诺依曼架构
取出指针指到的地址,送入控制器执行
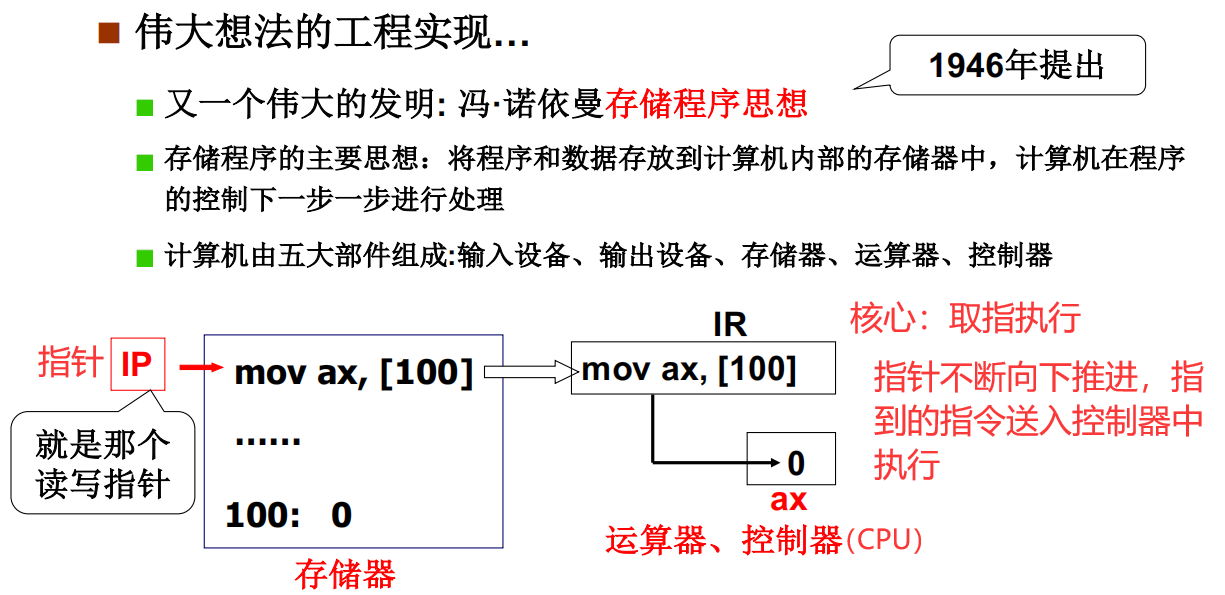
引导操作系统启动的第一条指令
回到最开始的问题,系统电源启动的第一条命令是运行的什么?
答案就是 PC(指针)=某某内存中的地址
开机引导过程
- CS: code segment 代码段寄存器
- IP: instruction point 指令指针寄存器
因为在计算的时候,是CS:IP CS与IP要做加和处理。这个时候就是CS先左移四位给IP让出空间,再与IP做加和处理,那么这个时候运算结果就是0xFFFF0,也就是BIOS的默认地址
得到的就是BIOS ROM的存储位置

BIOS
全称叫做(ROM BIOS映射区)
BIOS:Basic Input Output System
对于PC机来说,有一部分引导指令是固化的。也就是我们主板上熟知的BIOS模块。因为刚一上电,内存里面肯定是全空的,需要有一部分固定的内容做整个系统的引导操作,这个固化的代码去哪找?去CS:IP的地址也就是BIOS的的0xFFFF0进行寻址,找到这段固定的代码进行加载。

引导扇区
每个扇区是512个字节
0磁道0扇区就是操作系统的引导扇区,把引导扇区中的东西读取到内存(0x7c00)中,等待下一步的处理。

0x7c00处存放的代码
之前说到把引导扇区的代码读取到0x7c00的内存中,这里放着引导

汇编语言(assembly language)
bootsect.s 意为:引导扇区(汇编代码)

也就是说:操作系统从上电开始,要从磁盘的引导扇区把汇编代码载入到内存(不载入内存是不能取指执行的)。载入之后就可以被CPU从内存取指执行了
这段引导程序载入内存的程序,就叫bootsect.s
bootsect.s之后就是setup.s setup将完成OS启动前的设置
总结一下:
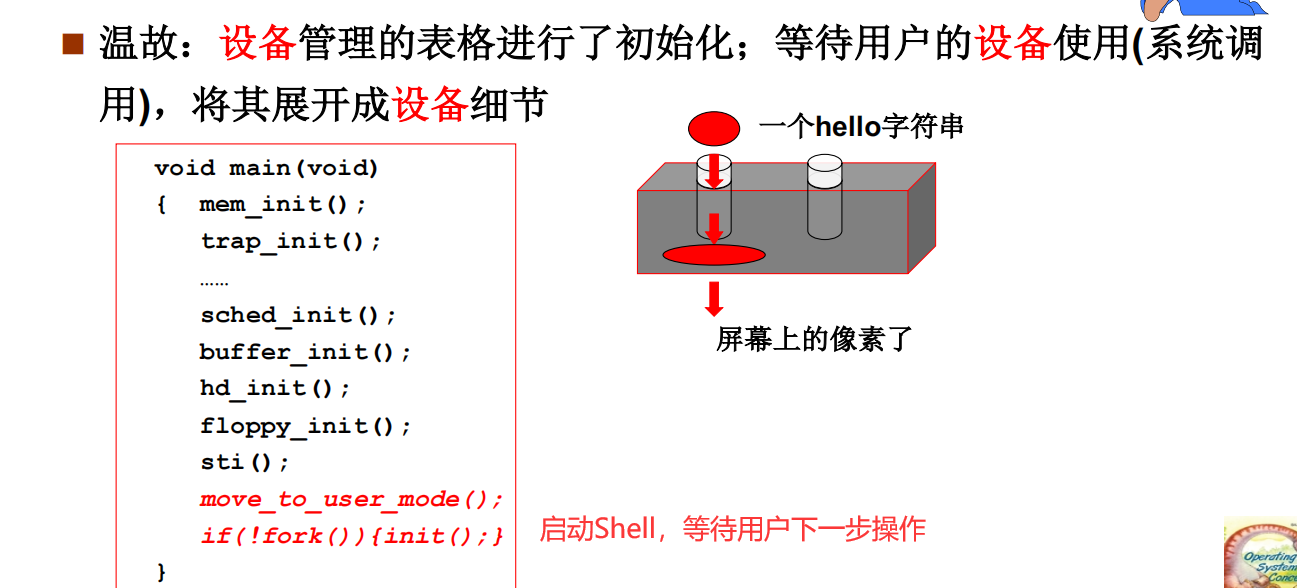
1.系统启动之后,pc指针首先指向BIOS区,检测RAM,键盘,显示器,软硬磁盘是否正常运作,之后会把磁盘0磁道0扇区的256字节的引导启动代码放到内存0x7c00处,PC指该内存地址处开始运行。
该引导代码用汇编而不是用C语言,因为C语言的代码编译之后,它的内存位置是人为不可控的(比如自动分配栈),而汇编可以。
引导启动代码的第一步是:
(1)把256字节的代码从0x7c00处移动到0x9000处。然后从0x9000处开始运行。
(2)运行一开始读磁盘0磁道0扇区后面的4个setup扇区,把这4个扇区读到0x90200地址处。
(3)接下来的代码不读磁盘了,而是用13号中断在屏幕上显示加载系统的图片和文字。
(4)最后再把磁盘前5个扇区之后的内容读到内存
(5)程序跳到setup程序的地址去执行
(6)setup程序首先通过15号中断获得内存的大小等硬件参数。然后把从0x9000处所有的操作系统代码移到0地址处。(在物理内存中,操作系统就存放在低地址中)
(7)set up的最后代码是一条高级指令,它会把cr寄存器的最后一位置1,这样寻址方式从以前的模式转变为保护模式,寻址不再是cs左移4位加上ip地址,而是cs寄存器指向gdt表,找到基地址,然后加上ip寄存器的偏移地址来寻址,这样可以查找更大的空间,以前是寻址空间2的16次方,现在是2的32次方。
(8)接下来跳到system模块去执行,也就是前5个扇区之后的代码处去执行。
注意,磁盘上的程序一次是boot–setup–system程序,最终转变到内存中也要是这样的顺序,boot将setup的程序拿到内存,setup将system的程序拿到内存。system程序的开始一定是是head.s文件
(9)head.s文件会初始化idt和gdt表,这两个表格是寻址用的,以方便保护模式下使用,该模式下很多汇编指令改变,比如mov des sor 变成
mov sor des,32位汇编代码和16位汇编代码不同。整个启动过程用了16位汇编,32位汇编,内嵌汇编三种。
(10)最后跳到main()函数去执行,在main函数里面进行各个模块的初始化工作。前面第6部获得的物理内存大小参数就可以传到一些初始化函数中进行使用。
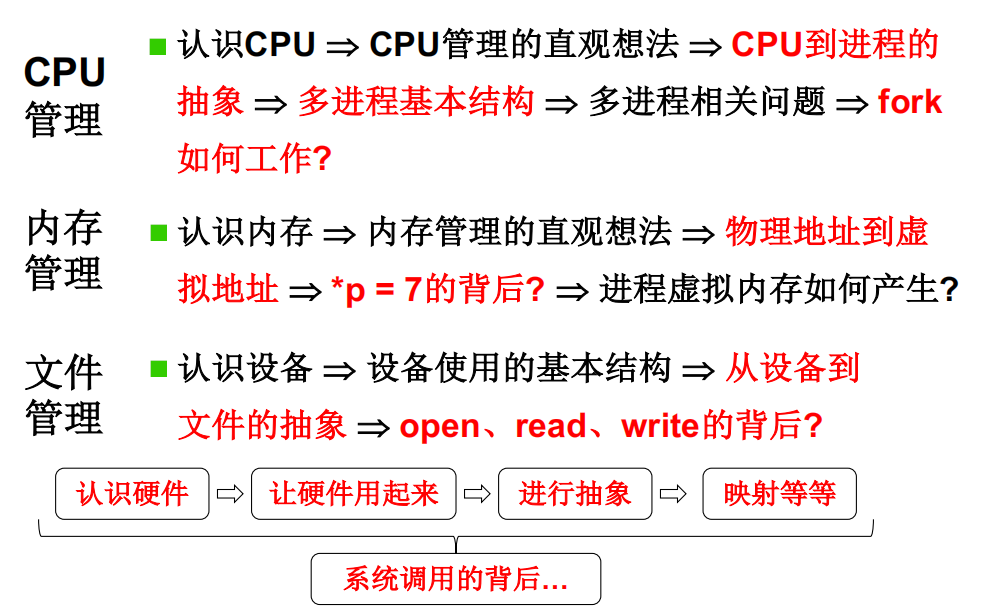
操作系统的接口
何为接口
interface,屏蔽细节,会使用接口就行,由接口来提供直接的功能。本质上就是一些函数,上层的应用来调用操作系统提供的一些函数,进行下一步的操作
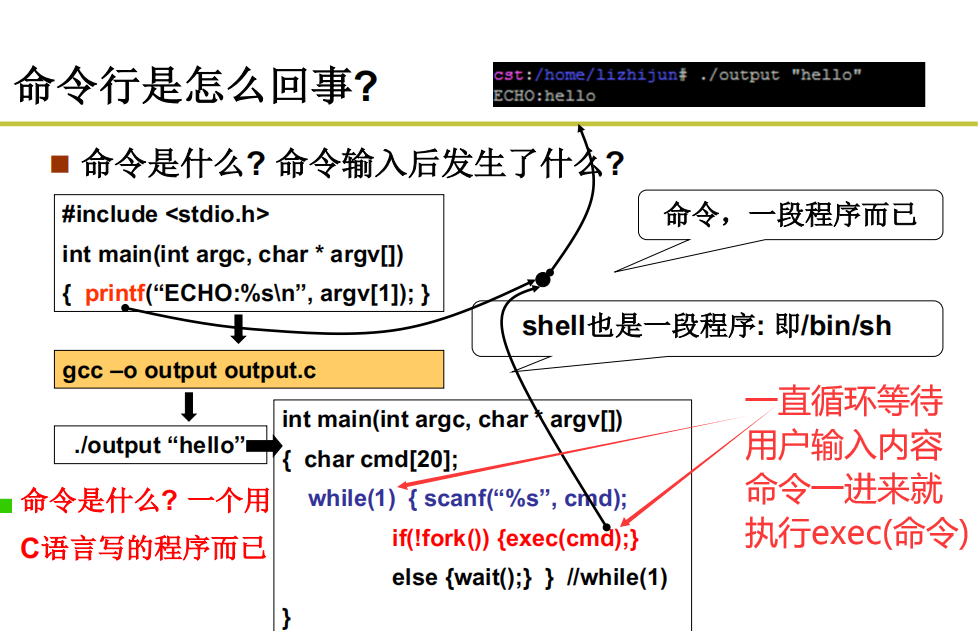
命令行
实际上本质也是操作一段代码让其执行,操作系统加载完毕后,一直在等shell命令输入,while(1){执行内容}
图形按钮
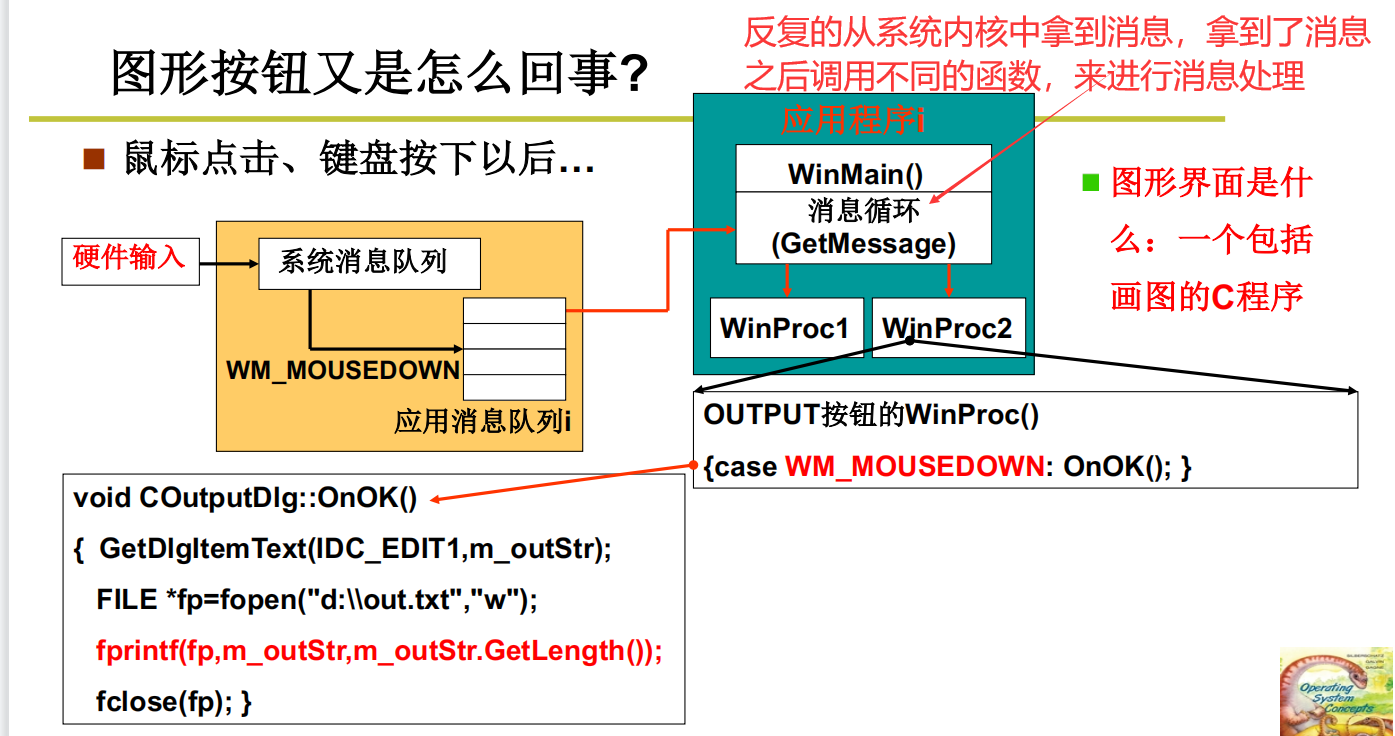
总结:何为操作系统
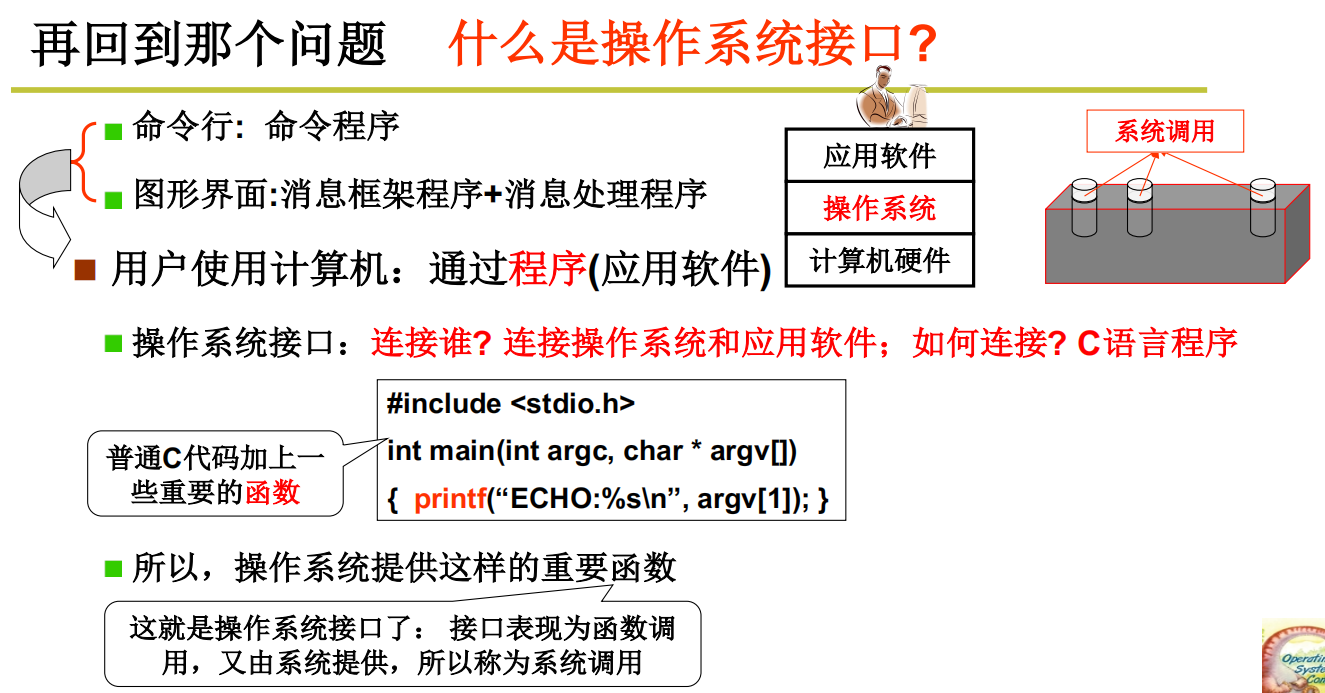
总结下来:接口的函数调用,也成为系统调用
操作系统有哪些接口

系统调用的实现
先说结论:系统调用的实现是通过调用中断实现的
实现一个系统调用
从一个简单的问题开始,实现一个叫(whoami)的系统调用。
我们知道,正常的操作系统接口无非就是函数,那我直接在用户的应用程序里面调用操作系统的接口不就好了,当然,这是不行的。
所以,上层的应用系统不可以去操作内存
系统调用实际上就是提供了一种能够进入系统内核的手段

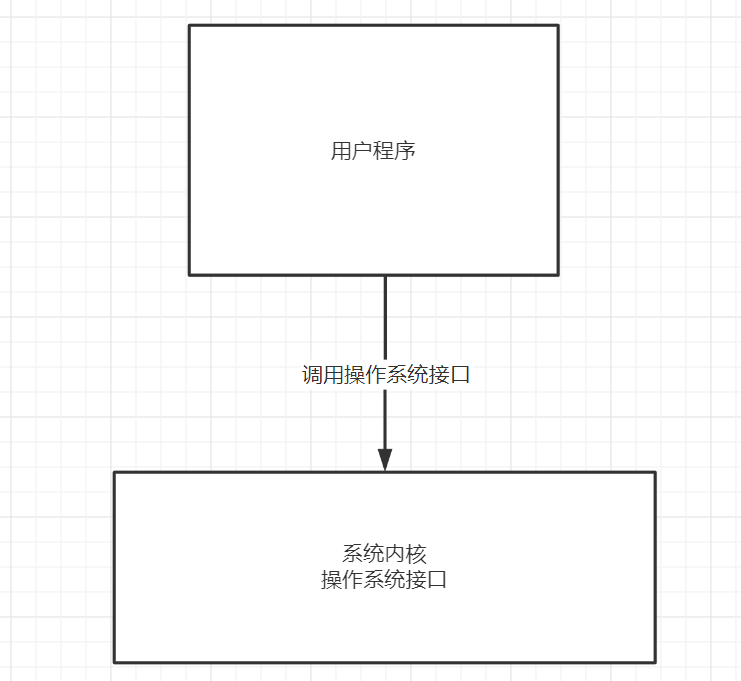
以Word写入操作为例
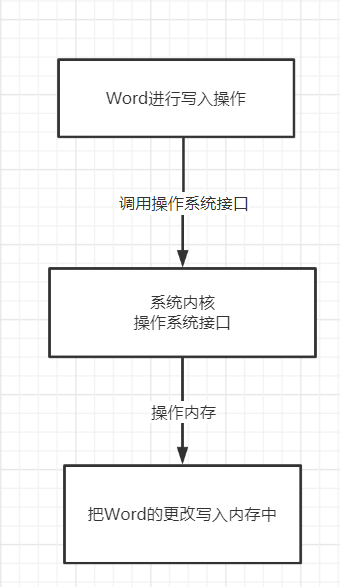
内核(用户)态,内核(用户)段
这种不允许直接操作内存是怎么做到的?
软件肯定做不到这种行为,因为软件终究会有Bug,这种在硬件级别的隔离
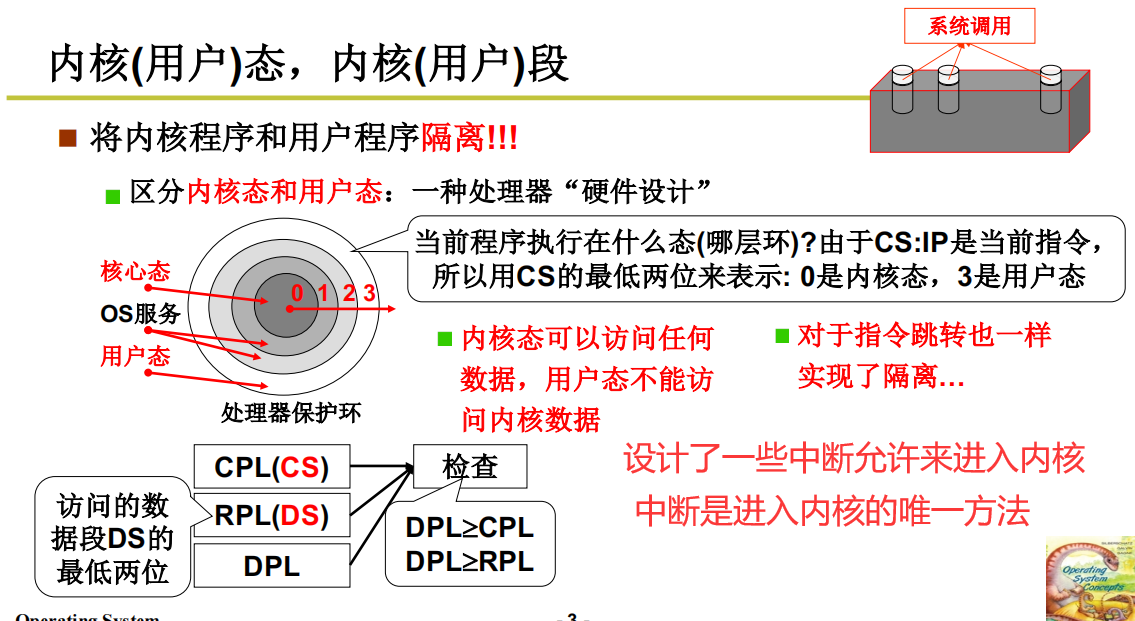
对于Intel x86,那就是中断指令int
int指令将使CS中的CPL改成0,“进入内核” 这是用户程序发起的调用内核代码的唯一方式。
系统调用的核心:
- (1) 用户程序中包含一段包含int指令的代码
- (2) 操作系统写中断处理,获取想调程序的编号
- (3) 操作系统根据编号执行相应代码
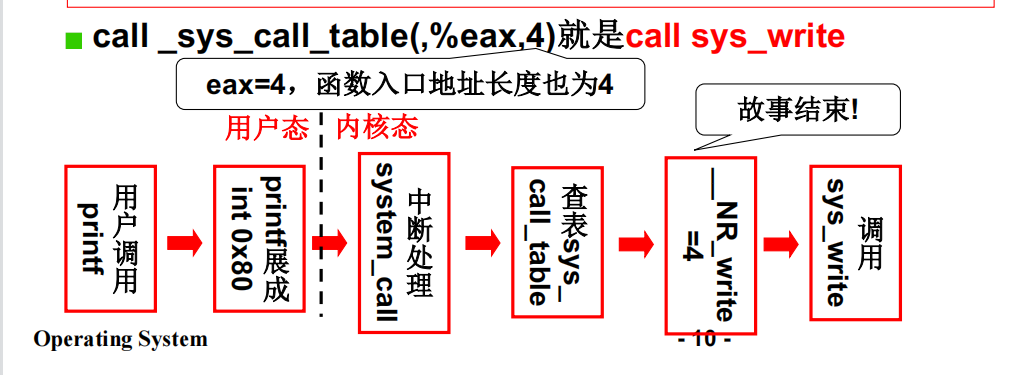
都是从int 0x80进入的操作系统

int 0x80是什么

中断处理程序: system_call

流程
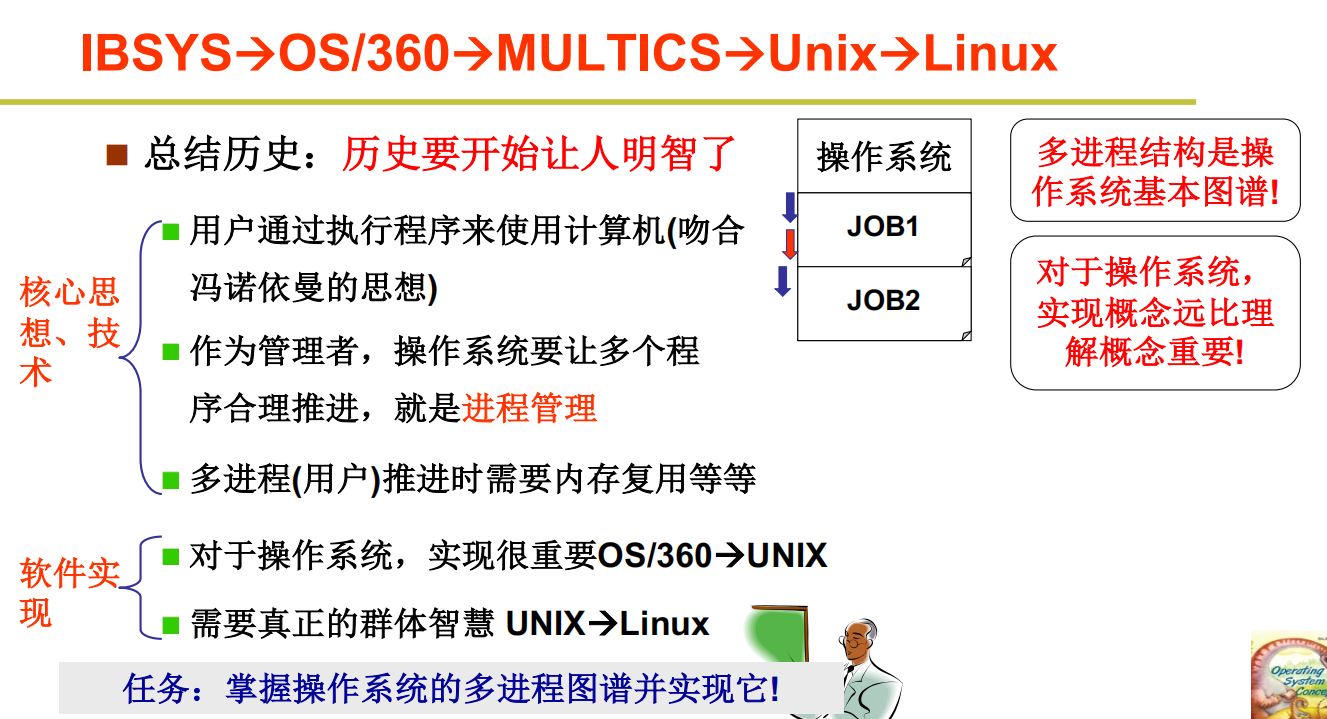
操作系统的历史
直接看这个操作系统发展史

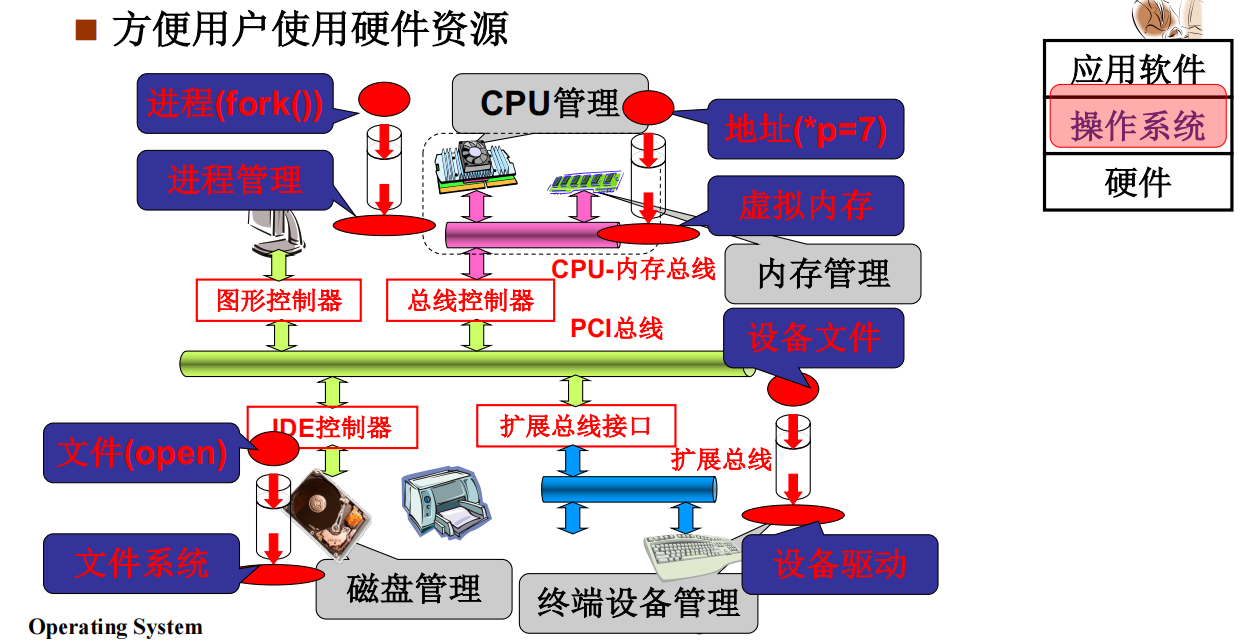
CPU管理
操作系统中CPU是最核心的硬件存在
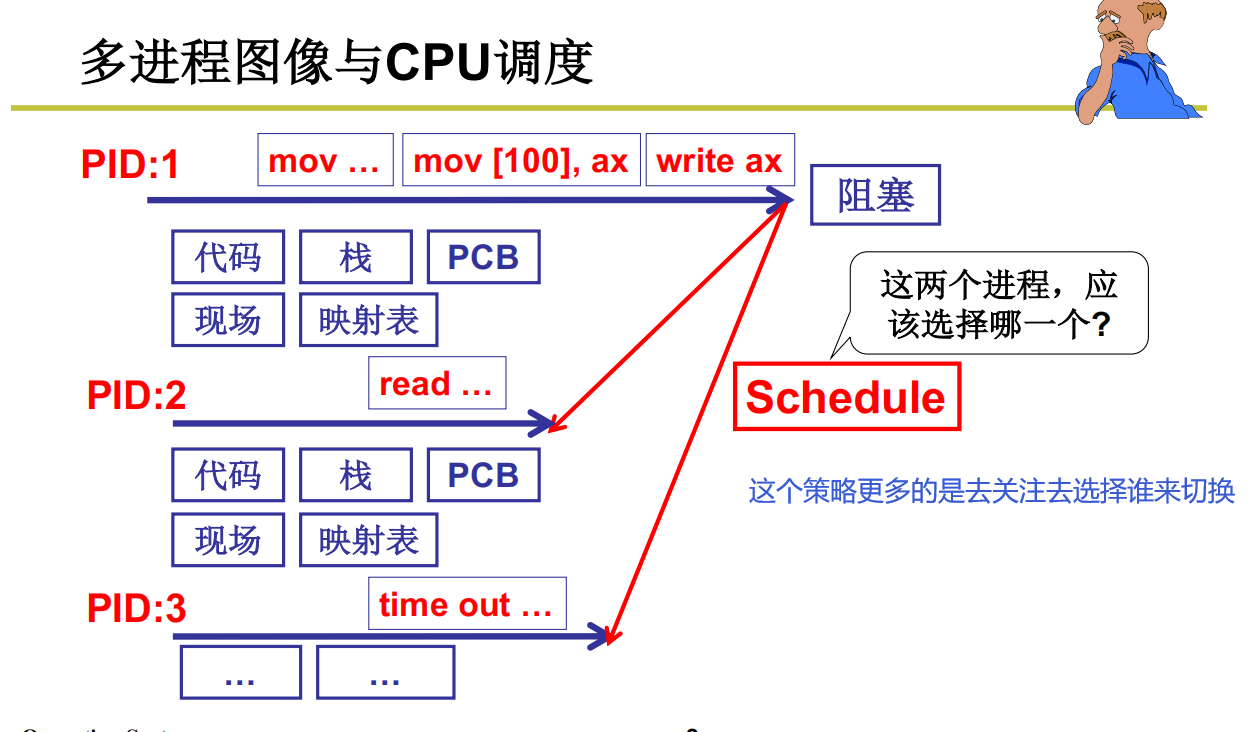
操作系统在管理CPU的时候引出了多进程图像,操作系统把CPU管理好了,就可以管理好其他的硬件。
使用CPU
在学会管理CPU之前,更重要的是学会去使用CPU
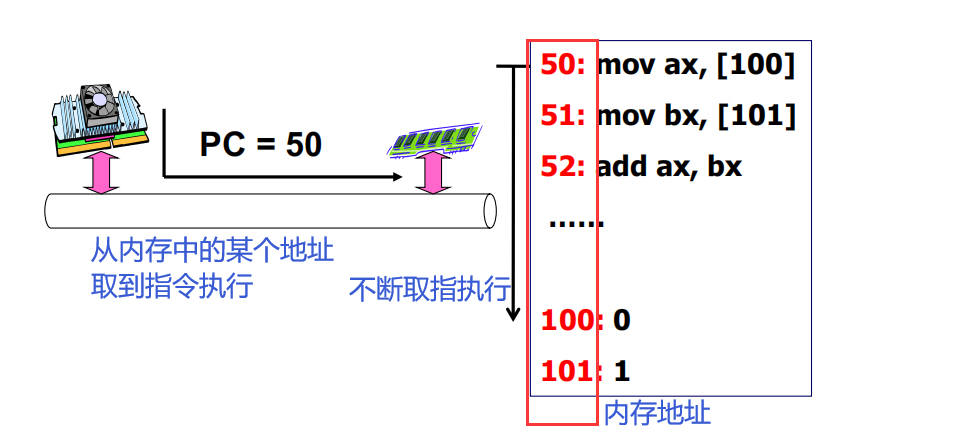
CPU工作原理
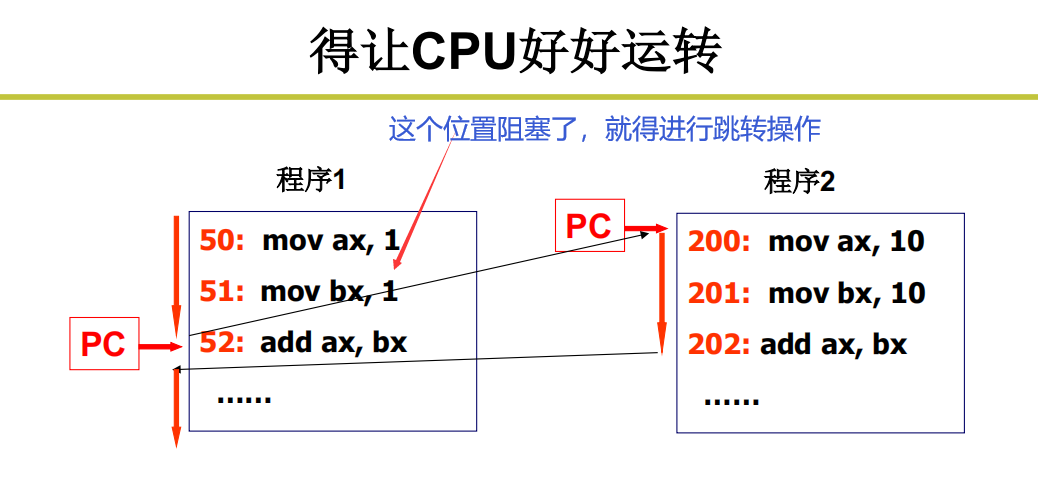
上电以后,把程序存放在内存中,设置一个PC地址,CPU根据这个PC的地址发出一条取出指令的命令,指令从总线传回CPU,CPU对指令进行解释执行。不断的取指执行(看一个菜谱干一个活,不断的给地址就取指执行),只需要给第一个地址就行,剩下的地址由PC自动叠加运行。
CPU的一些问题
CPU内执行要比IO执行快很多很多倍,所以就会导致一种现象,CPU干个活0.01s就处理好了,等IO操作要等10s,整个流程要10.01s,这样CPU的利用率就非常低,10s只有0.1s在干活。那这个现象怎么解决呢
解决方案
在IO的过程中,切出去让CPU干别的是不是利用率就上来了?
所以当被IO阻塞执行不下去的时候,切出去执行别的就可以了。
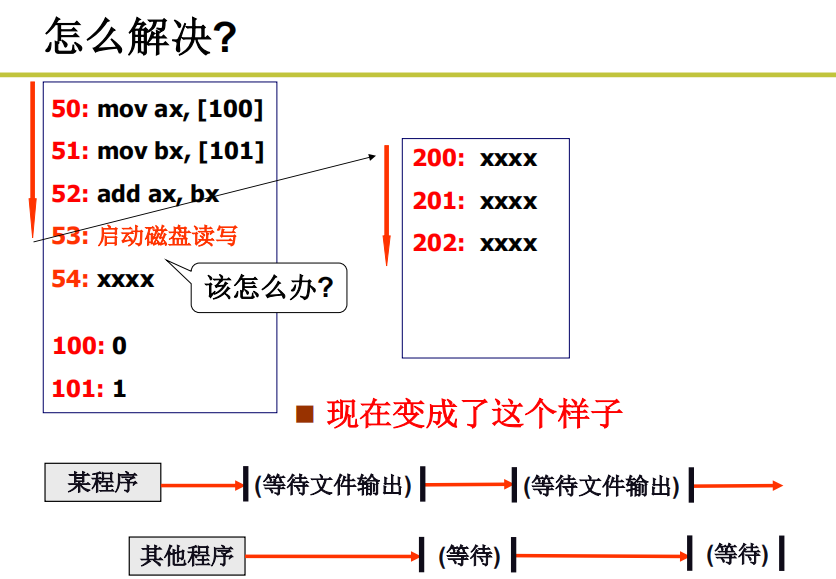
这种思想下,就出现了多个程序在内存中来回切来切去,多个程序交替执行。就会让CPU忙碌起来。
让总体的处理时间大幅度压缩
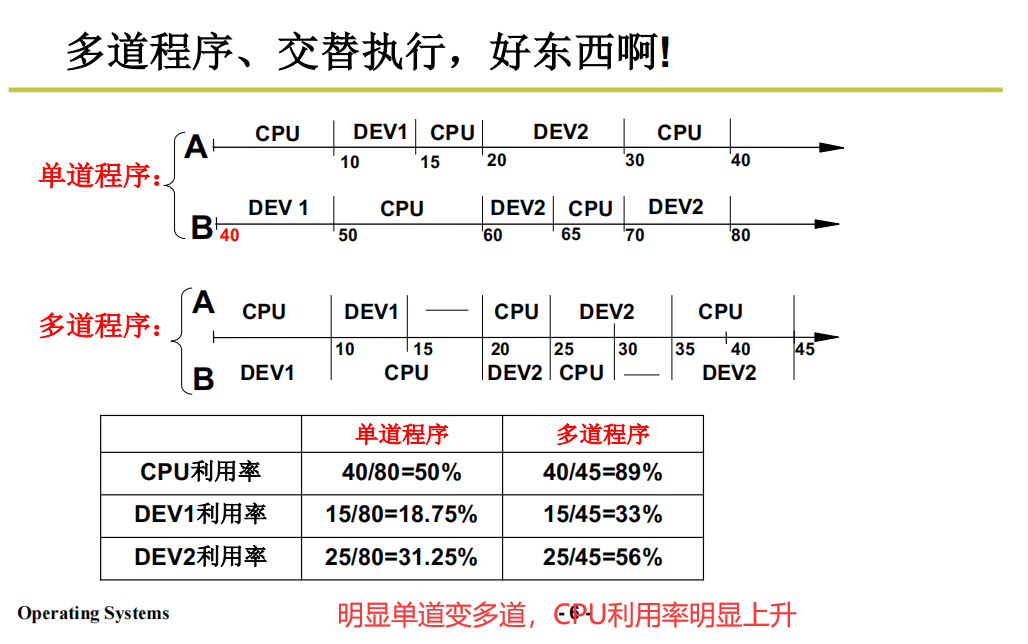
并发
两个及两个以上的作业在同一 时间段 内执行。
控制好CPU切换任务的时机,在他被阻塞时就切换出去执行其他的任务。
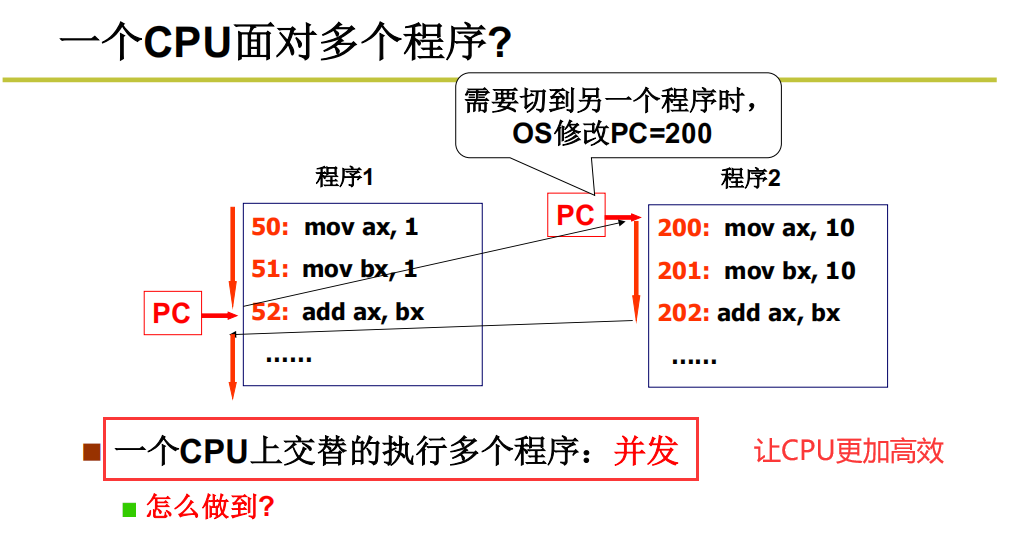
为了完成这种切来切去的操作,就需要记录当前执行的程序执行出来的样子。
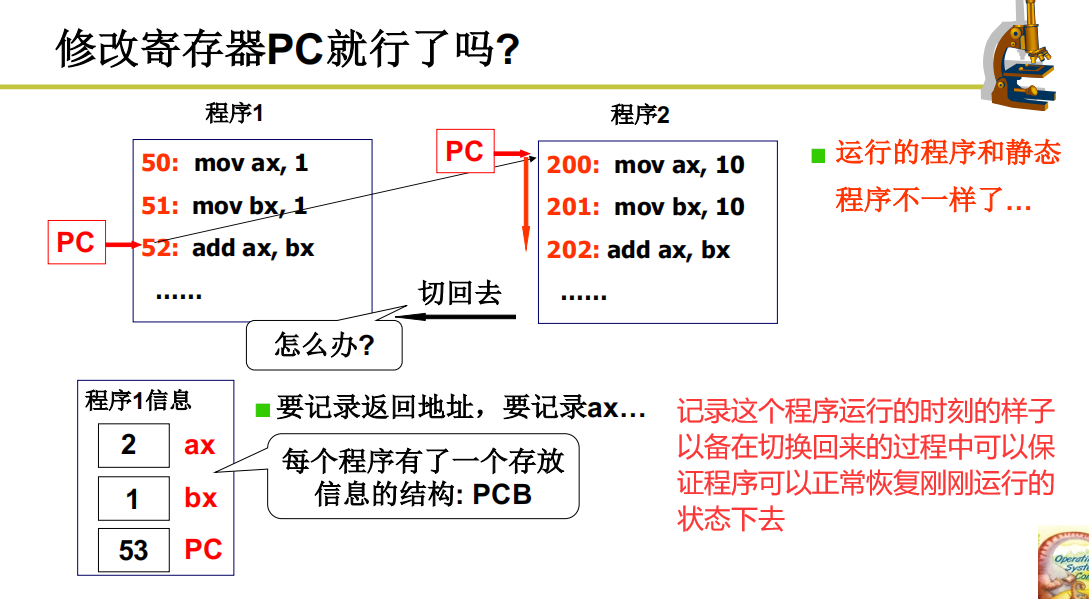
多个程序运行的使用就需要记录多个程序运行的样子,再来回切换的时候保证其正常运行。相比于静态的程序,运行中的程序更像是程序+一些不一样的数据,也就引出了进程的概念,来区别于静态的程序(静态的代码块)
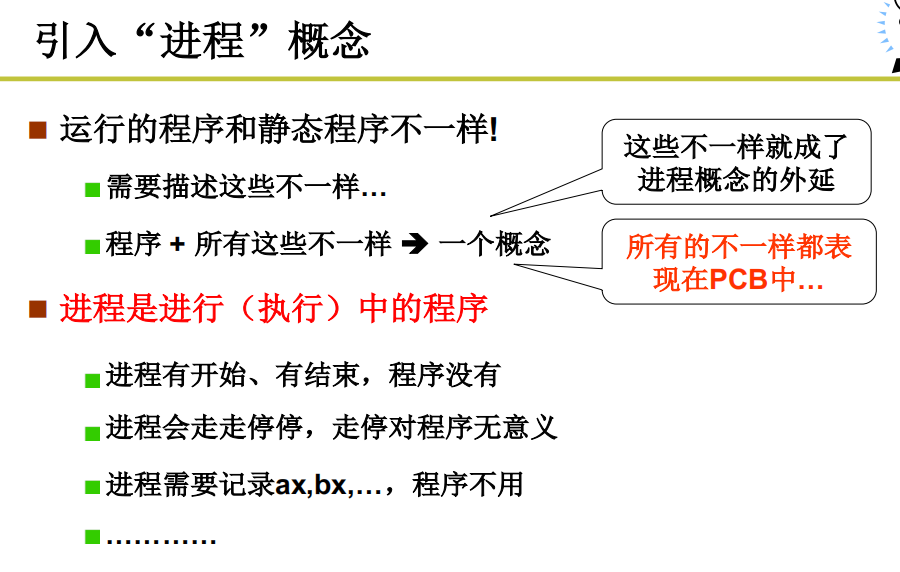
如何更好的管理的CPU
操作系统为了提高CPU的利用率,操作系统在CPU中把多个任务交替执行,在切来切去的过程中记录下来的一些东西,就引出了进程的概念。让CPU更好的被管理就是多个任务同时进行,多个进程向前跑的样子就是操作系统的管理CPU的样子。
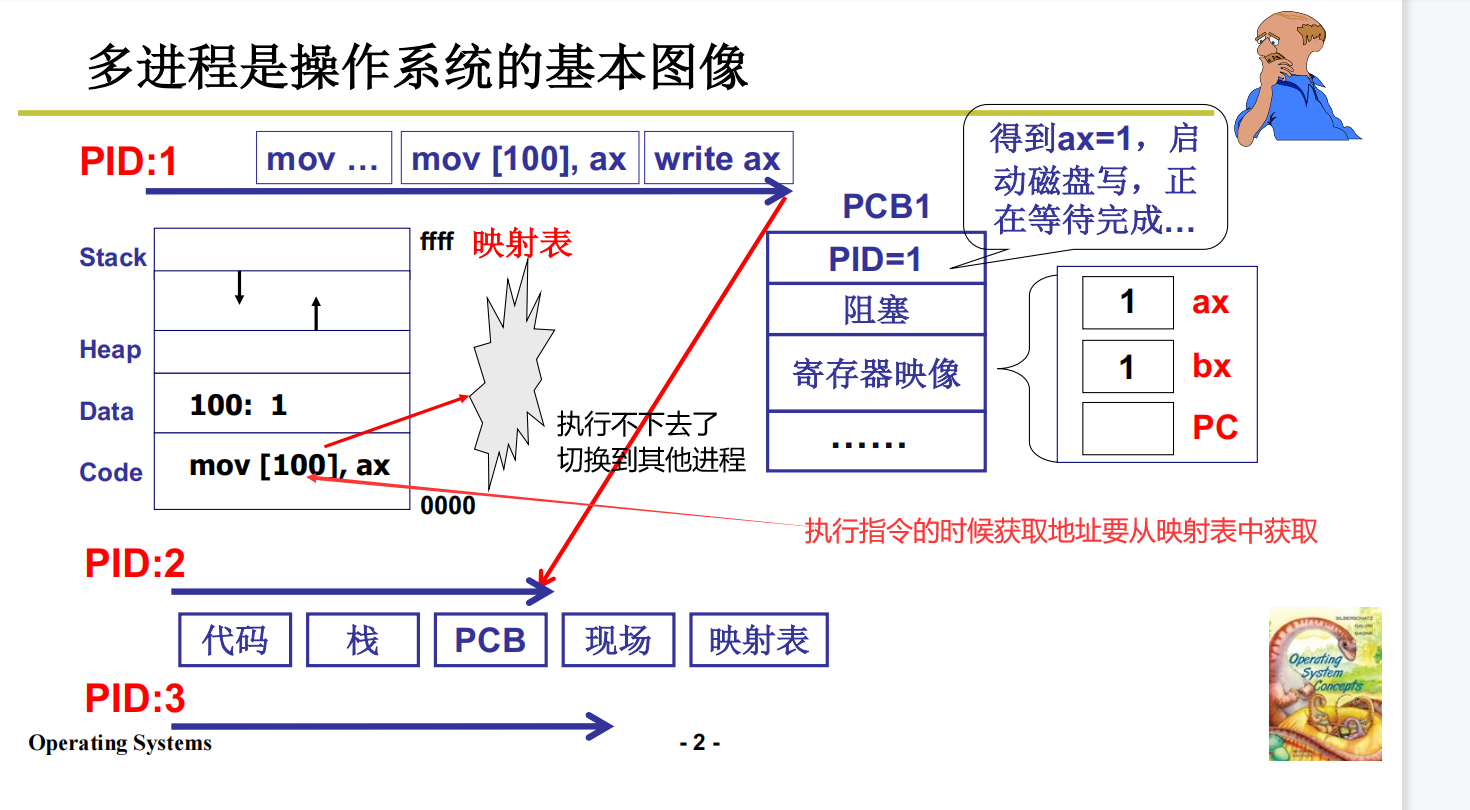
进程
操作系统为了支持多进程的处理作出了哪些努力?
在用户的眼里,只有很多的进程,还有多进程的推进的样子。不会去关注一些其他的东西。

多进程整体过程
main在初始化的时候fork(创建进程)了一个进程,fork的这个进程有init函数,init执行了shell(或者windows图形化界面),shell等待用户输入各种指令。
当你不想用这个应用的时候,把这个应用关闭就可以了
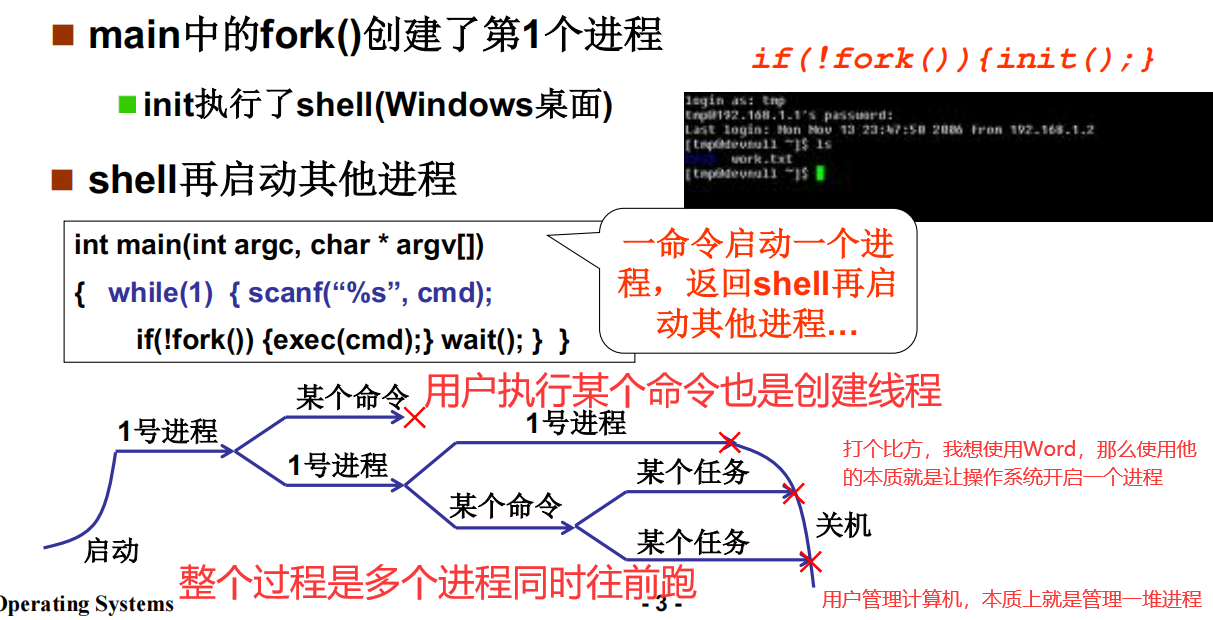
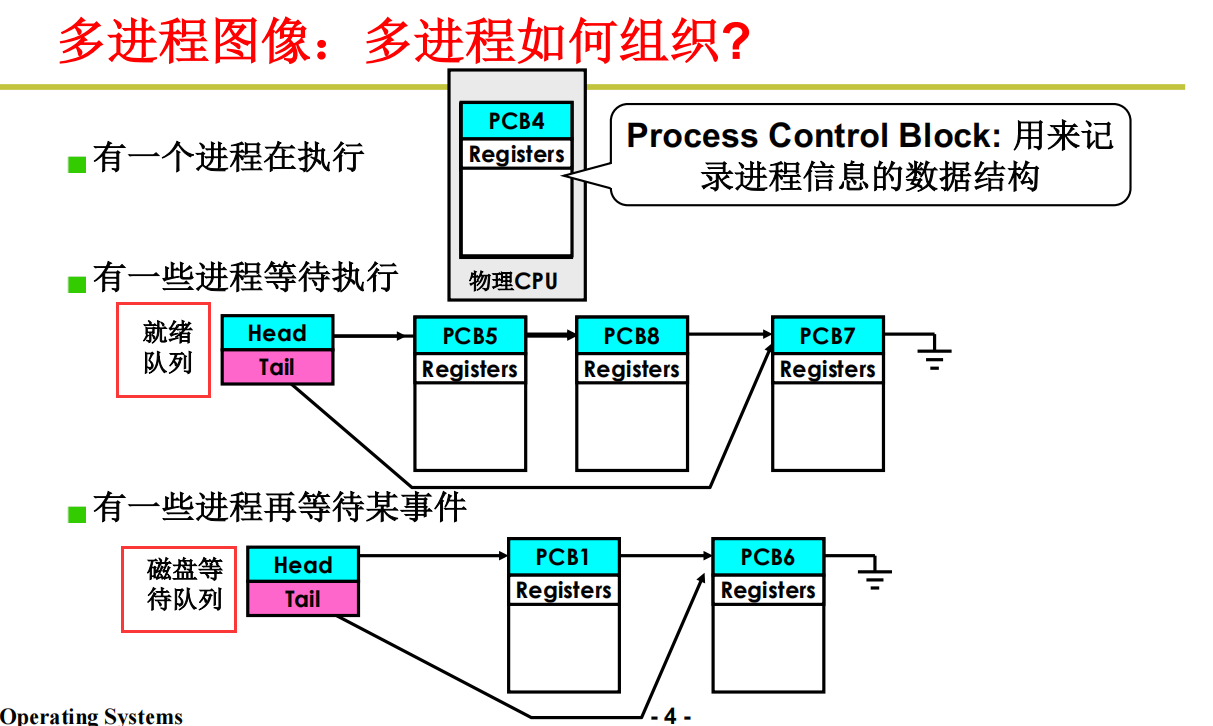
多进程是如何组织的
为了支持多进程,操作系统要做哪些努力?
操作系统对于进程的感知以及组织,全靠PCB(Process Control Block: 用来记 录进程信息的数据结构)
操作系统只有组织好多进程了,才能更好的推进多进程的运行。
在PCB结构体之上,组织一部分数据结构。比如队列
进程的状态
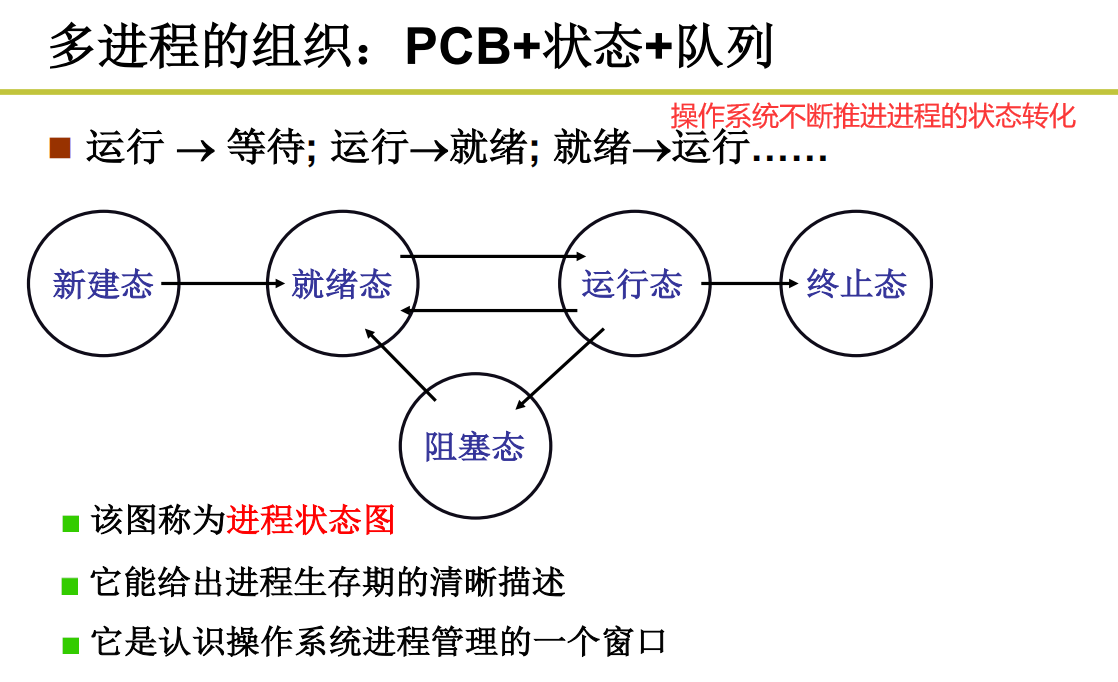
多进程如何交替
那么操作系统是如何交替向前推进的呢
多进程的意义就是切来切去去运行进程的

具体的进程是怎么调度的,这个涉及到很深刻的算法,所以不深入展开。

交替的三个部分:队列操作+调度+切换
操作系统找到了下一个进程就准备切换了
切换之前要把当前进程的信息保存好
切换回来要把之前保存的信息再恢复
保存在哪?保存在PCB的某些结构体中
进程对于内存的使用
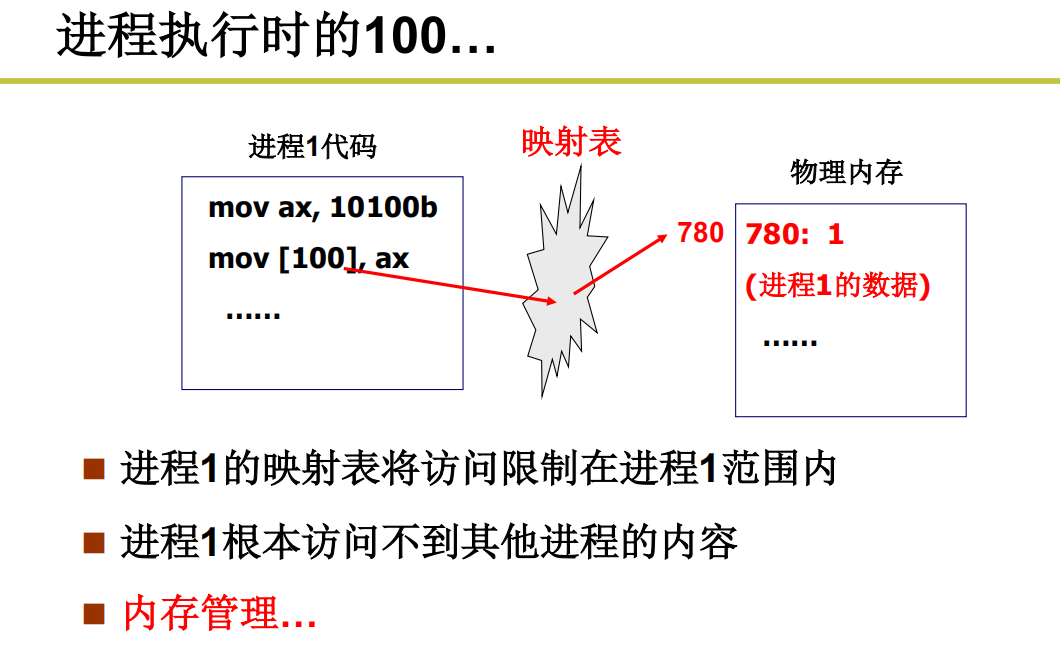
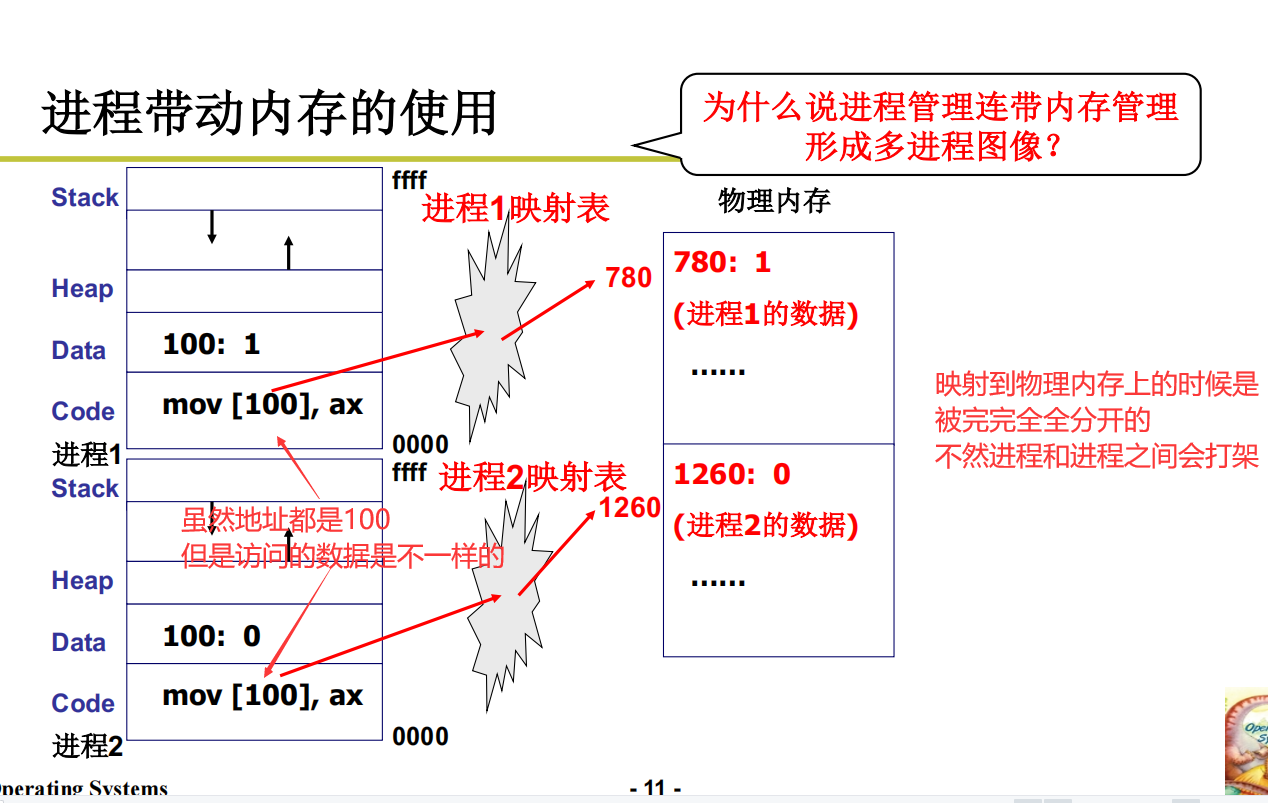
进程之间的合作
生产者-消费者实例

并发安全问题,看这个!
进程间的安全同步

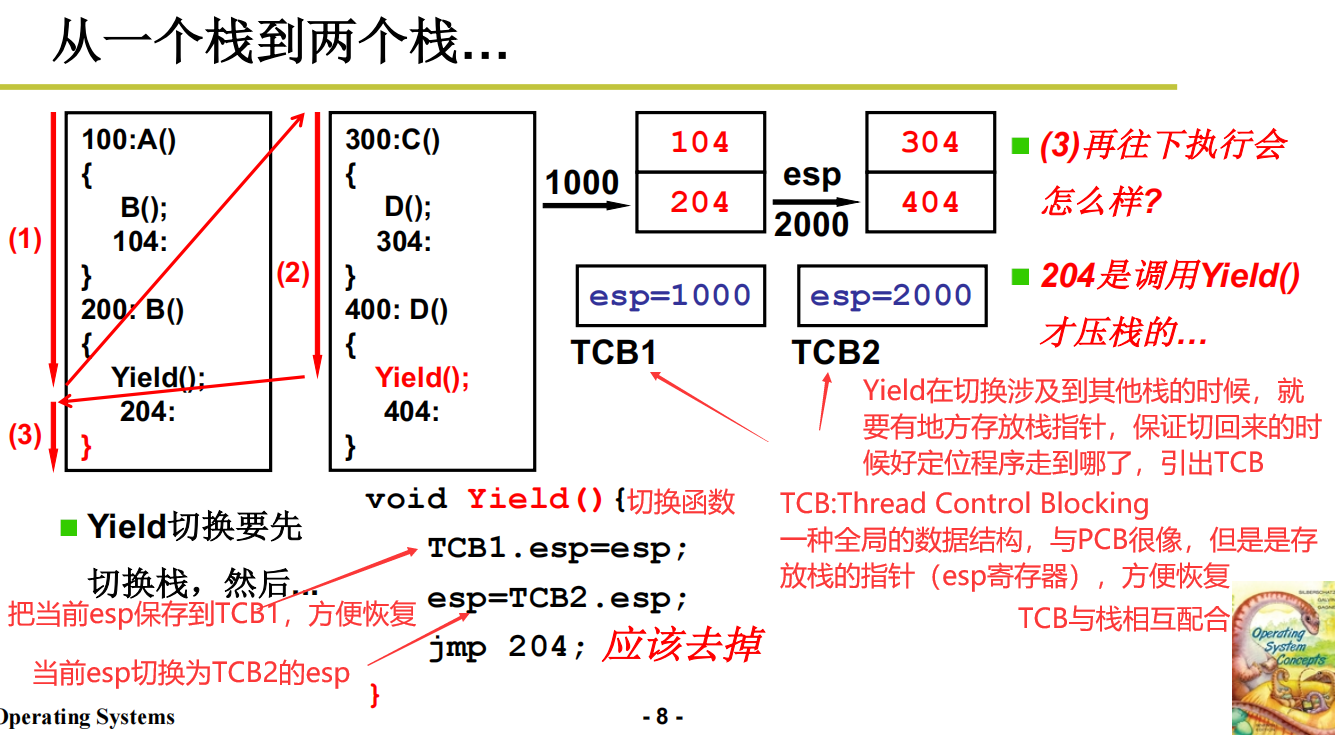
用户级线程(Yield)
Yield级别的线程完全靠用户来进行线程释放
概述
多个进程是如何切换的,操作系统做了什么让进程能切换起来。那要讲进程切换和线程有什么关系呢?
进程的切换是两个部分
- 指令的切换
- 映射表(内存)的切换
也是分治思想的体现。分而治之
线程级别的切换是快很多的,因为共用资源序列,所以不需要再依靠PCB频繁的记录和还原线程状态,因此只需要指令上去进行切换就行,所以速度很快。

线程切换的实际应用
数据都是一套资源,对于多个线程都是共享的
举个例子,网页加载的时候,大的资源比如图片加载很慢,小的资源比如文本加载很快。那么这种情况下,不能等都执行好了再去渲染页面。那怎么办呢,加载好一些小的内容就切出去把加载好的渲染到页面上。提升用户体验。

实现一个浏览器
Web加载源码:

Create、Yield 切换函数
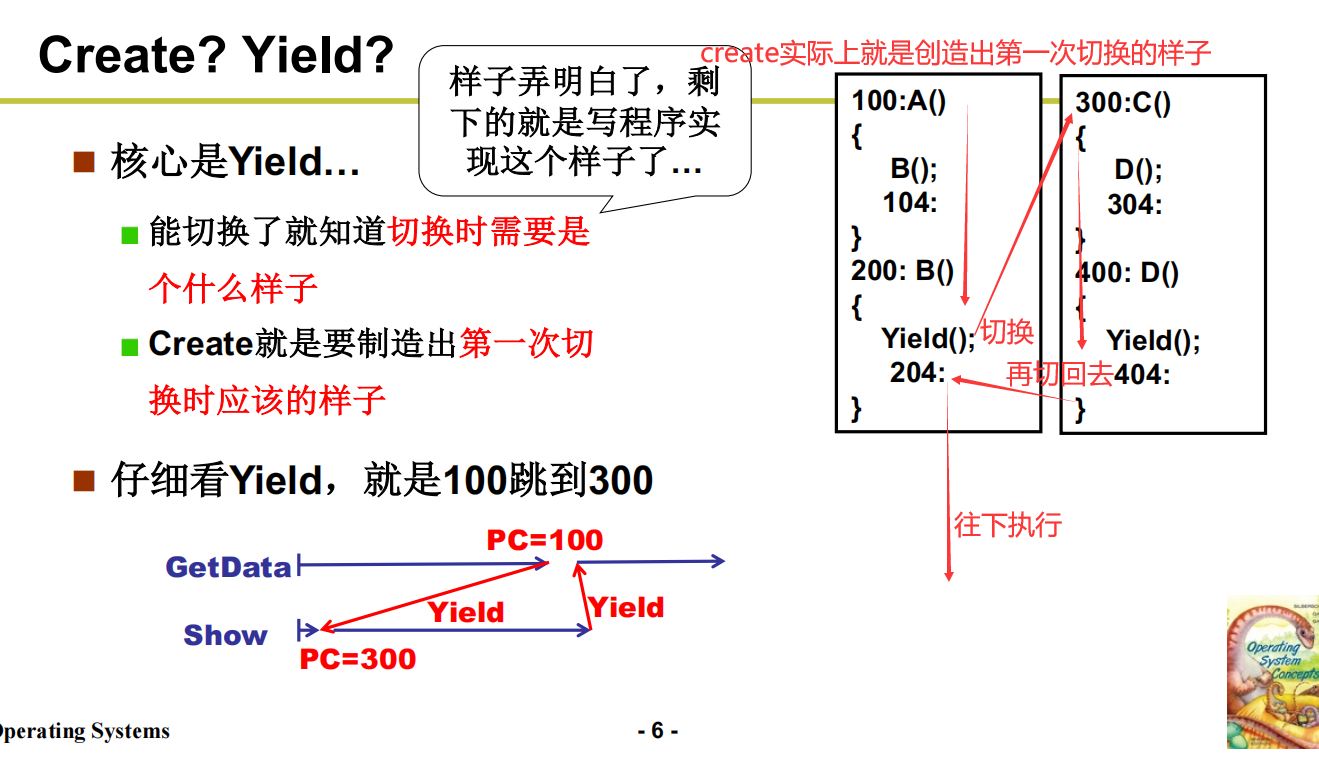
从一个栈到两个栈

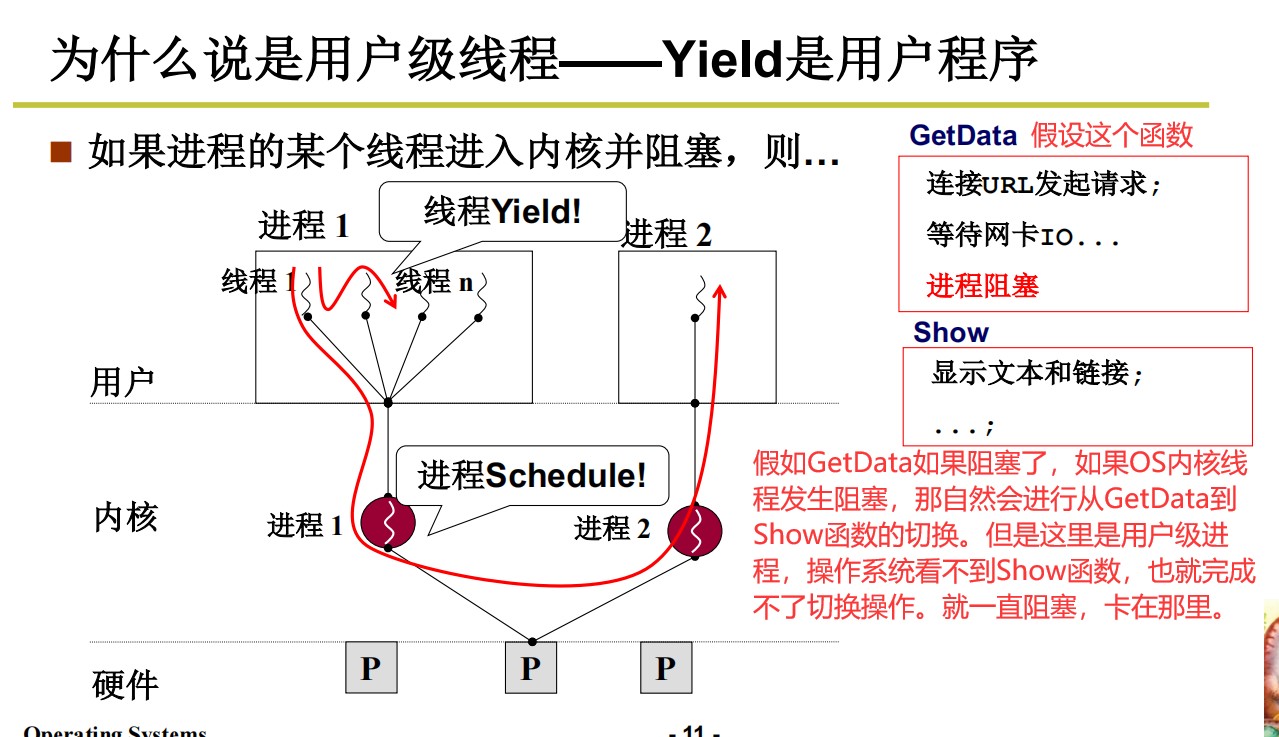
为什么说是用户级线程——Yield是用户程序
因为是用户级别线程,所以跟OS内核是完完全全分开的,仅限于用户态切来切去,操作系统完全感知不到他的存在,所以OS级别的切换,在用户级线程就够不到了,因为内核看不到OS的状态。
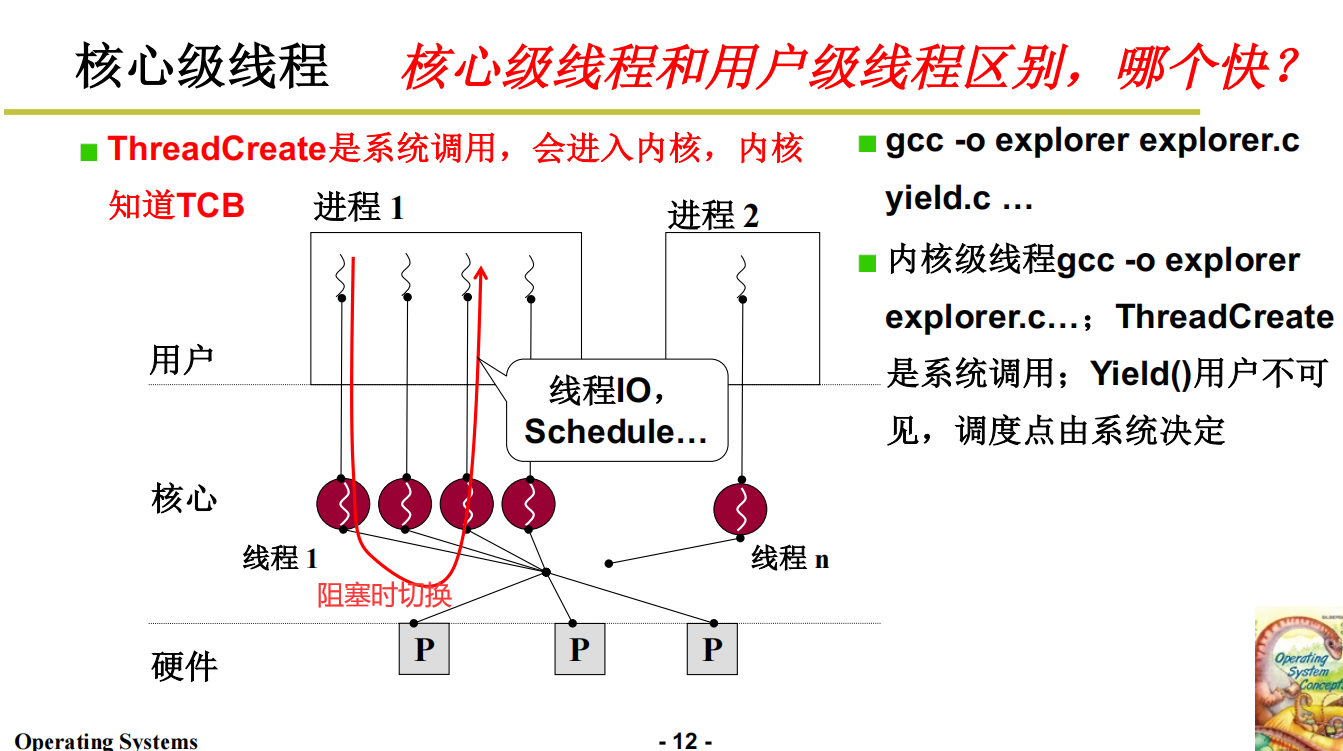
核心级线程(Schedule)
为啥要进入核心级别线程?因为要涉及到一些内核的处理,比如说print打印某些东西,这个操作在用户级别线程处理不了,必须通过中断进入核心处理,进入核心处理完了再出去继续执行用户线程。
核心级别线程的并发性要更好,因为阻塞可以切换到其他进程进行相应处理
多核处理器如果想发挥作用,必须要支持核心级线程。
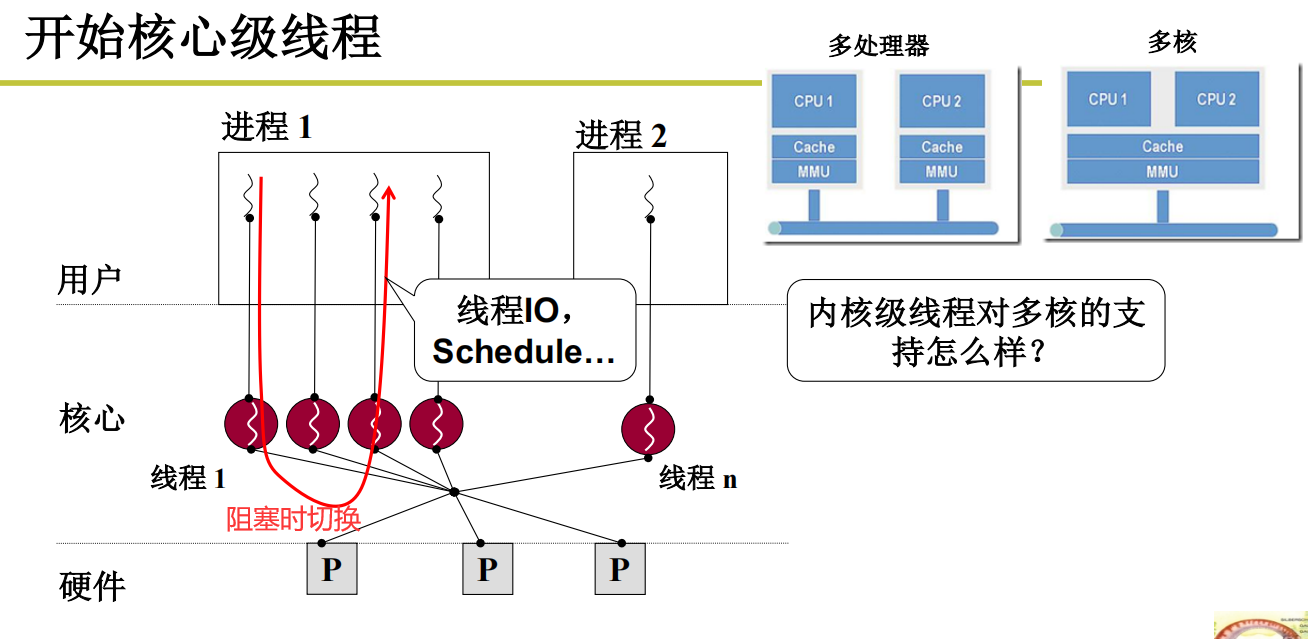
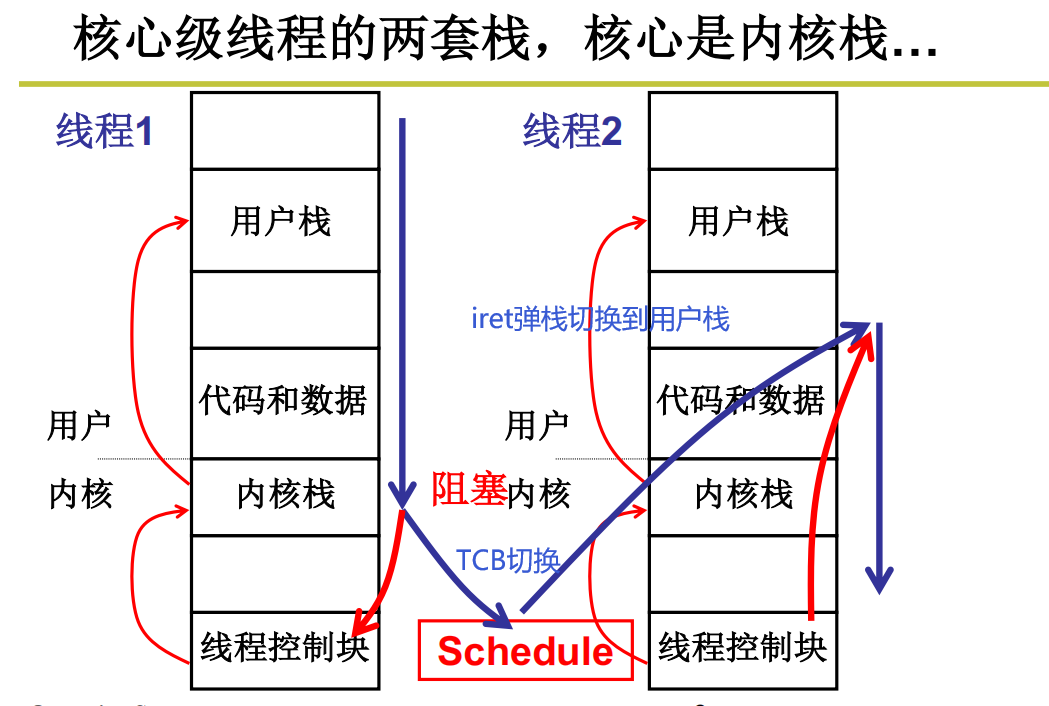
核心级线程有什么不同
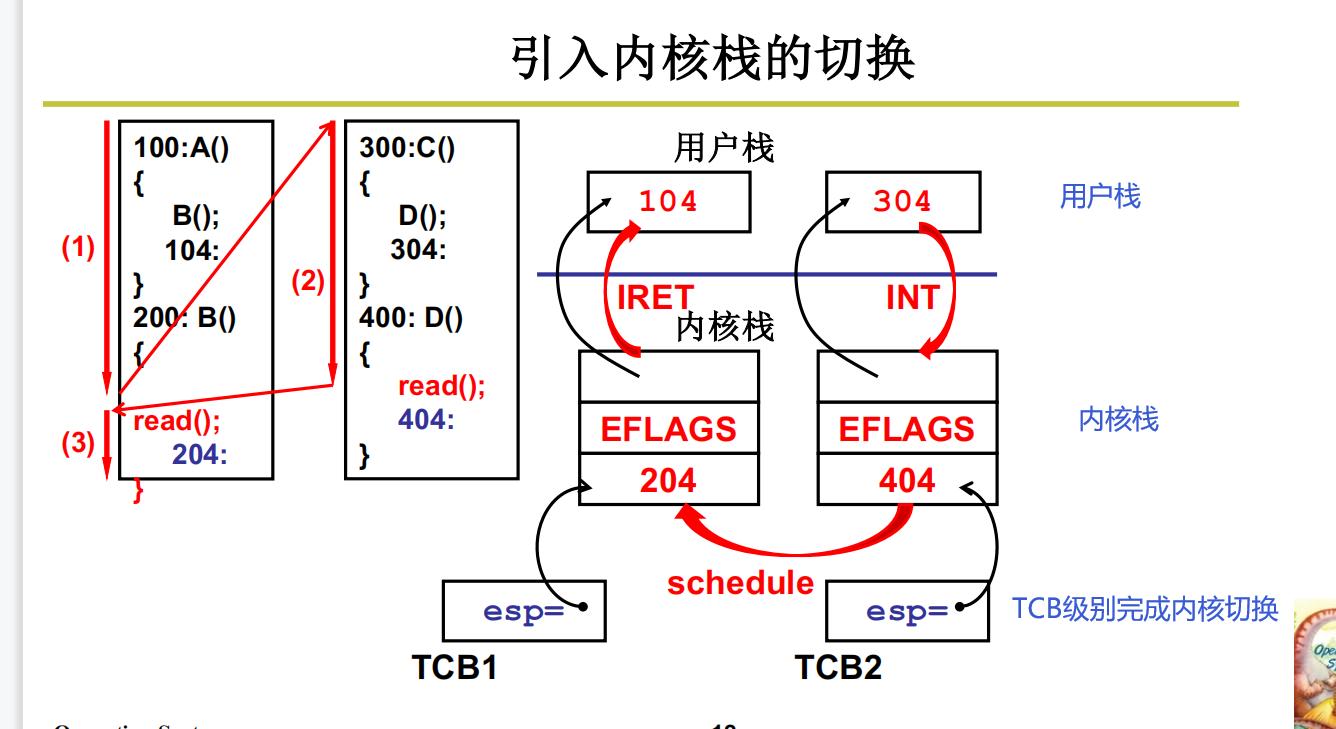
核心级线程是两套栈:用户栈+内核栈
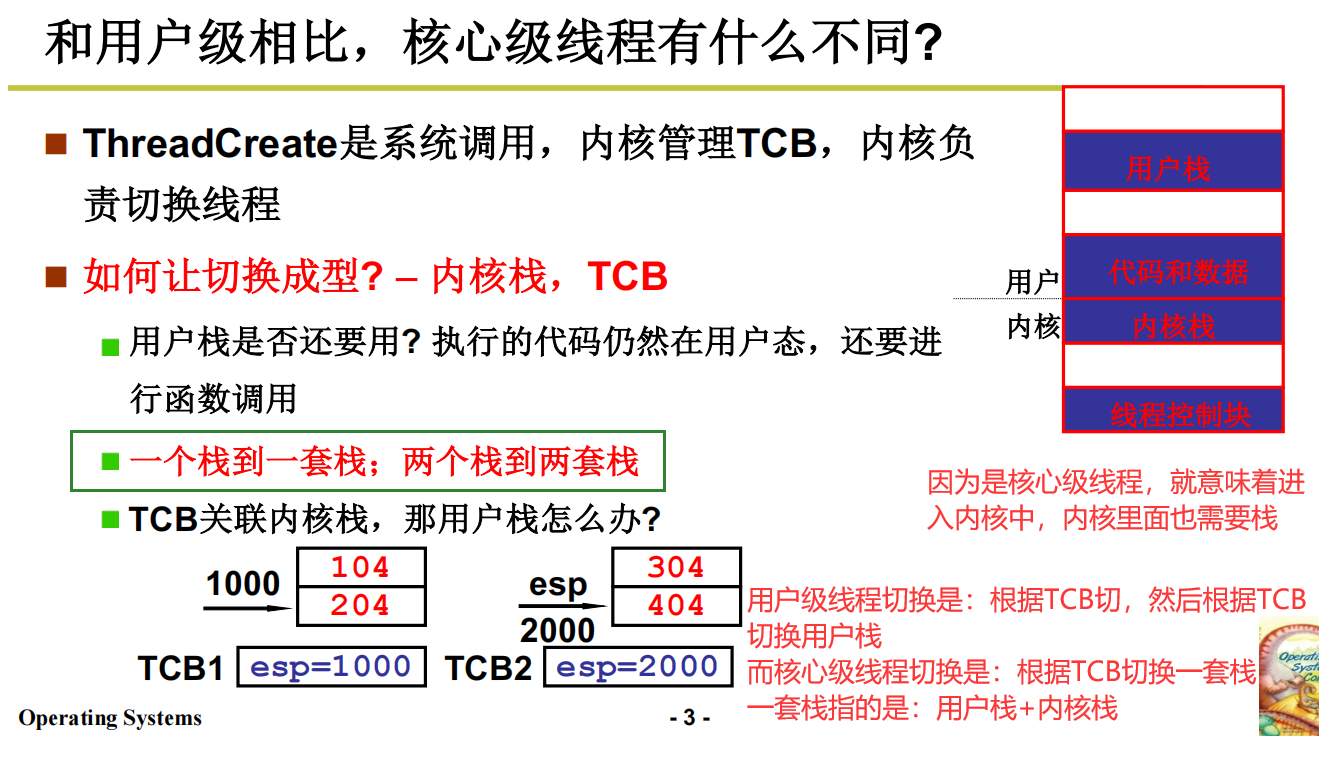
什么时候会出现内核栈?
当然是进入内核的时候就会出现内核栈。在内核中跑程序的时候分配栈空间。

举个例子
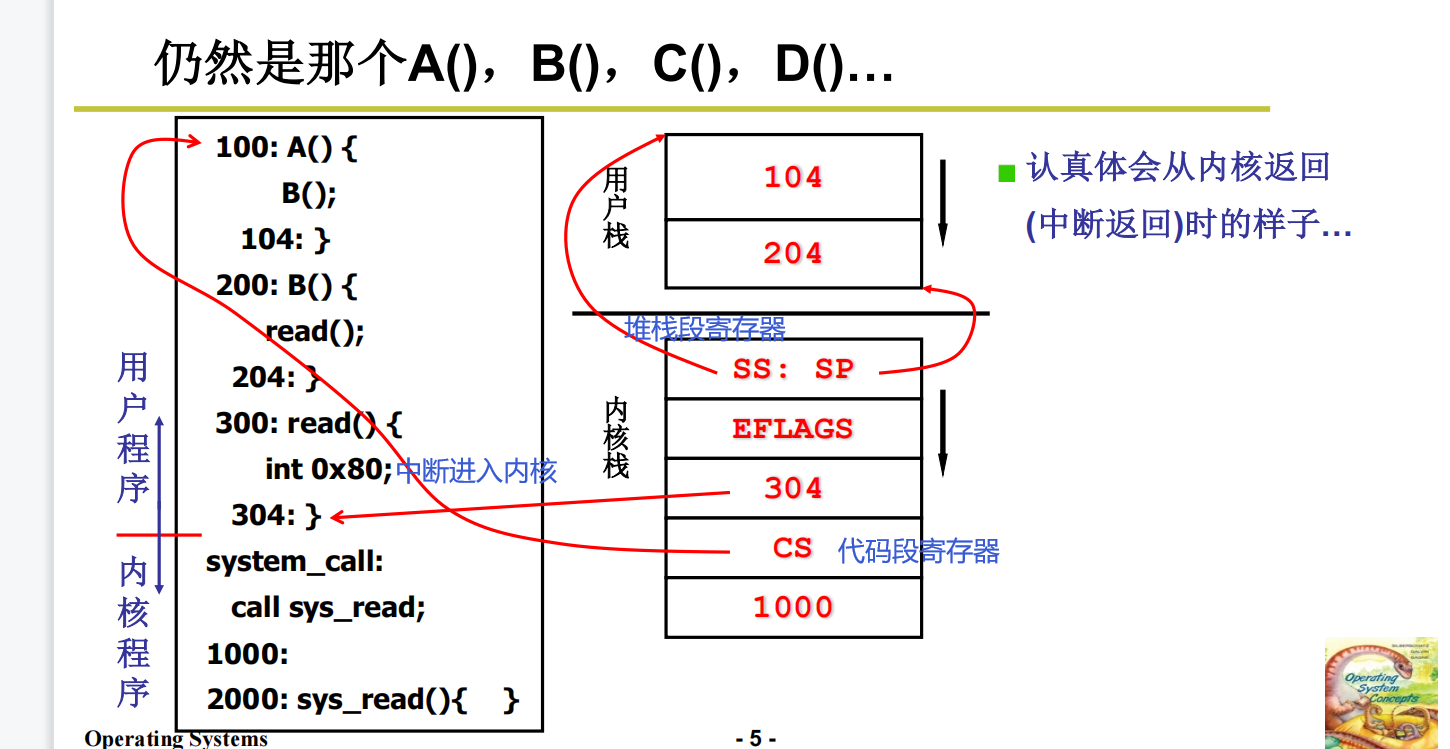
进来之前把用户级线程运行的数据保存好,保存好之后方便从内核切回来的时候恢复
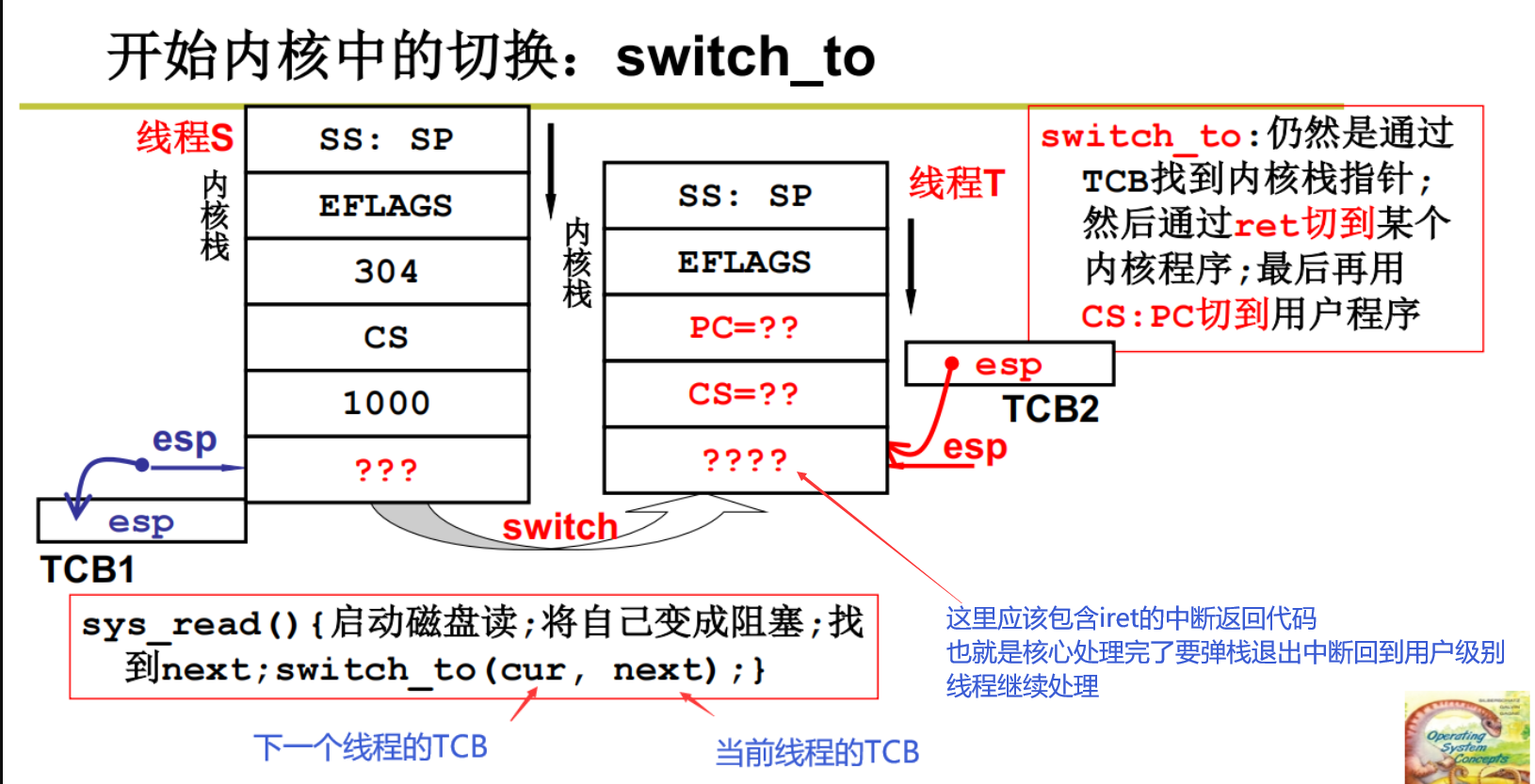

核心级线程切换总结图
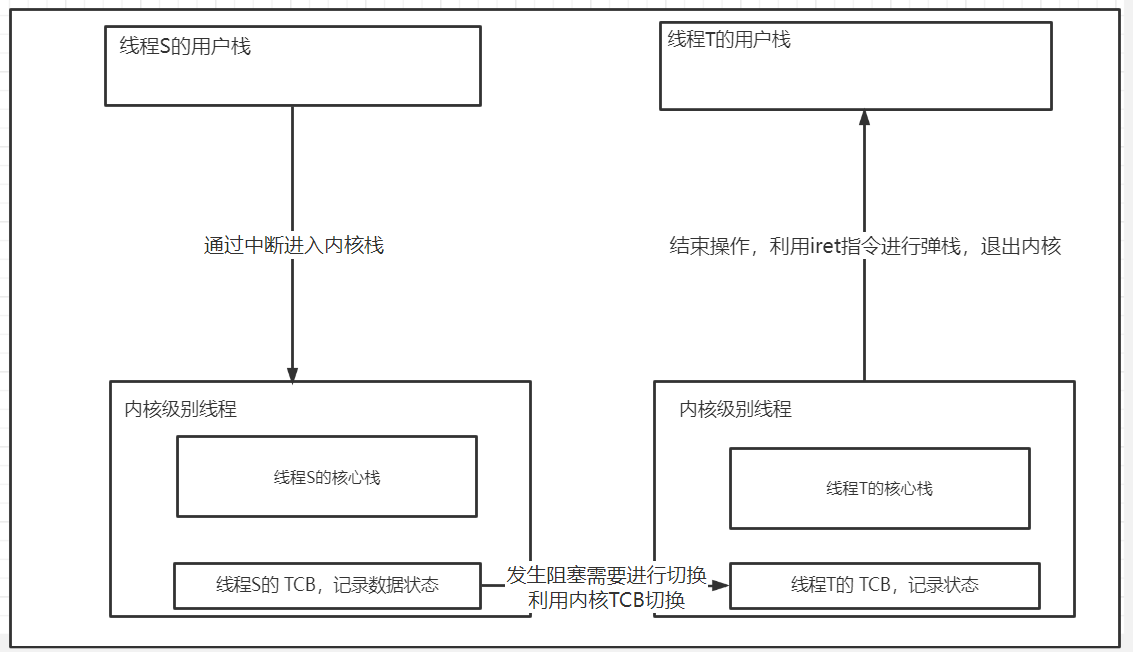
switch_to函数

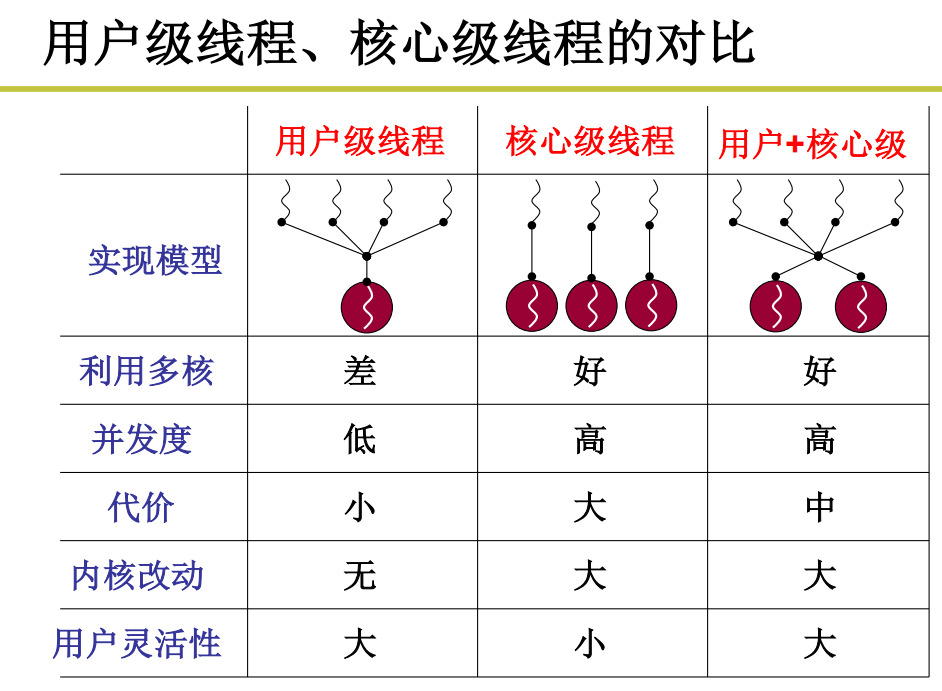
总结比较
核心级线程源码实现
切换五段概述
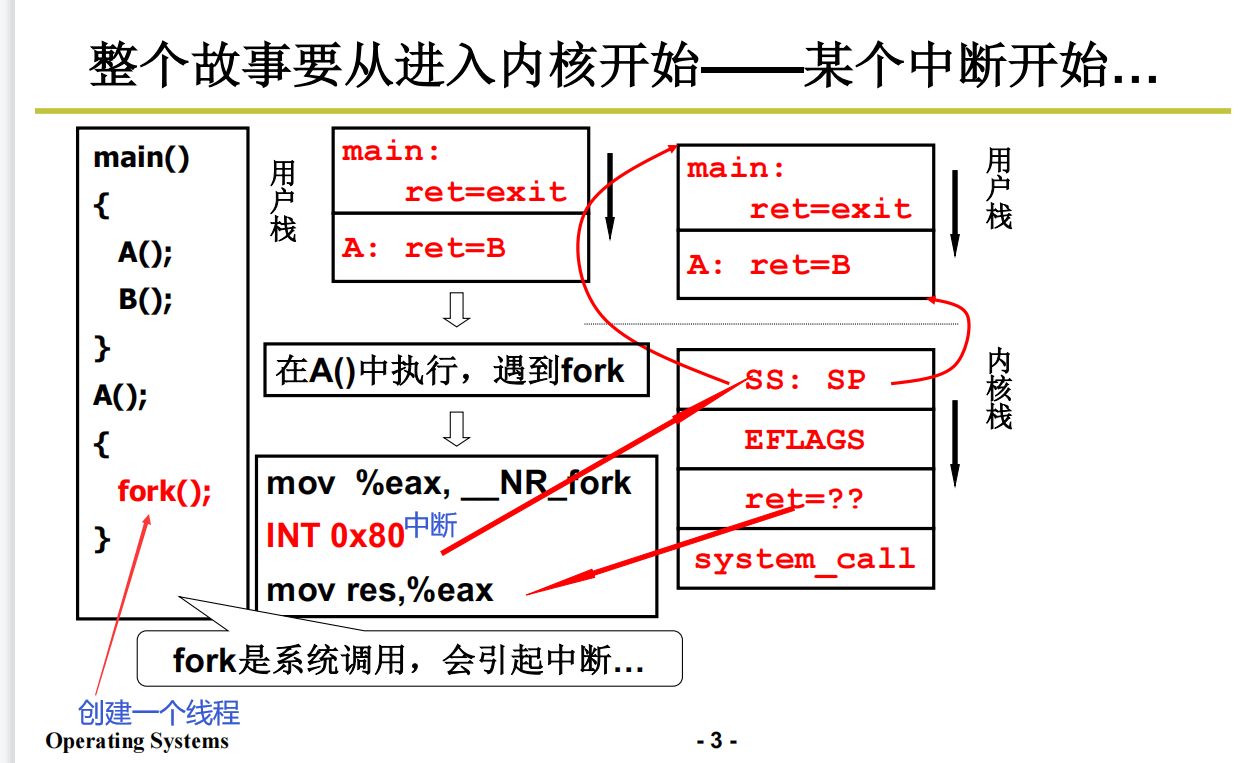
核心级线程的实现难点就在于两套栈之间的切换
从进入内核开始(中断进入)
剩下的源码需要汇编才能看懂,暂时跳过,吐槽一下,太难了~
存档点:L12 内核级线程实现
操作系统的那棵“树”
整理一下之前的内容,操作系统是人类创造的最复杂的系统之一。为什么说是树呢,是因为再复杂的系统也是从某一点开始发展起来、外扩起来的。
回顾
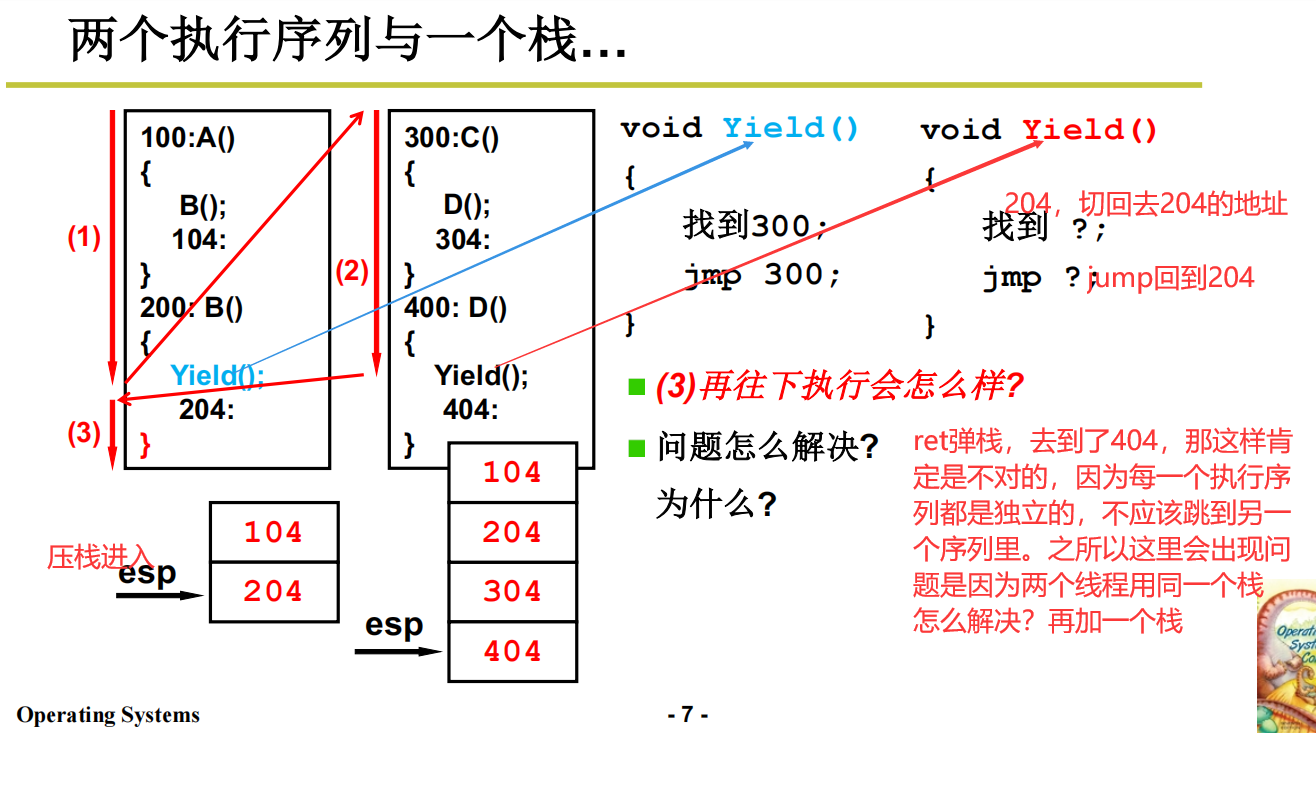
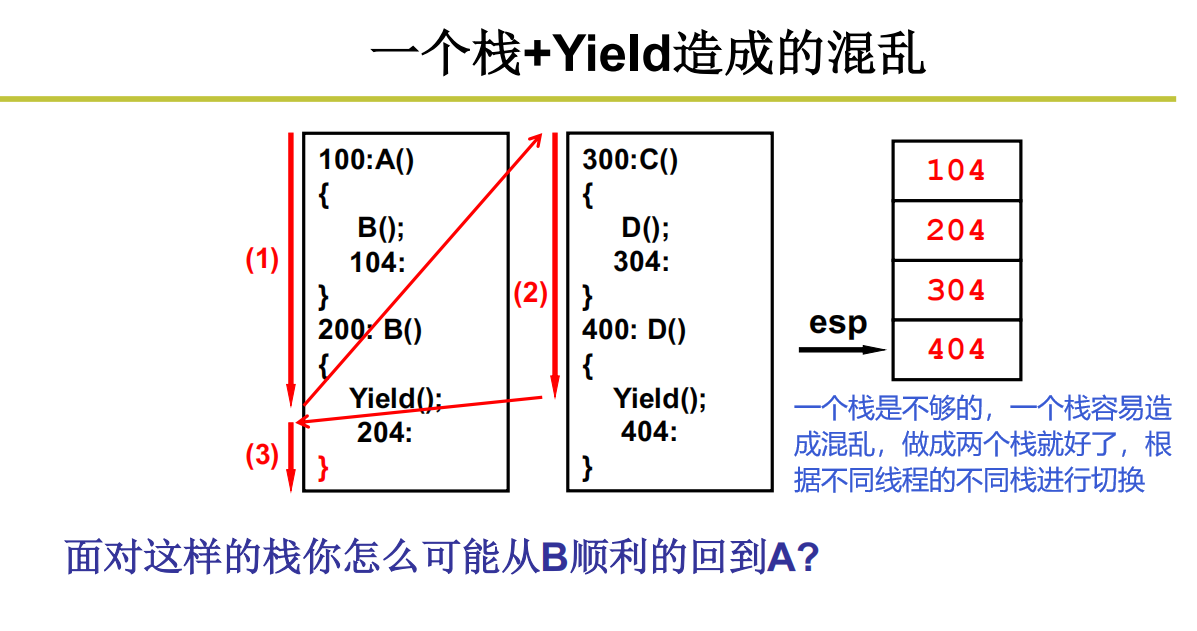
一个栈造成的混乱
那跳转(切换)怎么做呢?用栈来做这个事。但是切出去了只是暂时的,目的是为了等待某些长时间的操作(比如磁盘的IO),当这些长时间的操作结束之后,还需要再切回之前的线程继续完成相关操作。
两个线程两套栈+TCB
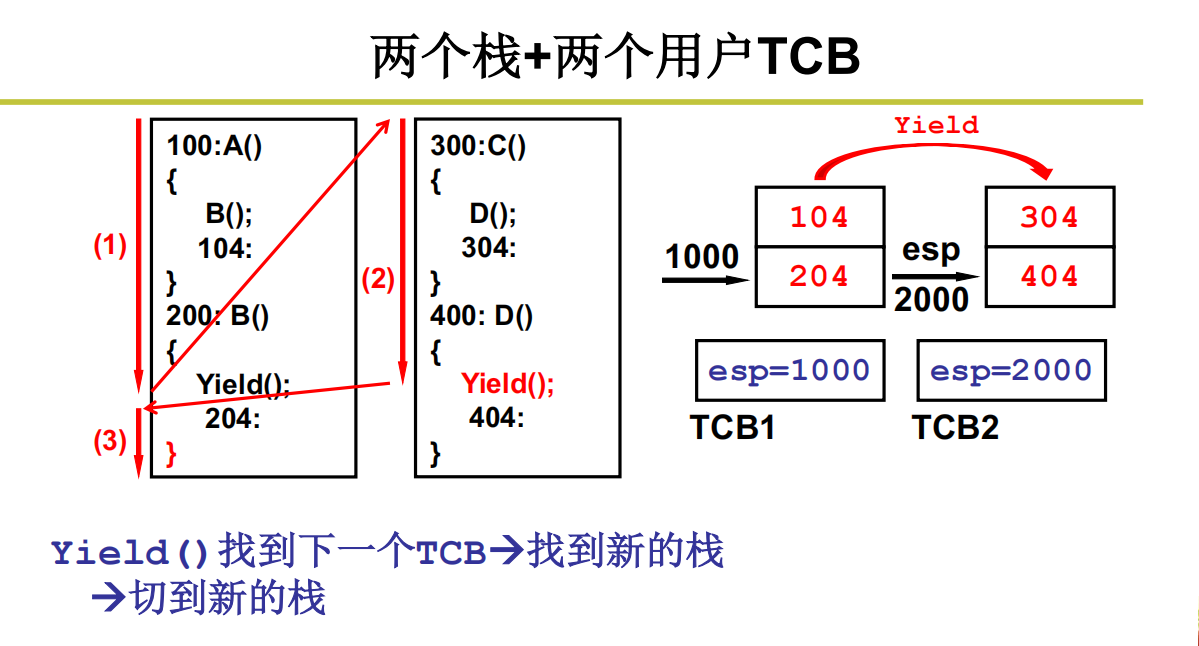
但是这也有问题,就是这种用户级别的线程切换涉及不到内核,所以想通过内核进行切换还是不行的。那怎么通过内核进行切换呢?引入内核栈的切换。
引入内核栈的切换
CPU调度
这个主要是学习一个调度的策略
概述
CPU调度的直观想法

如何设计调度算法
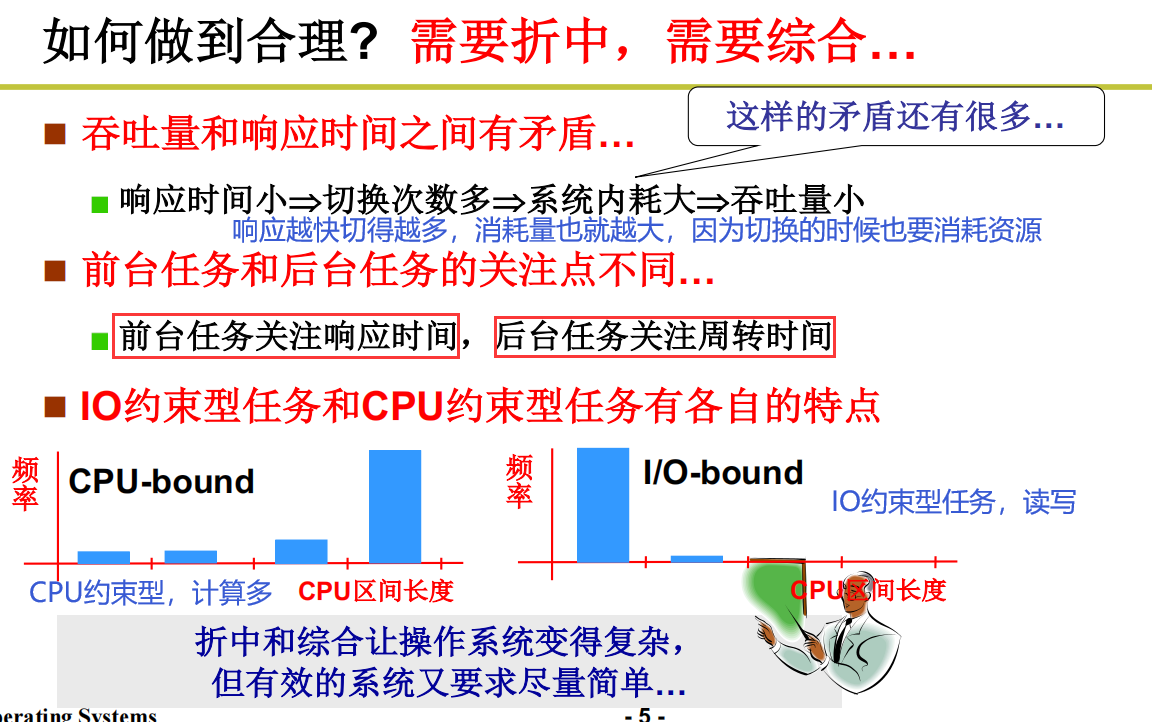
设计调度算法时的取舍

操作系统在调度的时候,应该做到折中和综合
没有完美的调度算法,只有最适合的调度算法,需要折中,需要综合。
各种调度算法
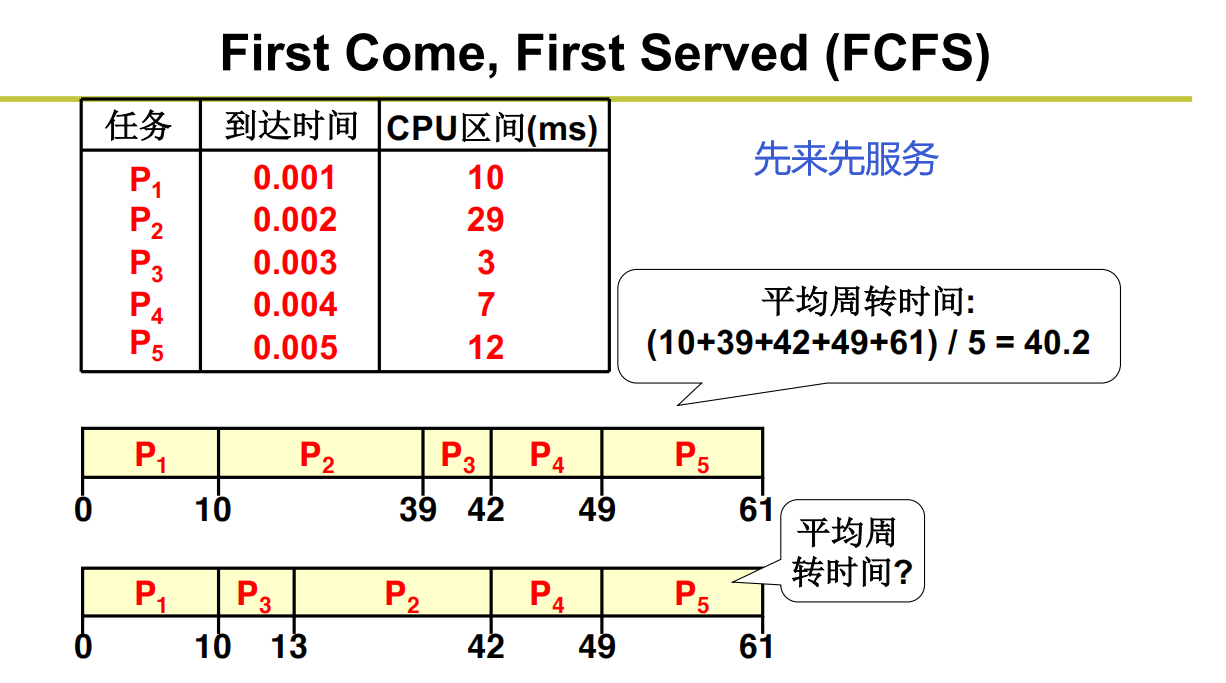
先来先服务(First Come, First Served (FCFS))
核心思想:和队列差不多,先进先服务
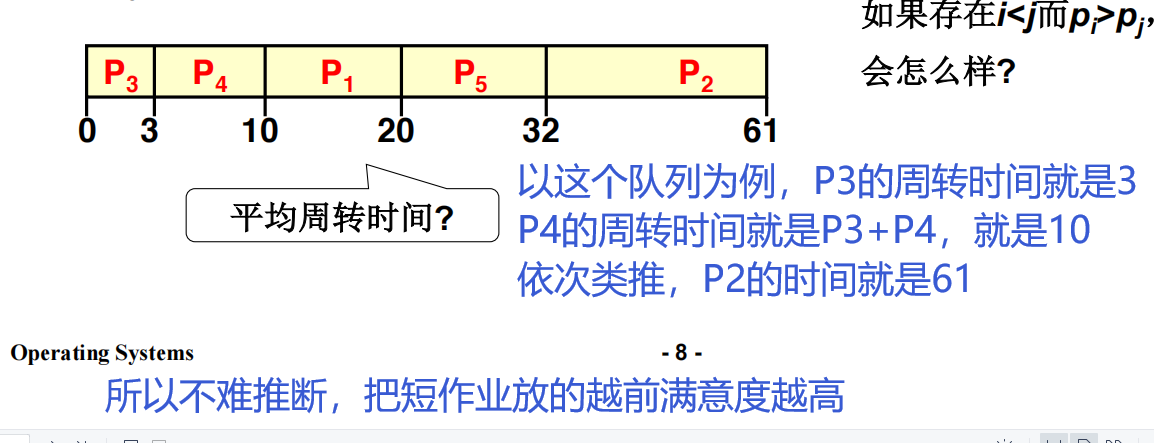
短作业优先(Shorest Job First(SJF))
周转时间角度解读
核心思想:将处理时间短的作业提前,使其短作业满意度上升,从而间接提升总满意度

响应时间角度解读

响应时间和周转时间的平衡

带来的一些问题,我们知道前台优先级是高于后台的,那如果一直优先执行前台程序,后台捞不到执行怎么办?
这种就很难取舍

还有许多的问题,所以设置一个合适的调度机制是非常非常重要的~
我们怎么知道哪些是前台任务,哪些是后台任务,fork
时告诉我们吗?
gcc就一点不需要交互吗? Ctrl+C按键怎么工作? word
就不会执行一段批处理吗? Ctrl+F按键?
SJF中的短作业优先如何体现? 如何判断作业的 长度?
这是未来的信息…
实现一个schedule函数
通过这个函数来体会操作系统中如何实现折中的调度。
调度函数schedule()

counter的作用: 时间片
counter是典型的时间片,所以是轮转调度,保证了响应
counter的另一个作用: 优先级

counter作用的整理

进程同步与信号量
为什么要搞这个东西,就是为了让多进程合理有序的合作。怎么实现同步?就要靠信号量来实现多进程合理有序的推进。
现实中多进程共同完成任务的例子
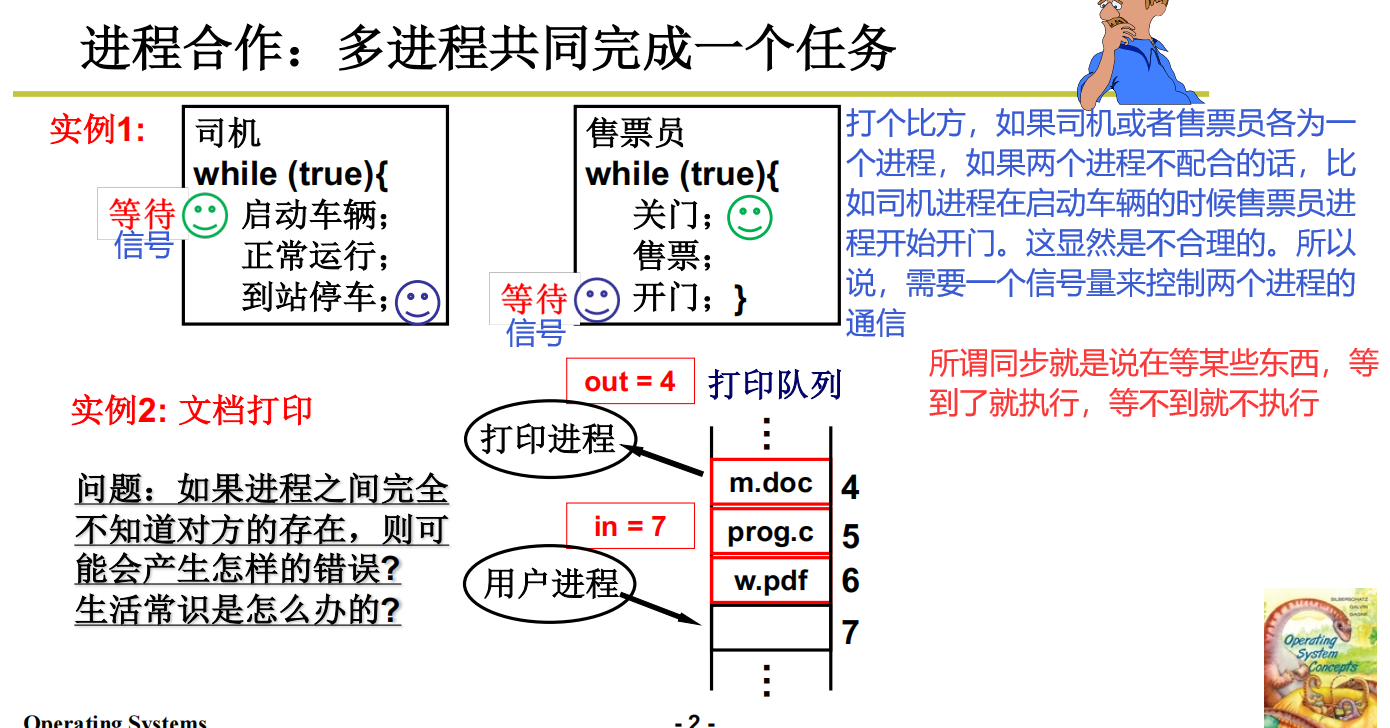
生产者消费者实例

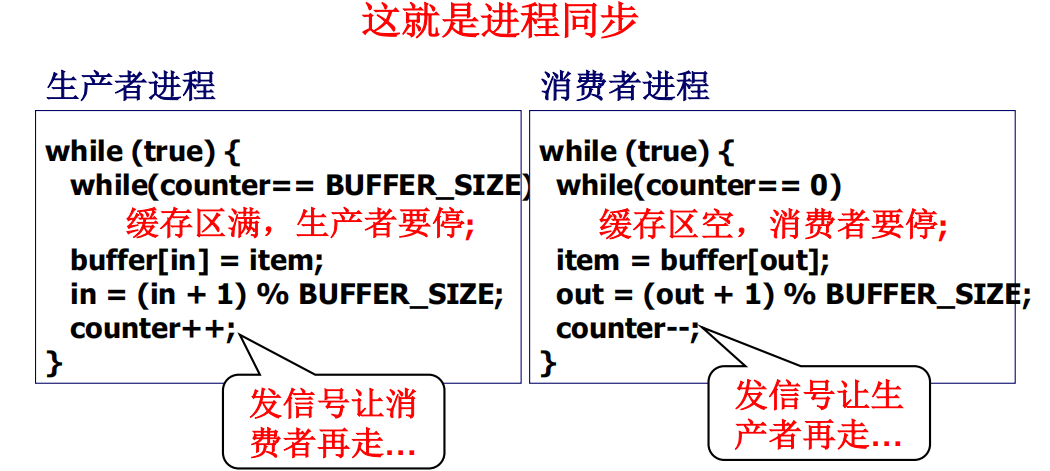
只发信号的问题
只发信号还不能解决全部问题
因为信号只是一个布尔值,无非是和不是,有和没有。所以这是不够的,要引入信号量,要有更多的信息。

信号量(Semaphore)
从信号到信号量。信号量不应该只是睡眠与唤醒,还应该除了睡眠与唤醒之外,记录一些更全面的信息。比如到底有多少个进程在等待
从信号到信号量是一个非常伟大的变革

解释上面的流程
信号量开始工作

什么是信号量? 信号量的定义

利用信号量解决生产者消费者问题

信号量临界保护
单有信号量还是不够的,没有信号量的保护是不能工作的。完整的应该是靠着临界区来保护信号量,靠信号量来实现进程的同步。
温故而知新:什么是信号量? 通过对这个量的访问和修改,让大家有序推进。哪里还有问题吗?
共同修改信号量引出的问题
所以,为什么要保护信号量?
因为信号量要保证正确,因为进程是看着信号量工作的。如果出错,那么线程就无法有序推进。
所以信号量的值必须要准确且清清楚
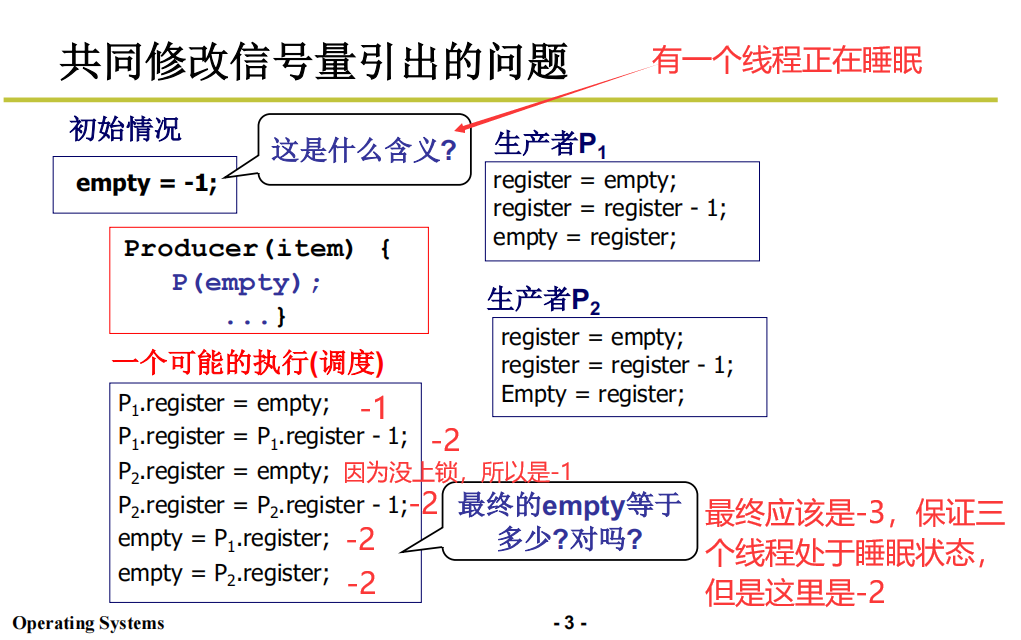
共享数据如果不做保护,就很容易出问题。
在不该争取的时候进入线程争取资源导致的问题。这个是CPU调度顺序导致的相关问题,不是程序上的错误。

解决竞争条件的直观想法
就是修改公共资源的时候加锁,保证其原子操作

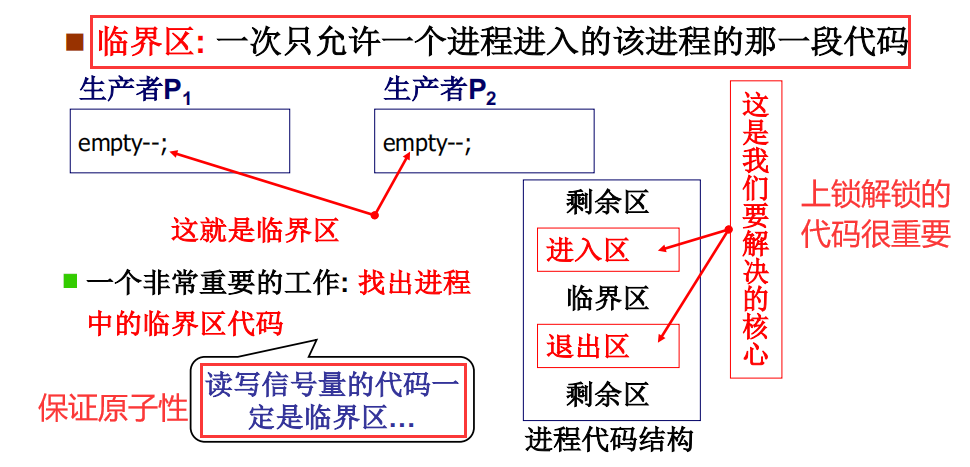
临界区(Critical Section)
被夹在加锁和解锁之间的那段代码成为临界区
进入区加锁,退出区解锁,剩余区就是剩余代码
临界区: 一次只允许一个进程进入的该进程的那一段代码
临界区代码的保护原则

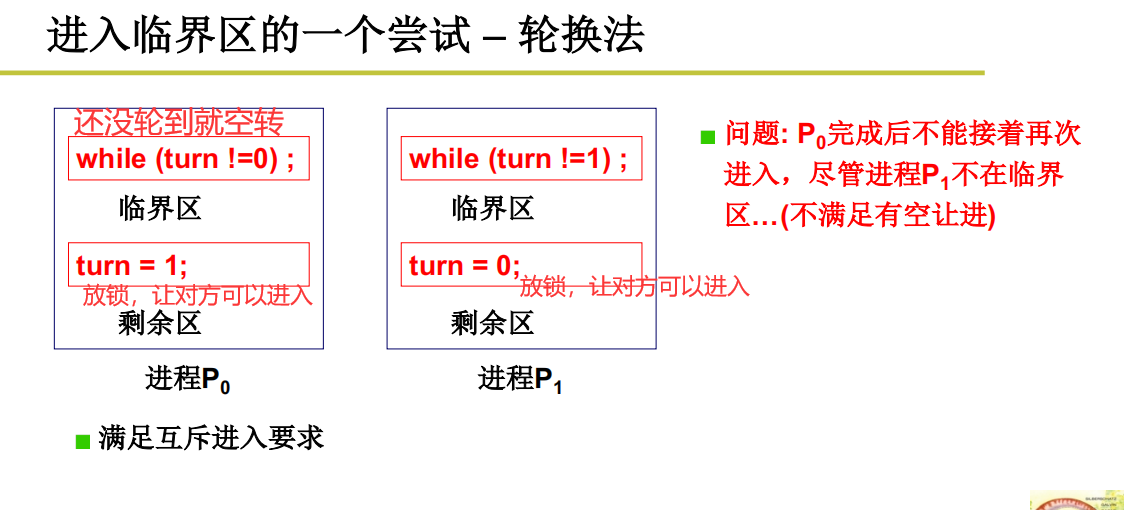
进入临界区之(轮换法)
现实生活中常见的值日
进入临界区之(标记法)
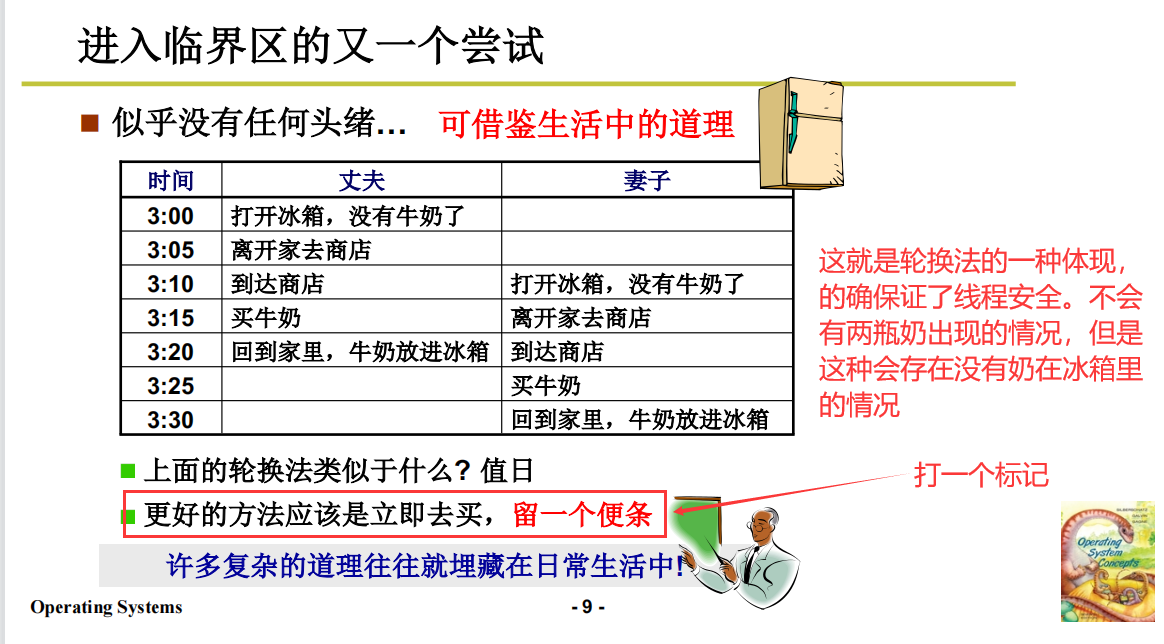
引出标记法
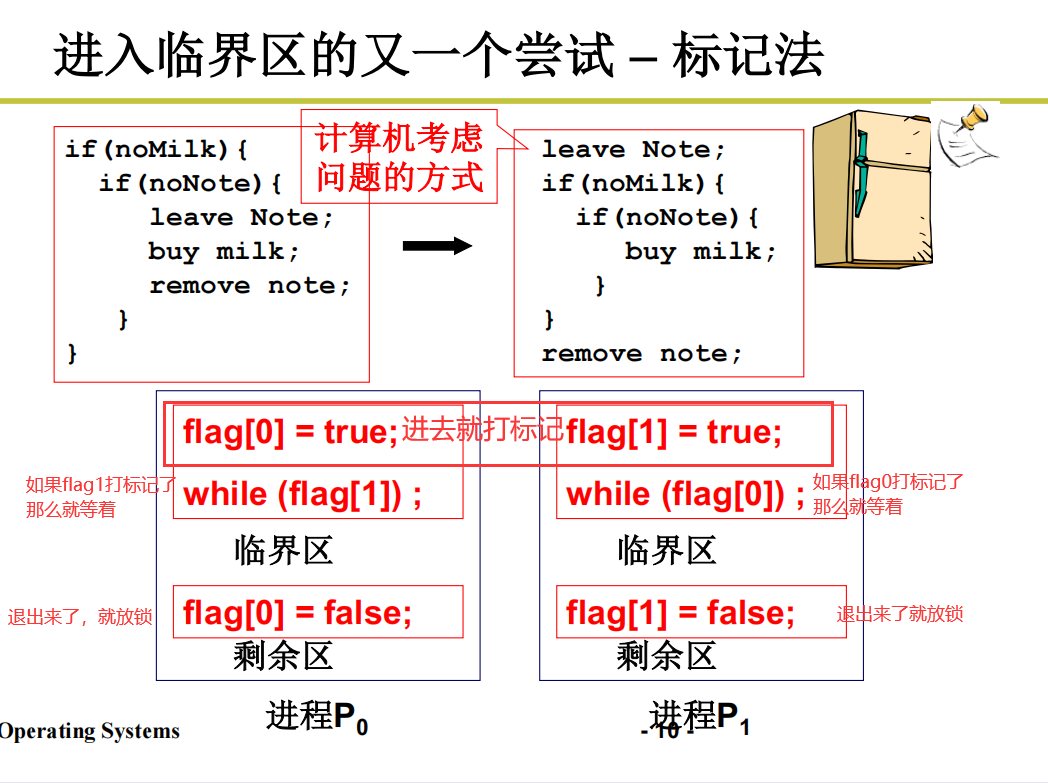
但是标记法还是解决不了有空让进的问题,因为他没办法主动进入临界区查看是否可以进入,所以对其进行改写。进入临界区的再一次尝试,非对称标记。何为非对称标记?就是让一个线程更多的去进行查看

进入临界区之(Peterson算法)

为什么说这个算法是正确的,满足了多个条件

多进程临界区算法(面包店算法)
一般来说,面包店算法是用于多个进程的
仍然是标记和轮转的结合。
借鉴于排队取号的思想,每个进程进来的时候先取号,取到的这个号不为0(代表我这个进程想进来)。
先取号的号码就小,优先级就高。

面包店算法的正确性

但是这个算法太复杂啦!要是信号量溢出了,这个怎么搞,很明显这个还是非常麻烦的。所以看看其他的简单算法。
优化面包店算法
这个算法是软件级别的,并非硬件级别的。
现在引入硬件级别的信号量,软硬件协同设计。

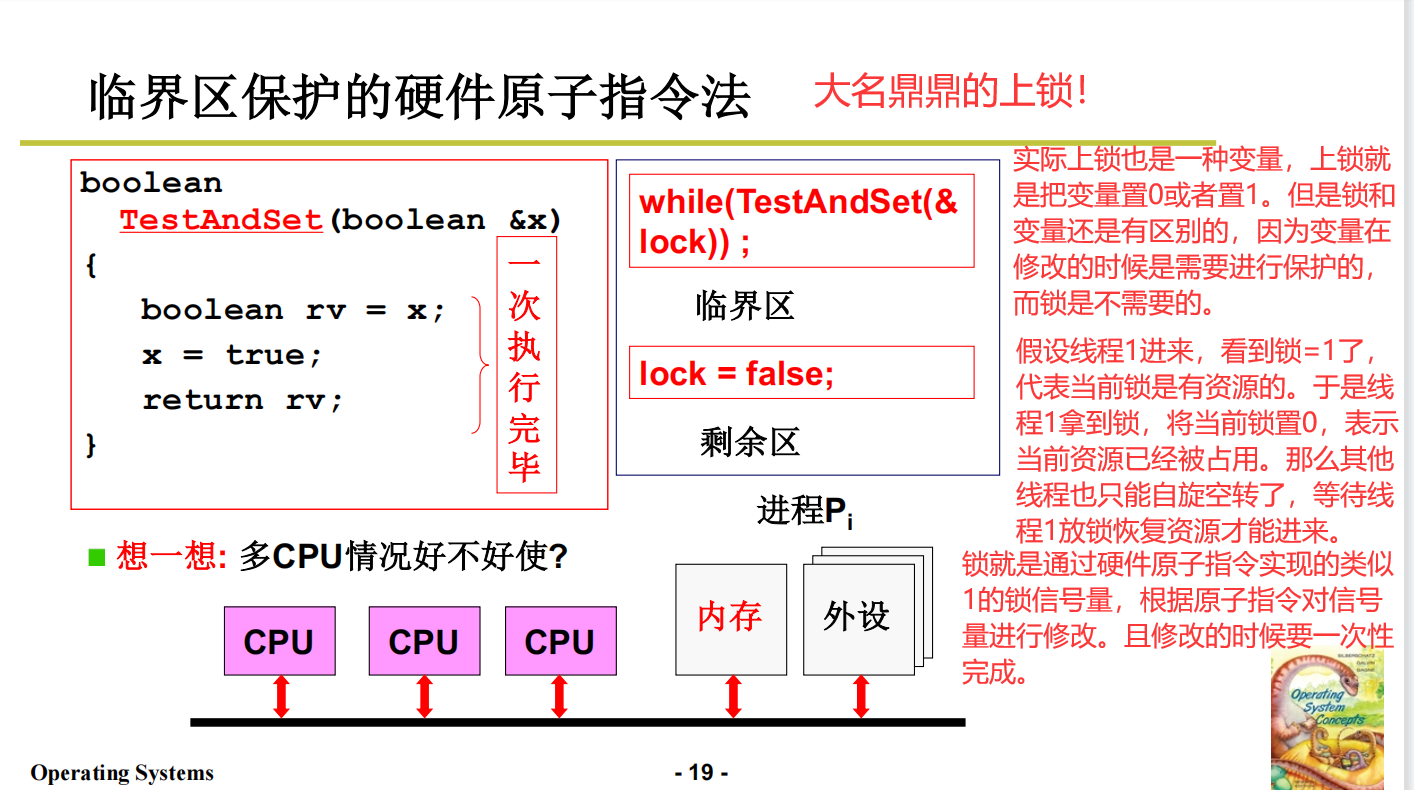
总结一下:
用临界区去保护信号量,用信号量来实现进程的同步。
信号量的代码实现


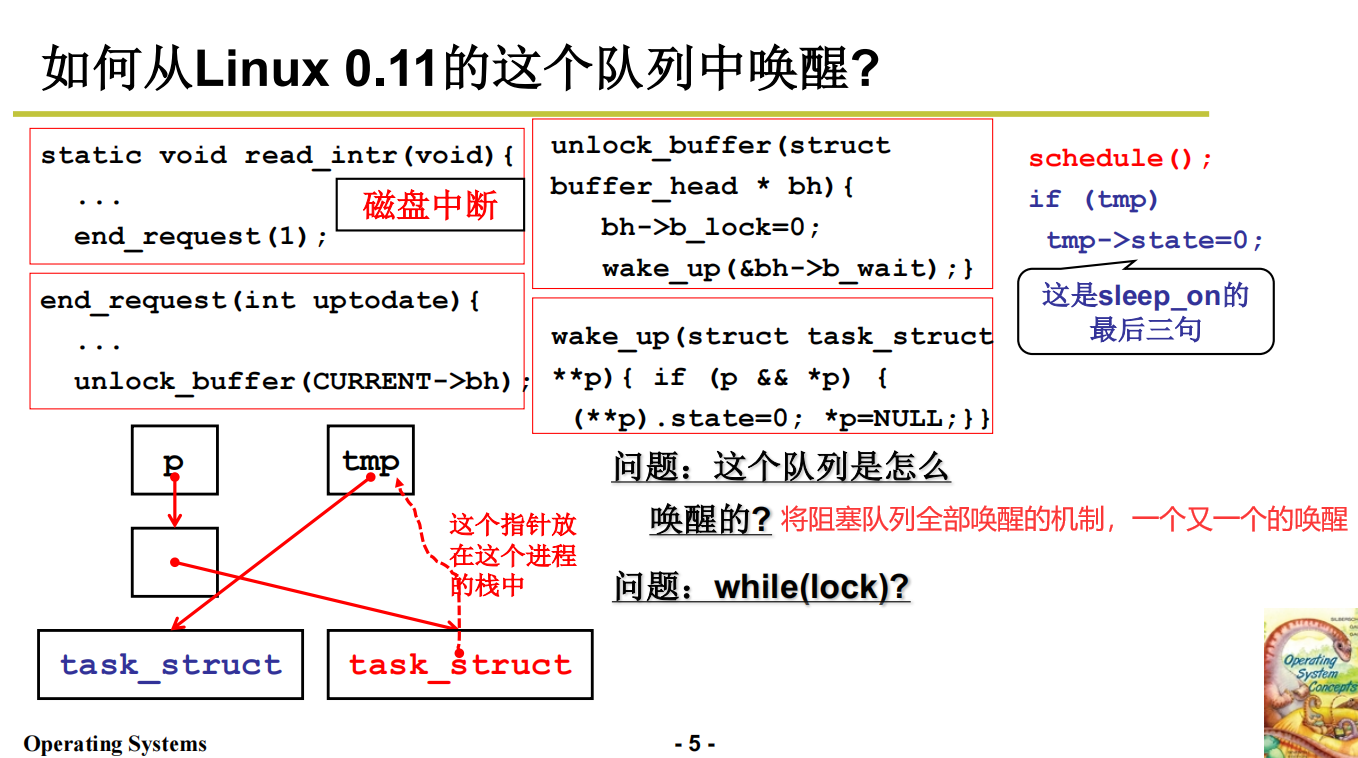
死锁处理
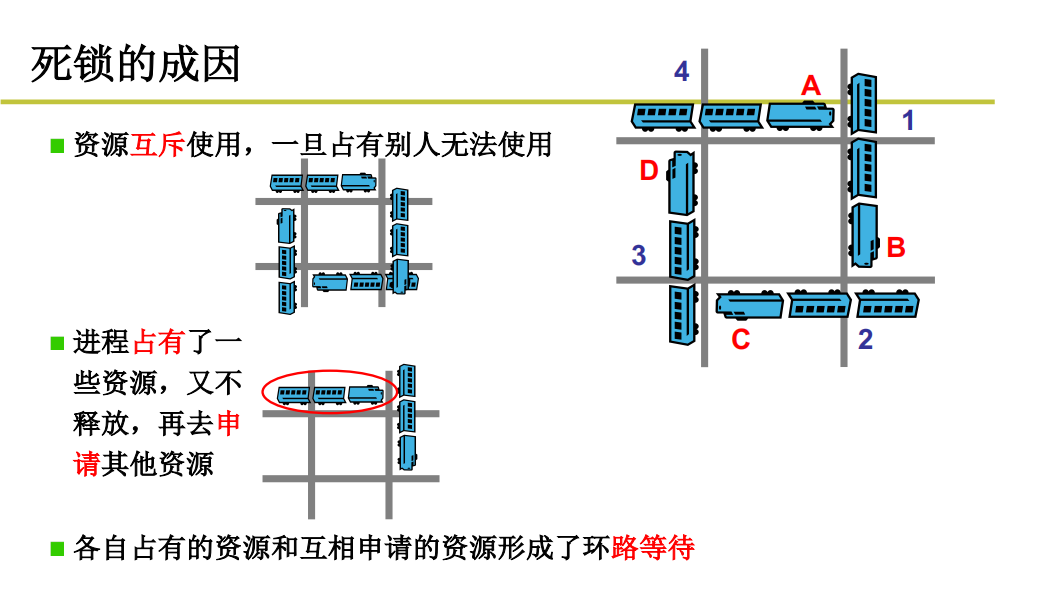
如果处理不好信号量,就容易产生死锁的问题。
死锁场景

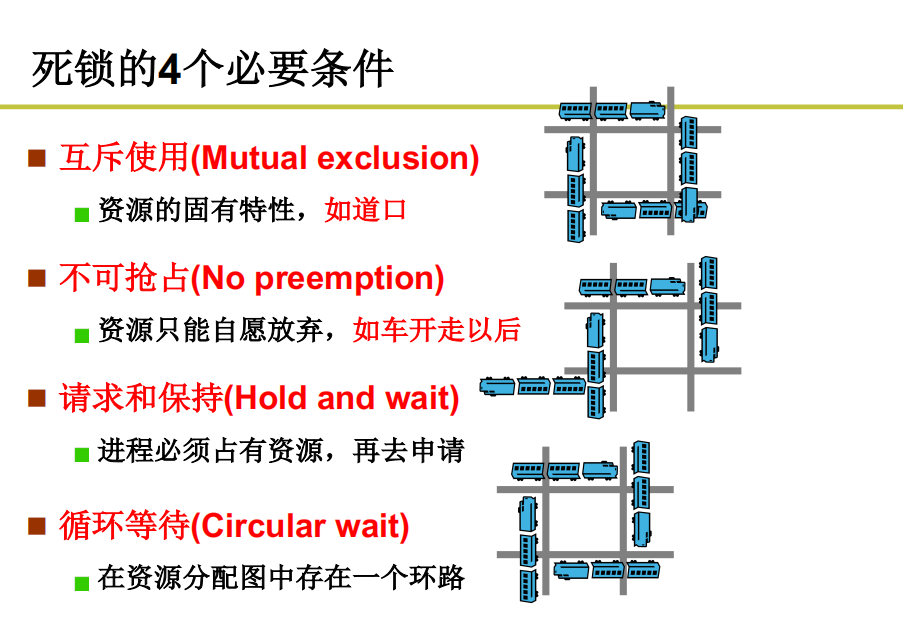
死锁的必要条件
死锁处理方式
早期在Linux0.1上根本没有死锁的处理相关代码,但是在一些特殊的场景代码,比如银行,卫星这类系统就必须有死锁处理的代码。

死锁的预防

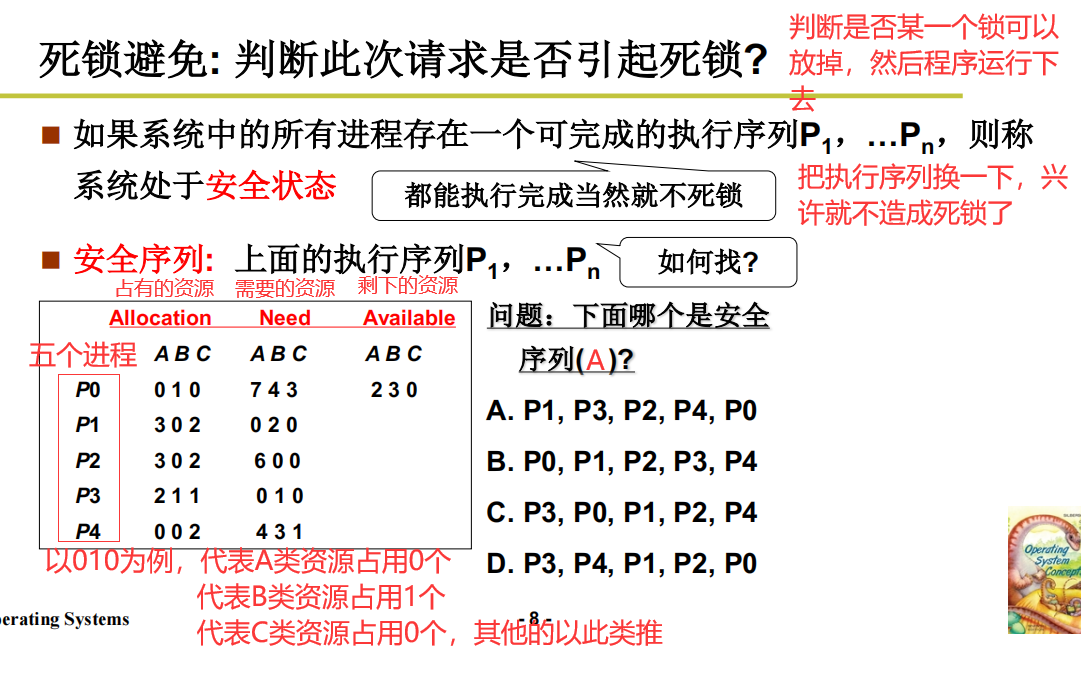
这种算法就叫做银行家算法

死锁避免之银行家算法实例
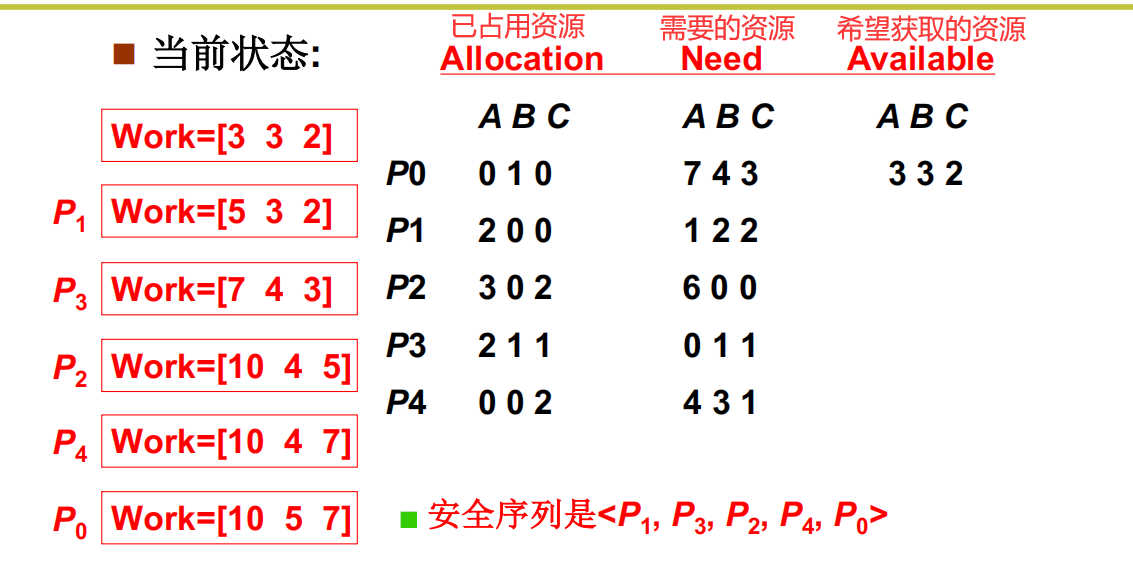
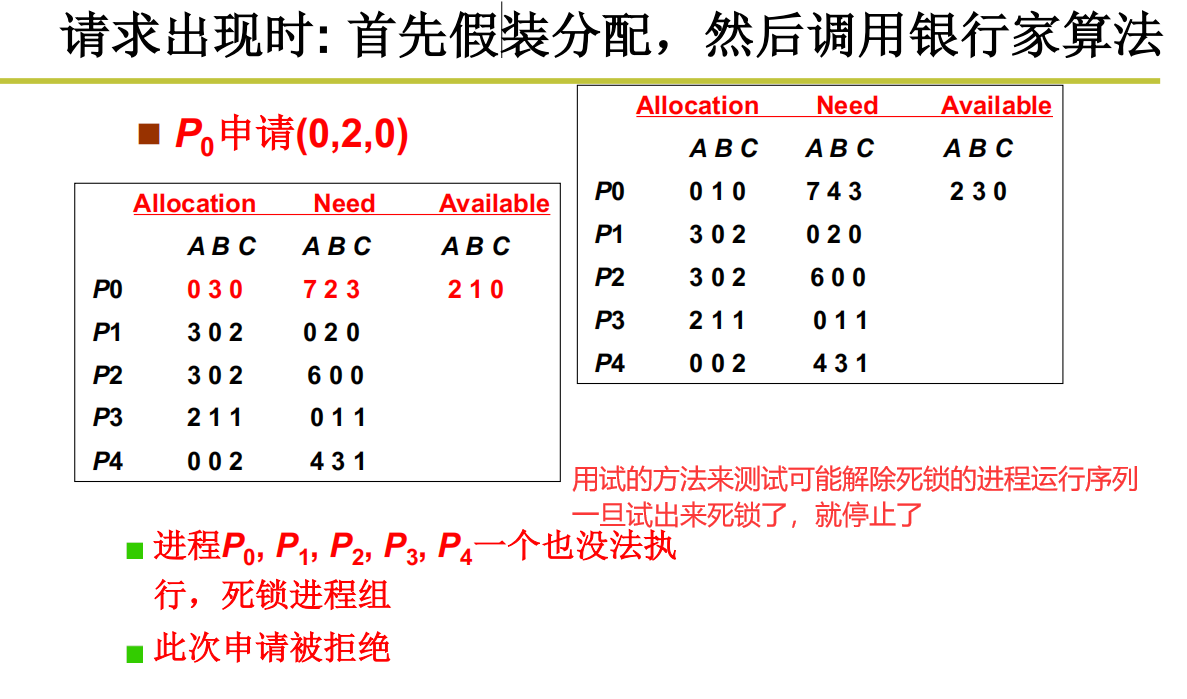
死锁检测+恢复: 发现问题再处理
一定条件下才会执行银行家算法对死锁进行处理

实际操作系统的处理
许多通用操作系统,如PC机上安装的Windows和Linux,都采用死锁忽略方法,因为相对而言这种死锁处理方式反而是性价比最高的选择。

















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









