







目录
Preface
typedef long long LL;
typedef double D;
typedef short int SI;
哈希表
2260. 必须拿起的最小连续卡牌数
给你一个整数数组 cards ,其中 cards[i] 表示第 i 张卡牌的 值 。如果两张卡牌的值相同,则认为这一对卡牌 匹配 。
返回你必须拿起的最小连续卡牌数,以使在拿起的卡牌中有一对匹配的卡牌。如果无法得到一对匹配的卡牌,返回 -1 。
示例 1:
输入:cards = [3,4,2,3,4,7]
输出:4
解释:拿起卡牌 [3,4,2,3] 将会包含一对值为 3 的匹配卡牌。注意,拿起 [4,2,3,4] 也是最优方案。
示例 2:
输入:cards = [1,0,5,3]
输出:-1
解释:无法找出含一对匹配卡牌的一组连续卡牌。
提示:
1 <= cards.length <= 105
0 <= cards[i] <= 106
最开始的方法:滑动窗口
两个循环
满足条件前r++,
满足条件后l++
优化后的方法,数组哈希
哈希表每次存当前的坐标,当发现该位置已经填入坐标时,更新ans
fill(mem, mem+1000001, -1);fill方法,用于填充数组。
int minimumCardPickup(vector<int>& cards) {
int mem[1000001] = {};
fill(mem, mem+1000001, -1);
int l = 0, r = 0, n = cards.size(), ans = 1e5 + 1;
while (r < n) {
if (mem[cards[r]]==-1) {
mem[cards[r]] = r;
}
else {
l = mem[cards[r]];
ans = min(ans, r - l + 1);
mem[cards[l]] = r;
}
r++;
}
return ans == 1e5 + 1 ? -1 : ans;
}
时间复杂度:O(n)
剑指 Offer II 030. 插入、删除和随机访问都是 O(1) 的容器
设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构:
insert(val):当元素 val 不存在时返回 true ,并向集合中插入该项,否则返回 false 。
remove(val):当元素 val 存在时返回 true ,并从集合中移除该项,否则返回 false 。
getRandom:随机返回现有集合中的一项。每个元素应该有 相同的概率 被返回。
示例 :
输入: inputs = ["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"]
[[], [1], [2], [2], [], [1], [2], []]
输出: [null, true, false, true, 2, true, false, 2]
解释:
RandomizedSet randomSet = new RandomizedSet(); // 初始化一个空的集合
randomSet.insert(1); // 向集合中插入 1 , 返回 true 表示 1 被成功地插入
randomSet.remove(2); // 返回 false,表示集合中不存在 2
randomSet.insert(2); // 向集合中插入 2 返回 true ,集合现在包含 [1,2]
randomSet.getRandom(); // getRandom 应随机返回 1 或 2
randomSet.remove(1); // 从集合中移除 1 返回 true 。集合现在包含 [2]
randomSet.insert(2); // 2 已在集合中,所以返回 false
randomSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2
提示:
-231 <= val <= 231 - 1
最多进行 2 * 105 次 insert , remove 和 getRandom 方法调用
当调用 getRandom 方法时,集合中至少有一个元素
哈希表+变长数组
- 变长数组可以在 O(1) 的时间内完成随机访问元素操作,但是由于无法在 O(1) 的时间内判断元素是否存在,因此不能在 O(1) 的时间内完成插入和删除操作。
- 哈希表可以在 O(1) 的时间内完成插入和删除操作,但是由于无法根据下标定位到特定元素,因此不能在 O(1) 的时间内完成随机访问元素操作。
为了满足插入、删除和随机访问元素操作的时间复杂度都是 O(1),需要将变长数组和哈希表结合,变长数组中存储元素,哈希表中存储每个元素在变长数组中的下标。
class RandomizedSet {
public:
RandomizedSet() {
srand((unsigned)time(NULL));
}
bool insert(int val) {
if (indices.count(val)) {
return false;
}
int index = nums.size(); // 即将开辟新的空间的位置
nums.emplace_back(val);
indices[val] = index;
return true;
}
bool remove(int val) {
if (!indices.count(val)) {
return false;
}
int index = indices[val]; // val的索引
int last = nums.back(); // 最后位置的值
nums[index] = last; // 把 最后位置的值 放进 删除值的位置
indices[last] = index; // 更新最后位置的值的索引
nums.pop_back(); // 删除最后一个值
indices.erase(val); // 删除val索引
return true;
}
int getRandom() {
int randomIndex = rand() % nums.size();
return nums[randomIndex];
}
private:
vector<int> nums;
unordered_map<int, int> indices;
};
复杂度分析
-
时间复杂度:初始化和各项操作的时间复杂度都是 O(1) 。
-
空间复杂度:O(n) ,其中 n 是集合中的元素个数。存储元素的数组和哈希表需要 O(n) 的空间。
剑指 Offer II 033. 变位词组
给定一个字符串数组 strs ,将 变位词 组合在一起。 可以按任意顺序返回结果列表。
注意:若两个字符串中每个字符出现的次数都相同,则称它们互为变位词。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
提示:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] 仅包含小写字母
我的方法:数组哈希映射+暴力
vector<vector<string>> groupAnagrams(vector<string>& strs) {
int n = strs.size();
vector<bool> vis(n);
vector<vector<string>> ans;
for (int i = 0; i < n; ++i) {
if (vis[i]) continue;
int mp[26] = {};
for (char c : strs[i]) {
mp[c - 'a']++;
}
ans.push_back(vector<string>());
ans.back().push_back(strs[i]);
vis[i] = true;
for (int j = i + 1; j < n; ++j) {
if (vis[j] || strs[i].size() != strs[j].size()) continue;
int tmp[26] = {};
bool flag = true;
for (auto c : strs[j]) {
tmp[c - 'a']++;
if (tmp[c - 'a'] > mp[c - 'a']) flag = false;
}
if (flag) {
ans.back().push_back(strs[j]);
vis[j] = true;
}
}
}
return ans;
}
复杂度:
时间:
O
(
n
2
m
)
O(n^2m)
O(n2m)
空间:除了返回的ans,其他只用了O(n)的vis数组
方法一:排序
由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。
自己想不出线性映射关系,就直接用哈希表,不要浪费时间
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> mp;
for (string& str: strs) {
string key = str;
sort(key.begin(), key.end());
mp[key].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
复杂度分析
- 时间复杂度: O ( n k log k ) O(nk \log k) O(nklogk),其中 n 是 strs \textit{strs} strs 中的字符串的数量,k 是 strs \textit{strs} strs 中的字符串的的最大长度。需要遍历 n 个字符串,对于每个字符串,需要 O ( k log k ) O(k \log k) O(klogk)的时间进行排序以及 O ( 1 ) O(1) O(1) 的时间更新哈希表,因此总时间复杂度是 O ( n k log k ) O(nk \log k) O(nklogk)。
- 空间复杂度: O ( n k ) O(nk) O(nk),其中 n 是 strs \textit{strs} strs 中的字符串的数量, k 是 strs \textit{strs} strs 中的字符串的的最大长度。需要用哈希表存储全部字符串。
剑指 Offer II 034. 外星语言是否排序
某种外星语也使用英文小写字母,但可能顺序 order 不同。字母表的顺序(order)是一些小写字母的排列。
给定一组用外星语书写的单词 words,以及其字母表的顺序 order,只有当给定的单词在这种外星语中按字典序排列时,返回 true;否则,返回 false。
示例 1:
输入:words = ["hello","leetcode"], order = "hlabcdefgijkmnopqrstuvwxyz"
输出:true
解释:在该语言的字母表中,'h' 位于 'l' 之前,所以单词序列是按字典序排列的。
示例 2:
输入:words = ["word","world","row"], order = "worldabcefghijkmnpqstuvxyz"
输出:false
解释:在该语言的字母表中,'d' 位于 'l' 之后,那么 words[0] > words[1],因此单词序列不是按字典序排列的。
示例 3:
输入:words = ["apple","app"], order = "abcdefghijklmnopqrstuvwxyz"
输出:false
解释:当前三个字符 "app" 匹配时,第二个字符串相对短一些,然后根据词典编纂规则 "apple" > "app",因为 'l' > '∅',其中 '∅' 是空白字符,定义为比任何其他字符都小(更多信息)。
提示:
1 <= words.length <= 100
1 <= words[i].length <= 20
order.length == 26
在 words[i] 和 order 中的所有字符都是英文小写字母。
我的方法:哈希数组映射,相邻单词比较
bool isAlienSorted(vector<string>& words, string order) {
SI n = words.size();
if (n == 1) return true;
int ord[26] = {};
for (int i = 0; i < 26;++i){
ord[order[i] - 'a'] = i;
}
int pre, cur;
for (SI i = 0; i < n-1; ++i) {
int nPre = words[i].size(), nCur = words[i + 1].size();
for (SI j = 0; j < 20; ++j) {
if (nPre <= j) break; // 前者到最后一个字母了,跳
if (nCur <= j) return false; // 前者字符多于后者
pre = ord[words[i][j]-'a'];
cur = ord[words[i + 1][j] - 'a'];
if (pre > cur) return false; // 不符合规则
else if (pre < cur) break; // 符合规则
}
}
return true;
}
复杂度分析
-
时间复杂度: O ( C ) O(C) O(C) ,其中 C 是 words 中单词总长度和。
-
空间复杂度: O(1) 。
剑指 Offer II 035. 最小时间差
给定一个 24 小时制(小时:分钟 “HH:MM”)的时间列表,找出列表中任意两个时间的最小时间差并以分钟数表示。
示例 1:
输入:timePoints = ["23:59","00:00"]
输出:1
示例 2:
输入:timePoints = ["00:00","23:59","00:00"]
输出:0
提示:
2 <= timePoints <= 2 * 104
timePoints[i] 格式为 "HH:MM"
方法一:排序
两个string容器之间是可以相互比较的,因此直接用sort对vector<string>比较即可
将 timePoints \textit{timePoints} timePoints 排序后,最小时间差必然出现在 timePoints \textit{timePoints} timePoints 的两个相邻时间,或者 timePoints \textit{timePoints} timePoints 的两个首尾时间中。因此排序后遍历一遍 timePoints \textit{timePoints} timePoints 即可得到最小时间差。
时间映射:ab:cd -> (a*10+b)*60 + c*10+d
inline int trans(string& t) {
int t1 = (int(t[0] - '0') * 10 + int(t[1] - '0')) * 60
+ int(t[3] - '0') * 10 + int(t[4] - '0');
return t1;
}
int findMinDifference(vector<string>& timePoints) {
int n = timePoints.size();
sort(timePoints.begin(), timePoints.end());
int pre = trans(timePoints[1]) - trans(timePoints[0]);
for (int i=2; i<n; i++){
int curDiff = trans(timePoints[i]) - trans(timePoints[i-1]);
if (curDiff<pre) {
pre = curDiff;
}
}
int last = trans(timePoints[0]) - trans(timePoints[n-1]) + 24*60;
return min(pre, last);
}
复杂度分析
-
时间复杂度: O ( n log n ) O(n\log n) O(nlogn),其中 n 是数组 timePoints \textit{timePoints} timePoints的长度。排序需要 O ( n log n ) O(n\log n) O(nlogn) 的时间。
-
空间复杂度: O ( n ) O(n) O(n)或 O ( log n ) O(\log n) O(logn)。为排序需要的空间,取决于具体语言的实现。
剑指 Offer II 031. 最近最少使用缓存
运用所掌握的数据结构,设计和实现一个 LRU (Least Recently Used,最近最少使用) 缓存机制 。
实现 LRUCache 类:
LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
进阶:是否可以在 O(1) 时间复杂度内完成这两种操作?
哈希双向链表
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
关键是双向链表四个操作方法的实现:
双向链表内部结构
head(-1, 0) -> first ->second ->......-> last -> trail (-1, 0) 注意,-1,-2的索引不在定义域内,用户不可查询
add2Head(DListNode* node)将node放到first的位置remove(DListNode* node)移除某个nodeDListNode* removeLast()移除最后一个node,并返回该node(用于删除HashTable 中的元素)void move2Head(DListNode* node)移动到first的位置
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在
O
(
1
)
O(1)
O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
-
对于
get操作,首先判断key是否存在:-
如果
key不存在,则返回-1; -
如果
key存在,则key对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
-
-
对于
put操作,首先判断key是否存在:-
如果
key不存在,使用key和value创建一个新的节点,在双向链表的头部添加该节点,并将key和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项; -
如果
key存在,则与get操作类似,先通过哈希表定位,再将对应的节点的值更新为value,并将该节点移到双向链表的头部。
-
上述各项操作中,访问哈希表的时间复杂度为 O ( 1 ) O(1) O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O ( 1 ) O(1) O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O ( 1 ) O(1) O(1) 时间内完成。
小贴士
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
class DListNode {
public:
int key, val;
DListNode* next, * pre;
DListNode(int k, int v) : key(k), val(v), next(nullptr), pre(nullptr) {};
};
class LRUCache {
private:
unordered_map<int, DListNode*> m;
DListNode* head, *trail; // 头尾不能改,改的是内部中间结点
int size;
int cap; // 最大容量
// 在链表头部添加Node x,时间O(1)
void add2Head(DListNode* node) {
node->pre = head;
node->next = head->next;
head->next = node;
node->next->pre = node;
}
// 删除链表中的Node x, (x一定存在), 时间O(1)
void remove(DListNode* node) {
node->pre->next = node->next;
node->next->pre = node->pre;
}
// 删除链表中的最后一个结点,并返回该节点,时间O(1)
DListNode* removeLast() {
DListNode* node = trail->pre;
remove(node);
return node;
}
// 将node移动到第一位
void move2Head(DListNode* node) {
remove(node);
add2Head(node);
}
public:
LRUCache(int capacity) {
this->cap = capacity;
head = new DListNode(-1, 0);
trail = new DListNode(-2, 0);
head->next = trail;
trail->pre = head;
size = 0;
}
int get(int key) {
if (m.count(key)) {
DListNode* cur = m[key];
move2Head(cur);
return cur->val;
}
else return -1;
}
void put(int key, int value) {
if (m.count(key)) {
DListNode* cur = m[key];
cur->val = value;
move2Head(cur);
}
else if (size < cap) {
DListNode* cur = new DListNode(key, value);
add2Head(cur);
++size;
m[key] = cur;
}
else {
DListNode* cur = new DListNode(key, value);
add2Head(cur);
m[key] = cur;
cur = removeLast();
m.erase(cur->key);
}
}
};
复杂度分析
- 时间复杂度:对于
put和get都是 O ( 1 ) O(1) O(1)。 - 空间复杂度: O ( capacity ) O(\text{capacity}) O(capacity),因为哈希表和双向链表最多存储 capacity + 1 \text{capacity} + 1 capacity+1 个元素。
栈
剑指 Offer II 036. 后缀表达式
根据 逆波兰表示法,求该后缀表达式的计算结果。
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
说明:
整数除法只保留整数部分。
给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
输入:tokens = ["2","1","+","3","*"]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
输入:tokens = ["4","13","5","/","+"]
输出:6
解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
输出:22
解释:
该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
提示:
1 <= tokens.length <= 104
tokens[i] 要么是一个算符("+"、"-"、"*" 或 "/"),要么是一个在范围 [-200, 200] 内的整数
我的方法:栈
注意:不要做重复的操作,比如说把tmp转成string,又转换成int,这样很浪费时间。因此在声明栈时,应该声明一个stack<int>,而不是stack<string>
int funEvalRPN(int x, int y, string s) {
if (s == "+") return x + y;
else if (s == "-") return x - y;
else if (s == "*") return x * y;
return x / y;
}
int evalRPN(vector<string>& tokens) {
int n = tokens.size(), tmp1, tmp2; stack<int> stk;
unordered_set<string> s{"+", "-", "*", "/"};
for (int i = 0; i < n; i++) {
if (s.count(tokens[i])) {
tmp1 = stk.top(); stk.pop();
tmp2 = stk.top(); stk.pop();
int tmp = funEvalRPN(tmp2, tmp1, tokens[i]);
stk.push(tmp);
continue;
}
stk.push(stoi(tokens[i]));
}
return stk.top();
}
单调栈什么时候应用呢?
- 当需要为任意一个元素找
左
边
/
右
边
\color{red}左边/右边
左边/右边 第一个比自己 大/ 小的位置时,使用单调栈
- → \rightarrow →顺序遍历:stack保留左侧信息 (遍历方向不影响解题,看自己如何理解)
- ← \leftarrow ←倒序遍历:stack保留右侧信息
- 递增单调栈(top一定是栈里面的最大值,否则弹出):出现波峰就剔除,留下波谷
- 递减单调栈(top一定是栈里面的最小值,否则弹出):出现波谷就剔除,留下波峰

剑指 Offer II 038. 每日温度
请根据每日 气温 列表 temperatures ,重新生成一个列表,要求其对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例 1:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
示例 2:
输入: temperatures = [30,40,50,60]
输出: [1,1,1,0]
示例 3:
输入: temperatures = [30,60,90]
输出: [1,1,0]
提示:
1 <= temperatures.length <= 105
30 <= temperatures[i] <= 100
顺序遍历。单调递减栈
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
stk = []
n = len(temperatures)
ans = [0]*n
for i, cur in enumerate(temperatures):
while stk and cur>temperatures[stk[-1]]:
top = stk.pop()
ans[top] = i-top
stk.append(i)
return ans
倒序遍历,单调递减栈:
从后往前入栈,每次只压入比栈头小的值,若不满足则把栈头不断pop到满足条件。(矮个子只看得到第一个比他高的,后面的都被遮住了)
但要注意根据题意变通,
stack里面存的是索引!!
vector<int> dailyTemperatures(vector<int>& temperatures) {
stack<int> stk;
int n = temperatures.size();
vector<int> ans(n);
for (int i = n-1; i >= 0; --i) {
while (!stk.empty() && temperatures[i] >= temperatures[stk.top()]) {
stk.pop();
}
ans[i] = stk.empty()? 0: stk.top()-i;
stk.push(i);
}
return ans;
}
剑指 Offer II 039. 直方图最大矩形面积
给定非负整数数组 heights ,数组中的数字用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
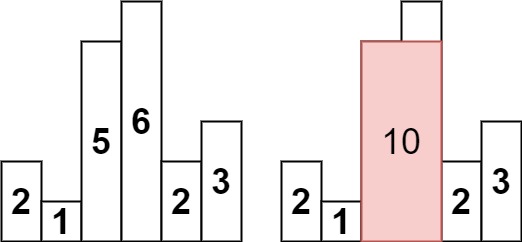
输入:heights = [2,1,5,6,2,3]
输出:10
解释:最大的矩形为图中红色区域,面积为 10
示例 2:
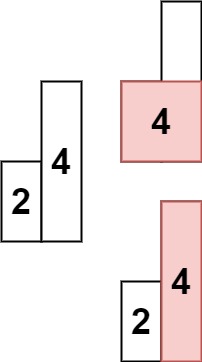
输入: heights = [2,4]
输出: 4
提示:
1 <= heights.length <=105
0 <= heights[i] <= 104
我的方法:暴力,超时
类似于回文串,遍历每个中心点
int lraHelper(int c, vector<int>& nums) {
int l = c, r = c;
int t = nums[c];
while (l >= 0 && nums[l] >= t) l--;
while (r < nums.size() && nums[r] >= t) r++;
if (l < c) l++;
if (r > c) r--;
return t * (r - l + 1);
}
int largestRectangleArea(vector<int>& heights) {
int l = 0, r = heights.size();
int ans = INT_MIN;
for (int i = 0; i < r; i++) {
ans = max(ans, lraHelper(i, heights));
}
return ans;
}
复杂度: O ( n 2 ) O(n^2) O(n2)
优化:单调递增栈
int largestRectangleArea(vector<int>& heights) {
int n = heights.size(), ans = 0;
vector<int> stk;
for (int i = 0; i < n; i++) { // 顺序遍历,保留左侧信息
while (!stk.empty() && heights[i] <= heights[stk.back()])
stk.pop_back(); // 维护一个递增栈,栈出口元素必须是最大值
stk.push_back(i);
for (int j = stk.size() - 1; j >= 0; j--) {
if (j == 0) // stk[0]是[0, i]范围内的最小值,因此矩形的宽应该为(i-0+1)
ans = max(ans, heights[stk[j]] * (i + 1));
else // 其余元素的长度,只需要找到前一个元素的索引(比当前元素小)
ans = max(ans, heights[stk[j]] * (i - stk[j - 1]));
}
}
return ans;
}
最糟糕情况:当heights也是单调递增时, O ( n 2 ) O(n^2) O(n2)
单调栈
思路:维护两个数组left, right
left:顺序遍历,存当前位置 i i i 的左侧第一个小于heights[i]的索引(递增栈)left:反向遍历,存当前位置 i i i 的右侧第一个小于heights[i]的索引(递增栈)
最后再遍历一次heights,计算每个位置
i
i
i 的最大面积:heights[i] * (right[i] - left[i] - 1)
分析
单调栈的时间复杂度是多少?直接计算十分困难,但是我们可以发现:
每一个位置只会入栈一次(在枚举到它时),并且最多出栈一次。
因此当我们从左向右/总右向左遍历数组时,对栈的操作的次数就为 O ( N ) O(N) O(N)。所以单调栈的总时间复杂度为 O ( N ) O(N) O(N)。
int largestRectangleArea(vector<int>& heights) {
int n = heights.size(), ans = 0;
vector<int> left(n), right(n);
stack<int> stk;
for (int i = 0; i < n; i++) {
while (!stk.empty() && heights[i] <= heights[stk.top()])
stk.pop();
left[i] = stk.empty() ? -1 : stk.top();
stk.push(i);
}
stk = stack<int>{};
for (int i = n-1; i >= 0; i--) {
while (!stk.empty() && heights[i] <= heights[stk.top()])
stk.pop();
right[i] = stk.empty() ? n : stk.top();
stk.push(i);
}
for (int i = 0; i < n; i++) {
ans = max(ans, heights[i] * (right[i] - left[i] - 1));
}
return ans;
}
复杂度分析
-
时间复杂度:O(N) 。
-
空间复杂度:O(N) 。
剑指 Offer II 040. 矩阵中最大的矩形
给定一个由 0 和 1 组成的矩阵 matrix ,找出只包含 1 的最大矩形,并返回其面积。
注意:此题 matrix 输入格式为一维 01 字符串数组。
示例 1:
输入:matrix = ["10100","10111","11111","10010"]
输出:6
解释:最大矩形如上图所示。
示例 2:
输入:matrix = []
输出:0
示例 3:
输入:matrix = ["0"]
输出:0
示例 4:
输入:matrix = ["1"]
输出:1
示例 5:
输入:matrix = ["00"]
输出:0
提示:
rows == matrix.length
cols == matrix[0].length
0 <= row, cols <= 200
matrix[i][j] 为 '0' 或 '1'
我的方法:暴力遍历
维护一个整数变量rBound,记录最小右边界。
最外层遍历,选择矩形框左上角的起点(i, j),
然后进入内层循环,计算方框面积 = (curI + 1 - i) * (rBound-j)
每次比较方框面积大小,存最大值即可

int maximalRectangle(vector<string>& matrix) {
int rBound, ans =0;
int m = matrix.size(), n, curI, curJ;
if (m != 0) n = matrix.back().size();
else n = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (matrix[i][j] == '0') continue;
rBound = n;
curI = i; curJ = j;
for (; curI < m; curI++) {
if (matrix[curI][curJ] == '0') break;
for (; curJ < rBound; curJ++) {
if (matrix[curI][curJ] == '0') {
rBound = curJ; break;
}
}
ans = max(ans, (curI + 1 - i) * (rBound-j));
curJ = j;
}
}
}
return ans;
}
时间复杂度:
O
(
m
2
n
)
O(m^2n)
O(m2n)
空间复杂度:
O
(
1
)
O(1)
O(1)
int maximalRectangle(vector<string>& matrix) {
int m = matrix.size();
if (m == 0) {
return 0;
}
int n = matrix[0].size();
vector<vector<int>> left(m, vector<int>(n, 0));
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (matrix[i][j] == '1') {
left[i][j] = (j == 0 ? 0 : left[i][j - 1]) + 1;
}
}
}
int ret = 0;
for (int j = 0; j < n; j++) { // 对于每一列,使用基于柱状图的方法
vector<int> up(m, 0), down(m, 0);
stack<int> stk;
for (int i = 0; i < m; i++) {
while (!stk.empty() && left[stk.top()][j] >= left[i][j]) {
stk.pop();
}
up[i] = stk.empty() ? -1 : stk.top();
stk.push(i);
}
stk = stack<int>();
for (int i = m - 1; i >= 0; i--) {
while (!stk.empty() && left[stk.top()][j] >= left[i][j]) {
stk.pop();
}
down[i] = stk.empty() ? m : stk.top();
stk.push(i);
}
for (int i = 0; i < m; i++) {
int height = down[i] - up[i] - 1;
int area = height * left[i][j];
ret = max(ret, area);
}
}
return ret;
}
42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。

示例 1:
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
提示:
n == height.length
1 <= n <= 2 * 104
0 <= height[i] <= 105
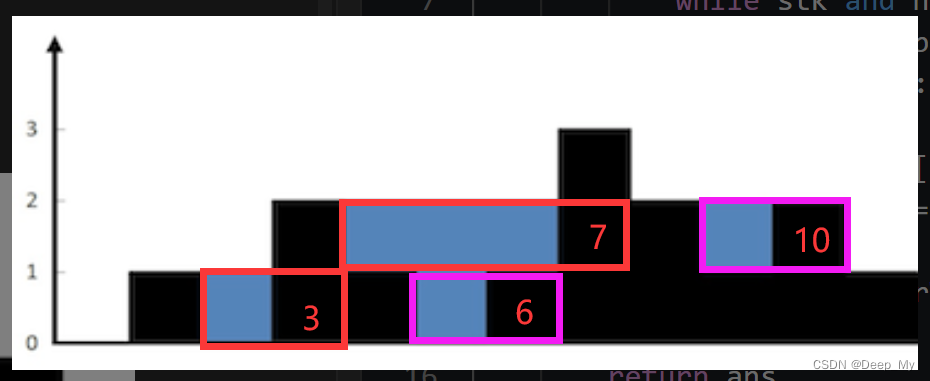
解法:单调栈
这里我们顺序遍历,使用单调递减栈,利用 stk 中的信息,每次stk弹出时,计算面积:
注意
- i = 5 时,stk = [3, 4, 5]
- i = 6 时,stk = [3, 4], top = 5, left = stk[-1] = 4,计算紫色6
- i = 7 时, stk = [3], top =4, left = stk[-1] = 3, 计算 红色7
stk = [], top = 4, break
class Solution:
def trap(self, height: List[int]) -> int:
stk = []
ans = 0
for i in range(len(height)):
while len(stk)>0 and height[stk[-1]]<=height[i]:
bottom_idx = stk.pop() # 弹出的是底
if len(stk)==0: # stk没有元素时,左边没有边界,不参与计算
break
left = stk[-1] # stk的top是左侧的边
height_top = min(height[i], height[left])
ans += (height_top - height[bottom_idx])*(i-left-1)
stk.append(i)
return ans
堆
class heapMaxTop:
def __init__(self, lst: list=[]) -> None:
self.data = [0]
self.total = 0
for it in lst:
self.insert(it)
def pa(self, node: int) ->int:
return node//2
def left(self, root: int) -> int:
return root*2
def right(self, root: int) ->int:
return root*2+1
def swap(self, x: int, y: int):
tmp = self.data[x]
self.data[x] = self.data[y]
self.data[y] = tmp
def swim(self, k: int):
""" 对堆底的元素,上浮"""
while k>1 and self.data[self.pa(k)]<self.data[k]: # 浮到堆顶,退出循环
self.swap(self.pa(k), k)
k = self.pa(k)
def sink(self, k: int):
""" 对堆顶的元素,下沉"""
while self.left(k) <= self.total: # 沉到堆底,退出
older = self.left(k)
if self.right(k) <= self.total and self.data[older]<self.data[self.right(k)]:
older = self.right(k)
if self.data[older] < self.data[k]: break # k大于子节点, 不用下沉
self.swap(older, k) #
k = older
def insert(self, val: int):
self.total += 1
self.data.append(val)
self.swim(self.total)
def pop(self):
self.total -= 1
max_ = self.data[1]
self.data[1] = self.data[-1]
self.data.pop()
self.sink(1)
return max_
347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
1 <= nums.length <= 105
k 的取值范围是 [1, 数组中不相同的元素的个数]
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
我的方法:哈希+二叉堆(优先序列)
auto compfun = [](pair<int, int>& a, pair<int, int>& b)->bool { return a.second > b.second; };
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(compfun)> q(compfun);
注意lambda函数没有type的仿函数,因此我们需要用decltype来自动生成这个对象
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> m; vector<int> ans(k);
for (int i = 0; i < nums.size(); i++) {
m[nums[i]]++;
}
auto it = m.begin();
auto compfun = [](pair<int, int>& a, pair<int, int>& b)->bool {
return a.second > b.second;
};
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(compfun)> q(compfun);
for (int i = 0; i < k; i++, it++) {
q.emplace(*it);
}
for (int i = k; i < m.size(); i++, ++it) {
if (q.top().second >= (*it).second) { continue; }
q.pop(); q.emplace(*it);
}
for (int i = k-1; i >= 0; i--) {
ans[i] = q.top().first;
q.pop();
}
return ans;
}
复杂度分析
时间复杂度:
O
(
N
log
k
)
O(N\log k)
O(Nlogk),其中 N 为数组的长度。我们首先遍历原数组,并使用哈希表记录出现次数,每个元素需要 O(1) 的时间,共需 O(N) 的时间。随后,我们遍历「出现次数数组」,由于堆的大小至多为
k
k
k,因此每次堆操作需要
O
(
log
k
)
O(\log k)
O(logk)的时间,共需
O
(
N
log
k
)
O(N\log k)
O(Nlogk) 的时间。二者之和为
O
(
N
log
k
)
O(N\log k)
O(Nlogk)。
空间复杂度:O(N) 。哈希表的大小为 O(N) ,而堆的大小为 O(k) ,共计为 O(N)
剑指 Offer II 061. 和最小的 k 个数对
给定两个以升序排列的整数数组 nums1 和 nums2 , 以及一个整数 k 。
定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2 。
请找到和最小的 k 个数对 (u1,v1), (u2,v2) … (uk,vk) 。
示例 1:
输入: nums1 = [1,7,11], nums2 = [2,4,6], k = 3
输出: [1,2],[1,4],[1,6]
解释: 返回序列中的前 3 对数:
[1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
示例 2:
输入: nums1 = [1,1,2], nums2 = [1,2,3], k = 2
输出: [1,1],[1,1]
解释: 返回序列中的前 2 对数:
[1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3]
示例 3:
输入: nums1 = [1,2], nums2 = [3], k = 3
输出: [1,3],[2,3]
解释: 也可能序列中所有的数对都被返回:[1,3],[2,3]
提示:
1 <= nums1.length, nums2.length <= 104
-109 <= nums1[i], nums2[i] <= 109
nums1, nums2 均为升序排列
1 <= k <= 1000
我的方法:优先队列,topK方法
vector<vector<int>> kSmallestPairs(vector<int>& nums1, vector<int>& nums2, int k) {
auto f = [](pair<int, int>& a, pair<int, int>& b)->bool { return a.first + a.second < b.first + b.second; };
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(f)>q(f);
pair<int, int> tmp, cur;
for (auto& i : nums1) {
for (auto& j : nums2) {
tmp = pair<int, int>(i, j);
if (q.size() < k) q.push(tmp);
else {
cur = q.top();
if (f(cur, tmp)) continue;
else {
q.push(tmp);
q.pop();
}
}
}
}
vector<vector<int>> ans; vector<int> tmpv(2);
while (!q.empty()) {
auto& [a, b] = q.top();
tmpv[0] = a; tmpv[1] = b;
ans.push_back(tmpv); q.pop();
}
return ans;
}
优化:避免重复元素
对于已经按升序排列的两个数组
nums
1
,
nums
2
\textit{nums}_1,\textit{nums}_2
nums1,nums2 ,长度分别为
length
1
,
length
2
\textit{length}_1,\textit{length}_2
length1,length2,我们可以知道和最小的数对一定为
(
nums
1
[
0
]
,
nums
2
[
0
]
)
(\textit{nums}_1[0], \textit{nums}_2[0])
(nums1[0],nums2[0]),和最大的数对一定为
(
nums
1
[
length
1
−
1
]
,
nums
2
[
length
2
−
1
]
)
(\textit{nums}_1[\textit{length}_1-1], \textit{nums}_2[\textit{length}_2-1])
(nums1[length1−1],nums2[length2−1])。本题要求找到最小的 k 个数对,最直接的办法是可以将所有的数对求出来,然后利用排序或者
TopK
\texttt{TopK}
TopK 解法求出最小的 k 个数对即可。
实际求解时可以不用求出所有的数对,只需从所有符合待选的数对中选出最小的即可,假设当前已选的前 n n n 小数对的索引分别为 ( a 1 , b 1 ) , ( a 2 , b 2 ) , ( a 3 , b 3 ) , … , ( a n , b n ) (a_1,b_1),(a_2,b_2),(a_3,b_3),\ldots,(a_n,b_n) (a1,b1),(a2,b2),(a3,b3),…,(an,bn),由于两个数组都是按照升序进行排序的,则可以推出第 n + 1 n+1 n+1 小的数对的索引选择范围为 ( a 1 + 1 , b 1 ) , ( a 1 , b 1 + 1 ) , ( a 2 + 1 , b 2 ) , ( a 2 , b 2 + 1 ) , ( a 3 + 1 , b 3 ) , ( a 3 , b 3 + 1 ) , … , ( a n + 1 , b n ) , ( a n , b n + 1 ) (a_1+1,b_1),(a_1,b_1+1),(a_2+1,b_2),(a_2,b_2+1),(a_3+1,b_3),(a_3,b_3+1),\ldots,(a_n+1,b_n),(a_n,b_n+1) (a1+1,b1),(a1,b1+1),(a2+1,b2),(a2,b2+1),(a3+1,b3),(a3,b3+1),…,(an+1,bn),(an,bn+1),假设我们利用堆的特性可以求出待选范围中最小数对的索引为 ( a i , b i ) (a_{i},b_{i}) (ai,bi),同时将新的待选的数对 ( a i + 1 , b i ) , ( a i , b i + 1 ) (a_{i}+1,b_{i}),(a_{i},b_{i}+1) (ai+1,bi),(ai,bi+1) 加入到堆中,直到我们选出 k 个数对即可。
如果我们每次都将已选的数对 ( a i , b i ) (a_{i},b_{i}) (ai,bi) 的待选索引 ( a i + 1 , b i ) , ( a i , b i + 1 ) (a_{i}+1,b_{i}),(a_{i},b_{i}+1) (ai+1,bi),(ai,bi+1) 加入到堆中则可能出现重复的问题,一般需要设置标记位解决去重的问题。我们可以将 nums 1 \textit{nums}_1 nums1 的前 k 个索引数对 ( 0 , 0 ) , ( 1 , 0 ) , … , ( k − 1 , 0 ) (0,0),(1,0),\ldots,(k-1,0) (0,0),(1,0),…,(k−1,0) 加入到队列中,每次从队列中取出元素 ( x , y ) (x,y) (x,y) 时,我们只需要将 nums 2 \textit{nums}_2 nums2 的索引增加即可,这样避免了重复加入元素的问题。
vector<vector<int>> kSmallestPairs(vector<int>& nums1, vector<int>& nums2, int k) {
auto cmp = [&nums1, &nums2](const pair<int, int> & a, const pair<int, int> & b) {
return nums1[a.first] + nums2[a.second] > nums1[b.first] + nums2[b.second];
};
int m = nums1.size();
int n = nums2.size();
vector<vector<int>> ans;
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp)> pq(cmp);
for (int i = 0; i < min(k, m); i++) {
pq.emplace(i, 0);
}
while (k-- > 0 && !pq.empty()) {
auto [x, y] = pq.top();
pq.pop();
ans.emplace_back(initializer_list<int>{nums1[x], nums2[y]});
if (y + 1 < n) {
pq.emplace(x, y + 1);
}
}
return ans;
}
复杂度分析
-
时间复杂度: O ( k log k ) O(k \log k) O(klogk),其中 k 是选择的数对的数目。优先队列中最多只保存 k 个元素,每次压入新的元素队列进行调整的时间复杂度为 log k \log k logk,入队操作一共有 2 k 2k 2k 次, 一共需要从队列中弹出 k 个数据。
-
空间复杂度: O ( k ) O(k) O(k)。优先队列中最多只保存 k 个元素。
面试题 17.09. 第 k 个数
有些数的素因子只有 3,5,7,请设计一个算法找出第 k 个数。注意,不是必须有这些素因子,而是必须不包含其他的素因子。例如,前几个数按顺序应该是 1,3,5,7,9,15,21。
示例 1:
输入: k = 5
输出: 9
思路:优先队列
每次只加最小值 * 【3, 5, 7】 这三个数即可
优先队列弹出 k 次,最后一次弹出的为 top k
class Solution:
def getKthMagicNumber(self, k: int) -> int:
import heapq
pq = [1]
heapq.heapify(pq)
vis = set([1])
cnt = 0
ans = 0
while cnt<k:
cur = heapq.heappop(pq)
ans = cur
for it in [3, 5, 7]:
nxt = it*cur
if nxt in vis: continue
vis.add(nxt)
heapq.heappush(pq, nxt)
cnt += 1
return ans
字典树(前缀、后缀)
实现方式,
- 用一个数组构建26叉树
- (视题目再决定加辅助变量,例如用一个 bool 表示 叶节点)
- 用 d e f a u l t d i c t ( T i e r ) defaultdict(Tier) defaultdict(Tier) 实现一个字典树 √ 推荐
剑指 Offer II 062. 实现前缀树
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
示例:
输入
inputs = ["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
inputs = [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
提示:
1 <= word.length, prefix.length <= 2000
word 和 prefix 仅由小写英文字母组成
insert、search 和 startsWith 调用次数 总计 不超过 3 * 104 次
我的思路:26叉树
class NodeTrie 包含一个char c,一个26字母指针数组NodeTrie* next[26],以及一个bool终点符bool end
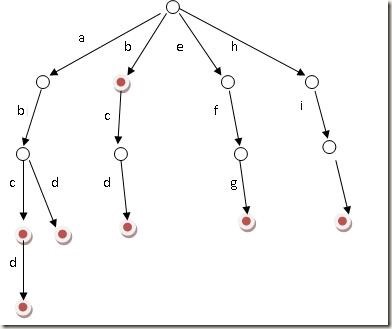
class Trie {
public:
class NodeTrie {
public:
NodeTrie* next[26] = {}; // 这是不对的,初始化必须放到构造函数里面去!!!
bool end;
NodeTrie() {
end = False;
for (int i = 0; i < 26; ++i)
this->next[i] = nullptr;
}
};
NodeTrie* root;
/** Initialize your data structure here. */
Trie() { root = new NodeTrie('0'); }
~Trie() { delete root; }
/** Inserts a word into the trie. */
void insert(string word) {
NodeTrie* tmp = root;
for (int i=0; i < word.size(); i++) {
if (tmp->next[word[i] - 'a'] == nullptr)
tmp->next[word[i]-'a'] = new NodeTrie(word[i]);
tmp = tmp->next[word[i] - 'a'];
}
tmp->end = true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
NodeTrie* tmp = root;
for (int i = 0; i < word.size(); i++) {
if (tmp->next[word[i] - 'a'] == nullptr) return false;
tmp = tmp->next[word[i] - 'a'];
}
if (tmp->end) return true;
return false;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
NodeTrie* tmp = root;
for (const auto& i : prefix) {
if (tmp->next[i - 'a'] == nullptr) return false;
tmp = tmp->next[i - 'a'];
}
return true;
}
};
复杂度分析
-
时间复杂度:初始化为 O ( 1 ) O(1) O(1),其余操作为 O ( ∣ S ∣ ) O(|S|) O(∣S∣),其中 ∣ S ∣ |S| ∣S∣ 是每次插入或查询的字符串的长度。
-
空间复杂度: O ( ∣ T ∣ ⋅ Σ ) O(|T|\cdot\Sigma) O(∣T∣⋅Σ),其中 ∣ T ∣ |T| ∣T∣ 为所有插入字符串的长度之和, Σ \Sigma Σ 为字符集的大小,本题 Σ = 26 \Sigma=26 Σ=26。
剑指 Offer II 063. 替换单词
在英语中,有一个叫做 词根(root) 的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典和一个句子,需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
需要输出替换之后的句子。
示例 1:
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例 2:
输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
示例 3:
输入:dictionary = ["a", "aa", "aaa", "aaaa"], sentence = "a aa a aaaa aaa aaa aaa aaaaaa bbb baba ababa"
输出:"a a a a a a a a bbb baba a"
示例 4:
输入:dictionary = ["catt","cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例 5:
输入:dictionary = ["ac","ab"], sentence = "it is abnormal that this solution is accepted"
输出:"it is ab that this solution is ac"
提示:
1 <= dictionary.length <= 1000
1 <= dictionary[i].length <= 100
dictionary[i] 仅由小写字母组成。
1 <= sentence.length <= 10^6
sentence 仅由小写字母和空格组成。
sentence 中单词的总量在范围 [1, 1000] 内。
sentence 中每个单词的长度在范围 [1, 1000] 内。
sentence 中单词之间由一个空格隔开。
sentence 没有前导或尾随空格。
我的方法:Tier 前缀树、字典树
新方法:将string sentence 按空格分割
使用#include<sstream>头文件的istringstream 方法
istringstream in(sentence);
string t; vector<string> ans;
while (in >> t)
ans.push_back(t);
本题主要思路是,将 前缀插入字典树;
遍历目标句子,如果发现前缀终止符end,则将该单词替换为前缀单词。
class rWnode {
private:
char val; // val不需要
bool end = false;
rWnode* child[26] = {};
public:
rWnode(char a):val(a){}
void insert(string& s) {
rWnode* tmp = this;
for (int i = 0; i < s.size(); ++i) {
if (tmp->end) return;
if (tmp->child[s[i] - 'a'] == nullptr)
tmp->child[s[i] - 'a'] = new rWnode(s[i]);
tmp = tmp->child[s[i] - 'a'];
}
tmp->end = true;
}
void prefix(string& s) {
rWnode* tmp = this;
for (int i = 0; i < s.size(); ++i) {
if (tmp->child[s[i] - 'a'] == nullptr) return;
tmp = tmp->child[s[i] - 'a'];
if (tmp->end) {
s = s.substr(0, i+1);
return;
}
}
}
};
string replaceWords(vector<string>& dictionary, string sentence) {
rWnode* root = new rWnode('0');
sort(dictionary.begin(), dictionary.end());
for (int i = 0; i < dictionary.size(); ++i)
root->insert(dictionary[i]);
istringstream in(sentence);
string t, ans;
while (in >> t) {
root->prefix(t);
ans += t + ' ';
}
ans.erase(--ans.end());
return ans;
}
复杂度分析
时间复杂度:O(N),其中 N 是 sentence 的长度。每次查询操作为线性时间复杂度。
空间复杂度:O(N),前缀树的大小。
(cpp,py字典树)剑指 Offer II 064. 神奇的字典
设计一个使用单词列表进行初始化的数据结构,单词列表中的单词 互不相同 。 如果给出一个单词,请判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于已构建的神奇字典中。
实现 MagicDictionary 类:
MagicDictionary() 初始化对象
void buildDict(String[] dictionary) 使用字符串数组 dictionary 设定该数据结构,dictionary 中的字符串互不相同
bool search(String searchWord) 给定一个字符串 searchWord ,判定能否只将字符串中 一个 字母换成另一个字母,使得所形成的新字符串能够与字典中的任一字符串匹配。如果可以,返回 true ;否则,返回 false 。
示例:
输入
inputs = ["MagicDictionary", "buildDict", "search", "search", "search", "search"]
inputs = [[], [["hello", "leetcode"]], ["hello"], ["hhllo"], ["hell"], ["leetcoded"]]
输出
[null, null, false, true, false, false]
解释
MagicDictionary magicDictionary = new MagicDictionary();
magicDictionary.buildDict(["hello", "leetcode"]);
magicDictionary.search("hello"); // 返回 False
magicDictionary.search("hhllo"); // 将第二个 'h' 替换为 'e' 可以匹配 "hello" ,所以返回 True
magicDictionary.search("hell"); // 返回 False
magicDictionary.search("leetcoded"); // 返回 False
提示:
1 <= dictionary.length <= 100
1 <= dictionary[i].length <= 100
dictionary[i] 仅由小写英文字母组成
dictionary 中的所有字符串 互不相同
1 <= searchWord.length <= 100
searchWord 仅由小写英文字母组成
buildDict 仅在 search 之前调用一次
最多调用 100 次 search
我的方法:字典树
- 建26叉树 (常规操作)
- 查找
给定一个int cnt = 1表示查找过程中,还能够出现不匹配字符的次数
2.1 当cnt==0时,说明接下来的搜索必须匹配
2.2 当cnt ==1时(可用作剪枝),说明接下来的搜索的可以匹配,也可以不匹配,因此我们需要回溯26叉树,只要发现有一个案例能够满足条件,则返回true;否则,所有路径不匹配,返回false
class MagicDictionary {
public:
class Node {
public:
Node* next[26] = { nullptr };
bool end;
Node(): end(false) {
}
};
Node* root;
/** Initialize your data structure here. */
MagicDictionary() {
this->root = new Node();
}
void buildDict(vector<string> dictionary) {
Node* cur;
for (const auto& it : dictionary) {
cur = root; int tmp;
for (int i = 0; i < it.size(); i++) {
tmp = it[i] - 'a';
if (!cur->next[tmp]) cur->next[tmp] = new Node();
cur = cur->next[tmp];
}
cur->end = true;
}
}
bool dfssearch(string& searchWord, int cnt, Node* cur, int index) {
if (cnt < 0) return false;
int tmp;
for (int i = index; i < searchWord.size(); i++) {
tmp = searchWord[i] - 'a';
if (cnt == 0) { // 2.1 情况
if (cur->next[tmp]) cur = cur->next[tmp];
else return false;
}
else { // 2.2 情况
for (int j = 0; j < 26; j++) {
if (!cur->next[j]) continue;
if (cur->next[tmp] == cur->next[j]) { // 找到匹配字符,cnt传1
if(dfssearch(searchWord, cnt, cur->next[j], i + 1))
return true;
}
else { // 找到不匹配字符,cnt传0
if (dfssearch(searchWord, cnt-1, cur->next[j], i + 1))
return true;
}
}
return false; // 所有路径不匹配
}
}
return cnt == 0 && cur->end; // 当cnt==0,且此时为最后一个单词时,返回true;
}
bool search(string searchWord) {
return dfssearch(searchWord, 1, root, 0);
}
};
py版本
- 26叉树,
class myTier:
def __init__(self) -> None:
self.child = [None]*26
self.end = False
class MagicDictionary:
def __init__(self):
self.head = myTier()
def buildDict(self, dictionary: List[str]) -> None:
for string in dictionary:
head = self.head
for i in string:
idx = ord(i) - ord('a')
if head.child[idx]==None:
head.child[idx] = myTier()
head = head.child[idx]
head.end = True
def search(self, searchWord: str):
head = self.head
ans = [False]
def dfs(string: str, cnt: int, deep: int, head: myTier, ans:list):
if not head : return
if head.end==True and cnt==1 and deep==len(string):
ans[0] = True
return
if ans[0] or deep>=len(string):
return
for i in range(26):
idx = ord(string[deep]) - ord('a')
if i==idx:
dfs(string, cnt, deep+1, head.child[i], ans)
elif cnt==0: # 👀 剪枝
dfs(string, cnt+1, deep+1, head.child[i], ans)
dfs(searchWord, 0, 0, head, ans)
return ans[0]
- 由于问题涉及到回溯,26叉树复杂度太高,因此可以优化为字典树
class myTier:
def __init__(self) -> None:
self.child = defaultdict(myTier)
self.end = False
class MagicDictionary:
def __init__(self):
self.head = myTier()
def buildDict(self, dictionary: List[str]) -> None:
for string in dictionary:
head = self.head
for i in string:
head = head.child[i]
head.end = True
def search(self, searchWord: str):
head = self.head
ans = [False]
def dfs(string: str, cnt: int, deep: int, head: myTier, ans:list):
if not head or ans[0]:
return
if head.end==True and cnt==1 and deep==len(string):
ans[0] = True
return
if deep>=len(string):
return
for i in head.child.keys():
if i==string[deep]:
dfs(string, cnt, deep+1, head.child[i], ans)
elif cnt==0:# 👀 剪枝
dfs(string, cnt+1, deep+1, head.child[i], ans)
dfs(searchWord, 0, 0, head, ans)
return ans[0]
(py, 后缀树)剑指 Offer II 065. 最短的单词编码
单词数组 words 的 有效编码 由任意助记字符串 s 和下标数组 indices 组成,且满足:
words.length == indices.length
助记字符串 s 以 ‘#’ 字符结尾
对于每个下标 indices[i] ,s 的一个从 indices[i] 开始、到下一个 ‘#’ 字符结束(但不包括 ‘#’)的 子字符串 恰好与 words[i] 相等
给定一个单词数组 words ,返回成功对 words 进行编码的最小助记字符串 s 的长度 。
示例 1:
输入:words = ["time", "me", "bell"]
输出:10
解释:一组有效编码为 s = "time#bell#" 和 indices = [0, 2, 5] 。
words[0] = "time" ,s 开始于 indices[0] = 0 到下一个 '#' 结束的子字符串,如加粗部分所示 "time#bell#"
words[1] = "me" ,s 开始于 indices[1] = 2 到下一个 '#' 结束的子字符串,如加粗部分所示 "time#bell#"
words[2] = "bell" ,s 开始于 indices[2] = 5 到下一个 '#' 结束的子字符串,如加粗部分所示 "time#bell#"
示例 2:
输入:words = ["t"]
输出:2
解释:一组有效编码为 s = "t#" 和 indices = [0] 。
提示:
1 <= words.length <= 2000
1 <= words[i].length <= 7
words[i] 仅由小写字母组成
python版,后缀树,仿cpp,用数组 存 类节点
- 👀1:倒叙生成树
dfs函数,计算字典树中存储节点的和
class Solution:
class MyTrie:
def __init__(self):
self.tire = [None]*26
self.end = None
self.val = None
def __init__(self):
self.myTrie = self.MyTrie()
def minimumLengthEncoding(self, words: List[str]) -> int:
for s in words:
cur = self.myTrie
for i in range(len(s)-1, -1, -1): #👀1: 倒叙生成树
cur.end = False
idx = ord(s[i]) - ord('a')
if (cur.tire[idx] == None):
cur.tire[idx] = self.MyTrie()
cur = cur.tire[idx]
cur.end = True
for i in range(26):
if cur.tire[i]!=None:
cur.end = False
break
cur.val = len(s) + 1
return self.dfs(self.myTrie)
def dfs(self, node:MyTrie)->int:
if node == None: return 0
ans = node.val if node.end==True else 0
for i in range(26):
ans += self.dfs(node.tire[i])
return ans
优化:用一个dict() or unordered_map去存叶节点,可以省去dfs函数
class Solution:
class MyTrie:
def __init__(self):
self.tire = [None]*26
self.end = None
def __init__(self):
self.myTrie = self.MyTrie()
def minimumLengthEncoding(self, words: List[str]) -> int:
dic = {}
for s in words:
cur = self.myTrie
for i in range(len(s)-1, -1, -1):
cur.end = False
idx = ord(s[i]) - ord('a')
if (cur.tire[idx] == None):
cur.tire[idx] = self.MyTrie()
cur = cur.tire[idx]
cur.end = True
for i in range(26): # 👀 待优化
if cur.tire[i]!=None:
cur.end = False
break
dic[cur] = len(s) + 1
ans = 0
for idx, node in enumerate(dic):
if node.end == True: ans += dic[node]
return ans
继续优化:self.end 的逻辑
如果self.end = True:表示该字符不是叶节点
class Solution:
class MyTrie:
def __init__(self):
self.tire = [None]*26
self.end = False
def __init__(self):
self.myTrie = self.MyTrie()
def minimumLengthEncoding(self, words: List[str]) -> int:
dic = {}
for s in words:
cur = self.myTrie
for i in range(len(s)-1, -1, -1):
cur.end = True
idx = ord(s[i]) - ord('a')
if (cur.tire[idx] == None):
cur.tire[idx] = self.MyTrie()
cur = cur.tire[idx]
dic[cur] = len(s) + 1
ans = 0
for idx, node in enumerate(dic):
if node.end == False: ans += dic[node]
return ans
def dfs(self, node:MyTrie)->int:
if node == None: return 0
ans = node.val if node.end==True else 0
for i in range(26):
ans += self.dfs(node.tire[i])
return ans
cpp版本
class TrieNode{
TrieNode* children[26];
public:
int count;
TrieNode() {
for (int i = 0; i < 26; ++i) children[i] = NULL;
count = 0;
}
TrieNode* get(char c) {
if (children[c - 'a'] == NULL) {
children[c - 'a'] = new TrieNode();
count++;
}
return children[c - 'a'];
}
};
class Solution {
public:
int minimumLengthEncoding(vector<string>& words) {
TrieNode* trie = new TrieNode();
unordered_map<TrieNode*, int> nodes;
for (int i = 0; i < (int)words.size(); ++i) {
string word = words[i];
TrieNode* cur = trie;
for (int j = word.length() - 1; j >= 0; --j)
cur = cur->get(word[j]);
nodes[cur] = i;
}
int ans = 0;
for (auto& [node, idx] : nodes) {
if (node->count == 0) {
ans += words[idx].length() + 1;
}
}
return ans;
}
};
py字典树(极简) Trie = lambda: collections.defaultdict(Trie)
collections.defaultdict: 访问不存在的key时,会默认生成None;(相当于unordered_map)
collections.defaultdict(Trie) ,访问不存在的key时,默认生成Trie
参数default_factory必须是一个可调用的对象 (换言之,必须是class),例如defaultdict(int), defaultdict(str)
Trie = lambda: collections.defaultdict(Trie)
因为defaultdict注册的默认构造函数只有第一次调用的时候才会真正地调用,所以这里可以用自己来定义自己
Trie是一个函数,调用它会返回一个defaultdict
dict.__getitem__需要两个参数,第一个是字典对象,第二个是key
最开始,字典对象是trie,key是words的第一个字符word,trie[word]会返回一个新字典
新字典代表着该节点以字符word为开头的子节点
以此类推,最后得到一个叶子结点,它是默认应该是空的
Trie = lambda: collections.defaultdict(Trie)
trie = Trie() # 这是字典树的根
for word in words:
reduce(dict.__getitem__, word, trie)
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
words = list(set(words)) # 去重
Trie = lambda: collections.defaultdict(Trie)
trie = Trie()
#reduce(..., S, trie) is trie[S[0]][S[1]][S[2]][...][S[S.length - 1]],将单词反序插入
#reduce(dict.__getitem__, word[::-1], trie) = trie[word[-1]][word[-2]].........
nodes = [reduce(dict.__getitem__, word[::-1], trie)
for word in words]
#Add word to the answer if it's node has no neighbors
return sum(len(word) + 1
for i, word in enumerate(words)
关于py中 map(), reduce(), filter()三个函数
python 中的for 循环和while 循环的效率比较低。
如果遇到循环时,尽量使用map() reduce() filter()。这三个函数的运行速度比较快:
map(function, iterable[)函数:- 接收一个函数和一个序列。
- 返回一个map对象。
b=map(lambda x:print("中秋快乐%s"%x),[1,2,3])
b3 = map(lambda x:x*2,range(10)) #相当于 [ i*2 for i in range(10)],但是存在一个map对象中
print(lsit(b3)) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
reduce(function, iterable[, initializer])在python3 中需要导入from functools import reduce。- 接收一个函数,一个可迭代序列,一个初始值
- 先对可迭代序列中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
from functools import reduce
from typing import List
n=[1,2,3,4,5]
n5 =reduce(lambda x,y:x*y,n) # 计算5的阶乘
print(n5)
a = reduce(lambda x,y:x * y , [1],2) #第三个参数是初始值
b = reduce(lambda x,y:x * y , [2,2,3],3) # (初始值:3)*2*2*3 = 36
c = reduce(lambda x,y:x - y , [1,2,3,5,6],0)# 0-1-2-3-5-6 = -17
d = reduce(lambda x,y:x * y , [ ],5) # 直接return 5
print(a,b,c,d) # 2 36 -17 5
from collections import defaultdict
dic = defaultdict(int)
dic[0],dic[2] = 1,3
print(defaultdict.__getitem__(dic, 5)) #output 0
filter 函数是一个过滤器。例如:
#相当于 [i for i in range(10) if i >5 and i <8]
b1 = filter(lambda x:x >6 and x<8,range(12))
print(b1) # [7]
剑指 Offer II 066. 单词之和
实现一个 MapSum 类,支持两个方法,insert 和 sum:
MapSum() 初始化 MapSum 对象
void insert(String key, int val) 插入 key-val 键值对,字符串表示键 key ,整数表示值 val 。如果键 key 已经存在,那么原来的键值对将被替代成新的键值对。
int sum(string prefix) 返回所有以该前缀 prefix 开头的键 key 的值的总和。
示例:
输入:
inputs = ["MapSum", "insert", "sum", "insert", "sum"]
inputs = [[], ["apple", 3], ["ap"], ["app", 2], ["ap"]]
输出:
[null, null, 3, null, 5]
解释:
MapSum mapSum = new MapSum();
mapSum.insert("apple", 3);
mapSum.sum("ap"); // return 3 (apple = 3)
mapSum.insert("app", 2);
mapSum.sum("ap"); // return 5 (apple + app = 3 + 2 = 5)
提示:
1 <= key.length, prefix.length <= 50
key 和 prefix 仅由小写英文字母组成
1 <= val <= 1000
最多调用 50 次 insert 和 sum
我的方法,26叉树
思路:insert 构建树
sum:通过辅助函数dfs搜索树
class Mytire:
def __init__(self) -> None:
self.lst = [None] * 26
self.val = 0
class MapSum:
def __init__(self):
"""
Initialize your data structure here.
"""
self.tire = Mytire()
def insert(self, key: str, val: int) -> None:
cur = self.tire
for i in key:
idx = ord(i) - ord('a')
if cur.lst[idx] == None:
cur.lst[idx] = Mytire()
cur = cur.lst[idx]
else:
cur = cur.lst[idx]
cur.val = val
def dfs(self, root: Mytire)->int:
if root == None: return 0
ans = 0 if root.val==0 else root.val
for i in range(26):
ans += self.dfs(root.lst[i])
return ans
def sum(self, prefix: str) -> int:
cur = self.tire
for i in prefix:
idx = ord(i) - ord('a')
if cur.lst[idx] == None:
return 0
else:
cur = cur.lst[idx]
return self.dfs(cur)
py dfs函数 类似cpp传递引用
传递一个list(),作为函数参数,已达到类似 CPP 引用(指针)的效果
class Mytire:
def __init__(self) -> None:
self.lst = [None] * 26
self.val = 0
class MapSum:
def __init__(self):
self.tire = Mytire()
def insert(self, key: str, val: int) -> None:
cur = self.tire
for i in key:
idx = ord(i) - ord('a')
if cur.lst[idx] == None:
cur.lst[idx] = Mytire()
cur = cur.lst[idx]
else:
cur = cur.lst[idx]
cur.val = val
def dfs(self, root: Mytire, ans:list)->None: # 👀
if root == None: return 0
ans[0] += root.val
for i in range(26):
self.dfs(root.lst[i], ans)
def sum(self, prefix: str) -> int:
cur = self.tire
for i in prefix:
idx = ord(i) - ord('a')
if cur.lst[idx] == None:
return 0
else:
cur = cur.lst[idx]
ans = [0] # 👀
self.dfs(cur, ans)
return ans[0]
剑指 Offer II 067. 最大的异或
给定一个整数数组 nums ,返回 nums[i] XOR nums[j] 的最大运算结果,其中 0 ≤ i ≤ j < n 。
示例 1:
输入:nums = [3,10,5,25,2,8]
输出:28
解释:最大运算结果是 5 XOR 25 = 28.
示例 2:
输入:nums = [0]
输出:0
示例 3:
输入:nums = [2,4]
输出:6
示例 4:
输入:nums = [8,10,2]
输出:10
示例 5:
输入:nums = [14,70,53,83,49,91,36,80,92,51,66,70]
输出:127
提示:
1 <= nums.length <= 2 * 104
0 <= nums[i] <= 231 - 1
进阶:你可以在 O(n) 的时间解决这个问题吗?
对于位运算的题,一般都要考虑二进制方法去做,否则非常容易超时
假设我们在数组中选择了元素
a
i
a_i
ai 和
a
j
(
i
≠
j
)
a_j(i \neq j)
aj(i=j),使得它们达到最大的按位异或运算结果
x
x
x:
x
=
a
i
⊕
a
j
x = a_i \oplus a_j
x=ai⊕aj
其中
⊕
\oplus
⊕ 表示按位异或运算。要想求出
x
x
x,一种简单的方法是使用二重循环枚举
i
i
i 和
j
j
j,但这样做的时间复杂度为
O
(
n
2
)
O(n^2)
O(n2),会超出时间限制。因此,我们需要寻求时间复杂度更低的做法。
根据按位异或运算的性质, x = a i ⊕ a j x = a_i \oplus a_j x=ai⊕aj 等价于 a j = x ⊕ a i a_j = x \oplus a_i aj=x⊕ai。我们可以根据这一变换,设计一种「从高位到低位依次确定 x x x 二进制表示的每一位」的方法,以此得到 x x x 的值。该方法的精髓在于:
-
由于数组中的元素都在 [ 0 , 2 31 ) [0, 2^{31}) [0,231) 的范围内,那么我们可以将每一个数表示为一个长度为 31 31 31 位的二进制数(如果不满 31 31 31 位,在最高位之前补上若干个前导 0 0 0 即可);
-
这 31 31 31 个二进制位从低位到高位依次编号为 0 , 1 , ⋯ , 30 0, 1, \cdots, 30 0,1,⋯,30。我们从最高位第 30 30 30 个二进制位开始,依次确定 x x x 的每一位是 0 0 0 还是 1 1 1;
-
由于我们需要找出最大的 x x x,因此在枚举每一位时,我们先判断 x x x 的这一位是否能取到 1 1 1。如果能,我们取这一位为 1 1 1,否则我们取这一位为 0 0 0。
「判断 x x x 的某一位是否能取到 1 1 1」这一步骤并不容易。下面介绍两种判断的方法。
方法一:哈希表
思路与算法
假设我们已经确定了 x x x 最高的若干个二进制位,当前正在确定第 k k k 个二进制位。根据「前言」部分的分析,我们希望第 k k k 个二进制位能够取到 1 1 1。
我们用
pre
k
(
x
)
\textit{pre}^k(x)
prek(x) 表示
x
x
x 从最高位第
30
30
30 个二进制位开始,到第
k
k
k 个二进制位为止的数,那么
a
j
=
x
⊕
a
i
a_j = x \oplus a_i
aj=x⊕ai 蕴含着:
pre
k
(
a
j
)
=
pre
k
(
x
)
⊕
pre
k
(
a
i
)
\textit{pre}^k (a_j) = \textit{pre}^k (x) \oplus \textit{pre}^k (a_i)
prek(aj)=prek(x)⊕prek(ai)
由于
pre
k
(
x
)
\textit{pre}^k(x)
prek(x) 对于我们来说是已知的,因此我们将所有的
pre
k
(
a
j
)
\textit{pre}^k (a_j)
prek(aj) 放入哈希表中,随后枚举
i
i
i 并计算
pre
k
(
x
)
⊕
pre
k
(
a
i
)
\textit{pre}^k (x) \oplus \textit{pre}^k (a_i)
prek(x)⊕prek(ai)。如果其出现在哈希表中,那么说明第
k
k
k 个二进制位能够取到
1
1
1,否则第
k
k
k 个二进制位只能为
0
0
0 。
本方法若仅阅读文字,理解起来可能较为困难,读者可以参考下面的代码以及注释。
细节
计算 pre k ( x ) \textit{pre}^k(x) prek(x) 可以使用右移运算 >> \texttt{>>} >>。
int findMaximumXOR(vector<int>& nums) {
if (nums.size() <= 1) return 0;
int ans = 0;
for (int i=30; i>=0; i--){
unordered_set<int> s;
for (int j=0; j<nums.size(); j++){
s.insert(nums[j] >> i);
}
// ans 包含从最高位开始,到第 i+1 个二进制为止的部分
// 现考虑第 i 位,将其置 1,即为 ans_next = ans*2+1
int ans_next = ans * 2 + 1;
bool found = false;
for (int num: nums){
if (s.count(ans_next ^ (num >> i))){
found = true;
break;
}
}
if (found) ans = ans_next;
else ans = ans_next -1; // 没有找到,则 ans = ans*2 即 ans_next-1
}
return ans;
}
复杂度分析
时间复杂度: O ( n log C ) O(n \log C) O(nlogC),其中 nn 是数组 nums \textit{nums} nums 的长度, C C C 是数组中的元素范围,在本题中 C < 2 31 C < C < 2^{31}C< C<231C<。枚举答案 x x x 的每一个二进制位的时间复杂度为 O ( log C ) O(\log C) O(logC),在每一次枚举的过程中,我们需要 O ( n ) O(n) O(n) 的时间进行判断,因此总时间复杂度为 O ( n log C ) O(n \log C) O(nlogC)。
空间复杂度: O ( n ) O(n) O(n),即为哈希表需要使用的空间。
(字典树中存tuple)745. 前缀和后缀搜索
设计一个包含一些单词的特殊词典,并能够通过前缀和后缀来检索单词。
实现 WordFilter 类:
WordFilter(string[] words) 使用词典中的单词 words 初始化对象。
f(string pref, string suff) 返回词典中具有前缀 prefix 和后缀 suff 的单词的下标。如果存在不止一个满足要求的下标,返回其中 最大的下标 。如果不存在这样的单词,返回 -1 。
示例:
输入
["WordFilter", "f"]
[[["apple"]], ["a", "e"]]
输出
[null, 0]
解释
WordFilter wordFilter = new WordFilter(["apple"]);
wordFilter.f("a", "e"); // 返回 0 ,因为下标为 0 的单词:前缀 prefix = "a" 且 后缀 suff = "e" 。
提示:
1 <= words.length <= 104
1 <= words[i].length <= 7
1 <= pref.length, suff.length <= 7
words[i]、pref 和 suff 仅由小写英文字母组成
最多对函数 f 执行 104 次调用
字典树
字典中节点存的是:前后缀
调用 f 时,如果前缀和后缀的长度相同,那么此题可以用字典树来解决。初始化时,只需将单词正序和倒序后得到的单词对依次插入字典树即可。比如要插入
"apple"
\text{"apple"}
"apple" 时,只需依次插入
(a, e), (‘p’, ‘l’), (‘p’, ‘p’), (‘l’, ‘p’), (‘e’, ‘a’)
\text{(a, e), (`p', `l'), (`p', `p'), (`l', `p'), (`e', `a')}
(a, e), (‘p’, ‘l’), (‘p’, ‘p’), (‘l’, ‘p’), (‘e’, ‘a’) 即可。这样初始化后,对于前缀和后缀相同的检索,也只需要在字典树上检索前缀和后缀倒序得到的单词对。
但是调用
f
f
f 时,还有可能遇到前缀和后缀长度不同的情况。为了应对这一情况,可以将短的字符串用特殊字符补足,使得前缀和后缀长度相同。而在初始化时,也需要考虑到这个情况,特殊字符组成的单词对,也要插入字典树中。
class WordFilter:
def __init__(self, words: List[str]):
self.tier = {}
self.weightKey = ('#', '#')
for i, word in enumerate(words):
cur = self.tier
m = len(word)
for j in range(m):
tmp = cur
for k in range(j, m):
key = (word[k], '#') # 正序插,倒叙补#
if key not in tmp:
tmp[key] = {}
tmp = tmp[key]
tmp[self.weightKey] = i
tmp = cur
for k in range(j, m):
key = ('#', word[-k-1]) # 倒叙插,正序补#
if key not in tmp:
tmp[key] = {}
tmp = tmp[key]
tmp[self.weightKey] = i
key = (word[j], word[-j-1])
if key not in cur:
cur[key] = {}
cur = cur[key]
cur[self.weightKey] = i
def f(self, pref: str, suff: str) -> int:
cur = self.tier
for key in zip_longest(pref, suff[::-1], fillvalue='#'):
# 每次都是前缀,后缀各取一个进行迭代
# zip_longest函数功能与zip类似
# 内置的zip函数是已元素最少对象为基准,
# 而zip_longest函数是已元素最多对象为基准,使用fillvalue的值来填充
if key not in cur:
return -1
cur = cur[key]
return cur[self.weightKey]
复杂度分析
- 时间复杂度:初始化消耗 O ( ∑ i = 0 n − 1 w i 2 ) O(\sum\limits_{i=0}^{n-1}w_i^2) O(i=0∑n−1wi2) 时间,其中 w i w_i wi 是每个单词的字符数。每次检索消耗 O ( max ( p , s ) ) O(\max(p, s)) O(max(p,s)),其中 p p p 和 s s s 分别是输入的 pref \textit{pref} pref 和 suff \textit{suff} suff 的长度。
- 空间复杂度:初始化消耗 O ( ∑ i = 0 n − 1 w i 2 ) O(\sum\limits_{i=0}^{n-1}w_i^2) O(i=0∑n−1wi2) 空间,每次检索消耗 O ( 1 ) O(1) O(1)空间。















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









