








引言
本期分享主题是美图SRE团队的稳定性运营实践,本期分享内容为「攻」规划&运营:3大方向、2个基础、1些探索、小结、Q&A

一、3大方向
稳定性「监控体系梳理」
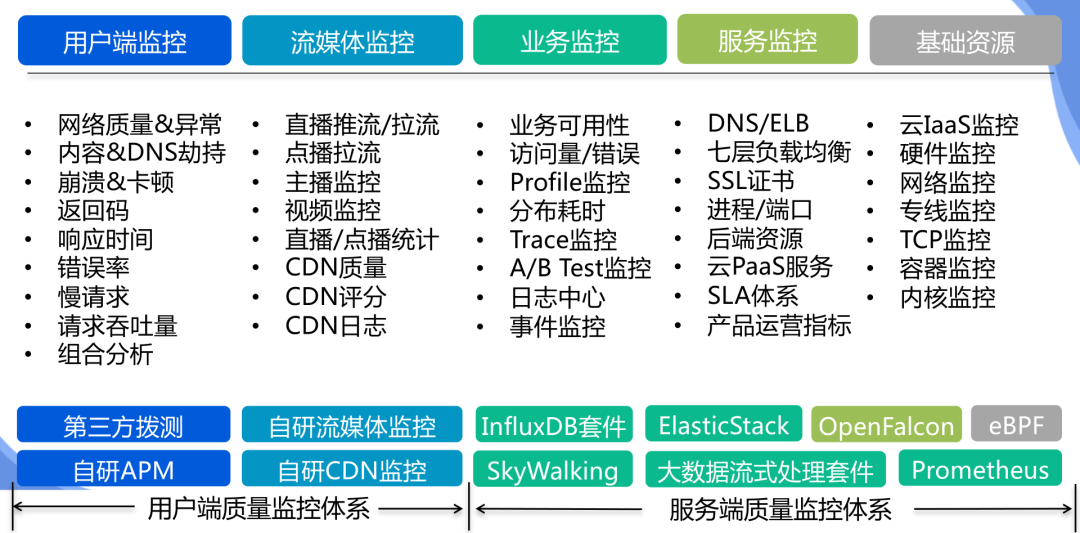
稳定性「可观测性建设-整体架构」
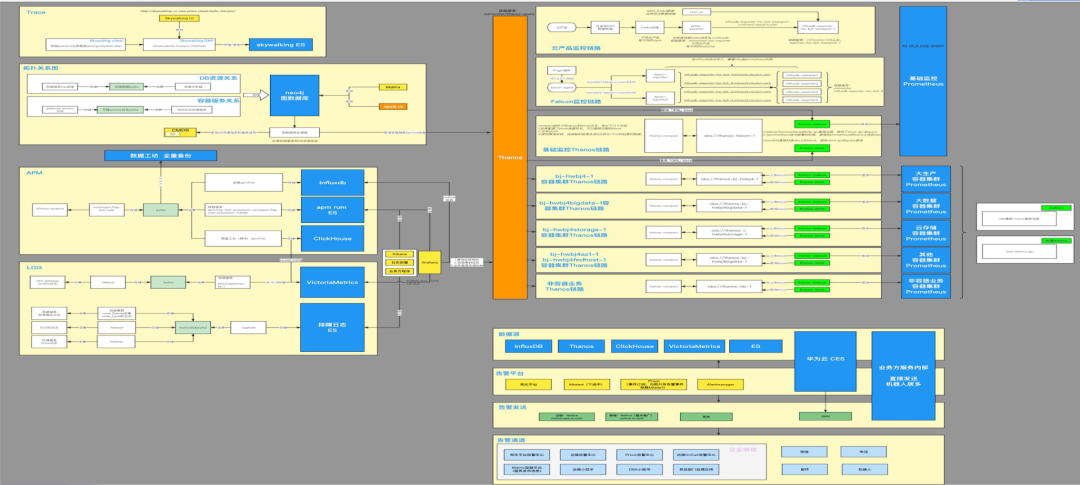
稳定性「监控大盘建设」
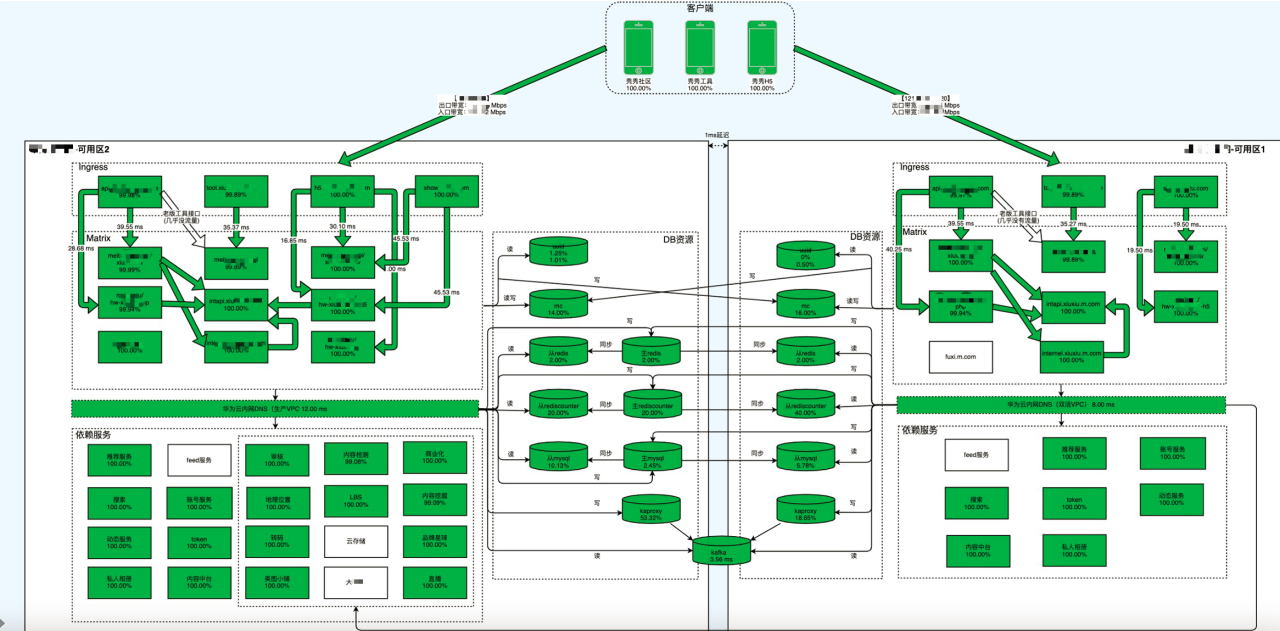
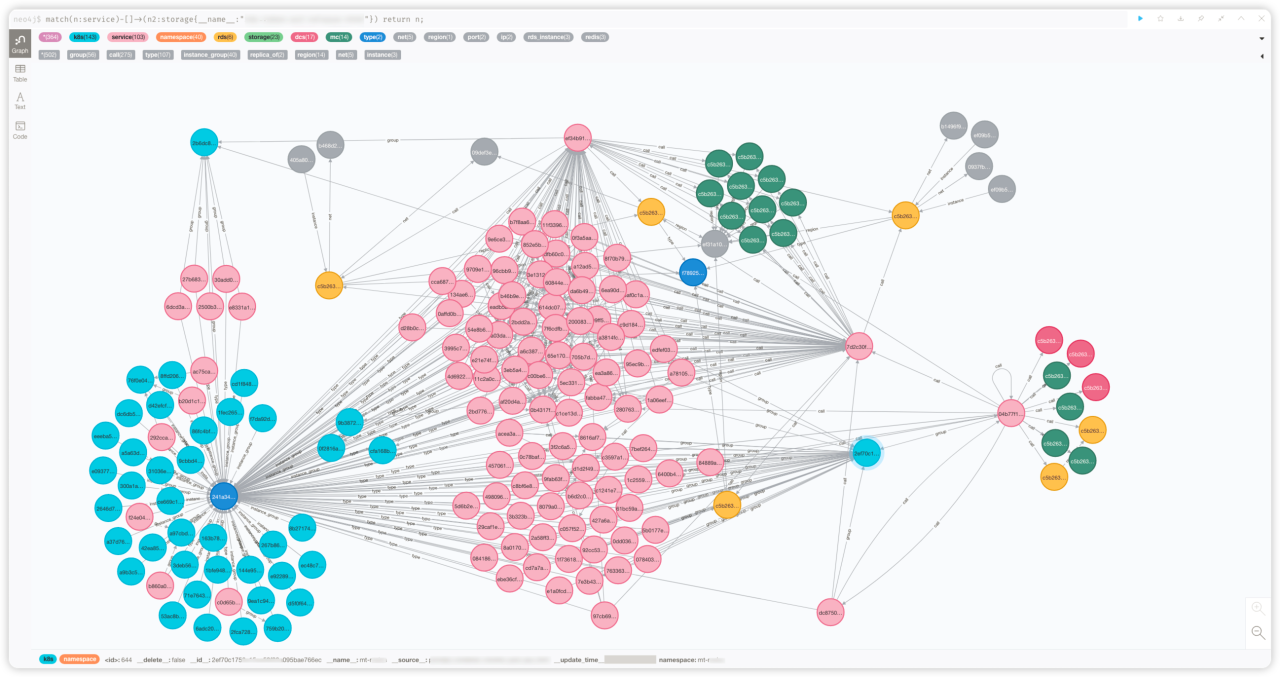
稳定性「运维元数据+应用拓扑」
稳定性「事件治理」
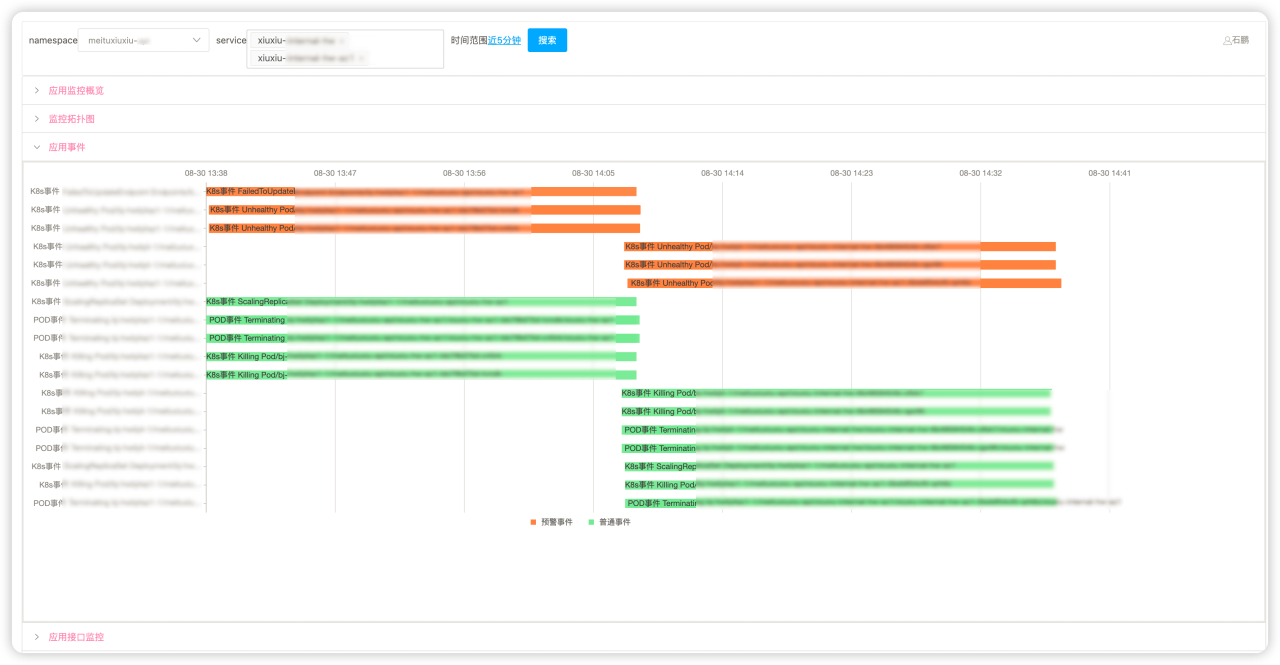
稳定性「图文告警推广」
提高告警消息的信息密度 (一图胜千言)
快速感知服务整体状态 (上下游/周边依赖)
缩短故障定位时间, 降低MTTR

稳定性「由监到控」
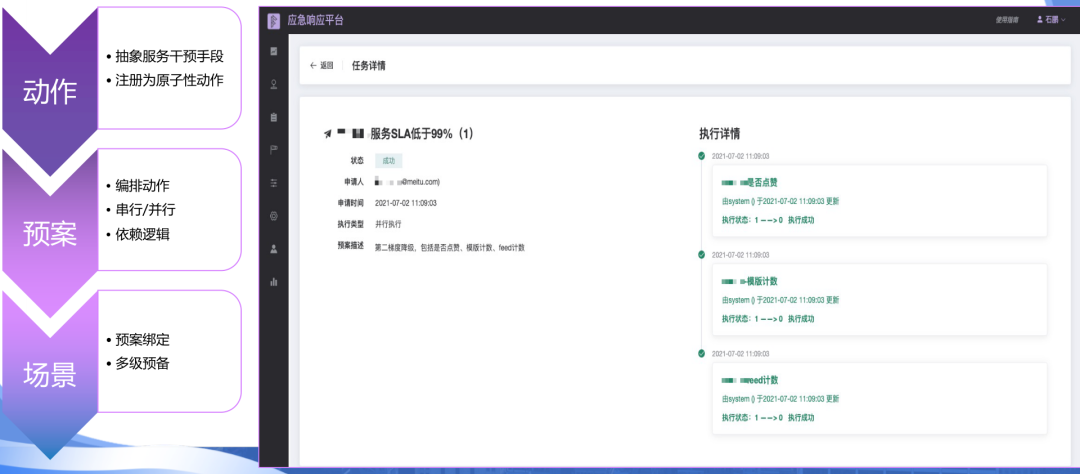
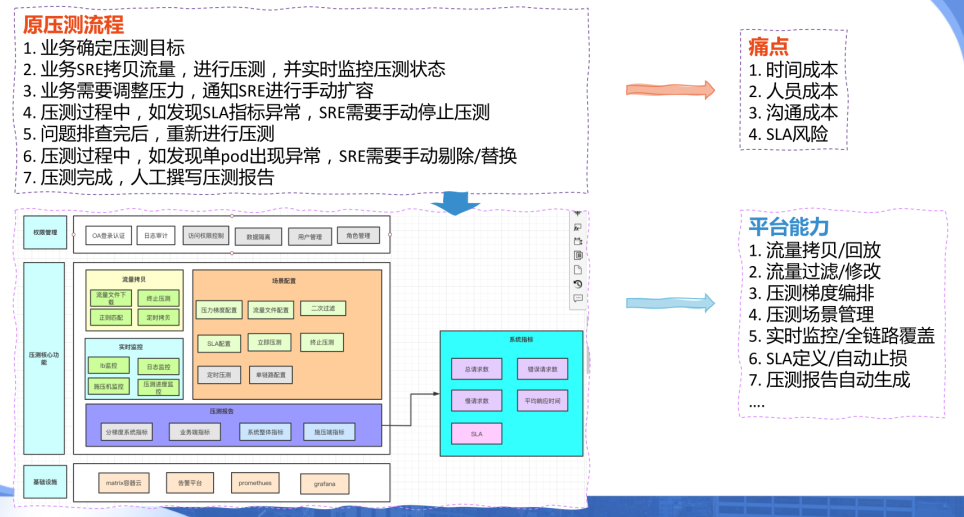
稳定性「全链路压测平台」
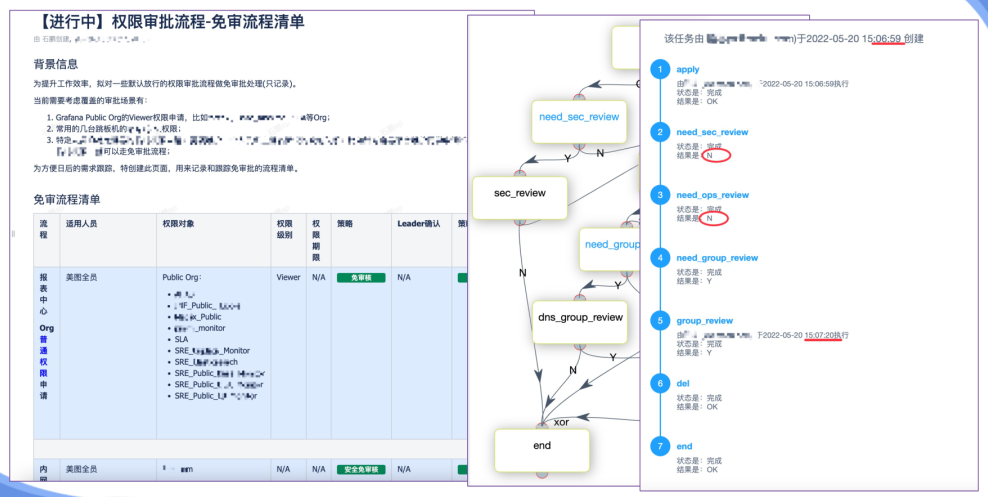
效率/支撑「工单流程优化」
效率/支撑「例行工作自动化」
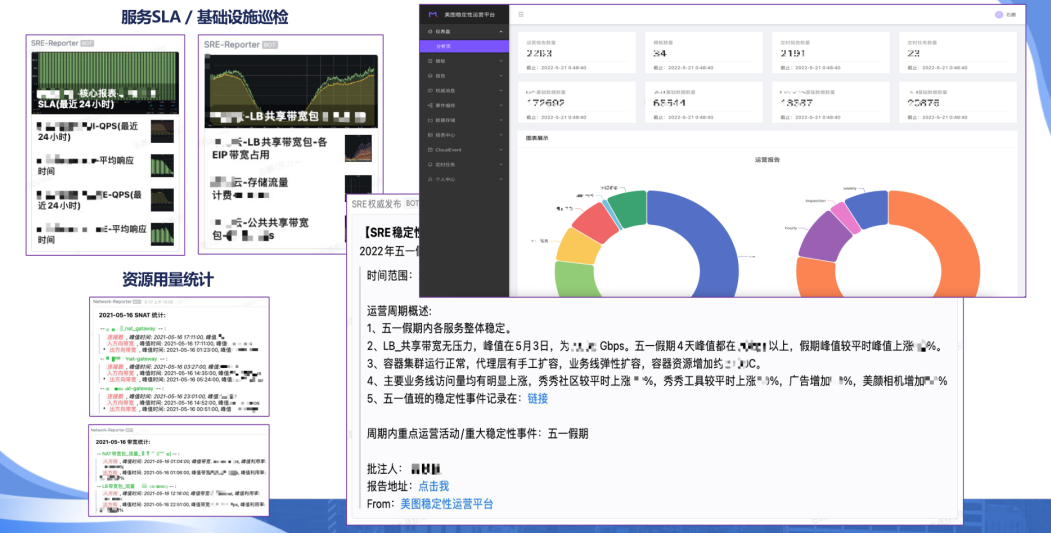
效率/支撑「命令行&移动端工具建设」
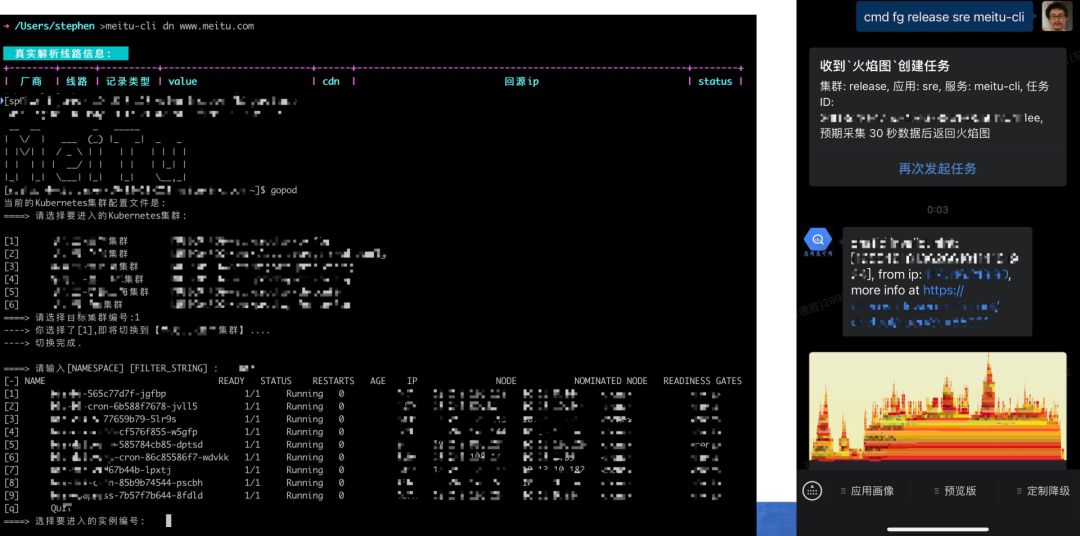
成本「成本管控之 CAP」
成本「FinOps探索实践」
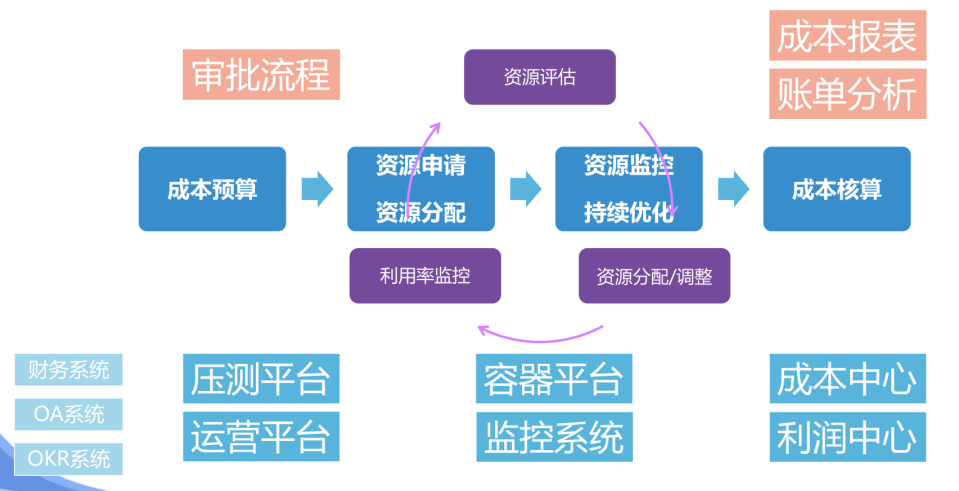
成本「MTCC平台」
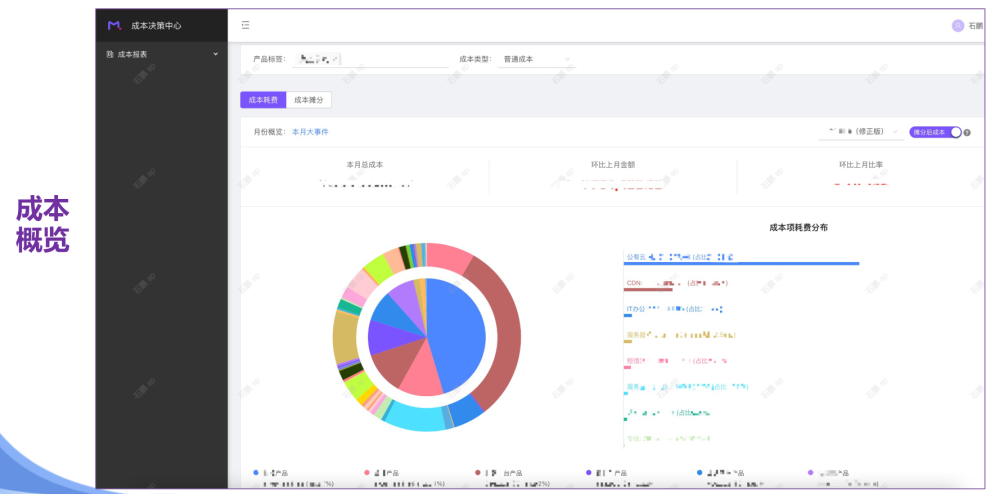
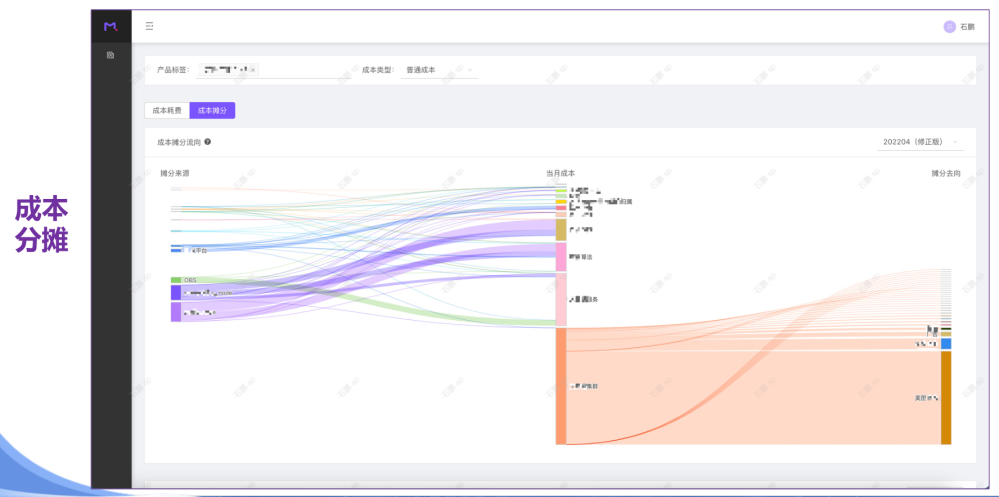
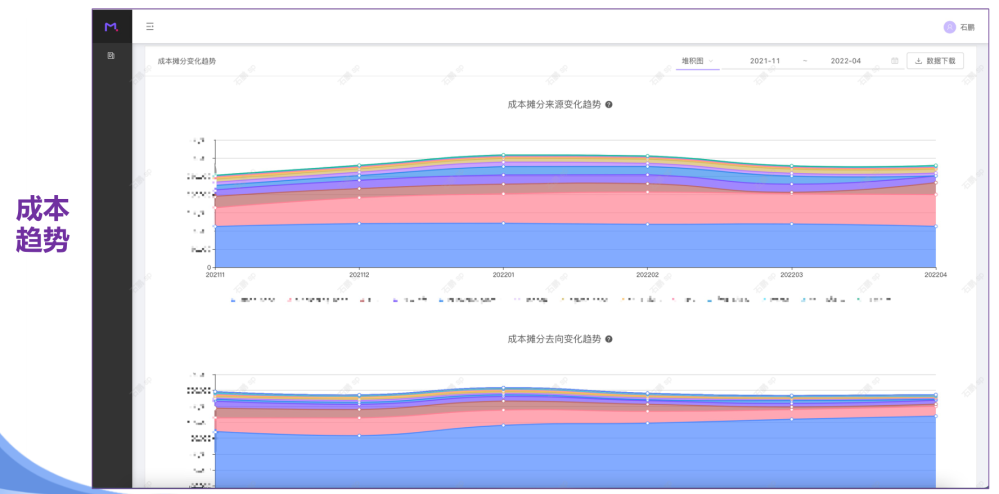
成本「FinOps落地的关键要素」

二、2个基础
2个基础「运维元数据 + 团队建设」

「运维元数据」

「团队建设:Pharos & AB岗」
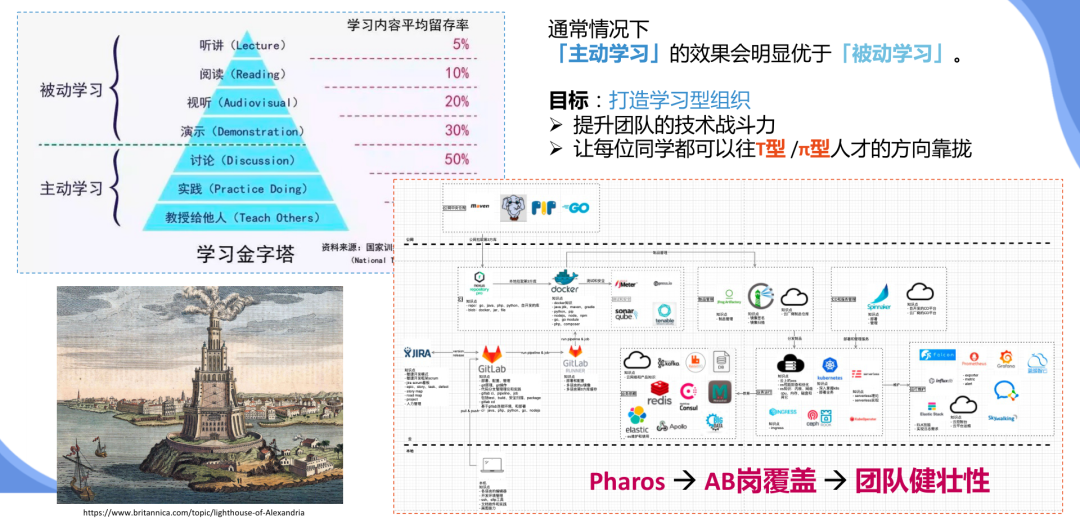
「团队建设:OKR + 敏捷」
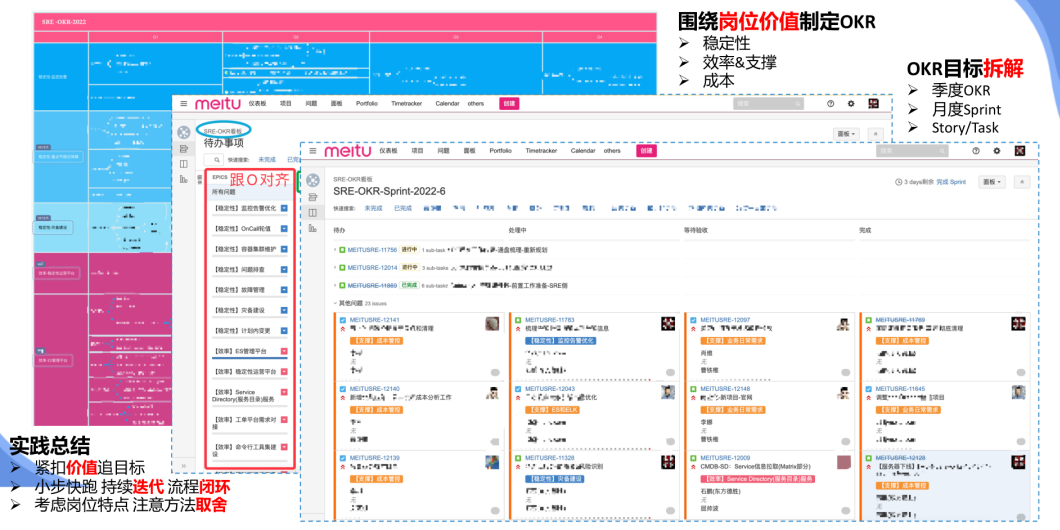
三、1些探索
SRE稳定性运营的「一些探索」

建立及运营「权威消息通道」


收敛固定SRE支撑「官方群组」

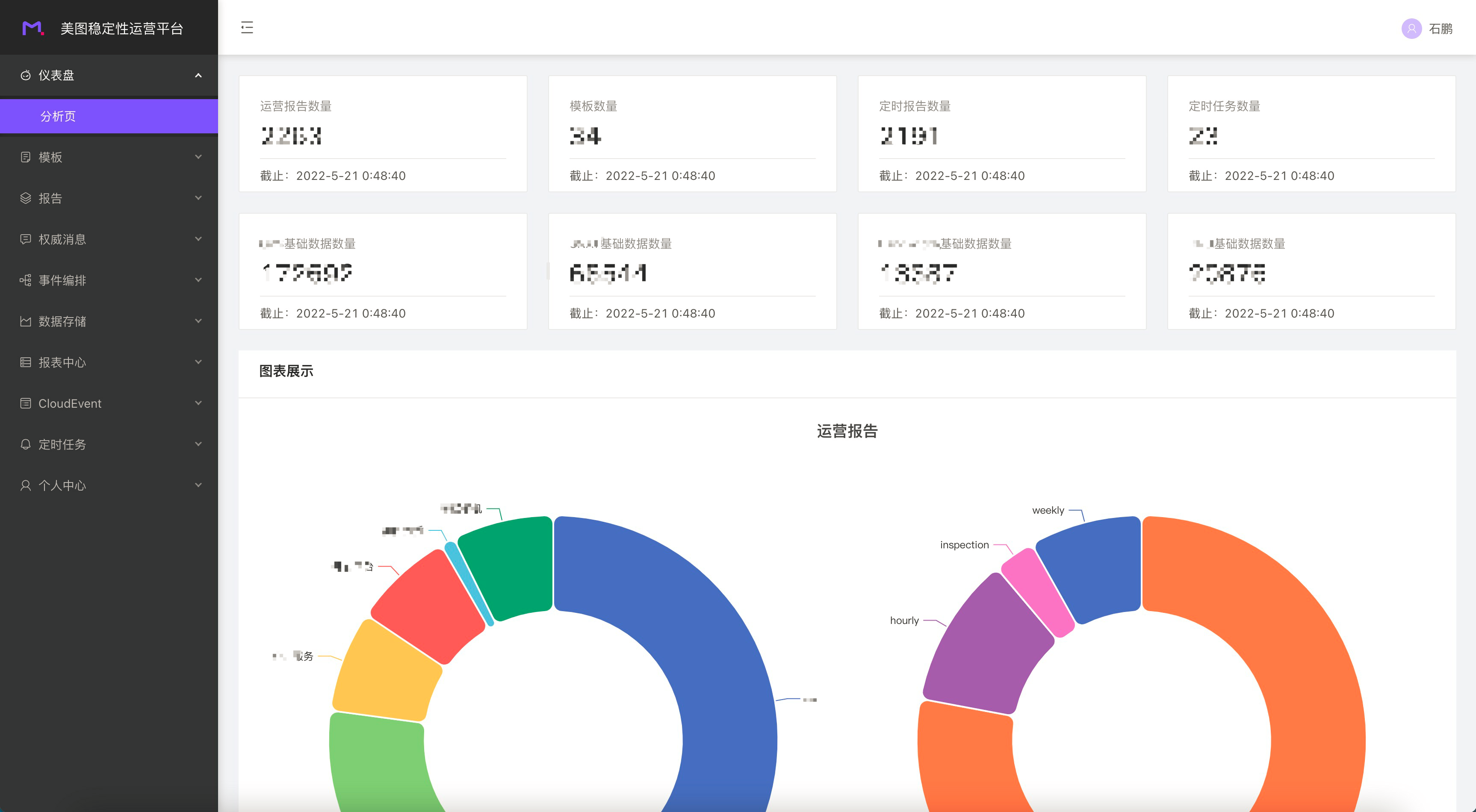
稳定性运营平台(在线使用)
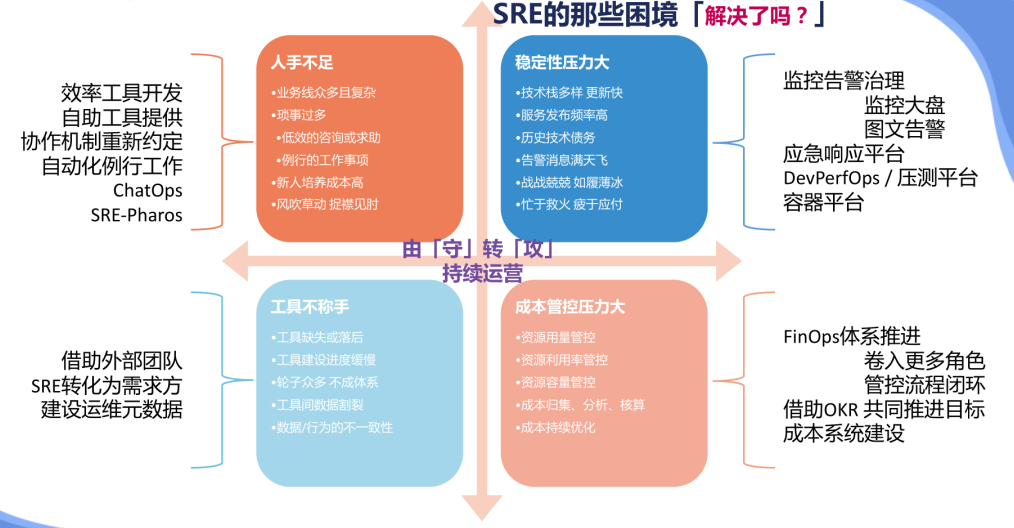
SRE的那些困境「解决了吗?」
四、小结
关于SRE工作开展的「几点概括」
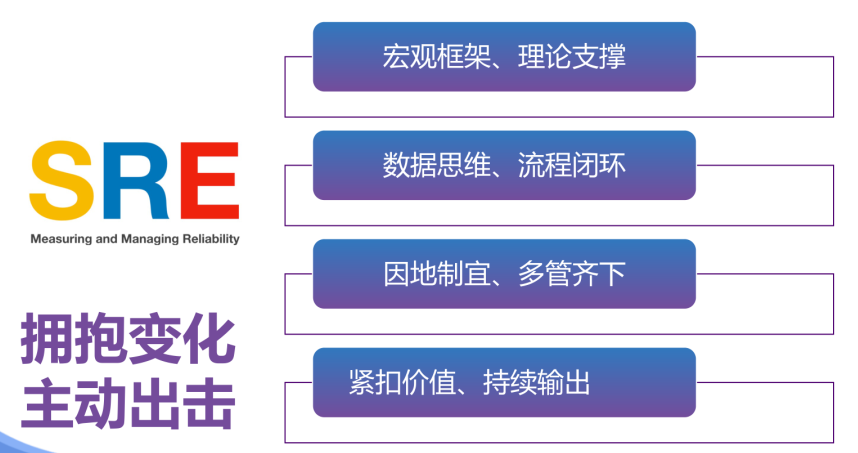
我所看到的几个「趋势」

最后的话「如何面对汹涌的技术浪潮」

五、互动答疑(Q&A)

石鹏(东方德胜)
2016年加入美图,运维技术专家,美图产品SRE负责人。目前在美图负责社区、商业化、实验室、影像SaaS、创新等全线产品的运维保障工作,同时参与公司日志、监控等基础设施的建设。参与或主导过多次公司基础设施的调整、改造,在监控、灾备、故障管理、稳定性运营等方面有一定的经验和积累。业界多个技术峰会的分享嘉宾或出品人。
Q1:可观测性建设整体架构中引用的工具体系非常多,它的底层的技术是 open telemetry 吗?是可以实现内核层面的观测,他可以拿到很多的信息,对吧?
A1:这里边我们其实用到了非常多的技术。Open Telemetry的话,我们是从去年年底开始来推,目前的话我们正在逐步地把我们的基础监控的agent换成Telemetry。其实现在大家讲这个内核层面的监控,大多都是用 BPF来做的。之前,我们架构团队同学有自研过Agent,也是用 BPF 的技术,去做一些这种内核级别的信息获取。
Q2:现在一个趋势是屏幕越做越大,但事实上里面实际用到的有用数据其实并不多,它堆砌了很多无用的东西,即可视化(visibility)做的并不好。从 SRE 的运维或者管理角度来讲,哪些是最有价值的一些信息?
A2:我的想法是这个事情可能还是要以终为始,从你要达成的目标来看。我们建设大屏是为了让我们更好地去发现问题,然后更快地去解决问题。所以说现在的一个建设思路,就是把一些更高维的一些信息,把最能够体现业务状态的关键指标抽出来,定义为一个北极星指标。但是我实际去解决问题的时候,我光靠这个北极星指标是不够的,我还是要去看日志、链路跟踪、一些堆栈的报错等。不过它可以给我一个指引,让我可以根据服务的拓扑关系,能够层层地钻下去。
Q3:所以您的建议是,大屏上并不是显示越来越多的信息就好,而是首先希望能够显示这些黄金指标,基于此能够有利于我们做 travel shooting 的这些全链路跟踪信息,您认为非常重要对吧?
A3:对,是的。我们要去做北极星指标,然后再下面的话,我们需要能够层层下钻。逐层去分析我们哪个层次、哪个环节出现了什么问题。然后要钻的话,需要有一个可靠的拓扑信息,也就是现在大家在屏幕上看大盘和报表底层的一个支撑数据。
Q4:现在已经是一个动态的环境了,在 Docker 和 K8S 里面都是。Docker 是个运行时,它其实一直在变动的,全链路跟踪也在实时的变动,你这个图是一个稳定的图吗?还是动态的?
A4:首先这个图它是动态的,它不是说静态的,你可以看到里面它有很多ID,这个其实就是我们不同 Pod 的这个ID,是动态的。
Q5:所以是基于一个时间线的trace,每一条都是代表一个span吗?这个 span 和 span 之间我把它串接起来以后,可以整个显示故障的影响范围和过程吗?
A5:大概的思路是这个样子,但是这个我们现在在图上看到的更多是我们的事件系统,跟Trace还有些区别。底层是一个我们基于Cloud Events的实现,用来做事件消息的管理。
Q6:从 AI 到生产还是有距离,对吧?
A6:我觉得它也是逐步发展。首先它可能是在学术领域会有比较好的成果,然后逐步的话可能会在某些垂直领域有一些行业的专家经验,或者比较丰富的一些历史素材的积累的加持,然后再这种前提下我们才能够把那一块做深、做好。
然后如果说是想直接去出一个大而全的,像 ChatGPT 这样,你去跟他聊什么他都能跟你聊两句,什么故障他都能帮你处理,这种可能大概率是不现实的。因为这个可能还会涉及到不同企业里面的个性化情况,比如基础设施并不是标准的,可能是自建的、公有云的或是其他,这些所有的可行性的预案类的东西都要基于一些标准化的前提,当然如果只是给我们提供一些专家经验、知识库的问答,应该还是比较可行的。
Q7:压测流程目前是基于人来调用,还是用那个pipeline,用流水线都做到了目前这么一个状态?
A7:就是中间执行的部分是流水线,触发部分的话是可以去定时触发,也可以手动触发。也可以做相对比较自由的编排。
Q8:这个流程是写在 yaml 文件里面的,是吗?用pipeline是怎么做到的?
A8:目前不是这样的,目前我们是选择式的,为了降低用户的使用门槛,用户可能就勾勾选选就好了,然后把一些东西抽象出来,填一填。没有把类似Pipeline的配置文件开放出来。
Q9:这个 FinOps最近也比较热,但它的来源是来自于公有云的,基于这个订阅式服务的,它的适用场景是就去中心化的,但是这个跟传统 ITIL 里面讲这个集中管控的财务管理不太一样。美图是公有的,都放在云上的吗?还是自己私有云呢?
A9:目前的话我们绝大多数资源都是在云上,都是公有云。但是我认为,FinOps 它所定义的这个场景范围其实是被大大缩小了的、被定义给局限了。其实FinOps里面的一些理念抽象之后,就是在做一个 IT 资源的一个供需管理,你的需求是什么样的,然后我的供给侧是什么样子的?我怎么去更好地去做供给,然后怎么样让资源达到一个比较理想的利用率,最终去达到降本这个目标。
Q10:在传统的 IT 环境下也是讲这个供需的平衡,但是这个平衡在公有云模式下被这个去中心化给突破了,因为没有一个管控点。你们怎么管控这个云资源、云服务的使用 ?
A10:最近在FinOps这个方向上,我跟多个企业的老师也有过交流。然后关于管控点这个点其实蛮重要的,就是你的基础设施资源一定要是中央集权化管控的才会更好推行FinOps。
本期视频回看:

雅菲奥朗官网:www.sretraining.cn
简介:雅菲奥朗是国内知名的IT培训和咨询公司,是SRE的实践者与引领者。我们秉承“知识创新、方法创新、实践创新”的核心理念。我们基于在多家知名企业的成功落地经验,持续引入国际先进的理念和方法论,并结合中国实际情况进行深度创新,我们拥有独创的培训和咨询方法论。雅菲奥朗致力于培养与时俱进的科技创新人才,专注于“互联网时代”的IT培训与咨询,我们帮助企业进行数字化转型,持续提升科技管理能力,赶超世界先进水平。
















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









