







**
一、事前准备
**
目标:爬取www.zol.com.cn的收集资料,各种参数
库:BeautifulSoup和requests。对BeautifulSoup库的find和find_all有基本的了解,对requests库的get方法有基本的了解。
原网页面分析:
网址:(第一页)http://detail.zol.com.cn/cell_phone_index/subcate57_0_list_1_0_1_1_0_1.html
分析页面元素:鼠标右键→审查元素→“Elements”→刷新页面→就可以看到数据哗哗哗地显示出来了,这就是我们下面将要分析的东东~~~
**
二、小白热身
**
以下暴力摘抄整理了网页的部分内容,以此为例,先给大家一个直观的感受,免得一上来就是一大段代码,不知从何下手,头都大了~~~
先把下面这段拷贝下来,自己运行下试试
html="""
<body class="list-for-mobile-phone">
<div class="content">
<div class="list-box">
<div class="pro-intro">
<h3><a href="/cell_phone/index1316807.shtml" target="_blank">OPPO Ace2(8GB/128GB/全网通/5G版)</a></h3>
<ul class="param clearfix">
<li title="移动TD-LTE,联通TD-LTE,联通FDD-LTE,电信TD-LTE,电信FDD-LTE"><span>4G网络:</span>移动TD-LTE</li>
<li title="6.55英寸 2400x1080像素"><span>主屏尺寸:</span>6.55英寸 2400x1080像素</li>
<li title="高通 骁龙865"><span>CPU型号:</span>高通 骁龙865</li>
</ul>
</div>
<div class="price-box">
<span class="price price-normal"><b class="price-sign">¥</b>
<b class="price-type">2698</b>
</span><span class="price-attr">[128GB行货]</span>
<span class="date">2020-05-14</span>
<p class="mernum"><a href="/1319/1318500/price.shtml" target="_blank">1家商家报价</a></p>
<a href="/1319/1318500/price.shtml" class="base" target="_blank">查询底价</a>
</div>
<div class="pro-intro">
<h3><a href="/cell_phone/index1316807.shtml" target="_blank">iQOO Neo3(6GB/128GB/全网通/5G版)</a></h3>
<ul class="param clearfix">
<li title="移动TD-LTE,联通TD-LTE,联通FDD-LTE,电信TD-LTE,电信FDD-LTE"><span>4G网络:</span>移动TD-LTE</li>
<li title="6.57英寸 2408x1080像素"><span>主屏尺寸:</span>6.57英寸 4800x1080像素</li>
<li title="高通 骁龙865"><span>CPU型号:</span>高通 骁龙865</li>
</ul>
</div>
<div class="price-box">
<span class="price price-normal"><b class="price-sign">¥</b>
<b class="price-type">5988</b>
</span><span class="price-attr">[128GB厂商指导价]</span>
<span class="date">2020-05-14</span>
<p class="mernum"><a href="/1316/1315874/price.shtml" target="_blank">92家商家报价</a></p>
<a href="/1316/1315874/price.shtml" class="base" target="_blank">查询底价</a>
</div>
</div>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup=BeautifulSoup(html,"html.parser")
a=soup.find("div",class_="list-box").find_all("div",class_="price-box")
print(a)
print("find_all返回值的数量:",len(a))
print("find_all返回值的类型:",type(a))
#print("find_all返回值的第一个值:",a[0])
for i in a:
print(i.find("b",class_="price-type").string)
print("......","这是find_all返回值的第一个标签'b'的内容","......")
>>>[<div class="price-box">
<span class="price price-normal"><b class="price-sign">¥</b>
<b class="price-type">2698</b>
</span><span class="price-attr">[128GB行货]</span>
<span class="date">2020-05-14</span>
<p class="mernum"><a href="/1319/1318500/price.shtml" target="_blank">1家商家报价</a></p>
<a class="base" href="/1319/1318500/price.shtml" target="_blank">查询底价</a>
</div>, <div class="price-box">
<span class="price price-normal"><b class="price-sign">¥</b>
<b class="price-type">5988</b>
</span><span class="price-attr">[128GB厂商指导价]</span>
<span class="date">2020-05-14</span>
<p class="mernum"><a href="/1316/1315874/price.shtml" target="_blank">92家商家报价</a></p>
<a class="base" href="/1316/1315874/price.shtml" target="_blank">查询底价</a>
</div>]
find_all返回值的数量: 2
find_all返回值的类型: <class 'bs4.element.ResultSet'>
2698
...... 这是find_all返回值的第一个标签'b'的内容 ......
5988
...... 这是find_all返回值的第一个标签'b'的内容 ......
>>>
for i in soup.find("div",class_="list-box").find_all("div",class_="pro-intro"):
print(i.find("span").string)
print(type(i.find("span").string))
print(i.find("span").string[1])
>>>4G网络:
<class 'bs4.element.NavigableString'>
G
4G网络:
<class 'bs4.element.NavigableString'>
G
from bs4 import BeautifulSoup as bs
soup=bs(html,"html.parser")
for i in soup.find("div",class_="list-box").find_all("div",class_="pro-intro"):
print(i.find("h3").string)
for j in i.find("ul",class_="param clearfix").find_all("li")[1:]:
print(j)
>>>OPPO Ace2(8GB/128GB/全网通/5G版)
<li title="6.55英寸 2400x1080像素"><span>主屏尺寸:</span>6.55英寸 2400x1080像素</li>
<li title="高通 骁龙865"><span>CPU型号:</span>高通 骁龙865</li>
iQOO Neo3(6GB/128GB/全网通/5G版)
<li title="6.57英寸 2408x1080像素"><span>主屏尺寸:</span>6.57英寸 4800x1080像素</li>
<li title="高通 骁龙865"><span>CPU型号:</span>高通 骁龙865</li>
from bs4 import BeautifulSoup as bs
soup=bs(html,"html.parser")
for i in soup.find("div",class_="list-box").find_all("div",class_="pro-intro"):
print(i.find("h3").string)
for j in i.find("ul",class_="param clearfix").find_all("li")[1:]:
print(j.find("span").string[:-1])
>>>OPPO Ace2(8GB/128GB/全网通/5G版)
主屏尺寸
CPU型号
iQOO Neo3(6GB/128GB/全网通/5G版)
主屏尺寸
CPU型号
from bs4 import BeautifulSoup as bs
soup=bs(html,"html.parser")
for i in soup.find("div",class_="list-box").find_all("div",class_="pro-intro"):
for j in i.find("ul",class_="param clearfix").find_all("li")[1:]:
print(j["title"])
>>>6.55英寸 2400x1080像素
高通 骁龙865
6.57英寸 2408x1080像素
高通 骁龙865
>>>
一步步测试,查看得到的结果是否符合预期,不断完善。
上面的这点搞定,下面就顺理成章,开动啦
**
三、实战
**
其实主要的内容都在下面这两张图里了,你只要把鼠标放在这些五颜六色的代码上网页就会出现阴影覆盖,这样就可以看到哪一块代码对应网页的哪块内容。确定这块代码后,就可以专心分析这段代码,看看它有什么特点,然后用Python定位它,获取你想要的
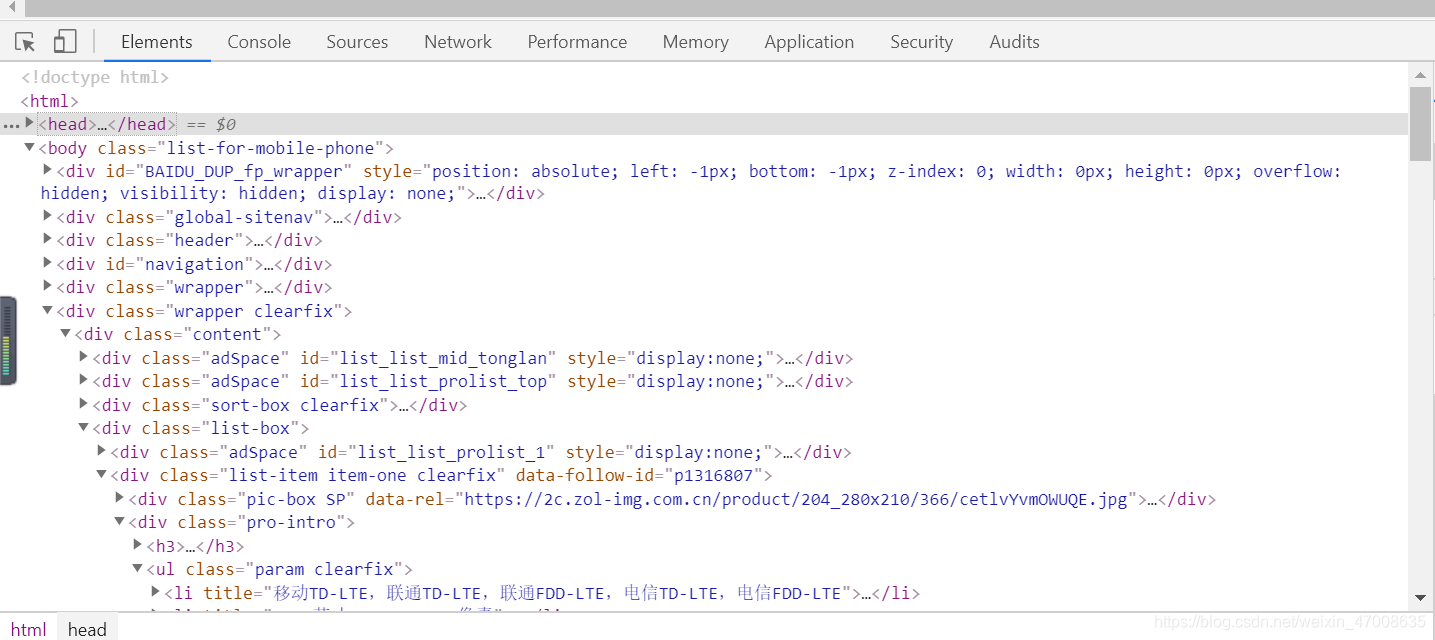
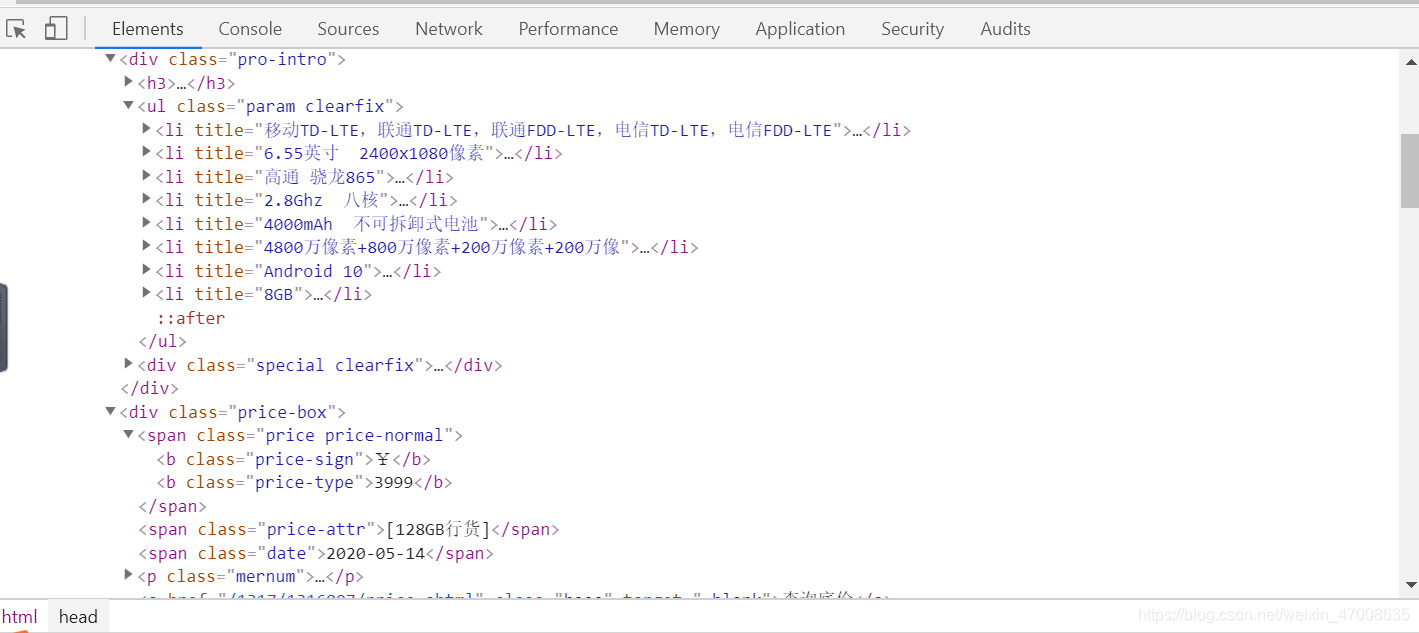
import time
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
def get_value(url):
soup=bs(htmltext,"html.parser")
Dic1={"NAME":[],"PRICE":[],"DATE":[]}
Dic2={}
num=0
for z in soup.find("div",class_="list-box").find_all("div",class_="price-box"):
try:
price=z.find("b",class_="price-type").string
except:
price="n/a"
Dic1["PRICE"].append(price)
try:
shelfdate=z.find("span",class_="date").string
except:
shelfdate="n/a"
Dic1["DATE"].append(shelfdate)
for i in soup.find("div",class_="list-box").find_all("div",class_="pro-intro"):
a=i.find("h3").find("a").string
Dic1["NAME"].append(a)
for j in i.find("ul",class_="param clearfix").find_all("li")[1:]:
c1=j.find("span").string[:-1]
if c1 not in Dic1:
Dic1[c1]=["N/A"]*num
Dic2[c1]=j["title"]
for key in Dic1:
if key!="NAME" and key!="PRICE" and key!="DATE":
try:
Dic1[key].append(Dic2[key])
except:
Dic1[key].append("N/A")
num+=1
return Dic1
total=[]
for i in range(1,3):
url="http://detail.zol.com.cn/cell_phone_index/subcate57_0_list_1_0_1_1_0_{0}.html".format(i)
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
response=requests.get(url,headers=head)
response.encoding=response.apparent_encoding
htmltext=response.text
d=get_value(url)
data=pd.DataFrame(d)
data=data.loc[:,["NAME","CPU型号","电池容量","主屏尺寸","CPU频率","后置摄像头","RAM容量","DATE","PRICE"]]
total.append(data)
D=pd.concat(total,ignore_index=True)
print("---完成第",i,"页,获取了",len(D["NAME"]),"条,积累了",len(D["NAME"]),"条")
time.sleep(3)
D.to_csv(r"c:\users\admin\desktop\中关村手机资料.csv")
print("爬取完成,共计有",len(D["NAME"]),"条")
data.head()
---完成第 1 页,获取了 48 条,积累了 48 条
---完成第 2 页,获取了 96 条,积累了 96 条
爬取完成,共计有 96 条
>>>
参考:https://blog.csdn.net/qq_40523096/article/details/88544692

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









