







需求
有业务需求,想实现同一表单中的不同明细表,根据批次与数量,进行匹配校验,如果相同批次的数量,与另一明细表中相同批次的数量不同,要求提示并无法提交。
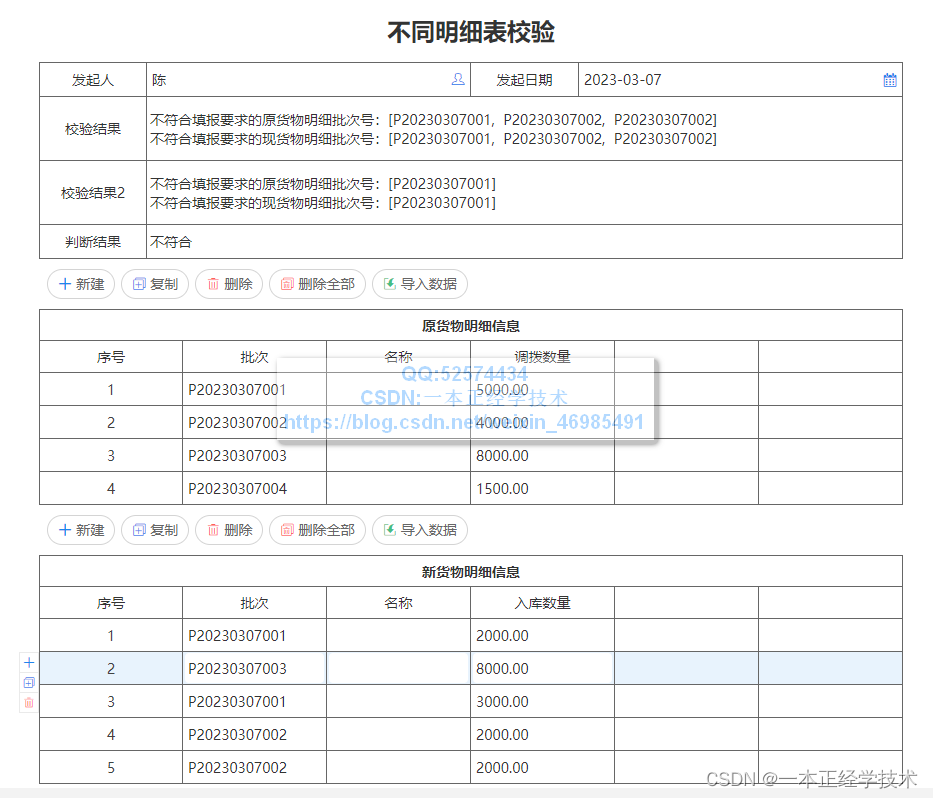
原表单截图如下:
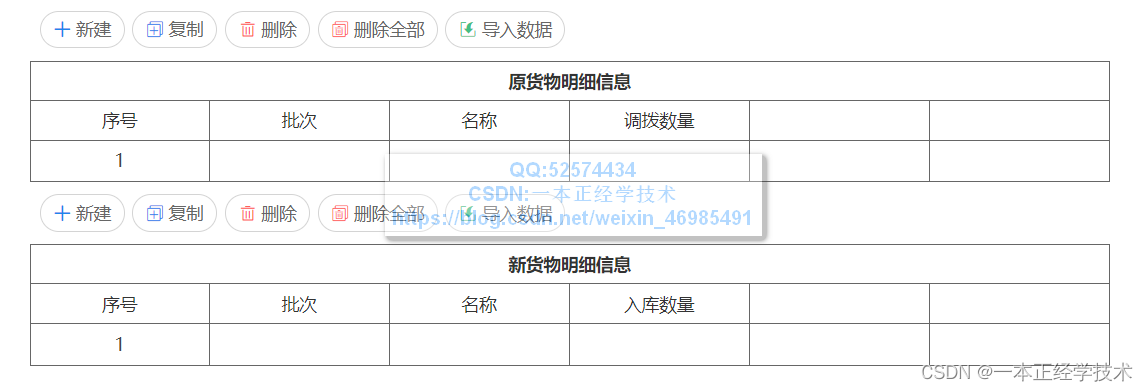
原货物明细中的批次对应的调拨数量与新货物明细中的批次对应的入库数量相匹配,例如:在原货物明细中批次P20230307001,对应调拨数量1000.00,在现货物明细中批次P20230307001,对应的入库数量如果不为1000.00,则提示并无法提交,以保证数据精准度要求。
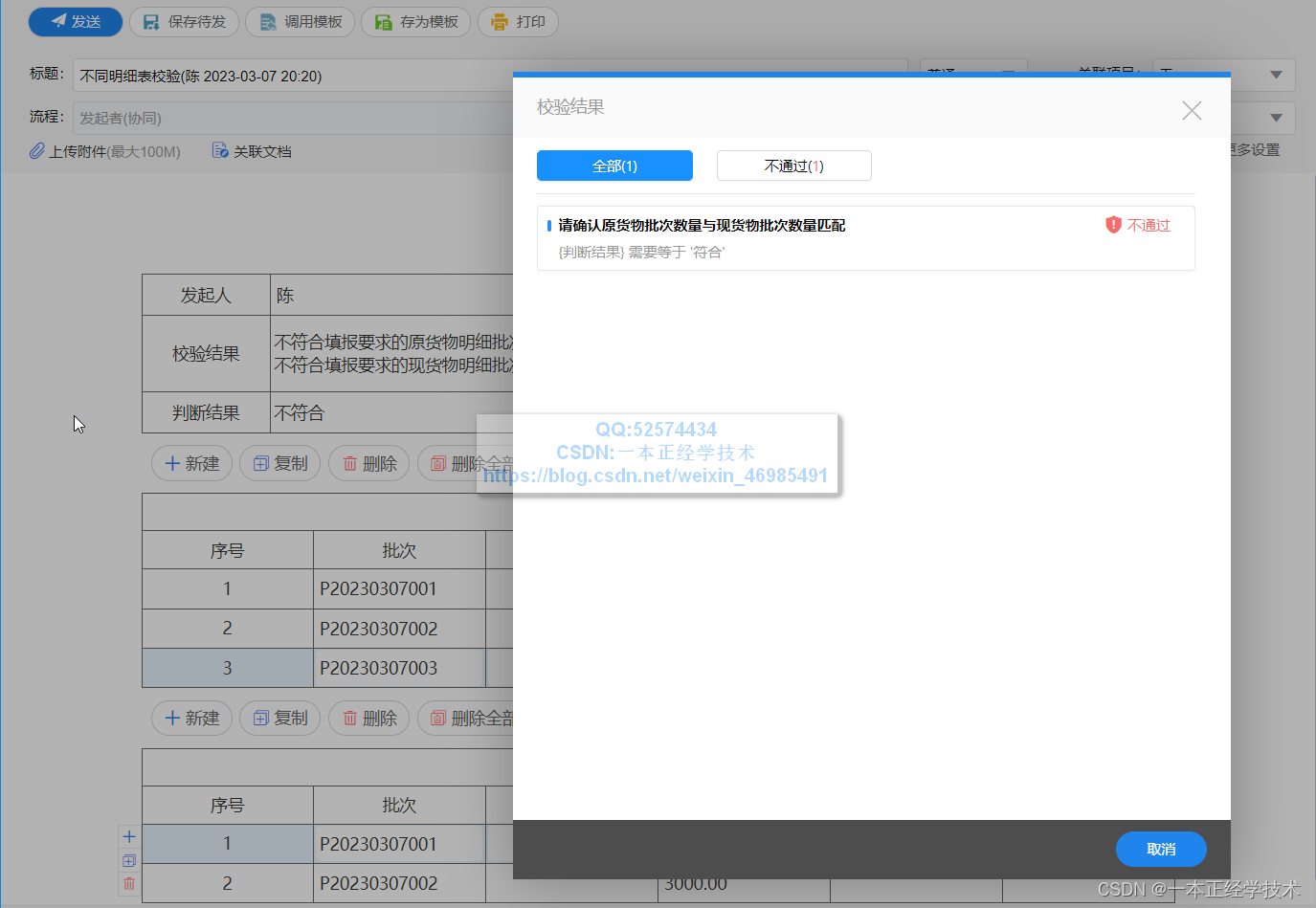
效果示例如下图:

在提交发送时,会弹出校验提示:
实现
1、设计表单
在原表单基础上增加相关字段,分别如下:
原货物批次、原货物数量、现货物批次、现货物数量、校验结果、判断结果等。
如果致远的表单定义函数支持参数跨明细表选择,那就不用这么麻烦增加设置多个字段了!o_o
表单设计态的效果如下图:
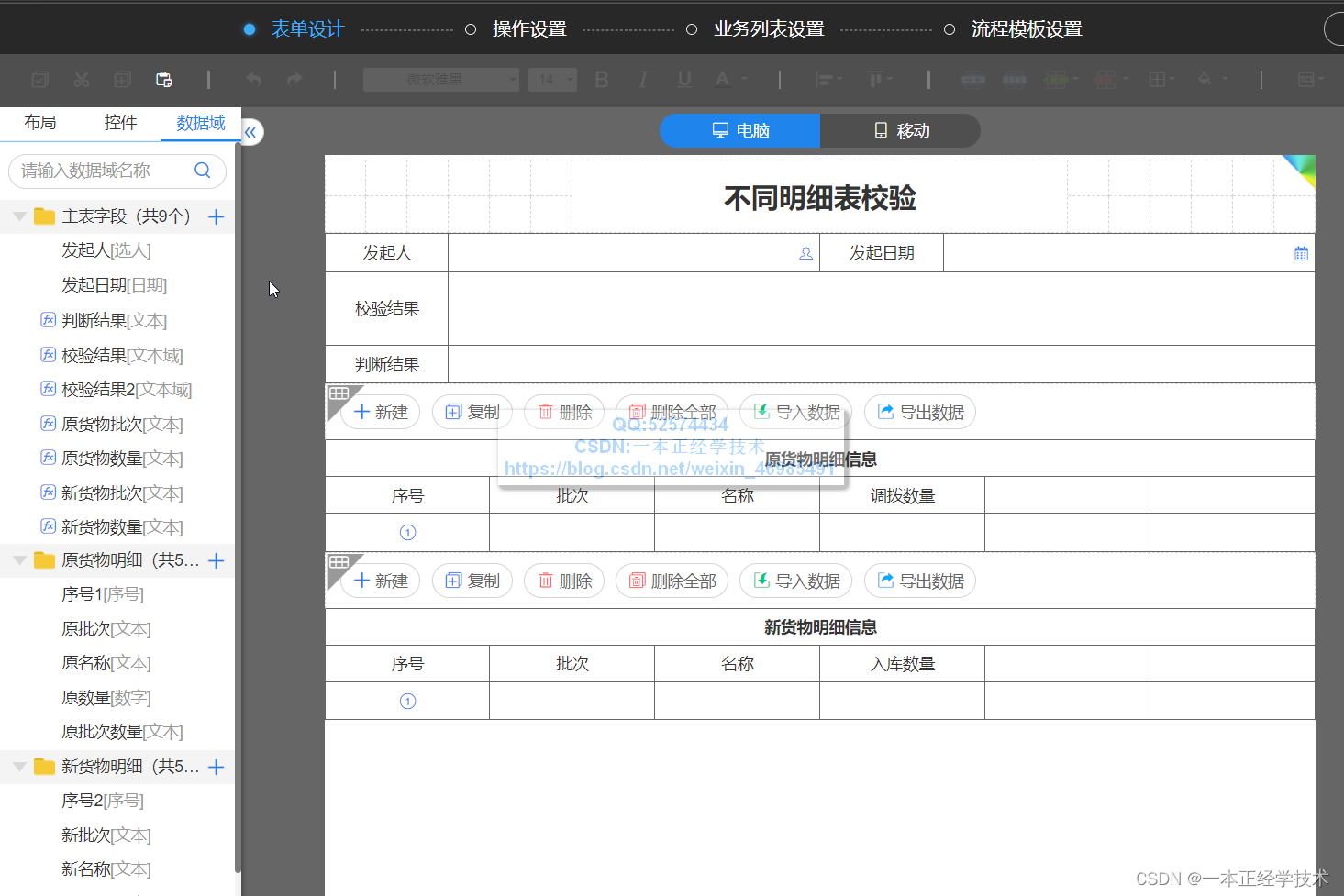
相关过程字段可以不用显示在表单中,例如数据域中的原货物批次、原货物数量、现货物批次、现货物数量等。
图中的校验结果2是基于本需求的扩展需求设计,后续有介绍。
表单运行态的效果如下:
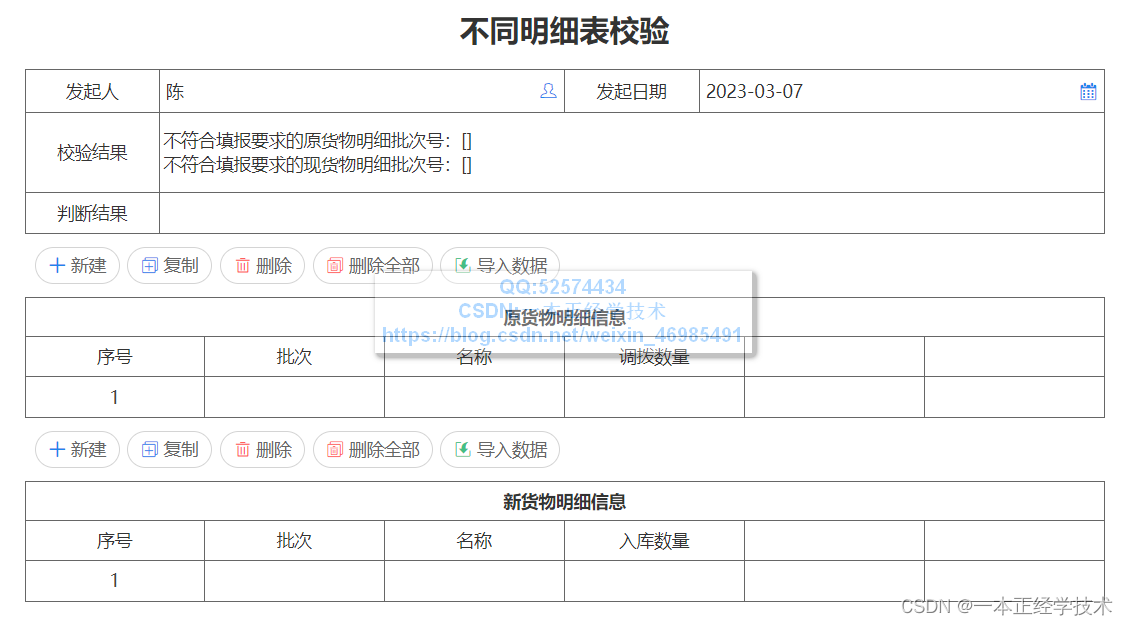
完成以上表单设计后,接后续分别进行函数定义。
2、定义自定义函数
2.1、原货物批次、原货物数量、现货物批次、现货物数量
原货物批次字段的计算公式如下图:
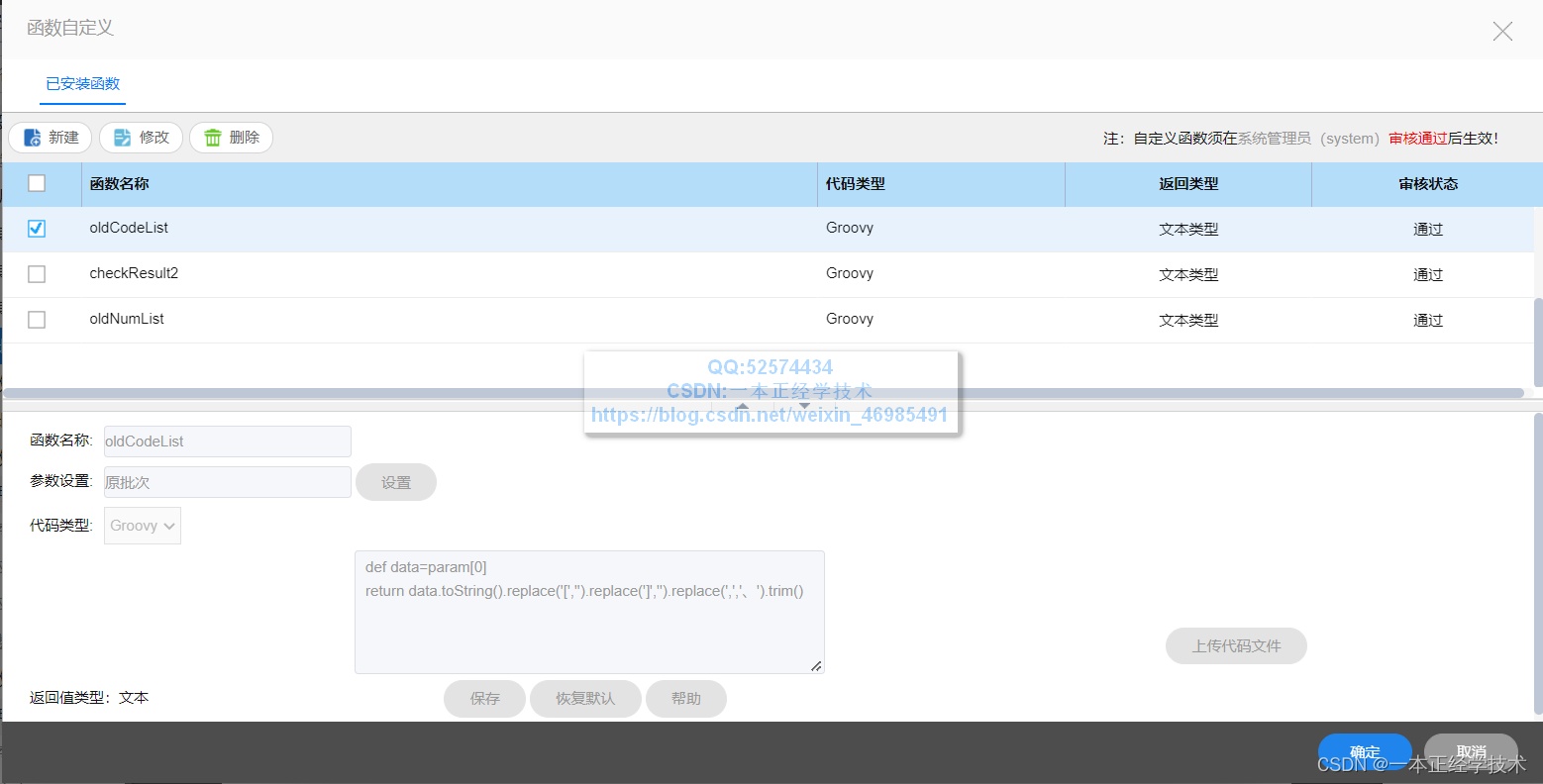
以原货物明细表的原批次字段为参数,代码内容如下:
def data=param[0]
return data.toString().replace('[','').replace(']','').replace(',','、').trim()
原货物数量、现货物批次、现货物数量字段的计算公式与此完全相同,参数改为对应需要计算的字段参数即可。
分别如下:
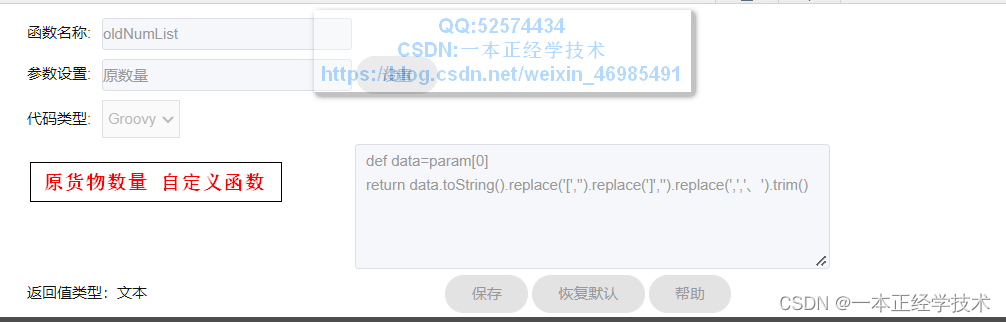
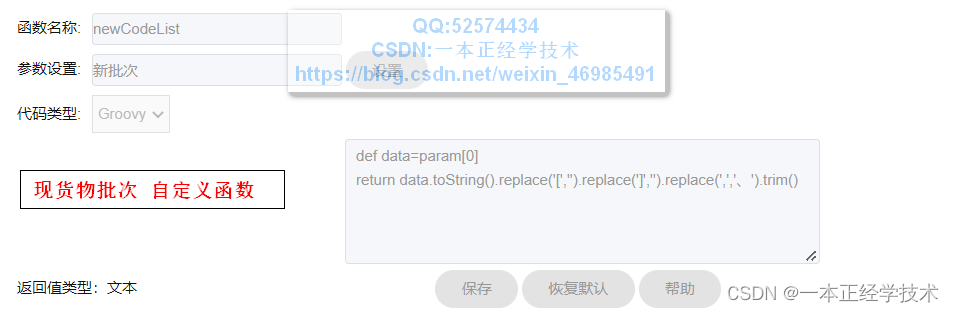
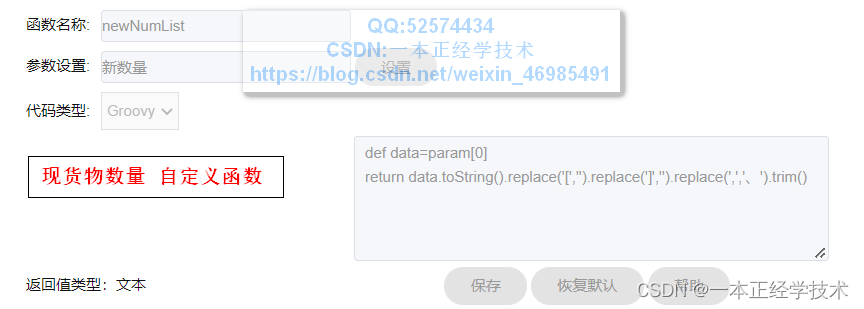
2.2、校验结果
校验结果字段的计算公式如下图:
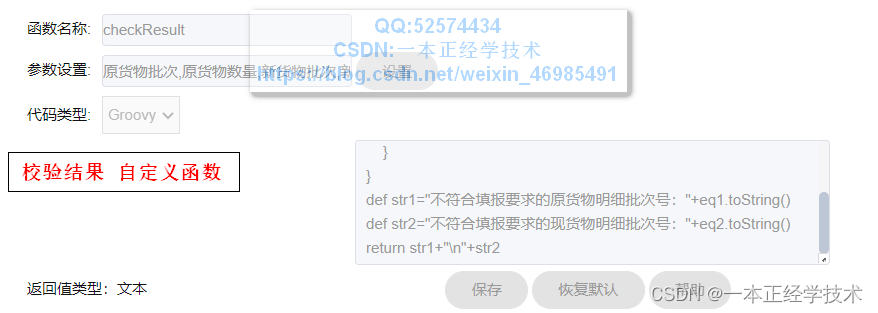
此自定义函数的参数为:原货物批次、原货物数量、现货物批次、现货物数量。即上面新增加的自定义函数字段,顺序要求按照此顺序放置。
代码内容如下:
(于2023年3月8日更新,解决批次中的空格字符串BUG)
def oldCode= param[0].replace(' ','')
def oldNum= param[1].replace(' ','')
def newCode= param[2].replace(' ','')
def newNum= param[3].replace(' ','')
def p1=oldCode.split("、")
def n1=oldNum.split("、")
def p2=newCode.split("、")
def n2=newNum.split("、")
def eq1=[]
def eq2=[]
int i = 0;
for (int j=0;j<p2.size();j++){
i++;
def indexJ = p1.findIndexOf { it.trim()==p2[j].trim()}
if (indexJ != -1 && !(n2[i-1].equals(n1[indexJ])) ){
eq1.add(p1[indexJ])
eq2.add(p2[i-1])
}
}
def str1="不符合填报要求的原货物明细批次号:"+eq1.toString()
def str2="不符合填报要求的现货物明细批次号:"+eq2.toString()
return str1+"\n"+str2
2.3、判断结果
判断结果字段的计算公式如下图:
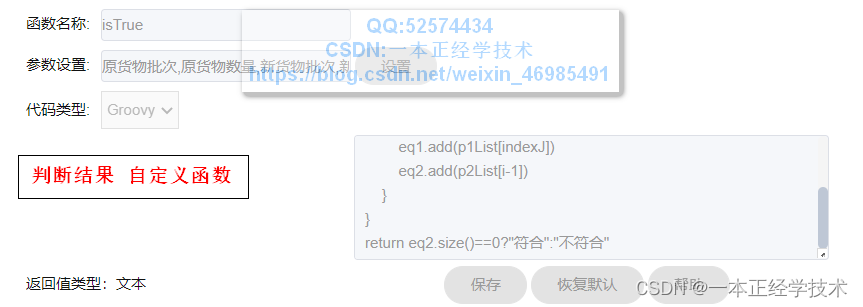
此自定义函数与校验结果的函数设置类似,只有最后的返回结果代码不同。
参数为:原货物批次、原货物数量、现货物批次、现货物数量。即上面新增加的自定义函数字段,顺序要求按照此顺序放置。
代码内容如下:
(于2023年3月8日更新,解决批次中的空格字符串BUG)
def oldCode= param[0].replace(' ','')
def oldNum= param[1].replace(' ','')
def newCode= param[2].replace(' ','')
def newNum= param[3].replace(' ','')
def p1=oldCode.split("、")
def n1=oldNum.split("、")
def p2=newCode.split("、")
def n2=newNum.split("、")
def eq1=[]
def eq2=[]
int i = 0;
for (int j=0;j<p2List.size();j++){
i++;
def indexJ = p1List.findIndexOf { it.trim()==p2List[j].trim()}
if (indexJ != -1 && !(n2List[i-1].equals(n1List[indexJ])) ){
eq1.add(p1List[indexJ])
eq2.add(p2List[i-1])
}
}
return eq2.size()==0?"符合":"不符合"
以上完成后,即可进行表单校验条件设置。
3、设置表单校验条件
通过致远表单的标准功能,进行校验条件的设置,如下图:
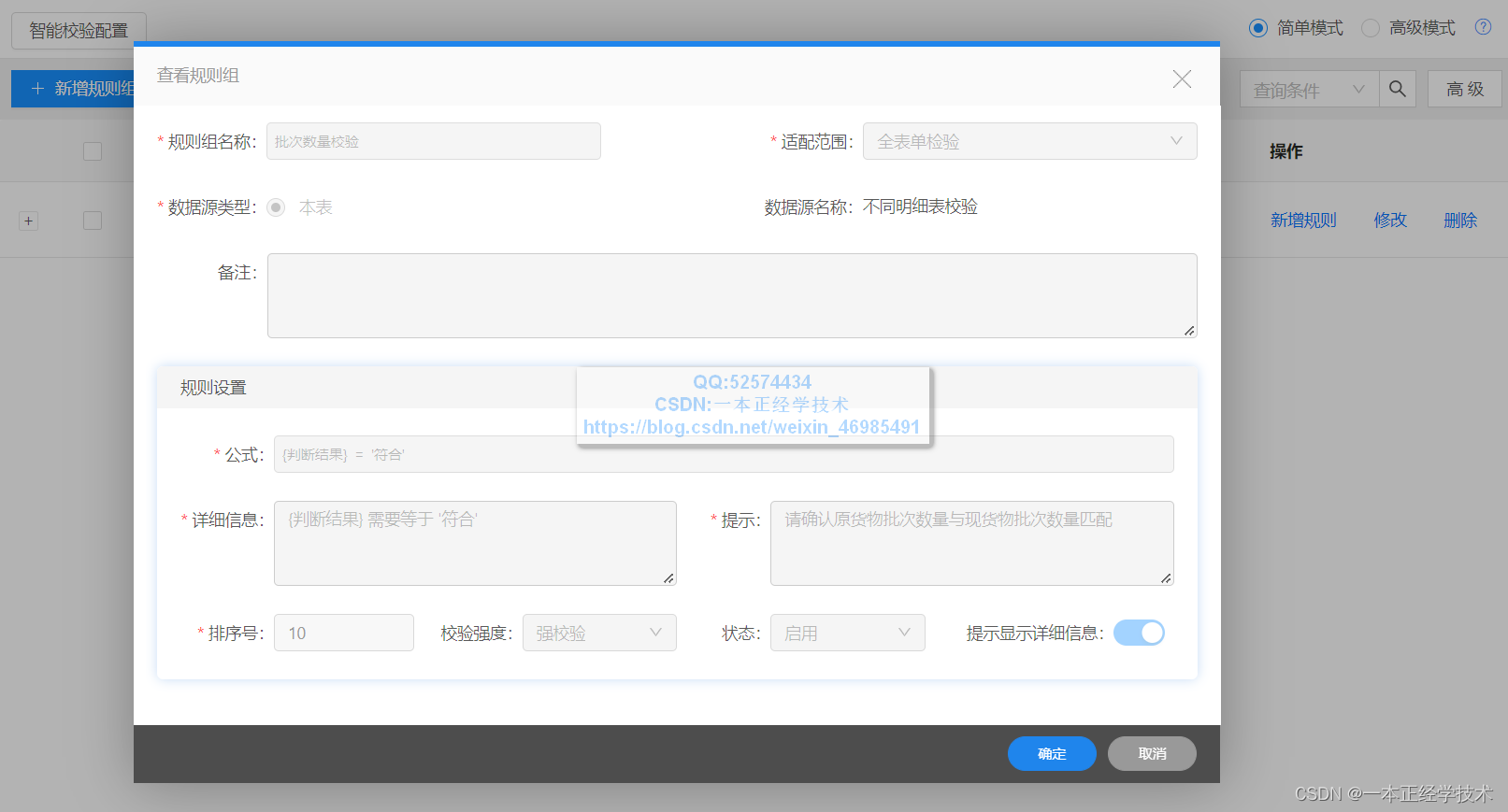
致远新版本(V8.1)的表单校验功能更强大,大家可以升级体验!!!
增加规则组名称,设置规则公式:** {判断结果} = ‘符合’ **,并设置校验提示信息,方便使用人员清楚表单无法提交的问题所在。校验强度设置成强校验,表示不符合规则,无法提交,如果设置成弱校验,在提交时会提示不符合规则,但仍可继续提交。
以上便完成同一表单不同明细表的相关数据校验需求。
4、需求扩展
在以上需求基础之上,可能会有另外一种场景:同一表单,不同明细表,在填写或导入的数据,比如批次会有重复,基于仓库不同等原因,如下图:
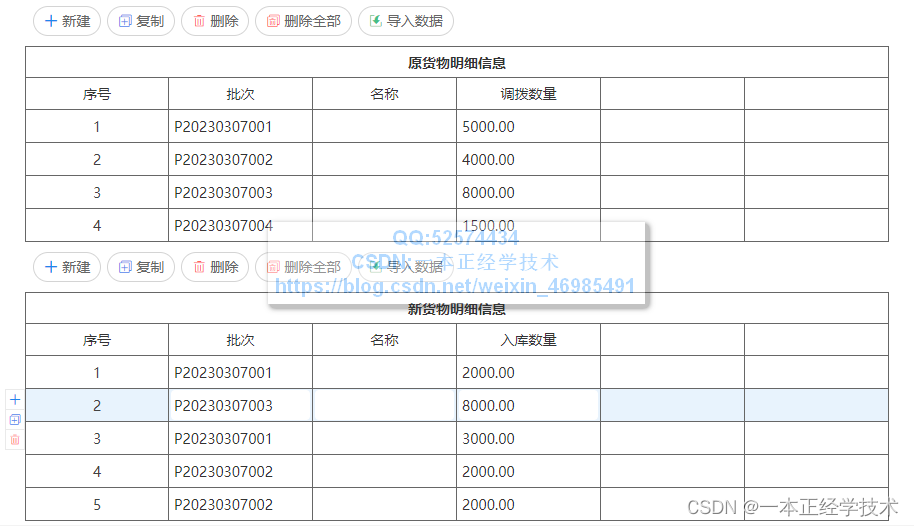
此时,需要对明细表中的相同批次的数量进行汇总,然后再匹配校验。
则需要改造校验结果函数,直接上代码:
(于2023年3月8日更新,解决批次中的空格字符串BUG)
def oldCode= param[0].replace(' ','')
def oldNum= param[1].replace(' ','')
def newCode= param[2].replace(' ','')
def newNum= param[3].replace(' ','')
def p1=oldCode.split("、")
def n1=oldNum.split("、")
def p2=newCode.split("、")
def n2=newNum.split("、")
def pnList1=[]
def pnList2=[]
for (i in 0..<p1.size()) {
def map1=[code: p1[i],num: n1[i].toBigDecimal() ]
pnList1.add(map1)
}
for (i in 0..<p2.size()) {
def map2=[code: p2[i], num: n2[i].toBigDecimal() ]
pnList2.add(map2)
}
def pn1_totalByCode=pnList1.groupBy {it.code}.collectEntries {k,v -> [k, v.num.sum()]}
def pn2_totalByCode=pnList2.groupBy {it.code}.collectEntries {k,v -> [k, v.num.sum()]}
def p1List=pn1_totalByCode.keySet()
def n1List=pn1_totalByCode.values()
def p2List=pn2_totalByCode.keySet()
def n2List=pn2_totalByCode.values()
def eq1=[]
def eq2=[]
int i = 0;
for (int j=0;j<p2List.size();j++){
i++;
def indexJ = p1List.findIndexOf { it.trim()==p2List[j].trim()}
if (indexJ != -1 && !(n2List[i-1].equals(n1List[indexJ])) ){
eq1.add(p1List[indexJ])
eq2.add(p2List[i-1])
}
}
def str1="不符合填报要求的原货物明细批次号:"+eq1.toString()
def str2="不符合填报要求的现货物明细批次号:"+eq2.toString()
return str1+"\n"+str2
此函数与上面的代码增加的核心内容为这段代码:
for (i in 0..<p1.size()) {
def map1=[code: p1[i],num: n1[i].toBigDecimal() ]
pnList1.add(map1)
}
for (i in 0..<p2.size()) {
def map2=[code: p2[i], num: n2[i].toBigDecimal() ]
pnList2.add(map2)
}
def pn1_totalByCode=pnList1.groupBy {it.code}.collectEntries {k,v -> [k, v.num.sum()]}
def pn2_totalByCode=pnList2.groupBy {it.code}.collectEntries {k,v -> [k, v.num.sum()]}
def p1List=pn1_totalByCode.keySet()
def n1List=pn1_totalByCode.values()
def p2List=pn2_totalByCode.keySet()
def n2List=pn2_totalByCode.values()
主要是为了实现相同批次的数量汇总,然后再转为原来的形式进行匹配校验。
同样,判断结果字段的代码也调整为如下:
(于2023年3月8日更新,解决批次中的空格字符串BUG)
def oldCode= param[0].replace(' ','')
def oldNum= param[1].replace(' ','')
def newCode= param[2].replace(' ','')
def newNum= param[3].replace(' ','')
def p1=oldCode.split("、")
def n1=oldNum.split("、")
def p2=newCode.split("、")
def n2=newNum.split("、")
def pnList1=[]
def pnList2=[]
for (i in 0..<p1.size()) {
def map1=[code: p1[i],num: n1[i].toBigDecimal() ]
pnList1.add(map1)
}
for (i in 0..<p2.size()) {
def map2=[code: p2[i], num: n2[i].toBigDecimal() ]
pnList2.add(map2)
}
def pn1_totalByCode=pnList1.groupBy {it.code}.collectEntries {k,v -> [k, v.num.sum()]}
def pn2_totalByCode=pnList2.groupBy {it.code}.collectEntries {k,v -> [k, v.num.sum()]}
def p1List=pn1_totalByCode.keySet()
def n1List=pn1_totalByCode.values()
def p2List=pn2_totalByCode.keySet()
def n2List=pn2_totalByCode.values()
def eq1=[]
def eq2=[]
int i = 0;
for (int j=0;j<p2List.size();j++){
i++;
def indexJ = p1List.findIndexOf { it.trim()==p2List[j].trim()}
if (indexJ != -1 && !(n2List[i-1].equals(n1List[indexJ])) ){
eq1.add(p1List[indexJ])
eq2.add(p2List[i-1])
}
}
return eq2.size()==0?"符合":"不符合"
最终提交时的效果如下图:
(校验结果2字段中的信息显示为汇总后不匹配的批次,汇总后匹配的批次不再显示,与校验结果字段的显示结果不同)
注意:自定义函数创建后,需要通过系统管理员后台审核确认!!!
如果各位有兴趣或需求,可沟通交流。
【记录于2023年3月7日】
















 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









