






机器学习运用到VRP的若干小知识
车辆路径规划问题(Vehicle Routing Problem,VRP)是运筹学领域十分经典的组合优化问题。近几十年来已经有众多学者通过启发式以及一些精确算法对该问题进行了全面且深入的研究。
相关文献
通过机器学习解决旅行商问题(TSP)和车辆路径规划问题(VRP)一般有两种方式:
1、端到端方法( Pointer Network +Attention Model)
- Vinyals 等人(2015)首先引入了Pointer Network,以Seq2Seq模型为灵感,以解决TSP。他们使用注意力模型以监督方式学习不同节点的顺序。
- Bello 等人(2016年)开发了一种RL算法来训练Pointer Network。他们的框架从问题实例中学习最佳策略,不需要监督解决方案。
- Nazari 等人(2018)用新设计改进了Pointer Network,使输入序列的模型不变性得以扩展,并对其进行扩展以解决VRP。
- Kool等人(2019)提出了一个基于注意力层的模型,以及一种RL算法来训练具有简单但有效基线的模型。
2、强化学习方法(Policy Gradient、Actor Critic)
除了上述端到端的方法,强化学习也在近年被运用到VRP问题中。这种方法一般基于元启发式算法的基础之上,通过RL可以准确有效的进行算子的选择。
- Chen&Tian(2019)提出了针对VRP的NeuRewriter Model。他们定义了重写规则集,并训练了两个策略网络(区域选择策略和规则选择策略)以获得下一个状态。给定一个初始解决方案,他们的目标是找到以最小的成本实现解决方案的一系列步骤。
- Hao Lu等人提出了一个“Learn to Improve”(L2I)方法,更加高效,并且与OR方法进行了比较更优。其核心思想就是在元启发式迭代搜索的过程中,加入了RL来帮助更有效的选择算子。
背景小知识
那么有哪些机器学习中的小知识被广泛的运用到VRP问题的解决中来呢,本文将简单的介绍3个最基础的背景小知识:注意力机制、指针网络和策略网络。
1、注意力机制(Attention Mechanism)
首先,我们要理解VRP的输入和输出,其实就是输入一些离散的点,然后把它们连接为一条条路,这样就完成了车辆路径的规划。所以我们可以将其作为一个Seq2Seq的过程,客户点的序列进行处理后作为输入,而生成的最终路径就是输出。Seq2Seq是通过encoder和decoder的过程进行翻译,这一过程在机器翻译的场景中十分常见,这里就产生了一个问题。
在机器翻译中一直存在对齐的问题。也就是说源语言的某个单词应该和目标语言的哪个单词对应的问题,比如说“Who are you”对应“你是谁”,由于英文和中文常用的语序不同,如果我们简单地按照顺序将词汇进行翻译,显然会得到一个错误的翻译结果“谁是你”。下图展示了Seq2Seq的过程(图片来源于网络)。
那么如何让词之间实现对齐,让模型准确的知道“你”是和“you”对应的呢?这时候,我们就得用到注意力机制。注意力机制(Attention Mechanism)会给输入序列的每一个元素分配一个权重,这样在预测“你”这个字的时候输入序列中的“you”这个词的权重最大,从而实现了软对齐。
传统的注意力公式如下。第一条公式中
e
j
e_j
ej和
d
i
d_i
di分别是encoder和decoder的隐状态,其余是可学习的参数;得到的
u
j
i
u^i_j
uji通过softmax操作得到分配给输入序列的权重
a
j
i
a^i_j
aji。之后再根据该权重求加权和,得到
d
i
′
d'_i
di′后加到decoder的隐状态上,即可进行解码和预测。
u
j
i
=
v
T
tanh
(
W
1
e
j
+
W
2
d
i
)
j
∈
(
1
,
.
.
.
,
n
)
a
j
i
=
softmax
(
u
j
i
)
j
∈
(
1
,
.
.
.
,
n
)
d
i
′
=
∑
j
=
1
n
a
j
i
e
j
u^i_j = v^T\tanh(W_1e_j+W_2d_i) \quad j\in (1,...,n) \\ a^i_j = \text{softmax}(u^i_j) \quad j\in (1,...,n) \\ d'_i = \sum_{j=1}^na^i_je_j
uji=vTtanh(W1ej+W2di)j∈(1,...,n)aji=softmax(uji)j∈(1,...,n)di′=j=1∑najiej
2、指针网络(Pointer Network)
解决了软对齐的问题,接下来还要处理另一个问题:传统注意力机制的输出是输出词汇表中的词汇,接着上面的例子来说,输出是英文词汇对应的中文词汇表“你”、“是”、“谁”。但是在VRP中,我们希望输出的路径序列中的组成元素恰恰就是输入中的客户点。
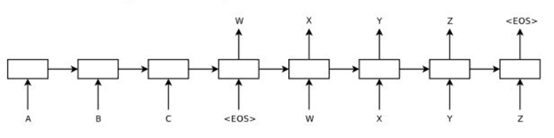
对于这种输出往往是输入的子集的问题。考虑能不能找到一种指针,每个指针对应输入序列的一个元素,我们可以直接通过指针来讲输入序列进行变换和输出,而不是输出词汇表。这就是指针网络(Pointer Networks)。下图展示了传统Seq2Seq和指针网络输入输出的区别(图片来源于网络)。

下面是指针网络的公式,相比传统注意力机制更加简单,公式一与传统注意力机制相同,公式二直接将softmax得到的权重值作为了输出,充当指针。
u j i = v T tanh ( W 1 e j + W 2 d i ) j ∈ ( 1 , . . . , n ) p ( C i ∣ C 1 , . . . , C i − 1 , P ) = softmax ( u i ) u^i_j = v^T\tanh(W_1e_j+W_2d_i) \quad j\in (1,...,n) \\ p(C_i|C_1,...,C_{i-1},\mathcal{P})= \text{softmax}(u^i) \\ uji=vTtanh(W1ej+W2di)j∈(1,...,n)p(Ci∣C1,...,Ci−1,P)=softmax(ui)
3、策略网络(Policy Network)
接下来要将的策略网络就是强化学习比较核心的内容了。其实对于VRP,也有很多学者用DQN等方法进行解决,大家可以更多的查阅文献进行了解。此处,我仅着重介绍策略网络。

策略网络其实十分简单粗暴,仅仅是循环这3个步骤 :1、作出行为 2、得到结果3、根据结果来增加/减少下次该行为被选择的概率。
举个小例子:小老鼠在一个房间中爬行,它可以进行上下左右移动的行为。如果他遇到猫或者捕鼠夹,他会受伤或死亡,这时环境返回的reward将会很小甚至是负的。但如果他遇到奶酪,就会得到一个较大的正reward。策略网络将根据这些reward来增大或减少行为发生的概率,从而使小老鼠学会正确的找奶酪路径。(图片来源于网络)

下图给出了经典的蒙特卡洛梯度策略强化算法Monte-Carlo Policy Gradient(图片来源于网络),其中:
π
\pi
π:自变量为θ的策略函数,s状态下a动作发生的概率
v
t
v_t
vt:奖励函数,根据动作好坏决定改进方向取对数:以得到更好的收敛性
∇
\nabla
∇:梯度,即参数改进的方向
α
α
α:学习率















 1537
1537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









