







一、ES核心概念
1)Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为节点。
3)Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5)全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
二、基本概念
2.1、文档(Document)
-
我们知道Java是面向对象的,而Elasticsearch是面向文档的,也就是说文档是所有可搜索数据的最小单元。ES的文档就像MySql中的一条记录,只是ES的文档会被序列化成json格式,保存在Elasticsearch中;
-
这个json对象是由字段组成,字段就相当于Mysql的列,每个字段都有自己的类型(字符串、数值、布尔、二进制、日期范围类型);
-
当我们创建文档时,如果不指定字段的类型,Elasticsearch会帮我们自动匹配类型;
-
每个文档都有一个ID,类似MySql的主键,咱们可以自己指定,也可以让Elasticsearch自动生成;
-
文档的json格式支持数组/嵌套,在一个索引(数据库)或类型(表)里面,你可以存储任意多的文档。
注意:虽然在实际存储上,文档存在于某个索引里,但是文档必须被赋予一个索引下的类型才可以。
2.2、类型(Type)
类型就相当于MySql里的表,我们知道MySql里一个库下可以有很多表,最原始的时候ES也是这样,一个索引下可以有很多类型,但是从6.0版本开始,type已经被逐渐废弃,但是这时候一个索引仍然可以设置多个类型,一直到7.0版本开始,一个索引就只能创建一个类型了(_doc)。这一点,大家要注意,网上很多资料都是旧版本的,没有对这点进行说明。
2.3、索引(Index)
- 索引就相当于MySql里的数据库,它是具有某种相似特性的文档集合。反过来说不同特性的文档一般都放在不同的索引里;
- 索引的名称必须全部是小写;
- 在单个集群中,可以定义任意多个索引;
- 索引具有mapping和setting的概念,mapping用来定义文档字段的类型,setting用来定义不同数据的分布。
2.4、节点(node)
- 一个节点就是一个ES实例,其实本质上就是一个java进程;
- 节点的名称可以通过配置文件配置,或者在启动的时候使用
-E node.name=ropledata指定,默认是随机分配的。建议咱们自己指定,因为节点名称对于管理目的很重要,咱们可以通过节点名称确定网络中的哪些服务器对应于ES集群中的哪些节点; - ES的节点类型主要分为如下几种:
- Master Eligible节点:每个节点启动后,默认就是Master Eligible节点,可以通过设置
node.master: false来禁止。Master Eligible可以参加选主流程,并成为Master节点(当第一个节点启动后,它会将自己选为Master节点);注意:每个节点都保存了集群的状态,只有Master节点才能修改集群的状态信息。 - Data节点:可以保存数据的节点。主要负责保存分片数据,利于数据扩展。
- Coordinating 节点:负责接收客户端请求,将请求发送到合适的节点,最终把结果汇集到一起
- Master Eligible节点:每个节点启动后,默认就是Master Eligible节点,可以通过设置
注意:每个节点默认都起到了Coordinating node的职责。一般在开发环境中一个节点可以承担多个角色,但是在生产环境中,还是设置单一的角色比较好,因为有助于提高性能。
2.5、分片(shard)
了解分布式或者学过mysql分库分表的应该对分片的概念比较熟悉,ES里面的索引可能存储大量数据,这些数据可能会超出单个节点的硬件限制。
为了解决这个问题,ES提供了将索引细分为多个碎片的功能,这就是分片。这里咱们可以简单去理解,在创建索引时,只需要咱们定义所需的碎片数量就可以了,其实每个分片都可以看作是一个完全功能性和独立的索引,可以托管在集群中的任何节点上。
疑问:分片有什么好处和注意事项呢?通过分片技术,咱们可以水平拆分数据量,同时它还支持跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量;
ES可以完全自动管理分片的分配和文档的聚合来完成搜索请求,并且对用户完全透明;
主分片数在索引创建时指定,后续只能通过Reindex修改,但是较麻烦,一般不进行修改。
2.6、副本分片(replica shard)
熟悉分布式的朋友应该对副本对概念不陌生,为了实现高可用、遇到问题时实现分片的故障转移机制,ElasticSearch允许将索引分片的一个或多个复制成所谓的副本分片。
疑问:副本分片有什么作用和注意事项呢?当分片或者节点发生故障时提供高可用性。因此,需要注意的是,副本分片永远不会分配到复制它的原始或主分片所在的节点上;
可以提高扩展搜索量和吞吐量,因为ES允许在所有副本上并行执行搜索;
默认情况下,ES中的每个索引都分配5个主分片,并为每个主分片分配1个副本分片。主分片在创建索引时指定,不能修改,副本分片可以修改。
三、与mysql区别
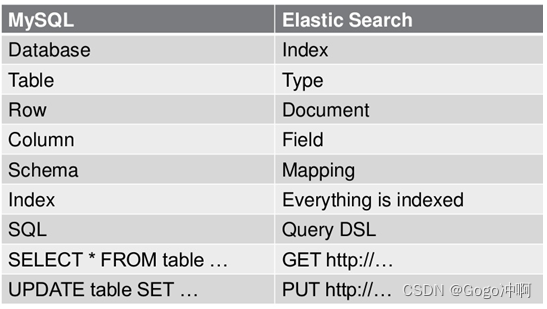
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
四、ELK是什么?
ELK=elasticsearch+Logstash+kibana
- elasticsearch:后台分布式存储以及全文检索
- logstash: 日志加工、“搬运工”
- kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
五、ES特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
六、项目中应用
1、定义好接口(IUserAnalysisService)
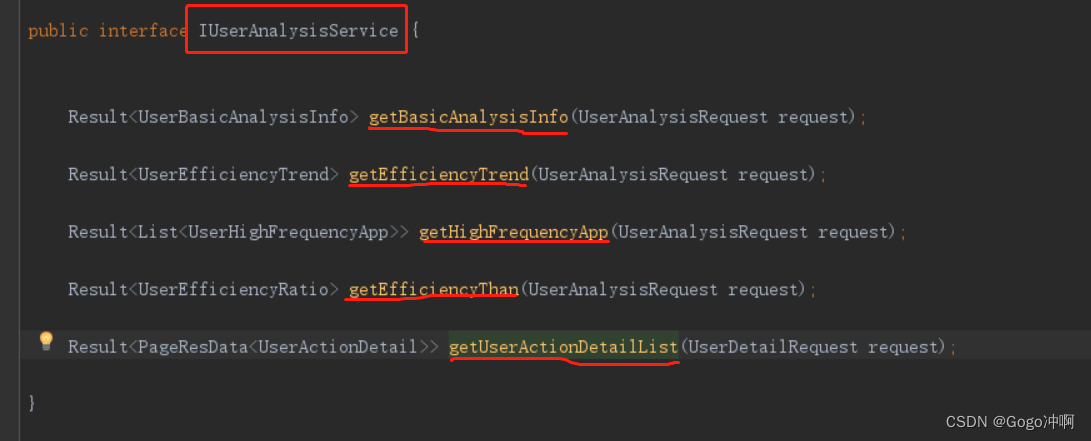
接口里面定义好5种方法:
getBasicAnalysisInfo: 获取基本的效率分析信息getEfficiencyTrend:获取趋势曲线图getHighFrequencyApp:获取高频使用APPgetEfficiencyThan:获取有效无效工作时间占比getUserActionDetailList:获取用户点击详情
上面五种方法都需要通过UserDetailRequest来获取参数。(通过前端post请求里面的请求体传入查询所需要的信息)
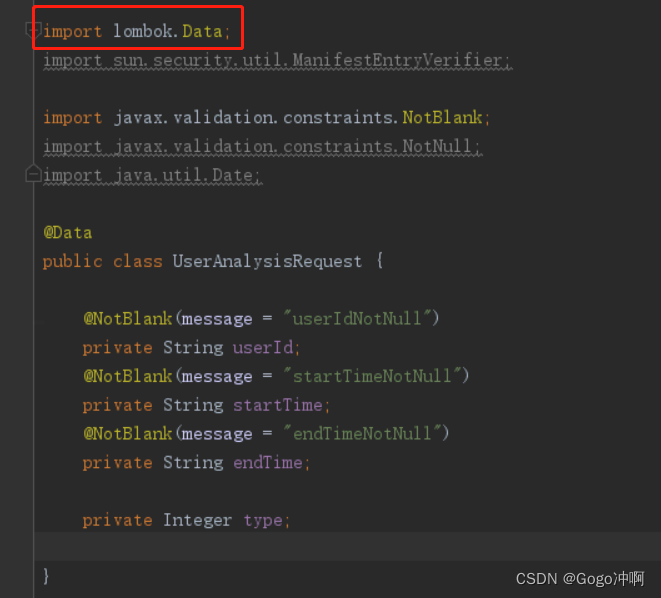
UserDetailReques
通过Lombok来自动生成getter、setter方法(getUserId、setUserId、getStartTime。。。)
2、创建实现类实现IUserAnalysisService接口(UserAnalysisServiceImpl)
2.1 注入的属性
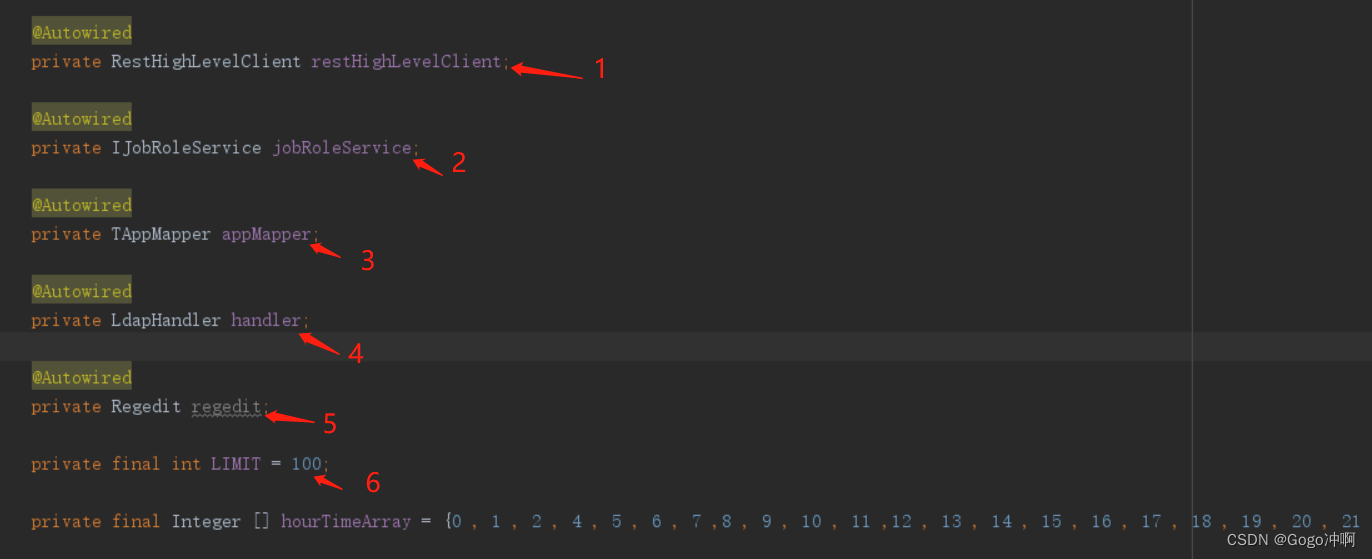
1)RestHighLevelClient:RestHighLevelClient的API作为ElasticSearch备受推荐的客户端组件,其封装系统操作ES的方法,包括索引结构管理,数据增删改查管理,常用查询方法,并且可以结合原生ES查询原生语法,功能十分强大。(项目里主要用到search方法来做查询)
2)IJobRoleService:
里面定义了两个方法:
- getUserJobAndAppInfo:通过UserId获取用户的工作属性(研发、运维。。)和以及使用的APP。
- getUserJobAndAppList:通过传入多个用户的ID来获取用户的工作属性(研发、运维。。)和以及使用的APP。
3)TAppMapper:APP集合及其属性(有效APP、无效APP)。
4)LdapHandler:LDAP(Light Directory Access Portocol),它是基于X.500标准的轻量级目录访问协议。目录是一个为查询、浏览和搜索而优化的数据库,它成树状结构组织数据,类似文件目录一样。
5)Regedit:暂不确定。。。
6)Limit=100:限制访问数据为100条。
2.2 返回值(自己定义好的Result方法)
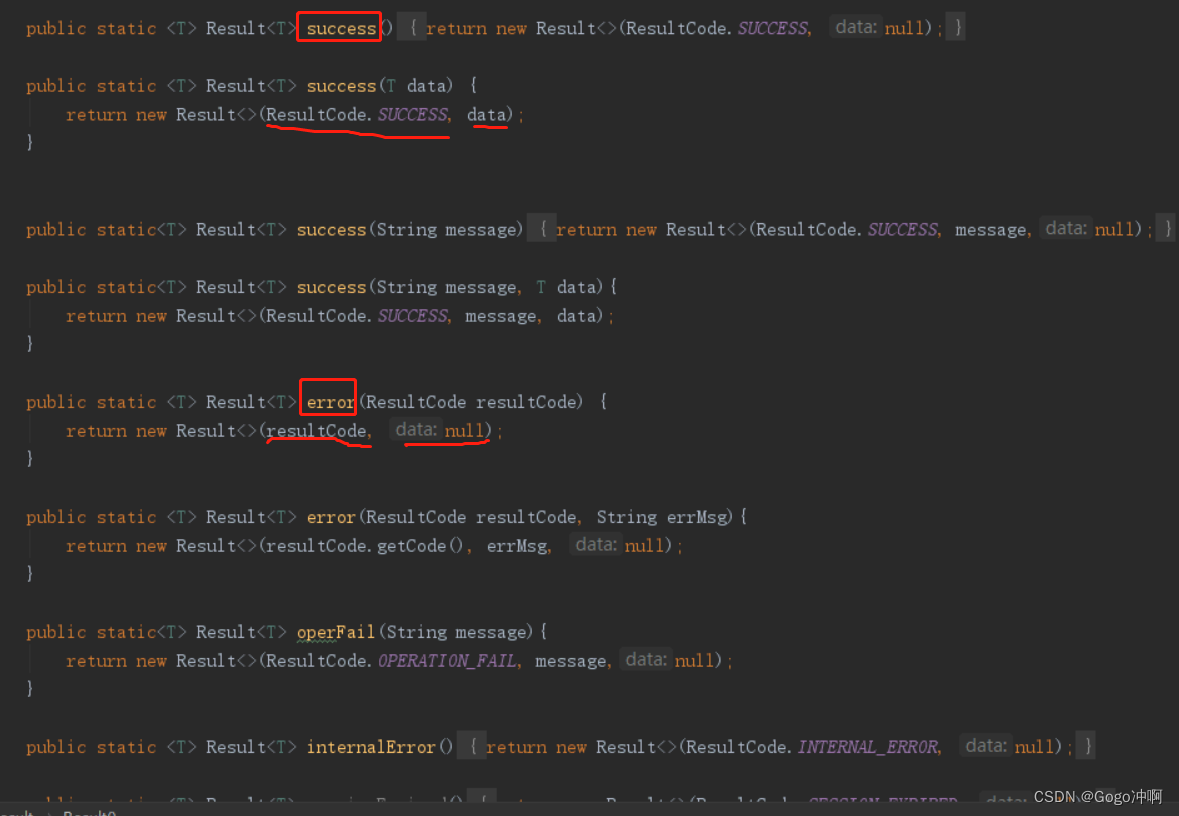
返回具体的成功\失败状态码以及需要返回的具体信息(basicAnalysis中用户的有效工作时间、无效工作时间等等)
2.3 具体API及代码逻辑
2.3.1、基本工具类

1)UserBasicAnalysisInfo:存储用户效率分析的基本信息
具体属性有:
rating:效率评级ratingTime:效率评级标准时间averageOfDay:日均工作时间attendanceDay:出勤天数averageOperationOfDay:日均操作时长idlePercent:空闲时间占比
2)SearchRequest:SearchRequest用于与搜索文档、聚合、定制查询有关的任何操作,还提供了在查询结果的基于上,对于匹配的关键词进行突出显示的方法。(搜索请求对象)
3)BoolQueryBuilder:
1,qb.must(QueryBuilder queryBuilder); //返回的文档必须满足must子句的条件,并且参与计算分值
2,qb.mustNot(QueryBuilder queryBuilder) //返回的文档必须不满足定义的条件
3,qb.should(QueryBuilder queryBuilder))
//返回的文档可能满足should子句的条件.在一个bool查询中,如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回.minimum_should_match参数定义了至少满足几个子句.
4,qb.filter(QueryBuilder queryBuilder))
//返回的文档必须满足filter子句的条件,但是不会像must一样,参与计算分值
4)SearchSourceBuilder:搜索源构建对象
5)attendanceDaySet:存储用户出勤日期
2.3.2、获取用户产生的事件会话
1)通过自己定义的pagehandler根据相对应的条件来获取用户产生的事件,再通过一个List把活动记录索引记录起来。(ActionIndex是记录用户相关信息,如:用户ID、当前会话开始时间与结束时间等)

pageHandle部分代码:
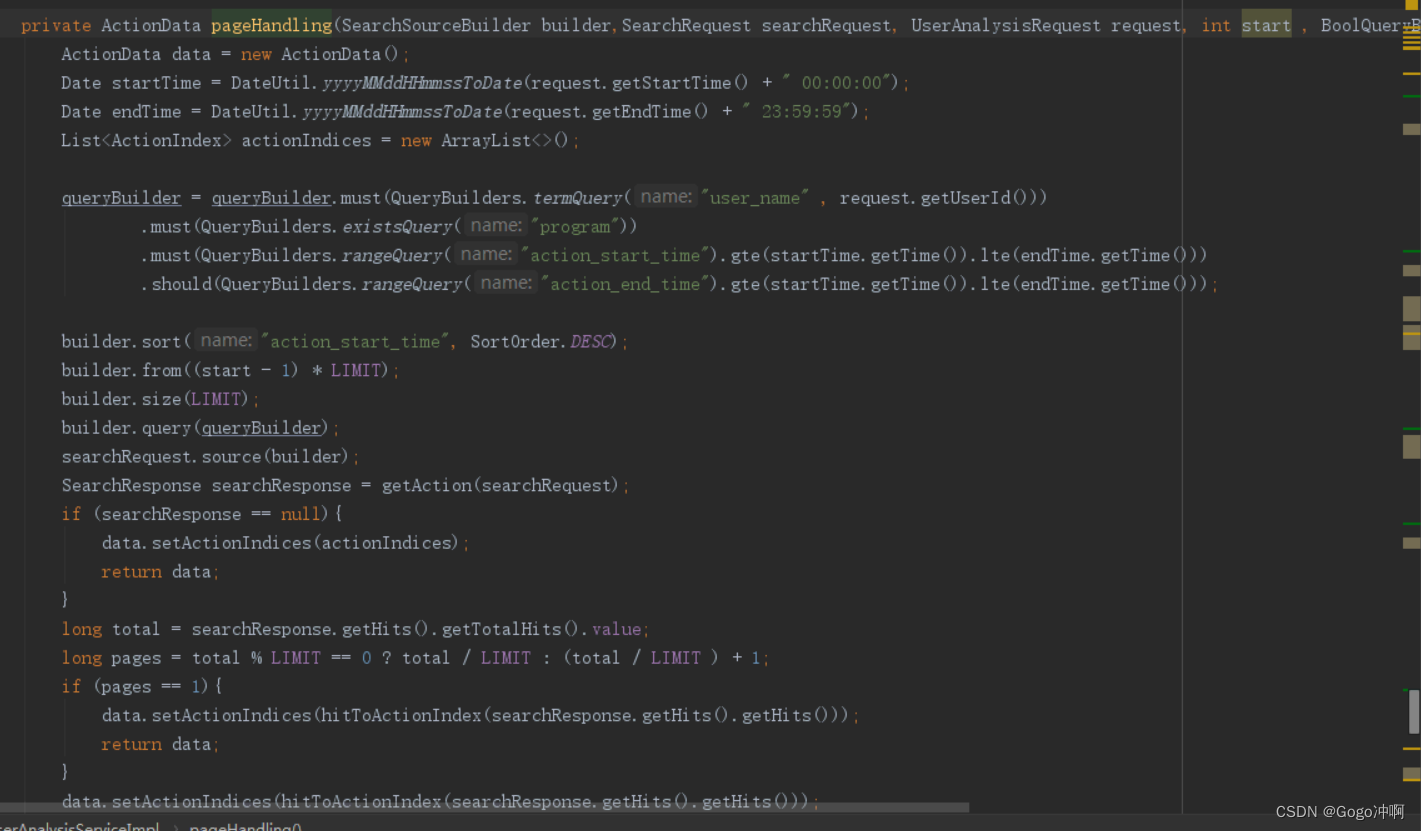
2)通过自己定义的findBetweenDay()筛掉时间范围外的出勤日期。

2.3.3、计算用户出勤日期、日军工作时长和日均有效工作时长
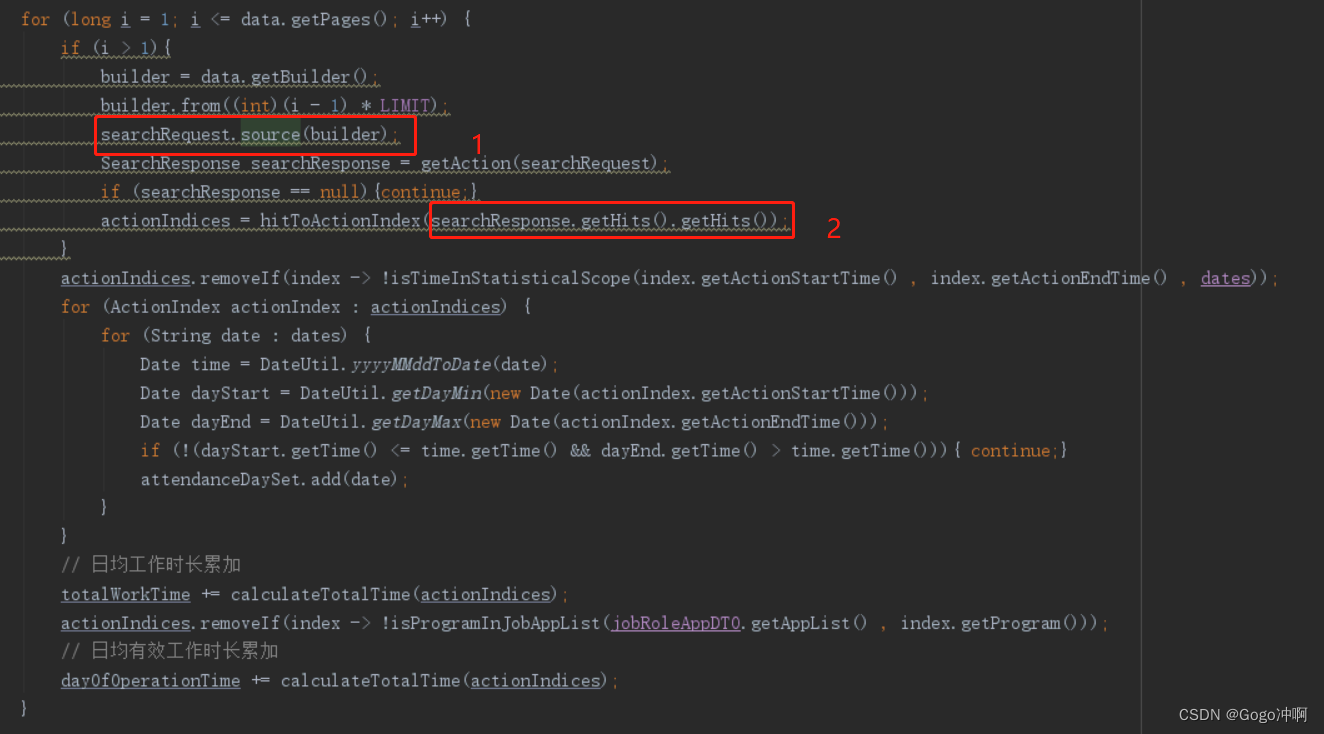
1)searchRequest.source(builder):向搜索请求对象中设置搜索源
2)searchResponse.getHits():获取搜索结果并封装到actionIndices中。(每个Index索引就是用户的一次操作记录)
2.3.4、计算前端需要的有关数据
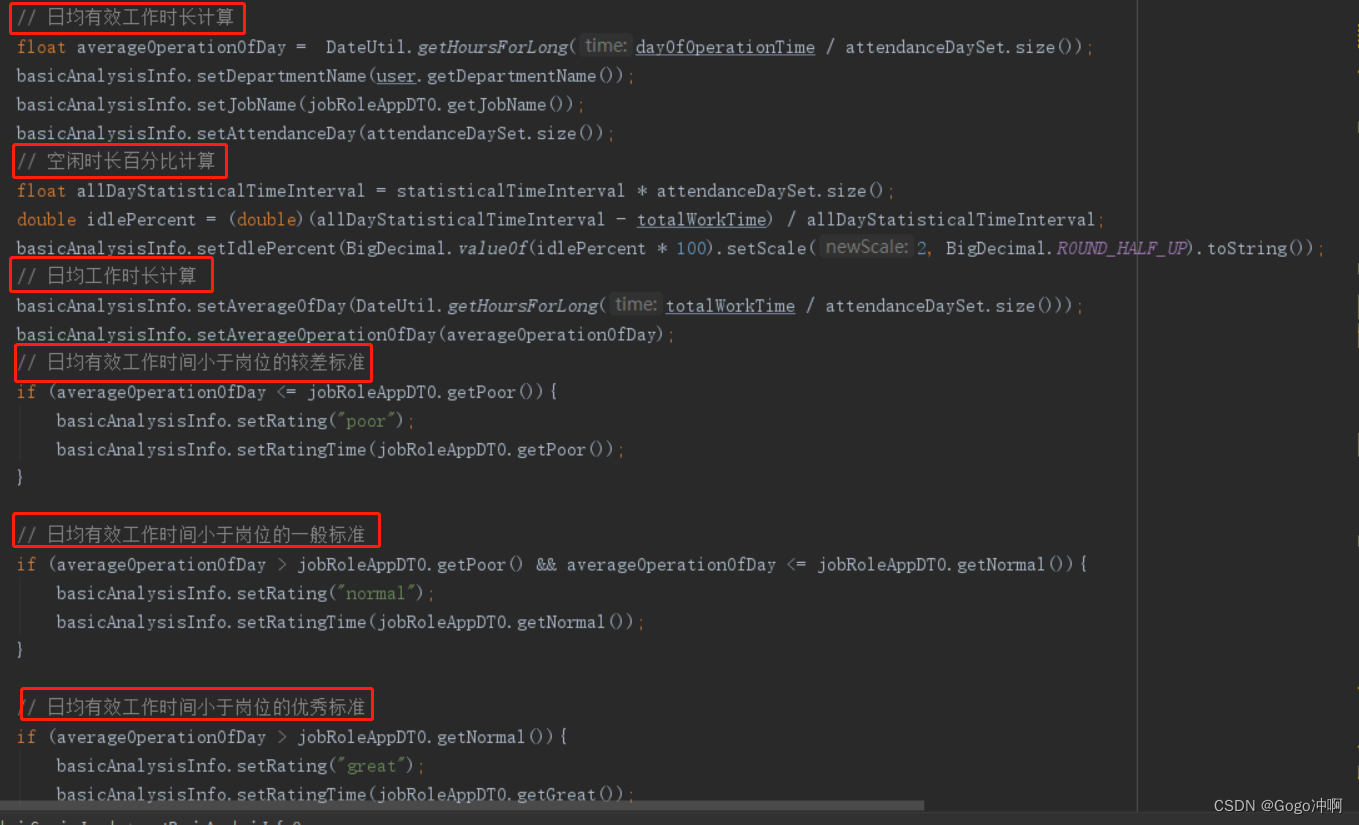
ES相关类及其继承关系
QueryBuilders类里面封装有不同的具体查询方法(组合查询、范围查询等)
















 2552
2552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









