









原理
模型如下图所示

Zi,t 表示 序列i 在 第t个时间点 的数据
Zi,t0就是要预测数据的开始区间
预测的数据集合定义为 [ Zi : t0: T] LSTM输入
Xi,1:T表示再整个预测期间内都知道的协变量,就是输入的原始数据。
上图 左右都是LSTM结构,
左右用的数据不一样,一个用的是训练数据,一个用的是预测数据
deepar 本质就是lstm+softplus。
要求
数据具有相同的频率、分类特征数量和动态特征数量
GluonTS优点
模型非常简单。
GluonTS 提供多种选择,
例如序列到序列框架、自回归网络和因果卷积等等。
GluonTS 提供了累积分布函数或分位函数的直接建模工具,这些都可以方便地包含在神经网络架构中。此外还包括了其他概率化组件,例如高斯过程和线性高斯状态空间模型(包括一种卡尔曼滤波器的实现),从而轻松创建神经网络与传统概率模型的组合。
GluonTS模型
model.canonical 基础RNN模型
model.deep_factor DeepFactor模型
model.deepar DeepAR模型
model.deepstate DeepSate模型
model.deepvar DeepVAR模型
model.gp_forecaster 高斯过程模型
model.gpvar GPVAR模型
model.lstnet LSTNet模型
model.n_beats NBEATS模型
model.naive_2 季节模型
model.npts NPTS模型
model.Prophet Prophet模型
model.r_forecast R语言 Forecast
model.renewal Renewal模型
model.rotbaum QRX模型
model.san 注意力模型
model.seasonal_naive 季节模型
model.seq2seq 序列模型
model.simple_feedforward 全连接网络
model.tft 时序融合Transformer模型
model.tpp PointProcess模型
model.transformer transformer模型
model.trivial 常数模型
model.wavenet Wavenet模型
源自aws
https://aws.amazon.com/cn/blogs/china/gluon-time-series-open-source-time-series-modeling-toolkit/
环境安装
强烈建议新建一个虚拟环境,在虚拟环境里面折腾
不要直接在root的环境里面搞事情
通过anaconda创建虚拟环境
记得选择python的版本为3.6版本

如果anaconda创建虚拟环境报错
参考下面这个链接的文章去修改一下下载的包的网址为清华镜像就可以了
https://abraham.blog.csdn.net/article/details/105105728?spm=1001.2014.3001.5506
如果还是存在下载超时,速度慢的问题可以参加下面这个文章进行修改
https://blog.csdn.net/ak739105231/article/details/90109096
进入虚拟环境安装
安装ipykernel
conda install ipykernel
python -m ipykernel install --user --name=python3.6
启动jupyternotebook
在kenel中就可以看到新配置的虚拟环境jupyternotebook的配置进行切换了

pip install matplotlib numpy pandas pathlib
pip install mxnet mxnet-mkl gluon gluonts
安装mxnet
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ mxnet gluonts
先行案例:
下面这个案例跑一下:
看看效果
from gluonts.mx.trainer import Trainer
from gluonts.dataset import common
from gluonts.model import deepar
import pandas as pd
#读取数据
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd.read_csv(url, header=0, index_col=0)
data = common.ListDataset([{
"start": df.index[0],
"target": df.value[:"2015-04-05 00:00:00"]
}], freq="5min")
#初始化deepAR模型
trainer = Trainer(epochs=10)
estimator = deepar.DeepAREstimator(
freq="5min", prediction_length=12, trainer=trainer)
predictor = estimator.train(training_data=data)
# 得到预测结果
prediction = next(predictor.predict(data))
print(prediction.mean)
prediction.plot(output_file='graph.png')

入门案例
导包
from gluonts.mx.trainer import Trainer
from gluonts.model.deepar import DeepAREstimator
from gluonts.dataset.util import to_pandas
import matplotlib.pyplot as plt
import pandas as pd
数据下载地址
https://github.com/zmkwjx/GluonTS-Learning-in-Action/blob/master/chapter-1/data/Twitter_volume_AMZN.csv
读取数据
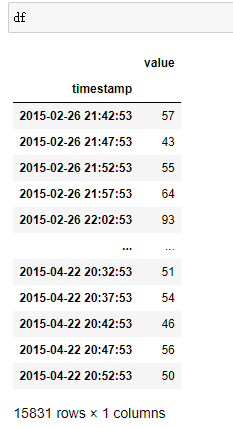
将时间设为索引列,另一列为要用来进行预测的历史值
path = r'C:\Users\Administrator\Desktop\Twitter_volume_AMZN.csv'
# 索引为第一个列
df = pd.read_csv(path, header=0, index_col=0)
设置开始时间和所以用于训练模型的值
common.ListDataset 加载训练数据
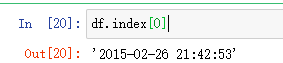
data = common.ListDataset([{"start": df.index[0],
"target": df.value[:"2015-04-23 00:00:00"]}], freq="H")

加载训练数据
# 加载训练数据
# 将数据开始日期,预测最后要结束的日期,和频率导入
data = common.ListDataset([{"start": df.index[0],
"target": df.value[:"2015-04-22 20:52:53"]}], freq="H")
class gluonts.dataset.common.ListDataset(data_iter: Iterable[Dict[str, Any]],
freq: str,
one_dim_target: bool = True)
data_iter: 可迭代对象产生数据集中的所有项目。每个项目都应该是一个将字符串映射到值的字典。
例如:{“start”: “2014-09-07”, “target”: [0.1, 0.2]}
freq: 时间序列中的观察频率。
one_dim_target: 是否仅接受单变量目标时间序列。
参考网站 or API参数官方指导
https://ts.gluon.ai/api/gluonts/gluonts.dataset.common.html
训练模型
# 训练现有的模型 GluonTS
# 构造一个DeepAR网络、并进行训练
# prediction_length: 需要预测的时间长度
# training_data: 训练数据
# 搭建网络
estimator = deepar.DeepAREstimator(freq="H", prediction_length=24) # 设置预测频率,预测长度和迭代次数
# 将数据传入预估器 继续训练
predictor = estimator.train(training_data=data)

将预测结果绘图展示
# 画图展示预测
for test_entry, forecast in zip(data, predictor.predict(data)):
plt.figure(figsize =(15,8),dpi=80)
to_pandas(test_entry)[-60:].plot(linewidth=2)
forecast.plot(color='g', prediction_intervals=[50.0, 90.0])
plt.grid(which='both')
# plt.grid(linestyle='-.') # 添加网格
plt.legend(['past observations','median prediction','90% prediction interval','50% prediction'])
plt.show()

输出预测结果
##输出预测结果
prediction = next(predictor.predict(data))
print(prediction.mean)
prediction.plot(output_file='graph.png')

保存训练好的模型
保存训练好的模型
predictor.serialize(path("保存模型的路径"))
使用之前训练好的模型进行预测
predictor = Predictor.deserialize(path(“模型所在的路径”))
例子:
直接使用之前已经训练好的模型进行预测
path = "./data/Twitter_volume_AMZN.csv"
df = pd.read_csv(path, header=0, index_col=0)
train_data = common.ListDataset({"start":df.index[0],
"target":df.value[:'"2015-04-23 00:00:00"']},
freq="H")
导入训练好的模型
predictor = Predictor.deserialize(path("模型所在的路径"))
使用模型进行预测
prediction = next(predictor.predict(train_data))
将预测结果绘制并保存
prediction.plt(output_file='graph.png')
给DeepAR模型传入数据
data = common.ListDataset([{"start": df.index[0],
"target": df.value[:"2015-04-23 00:00:00"]}], freq="H")
参数
start — 格式为 yyy-MM-DD HH:MM:SS 的字符串。开始时间戳不能包含时区信息。
开始时间。
target — 表示时间序列的浮点值或整数数组。您可以将丢失的值编码为null,或者在JSON中编码为"NAN"字符串:
所有的过去的值。
举例子
{"start": "2009-11-01 00:00:00",
"target": [5, "NAN", 7, 12]}
额外的可选参数
feat_dynamic_real:
代表自定义要素时间序列(动态要素)向量的浮点值或整数数组。
设置这个字段的话,
所有记录必须具有相同数量的内部数组(相同数量的特征时间序列)。
每个内部数组必须具有与关联target值相同的长度 。
如果目标时间序列代表不同产品的需求,则feat_dynamic_real可能是布尔时间序列,它指示是否对特定产品应用了促销:
{"start": ...,
"target": [5, "NAN", 7, 12],
"dynamic_feat": [[1, 0, 0, 1]]}
这里的1表示促销,0表示不促销。
feat_static_cat:
对记录所属的组进行编码的分类特征数组。
分类要素必须编码为基于0的正整数序列。
如果 target 时间序列表示服装商品需求,则您可以关联一个二维 cat 向量,该向量在第一个组件中编码商品类型(例如,0 = 鞋子,1 = 连衣裙),在第二个组件中编码商品颜色(例如,0 = 红色,1 = 蓝色)。示例输入如下所示
{ "start": ..., "target": ..., "feat_static_cat": [0, 0], ... } # red shoes
{ "start": ..., "target": ..., "feat_static_cat": [1, 1], ... } # blue dress
两个参数都用的例子
分类域{R,G,B}可以编码为{0,1,2}。
来自每个分类域的所有值都必须在训练数据集中表示。
{"start": "2009-11-01 00:00:00",
"target": [4.3, "NaN", 5.1, ...],
"feat_static_cat": [0, 1],
"feat_dynamic_real": [[1.1, 1.2, 0.5, ...]]}
{"start": "2012-01-30 00:00:00",
"target": [1.0, -5.0, ...],
"feat_static_cat": [2, 3],
"feat_dynamic_real": [[1.1, 2.05, ...]]}
{"start": "1999-01-30 00:00:00",
"target": [2.0, 1.0],
"feat_static_cat": [1, 4],
"feat_dynamic_real": [[1.3, 0.4]]}
如果不添加以上两个 可选参数,
就是一个“全局”模型,该模型在推理时与目标时间序列的特定身份无关,并且只受其形状的约束。
搭建DeepAR网络
class gluonts.model.deepar.DeepAREstimator(
# 时间序列中的观测频率
freq: str,
# 预测范围的长度
prediction_length: int,
trainer: gluonts.trainer._base.Trainer = gluonts.trainer._base.Trainer(batch_size=32,
clip_gradient=10.0,
ctx=None, # ctx="cpu" 是否使用GPU
epochs=100, # 全部数据训练次数 可以改为epochs=300
hybridize=True,
init="xavier",
learning_rate=0.001, # 学习率 可以改为 1e-3
learning_rate_decay_factor=0.5,
minimum_learning_rate=5e-05,
num_batches_per_epoch=50,
patience=10,
weight_decay=1e-08),
# 在计算预测之前要为RNN展开的步骤数(默认值:None,在这种情况下,context_length = projection_length)
context_length: Optional[int] = None,
# RNN层数(默认值:2)
num_layers: int = 2,
# 每层的RNN信元数(默认值:40)
num_cells: int = 40,
# 要使用的循环单元格类型(可用:“ lstm”或“ gru”;默认值:“ lstm”)
cell_type: str = 'lstm',
# dropout_rate: 辍学正则化参数(默认值:0.1)
dropout_rate: float = 0.1,
# 是否使用 feat_dynamic_real 数据中的字段(默认值:False)
use_feat_dynamic_real: bool = False,
# 是否使用 feat_static_cat 数据中的字段(默认值:False)
use_feat_static_cat: bool = False,
# 是否使用 feat_static_real 数据中的字段(默认值:False)
use_feat_static_real: bool = False,
# 每个分类特征的值数。如果 use_feat_static_cat == True,则必须设置(默认:None)
cardinality: Optional[List[int]] = None,
embedding_dimension: Optional[List[int]] = None,
distr_output:gluonts.distribution.distribution_output.DistributionOutput = gluonts.distribution.student_t.StudentTOutput(),
# 是否自动缩放目标值(默认值:True)
scaling: bool = True,
# 用作RNN输入的滞后目标值的索引(默认值:None,在这种情况下,将根据频率自动确定这些值)
lags_seq: Optional[List[int]] = None,
# 用作RNN输入的时间特征(默认值:None,在这种情况下,它们是根据频率自动确定的)
time_features:Optional[List[gluonts.time_feature._base.TimeFeature]] = None,
# 每个时间序列的评估样本数,以在推理期间增加并行度。这是一个不影响准确性的模型优化(默认值:100)
num_parallel_samples: int = 100)
参考文章链接:
https://zhuanlan.zhihu.com/p/80851582
https://juejin.cn/post/6949076763230568485
https://github.com/zmkwjx/GluonTS-Learning-in-Action/tree/master/chapter-1
https://zmkwjx.github.io/2019/11/14/gluonts-learning-in-action-chapter2/
https://mp.weixin.qq.com/s/sO-Od9x_QH27zJOg6e_FKg
https://aws.amazon.com/cn/blogs/china/gluon-time-series-open-source-time-series-modeling-toolkit/
https://github.com/zmkwjx/GluonTS-Learning-in-Action/blob/master/chapter-1/data/Twitter_volume_AMZN.csv
https://blog.csdn.net/qq_34461600/article/details/103067584














 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









