






1、死信队列
死信队列(ex - routing - queue)又称之为”延迟队列“或者”延时队列”,也是RabbitMQ队列的一种,指的是进入队列的消息会被延迟消费的队列,这种队列根普通的队列相比,最大的差异在于消息一旦进入普通队列将会立即被消费处理,而进入死信队列则会过一定的时间在被消费处理。
在传统企业级的应用系统中实现消息,业务数据的延迟处理一般是通过开启定时器的方式,轮询扫描并获取数据表中满足条件的业务数据记录,比较数据记录的业务时间和当前时间,如果当前时间大于记录中的业务时间,则说明数据记录已经超过了指定的时间而未被处理,此时需要执行相应的业务逻辑,比如:失效该数据记录,发送通知信息给指定用户等。
这种处理方式中,定时器每隔一定的时间不间断地去扫描数据库表,并不断地获取满足业务条件的数据,直到手动关闭定时器,如果不关闭,定时器开启的线程会一直执行下去。
使用定时器问题:
1、如果数据量不大,这个是没问题。如果你数据量大的离谱比如:上百万,上千万那么可能直接你程序全部夯住,你cpu和内存全部会耗尽,处于假死状态,甚至jvm直接出现栈异常java
space或者oom对异常。2、数据链接也可能会被耗尽,一直得不的释放,网站全部瘫痪,数据可能会上锁。
3、假设你数据量不大,但是这种定时器,时间问题其实是一个问题的,太短:消耗性能 ,太长:体验不好不及时。
4、如果你项目是集群部署,定时器就会多个,定时器你没办法控制别的的顺序执行
- 分布式定时器
- 分布式锁(牵涉到save)
5、能不用就尽量不用使用。(eureka + nacos 就是定时器 + 多线程 = 心跳机制)
2、业务流程
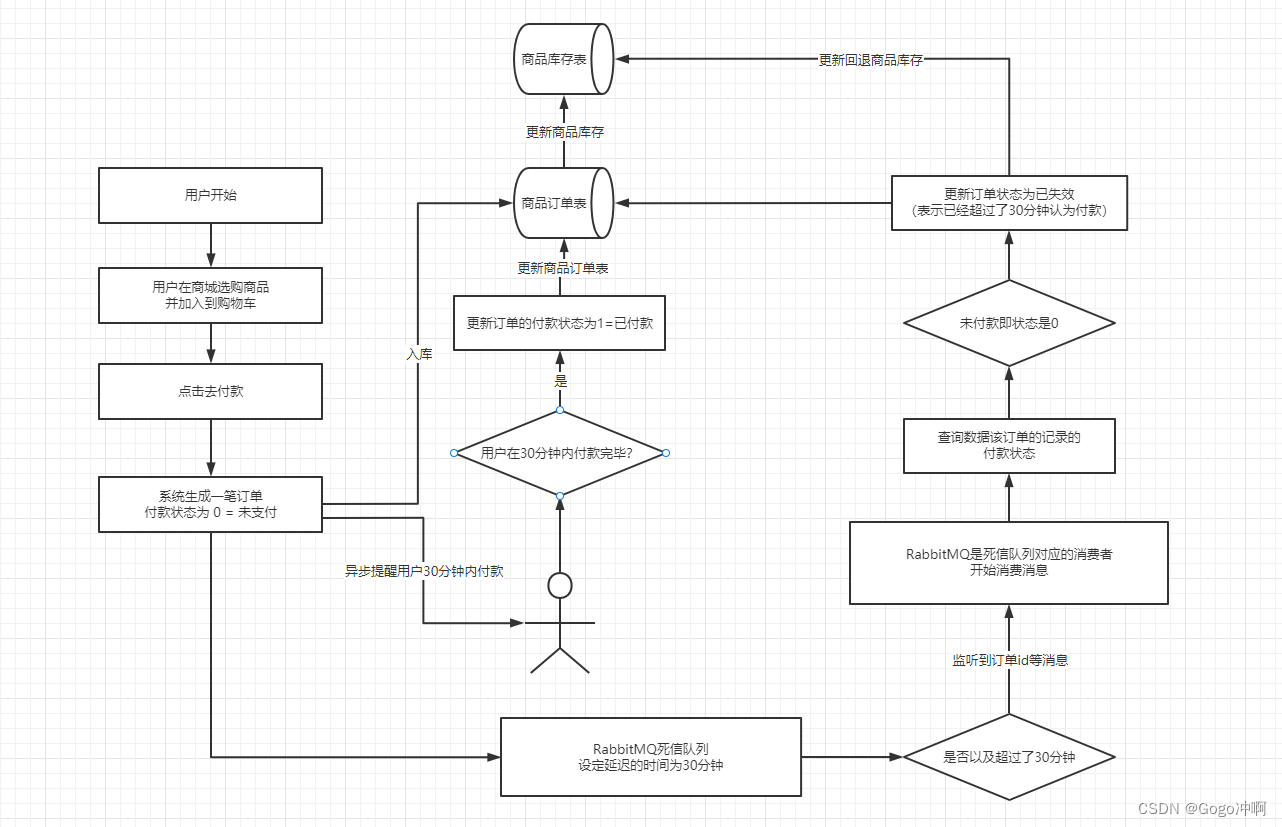
和抢票一样,在一些电商或者有支付的场景中,也会存在这种类似的情况。用户在选购商品后点击“去付款”后,商城将会引导用户跳转到支付页面,此时系统会为用户生成一笔对应购物车中商品的订单,并将该订单的付款状态设置为0。即代表未付款,同时该订单id或者订单编号加入RabbitMQ的死信队列中,并设置延迟时间为30分钟。
如果用户在30分钟内选择了某种付款方式进行付款,则系统将更新该订单ID对应的订单的付款状态为1,即已付款状态。同时在商品表的库存表中更新订单中所包含的商品对应的库存,
如果用在30分钟内未付款,则RabbitMQ的死信队列对应的消费者将会在30分钟后监听到该订单id或编号,根据订单id或编号查询数据库的商品订单表,如果该订单的付款状态仍然为0,即未付款,则表示用户在30分钟内仍然未付款,此时需要失效该笔订单,同时更新回退商品库存,这以业务场景的整体流程如下图所示:
死信队列的专有术语和词汇
与普通的队列相比,死信队列同样具有三个核心成员:
- 交换机
- 路由
- 队列
只不过死信队列,增加了另外三个成员即:
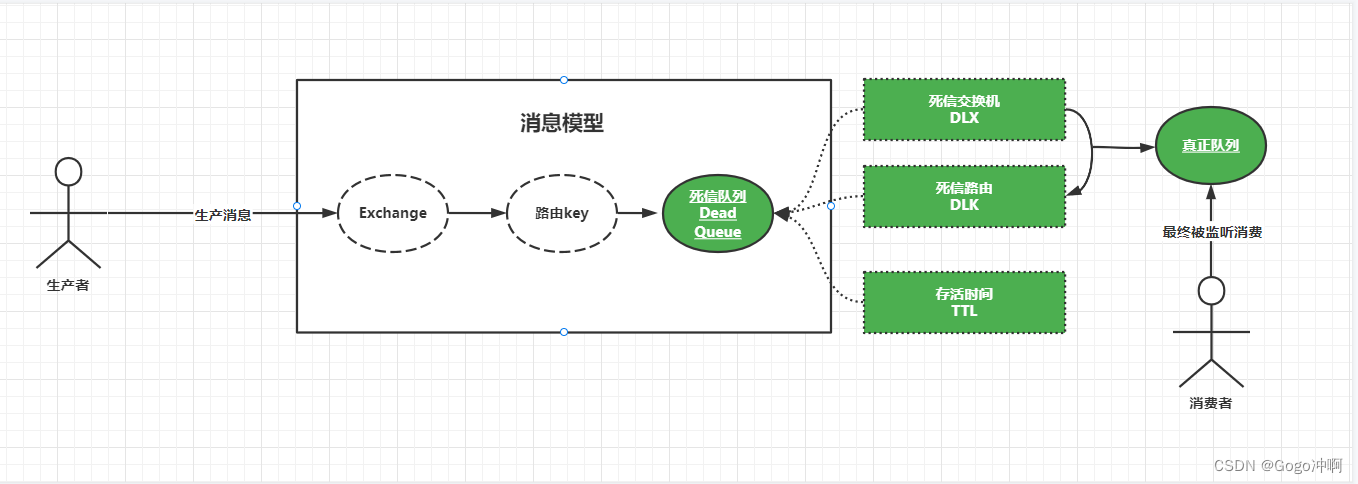
- DLX:死信交换机:即Dead -Letter-Exchange。是一种特殊的交换机。
- DLK:死信路由:即Dead-Letter-Routing-Key。主要和DLX一起使用,
- TTL:存活时间,即Time-To-Live,指的是进入死信队列的消息可以存活的时间,一旦达到TTL,讲以为这该消息“死了”,从而进入下一个中转站,等待被正在的消息队列监听消费。
什么样子的消息会进入死信DLX —死信队列 —DLX–DLK
- 消息被拒绝,比如通过调用basic.reject或者basic.nack方法的时候,会进入到死信中,并且不在重新投递,即requeue参数的取值是false.
- 消息超过指定的存活时间(比如通过调用messageProperties.setExpiration()设置消息的TTL时间即可实现)。
- 队列达到最大长度。
当发生上述的情况时,将会出现死信的情况,而之后的消费讲被重新投递到另一个交换机,此时该交换机就是死信队列交换机。由于该死信队列交换机和死信路由绑定在一起对应真正的队列。导致消息讲被分发到真正的队列。最终被该队列对应的消费者所监听消费,简单说:就是没有被死信队列消费的消息,讲换个地方重新被消费从而实现消息:“延迟”,“延时”消费,而这个地方就是消息的下一个中转站,即死信交换机。















 2932
2932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









