






一、什么是MySQL
1.1 概念
MySQL是一种关系型数据库管理系统。关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
1.2 SQL 语言
MySQL所使用的 SQL 语言是结构化查询语言, 此语言是用于程序员和数据库软件进行交流
的语言,是用于访问数据库的最常用标准化语言。
1.3 SQL语句分类
- DDL:数据定义语言,包含数据库相关和表相关的SQL语句
- DML:数据操作语言,包括增删改查
- DQL:数据查询语言,只包含查询
- TCL:事务控制语言, 包含和事务相关
- DCL:数据控制语言, 包含和用户管理和权限分配相关的SQL语句
1.4 连接MySQL
连接格式:mysql -h 主机地址 -u 用户名 -p 用户密码
修改密码格式 :mysqladmin -u用户名 -p 旧密码 -password 新密码
增加新用户格式 : grant select on 数据库.* to 用户名@登录主机 identified by “密码”
二、MySQL中的日志及主从复制
2.1 MySQL日志
2.1.1错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
# 查看日志位置:
mysql> show variables like '%log_error%';
2.1.2 二进制日志(binlog)
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用:①灾难时的数据恢复;②MySQL的主从复制。
MariaDB [(none)]> show variables like '%log_bin%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin | OFF |
| log_bin_basename | |
| log_bin_compress | OFF |
| log_bin_compress_min_len | 256 |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| sql_log_bin | ON |
+---------------------------------+-------+
7 rows in set (0.002 sec)2.2 MySQL主从复制
2.2.1 概述
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
2.2.1 主从复制的优点
MySQL 复制的优点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务。
实现读写分离,降低主库的访问压力。
可以在从库中执行备份,以避免备份期间影响主库服务。
2.2.3 主从复制原理
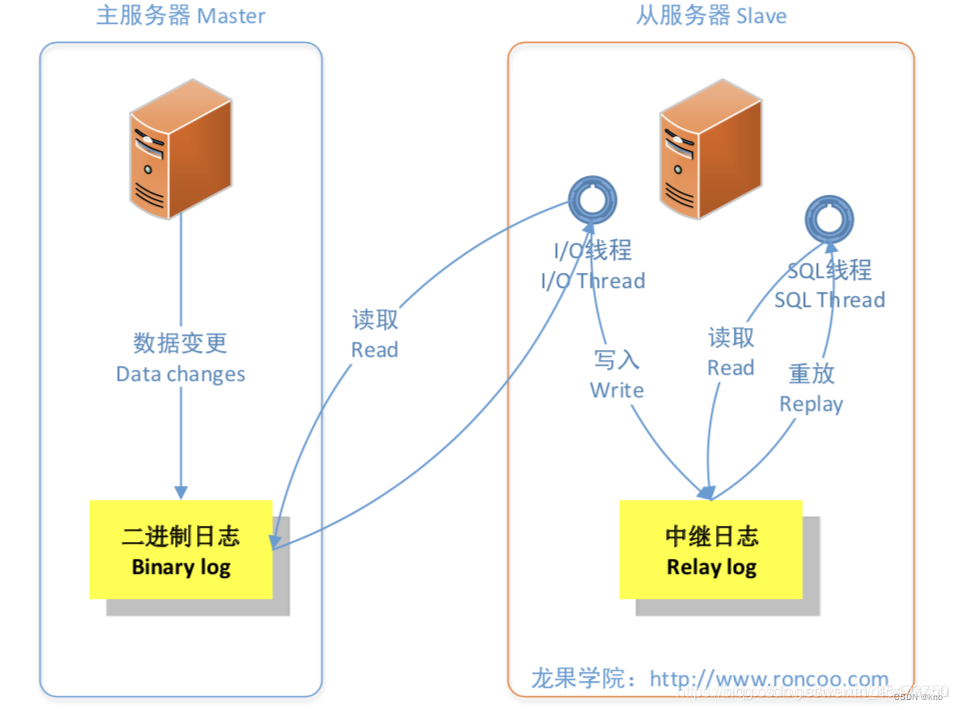
从上图来看,复制分成三步:
1、Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
2、从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
3、slave重做中继日志中的事件,将改变反映它自己的数据。
三、MySQL的分库分表
3.1 概述
3.1.1 分库分表概念
(1)分库:就是一个数据库分成多个数据库,部署到不同机器。

(2)分表:就是一个数据表分成多个表。

3.1.2分库分表的原因
(1)业务量剧增,数据库可能会出现性能瓶颈,MySQL单机磁盘容量会撑爆,拆成多个数据库,磁盘使用率大大降低。
数据库连接是有限的。为了应对高并发。它把订单、用户、商品等不同模块,拆分成多个应用,并且把单个数据库也拆分成多个不同功能模块的数据库(订单库、用户库、商品库),以分担读写压力。
(2)数据量太大,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量级别的表可能会拖垮整个数据库。
3.2 分库分表的类别
3.2.1 垂直分库
垂直分库,将原来一个单数据库的压力分担到不同的数据库,可以很好应对高并发场景。
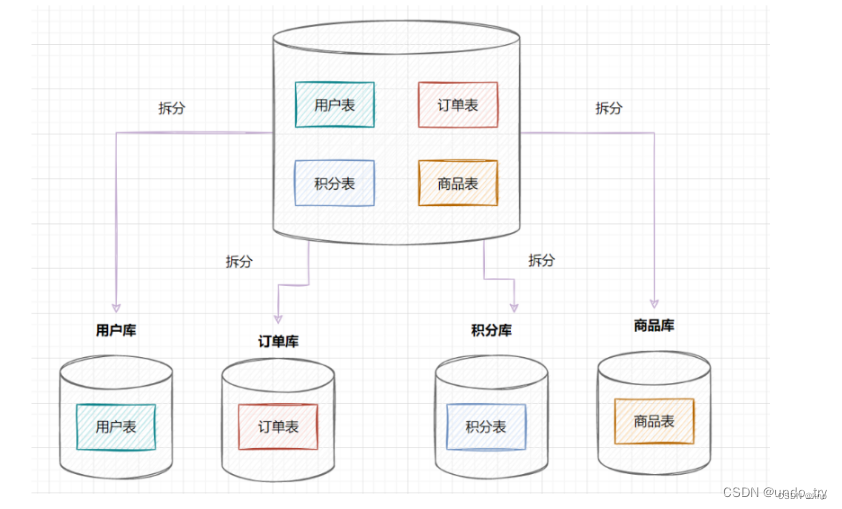
3.2.2 水平分库
水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力。

3.2.3 垂直分表
如果一个单表包含了几十列甚至上百列,管理起来很混乱,每次都select *的话,还占用IO资源。这时候,可以将一些不常用的、数据较大或者长度较长的列拆分到另外一张表。

3.2.4 水平分表
如果一个表的数据量太大,可以按照某种规则(如hash取模、range),把数据切分到多张表去。

3.3 分库分表的方案
分库分表方案一般有几种,使用在不同的场景:
- range范围
- hash取模
- range+hash取模混合
3.3.1 range范围
range,即范围策略划分表。比如我们可以按时间范围来划分,如不同年月的订单放到不同的表,也可以将表的主键,按照从0~1000万的划分为一个表,1000~2000万划分到另外一个表。如下图:

此方法优点:有利于扩容,不需要数据迁移。
缺点:存在数据热点问题;若订单id是一直在增大的,也就是说最近一段时间都是汇聚在一张表里面的。比如最近一个月的订单都在1000万~2000万之间,平时用户一般都查最近一个月的订单比较多,请求都打到order_1表啦,这就导致数据热点问题。
3.3.2 hash取模
hash取模策略:指定的路由key(一般是user_id、订单id作为key)对分表总数进行取模,把数据分散到各个表中。
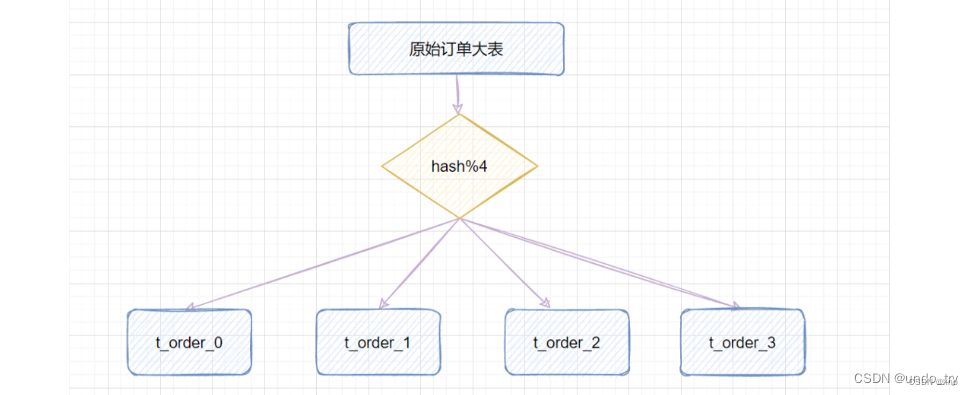
此方案的优点:不会存在明显的热点问题。
缺点:在某个未来的时间段,表数据量又到瓶颈了,需要扩容,数据大概率会重新分布在另一张新表。比如从4张表,又扩容成8张表,那之前id=5的数据是在(5%4=1,即t_order_1),现在应该放到(5%8=5,即t_order_5),也就是说历史数据要做迁移了。
3.3.3 range+hash取模混合
在拆分库的时候,可以先用range范围方案,比如订单id在0-4000万的区间,划分为订单库1; id在4000万-8000万的数据,划分到订单库2;将来要扩容时,id在8000万-1.2亿的数据,划分到订单库3。然后订单库内,再用hash取模的策略,把不同订单划分到不同的表。如下图所示:

3.4 分库分表的使用
3.4.1 何时分表
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。(参考阿里开发手册)
3.4.2 何时分库
业务发展很快,还是多个服务共享一个单体数据库,数据库成为了性能瓶颈,就需要考虑分库了。比如订单、用户等,都可以抽取出来,并且拆分数据库(订单库、用户库)---微服务架构思想。
3.5 分库分表产生的问题
(1)事务问题
分库分表后,假设两个表在不同的数据库,那么本地事务已经无效啦,需要使用分布式事务了。
(2)跨库关联
跨节点Join的问题:解决这一问题可以分两次查询实现。超过三个表禁止 join。需要 join 的字段,数据类型必须绝对一致;多表关联查询时,保证被关联的字段需要有索引。
(3)排序问题
跨节点的count,order by,group by以及聚合函数等问题:可以分别在各个节点上得到结果后在应用程序端进行合并。
(4)分布式ID
数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID,或者使用雪花算法生成分布式ID。
(5)分页问题
方案1:在各节点查到对应结果后,在代码端汇聚再分页。
方案2:把分页交给前端,前端传来pageSize和pageNo,在各个数据库节点都执行分页,然后汇聚总数量前端。这样缺点就是会造成空查,如果分页需要排序,不好显示。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









