









参考书目:Pytorch深度学习入门,作者:曾芃壹
卷积神经网络
卷积
我们把输入层看做二维的神经元,如输入的是28*28的图片则可以看做28*28的二维神经元,每个节点对应图片在这个像素点的灰度值。
在传统神经网络中,我们把输入层的每一个节点都连接到隐含层的每一个节点上,而这里我们使用一个过滤器例如5*5的一个小网格在28*28的图片上从左上角开始逐层滑动直到右下角,每次滑动的距离为一个stride称为步长,生成的隐含层称为特征图。
过滤器
过滤器是每一格都有权重的一个网格,卷积的过程就是将网格中的所有权重值分别与对应输入的那一部分相乘后进行累加之后形成特征图的一部分。但即便进行卷积的的stride为1,其生成的特征图尺寸也会缩小,由于过滤器移动到边缘的时候就结束了,导致中间的像素点相较于边缘像素点参与计算的次数要多一些丢失了边缘信息,为解决这一问题我们使用填充称为padding,在图片外围补充一些像素点并初始化为0。
通过卷积相较于全连接神经网络我们可以大大减少权重数目。实际训练中第一层的权重值会不断地被更新优化,最终反映各个方向上的边缘特征。
池化
池化的作用是降低数据的维度,实际上为向下采样。如图片尺寸是8*8,池化窗口为4*4即对特征图每4*4进行一次采样生成一个池化特征值,最终8*8的特征图可以生成一个2*2的池化特征值。实际应用中池化可以分为最大池化(Max-Pooling)和平均值池化(Mean-Pooling),最大池化即将池化窗口范围内的最大值作为池化的结果的特征值;平均值池化即取窗口范围内所有值的平均后作为池化的特征值。
实战:手写体识别
准备数据集
MNIST是一个手写数字数据库(官网地址http://yann.lecun.com/exdb/mnist/ )。该数据库有60000张训练样本和10000张测试样本,每张图像素尺寸28*28
torchvision
pytorch的图像处理工具包Torchvision里面包含了图像的预处理、加载等方法,还包括数种经过预训练的经典卷积神经网络模型。
我们从Torchvision中导入datasets加载图像数据方法和transforms图像预处理方法
需要导入的模块
import os.path
import torch
from torch import nn, optim
import torch.nn.functional as F
from torchvision import datasets, transforms
是将数据归一化处理,将数据转化为0-1之间的数,前一个参数指定mean平均值,后一个参数指定std标准差
再通过image=(image-mean)/std归一化
transform = transforms.Compose([ # 设置预处理的方式,里面依次填写预处理的方法
transforms.ToTensor(), # 将数据转换为tensor对象
transforms.Normalize((0.1307,), (0.3081,))
])
第一个参数为数据下载目标文件
train=TRUE表示加载训练数据集,False表示加载测试数据集
download代表自动下载MNIST数据集
transform表示使用我们刚才定义的数据预处理方法
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)
testset = datasets.MNIST('data', train=False, download=True, transform=transform)
构建LeNet模型
根据此图构建训练模型,函数功能代码中有详细说明
图片来源于曾芃壹的PyTorch深度学习入门

class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# C1卷积层,pytorch中conv2d简化了卷积层的构建
# 第一个参数为代表输入为一张灰度图,第二参数代表6个特征图,第三个参数为过滤器大小
self.c1 = nn.Conv2d(1, 6, (5, 5)) # (5,5)可简写为5
# C3卷积层
self.c3 = nn.Conv2d(6, 16, (5, 5))
# 全连接层定义
# F5全连接层由池化层S4的所有特征点(16*4*4)全连接到F5的120个点
self.fc1 = nn.Linear(16 * 4 * 4, 120)
# F6
self.fc2 = nn.Linear(120, 84)
# 输出层
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 池化操作
# 在c1卷积之后加一个relu激活函数增加非线性拟合能力
x = F.max_pool2d(F.relu(self.c1(x)), (2, 2)) # 2*2可以简写为2
x = F.max_pool2d(F.relu(self.c3(x)), 2)
x = x.view(-1, self.num_flat_features(x)) # 参数-1表将x的形状转换为1维的向量,num_flat_features定义在后
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
# 交叉熵计算自带了softmax函数,不用写softmax
return x
# 用于计算x的特征点的总数
def num_flat_features(self, x):
# 因为pytorch只接受批数据输入的方式,所以x是4维的,例如批量输入4张图片则为4*16*4*4
# 则我们使用size的结果为(4,16,4,4),使用[1:]返回第二维以后的形状
size = x.size()[1:]
num_features = 1
# 计算16*4*4
for s in size:
num_features *= s
return num_features
训练函数
def train(module, criterion, optimizer, epochs=1):
for epoch in range(epochs):
# loss值
running_loss = 0.0
# 从0项开始对trainloader中的数据进行枚举,返回i为序号,data中包含了训练数据和标签
for i, data in enumerate(trainloader, 0):
inputs, label = data
if CUDA:
inputs, label = inputs.cuda(), label.cuda()
optimizer.zero_grad()
outputs = module(inputs)
loss = criterion(outputs, label)
loss.backward()
optimizer.step()
running_loss += loss.item() # 取出张量的值
# 每1000次打印一次
if i % 1000 == 999:
print('[epoch:%d],Batch:%5d] Loss:%.3f' % (epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
print('Finished Training')
模型保存、读取和测试功能函数
load_param中os.path判断当前文件夹下是否有该文件
关于torch中save与load解释在后面
def load_param(model, path):
if os.path.exists(path):
model.load_state_dict(torch.load(path))
def save_param(model, path):
torch.save(model.state_dict(), path)
def model_test(testloader, model):
correct = 0
total = 0
for data in testloader:
images, labels = data
if CUDA:
images = images.cuda()
labels = labels.cuda()
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy:%d%%' % (100 * correct / total))
训练前准备、数据加载、模型保存的运行代码
# 没有这一行则多线程加载数据会报错
if __name__ == '__main__':
CUDA = torch.cuda.is_available()
if CUDA:
lenet = LeNet().cuda()
else:
lenet = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(lenet.parameters(), lr=0.001, momentum=0.9)
'''
说明引入momentum参数后,采用如下公式:
v = mu * v - learning_rate * dw
w = w + v
可以起到加速训练的效果
'''
# 加载训练数据
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
'''
batch_size代表一次性加载的数据量,shuffle表示遍历不同批次的数据时打乱顺序,num_works表示使用两个子进程加载数据
'''
train(lenet, criterion, optimizer, epochs=2)
# 保存模型,缺点占用空间大
# torch.save(lenet, 'model.pkl')
# 只保存模型的参数
torch.save(lenet.state_dict(), 'model_weight.pkl')
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
load_param(lenet, 'model_weight.pkl')
model_test(testloader, lenet)
[epoch:1],Batch: 1000] Loss:1.421
[epoch:1],Batch: 2000] Loss:0.330
[epoch:1],Batch: 3000] Loss:0.200
[epoch:1],Batch: 4000] Loss:0.170
[epoch:1],Batch: 5000] Loss:0.149
[epoch:1],Batch: 6000] Loss:0.124
[epoch:1],Batch: 7000] Loss:0.096
[epoch:1],Batch: 8000] Loss:0.101
[epoch:1],Batch: 9000] Loss:0.095
[epoch:1],Batch:10000] Loss:0.103
[epoch:1],Batch:11000] Loss:0.084
[epoch:1],Batch:12000] Loss:0.084
[epoch:1],Batch:13000] Loss:0.078
[epoch:1],Batch:14000] Loss:0.077
[epoch:1],Batch:15000] Loss:0.084
[epoch:2],Batch: 1000] Loss:0.062
[epoch:2],Batch: 2000] Loss:0.056
[epoch:2],Batch: 3000] Loss:0.059
[epoch:2],Batch: 4000] Loss:0.070
[epoch:2],Batch: 5000] Loss:0.060
[epoch:2],Batch: 6000] Loss:0.056
[epoch:2],Batch: 7000] Loss:0.056
[epoch:2],Batch: 8000] Loss:0.059
[epoch:2],Batch: 9000] Loss:0.057
[epoch:2],Batch:10000] Loss:0.063
[epoch:2],Batch:11000] Loss:0.042
[epoch:2],Batch:12000] Loss:0.052
[epoch:2],Batch:13000] Loss:0.037
[epoch:2],Batch:14000] Loss:0.065
[epoch:2],Batch:15000] Loss:0.063
Finished Training
Accuracy:98%
训练结束,该模型准确率有98%
卷积数学表达
将全连接看做二维的东西(把一列变成一个矩阵): 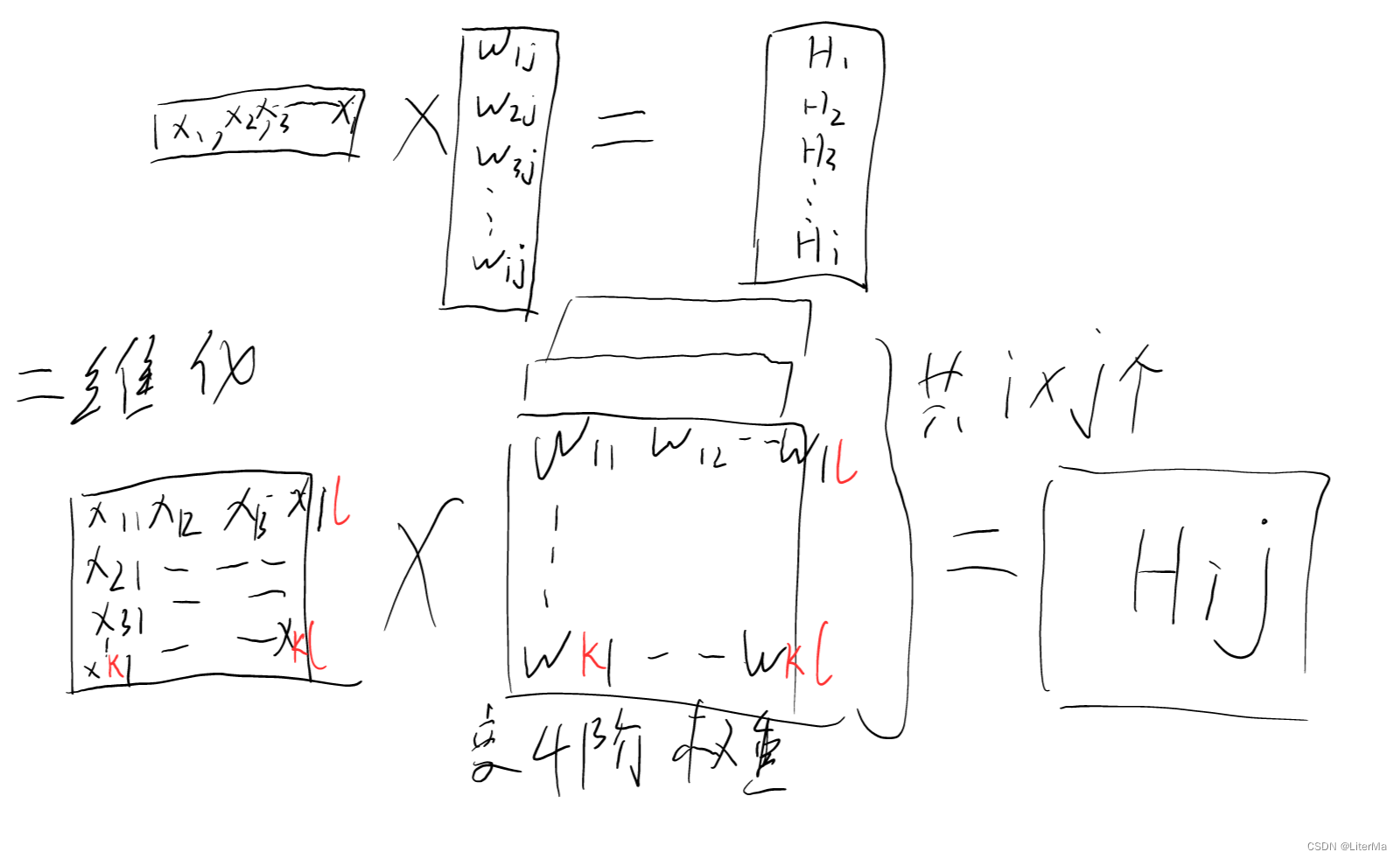
输入为
X
i
,
j
X_{i,j}
Xi,j,隐藏层为
W
i
,
j
W_{i,j}
Wi,j,输出为
H
i
,
j
H_{i,j}
Hi,j,则可以得出全连接表达式为:
H
i
,
j
=
∑
k
∑
l
W
i
,
j
,
k
,
l
X
k
,
l
H_{i,j}=\sum_{k}\sum_{l}{W_{i,j,k,l}}X_{k,l}
Hi,j=k∑l∑Wi,j,k,lXk,l
对
X
k
,
l
X_{k,l}
Xk,l,因为
k
,
l
k,l
k,l与
i
,
j
i,j
i,j有对应位置关系可以使用
k
=
i
+
a
,
l
=
j
+
b
k=i+a,l=j+b
k=i+a,l=j+b来进行替换为
X
i
+
a
,
j
+
b
X_{i+a,j+b}
Xi+a,j+b
W
i
,
j
,
k
,
l
W_{i,j,k,l}
Wi,j,k,l进行重新索引替换为
V
i
,
j
,
a
,
b
V_{i,j,a,b}
Vi,j,a,b则全连接公式可以写为:
H
i
,
j
=
∑
a
∑
b
V
i
,
j
,
a
,
b
X
i
+
a
,
j
+
b
H_{i,j}=\sum_a\sum_b V_{i,j,a,b}X_{i+a,j+b}
Hi,j=a∑b∑Vi,j,a,bXi+a,j+b
图像识别需要有不变性和局部性:
不变性:以
V
V
V作为卷积核的参数值不应该改变,即不受
i
,
j
i,j
i,j的影响,是shared weights。
局部性:卷积核
V
V
V应该聚焦于某一范围,所以
∣
a
∣
>
Δ
|a|>\Delta
∣a∣>Δ或
∣
b
∣
>
Δ
|b|>\Delta
∣b∣>Δ时,
V
a
,
b
V_{a,b}
Va,b应该为0。
综上卷积公式为:
H
i
,
j
=
∑
a
=
−
Δ
Δ
∑
b
=
−
Δ
Δ
V
a
,
b
X
i
+
a
,
j
+
b
H_{i,j}=\sum_{a=-\Delta}^\Delta\sum_{b=-\Delta}^\Delta V_{a,b}X_{i+a,j+b}
Hi,j=a=−Δ∑Δb=−Δ∑ΔVa,bXi+a,j+b
所以卷积层可以理解为:多个参数相同的神经元且参数个数和神经元个数
取决于
Δ
\Delta
Δ的特殊全连接层,最后将输出排列叠加为一个特征图,特征图的大小取决于
Δ
\Delta
Δ。















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









