






 文章介绍了如何在Python中计算混淆矩阵,以及基于混淆矩阵的性能指标,如IOU(交并比)、类别像素准确率(CPA/召回率)、准确率和精准率。主要涉及的函数包括`fast_hist`用于生成混淆矩阵,以及`per_class_iu`计算IOU,`per_class_PA_Recall`计算CPA/召回率,和`per_Accuracy`、`per_class_Precision`分别计算准确率和精准率。
文章介绍了如何在Python中计算混淆矩阵,以及基于混淆矩阵的性能指标,如IOU(交并比)、类别像素准确率(CPA/召回率)、准确率和精准率。主要涉及的函数包括`fast_hist`用于生成混淆矩阵,以及`per_class_iu`计算IOU,`per_class_PA_Recall`计算CPA/召回率,和`per_Accuracy`、`per_class_Precision`分别计算准确率和精准率。
分割常见性能指标的计算方法(python)
混淆矩阵
对于很多指标的计算,第一步就是计算混淆矩阵。混淆矩阵实际上就是总结分类结果的矩阵。对于k元分类,其实它就是一个k * k的表格,用来记录分类器的预测结果。
以二元分类为例,比如我们一个模型对15个样本进行预测,然后结果如下:
真实值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0
预测值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1
那么混淆矩阵则为如下形式:

在python中可用如下代码进行计算
def fast_hist(a, b, n):
k = (a >= 0) & (a < n)
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
hist = fast_hist(label.flatten(), pred.flatten(), num_classes)
函数解释为:
以常见的三维数组为例,a为标签图,b为预测图,a = np.array([[0, 1, 2],[1, 2, 0],[2, 0, 1]]),b = np.array([[0, 0, 1],[1, 2, 0],[2, 0, 2]])
将标签数组展平:[0, 1, 2, 1, 2, 0, 2, 0, 1] 和预测数组展平:[0, 0, 1, 1, 2, 0, 2, 0, 2]。
首先计算 a>=0 且 a<n的掩码,为包含我们所需类别的mask(类别1标签为0,类别2标签为1,以此类推),即 (a >= 0) & (a < 3) = [True, True, True, True, True, True, True, True, True]。
根据掩码取出 a 中对应的值,即 a[k] = [0, 1, 2, 1, 2, 0, 2, 0, 1],同理取出 b[k] = [0, 0, 1, 1, 2, 0, 2, 0, 2]。
将 a[k] 中的值乘以 n(即 3),并将 b[k] 加到乘积中,得到 3×a[k]+b[k] = [0, 3, 7, 4, 8, 0, 8, 0, 5]。
使用 np.bincount 函数计算每个 bin 中出现的次数,例如0出现3次,1出现0次,2出现0次,以此类推,得到 [3, 0, 0, 1, 1, 1, 0, 1, 2]。minlength=n ** 2即规定该数组长度为n的平方,不足则补零。
由于混淆矩阵是 n*n 的,因此使用 reshape 函数将 1 维数组转换为 3x3 的二维数组,得到 [[3, 0, 0], [1, 1, 1], [0, 1, 2]],即为最终的混淆矩阵。可以将其与上面二类的混淆矩阵做一个对应,例如第一行意为标签为0预测0的有3个,没有预测为1或2的。
交并比IOU
交并比表示的含义是模型对某一类别预测结果和真实值的交集与并集的比值。只不过对于目标检测而言是检测框和真实框之间的交并比,而对于图像分割而言是计算预测掩码和真实掩码之间的交并比。
def per_class_iu(hist):
return np.diag(hist) / np.maximum((hist.sum(1) + hist.sum(0) - np.diag(hist)), 1)
函数解释为:
接受一个二维数组混淆矩阵作为输入,然后返回一个一维数组。以下是函数中使用的各个部分的解释:
np.diag(hist):用于从给定矩阵的对角线中返回元素。在这里,它返回二维数组 hist 的对角线元素,也就是混淆矩阵中的真阳性和真阴性数量, 注意返回的只是元素,比如上面的例子就应该为[3,1,2]。
hist.sum(1):用于计算给定矩阵的行之和。在这里,它返回二维数组 hist 中每一行的元素之和,也就是混淆矩阵中每个类别的实际样本数量,比如上面的例子就应该为[3,3,3]。
hist.sum(0):用于计算给定矩阵的列之和。在这里,它返回二维数组 hist 中每一列的元素之和,也就是混淆矩阵中每个预测类别的数量,比如上面的例子就应该为[4,2,3]。
hist.sum(1) + hist.sum(0) - np.diag(hist):计算的是混淆矩阵中每个类别的样本总数,减去它们之间的交集数量,从而得到它们的并集数量,比如上面的例子就应该为[4,4,4]。
np.maximum():用于返回两个数组中对应位置上的最大值。在这里,它计算每个类别的交并比,并返回每个类别的最大值,如果分母列表中有元素为零,它会将其替换为1,以避免出现除以零错误。
np.diag(hist) / np.maximum((hist.sum(1) + hist.sum(0) - np.diag(hist)), 1):函数的主体部分。它使用了前面提到的所有函数来计算每个类别的交并比(即每个类别的“像素准确率”)。它首先计算混淆矩阵中每个类别的真阳性和真阴性数量,并将其除以交集并集的数量。最终,它将每个类别的结果放入一个一维数组中,并返回该数组作为函数的输出,比如上面的例子就应该为[3/4,1/4,2/4],分别是类别0,1,2的交并比。
类别像素准确率(Class Pixel Accuracy) / 召回率
如果将混淆矩阵与IOU的计算方式搞懂了,那么其余的性能指标就是依葫芦画瓢了,以CPA为例。类别像素准确率(Class Pixel Accuracy,CPA)含义是预测类别正确的像素数占类别总像素数的比例,也称召回率。
python代码为:
def per_class_PA_Recall(hist):
return np.diag(hist) / np.maximum(hist.sum(1), 1)
计算公式:对角线元素 / 标签矩阵此类别所有元素,比如上面的例子就应该为[3/3,1/3,2/3]。
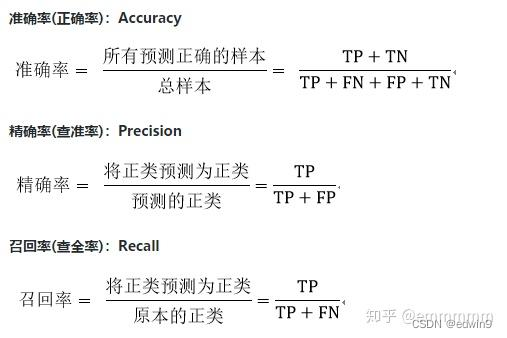
准确率(Accuracy)
预测对的样本数除以所有的样本数就是准确率(Accuracy),实际上就是类别像素准确率的均值。
python代码为:
def per_Accuracy(hist):
return np.sum(np.diag(hist)) / np.maximum(np.sum(hist), 1)
比如上面的例子就应该为(3+1+2)/(3+0+0+1+1+1+0+1+2)=6/9。
精准率(Precision)
预测结果中某类别预测正确的概率。
def per_class_Precision(hist):
return np.diag(hist) / np.maximum(hist.sum(0), 1)
比如上面的例子就应该为[3/4,1/2,2/3]。
博主也是名初学者,如有错误欢迎指正。















 4181
4181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









