






Spark学习
什么是spark?
Apache Spark是一个开源的集群计算系统,旨在使数据分析变得快速
既运行得快,又写得快
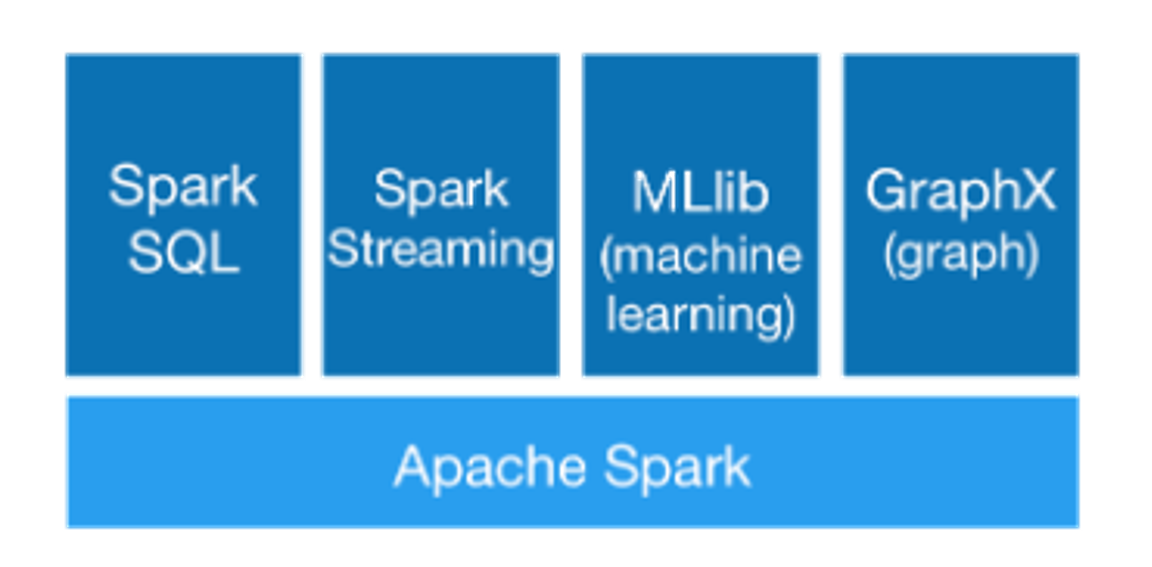
spark5大模块:
回顾:MR的执行流程
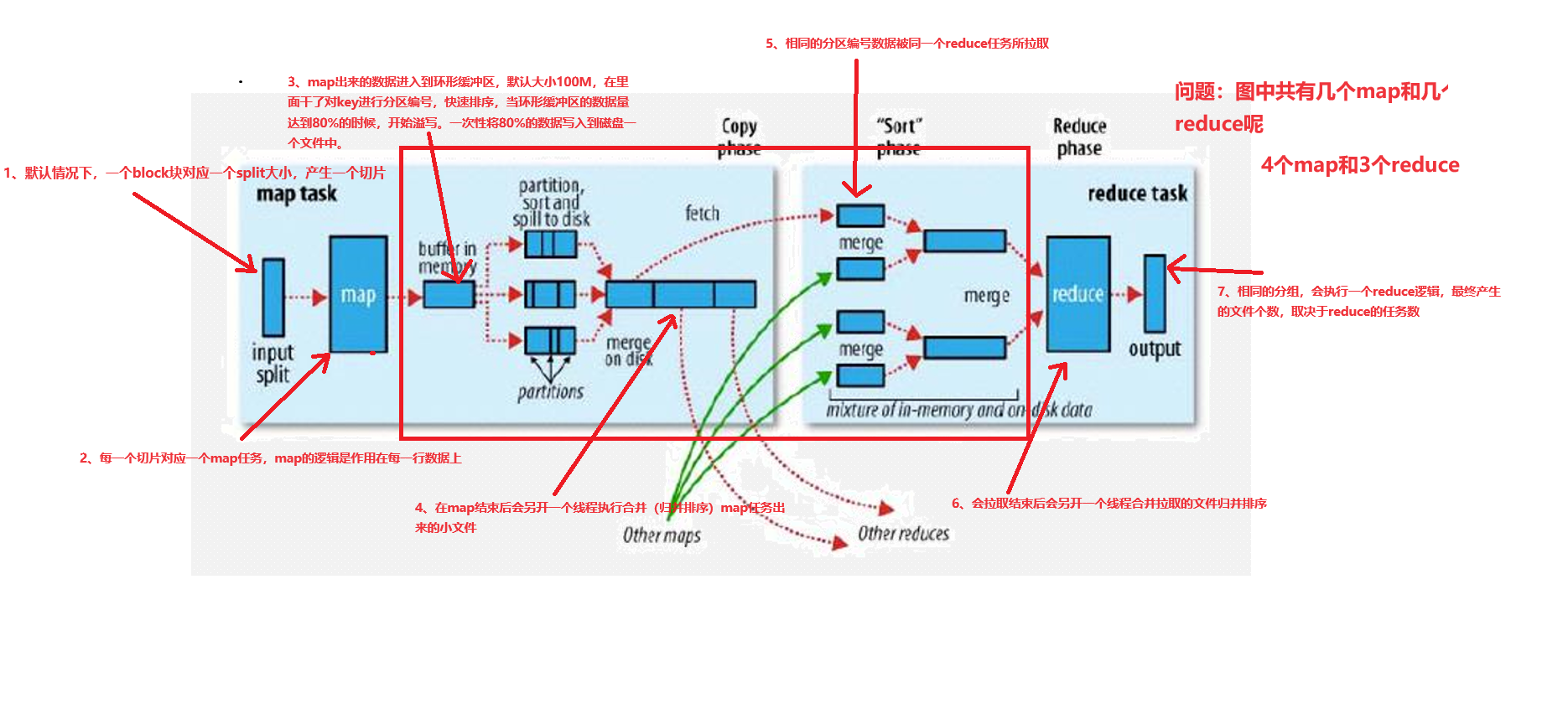
hadoop为什么慢???额外的复制,序列化,磁盘IO开销
spark为什么快???因为内存计算,当然还有DAG(有向无环图)
支持3种语言的API :Scala(很好)Python(不错)Java(…)
有4种模式可以运行
Local 多用于测试
Standalone 节点运行
Mesos
YARN 最具前景
本地部署spark:
添加依赖
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.10</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.12.10</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.12.10</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.3</version>
</dependency>
WordCount:
数据展示:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建spark配置文件对象
val conf = new SparkConf()
// 设置运行模式
// local模式运行,需要设置setMaster
// 若要是集群运行,注释这句话即可
conf.setMaster("local")
// 设置spark作业的名字
conf.setAppName("wordcount")
// 创建spark上下文环境对象
val sc = new SparkContext(conf)
// 1. 读取文件 每次读一行
//RDD是spark core中的核心数据结构,将来运行的时候,数据会在RDD之间流动,默认基于内存计算
val lineRDD: RDD[String] = sc.textFile("spark/data/test.text")
// lineRDD.foreach(println)
// 2.处理数据 根据分隔符切分 扁平化处理
val wordRDD: RDD[String] = lineRDD.flatMap(_.split(" "))
// wordRDD.foreach(println)
// 3.将每一个单词组成(word,1)
val kvRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
// 分组
val kv: RDD[(String, Iterable[(String, Int)])] = kvRDD.groupBy(_._1)
val result: RDD[(String, Int)] = kv.map(s => (s._1, s._2.size))
// 打印
result.foreach(println)
/*
* 链式调用
* */
sc.textFile("spark/data/test.text")
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(s => (s._1, s._2.size))
.foreach(println)
}
}
wordcount 图解:
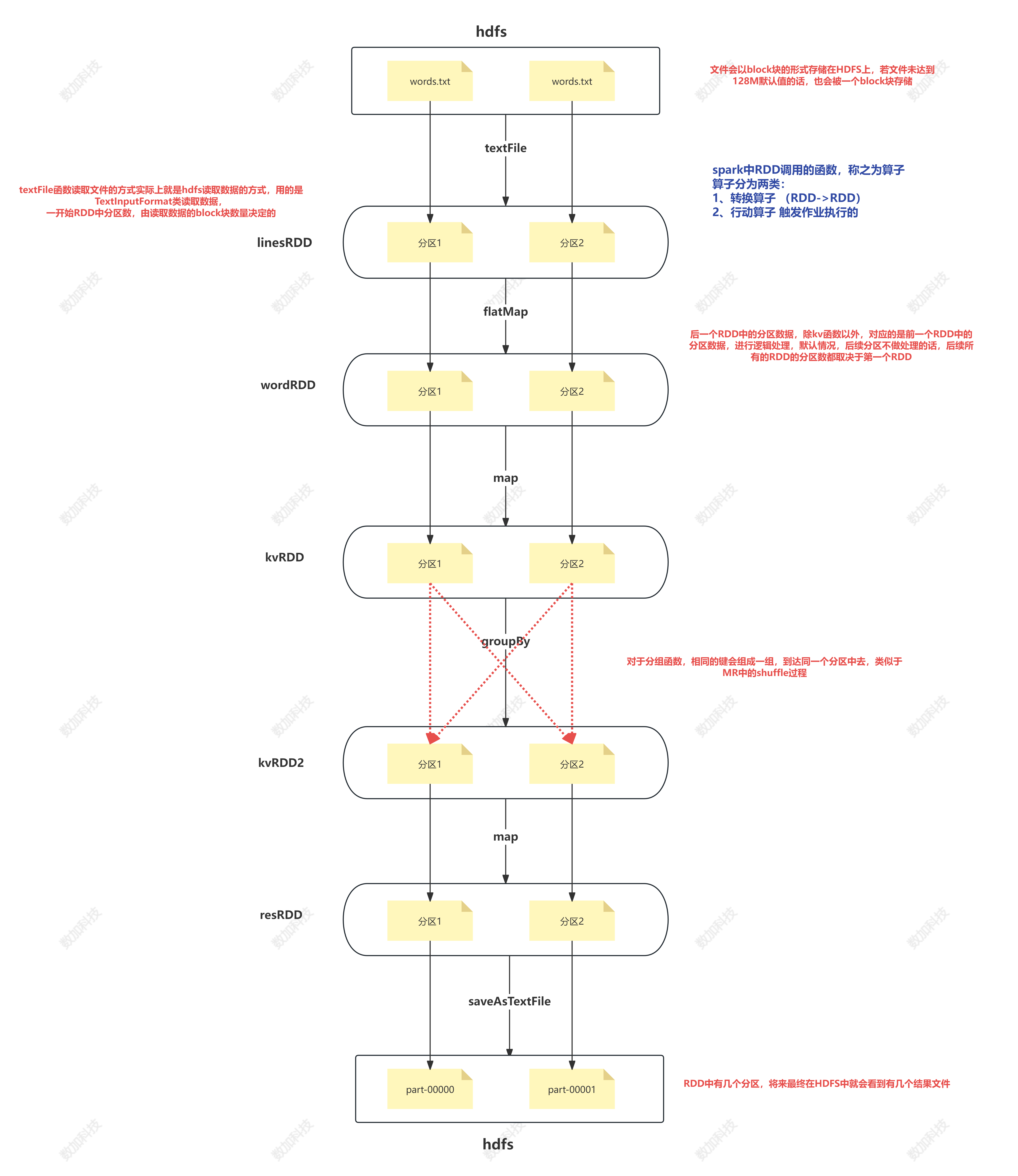
Spark Core
spark RDD
RDD: 弹性分布式数据集
弹性:数据量可大可小
RDD类似于容器,但是本身存储的不是数据,是计算逻辑
当遇到行动算子的时候,整个spark作业才会被触发执行,是从第一个RDD开始执行,数据才开始产生流动
数据在RDD之间只是流动关系,不会存储
流动的数据量可以很大,也可以很小,所以称为弹性
分布式:
spark本质上它是需要从HDFS中读取数据的,HDFS是分布式,数据block块将来可能会在不同的datanode上
RDD中流动的数据,可能会来自不同的datanode中的block块数据
数据集:
计算流动过程中,可以短暂地将RDD看成一个容器,容器中有数据,默认情况下在内存中不会进行存储
后面会有办法将一个RDD的数据存储到磁盘中
RDD的五大特性(重要!!!)
1、RDD是由一系列分区构成
注意:
1)读文件时的minPartitions参数只能决定最小分区数,实际读取文件后的RDD分区数,由数据内容本身以及集群的分布来共同决定的
2)若设置minPartitions的大小比block块数量还少的话,实际上以block块数量来决定分区数
3)产生shuffle的算子调用时,可以传入numPartitions,实际真正改变RDD的分区数,设置多少,最终RDD就有多少分区
2、算子是作用在每一个分区上的
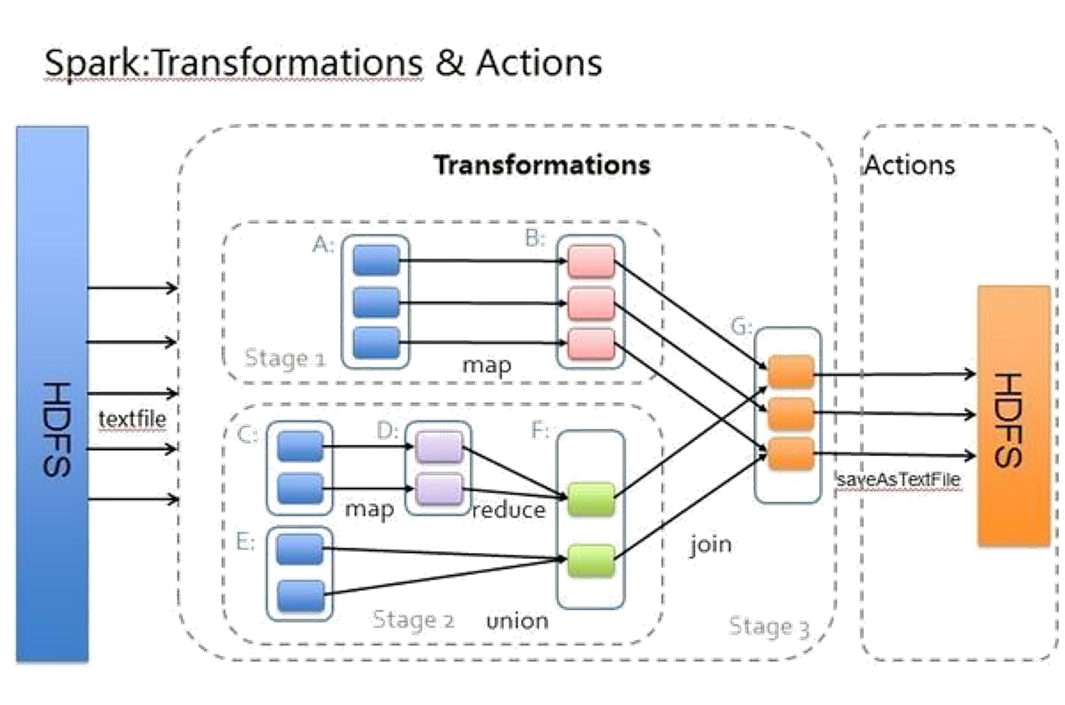
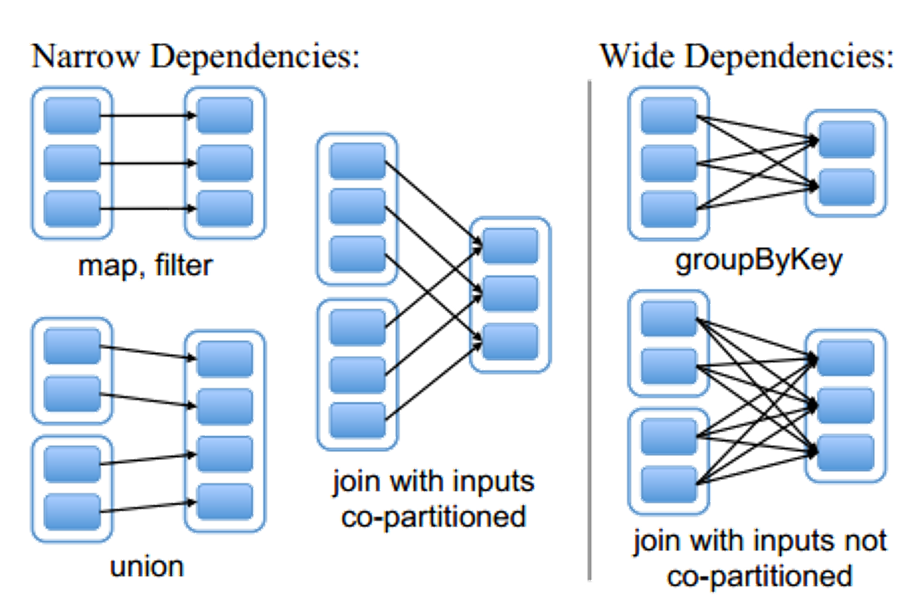
3、RDD与RDD之间存在一些依赖关系
- 1)窄依赖 前一个RDD中的某一个分区数据只会到后一个RDD中的某一个分区 一对一的关系
- 2)宽依赖 前一个RDD中的某一个分区数据会进入到后一个RDD中的不同分区中 一对多的关系 也可以通过查看是否产生shuffle来判断
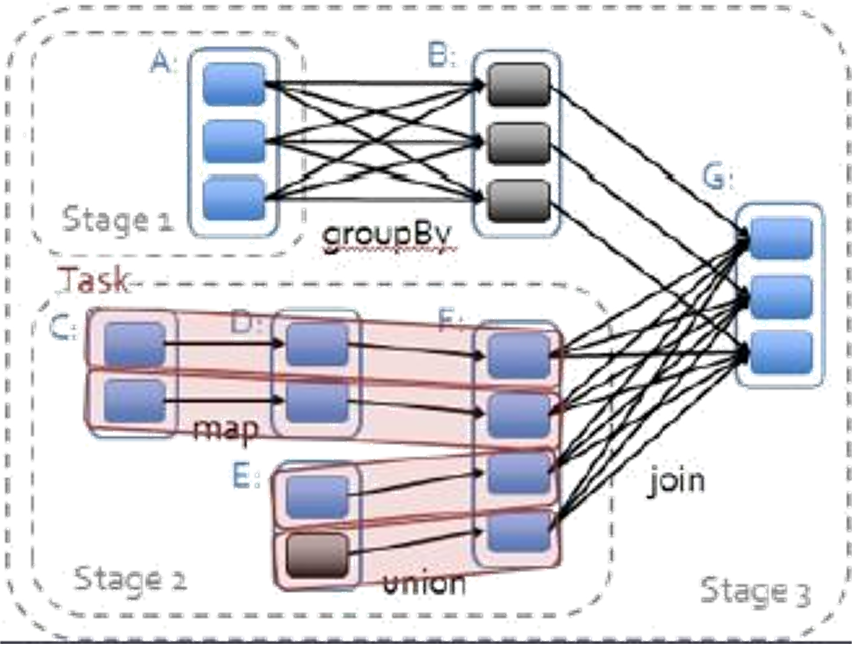
- 3)整个spark作业会被宽依赖的个数划分若干个stage, Num(stage) = Num(宽依赖) + 1
- 4)当遇到产生shuffle的算子的时候,涉及到从前一个RDD写数据到磁盘中,从磁盘中读取数据到后一个RDD的现象,
- 注意:第一次触发执行的时候,磁盘是没有数据的,所以会从第一个RDD产生开始执行
- 当重复触发相同的执行的时候,对于同一个DAG有向无环图而言,会直接从shuffle之后的RDD开始执行,可以直接从磁盘读取数据。
- 5)一个阶段中,RDD有几个分区,就会有几个并行task任务
4、kv算子只能作用在kv的RDD上
5、spark会提供最优的任务计算方式,只移动计算,不移动数据。
spark作业执行的特点:
- 1、只有遇到行动算子的时候,整个spark作业才会被触发执行
- 2、遇到几次,执行几次
def main(args: Array[String]): Unit = {
// 创建spark配置文件对象
val conf = new SparkConf()
// 设置运行模式
// local模式运行,需要设置setMaster
// 若要是集群运行,注释这句话即可
conf.setMaster("local")
// 设置spark作业的名字
conf.setAppName("WordCount")
// 创建spark上下文环境对象
val sc = new SparkContext(conf)
// 1. 读取文件 每次读一行
//RDD是spark core中的核心数据结构,将来运行的时候,数据会在RDD之间流动,默认基于内存计算
// val lineRDD: RDD[String] = sc.textFile("spark/data/test.text")
// println(lineRDD.getNumPartitions) // 查看分区数 默认一个分区
val linesRDD: RDD[String] = sc.textFile("spark/data/wcs/*",minPartitions = 3) // 设置最小分区数 为3 不是实际分区数
println(s"lineRDD的分区数:${linesRDD.getNumPartitions}") // 2个分区 说明 有几个block块 就有几个分区 下面的几个RDD都是两个分区
// 2.处理数据 根据分隔符切分 扁平化处理
val wordRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
// wordRDD.foreach(println)
// 3.将每一个单词组成(word,1)
val kvRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
// 分组
// 需要取消读文件时设置的最小分区数,从这之后的分区数为5,说明产生shuffle的算子调用时 numPartitions可以改变RDD的分区数
val kv: RDD[(String, Iterable[(String, Int)])] = kvRDD.groupBy(_._1,numPartitions = 5)
val result: RDD[(String, Int)] = kv.map(s => (s._1, s._2.size))
val resRDD2: RDD[(String, Int)] = result.map((kv: (String, Int)) => {
println("==================防伪码=====================")
(kv._1, kv._2)
})
//打印
resRDD2.foreach(println) // 调用了算子 所以执行了 直接使用println是不行的
// println("=" * 100)
// resRDD2.foreach(println) 调用一次 执行一次
// 查看spark jobs 界面 查看job数 stage数 task任务数(取决于分区数) DAG 有向无环图
// 打印
// result.foreach(println)
//指定的是文件夹的路径
//spark如果是local本地运行的话,会将本地文件系统看作一个hdfs文件系统 出现crc校验文件等
// result.saveAsTextFile("spark/data/outdata1")
}
RDD 算子
transformation 算子 转换算子(RDD->RDD)
Action算子 行动算子
宽依赖和窄依赖的例子:
窄依赖中的pipeline操作:使得task’的执行任务非常快
转换算子
Map
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1Map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Map算子演示")
// 上下文对象
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("spark/data/students.txt")
//map操作算子:将rdd中的数据依次取出,传递给后面函数逻辑,将计算后的数据返回到新的rdd中
//将rdd中的数据依次取出,处理完的数据返回下一个rdd直接继续执行后续的逻辑
val rdd: RDD[(String, String, String, String, String)] = lineRDD.map(s => {
println("============桀桀桀=============")
val arr1: Array[String] = s.split(",")
(arr1(0), arr1(1), arr1(2), arr1(3), arr1(4))
})
// 此时运行 没有结果 因为没有行动算子
// foreach就是一个行动算子
rdd.foreach(println)
// 结果: 不是先打印1000次 ============桀桀桀============= 交替进行
//...
//============桀桀桀=============
//(1500100934,隆高旻,21,男,理科五班)
//============桀桀桀=============
//(1500100935,蓬昆琦,21,男,文科六班)
//============桀桀桀=============
//(1500100936,习振锐,23,男,理科二班)
// ....
}
}
Filter
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo2Filter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Filter算子演示")
// 上下文对象
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("spark/data/students.txt")
// 过滤除所有的男生
//filter转换算子:将rdd中的数据依次取出,传递给后面的函数,跟map一样,也是依次传递一条
val genderRDD: RDD[String] = lineRDD.filter(s => {
// println("============桀桀桀=============") 打印的可能是女生
// s.split(",")(3).equals("男")
// 将确定的字符串值放前面 假如为空?
// "男".equals(s.split(",")(3))
var b: Boolean = false
if ("女".equals(s.split(",")(3))) {
println("============这是女生==================")
} else {
println("============这是男生==================")
b = "男".equals(s.split(",")(3))
}
b
})
genderRDD.foreach(println)
// 结果
// ...
// 1500100968,谭晗日,24,男,文科五班
// ============桀桀桀=============
// 1500100969,毛昆鹏,24,男,文科三班
// ============桀桀桀=============
// ============桀桀桀=============
// ============桀桀桀=============
// 1500100972,王昂杰,23,男,理科二班
// ============桀桀桀=============
// ============桀桀桀=============
// 1500100974,容鸿晖,21,男,文科五班
// ============桀桀桀=============
// 1500100975,蓬曜瑞,22,男,理科三班
// ============桀桀桀=============
// ============桀桀桀=============
// ============桀桀桀=============
// 1500100978,郜昆卉,21,男,文科五班
// ...
// 结果2: 验证打印============桀桀桀=============是因为 过滤了女生
// 1500100898,祁高旻,22,男,理科五班
// ============这是男生==================
// 1500100899,计浩言,22,男,文科四班
// ============这是女生==================
// ============这是男生==================
// 1500100901,崔海昌,21,男,理科六班
// ============这是男生==================
// 1500100902,丰昊明,23,男,文科六班
// ============这是女生==================
// ============这是女生==================
// ============这是女生==================
// ============这是女生==================
// ============这是女生==================
// ============这是男生==================
// 1500100908,那光济,22,男,文科二班
// ============这是男生==================
// 1500100909,符景天,23,男,文科二班
}
}
FlatMap
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo3FlatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("FlatMap算子演示")
// 上下文对象
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("spark/data/wcs/words.txt")
/**
* flatMap: 将rdd中的数据每一条数据传递给后面的函数,最终将返回的数组或者是序列进行扁平化,返回给新的集合
*/
val rdd1: RDD[String] = lineRDD.flatMap(s=>{
println("============一条数据=============")
s.split("\\|")
})
rdd1.foreach(println)
// 结果
// ============一条数据=============
//hello
//world
//============一条数据=============
//java
//hadoop
//linux
//============一条数据=============
//java
//scala
//hadoop
// ......
}
}
Sample
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo4Sample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Sample算子演示")
// 上下文对象
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("spark/data/students.txt")
/*
def sample(
withReplacement: Boolean, 去重
fraction: Double, 抽样的比例
seed: Long = Utils.random.nextLong): RDD[T] = {
*/
/**
* sample抽样,1000条数据,抽0.1比例,结果的数量在100左右 不去重
* 这个函数主要在机器学习的时候会用到
*/
val rdd1: RDD[String] = lineRDD.sample(withReplacement = false, fraction = 0.1)
rdd1.foreach(println)
// 结果: 在100条数据左右 每次运行不一样
}
}
GroupBy
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo5GroupBy {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("groupBy")
val sc: SparkContext = new SparkContext(conf)
// 求每个班的平均年龄
val lineRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val arr1: RDD[Array[String]] = lineRDD.map(s => {
s.split(",")
})
//像这种RDD中的元素是(key,value)类型的,我们将这种RDD称之为键值对RDD(kv格式RDD)
val clazzWithAgeRDD: RDD[(String, Int)] = arr1.map {
case Array(_, _, age: String, _, clazz: String) =>
(clazz, age.toInt)
}
// groupBy算子 的使用 分组条件是我们自己指定的 spark中groupBy之后的,所有值会被封装到一个Iterable迭代器中存储
val groupRDD: RDD[(String, Iterable[(String, Int)])] = clazzWithAgeRDD.groupBy(_._1)
val kvRDD: RDD[(String, Double)] = groupRDD.map(kv => {
val clazz: String = kv._1
val avgAge: Double = kv._2.map(_._2).sum.toDouble / kv._2.size
(clazz, avgAge)
})
kvRDD.foreach(println)
// 结果:
//(理科二班,22.556962025316455)
//(文科三班,22.680851063829788)
//(理科四班,22.63736263736264)
//(理科一班,22.333333333333332)
//(文科五班,22.30952380952381)
//(文科一班,22.416666666666668)
//(文科四班,22.506172839506174)
//(理科六班,22.48913043478261)
//(理科三班,22.676470588235293)
//(文科六班,22.60576923076923)
//(理科五班,22.642857142857142)
//(文科二班,22.379310344827587)
}
}
GroupByKey
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo6GroupByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("groupByKey")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
//求每个班级的平均年龄
val arrayRDD: RDD[Array[String]] = linesRDD.map((line: String) => line.split(","))
val clazzWithAgeRDD: RDD[(String, Int)] = arrayRDD.map {
case Array(_, _, age: String, _, clazz: String) =>
(clazz, age.toInt)
}
/**
* GroupByKey属于kv格式的算子,只能作用在kv格式的RDD上
* 也就说,只有kv格式的RDD才能调用kv格式的算子
*/
val gbkRDD: RDD[(String, Iterable[Int])] = clazzWithAgeRDD.groupByKey()
val resRDD: RDD[(String, Double)] = gbkRDD.map(kv => (kv._1, kv._2.sum.toDouble / kv._2.size))
resRDD.foreach(println)
// 结果:
//(理科二班,22.556962025316455)
//(文科三班,22.680851063829788)
//(理科四班,22.63736263736264)
//(理科一班,22.333333333333332)
//(文科五班,22.30952380952381)
//(文科一班,22.416666666666668)
//(文科四班,22.506172839506174)
//(理科六班,22.48913043478261)
//(理科三班,22.676470588235293)
//(文科六班,22.60576923076923)
//(理科五班,22.642857142857142)
//(文科二班,22.379310344827587)
}
}
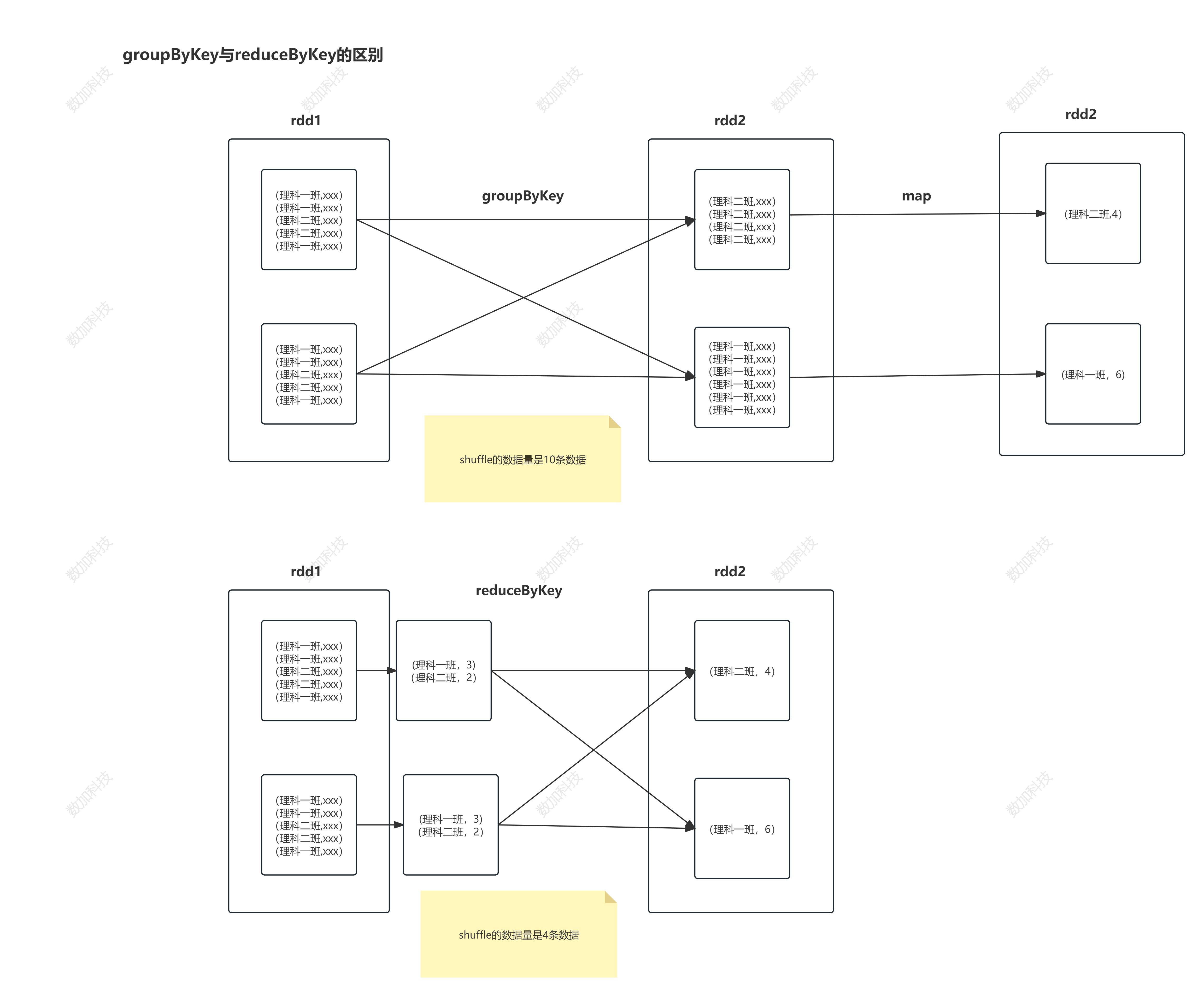
spark core中 groupBy算子与groupByKey算子的区别?
1、代码格式上:
groupBy的分组条件可以自己指定,并且绝大部分的RDD都可以调用该算子,返回的是键和元素本身组成的迭代器构成的kv格式RDD
groupByKey算子,只能由kv格式的RDD进行调用,分组的条件会自动根据键进行分组,不需要在自己指定,返回的是键和值组成的迭代器构成的kv格式RDD
2、执行shuffle数据量来看
groupBy产生的shuffle数据量在一定程度上要大于groupByKey产生的shuffle数据量
所以groupByKey算子的执行效率要比groupBy算子的执行效率要高
ReduceByKey
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo7ReduceByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("ReduceByKey")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/score.txt")
val arrayRDD: RDD[Array[String]] = linesRDD.map((line: String) => line.split(","))
//分别使用groupByKey和reduceByKey计算每个学生的总分
// 封装成只有kv
val idWithScoreRDD: RDD[(String, Int)] = arrayRDD.map {
case Array(id: String, _, score: String) =>
(id, score.toInt)
}
// 先使用groupByKey
val kvRDD1: RDD[(String, Iterable[Int])] = idWithScoreRDD.groupByKey()
val resRDD1: RDD[(String, Int)] = kvRDD1.map(kv => (kv._1, kv._2.sum))
// resRDD1.foreach(println)
//结果
//(1500100724,440)
//(1500100369,376)
//(1500100378,402)
//(1500100306,505)
//(1500100578,397)
//(1500100968,320)
//(1500100690,435) ...
// 使用ReduceByKey
val resRDD2: RDD[(String, Int)] = idWithScoreRDD.reduceByKey(_ + _)
resRDD2.foreach(println)
// 结果
//(1500100883,362)
//(1500100990,422)
//(1500100346,391)
//(1500100178,388)
//(1500100894,371)
//(1500100519,334)
//(1500100905,264)
//(1500100624,317)...
}
}
groupByKey与reduceBykey的区别?
相同点:
- 它们都是kv格式的算子,只有kv格式的RDD才能调用
不同点:
- 1)groupByKey只是单纯地根据键进行分组,分组后的逻辑可以在后续的处理中调用其他的算子实现
- 2)reduceByKey 相当于MR中的预聚合,所以shuffle产生的数据量要比groupByKey中shuffle产生的数据量少,效率高,速度要快一些
- 3)groupByKey的灵活度要比reduceByKey灵活度要高,reduceBykey无法做一些复杂的操作,比如方差。但是groupByKey可以在分组之后的RDD进行方差操作
图解:
Union
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo8Union {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("reduceByKey")
val sc: SparkContext = new SparkContext(conf)
//parallelize:将scala的集合变成spark中的RDD
val rdd1: RDD[(String, String)] = sc.parallelize(List(
("1001", "fy"),
("1002", "fy2"),
("1003", "fy3"),
("1004", "fy4"),
("1005", "fy5")
))
println(s"rdd1的分区数:${rdd1.getNumPartitions}")
val rdd2: RDD[(String, String)] = sc.parallelize(List(
("1006", "fz6"),
("1007", "fz7"),
("1008", "fz8"),
("1003", "fy3"),
("1009", "fz9")
))
println(s"rdd2的分区数:${rdd2.getNumPartitions}")
val rdd3: RDD[(String, Int)] = sc.parallelize(List(
("1006", 1),
("1007", 2),
("1008", 3),
("1003", 4),
("1009", 5)
))
//两个RDD要想进行union合并,必须保证元素的格式和数据类型是一致的
//分区数也会进行合并,最终的分区数由两个RDD总共的分区数决定
// rdd1.union(rdd3) 不行
val resRDD1: RDD[(String, String)] = rdd1.union(rdd2)
resRDD1.foreach(println) // 结果看不出端倪 打印分区看看
println(s"resRDD1的分区数:${resRDD1.getNumPartitions}")
// 结果
//rdd1的分区数:1
//rdd2的分区数:1
//resRDD1的分区数:2
}
}
Join
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* join算子也要作用在kv格式的RDD上
*/
object Demo9Join {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Join")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[(String, String)] = sc.parallelize(List(
("1001", "1号"),
("1002", "2号"),
("1003", "3号"),
("1004", "4号"),
("1005", "5号")
))
val rdd2: RDD[(String, String)] = sc.parallelize(List(
("1001", "看美女"),
("1002", "看综艺"),
("1003", "看八卦"),
("1004", "打游戏"),
("1009", "学习")
))
/**
* join 内连接
* right join 右连接
* left join 左连接
* full join 全连接
*/
// join 内连接 两个rdd共同拥有的键才会进行关联
// val resRDD1: RDD[(String, (String, String))] = rdd1.join(rdd2)
// val resRDD2: RDD[(String, String, String)] = resRDD1.map {
// case (id: String, (name: String, like: String)) =>
// (id, name, like)
// }
// resRDD2.foreach(println)
//right join 右连接 保证右边rdd键的完整性
// val resRDD2: RDD[(String, (Option[String], String))] = rdd1.rightOuterJoin(rdd2)
// val resRDD3: RDD[(String, String, String)] = resRDD2.map {
// case (id: String, (Some(name), like: String)) =>
// (id, name, like)
// case (id: String, (None, like: String)) =>
// (id, "查无此人", like)
// }
// resRDD3.foreach(println)
//TODO:自己完成左关联
// left join 左连接 保证左边rdd键的完整性
val resRDD2: RDD[(String, (String, Option[String]))] = rdd1.leftOuterJoin(rdd2)
val resRDD3: RDD[(String, String, String)] = resRDD2.map {
case (id: String, (name: String, Some(like))) =>
(id, name, like)
case (id: String, (name: String, None)) =>
(id, name, "此人无爱好")
}
resRDD3.foreach(println)
// 结果
// (1005,5号,此人无爱好)
// (1001,1号,看美女)
// (1002,2号,看综艺)
// (1004,4号,打游戏)
// (1003,3号,看八卦)
// //全关联
// val resRDD2: RDD[(String, (Option[String], Option[String]))] = rdd1.fullOuterJoin(rdd2)
// val resRDD3: RDD[(String, String, String)] = resRDD2.map {
// case (id: String, (Some(name), Some(like))) =>
// (id, name, like)
// case (id: String, (Some(name), None)) =>
// (id, name, "此人无爱好")
// case (id: String, (None, Some(like))) =>
// (id, "查无此人", like)
// }
// resRDD3.foreach(println)
}
}
MapValues
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10MapValues {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
// 给每个人的年龄加上100
val kvRDD1: RDD[(String, Int)] = linesRDD.map(_.split(",")).map {
case Array(_, name:String, age:String, _,_) =>
(name, age.toInt)
}
/**
* mapValues函数也是作用在kv格式的算子上
* 将每个元素的值传递给后面的函数,进行处理得到新的值,键不变,这个处理后的组合重新返回到新的RDD中
*/
kvRDD1.mapValues(_ + 100).foreach(println)
//(于从寒,123)
//(凌智阳,121)
//(卞乐萱,121)
//(于晗昱,122)
//(濮恨蕊,123)
//(戚昌盛,122)
//(满慕易,121)
}
}
mapPartitions
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo11PartitionBy {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("mapPartitions算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/wcs/*")
/**
* mapPartitions:一次处理一个分区中的数据
* 它与map的区别在于,map是每次处理一条数据就返回一条数据到下一个rdd
* 而mapPartitions一次处理一个分区的数据,处理完再返回
* 最后的处理效果和map的处理效果是一样的
*
* mapPartition可以优化与数据库连接的次数
*/
// s是Iterator[String]类型
val rdd1: RDD[String] = linesRDD.mapPartitions(s => {
println("=========================") // 打印了两次 对应两个分区
s.map(e => {
e
})
})
rdd1.foreach(println)
}
}
SortBy
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo12SortBy {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("SortBy算子演示")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(List(34, 123, 6, 1, 231, 1, 34, 56, 2))
val rdd2: RDD[Int] = rdd1.sortBy((e: Int) => e)
rdd2.foreach(println)
//1
//1
//2
//6
//34
//34
//56
//123
//231
}
}
行动算子
Foreach
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo13Foreach {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("foreach算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val rdd1: RDD[Array[String]] = linesRDD.map((e: String) => {
e.split(",")
})
val rdd2: RDD[(String, String, String, String, String)] = rdd1.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
/**
* 行动算子,就可以触发一次作业执行,有几次行动算子调用,就会触发几次
*
* rdd是懒加载的性质
*/
// rdd2.foreach(println)
// println("====================================")
// rdd2.foreach(println)
println("哈哈哈") // 一定会打印,不属于spark作业中的语句
val rdd3: RDD[(String, String, String, String, String)] = rdd2.map((t5: (String, String, String, String, String)) => {
println("===============================") // 没有行动算子时 不会打印
t5
})
println("嘿嘿嘿")// 不是Spark作业里的
rdd3.foreach(println) // 数据和"===============================" 交替打印
}
}
Collect
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo14collect {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Collect算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val rdd1: RDD[Array[String]] = linesRDD.map((e: String) => {
e.split(",")
})
val rdd2: RDD[Student] = rdd1.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student(id.toInt, name, age.toInt, gender, clazz)
}
//collect将rdd转成合适的scala中的数据结构
val stuArr: Array[Student] = rdd2.collect()
//foreach是scala中的foreach,不会产生作业执行的
stuArr.foreach(println)
}
}
case class Student(id:Int,name:String,age:Int,gender:String,clazz:String)
算子应用
// 求总分前十的学生的各科成绩:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo15StudentTest1 {
def main(args: Array[String]): Unit = {
//求年级总分前10的学生各科分数的详细信息
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/score.txt")
val idWithScoreRDD: RDD[(String, String, Int)] = linesRDD.map((line: String) => {
line.split(",") match {
case Array(id: String, subject_id: String, score: String) =>
(id, subject_id, score.toInt)
}
})
val array1: Array[String] = idWithScoreRDD
.map((t3: (String, String, Int)) => (t3._1, t3._3))
.reduceByKey(_ + _)
.sortBy((kv: (String, Int)) => -kv._2)
.take(10) // take 也是行动算子
.map(_._1)
idWithScoreRDD.filter((t3: (String, String, Int)) => {
val bool: Boolean = array1.contains(t3._1)
if(bool){
println("存在")
}
bool
}).foreach((t3: (String, String, Int)) => {
println("==========================")
println(t3)
})
}
}
缓存
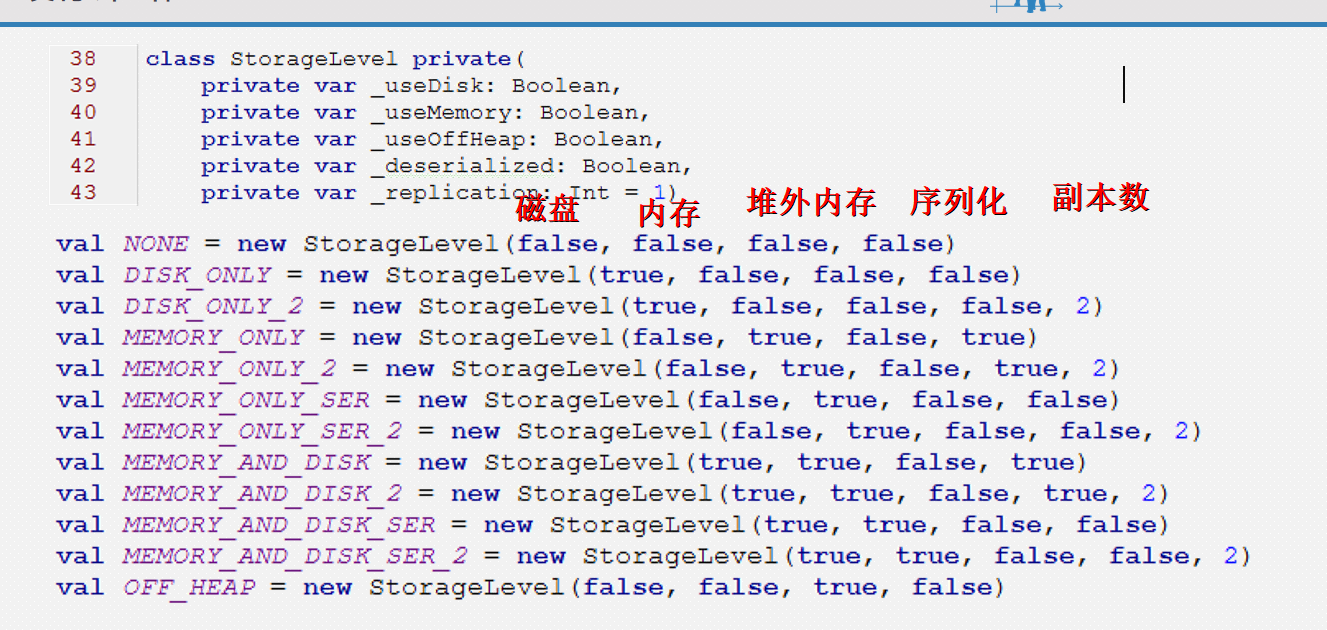
缓存级别
cache
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
object Demo16cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("缓存演示")
val sc: SparkContext = new SparkContext(conf)
//===================================================================
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val studentsRDD: RDD[Student2] = linesRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student2(id, name, age.toInt, gender, clazz)
}
/**
* 缓存:
运行结束后 就消失了
* 缓存的目的是为了spark core作业执行的时候,缩短rdd的执行链,能够更快的得到结果
* 缓存的目的是避免每一次job作业执行的时候,都需要从第一个rdd算起
* 对重复使用RDD进行缓存
* cache 设置不了缓存级别
* persist 可以设置缓存级别
* 缓存的实现方式:
* 1、需要缓存的rdd调用cache函数
* 2、persist(StorageLevel.MEMORY_ONLY) 修改缓存级别
*
*/
studentsRDD.cache() //默认将rdd缓存到内存中,缓存级别为memory_only
// studentsRDD.persist(StorageLevel.MEMORY_AND_DISK) // 可以修改 这里改为加上磁盘(有时候内存不够的话)
// 需求1和2都重复使用了studentsRDD 可以放在一个地方 随用随拿 不用从第一个RDD开始运行
//需求1:求每个班级的人数
studentsRDD.groupBy(_.clazz).map(kv=>{
(kv._1,kv._2.size)
}).foreach(println)
//(理科二班,79)
//(文科三班,94)
//(理科四班,91)
//(理科一班,78)
//(文科五班,84)
//(文科一班,72)
//(文科四班,81)
//(理科六班,92)
//(理科三班,68)
//(文科六班,104)
//(理科五班,70)
//(文科二班,87)
//需求2:求每个年龄的人数
studentsRDD.groupBy(_.age)
.map(kv=>(kv._1,kv._2.size))
.foreach(println)
//(21,234)
//(22,271)
//(24,260)
//(23,235)
while(true){
}
}
}
case class Student2(id:String,name:String,age:Int,gender:String,clazz:String)
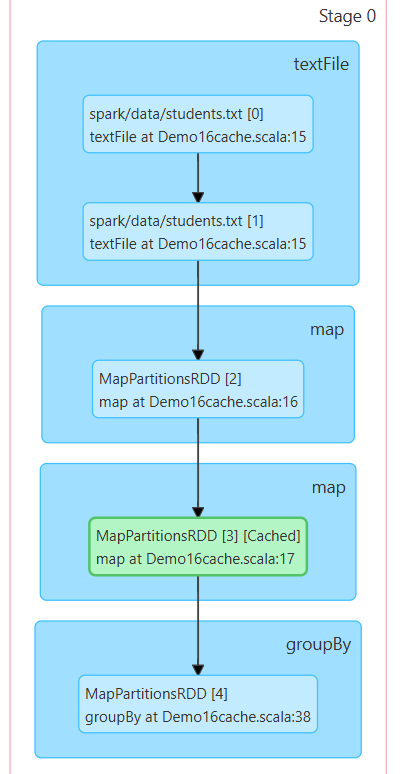
进入spark jobs 查看 DAG 在map阶段就从cache里拿RDD了。
checkpoint
永久的保存数据
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo17Checkpoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("缓存演示")
val sc: SparkContext = new SparkContext(conf)
//设置检查点的存储路径
sc.setCheckpointDir("spark/data/checkpoint1")
//===================================================================
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val studentsRDD: RDD[Student2] = linesRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student2(id, name, age.toInt, gender, clazz)
}
/**
* 永久将执行过程中RDD中流动的数据存储到磁盘(hdfs)中
* checkpoint
*
* 需要设置checkpoint的路径,统一设置的
*
* checkpoint也相当于一个行动算子,触发作业执行
* 第二次DAG有向无环图执行的时候,直接从最后一个有检查点的rdd开始向下执行
*/
studentsRDD.checkpoint()// 必须得设置路径 在SparkContext 设置
//需求1:求每个班级的人数
val rdd1: RDD[(String, Iterable[Student2])] = studentsRDD.groupBy(_.clazz)
val resRDD1: RDD[(String, Int)] = rdd1.map((kv: (String, Iterable[Student2])) => (kv._1, kv._2.size))
resRDD1.foreach(println)
//需求2:求每个年龄的人数
val rdd2: RDD[(Int, Iterable[Student2])] = studentsRDD.groupBy(_.age)
val resRDD2: RDD[(Int, Int)] = rdd2.map((kv: (Int, Iterable[Student2])) => (kv._1, kv._2.size))
resRDD2.foreach(println)
while (true) {
}
}
}
checkpoint和cache的区别?
- cache是将一个复杂的RDD做缓存,将来执行的时候,只是这个rdd会从缓存中取 数据量小
- checkpoint是永久将rdd数据持久化,将来执行的时候,直接从检查点的rdd往后执行 数据量大 逻辑简单
本地搭建Spark
下载spark-3.1.3-bin-hadoop3.2.tgz
(https://mirrors.huaweicloud.com/apache/spark/spark-3.1.3/)
上传解压:
tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz
改名
mv spark-3.1.3-bin-hadoop3.2/ spark-3.1.3
更该所属用户所属组
chown -R root:root spark-3.1.3/
添加环境变量
SPARK_HOME=/usr/local/soft/spark-3.1.3
export PATH=$SPARK_HOME/bin:$PATH
修改配置文件 conf
cp spark-env.sh.template spark-env.sh
增加配置
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
#master相当于RM worker相当于NM
增加从节点配置
cp workers.template workers
# 增加
node1
node2
复制到其它节点
scp -r spark-3.1.3 node1:`pwd`
scp -r spark-3.1.3 node2:`pwd`
撰写运行spark脚本
vim startspark.sh
#! /bin/bash
/usr/local/soft/spark-3.1.3/sbin/start-all.sh
给脚本赋予执行权限
chmod +x startspark.sh
访问spark ui
http://master:8080/
standalone
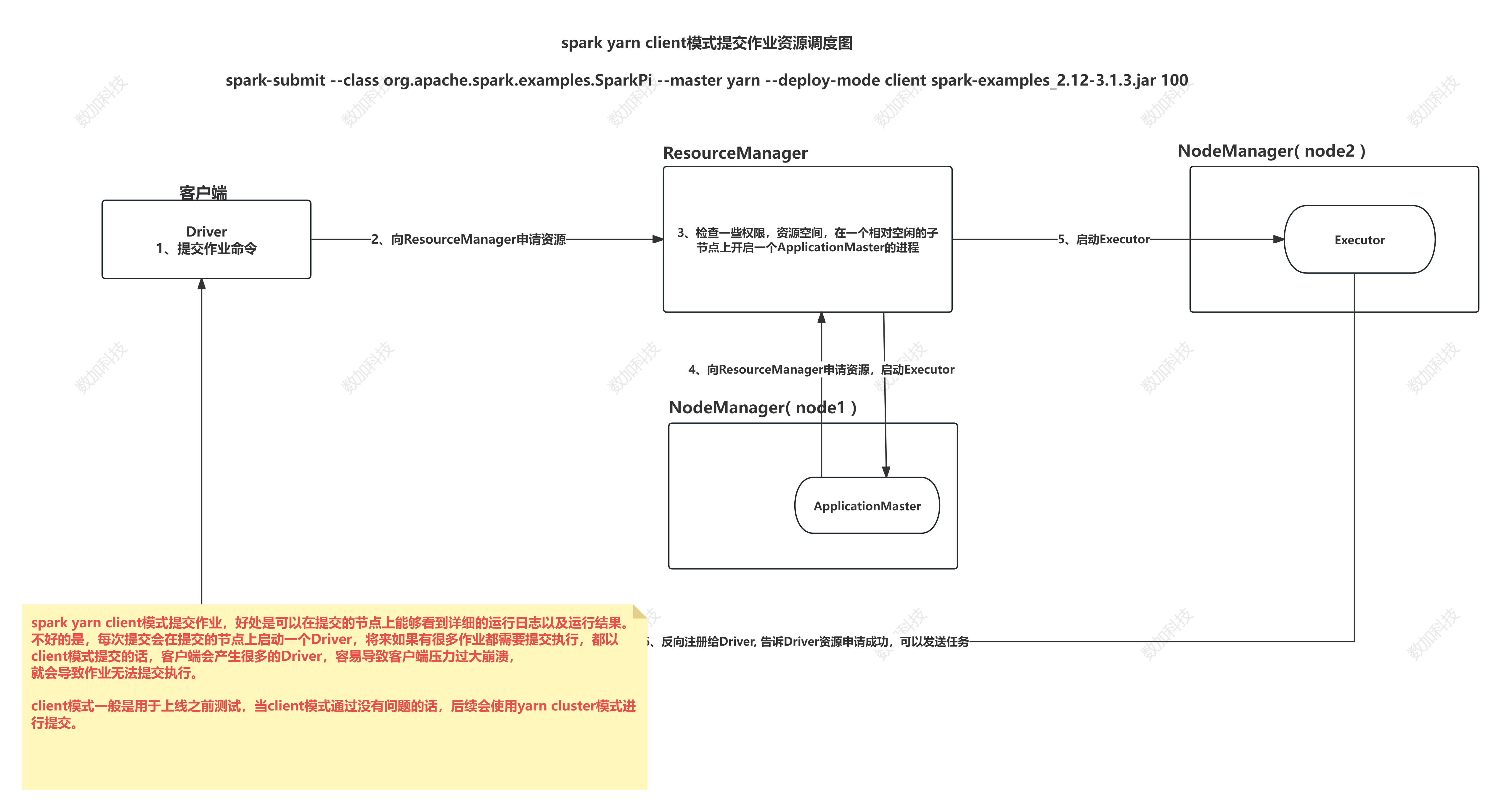
client模式
日志在本地输出,不需要开启hadoop一般用于上线前测试(bin/下执行)
使用spark样例 运行计算圆周率
/usr/local/soft/spark-3.1.3/examples/jars/spark-examples_2.12-3.1.3.jar
#提交spark任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.12-3.1.3.jar 10
# 10 是并行度 分区数 这里更大更精确
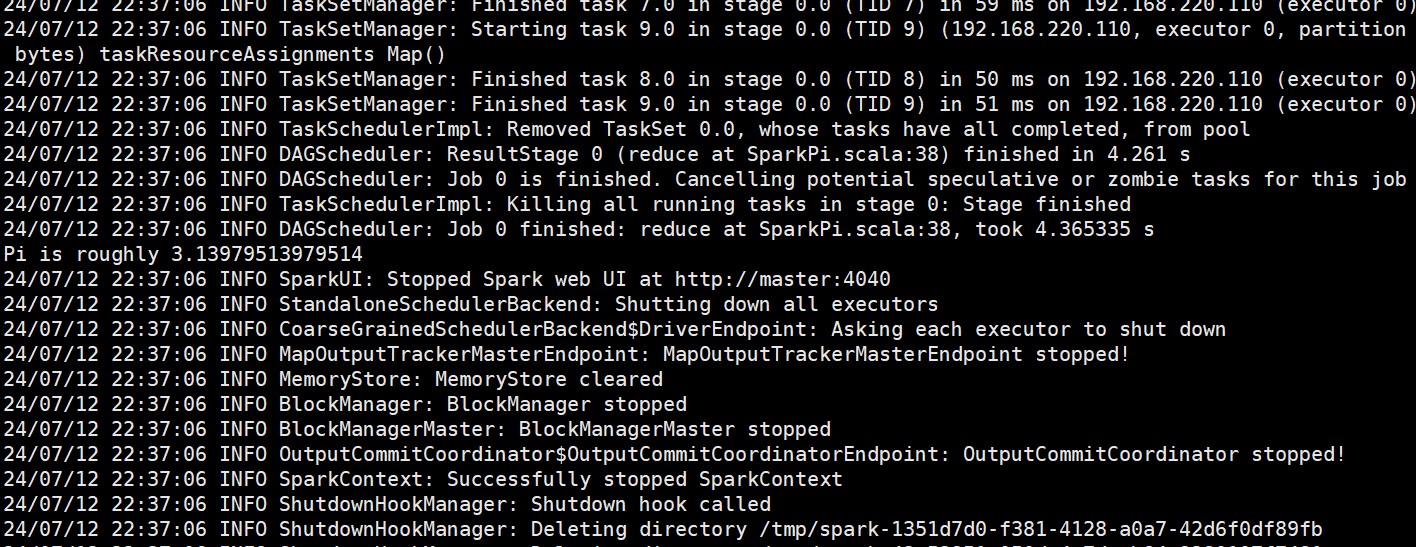
日志在本地显示
cluster模式
上线使用,不会再本地打印日志 集群化运行
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-examples_2.12-3.1.3.jar 100

spark-shell
spark 提供的一个交互式的命令行,可以直接写代码
编写代码打包上传在standalone下运行
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo18Standalone {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("standalone集群运行")
val sc: SparkContext = new SparkContext(conf)
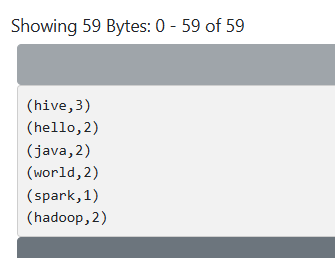
//统计单词个数
val rdd1: RDD[String] = sc.parallelize(List("hive|java|hello|world", "hive|java|hadoop|world", "hive|spark|hello|hadoop"))
rdd1.flatMap(_.split("\\|"))
.map((_,1))
.reduceByKey(_+_)
.foreach(println)
/**
* standalone
* - client模式提交命令:
* spark-submit --class com.shujia.core.Demo18Standalone --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar 10
*
* - cluster模式提交命令:
* spark-submit --class com.shujia.core.Demo18Standalone --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-1.0.jar 10
*
*
*/
}
}
client模式运行结果
cluster模式运行:
将jar包发给node1 和node2中
scp spark-1.0.jar node1:/usr/local/soft/spark-3.1.3/jars/
scp spark-1.0.jar node2:/usr/local/soft/spark-3.1.3/jars/
mv spark-1.0.jar /usr/local/soft/spark-3.1.3/jars/
yarn
停止spark集群
在spark sbin目录下执行 ./stop-all.sh
spark整合yarn只需要在一个节点整合, 可以删除node1 和node2中所有的spark 文件
增加hadoop 配置文件地址
vim spark-env.sh
#增加
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.3/etc/hadoop
往yarn提交任务需要增加两个配置 yarn-site.xml(/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml)
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/soft/hadoop-3.1.3/etc/hadoop:/usr/local/soft/hadoop-3.1.3/share/
hadoop/common/lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/common/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/hdfs:/usr/local/soft/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/hdfs/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/mapreduce/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/yarn:/usr/local/soft/hadoop-3.1.3/share/hadoop/yarn/lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value>
</property>
同步到其他节点,重启yarn
scp -r yarn-site.xml node1:`pwd`
scp -r yarn-site.xml node2:`pwd`
spark on yarn client模式 日志在本地输出,一班用于上线前测试
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client spark-examples_2.12-3.1.3.jar 100

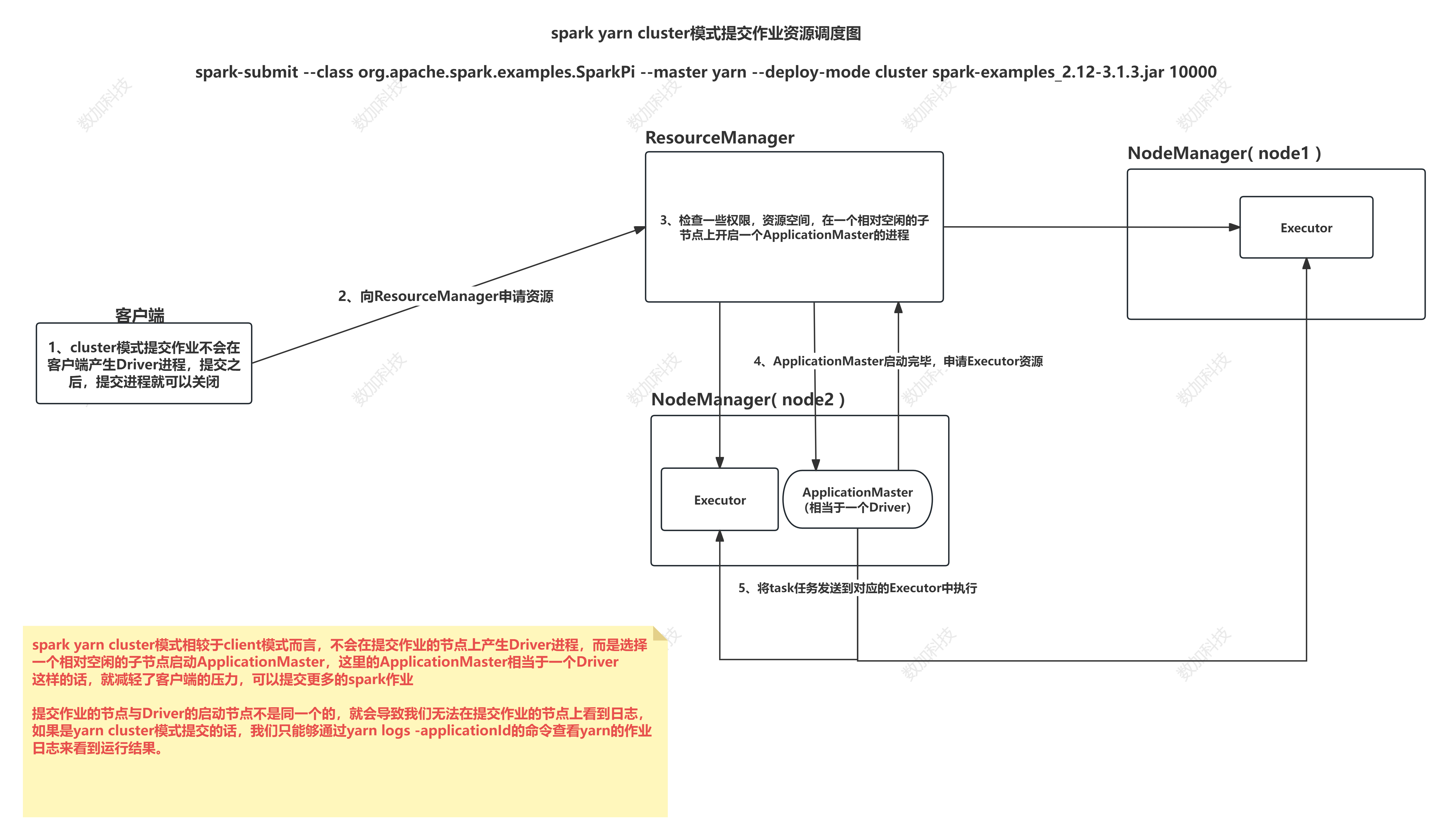
spark on yarn cluster模式 上线使用,不会再本地打印日志 减少io
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster spark-examples_2.12-3.1.3.jar 100
yarn logs -applicationId application_1720850173901_0001 # 查看日志
案例:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//读取hdfs上的学生数据,统计每个班级的人数,写回到hdfs上
object Demo19YarnCluster {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("spark yarn cluster")
val sc: SparkContext = new SparkContext(conf)
//如果是打包到集群的话,这里的路径就是hdfs路径
//如果是local的话,这个路径就是我们windows的路径
val linesRDD: RDD[String] = sc.textFile("/bigdata30/students.csv")
//coalesce函数,repartition函数可以修改分区
// val linesRDD2: RDD[String] = linesRDD.coalesce(1)
// linesRDD.repartition(1)
println("=============================================================================================================")
println(s"========================== linesRDD的分区数是:${linesRDD.getNumPartitions} ===================================")
println("=============================================================================================================")
val clazzKVRDD: RDD[(String, Int)] = linesRDD.map((line: String) => {
line.split(",") match {
case Array(_, _, _, _, clazz: String) =>
(clazz, 1) // 班级和1构成的键值对
}
})
val resultRDD: RDD[(String, Int)] = clazzKVRDD.reduceByKey(_ + _)
val resultRDD2: RDD[String] = resultRDD.map((t2: (String, Int)) => s"${t2._1},${t2._2}")
println("=============================================================================================================")
println(s"========================== resultRDD2的分区数是:${resultRDD2.getNumPartitions} ===================================")
println("=============================================================================================================")
//行动算子,触发作业执行
resultRDD2.saveAsTextFile("/bigdata30/sparkout1")
}
}
打包上传 在jar包目录下运行
spark-submit --class com.shujia.core.Demo19YarnCluster --master yarn --deploy-mode cluster spark-1.0.jar
在HDFS上可以看到结果
术语解释
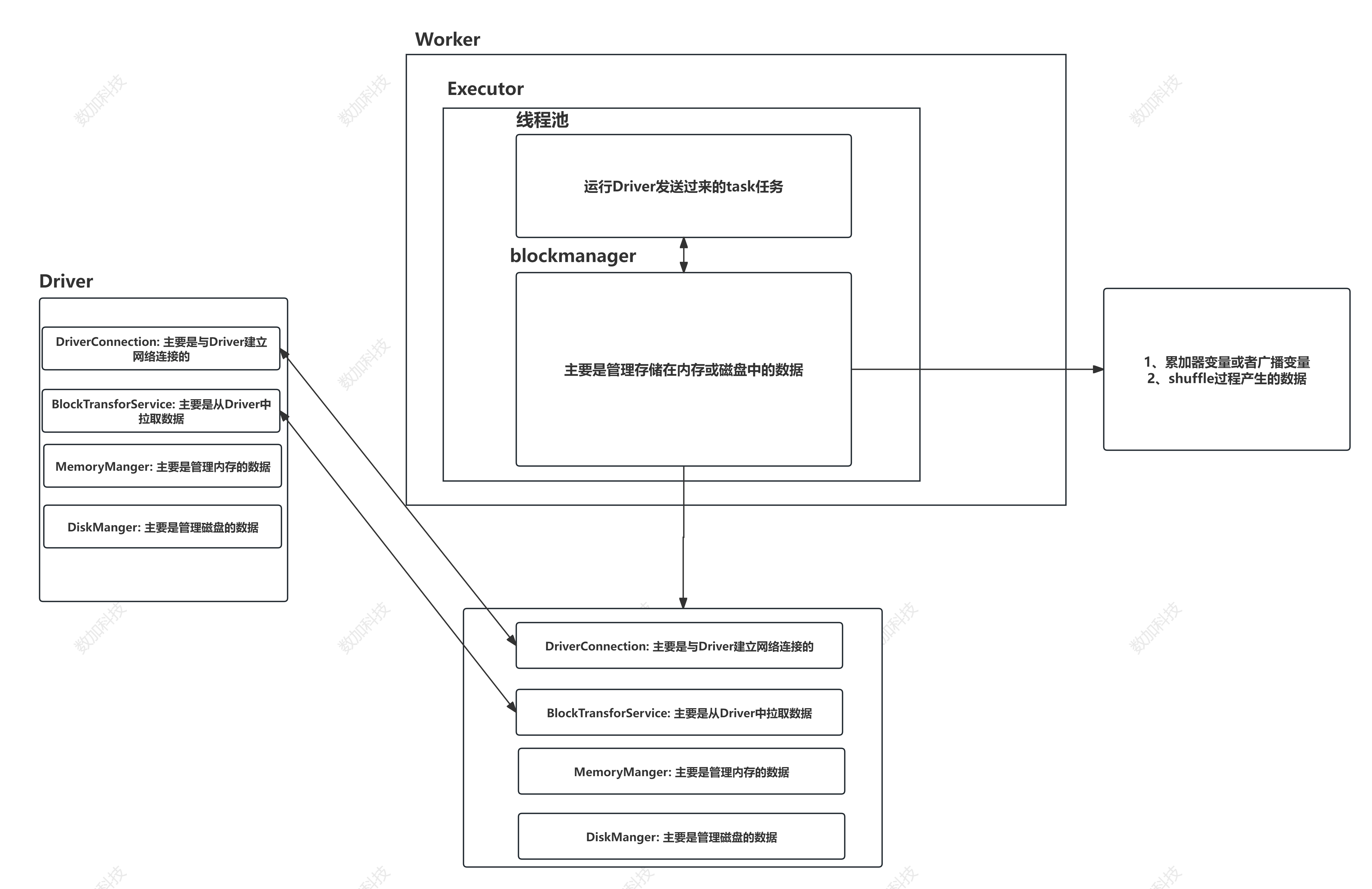
Application:基于Spark的应用程序,包含了driver程序和 集群上的executor
DriverProgram:运行main函数并且新建SparkContext的程序
ClusterManager:在集群上获取资源的外部服务(例如 standalone,Mesos,Yarn )
WorkerNode:集群中任何可以运行应用用代码的节点
Executor:是在一个workernode上为某应用用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用用都有各自自独立的executors
Task:被送到某个executor上的执行单元 线程
Job:包含很多任务的并行计算的task,可以看做和Spark的action对应,每个action都会触发一个job任务
Stage:一个Job会被拆分很多组任务,每组任务被称为Stage(就像MapReduce分map任务和reduce任务一样)
任务调度
包含 重试机制 推测执行机制
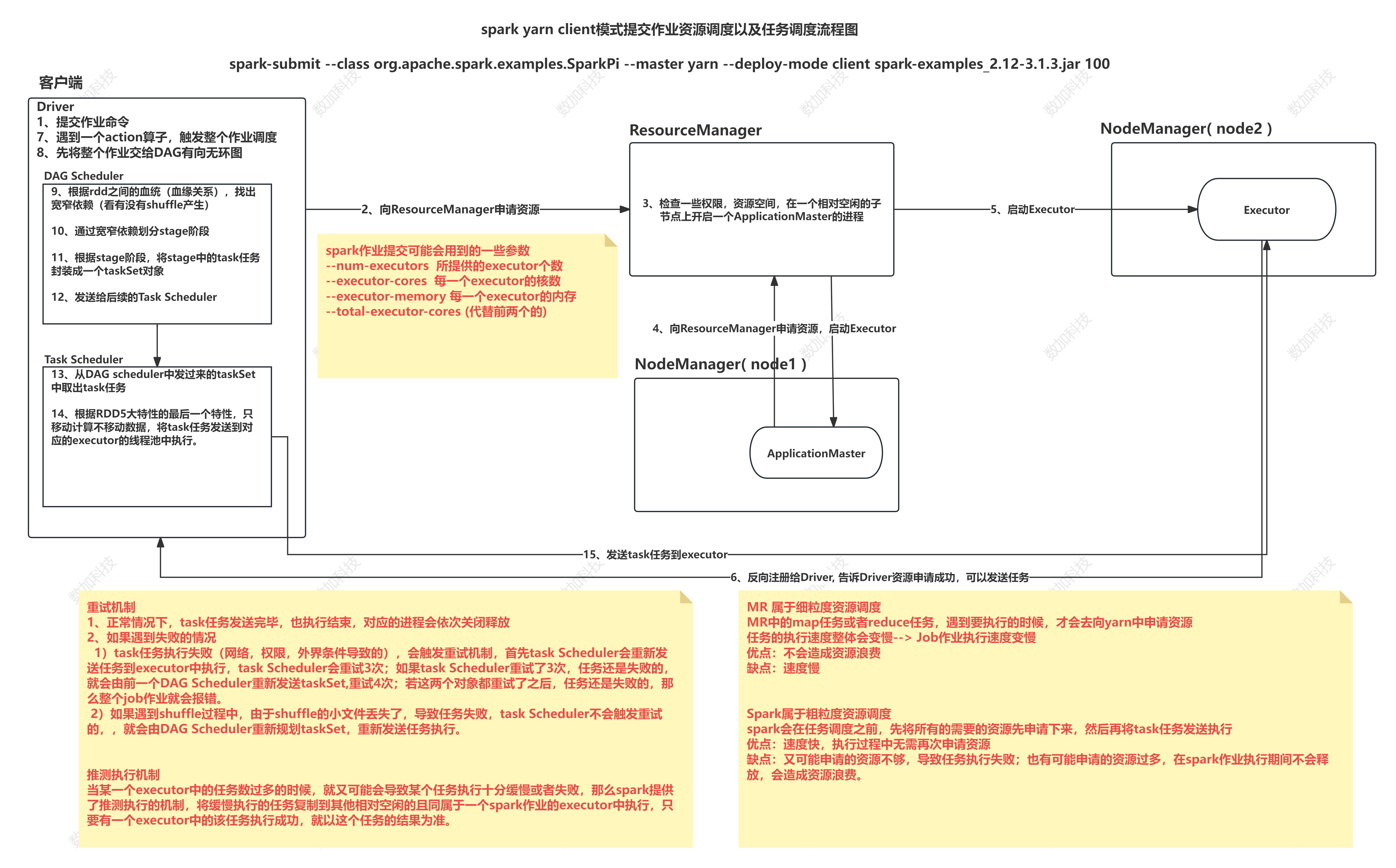
DAG Scheduler:
基于Stage构建DAG,决定每个任务的最佳位置
记录哪个RDD或者Stage输出被物化
将taskset传给底层调度器TaskScheduler
重新提交shuffle输出丢失的stage
Task Scheduler:
提交taskset(一组并行task)到集群运行并汇报结果
出现shuffle输出lost要报告fetchfailed错误
碰到straggle任务需要放到别的节点上重试
为每一一个TaskSet维护一一个TaskSetManager(追踪本地性及错误信息)
累加器
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object Demo21Accumulator {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("累加器案例")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
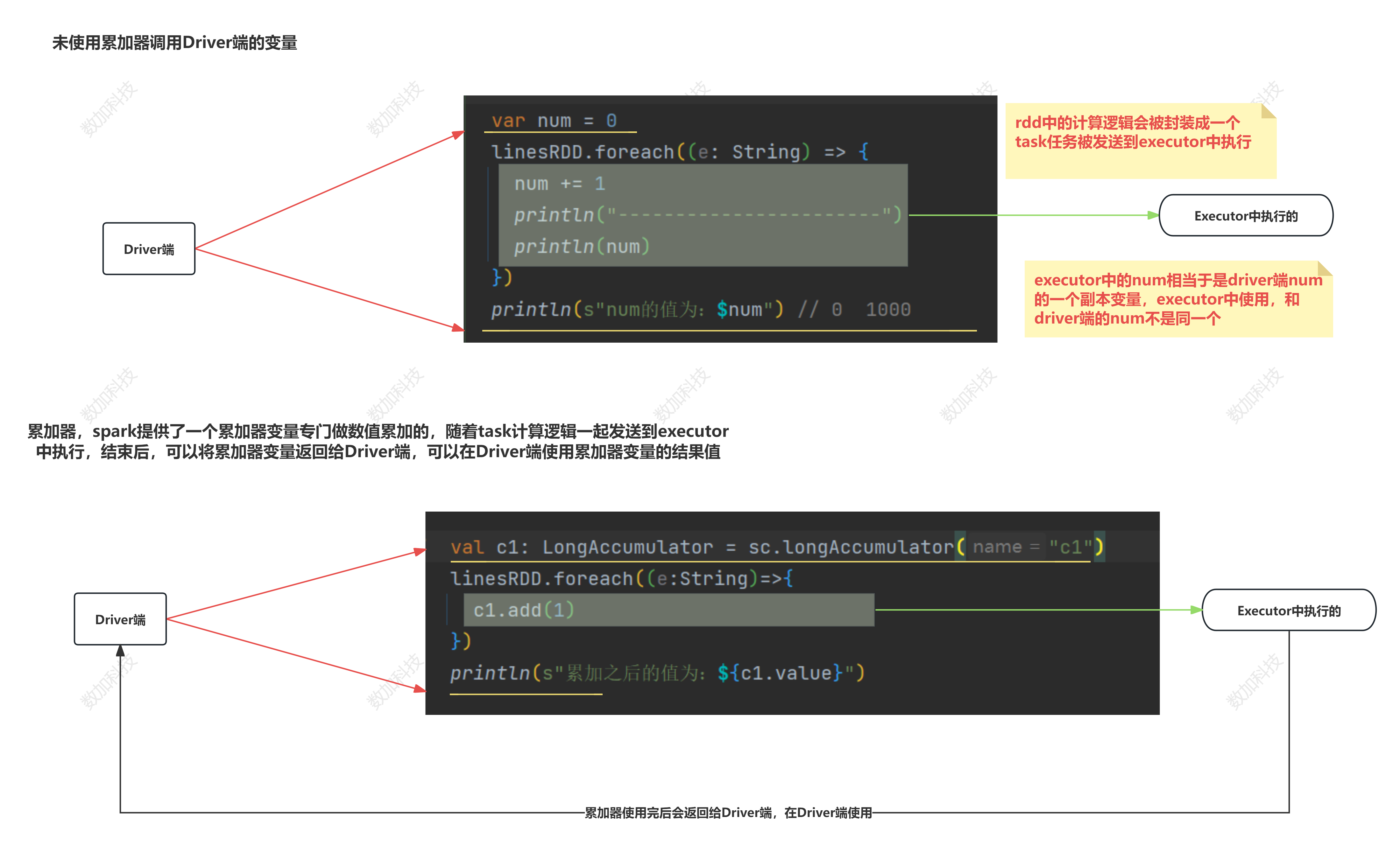
// var num = 0
/**
* 累加器
* 必要有行动算子触发作业执行
* 1.因为累加器的执行是在RDD中执行的,而RDD是在Executor中执行的,而要想在Executor中执行就得有一个action算子触发任务调度
*
*/
// linesRDD.foreach((e: String) => {
// num += 1
// println("-----------------------")
// println(num) // 可以到1000
// })
// println(s"num的值为:$num") // 0
//使用累加器
// 创建累加器变量
val c1: LongAccumulator = sc.longAccumulator("c1")
linesRDD.foreach((e:String)=>{
c1.add(1)
})
println(s"累加之后的值为:${c1.value}")
//使用累加器
// 使用map时 必须加上行动算子触发作业执行
// val c1: LongAccumulator = sc.longAccumulator("c1")
// linesRDD.map((e: String) => {
// c1.add(1)
// }).collect()
// println(s"累加之后的值为:${c1.value}")
}
}
Spark RDD 注意事项
/**
* 写spark core程序的注意事项
* 1、RDD中无法嵌套使用RDD
* 2、RDD中无法使用SparkContext
*/
val studentLinesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val scoreLinesRDD: RDD[String] = sc.textFile("spark/data/score.txt")
val rdd1: RDD[RDD[(String, String)]] = studentLinesRDD.map((line1: String) => {
scoreLinesRDD.map((line2: String) => {
val s1: String = line1.split(",").mkString("|")
val s2: String = line2.split(",").mkString("|")
(s1, s2)
})
})
rdd1.foreach(println) // 报错
// val studentLinesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
// val scoreLinesRDD: RDD[String] = sc.textFile("spark/data/score.txt")
//
// val rdd1: RDD[RDD[(String, String)]] = studentLinesRDD.map((line1: String) => {
// sc.textFile("spark/data/score.txt").map((line2: String) => {
// val s1: String = line1.split(",").mkString("|")
// val s2: String = line2.split(",").mkString("|")
// (s1, s2)
// })
// })
广播变量
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
import scala.io.{BufferedSource, Source}
/**
* 广播大变量
*/
object Demo22Broadcast {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("广播变量")
val sc: SparkContext = new SparkContext(conf)
val bs: List[String] = Source.fromFile("spark/data/students.txt").getLines().toList
//map1变量在Driver端
//会随着task任务一并发送到executor中执行,后期随着map1的数据量变大
//也就意味着,每次发送任务,附带的数据量就会很大,无形之中,降低的执行速度
val map1: mutable.Map[String, String] = new mutable.HashMap[String, String]()
for (elem <- bs) {
val array1: Array[String] = elem.split(",")
val id: String = array1(0)
val name: String = array1(1)
val age: String = array1(2)
val gender: String = array1(3)
val clazz: String = array1(4)
map1.put(id, name + "," + age + "," + gender + "," + clazz)
}
/**
* 广播变量
* 使用SparkContext中的一个功能,将Driver端的变量广播到executor执行的节点上的blockManager中
*/
val bc: Broadcast[mutable.Map[String, String]] = sc.broadcast(map1)
val scoreRDD: RDD[String] = sc.textFile("spark/data/score.txt")
//未使用广播变量
// val resRDD: RDD[(String, String, String)] = scoreRDD.map((line: String) => {
// val array1: Array[String] = line.split(",")
// val id: String = array1(0)
// // 通过map1的变量,通过键获取值
// val info: String = map1.getOrElse(id, "查无此人") // map1相当于一个副本与task任务一起发送到Executor中执行
// val score: String = array1(2)
// (id, info, score)
// })
//使用广播变量
//以广播变量的形式,发送到Executor中的blockManager中
// 只发送计算逻辑
val resRDD: RDD[(String, String, String)] = scoreRDD.map((line: String) => {
val array1: Array[String] = line.split(",")
val id: String = array1(0)
//通过广播过来的大变量,进行关联数据 .value 方法取出变量
val map2: mutable.Map[String, String] = bc.value
val info: String = map2.getOrElse(id, "查无此人")
val score: String = array1(2)
(id, info, score)
})
resRDD.foreach(println)
}
}
BlockManager:
Spark Sql
Spark SQL是Spark的核心组件之一
与RDD类似,DataFrame也是一个分布式数据容器,是spark sql的重要的数据结构
初识spark sql: WordCount
数据准备

spark sql处理数据的步骤
- 1、读取数据源
- 2、将读取到的DF注册成一个临时视图
- 3、使用sparkSession的sql函数,编写sql语句操作临时视图,返回的依旧是一个DataFrame
- 4、将结果写出到hdfs上
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
// spark sql的环境
val ss: SparkSession = SparkSession.builder()
.master("local")
.appName("sql语法")
.getOrCreate()
// spark sql是spark core的上层api,如果要想使用rdd的编程
// 可以直接通过sparkSession获取SparkContext对象
// val context: SparkContext = ss.sparkContext
// 读文件
//spark sql的核心数据类型是DataFrame
val df1: DataFrame = ss.read
.format("csv") // 读取csv格式的文件,但是实际上这种做法可以读取任意分隔符的文本文件
.option("sep", "\n") //指定读取数据的列与列之间的分隔符
.schema("line String") // 指定表的列字段 包括列名和列数据类型
.load("spark/data/wcs/words.txt")
// 查看dataframe的数据内容
// df1.show()
//查看表结构
// df1.printSchema()
/**
* sql语句是无法直接作用在DataFrame上面的
* 需要提前将要使用sql分析的DataFrame注册成一张表(临时视图)
*/
//老版本的做法将df注册成一张表
// df1.registerTempTable("wcs")
df1.createOrReplaceTempView("wcs")
/**
* 编写sql语句作用在表上
* sql语法是完全兼容hive语法
*/
val df2: DataFrame = ss.sql(
"""
|select
|t1.word,
|count(1) as counts
|from(
|select
|explode(split(line,'\\|')) as word
|from wcs) t1 group by t1.word
|""".stripMargin)
df2.show() // show默认结果只展示20条数据
//通过观察源码发现,DataFrame底层数据类型其实就是封装了DataSet的数据类型
val resDS: Dataset[Row] = df2.repartition(1) // 设置分区为1 合并分区
//将计算后的DataFrame保存到本地磁盘文件中
resDS.write
.format("csv") //csv文件默认的分隔符是英文逗号
.option("sep","\t") // 设置分隔符
.mode(SaveMode.Overwrite) // 如果想每次覆盖之前的执行结果的话,可以在写文件的同时指定写入模式,使用模式枚举类
.save("spark/data/sqlOut1") // 路径是一个文件夹
}
}

DSL WordCount
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo2DSLWordCount {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("DSL语法风格编写spark sql")
.getOrCreate()
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("line STRING")
.option("sep", "\n")
.load("spark/data/wcs/words.txt")
/**
* 如果要想使用DSL语法编写spark sql的话,需要导入两个隐式转换
*/
//将sql中的函数,封装成spark程序中的一个个的函数直接调用,以传参的方式调用
import org.apache.spark.sql.functions._
//主要作用是,将来可以在调用的函数中,使用$函数,将列名字符串类型转成一个ColumnName类型
//而ColumnName是继承自Column类的
import sparkSession.implicits._
//老版本聚合操作
// df1.select(explode(split($"line","\\|")) as "word")
// .groupBy($"word")
// .count().show()
//新版本聚合操作
val resDF: DataFrame = df1.select(explode(split($"line", "\\|")) as "word")
.groupBy($"word")
.agg(count($"word") as "counts")
resDF.repartition(1)
.write
.format("csv")
.option("sep","\t")
.mode(SaveMode.Overwrite)
.save("spark/data/sqlOut2")
}
}
DSl语法
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo3DSLApi {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val sparkSession: SparkSession = SparkSession.builder()
.config("spark.sql.shuffle.partitions","1") // 设置分区数 全局设置
.master("local")
.appName("DSL语法风格编写spark sql")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
// 读取json文件 转成DF
// 读取json数据的时候,是不需要指定表结构,可以自动根据json的键值来构建DataFrame
// sparkSession.read
// .format("json")
// .load("spark/data/students.json")
// 新版
val df1: DataFrame = sparkSession.read.json("spark/data/students.json")
// df1.show(100) // 可以指定读取数据行数
// 一列值过长时,不能完全显示 传入第二个参数,使其更详细
// df1.show(100,truncate = false)
/*
* DSL 语法的函数
* */
/*
*select
*类似于纯sql语法中的select关键字,传入要查询的列
*/
//LIKE:select name,clazz from xxx;
// df1.select("name","clazz").show()
// another type
// df1.select($"name", $"age").show()
//查询每个学生的姓名,原本的年龄,年龄+1
/**
* 与select功能差不多的查询函数
* 如果要以传字符串的形式给到select的话,并且还想对列进行表达式处理的话,可以使用selectExpr函数
*/
// df1.selectExpr("name","age","age+1 as new_age").show()
//如果想要使用select函数查询的时候对列做操作的话,可以使用$函数将列变成一个对象
// df1.select($"name", $"age", $"age" + 1 as "new_age").show()
/*
* where
* 过滤
* */
// df1.where("gender='男'").show()
// df1.where("gender='男' and substring(clazz,0,2)='理科'").show()// 不如sql语句
//建议使用隐式转换中的功能进行处理过滤 === 三个等号 类似于sql中的=
// df1.where($"gender"==="男" and substring($"clazz",0,2)==="理科").show()
// 过滤出女生 理科 不等于男生
// =!= : 类似于sql中的!=或者<> 不等于某个值
// df1.where($"gender"=!="男" and substring($"clazz",0,2)==="理科").show()
/*
* groupBy
* 非分组字段是无法出现在select查询语句中的
* */
//查询每个班级的人数
// df1.groupBy("clazz")
// .agg(count("clazz") as "counts")
// .show()
/*
* orderBy
* */
// df1.groupBy("clazz")
// .agg(count("clazz") as "counts")
// .orderBy($"counts".desc) // 降序
// .show(3)
/*
* join
* */
val df2: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
.schema("id STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
// df1与df2关联
//关联字段名不一样的情况
// df2.join(df1,$"id"===$"sid","inner")
// .select("id","name","age","gender","clazz","subject_id","score")
// .show(10)
// 一样的情况
// df2.join(df1,"id")
// .select("id","name","age","gender","clazz","subject_id","score")
// .show(10)
//如果关联的字段名一样且想使用其他连接方式的话,可以将字段名字用Seq()传入,同时可以传连接方式
// df2.join(df1, Seq("id"),"left")
// .select("id","name","age","gender","clazz","subject_id","score")
// .show(10)
/*
* 开窗
*无论是在纯sql中还是在DSL语法中,开窗是不会改变原表条数
* */
//计算每个班级总分前3的学生
//纯spark sql的方式实现
// df1.createOrReplaceTempView("students")
// df2.createOrReplaceTempView("scores")
// sparkSession.sql(
// """
// |select
// |*
// |from
// |(
// |select t1.id,
// |t2.name,
// |t2.clazz,
// |t1.sumScore,
// |row_number() over(partition by t2.clazz order by t1.sumScore desc) as rn
// |from
// |(
// | select id,
// | sum(score) as sumScore
// | from
// | scores
// | group by id) t1
// |join
// | students t2
// |on(t1.id=t2.id)) tt1 where tt1.rn<=3
// |""".stripMargin).show()
// DSl实现
df2.groupBy("id")
.agg(sum("score") as "sumScore") // 计算总分
.join(df1,"id")
.select($"id",$"name",$"clazz",$"sumScore",row_number() over Window.partitionBy("clazz").orderBy($"sumScore".desc)as "rn") //开窗 排序
.where($"rn"<=3)
//.repartition(1) 单独设置分区数
.write
.format("csv")
.mode(SaveMode.Overwrite)
.save("spark/data/sqlOut3")
}
}
Date Source Api
import org.apache.spark.sql.SparkSession
object Demo4SourceAPI {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("data source api")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
/**
* 导入隐式转换
*/
/**
* ================================读写csv格式的数据=========================
*/
//如果是直接调用csv函数读取数据的话,无法做表结构的设置
// val df1: DataFrame = sparkSession.read
// .csv("spark/data/test1.csv")
// //使用format的形式读取数据的同时可以设置表结构
// val df2: DataFrame = sparkSession.read
// .format("csv")
// .schema("id STRING,name STRING,age INT")
// .load("spark/data/test1.csv")
// df2.show()
// 读取学生数据
// val df1: DataFrame = sparkSession.read
// .format("csv")
// .schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
// .option("sep", ",")
// .load("spark/data/students.txt")
//
// df1.createOrReplaceTempView("students")
//
// val resDF1: DataFrame = sparkSession.sql(
// """
// |select
// |clazz,
// |count(1) as counts
// |from students
// |group by clazz
// |""".stripMargin)
// //以csv格式写出到磁盘文件夹中
// resDF1.write
// .format("csv")
.option("sep",",")
// .mode(SaveMode.Overwrite)
// .save("spark/data/sqlout4")
/**
* ===================================读写json格式的数据========================
*/
// val df1: DataFrame = sparkSession.read
// .json("spark/data/students.json")
// 写数据
// df1.groupBy("age")
// .agg(count("age") as "counts")
// .write
// .json("spark/data/sqlout5")
/**
* ================================读写parquet格式的数据=================
*
* parquet格式的文件存储,是由【信息熵】决定的
*/
// val df1: DataFrame = sparkSession.read
// .json("spark/data/students2.json")
//
// //以parquet格式写出去
// df1.write
// .parquet("spark/data/sqlout7")
//读取parquet格式的数据
// val df2: DataFrame = sparkSession.read
// .parquet("spark/data/sqlout7/part-00000-23f5482d-74d5-4569-9bf4-ea0ec91e86dd-c000.snappy.parquet")
// df2.show()
/**
* ======================================读写orc格式的数据=====================
*文件被压缩的更小 读写速度最快
*/
// val df1: DataFrame = sparkSession.read
// .json("spark/data/students2.json")
// df1.write
// .orc("spark/data/sqlout8")
//
// sparkSession.read
// .orc("spark/data/sqlout8/part-00000-a33e356c-fd1f-4a5e-a87f-1d5b28f6008b-c000.snappy.orc")
// .show()
/**
* ==================================读写jdbc格式的数据===================
* 需要导入mysql驱动包
*/
sparkSession.read
.format("jdbc")
.option("url", "jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=UTF-8&useSSL=false")
.option("dbtable", "studentdb.jd_goods")
.option("user", "root")
.option("password", "123456")
.load()
.show(10,truncate = false)
}
}
RDD与DataFrame互相转换
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object Demo5RDD2DataFrame {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("rdd与df之间的转换")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
//通过SparkSession获取sparkContext对象
val sparkContext: SparkContext = sparkSession.sparkContext
//作用1:使用$函数
//作用2:可以在不同的数据结构之间转换
import sparkSession.implicits._
/**
* spark core的核心数据结构是:RDD
* spark sql的核心数据结构是DataFrame
*/
// RDD->DataFrame .toDF
val linesRDD: RDD[String] = sparkContext.textFile("spark/data/students.txt")
val stuRDD: RDD[(String, String, String, String, String)] = linesRDD.map((line: String) => {
line.split(",") match {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
})
val resRDD1: RDD[(String, Int)] = stuRDD.groupBy(_._5)
.map((kv: (String, Iterable[(String, String, String, String, String)])) => {
(kv._1, kv._2.size)
})
val df1: DataFrame = resRDD1.toDF // 转成DF
val df2: DataFrame = df1.select($"_1" as "clazz", $"_2" as "counts")
df2.printSchema()
// DataFrame->RDD .rdd
val resRDD2: RDD[Row] = df2.rdd
// resRDD2.map((row:Row)=>{
// val clazz: String = row.getAs[String]("clazz")
// val counts: Integer = row.getAs[Integer]("counts")
// s"班级:$clazz, 人数:$counts"
// }).foreach(println)
// 模式匹配
resRDD2.map {
case Row(clazz:String, counts:Integer)=>
s"班级:$clazz, 人数:$counts"
}.foreach(println)
}
}
开窗函数
开窗:over
- 聚合开窗函数:sum count lag(取上一条) lead(取后一条)
- 排序开窗函数:row_number rank dense_rank
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 练习开窗的题目: DSL语法去做
* 统计总分年级排名前十学生各科的分数
* 统计每科都及格的学生
* 统计总分大于年级平均分的学生
* 统计每个班级的每个名次之间的分数差
*/
object Demo6WindowFun {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("rdd与df之间的转换")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
/**
* 导入隐式转换你
*/
import org.apache.spark.sql.functions._
import sparkSession.implicits._
/**
* 读取三个数据文件
*/
val studentsDF: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load("spark/data/students.txt")
// studentsDF.show()
val scoresDF: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
// scoresDF.show()
val subjectsDF: DataFrame = sparkSession.read
.format("csv")
.schema("subject_id STRING,subject_name STRING,subject_score INT")
.load("spark/data/subject.txt")
// subjectsDF.show()
//统计总分年级排名前十学生各科的分数
val resDS1: Dataset[Row] = scoresDF
.join(studentsDF, "id")
.withColumn("sumScore", sum("score") over Window.partitionBy("id"))
// dense_rank 不跳过排名 并列
.withColumn("rn", dense_rank() over Window.partitionBy(substring($"clazz", 0, 2)).orderBy($"sumScore".desc))
.where($"rn" <= 10)
.limit(120)
//统计每科都及格的学生
val resDS2: Dataset[Row] = scoresDF
.join(subjectsDF, "subject_id")
.where($"score" >= $"subject_score" * 0.6)
.withColumn("jigeCount", count(expr("1")) over Window.partitionBy($"id"))
.where($"jigeCount" === 6)
//统计总分大于年级平均分的学生
val resDS3: Dataset[Row] = scoresDF
.join(studentsDF, "id")
.withColumn("sumScore", sum($"score") over Window.partitionBy($"id"))
.withColumn("avgScore", avg($"sumScore") over Window.partitionBy(substring($"clazz", 0, 2)))
.where($"sumScore" > $"avgScore")
//统计每个班级的每个名次之间的分数差
val resDF4: DataFrame = scoresDF
.join(studentsDF, "id")
.groupBy("id", "clazz")
.agg(sum("score") as "sumScore")
.withColumn("rn", row_number() over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
.withColumn("beforeSumScore", lag($"sumScore", 1, 750) over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
.withColumn("cha", $"beforeSumScore" - $"sumScore")
}
}
DSL练习
公司代码,年度,1月-12月的收入金额
burk,year,tsl01,tsl02,tsl03,tsl04,tsl05,tsl06,tsl07,tsl08,tsl09,tsl10,tsl11,tsl12
853101,2010,100200,25002,19440,20550,14990,17227,40990,28778,19088,29889,10990,20990
853101,2011,19446,20556,14996,17233,40996,28784,19094,28779,19089,29890,10991,20991
853101,2012,19447,20557,14997,17234,20560,15000,17237,28780,19090,29891,10992,20992
853101,2013,20560,15000,17237,41000,17234,20560,15000,17237,41000,29892,10993,20993
853101,2014,19449,20559,14999,17236,41000,28788,28786,19096,29897,41000,28788,20994
853101,2015,100205,25007,19445,20555,17236,40999,28787,19097,29898,29894,10995,20995
853101,2016,100206,25008,19446,20556,17237,41000,28788,19098,29899,29895,10996,20996
853101,2017,100207,25009,17234,20560,15000,17237,41000,15000,17237,41000,28788,20997
853101,2018,100208,25010,41000,28788,28786,19096,29897,28786,19096,29897,10998,20998
853101,2019,100209,25011,17236,40999,28787,19097,29898,28787,19097,29898,10999,20999
846271,2010,100210,25012,17237,41000,28788,19098,29899,28788,19098,29899,11000,21000
846271,2011,100211,25013,19451,20561,15001,17238,41001,28789,19099,29900,11001,21001
846271,2012,100212,100213,20190,6484,46495,86506,126518,166529,206540,246551,286562,326573
846271,2013,100213,100214,21297,5008,44466,83924,123382,162839,202297,241755,281213,320671
846271,2014,100214,100215,22405,3531,42436,81341,120245,159150,198055,236959,275864,314769
846271,2015,100215,100216,23512,2055,19096,29897,28786,19096,29897,41000,29892,308866
846271,2016,100216,100217,24620,579,38377,76175,28788,28786,19096,29897,41000,302964
846271,2017,100217,100218,25727,898,36347,73592,40999,28787,19097,29898,29894,297062
846271,2018,100218,100219,26835,2374,34318,71009,41000,28788,19098,29899,29895,291159
846271,2019,100219,100220,27942,3850,32288,68427,17237,41000,15000,17237,41000,285257
1、统计每个公司每年按月累计收入 行转列 --> sum窗口函数
输出结果
公司代码,年度,月份,当月收入,累计收入
2、统计每个公司当月比上年同期增长率 行转列 --> lag窗口函数
公司代码,年度,月度,增长率(当月收入/上年当月收入 - 1)
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
object Demo7Burks {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("练习1需求")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
//导入隐式转换
import org.apache.spark.sql.functions._
import sparkSession.implicits._
// 加载数据
val burksDF: DataFrame = sparkSession.read
.format("csv")
.schema("burk STRING,year STRING" +
",tsl01 DOUBLE,tsl02 DOUBLE,tsl03 DOUBLE" +
",tsl04 DOUBLE,tsl05 DOUBLE,tsl06 DOUBLE" +
",tsl07 DOUBLE,tsl08 DOUBLE,tsl09 DOUBLE" +
",tsl10 DOUBLE,tsl11 DOUBLE,tsl12 DOUBLE")
.load("spark/data/burks.txt")
/**
* 1、统计每个公司每年按月累计收入 行转列 --> sum窗口函数
*
* 输出结果
* 公司代码,年度,月份,当月收入,累计收入
*/
// 纯sql的方式实现
burksDF.createOrReplaceTempView("burks")
val resDF1: DataFrame = sparkSession.sql(
"""
|select
|t1.burk as burk,
|t1.year as year,
|t1.month as month,
|t1.tsl as tsl,
|sum(t1.tsl) over(partition by burk,year order by month) as leiji
|from
|(select
| burk,
| year,
| month,
| tsl
|from
| burks
| lateral view explode(map(1,tsl01,2,tsl02,3,tsl03,4,tsl04,5,tsl05,6,tsl06,7,tsl07,8,tsl08,9,tsl09,10,tsl10,11,tsl11,12,tsl12)) T as month,tsl
| ) t1
|""".stripMargin)
// DSL方法实现
val m: Column = map(
expr("1"), $"tsl01",
expr("2"), $"tsl02",
expr("3"), $"tsl03",
expr("4"), $"tsl04",
expr("5"), $"tsl05",
expr("6"), $"tsl06",
expr("7"), $"tsl07",
expr("8"), $"tsl08",
expr("9"), $"tsl09",
expr("10"), $"tsl10",
expr("11"), $"tsl11",
expr("12"), $"tsl12"
)
// DSL语法方式实现
// burksDF.select($"burk",$"year",explode(m) as Array("month","tsl"))
// .withColumn("leiji",sum($"tsl") over Window.partitionBy($"burk",$"year").orderBy($"month"))
// .show()
/**
* 2、统计每个公司当月比上年同期增长率 行转列 --> lag窗口函数
* 公司代码,年度,月度,增长率(当月收入/上年当月收入 - 1)
*
* 853101 2010 1 10000
* 853101 2011 1 11000 10000
*/
val resDF2: DataFrame = burksDF.select($"burk", $"year", explode(m) as Array("month", "tsl"))
.withColumn("beforeTsl", lag($"tsl", 1, 0.0) over Window.partitionBy($"burk", $"month").orderBy($"year"))
.withColumn("p", round(($"tsl" / $"beforeTsl" - 1) * 100, 8).cast("string"))
.withColumn("new_p", when($"p".isNotNull, $"p").otherwise("该年的当月是第一次计数"))
.select($"burk", $"year", $"month", $"tsl", $"new_p")
}
}
集群运行 Spark sql
编写一个简单代码
package com.shujia.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo8SubmitYarn {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
// .master("local")
.appName("提交到yarn 计算每个班级的人数")
//参数设置的优先级:代码优先级 > 命令优先级 > 配置文件优先级
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load(args(0)) // hdfs上的路径 给参数
val df2: DataFrame = df1.groupBy($"clazz")
.agg(count($"id") as "counts")
df2.show()
df2.write
.csv(args(1))// 带传参数
}
}
打包上传 上传数据
运行
spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo8SubmitYarn --conf spark.sql.shuffle.partitions=1 spark-1.0.jar (数据输入路径)(输出路径)
注意:
在代码中,我们设置了分区数为1,我们在命令中设置分区数100 看看效果
spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo8SubmitYarn --conf spark.sql.shuffle.partitions=100 spark-1.0.jar(数据输入路径)(输出路径)
运行发现 还是一个分区。
结论:参数设置的优先级:代码优先级 > 命令优先级 > 配置文件优先级
spark shell (repl) 里面使用sqlContext 测试使用,简单任务使用
spark-shell --master yarn --deploy-mode client
可以在这里面编写代码
字符串拼接
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo9Test {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("提交到yarn 计算每个班级的人数")
//参数设置的优先级:代码优先级 > 命令优先级 > 配置文件优先级
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.option("sep", ",")
.load("spark/data/students.txt")
// 字符串拼接
df1.select($"name", concat(expr("'姓名: '"),$"name") as "new_str").show()
df1.groupBy($"clazz")
.agg(
count(expr("1")) as "counts",
avg($"age") as "avgAge"
).show()
}
}
spark-sql
进入命令行,和hive的命令行一样,直接写sql,默认去hive读数据
spark-sql --master yarn --deploy-mode client
spark整合hive
在spark sql中使用hive的元数据
spark sql是使用spark进行计算的,hive使用MR进行计算的
1、在hive的hive-site.xml修改一行配置,增加了这一行配置之后,以后在使用hive之前都需要先启动元数据服务
cd /usr/local/soft/hive-1.2.1/conf/
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
2、启动hive元数据服务, 将hvie的元数据暴露给第三方使用
nohup hive --service metastore >> metastore.log 2>&1 &
3、将hive-site.xml 复制到spark conf目录下
cp hive-site.xml /usr/local/soft/spark-3.1.3/conf/
4、 将mysql 驱动包复制到spark jars目录下
cd /usr/local/soft/hive-3.1.2/lib
cp mysql-connector-java-8.0.29.jar /usr/local/soft/spark-3.1.3/jars/
5、整合好之后在spark-sql 里面就可以使用hive的表了
# 启动hive元数据
# 模式是local模式
spark-sql -conf spark.sql.shuffle.partitions=2
# 使用yarn-client模式
spark-sql --master yarn-client --conf spark.sql.shuffle.partitions=1
#在spark-sql中设置运行参数
set spark.sql.shuffle.partitions=2;
# 执行一些sql...
spark-sql -e
-- 执行一条sql语句,执行完,自动退出
spark-sql -e "select * from student"
spark-sql -f
vim a.sql
select * from student
-- 执行一个sql文件
spark-sql -f a.sql
当spark-sql 和hive整合好之后再代码中也可以直接使用hive的表
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.0</version>
准备工作:将hive的配置文件,hadoop的配置文件 复制到项目中resources文件夹中:
core-site.xml
hdfs-site.xml
yarn-site.xml
hive-site.xml
import org.apache.spark.sql.SparkSession
object Demo10HiveOnSpark {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("提交到yarn 计算每个班级的人数")
.config("spark.sql.shuffle.partitions", "1")
.enableHiveSupport() // 开启hive的配置
.getOrCreate()
sparkSession.sql("use bigdata30")
sparkSession.sql("select * from sqoop_students1 limit 10").show(truncate = false)
}
}
//写好的代码不能再本地运行, 需要打包上传到集群运行
spark sql和hvie的建表语句一样
create external table students
(
id string,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
location '/bigdata30/spark_in/data/student';
create table score
(
student_id string,
cource_id string,
sco int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
location '/data/score/';
禁用集群spark日志
cd /usr/local/soft/spark-2.4.5/conf
mv log4j.properties.template log4j.properties
vim log4j.properties
修改配置
log4j.rootCategory=ERROR, console
spark sql和hive区别
1、spark sql缓存
-- 进入spark sql命令行
spark-sql
-- 可以通过一个网址访问spark任务
http://master:4040
-- 设置并行度
set spark.sql.shuffle.partitions=1;
-- 再spark-sql中对同一个表进行多次查询的时候可以将表缓存起来
cache table student;
-- 删除缓存
uncache table student;
-- 再代码中也可以缓存DF
studentDF.persist(StorageLevel.MEMORY_ONLY)
2、spark sql mapjoin — 广播变量
Reduce Join
select * from
student as a
join
score as b
on
a.id=b.student_id
MapJoin
当一个大表关联小表的时候可以将小表加载到内存中进行关联---- 广播变量
在map端进行表关联,不会产生shuffle
select /*+broadcast(a) */ * from
student as a
join
score as b
on
a.id=b.student_id
/*+broadcast(a) */ HINT:给sql加提示的语法
表1
姓名,科目,分数
name,item,score
张三,数学,33
张三,英语,77
李四,数学,66
李四,英语,78表2
姓名,数学,英语
name,math,english
张三,33,77
李四,66,781、将表1转化成表2
2、将表2转化成表1
行列转换
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
/**
*
* 1、行列转换
*
*/
object Demo11Student {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("行转列 列转行案例演示")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//当你配置了hdfs等一些配置文件,那么默认读取路径是hadoop的,否则是本地
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("name STRING,item STRING,score INT")
.load("/bigdata30/stu.txt")
//列转行
val resDF: DataFrame = df1.groupBy($"name")
.agg(
sum(when($"item" === "数学", $"score").otherwise(0)) as "math",
sum(when($"item" === "英语", $"score").otherwise(0)) as "english"
)
// val array1: Column = array($"math", $"english")
val m: Column = map(
expr("'数学'"), $"math",
expr("'英语'"), $"english"
)
//行转列
resDF.select($"name",explode(m) as Array("item","score")).show()
}
}
自定义UDF函数
sparkSession.udf.register(“hhh”,fun1) // 注册成函数
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo12UDF {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("行转列 列转行案例演示")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//当你配置了hdfs等一些配置文件,那么默认读取路径是hadoop的,否则是本地
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.option("sep", ",")
.load("/bigdata30/students.csv")
val fun1: UserDefinedFunction = udf("姓名: " + _)
// 注册成一张表
df1.createOrReplaceTempView("students")
//将自定义的函数变量注册成sql语句中的函数
sparkSession.udf.register("hhh",fun1) // 取任意名字
sparkSession.sql(
"""
|select
|id,
|name,
|hhh(name) as new_name
|from
|students
|""".stripMargin).show()
}
}
在spark-sql命令行创建:
import org.apache.hadoop.hive.ql.exec.UDF
class Demo13Str extends UDF {
def evaluate(line: String): String = "胡哈哈哈:" + line
}
/**
* 1、自定义类继承UDF类,重写evaluate方法
* 2、打包,spark-1.0.jar 将jar包放到spark目录下的jars目录下
* 3、在spark-sql命令行中注册函数
* create function hhhh as 'com.shujia.sql.Demo13Str'
*
*
* */
DSL练习(二)
工作经历
数据:
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-02-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-03-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-04-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-05-01 00:00:00
91330000733796106P,阿里云计算有限公司,2020-06-01 00:00:00
91330000733796106P,阿里云计算有限公司,2020-07-01 00:00:00
91330000733796106P,阿里云计算有限公司,2020-08-01 00:00:00
91330000733796106P,阿里云计算有限公司,2020-09-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-10-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-11-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2020-12-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2021-01-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2021-02-01 00:00:00
91330000733796106P,杭州海康威视数字技术股份有限公司,2021-03-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-02-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-03-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-04-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-05-01 00:00:00
aaaaaaaaaaaaaaaaaa,阿里云计算有限公司,2020-06-01 00:00:00
aaaaaaaaaaaaaaaaaa,阿里云计算有限公司,2020-07-01 00:00:00
aaaaaaaaaaaaaaaaaa,阿里云计算有限公司,2020-08-01 00:00:00
aaaaaaaaaaaaaaaaaa,阿里云计算有限公司,2020-09-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-10-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-11-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2020-12-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2021-01-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2021-02-01 00:00:00
aaaaaaaaaaaaaaaaaa,杭州海康威视数字技术股份有限公司,2021-03-01 00:00:00
需求:统计每个员工的工作经历
结果结构:
员工编号,开始时间,结束时间,公司名称
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo14SheBao {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("经历练习")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val df1: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,burk STRING,sdate STRING")
.load("/bigdata30/shebao.txt")
val resDF: DataFrame = df1.withColumn("before_burk", lag($"burk", 1) over Window.partitionBy($"id").orderBy($"sdate"))
.select(
$"id",
$"burk",
$"sdate",
when($"before_burk".isNull, $"burk").otherwise($"before_burk") as "before_burk"
).withColumn("flag", when($"burk" === $"before_burk", 0).otherwise(1))
.withColumn("tmp", sum($"flag") over Window.partitionBy($"id").orderBy($"sdate"))
.groupBy($"id", $"burk", $"tmp")
.agg(
min($"sdate") as "start_date",
max($"sdate") as "end_date"
).select($"id", $"burk", $"start_date", $"end_date")
// 保存结果
resDF.write
.format("csv")
.mode(SaveMode.Overwrite)
.save("/bigdata30/spark_out4")
}
}
蚂蚁森林植物申领统计
table_name:user_low_carbon
| 字段名 | 字段描述 |
|---|---|
| user_id | 用户 |
| data_dt | 日期 |
| low_carbon | 减少碳排放(g) |
蚂蚁森林植物换购表,用于记录申领环保植物所需要减少的碳排放量
table_name: plant_carbon
| 字段名 | 字段描述 |
|---|---|
| plant_id | 植物编号 |
| plant_name | 植物名 |
| plant_carbon | 换购植物所需要的碳 |
题目一
蚂蚁森林植物申领统计
问题:假设2017年1月1日开始记录低碳数据(user_low_carbon),假设2017年10月1日之前满足申领条件的用户都申领了一颗p004-胡杨,
剩余的能量全部用来领取“p002-沙柳” 。
统计在10月1日累计申领“p002-沙柳” 排名前10的用户信息;以及他比后一名多领了几颗沙柳。
得到的统计结果如下表样式:
user_id plant_count less_count(比后一名多领了几颗沙柳)
u_101 1000 100
u_088 900 400
u_103 500 …
题目二
蚂蚁森林低碳用户排名分析
问题:查询user_low_carbon表中每日流水记录,条件为:
用户在2017年,连续三天(或以上)的天数里,
每天减少碳排放(low_carbon)都超过100g的用户低碳流水。
需要查询返回满足以上条件的user_low_carbon表中的记录流水。
例如用户u_002符合条件的记录如下,因为2017/1/2~2017/1/5连续四天的碳排放量之和都大于等于100g:
user_id data_dt low_carbon
u_002 2017/1/2 150
u_002 2017/1/2 70
u_002 2017/1/3 30
u_002 2017/1/3 80
u_002 2017/1/4 150
u_002 2017/1/5 101
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object Demo15MaYi {
def main(args: Array[String]): Unit = {
/**
* 创建SparkSession的环境对象
*/
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("蚂蚁森林案例")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//读取用户每日碳排放量信息表
val userLowCarbonDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", "\t")
.schema("user_id STRING,date_dt STRING,low_carbon Double")
.load("spark/data/ant_user_low_carbon.txt")
val plantCarbonDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", "\t")
.schema("plant_id STRING,plant_name STRING,plant_carbon Double")
.load("spark/data/ant_plant_carbon.txt")
//因为用户信息表与植物信息表是没有直接关联条件的,需要单独的从植物信息表中将胡杨和沙柳的所需能量提取出来由变量保存
val huYangCarbon: Double = plantCarbonDF.where($"plant_name" === "胡杨")
.select($"plant_carbon")
.rdd
.collect()
.head
.getAs[Double]("plant_carbon")
val shaLiuCarbon: Double = plantCarbonDF.where($"plant_name" === "沙柳")
.select($"plant_carbon")
.rdd
.collect()
.head
.getAs[Double]("plant_carbon")
println(s"胡杨所需碳排放量:$huYangCarbon, 沙柳所需碳排放量:$shaLiuCarbon")
println("==========================================================================")
/**
* 题目一:蚂蚁森林植物申领统计
* 假设2017年1月1日开始记录低碳数据(user_low_carbon),假设2017年10月1日之前满足申领条件的用户都申领了一颗p004-胡杨,
* 剩余的能量全部用来领取“p002-沙柳” 。
* 统计在10月1日累计申领“p002-沙柳” 排名前10的用户信息;以及他比后一名多领了几颗沙柳。
* 得到的统计结果如下表样式:
*/
//过滤日期是2017年1月1日到2017年10月1日之间的
userLowCarbonDF.where($"date_dt" >= "2017/1/1" and $"date_dt" <= "2017/10/1")//.show()
//根据用户,日期分组,聚合每一天总的排放量
.groupBy($"user_id")
.agg(sum($"low_carbon") as "low_carbon")//.show()
//新增一列,表示申领条件后的剩余能量
.withColumn("other_carbon",when($"low_carbon" >= huYangCarbon,$"low_carbon" - huYangCarbon).otherwise($"low_carbon"))//.show()
//新增一列,计算领取沙柳的棵树
.withColumn("plant_count",floor($"other_carbon" / shaLiuCarbon))//.show()
//新增一列,取出后一个沙柳的棵树
.withColumn("after_plant_count",lead($"plant_count",1,0) over Window.orderBy($"plant_count".desc))
.withColumn("less_count",$"plant_count" - $"after_plant_count")
.limit(10)
.select($"user_id",$"plant_count",$"less_count")
// .show()
/**
* 题目二:蚂蚁森林低碳用户排名分析
* 查询user_low_carbon表中每日流水记录,条件为:
* 用户在2017年,连续三天(或以上)的天数里,
* 每天减少碳排放(low_carbon)都超过100g的用户低碳流水。
* 需要查询返回满足以上条件的user_low_carbon表中的记录流水。
* 例如用户u_002符合条件的记录如下,因为2017/1/2~2017/1/5连续四天的碳排放量之和都大于等于100g:
*/
//根据用户和日期进行分组,得到每一天碳排放量
userLowCarbonDF.groupBy($"user_id",$"date_dt")
.agg(sum($"low_carbon") as "day_carbon")
//过滤出大于100碳排放量的天
.where($"day_carbon" > 100)
//根据用户开窗,以日期升序排序
.withColumn("rn",row_number() over Window.partitionBy($"user_id").orderBy($"date_dt"))
//将日期减去编号,根据结果判断天数是否连续
.withColumn("tmp_date",date_sub(regexp_replace($"date_dt","/","-"),$"rn"))
//新增一列,计算用户连续的天数
.withColumn("days",count(expr("1")) over Window.partitionBy($"user_id",$"tmp_date"))
//过滤出连续天数是大于3的
.where($"days" >= 3)
.select($"user_id",$"date_dt")
.join(userLowCarbonDF,List("user_id","date_dt"))
.select($"user_id",$"date_dt",$"low_carbon")
.show(1000)
}
}
Spark streaming
通过wordcount 认识spark streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
object Demo1WordCount {
/**
* Spark core: SparkContext 核心数据结构:RDD
* Spark sql: SparkSession 核心数据结构:DataFrame
* Spark streaming: StreamingContext 核心数据结构:DStream(底层封装了RDD)
*/
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("wordCount")
conf.setMaster("local[2]") // 给定核数
val context = new SparkContext(conf)
//创建Spark Streaming的运行环境,和前两个模块是不一样的
//Spark Streaming是依赖于Spark core的环境的
//this(sparkContext: SparkContext, batchDuration: Duration)
//Spark Streaming处理之前,是有一个接收数据的过程
//batchDuration,表示接收多少时间段内的数据
val streamingContext = new StreamingContext(context, Durations.seconds(5)) // 传入接收时间
//Spark Streaming程序理论上是一旦启动,就不会停止,除非报错,人为停止,停电等其他突然场景导致程序终止
// 监控一个端口号中的数据,手动向端口号中打数据
// 模拟kafka
val rids: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 12345)
// 对接收的数据进行处理
val resDS: DStream[(String, Int)] = rids
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
resDS.print()
/**
* sparkStreaming启动的方式和前两个模块启动方式不一样
*/
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
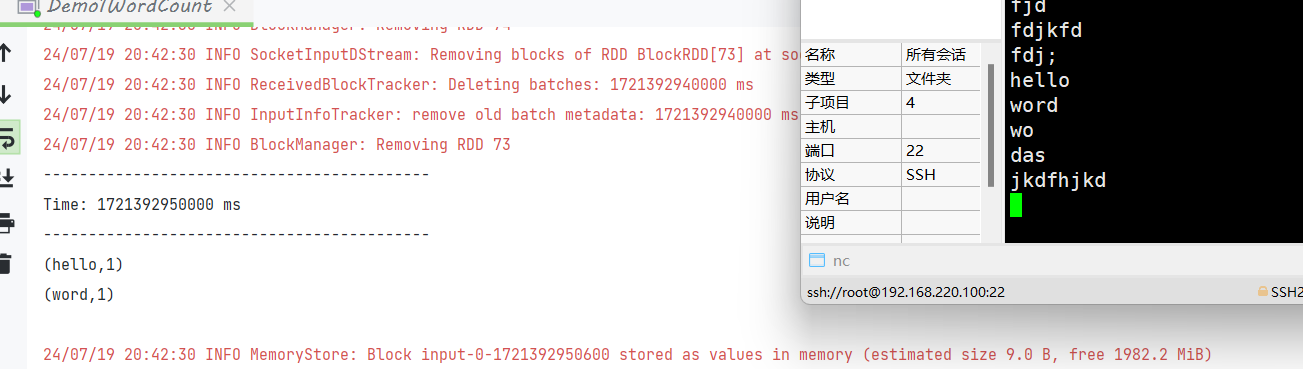
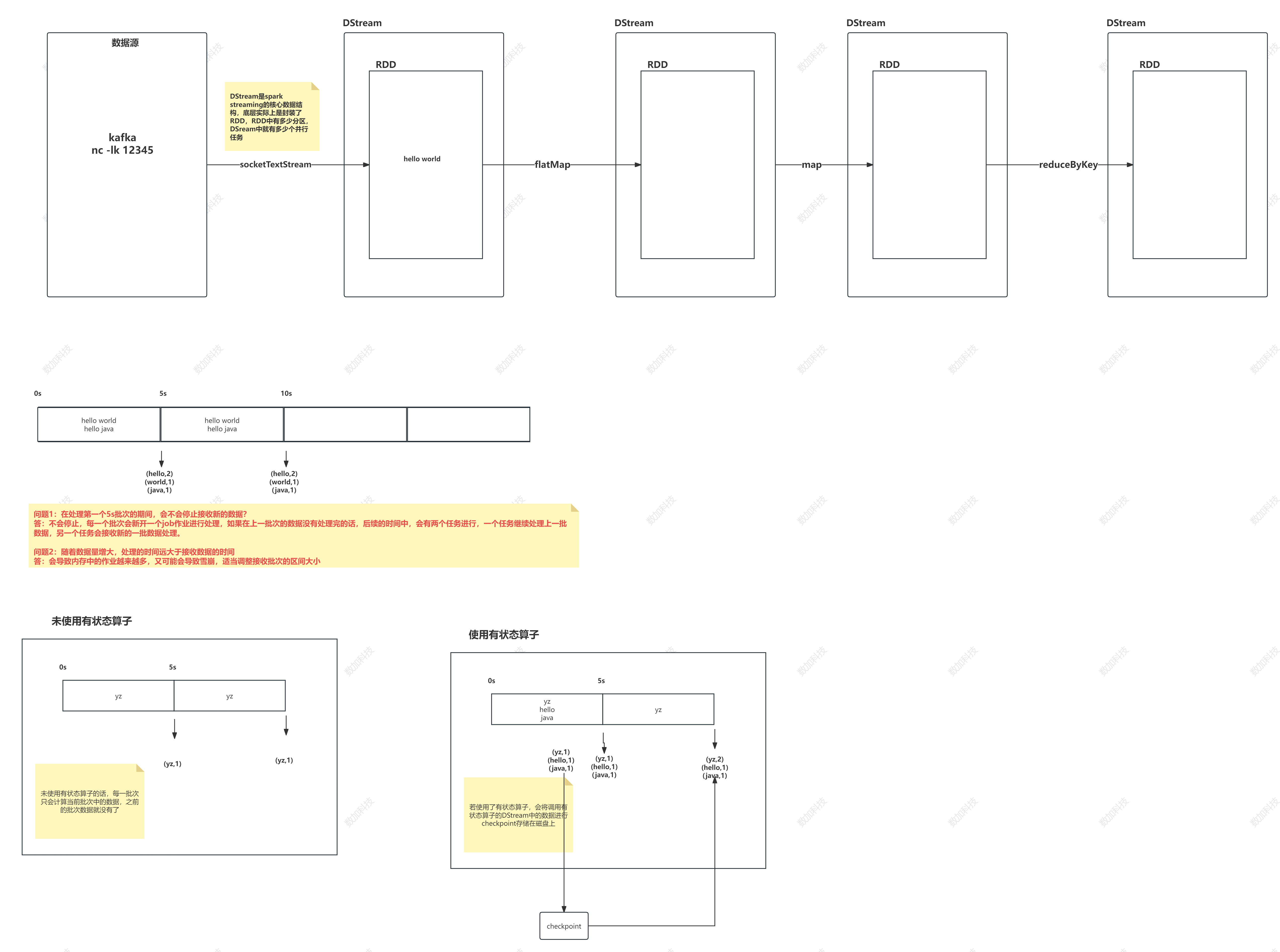
如何将上一次处理的结果保留下来?
- 需要使用有状态的算子来处理当前批次数据与历史数据的关系
* updateStateByKey(S:ClassTag)(updateFunc: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)]
- Seq: 序列,表示历史键对应的值组成的序列 (hello, seq:[1,1,1])
- Option: 当前批次输入键对应的value值,如果历史中没有该键,这个值就是None, 如果历史中出现了这个键,这个值就是Some(值)
- 有状态算子使用注意事项:
- 1、有状态算子ByKey算子只适用于k-v类型的DStream
- 2、有状态算子使用的时候,需要提前设置checkpoint的路径,因为需要将历史批次的结果存储下来
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
object Demo2WordCount2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]") // 给定核数
conf.setAppName("spark Streaming 单词统计")
val sparkContext = new SparkContext(conf)
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
//设置的是一个文件夹 存储历史数据
streamingContext.checkpoint("spark/data/checkpoint2")
val rids: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 12345)
//hello world
val wordsDS: DStream[String] = rids.flatMap(_.split(" "))
val kvDS: DStream[(String, Int)] = wordsDS.map((_, 1)) // (hello,1) (hello,1) (hello,1)
/**
* 每5秒中resDS中的数据,是当前5s内的数据
* reduceByKey,只会对当前5s批次中的数据求和
*/
// val resDS: DStream[(String, Int)] = kvDS.reduceByKey(_ + _)
val resDS: DStream[(String, Int)] = kvDS.updateStateByKey((seq1: Seq[Int], opt1: Option[Int]) => {
// 上一次的总和
val sumValue: Int = seq1.sum
// 这一次的
val num: Int = opt1.getOrElse(0)
Option(sumValue + num)
})
println("--------------------------------------")
resDS.print()
println("--------------------------------------")
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
窗口
滑动窗口和滚动窗口
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object Demo3Window {
def main(args: Array[String]): Unit = {
/**
* 创建spark streaming的环境
* 旧版本创建的方式
*/
// val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("窗口案例")
// val context = new SparkContext(conf)
// val sc = new StreamingContext(context, Durations.seconds(5))
/**
* 新版本的创建方式
*/
val context: SparkContext = SparkSession.builder()
.master("local[2]")
.appName("窗口案例")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate().sparkContext
val sc = new StreamingContext(context, Durations.seconds(3)) // 正常每次接收5s内的数据
//1000 ~ 65535 端口号
val infoDS: ReceiverInputDStream[String] = sc.socketTextStream("master", 10086)
val wordsDS: DStream[String] = infoDS.flatMap(_.split(" "))
val kvDS: DStream[(String, Int)] = wordsDS.map((_, 1))
/**
* 1、如果只是为了计算当前批次接收的数据,直接调用reduceByKey
* 2、如果要将最新批次的数据与历史数据结合处理的话,需要调用有状态算子 updateStateByKey
* 3、如果要实现滑动窗口或者滚动窗口的话,需要使用窗口类算子reduceByKeyAndWindow
*/
//def reduceByKeyAndWindow(reduceFunc: (V, V) => V,windowDuration: Duration,slideDuration: Duration): DStream[(K, V)]
//reduceFunc 编写处理相同的键对应的value值做处理
//windowDuration 设置窗口的大小
//slideDuration 设置滑动的大小
//每间隔slideDuration大小的时间计算一次数据,计算数据的范围是最近windowDuration大小时间的数据
val resDS: DStream[(String, Int)] = kvDS.reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Durations.seconds(12), Durations.seconds(6))
/**
* 当窗口大小与滑动大小一致的时候,那么就会从滑动窗口转变成滚动窗口的效果
*/
// val resDS: DStream[(String, Int)] = kvDS.reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Durations.seconds(10), Durations.seconds(10))
resDS.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
}
各数据类型之间的关系
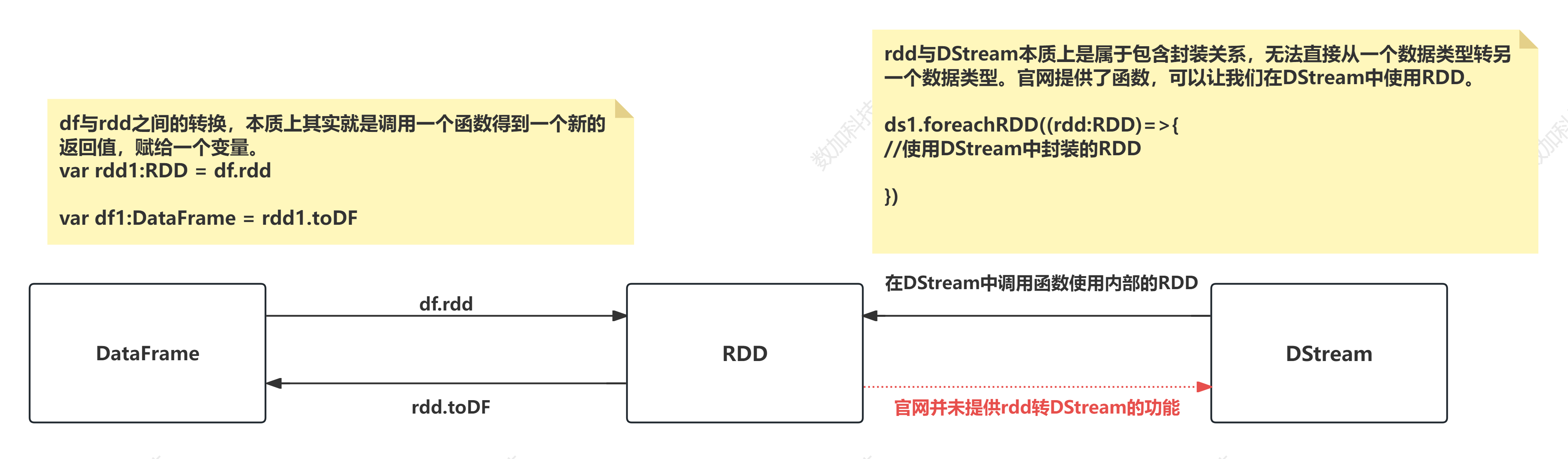
foreachRDD
package com.shujia.streaming
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object Demo4DStream2RDD {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
//如果DS不是键值形式的话,可以单独调用window函数进行设置窗口的形式
val new_infoDS: DStream[String] = infoDS.window(Durations.seconds(10), Durations.seconds(5))
// hello world java hello java
/**
* foreachRDD:在DS中使用rdd的语法操作数据
* 缺点:该函数是没有返回值的
* 需求:我们在想使用DS中的RDD的同时,想要使用结束后,会得到一个新的DS
*/
new_infoDS.foreachRDD((rdd:RDD[String])=>{
println("------------------------------")
// val resRDD: RDD[(String, Int)] = rdd.flatMap(_.split(" "))
// .map((_, 1))
// .reduceByKey(_ + _)
// resRDD.foreach(println)
//rdd和df之间可以转换 使用RDD的方式处理
val df1: DataFrame = rdd.toDF.select($"value" as "info")
df1.createOrReplaceTempView("words")
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.wds as word,
|count(1) as counts
|from
|(
|select
|explode(split(info,' ')) as wds
|from words) t1
|group by t1.wds
|""".stripMargin)
resDF.show()
})
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
transform
package com.shujia.streaming
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
/**
* 面试题:foreachRDD与transform的区别
*/
object Demo5TransFormat {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
val resDS: DStream[(String, Int)] = infoDS.transform((rdd: RDD[String]) => {
//直接对rdd进行处理,返回新的rdd
// val resRDD: RDD[(String, Int)] = rdd.flatMap(_.split(" "))
// .map((_, 1))
// .reduceByKey(_ + _)
// resRDD
//将rdd转df,使用sql做分析
//rdd和df之间可以转换
val df1: DataFrame = rdd.toDF.select($"value" as "info")
df1.createOrReplaceTempView("words")
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.wds as word,
|count(1) as counts
|from
|(
|select
|explode(split(info,' ')) as wds
|from words) t1
|group by t1.wds
|""".stripMargin)
val resRDD: RDD[(String, Int)] = resDF.rdd.map((row: Row) => (row.getAs[String](0), row.getAs[Int](1)))
resRDD
})
resDS.print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
区别:
transform: 将Dstream的操作转化为RDD的操作,返回的是一个新的RDD
foreach: 将Dstream的操作转化为RDD的操作,没有返回值 ,直接在函数中操作
yarn提交作业
打包代码 上传
spark-submit --master yarn --deploy-mode client --class com.shujia.streaming.Demo6YarnSubmiti spark-1.0.jar --num-executors 2 --executor-cores 1
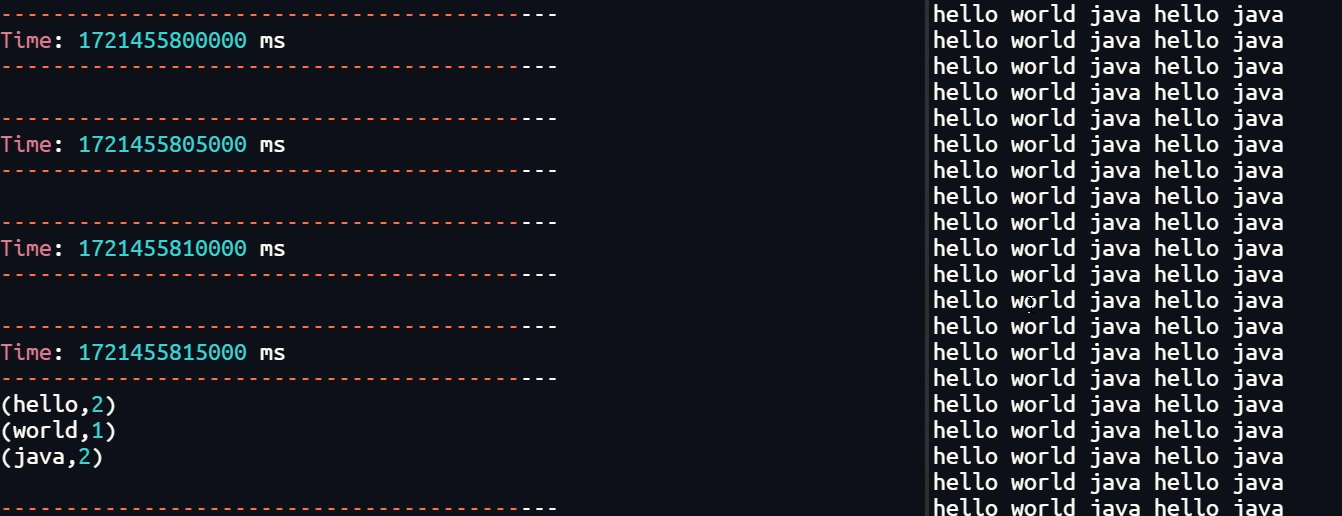
spark streaming保存文件到本地
//将结果存储到磁盘中
//只能设置文件夹的名字和文件的后缀
//每一批次运行,都会产生新的小文件夹,文件夹中有结果数据文件
resDS.saveAsTextFiles("spark/data/streamout/stream","txt")
拓展:将数据保存到数据库中
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import java.sql.{Connection, DriverManager, PreparedStatement}
object Demo8DS2Mysql {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
infoDS.foreachRDD((rdd:RDD[String])=>{
println("======================= 正在处理一批数据 ==========================")
//处理rdd中每一条数据
rdd.foreach((line:String)=>{
//如果将创建连接的代码写在这里,这样的话,每条数据都会创建一次连接
/**
* 创建与数据库连接对象
*/
//注册驱动
Class.forName("com.mysql.jdbc.Driver")
//创建数据库连接对象
val conn: Connection = DriverManager.getConnection(
"jdbc:mysql://master:3306/bigdata30?useUnicode=true&characterEncoding=UTF-8&useSSL=false",
"root",
"123456"
)
//创建预编译对象
val statement: PreparedStatement = conn.prepareStatement("insert into students values(?,?,?,?,?)")
val info: Array[String] = line.split(",")
statement.setInt(1,info(0).toInt)
statement.setString(2,info(1))
statement.setInt(3,info(2).toInt)
statement.setString(4,info(3))
statement.setString(5,info(4))
//执行sql语句
statement.executeUpdate()
//释放资源
statement.close()
conn.close()
})
})
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
但是这样做每一条数据处理都会创建一次连接,浪费资源: 尝试改造
/**
* 设想中的改造,不一定能运行
* 我们将原本在rdd中创建连接的代码放到了ds中,发现PreparedStatement不能与task任务一起序列化到executor中的
* 这样的写法是不可以的!!!!!!!
*/
// infoDS.foreachRDD((rdd: RDD[String]) => {
// println("======================= 正在处理一批数据 ==========================")
// //如果将创建连接的代码写在这里,这样的话,每条数据都会创建一次连接
// /**
// * 创建与数据库连接对象
// */
// //注册驱动
// Class.forName("com.mysql.jdbc.Driver")
// //创建数据库连接对象
// val conn: Connection = DriverManager.getConnection(
// "jdbc:mysql://master:3306/bigdata30?useUnicode=true&characterEncoding=UTF-8&useSSL=false",
// "root",
// "123456"
// )
// //创建预编译对象
// val statement: PreparedStatement = conn.prepareStatement("insert into students values(?,?,?,?,?)")
// //处理rdd中每一条数据
// rdd.foreach((line: String) => {
// val info: Array[String] = line.split(",")
// statement.setInt(1, info(0).toInt)
// statement.setString(2, info(1))
// statement.setInt(3, info(2).toInt)
// statement.setString(4, info(3))
// statement.setString(5, info(4))
// //执行sql语句
// statement.executeUpdate()
// })
//
// //释放资源
// statement.close()
// conn.close()
//
// })
最终版本:foreachPartition算子
/**
* rdd中有一个算子foreachPartition
* rdd本质是由一系列分区构成的,如果我们可以将分区数设置为1,且每个分区创建一个连接不就好了么
*/
infoDS.foreachRDD((rdd: RDD[String]) => {
println("======================= 接收到 5s 一批次数据 ==========================")
rdd.repartition(2)
println(s" DS封装的RDD中的分区数为:${rdd.getNumPartitions} ")
/**
* foreachPartition,处理一个分区的数据
* 将一个分区的数据,封装成了一个迭代器
*/
rdd.foreachPartition((itr: Iterator[String]) => {
println("======================= 正在处理一个分区的数据 ==========================")
/**
* 创建与数据库连接对象
*/
//注册驱动
Class.forName("com.mysql.jdbc.Driver")
//创建数据库连接对象
val conn: Connection = DriverManager.getConnection(
"jdbc:mysql://master:3306/bigdata30?useUnicode=true&characterEncoding=UTF-8&useSSL=false",
"root",
"123456"
)
//创建预编译对象
val statement: PreparedStatement = conn.prepareStatement("insert into students values(?,?,?,?,?)")
println("========================= 创建了一次连接 =========================")
itr.foreach((line: String) => {
val info: Array[String] = line.split(",")
statement.setInt(1, info(0).toInt)
statement.setString(2, info(1))
statement.setInt(3, info(2).toInt)
statement.setString(4, info(3))
statement.setString(5, info(4))
//执行sql语句
statement.executeUpdate()
})
statement.close()
conn.close()
})
})
Spark 优化
spark 调优
避免创建重复的RDD
尽可能复用同一个RDD
对多次使用的RDD进行持久化 ♥
尽量避免使用shuffle类算子
使用map-side预聚合的shuffle操作
使用高性能的算子 ♥
广播大变量♥
使用Kryo优化序列化性能
优化数据结构使用高性能的库fastutil
对多次使用的RDD进行持久化
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大, 可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避 免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作 ,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传 送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种 策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化 级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出(OOM),那么建议尝试使用 MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个 partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别 比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算 子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上, 如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是 MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无 法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优 先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写 ,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将 所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性 能开销,除非是要求作业的高可用性,否则不建议使用。
使用高性能的算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map Transformation算子
使用foreachPartitions替代foreach Action算子
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作代码
repartition:coalesce(numPartitions,true) 增多分区使用这个
coalesce(numPartitions,false) 减少分区 没有shuffle只是合并 partition
aggregateByKey
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object Demo2AggregateByKey {
def main(args: Array[String]): Unit = {
//使用reduceByKey/aggregateByKey替代groupByKey
val sparkSession: SparkSession = SparkSession.builder()
.config("spark.sql.shuffle.partitions", "1")
.master("local[2]")
.appName("缓存优化")
.getOrCreate()
val sparkContext: SparkContext = sparkSession.sparkContext
val stuRDD: RDD[String] = sparkContext.textFile("spark/data/students.txt")
val clazzKVRDD: RDD[(String, Int)] = stuRDD.map(_.split(",") match {
case Array(_, _, _, _, clazz: String) =>
(clazz, 1)
})
//reduceByKey的使用,分组之后,直接使用聚合
//理解为普通的MapReduce中的根据相同的键进入到同一个reduce, 然后在reduce端聚合
//实际上这里对应的是前一个RDD中的分区中数据相同的键到后一个RDD中同一个分区,在后一个RDD分区中的聚合
// val resRDD: RDD[(String, Int)] = clazzKVRDD.reduceByKey(_ + _)
// resRDD.foreach(println)
//groupByKey 不做聚合,只做前一个RDD中的分区中数据相同的键到后一个RDD中同一个分区 (尽量使用reduceByKey去替代)
// val resRDD2: RDD[(String, Int)] = clazzKVRDD.groupByKey()
// .map((kv: (String, Iterable[Int])) => {
// (kv._1, kv._2.sum)
// })
// resRDD2.foreach(println)
//aggregateByKey
//aggregateByKey(zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U)
//zeroValue: 初始值,这个参数只会被后面第一个参数函数所使用
//seqOp: 相当于map端预聚合的逻辑
//combOp: 相当于reduce端的聚合逻辑
val resRDD3: RDD[(String, Int)] = clazzKVRDD.aggregateByKey(0)(
//相当于map端预聚合的逻辑
(a1: Int, a2: Int) => a1 + a2,
//相当于reduce端的聚合逻辑
(b1: Int, b2: Int) => b1 + b2
)
resRDD3.foreach(println)
}
}
mapPartitions
package com.shujia.opt
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import java.text.SimpleDateFormat
import java.util.Date
object Demo3MapPartitions {
def main(args: Array[String]): Unit = {
//使用mapPartitions替代普通map Transformation算子
//使用reduceByKey/aggregateByKey替代groupByKey
val sparkSession: SparkSession = SparkSession.builder()
.config("spark.sql.shuffle.partitions", "1")
.master("local[2]")
.appName("缓存优化")
.getOrCreate()
val sparkContext: SparkContext = sparkSession.sparkContext
val lineRDD: RDD[String] = sparkContext.textFile("spark/data/ant_user_low_carbon.txt")
println(s"lineRDD的分区数:${lineRDD.getNumPartitions}")
/**
* map算子主要作用是,遍历RDD中的每一条数据,进行处理返回新的一条数据
* 如果在处理过程中,需要创建工具对象的话,那么使用map不太好,原因是因为每一条数据都需要new一下
* 可能会造成内存溢出
*/
// val resRDD: RDD[(String, String, String)] = lineRDD.map((line: String) => {
// println("===================创建一次对象=============================")// 每次都会创建
// val info: Array[String] = line.split("\t")
// val t1: String = info(1)
// val sdf = new SimpleDateFormat("yyyy/MM/dd")
// val date: Date = sdf.parse(t1)
// val sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
// val t2: String = sdf2.format(date)
// (info(0), t2, info(2))
// })
// resRDD.foreach(println)
/**
* 实际上针对上面的案例,我们可以针对rdd中的每一个分区创建一个工具对象,在每条数据上使用
* mapPartitions,将每一个分区中的数据封装成了一个迭代器
*/
val resRDD: RDD[(String, String, String)] = lineRDD.mapPartitions((itr: Iterator[String]) => {
println("===================创建一次对象=============================") // 只会创建两次
val sdf = new SimpleDateFormat("yyyy/MM/dd")
val sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
itr.map((line: String) => {
val info: Array[String] = line.split("\t")
val t1: String = info(1)
val date: Date = sdf.parse(t1)
val t2: String = sdf2.format(date)
(info(0), t2, info(2))
})
})
resRDD.foreach(println)
}
}
Repartition和Coalesce区别
-
关系:两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
-
区别:repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle,一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo4Coalesce1 {
def main(args: Array[String]): Unit = {
//repartition:coalesce(numPartitions,true) 增多分区使用这个
//coalesce(numPartitions,false) 减少分区 没有shuffle只是合并 partition
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("重分区")
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("spark/data/students.txt")
println(s"lineRDD的分区数:${lineRDD.getNumPartitions}")
/**
* 使用repartition
*/
//增大分区数,使用repartition,返回一个新的rdd,会产生shuffle
// val resRDD1: RDD[String] = lineRDD.repartition(10)
// println(s"resRDD1的分区数:${resRDD1.getNumPartitions}")
// resRDD1.foreach(println)
//减少分区数,使用repartition,返回一个新的rdd,会产生shuffle
// val resRDD2: RDD[String] = resRDD1.repartition(1)
// println(s"resRDD2的分区数:${resRDD2.getNumPartitions}")
// resRDD2.foreach(println)
/**
* coalesce
*
* 1、默认增大分区是不会产生shuffle的 如果想要,加上参数shuffle = true
* 2、合并分区直接给分区数,不会产生shuffle
*/
val resRDD1: RDD[String] = lineRDD.coalesce(10, shuffle = true)
println(s"resRDD1的分区数:${resRDD1.getNumPartitions}")
// resRDD1.foreach(println)
val resRDD2: RDD[String] = resRDD1.coalesce(1,shuffle = true)
println(s"resRDD2的分区数:${resRDD2.getNumPartitions}")
resRDD2.foreach(println)
while (true) {
// 查看DAG
}
}
}
合并小文件时:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* 当资源充足的情况下,可以适当的使用重分区算子,扩大分区数
* 当资源不足的情况下,可以适当的减少分区数
*
* 分区数会影响rdd的并行任务数
*/
object Demo5Coalesce2 {
def main(args: Array[String]): Unit = {
//repartition:coalesce(numPartitions,true) 增多分区使用这个
//coalesce(numPartitions,false) 减少分区 没有shuffle只是合并 partition
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("重分区")
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("spark/data/test1/*")
println(s"lineRDD的分区数:${lineRDD.getNumPartitions}")
/**
* Coalesce算子通常是用在合并小文件时候使用
* 对应的spark core中的话,通常使用该算子进行合并分区
*/
val lineRDD2: RDD[String] = lineRDD.coalesce(1)
lineRDD2.foreach(println)
}
}
广播大变量
如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播 后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的 task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本 的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低 GC的频率
广播大变量发送方式:Executor一开始并没有广播变量,而是task运行需要用到广 播变量,会找executor的blockManager要,bloackManager找Driver里面的 blockManagerMaster要。
package com.shujia.opt
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo6Join {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("spark sql使用广播变量")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val studentsDF: DataFrame = sparkSession.read
.format("csv")
.option("seq", ",")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load("spark/data/students.txt")
val scoresDF: DataFrame = sparkSession.read
.format("csv")
.option("seq", ",")
.schema("id STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
/**
* 如果在spark sql中是两个DF进行join关联的话,并且运行模式是local模式的话,会自动地将关联的DF进行广播
* 如果不是local模式,不会自动进行,需要手动将要广播的DF给广播出去
*
* 广播大变量,1G的变量
*
* hint
* 会进行两次job作业
* 第一次是将关联的DF广播
* 第二次是使用广播的DF进行关联
*/
val resDF: DataFrame = scoresDF.join(studentsDF.hint("broadcast"), "id")
resDF.show()
while (true){
}
}
}
使用Kryo优化序列化性能
序列化:
在Spark中,主要有三个地方涉及到了序列化
- 在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输
- 将自定义的类型作为RDD的泛型类型时(比如JavaRDD,SXT是自定义类型),所有自 定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现 Serializable接口。
- 使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个 partition都序列化成一个大的字节数组。
Kryo序列化器介绍:
park支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,速度要快 ,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可 以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和 反序列化的性能。Spark默认使用的是Java的序列化机制,也就是 ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同 时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。 官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有 使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类 型,因此对于开发者来说,这种方式比较麻烦
自定义一个序列化类:
import com.esotericsoftware.kryo.Kryo
import org.apache.spark.serializer.KryoRegistrator
class Demo8Kryo extends KryoRegistrator {
// 实现它的方法
override def registerClasses(kryo: Kryo): Unit = {
//告诉spark程序,使用kryo序列化,具体是什么要进行kryo序列化
kryo.register(classOf[Student])
// kryo.register(classOf[Teacher])
}
}
使用kryo序列化:
.config(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
.config(“spark.kryo.registrator”, “自定义类”)
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
object Demo7Kryo {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.config("spark.sql.shuffle.partitions", "1")
//将序列化方式设置为Kryo的序列化方式
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//自定义一个序列化类,指定要序列化的东西
.config("spark.kryo.registrator", "com.shujia.opt.Demo8Kryo")
.master("local[2]")
.appName("缓存优化")
.getOrCreate()
val sparkContext: SparkContext = sparkSession.sparkContext
val studentsRDD: RDD[Student] = sparkContext.textFile("spark/data/students.txt")
.map(_.split(",") match {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student(id, name, age.toInt, gender, clazz)
})
/**
* 第二次job作业使用的数据大小
* 未使用序列化进行缓存:238.3 KiB
* 使用是默认的序列化方式:65.4 KiB
* 使用kryo序列化:43.0 KiB
*/
// studentsRDD.cache() // 默认的缓存级别是MEMORY_ONLY
studentsRDD.persist(StorageLevel.MEMORY_ONLY_SER)
/**
* 计算每个班级的人数
*/
val resRDD: RDD[(String, Int)] = studentsRDD.map((stu:Student)=>(stu.clazz,1)).reduceByKey(_ + _)
resRDD.foreach(println)
/**
* 计算每个性别的人数
*/
val resRDD2: RDD[(String, Int)] = studentsRDD.map((stu:Student)=>(stu.gender,1)).reduceByKey(_ + _)
resRDD2.foreach(println)
while (true) {
// 查看DAG 等信息
}
}
}
case class Student(id:String,name:String,age:Int,gender:String,clazz:String)// 样例类
优化数据结构
Java中,有三种类型比较耗费内存:
- 对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
- 字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
- 集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来 封装集合元素,比如Map.Entry。
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽 量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如 Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用 ,从而降低GC频率,提升性能。
数据本地性
数据本地化级别:
PROCESS_LOCAL 进程本地化,数据和task任务在同一个Executor中执行,默认
NODE_LOCA 节点本地化 数据和task任务在同一个节点中不同的Executor中执行 跨Executor拉取数据
NO_PREF 第三方存储中间件得到数据,mysql clickhouse redis
RACK_LOCAL 机架本地化 task任务和数据在同一个机架不同的节点中执行 跨节点拉取数据
ANY 跨机架本地化 task任务和数据不在一个机架上
配置参数
spark.locality.wait
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
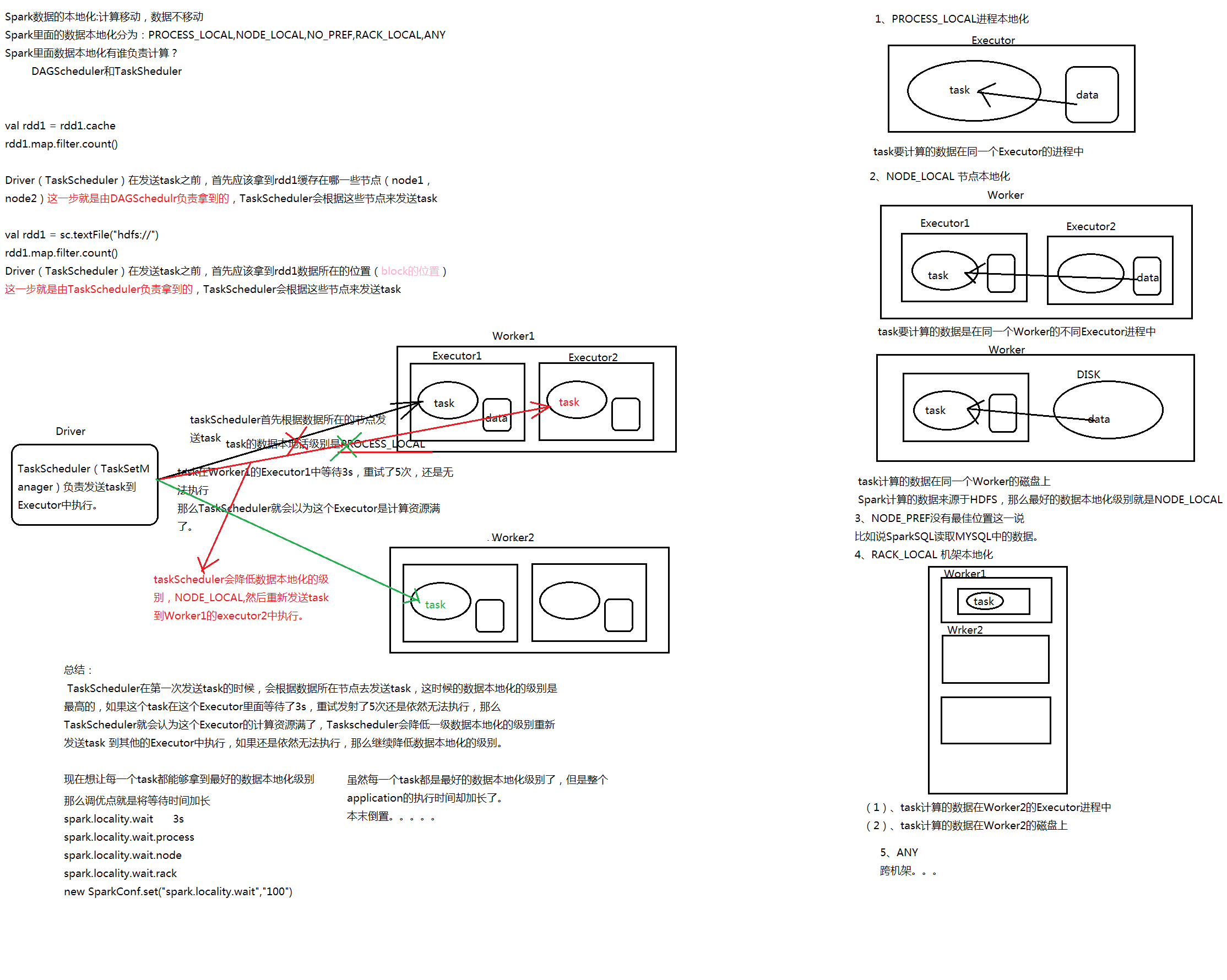
JVM调优
Spark task执行算子函数,可能会创建很多对象,这些对象,都是要放入JVM年轻代中
RDD的缓存数据也会放入到堆内存中
配置
spark.storage.memoryFraction 默认是0.6
调节Executor堆外内存
问题原因: Executor由于内存不足或者对外内存不足了,挂掉了,对应的Executor上面的block manager也挂掉了,找不到对应的shuffle map output文件,Reducer端不能够拉取数 据 Executor并没有挂掉,而是在拉取数据的过程出现了问题
调节一下executor的堆外内存。也许就可以避免报错;:
yarn下:–conf spark.yarn.executor.memoryOverhead=2048 单位M
standlone下:–conf spark.executor.memoryOverhead=2048单位M
也可以在代码中设置
堆外内存上限默认是每一个executor的内存大小的10%;真正处理大数据的时候, 这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G (1024M),甚至说2G、4G
调节等待时长
executor在进行shuffle write,优先从自己本地关联的BlockManager中获取某份数据如果本地 block manager没有的话,那么会通过TransferService,去远程连接其他节点上executor的block manager去获取,尝试建立远程的网络连接,并且去拉取数据 频繁的让JVM堆内存满溢,进行垃圾回收。正好碰到那个exeuctor的JVM在垃圾回收。处于垃圾回 收过程中,所有的工作线程全部停止;相当于只要一旦进行垃圾回收,spark / executor停止工作, 无法提供响应,spark默认的网络连接的超时时长,是60s;如果卡住60s都无法建立连接的话,那 么这个task就失败了。
解决?–conf spark.core.connection.ack.wait.timeout=300
参数模板
--num-executors executor的数量
--executor-memory 每一个executor的内存
--executor-cores 每一个executor的核心数
--driver-memory Driver的内存1G-2G(保存广播变量)
--spark.storage.memoryFraction 设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。
--spark.shuffle.memoryFraction 用户shuffle的内存占比默认0.2
-- spark提交yarn-client模式的命令模板
spark-submit --master yarn --deploy-mode client --num-executors 2 --executor-memory 1G --executor-cores 1 --class xxx.xxx.Xxx xxx.jar
-- spark提交yarn-cluster模式的命令模板
spark-submit --master yarn --deploy-mode cluster --num-executors 2 --executor-memory 1G --executor-cores 1 --class xxx.xxx.Xxx xxx.jar
总的内存=num-executors * executor-memory
总的核数=num-executors * executor-cores
不能乱给,且不能给满,因为作业执行还有其他的进行需要额外启动 --num-executors 200 --executor-memory 100G --executor-cores 100 (错误给资源的例子)
spark on yarn 资源设置标准
1、单个任务的总内存和总核数一般在yarn总的资源的1/3到1/2之间给资源
一般来说一个稍微大点的公司,集群的服务器个数大概在10台左右
单台服务器的内存大概是128G,核数大概是40个左右(国网,电信 100台以上)
小公司:如果公司规模总人数在80人左右,大数据部门在11人左右,5台大数据平台服务器 每一台的配置是8核16G内存
yarn总的内存 = 10*128G*0.8=960G
yarn总的核数 = 40*10=400
提交spark作业资源
参数计算后总的内存=960*(1/3 | 1/2)= 300G - 480G
参数计算后总的核数=400*(1/3 | 1/2)= 120 - 200
2、在实际生产上线的时候,资源要按照实际的情况合理定资源
2.1、数据量比较小 - 10G
10G = 80个block = rdd80分区 = 80个task
- 最理想资源指定 -- 剩余资源充足
--num-executors=40
--executor-memory=4G
--executor-cores=2
- 资源里面最优的方式 -- 剩余资源不是很充足时
--num-executors=20
--executor-memory=4G
--executor-cores=2
2.2、数据量比较大时 - 80G
80G = 640block = 640分区 = 640task
- 最理想资源指定 -- 剩余资源充足, 如果剩余资源不够,还需要减少指定的资源
--num-executors=100
--executor-memory=4G
--executor-cores=2
-- spark.locality.wait: spark task 再executor中执行前的等待时间 默认3秒
spark.yarn.executor.memoryOverhead : 堆外内存 默认等于堆内存的10%
spark.network.timeout spark网络链接的超时时间 默认120s
模板
spark-submit
--master yarn
--deploy-mode cluster
--num-executors = 50
--executor-memory = 4G
--executor-cores = 2
--driver-memory = 2G
--conf spark.storage.memoryFraction=0.4
--conf spark.shuffle.memoryFraction=0.4
--conf spark.locality.wait=10s
--conf spark.shuffle.file.buffer=64kb
--conf spark.yarn.executor.memoryOverhead=1024
--conf spark.network.timeout=200s
以下参数也可以在spark代码中指定
--conf spark.storage.memoryFraction=0.4
--conf spark.shuffle.memoryFraction=0.4
--conf spark.locality.wait=10s
--conf spark.shuffle.file.buffer=64kb
--conf spark.yarn.executor.memoryOverhead=1024
--conf spark.network.timeout=200s
shuffle调优
概述:
reduceByKey:要把分布在集群各个节点上的数据中的同一个key,对应的values,都给 集中到一个节点的一个executor的一个task中,对集合起来的value执行传入的函数进行 reduce操作,最后变成一个value
配置
spark.shuffle.manager, 默认是sort
spark.shuffle.consolidateFiles,默认是false
spark.shuffle.file.buffer,默认是32k
spark.shuffle.memoryFraction,默认是0.2
Spark 数据倾斜解决
-
Spark中的数据倾斜,表现主要有下面几种:
数据倾斜产生的原因:1、数据分布不均,2,同时产生了shuffle
- Executor lost,OOM,Shuffle过程出错;
- lDriver OOM;
- 单个Executor执行时间特别久,整体任务卡在某个阶段不能结束;
- 正常运行的任务突然失败
数据倾斜优化:
使用Hive ETL预处理数据
- 适用场景:导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
- 实现思路:此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
- 方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
- 方案优缺点:
- 优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
- 缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
- 方案实践经验:在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
过滤少数导致倾斜的key
- 方案适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
- 方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
- 方案实现原理:将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
- 方案优缺点:
- 优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
- 缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
提高shuffle操作的并行度
- 方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
- 方案实现思路:在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,默认是200,对于很多场景来说都有点过小。
- 方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。
- 方案优缺点:
- 优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
- 缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
双重聚合 (局部聚合+全局聚合)
- 方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
- 方案实现思路:这个方案的核心实现思路就是进行两阶段聚合:第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
- 方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
- 方案优缺点:
- 优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
- 缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
将reduce join转为map join
- 方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
- 方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量,广播给其他Executor节点;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
- 方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。具体原理如下图所示。
- 方案优缺点:
- 优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
- 缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
采样倾斜key并分拆join操作
- 方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
- 方案实现思路:对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀;而不会导致倾斜的大部分key形成另外一个RDD。接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀;不会导致倾斜的大部分key也形成另外一个RDD。再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。而另外两个普通的RDD就照常join即可。最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
- 方案实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。具体原理见下图。
- 方案优缺点:
- 优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
- 缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
使用随机前缀和扩容RDD进行join
- 方案实现思路:该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。然后将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。















 1825
1825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









