







Dax函数总结
行上下文,可以理解为原始数据中,一行接着一行的排序,这个就叫行上下文,也就是藏在内部的筛选关系,这里称之为隐性筛选。
切片器这种,摆在外面的控制器,来影响计算结果,筛选的条件,成为显性筛选。
一.新函数
rank——返回当前上下文在指定分区内按指定顺序排序的级别,如果找不到匹配项,则级别为空。
ADDCOLUMNS(<添加新列的表>,<新列的名字>,<表达式>) -返回包含原始列和新增列的一个新表。
二.聚合函数
①计数
APPROXIMATEDISTINCTCOUNT 在列中返回唯一值的估计计数。
COUNT 计算指定列中包含非空值的行数。【不支持布尔值】
COUNTA 计算指定列中包含非空值的行数。【支持布尔值】
COUNTAX 在对表计算表达式的结果时统计非空白结果数。
COUNTBLANK 对列中的空白单元格数目进行计数。【如果没有空白的行就返回0,如果没有要检查的行则返回空白】
COUNTROWS 统计指定表中或由表达式定义的表中的行数。
COUNTX 在针对表计算表达式的结果时,对包含数字或计算结果为数字的表达式的行数目进行计数。
DISTINCTCOUNT 对列中的非重复值数目进行计数。
②平均值
AVERAGE 返回列中所有数字的平均值(算术平均值)。
AVERAGEA 返回列中值的平均值(算术平均值)。
AVERAGEX 计算针对表进行计算的一组表达式的平均值(算术平均值)。
③最值
MAX 返回列中或两个标量表达式之间的最大数字值。【不支持布尔值】
MAXA 返回列中的最大值。【支持布尔值】
MAXX 针对表的每一行计算表达式,并返回最大数字值。
MIN 返回列中或两个标量表达式之间的最小数字值。
MINA 返回列中的最小值,包括任何逻辑值和以文本表示的数字。
MINX 返回针对表中的每一行计算表达式而得出的最小数值。
④求和
SUM 对某个列中的所有数值求和。
SUMX 返回为表中的每一行计算的表达式的和。
三.时间函数
时间|表|CALENDAR 返回一个表,其中有一个包含一组连续日期的名为“Date”的列。
时间|表|CALENDARAUTO函数 参数是几,那么就代表几个月不要了;必须要有一个数据的模型。
时间|值|DATE DATE(<年>,<月>,<日>)。
时间|值|DATEDIFF DATEDIFF(<开始日期>,<结束日期>,<间隔单位>)
DATEVALUE 将文本格式的日期转换为日期/时间格式的日期。
DAY 返回一月中的日期,1 到 31 之间的数字。
时间|值|EDATE 返回在开始日期之前或之后指定月份数的日期。
时间|值|EOMONTH 以日期/时间格式返回指定月份数之前或之后的月份的最后一天的日期。
时间|值|HOUR 以数字形式返回小时值,0 (12:00 A.M.) 到 23 (11:00 P.M.) 之间的数字。
时间|值|MINUTE 给定日期和时间值,以数字形式返回分钟值,0 到 59 之间的数字。
时间|值|MONTH 以数字形式返回月份值,1(一月)到 12(十二月)之间的数字。
时间|值|TIME 将以数值形式给定的小时、分钟和秒值转换为日期/时间格式的时间。
时间|值|TODAY 返回当前日期。
时间|值|YEAR 返回日期的年份,1900 到 9999 之间的四位整数。
1.时间|表|CALENDAR函数
语法:
CALENDAR(<开始日期>,<结束日期>)
返回结果:
一个具有日期列的表,从开始日期到结束日期,并且是连续不间断的。
应用:
表1 = calendar(DATE( 2023,8,1),DATE(2023,8,15))
结果:截图BI1-6
注意:calendar后面的日期一定不能是开始时间迟于结束日期的
2.时间|表|CALENDARAUTO函数
语法:
CALENDARAUTO([参数])
参数:默认不填的情况下,参数为12,一般情况是1-12的整数
注意:①参数是几,那么就代表几个月不要了,最多可以不要12个月。比如说,输入的参数是2,那么开始日期是3月1日,不要2月份之前以及2月份的数据。
②在使用这个函数的时候,必须要有一个数据的模型。
3.时间|值|DATE
语法:
DATE(<年>,<月>,<日>)
4.时间|值|Datediff
语法:
DATEDIFF(<开始日期>,<结束日期>,<间隔单位>)
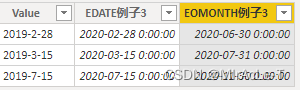
5.时间|值|EDATE&EMONTH
语法:
EDATE(<开始日期>,<间隔数>)
EMONTH(<开始日期>,<间隔月数>)
参数:
第—参数:开始日期,可以是一个值,可以是表达式,也可以是一列。
第二参数:间隔数,最好输入整数。小数遵循四舍五入的原则。负数向前平移。
区别:
EDATE返回的是当月的对应日期
EMONTH返回的是当月的最大值
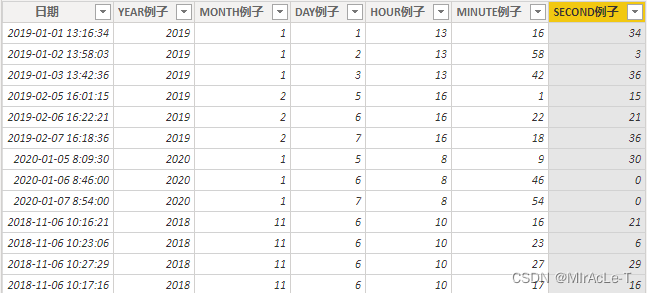
6.时间|值|HOUR & MINUTE & MONTH & TIME & TODAY & YEAR
注意:
1、这类函数通常遵循进位退位原则,超过上限就会在比较大或者比较小的时间单位上进位或者减位。
2、注意—些函数的时间范围,比如1990~9999年份之间。
3、通常这类函数都是用于生成日期表使用的。
四.筛选器函数
筛选|表|ALL 返回表中的所有行或列中的所有值,清除外部筛选器。【一般和calculate一起用】
筛选│无|ALLCROSSFILTERED 主要作calculate函数的调节器,其本身是不返回任何表和数值,为calculate而存在的一个函数。
筛选│无|ALLCROSSFILTERED 相当于就是一个门神,可以阻挡任何的筛选器来影响度量值,主要作calculate函数的调节器。
筛选|表|ALLNOBLANKROW 用途:①用来对比父表和子表之间的差异;②适用于连锁类销售对比差异值。和ALL用法差别不大,但是会被子父表影响。
筛选|表|ALLSELECTED 删除当前查询的列和行中的上下文筛选器,同时保留所有其他上下文筛选器或显式筛选器。
筛选|值|CALCULATE 在已修改的筛选器上下文中计算表达式。1、可以利用CALCULATE进行条件限定。2、CALCULATE可以自动的进行上下文转换。
筛选|表|CALCULATETABLE 在已修改的筛选器上下文中计算表表达式。
筛选|表|FILTER 返回一个表,用于表示另一个表或表达式的子集。不筛选上下文。
INDEX 在指定分区(按指定顺序排序)或指定轴上的绝对位置(由位置参数指定)处返回一行。
筛选|值|KEEPFILTERS 计算 CALCULATE 或 CALCULATETABLE 函数时,修改应用筛选器的方式。
信息|值|LOOKUPVALUE LOOKUPVALUE(<结果列>,<查找列>,<查找值>)——返回满足搜索条件所指定的所有条件的行的值。 函数可以应用一个或多个搜索条件。
MATCHBY 在窗口函数中,定义用于确定如何匹配数据和标识当前行的列。
OFFSET 返回一个行,该行位于同一表中的当前行之前或之后(按给定的偏移量)。
ORDERBY 定义用于确定每个 WINDOW 函数分区内排序顺序的列。
PARTITIONBY 定义用于对 WINDOW 函数的 <relation> 参数进行分区的列。
RANK 返回给定间隔内行的级别。
REMOVEFILTERS 清除指定表或列中的筛选器。
ROWNUMBER 返回给定间隔内行的唯一级别。
筛选|值|SELECTEDVALUE:语法是selectdvalue(<列>,<备用值>);列:固定的现有列,不能是表达式;备用值:可选项,如果第一参数上下文判定为空,或者出现多个重复值时,返回备用值;默认不填返回结果为空。
WINDOW 返回位于给定间隔内的多个行。
1.筛选|表|ALL
用途:用于清除外部筛选器
语法:
ALL([表]或[表的一列或者多列])
如果在不搭配其他函数的情况下,直接使用ALL其实就雷同于复制表。
当和calculate一起使用的时候,需要变化all函数内部的维度,达到类似笛卡尔积的效果,从而得出汇总值。
2.筛选│无|ALLCROSSFILTERED
主要作calculate函数的调节器,其本身是不返回任何表和数值,为calculate而存在的一个函数。
相当于就是一个门神,可以阻挡任何的筛选器来影响度量值。
语法:
ALLCROSSFILTERED(<表>) —— 只有一个参数,要清楚筛选的表,无返回结果。
这里需要@Fabric|白茶,对ALLCROSSFILTERED的一个思考,我认为是结合该博主的介绍更好的帮助我们理解这个函数:

3.筛选|表|ALLEXCEPT
用途:特别适用于组内占比的计算。
语法:
ALLEXCEPT(<需要清除筛选的表>,<需要保留筛选的列>[,...])
参数:
表:要清除筛选器的表;
列:(可重复)位于第一参数表中,需要保留筛选的列。除了这一列之外,其他列全部不受筛选影响。注意:不能使用表的表达式和列的表达。
ALL与ALLEXCEPT的区别:ALL用于清除所有筛选器并返回所有成员,而ALLEXCEPT用于清除除特定列或行之外的所有筛选器。
4.筛选|表|ALLNOBLANKROW
用途:①用来对比父表和子表之间的差异;②适用于连锁类销售对比差异值。
语法:
ALLNOBLANKROW(<表>|<列>[,..]) —— 返回去除重复值的表或者列
参数:
表:已经删除上下文筛选的表
列:(可重复)已经删除上下文筛选的列。
注意:此函数参数类型智能存在一种。
区别:
ALLNOBLANKROW("表") 和 ALL("表") 结果相同,都是复制表;
countrows(ALLNOBLANKROW("子表[列1]")) 和 countrows(ALL("子表[列1]"))结果相同;
countrows(ALLNOBLANKROW("父表")) 和 countrows(ALL("父表")),当子表和父表存在不同维度时,ALL会直接在父表中添加一行”空行“,这一行ALL函数计算在内,ALLNOBLANKROW则会忽略这一空行,只计算父表中存在的数据;
ALLNOBLANKROW("表[列1]") 和 values("表[列1]") 用法相同,去除重复值。
5.筛选|表|ALLSELECTED(**)
用途:用来计算或者显示明面上筛选影响,而忽略其行上下文的影响。
①用来计算相对排名;
②用来计算相对占比;
③用来保证没有模型关系的维度筛选生效。
语法:
ALLSELECTED(<表>|<列>) —— 返回不带任何列或行上下文的上下文。
参数:
表:(可选项)不能是表达式,现有表的名称。
列:(可选项可重复)不能是表达式,现有列的名称。
注意:要么是表,要么是列;如果是多列,必须在同表中。
6.筛选|值|CALCULATE
用来修改上下文使用。
语法:
calculate(<表达式>,<筛选器>,<筛选器>...) —— 根据修改的上下文重新计算的值
参数:
表达式:要进行求值的表达式。
筛选器:(可选可重复)用来修改上下文的限定条件。
注意:1、可以利用CALCULATE进行条件限定。2、CALCULATE可以自动的进行上下文转换。
7.筛选|表|CALCULATETABLE
CALCULATE和CALCULATETABLE的区别就是,前者返回的是一个值,后者返回的是一个表,但两者的功能都是一样的,就是用来修改上下文使用。
语法:
CALCULATETABLE(<表达式>,<筛选器1>,<筛选器2>,...) —— 根据筛选器生成的上下文表达式进行计算,返回一张表
参数:
表达式:必须项,可以是—个表,也可以是表的表达式。
筛选器:可选项可重复,用来过滤条件使用。
CALCULATETABLE和filter的区别:
CALCULATETABLE函数在执行的时候,和CALCULATE函数相同,是先改变上下文环境,在新的上下文中计算表达式。
而FILTER函数是先迭代第一参数,再查找满足条件的项目,也就是不生成新的上下文。
8.筛选|无|CROSSFILTER
改变计算过程的筛选方向
语法:
CROSSFILTER(<列1>,<列2>,<方向>)
参数:
列1;现有固定列的名称,不可以是表达式,代表多端
列2:现有固定列的名称,不可以是表达式,代表一端
方向:ONEWAY:表示单向筛选;BOTH表示双向筛选;NONE表示无交叉筛选
9.筛选|表&值|DISTINST
用法:去重
语法:
DISTINST(表or列) —— 当表为单列单行时,可以作为值使用。
注意:列模式下,返回结果收到筛选上下文影响;要与VALUES函数进行区分。
distinst和values的区别:
1、参数:DISTINCT可以使用表达式作为参数,而VALUES函数不可以。
2、计数:DISTINCT去掉重复值计数时,不会考虑重复项目;而VALUES会计算重复项目行数。
3、返回:DISTINCT返回的结果去掉重复项,且去掉空值;而VALUES则只去掉重复项,不去空值。

10.筛选|表|FILTER
用来筛选表或者作为计算的筛选条件。
语法:
FILTER(<表>,<条件>) —— 由符合筛选条件的行组成的表。
参数:
表:可以是固定的表,也可以是表的表达式。
条件:过滤条件。
注意:
1、从性能上看,双层FILTER的性能优于只用一个filter的;
2、从执行顺序上看,多层FILTER时,通常是从内往外计算。
11.筛选|值|FILTERS
用途:实际中可用来统计销售品类数量以及查看直接影响值。
语法:
FILTERS(<列>) —— 直接筛选列的值
参数:必须是现有列,不能是表达式。
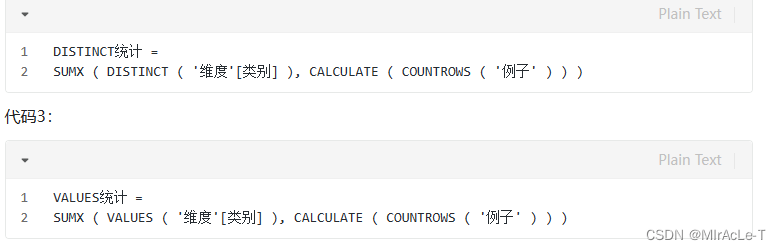
计算出[类别]这—项的直接筛选数量。当然,其效果等同于以下三组代码:
VALUES例子=COUNTROwS ( VALUES('例子'[类别]))
ALL例子=COUNTROwS ( ALL('例子'[类别]) )
DISTINCT例子=COUNTROwS ( DISTINCT('例子'[类别]) )
12.筛选|值|ISCROSSFILTERED和ISFILTERED
lS——是的意思;
CRoSS——交叉的意思;
FILTERED——筛选的意思;
ISCROSSFILTERED函数代表判断是否受到交叉筛选影响;
ISFILTERED函数代表判断是否受到直接筛选影响。
语法:
ISCROSSFILTERED(<列>) 、ISFILTERED(<列>) —— 返回结果为TRUE\FALSE
13.筛选|值|KEEPFILTERS
用途:将CALCULATE函数本身的覆盖上下文修改为追加上下文。
语法:
KEEPFILTERS(<表达式>)
区别:
CALCULATE是找到“白茶”这个人,在你们团队,那么你们团队就一起处罚;
而KEEPFILTERS是追加筛选是什么意思?就是我找到“白茶”这个人了,和其他人无关,只对“白茶”进行处罚。
14.Ⅰ筛选|无|REMOVEFILTERS
REMOVE—移除的意思;
FILTERS—筛选的意思;
REMOVEFILTERS函数的用途.移除筛选器。
语法:
REMOVEFILTERS(<表>|<列>) —— 本身不返回值或者表,但是会影响calculate的运算结果。
注意:
REMOVEFILTERS函数仅作为CALCULATE函数调节器使用,其用途此时与ALL函数一致;
15.筛选|值|SELECTEDVALUE
用途:当指定列当前上下文中只有—个非重复值时,返回该值;否则返回替代结果,省略则返回空值;通俗点来说,就是根据当前上下文匹配相关值。
语法:
selectdvalue(<列>[,<备用值>])
参数:
列:固定现有列,不能是表达式;
备用值:可选项,如果第—参数上下文判定为空,或者出现多个重复值时,返回备用值;默认不填返回结果为空。
16.筛选|表|values
用途:适用于度量值计算。
语法:
values(表or列)
参数:可以是表可以是列,但是不可以是表达式。
values、distinct、all函数区别;
1.values和all参数只有表的时候,相当于复制操作,distinct是对表进行去重操作;
distinct参数可以是表达式,而values和all的参数不能是表达式。
2.在例子和维度上下文中,DISTINCT函数排除掉因扩展表原因导致的空值项目,将其排除在计算范围之内;进行的是去除重复,排除空值计算。
无论在例子上下文还是维度上下文中,VALUES函数的计算都包含空值项目。
ALL函数在例子上下文中的计算,没有屏蔽掉例子的筛选效果,其计算结果包含空值项目;而在维度上下文中,清除了维度表的筛选效果,计算结果包含空值项目,每个返回值均为总计行数37。
五.逻辑函数
值|AND AND(<条件1>,<条件2>)检查两个参数是否均为 TRUE,如果两个参数都是 TRUE,则返回 TRUE;否则返回FALSE。
值|COALESCE COALESCE(<表达式>,<表达式>) 返回第一个计算结果不为 BLANK 的表达式。
列子:COALESCE(<表达式>,0),返回第一个不为空的表达式,如果为空则返回0。
值|FALSE 返回逻辑值 FALSE。
值|IF IF(<条件判断>,<正确的返回结果>,<错误返回结果>) 检查条件,如果为 TRUE,则返回一个值,否则返回第二个值。
值|IFERROR IFERROR(<表达式>,<容错值>) 计算表达式,如果表达式返回错误,则返回指定的值。
值|NOT 将 FALSE 更改为 TRUE,或者将 TRUE 更改为 FALSE。
值|SWITCH SWITCH(<表达式>,<值>,<结果>) 针对值列表计算表达式,并返回多个可能的结果表达式之一。
值|TRUE 返回逻辑值 TRUE。
六.时间智能函数
时间智能|值|DATEADD DATEADD(<日期列>,<整数>,<粒度>) 可以是一个具体的值,也可以是—列日期。
时间智能|表|DATESBETWEEN DATESBETWEEN(<日期列>,<开始日期>,<结束日期>) 包含两端值。
时间智能|表|DATESINPERIOD DATESINPERIOD(<日期列>,<开始日期>,<移动间隔>,<粒度>) 返回的日期如果在原表中没有的话,那么呈现的结果就是原表日期值的最大值/最小值。
时间智能|表|NEXT系列
NEXT系列一共包含四个函数:NEXTDAY函数,NEXTMONTH函数,NEXTQUARTER函数,NEXTYEAR函数。分别代表次日、次月、次季度、次年。
时间智能|值|TOTAL系列 TOTAL函数系列共包含三个函数:TOTALMTD函数,TOTALQTD函数,TOTALYTD函数。分别计算月初、季度初、年初迄今的累计值。
1.时间智能|值|DATEADD
语法:
DATEADD(<日期列>,<整数>,<平移的单位>)
参数:
日期列:可以是一个具体的日期,可以是一列日期,也可以是一个日期的表达式。
整数:正数向后平移,负数向前,小数四舍五入。
粒度:年、季度、月、日。
2.时间智能|表|DATESBETWEEN
语法:
DATESBETWEEN(<日期列>,<开始日期>,<结束日期>)
参数:
日期列:对日期列的引用。
开始日期:可以是固定日期,也可以是日期表达式。如果是空白日期,会取日期列的最早日期。
结束日期:可以是固定日期,也可以是日期表达式。如果是空白日期,会选取日期列的最晚日期。
注意:
取值包含两端值。
3.时间智能|表|DATESINPERIOD
用途1:可以用来返回固定的日期值。
用途2:可以用来算移动平均。
用途3:可以算固定日期内的累计值。
语法:
DATESINPERIOD(<日期列>,<开始日期>,<移动间隔>,<粒度>)
注意:
返回的日期如果在原表中没有的话,那么呈现的结果就是原表日期值的最大值/最小值。
4.时间智能|表|NEXT系列
用途1:生成日期表。初始为次日/次月/次季度/次年。
用途2:计算相对应范围的数据值。
NEXT系列一共包含四个函数:NEXTDAY函数,NEXTMONTH函数,NEXTQUARTER函数,NEXTYEAR函数。分别代表次日、次月、次季度、次年。
5.时间智能|值|TOTAL
TOTAL函数系列共包含三个函数:TOTALMTD函数,TOTALQTD函数,TOTALYTD函数。分别计算月初、季度初、年初迄今的累计值。
注意:这三个的区别就是参数,只有TOTALYTD的参数有结束日期,其他的都只有“<表达式>,<日期>,[筛选器]”
七.复杂函数
筛选|表|addmissingtems 用途:对一些筛选,比如只显示"可见项目“类函数的补充,能让其显示一些”缺失项“。
TREATAS()
1.维度表和事实表没有可以单独关联的列;
2.出现多对多;
3.模型很复杂时,通过建立虚拟关系以减少对表格之间物理连接的依赖。
八.数学函数
值|ABS ABS(<值>) 返回值的绝对值。
值|DIVIDE DIVIDE(<分子>,<分母>) 返回除法结果或者备用值。 注:此函数性能略差直接使用/
值|ROUND ROUND(<值>,<位数>) 将数值舍到指定位数















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









