






需要完整代码和论文私信我

摘 要
人体解析是图像分割中语义分割的一种,主要是识别出人体的头部、头发、身体、胳膊、腿、上衣等区域,它是一种像素级别的语义分割任务。随着FCN模型的提出,深度学习广泛应用于图像分割中的语义分割任务。本文主要介绍了FCN、U-Net、PSPNet以及DeepLabV3三种在人体解析语义分割任务中较为著名的深度学习模型,比较上述模型的不同以及指出各个模型针对性解决的问题。本文使用经过空洞卷积处理过的ResNet50模型作为特征提取模型,构建PSPNet模型对LIP数据集进行训练测试,得到的MIoU指标达到了74.3%,效果较好。
关键词:语义分割;深度学习;人体解析;空洞卷积;金字塔池化模块;PSPNet
Abstract
Human body analysis based on PSPNet
Human body analysis is a kind of semantic segmentation in image segmentation, mainly to identify the head, hair, body, arms, legs, coat and other areas of the human body, it is a pixel level semantic segmentation task. With the introduction of FCN model, deep learning is widely applied to semantic segmentation tasks in image segmentation. This paper mainly introduces FCN, U-NET, PSPNet and DeepLabV3 three famous deep learning models in human body parsing semantic segmentation task, compares the differences of the above models and points out the specific problems of each model. In this paper, ResNet50 model processed by cavity convolution is used as the feature extraction model, and PSPNet model is constructed to conduct training test on LIP data set, and the MIoU index obtained reaches 74.3%, with good effect.
Key words:Semantic segmentation; Deep learning; Human body analysis; Empty convolution; Pyramid pooling module; PSPNet
目 录
基于PSPNet的人体解析
1、引言
计算机视觉是计算机能够智能理解世界的一种途径,近年来深度学习迅的成功应用使得计算机视觉的图像识别、目标检测、语义分割等任务的性能大幅提升。图像识别任务解决的是图像物体分类的问题,相关著名的深度学习模型有VGG系列和ResNest系列等模型,可以应用在人脸识别和其他动植物图像分类的场景上,例如深度学习模型均在Image图像分类大赛上大放光彩;目标检测任务解决的是目标物体的定位以及分类的问题,主要是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别,相关著名的模型有Yolo系列等目标检测模型,目标检测可以助力于无人驾驶场景的相关方面;而语义分割就是对一张图片上的所有像素点进行分类,即对图像中的每个像素都划分出对应的类别,实现像素级别的分类,难度较大,相关的模型有FCN、SegNet与U-Net等。
计算机视觉中的语义分割任务,只是图像分割任务中的一种,图像分割主要分为三种。第一种为语义分割,即上述的对一张图片上的所有像素点进行分类;第二种是实例分割,图像实例分割是在对象检测的基础上进一步细化,分离对象的前景与背景,实现像素级别的对象分离;第三种是全景分割,全景分割是语义分割和实例分割的结合,全景分割是对图中的所有物体包括背景都要进行检测和分割。语义分割与实例分割最主要的区别就是,实例分割在正确检测目标的同时,还要精确的分割出每个实例,但不包括背景信息。本文所要实现的人体解析任务是计算机视觉分割任务中语义分割的一种。
人体解析的目标是将在图像中捕获的人分割成多个语义上一致的部分,它是语义分割的子任务之一,它作为一种细粒度的语义分割任务,比仅是寻找人体轮廓的人物分割更具挑战性。 人体解析它是以人为中心进行图像分割,目的是识别出人体的头部、头发、身体、胳膊、腿、上衣等区域。这是一种像素级别的预测任务,难度非常大,需要了解全局和局部水平的人体图像信息。而不同于简单的语义分割,人体解析不对背景细致的分割而是针对人体,它的目标仅仅是对人体部分进行分割。
人体解析是计算机视觉领域中一种比较基础的任务,具有广泛的应用价值,它的应用非常多,例如人体重识别、人体姿态估计、视频监控等领域,它在上述领域均已成功应用。而在未来,它在人机交互、人体行为分析、运动分析、虚拟试衣等领域的应用前景非常大,它潜在的研究价值和应用价值得到社会上相关研究者的关注与肯定。
2、人体解析
2.1技术简述
图像分割是计算机视觉领域的一个重要研究方向,随着计算机硬件的快速发展,深度学习技术的逐步深入,图像分割在多个视觉研究领域都有着广泛的应用。简单来说,图像分割其实就是将一张图像中分割出我们感兴趣目标的一个完整轮廓,通俗将就是我们常用的“抠图”。图像分割是根据图像的灰度、形状、纹理信息和结构等特性将图像分割成多个具有固定特性区域的过程,例如简单的前后景分离,而从数学角度来说,图像分割就是将图像分割成若干个互不相交的区域的过程。
而图像分割又分为语义分割、实例分割以及全景分割。语义分割它是一种典型的计算机视觉问题,主要将一些原始数据作为输入,最后对图像中的每一个像素进行分类,使得不同类别的目标在图像中被区分开来,是属于像素级别的一种分类任务,难度较大;实例分割是目标检测和语义分割的结合,主要使用一个边界框将图像中的目标检测出来(目标检测),然后对每个像素进行分类,并打上标签(语义分割);全景分割是同时实现对背景的语义分割和前景的实例分割,即包含语义分割也包含实例分割,要将图像中所有目标检测出来,又要将同一类别中的不同个体区分出来,与语义分割不同,它需要对图像中每个目标进行区分,与实例分割不同,所有的目标不能重叠。
人体解析是图像分割中语义分割任务的其中一种,其目标是将一个人身体的各个部位或者所着衣物配饰加以识别。所有组成人体和衣物的像素均被标记,并且归类为对应类别。人体解析集中于以人为中心的分割,须识别出人体的脸部、头发、上衣、裤子等区域。人体解析在诸多领域均有应用,如人体外观转移、行为识别、行人再识别 、时装合成等。因此,人体解析具有重要的研究意义和应用价值。
2.2研究现状
人体解析(Human Parsing, HP)作为图像分割中语义分割的任务之一,重点关注的是对人体图像的识别,是对图像中的人体部位(如:脸部、腿部)和衣物(如:裤子、背包)进行像素级的语义分割。近年来,计算机硬件与深度学习方法的不断发展,有关人体解析的工作也取得了极大进展,从2012 年开始, AlexNet 模型在Image图像分类任务中取得了惊人的成果后,卷积神经网络在深度学习中的地位变得非常突出,而深度学习也从此慢慢步入人们的眼中,在各种领域中开始出现了深度学习的身影。
而让深度学习广泛应用于图像分割任务的是 Long 等人提出全卷积网络(Fully Convolutional Network, FCN)[5],FCN使得卷积神经网络不需要全连接层就可以实现密集的像素级分类,从而成为当时最流行的像素级分类架构,从此语义分割领域的许多先进方法都是基于该模型进行扩展的与比较的。在早期的人体解析方法中,研究者们尝试了多种思路增强对人体图像特征的提取。ATR和 MCNN均采用了将人体部位或衣物先分离提取特征再合并的思路,Co-CNN针对深度卷积神经网络深层特征对细节不敏感的缺点,设计局部到全局到局部(local-to-global-to-local)的网络结构来提取局部和全局特征。对深层网络在特征提取中随着网络深度的加深,特征分辨率不断变小的情况,空洞卷积(dilated/atrous convolution)这一概念被提出。与一般卷积的不同之处在于,空洞卷积在卷积核之间注入一定数量的空洞,空洞的数量称之为空洞卷积率。空洞卷积在不改变卷积核尺寸的情况下,使得卷积层获得了更大的感受野。使用空洞卷积重新设计的深度卷积神经网络称之为 DeepLab。DeepLab 系列包含四个版本,分别为 DeepLabV1,DeepLabV2,DeepLabV3和 DeepLabV3+。DeepLab 系列网络在图像分割和人体解析任务上都取得了很好的效果。
而在目前,图像语义分割领域的方法大致可以被分为两种类型,第一种是基于特征分辨率保持的方法,此类方法尝试获得高分辨率的特征图从而更精准的恢复预测所需要的细节信息;第二种是基于上下文信息提取的方法,此类方法的目标在于捕捉丰富的上下文关系,从而更好的解决多尺度的目标预测问题。本文所使用的PSPNet模型就是第二种基于上下文信息提取的方法,而最早的FCN即是第一种基于特征分辨率保持的方法,后面发展的DeepLab 系列网络模型都是基于第二种方法,说明人们对于图像语义分割任务,都是注重于解决多尺度的目标预测问题。
2.3代表模型
首先FCN模型可以说是语义分割开始兴起的开山之作,它针对普通分类网络用于分割效果较差的问题,文章第一次提出抛弃全连接层,使用全卷积神经网络的架构,突破了以往的网络输入图片尺寸必须固定大小的限制,为以后的分割网络所沿用;使用了反卷积操作进行恢复分辨率;为了得到更加精细的分割结果,使用了跳跃连接,通过中层的语义信息来改善分割结果。在FCN出现之前,大多数的分割网络针对像素进行分类都是找到包含这个像素的一块区域,将这块区域的类别作为像素点的类别,显然这样操作耗费内存,而且区域可能会重叠,效率低下。FCN是第一次尝试从抽象的语义特征直接对像素进行分类。这篇论文具体解决的问题是如何恢复原有的分辨率,从网络来看,进行了多次的反卷积操作,每一次反卷积之后,找到相对应的池化后的中层信息进行加和,再进行反卷积操作。该模型的主要目的是使用了反卷积操作进行恢复分辨率,它注重的是图像的分辨率问题,所以它是属于基于特征分辨率保持的图像语义分割方法。
第二个代表模型是U-Net,它是一种编码-译码结构,是一种为医学图像分割而提出的一种轻量化的网络。它的轻量化,要求的数据量少且速度也够快;译码方式不同,与浅层特征融合采用的是叠加的方式。但是这种网络较为特殊的是要谨慎的选择输入图片的尺寸,要保证在进行池化时其尺寸要为偶数;这种网络较为特殊的一点是需要对特征图进行一定的裁剪,以保证译码过程进行特征融合时尺寸一致。模型的结构图可见下图,我们可以看到该模型是呈现一个“U型”的,所以它的名字前面有U的含义我们就不言而喻了。

图2-1 U-Net模型结构图
第三个代表模型即是DeepLab系列中的DeepLabV3模型,使用了空洞卷积扩大感受野;使用空洞金字塔池化处理多尺度问题;使用了CRF来改善分割结果,后来又使用了编码译码结构。空洞卷积(Dilatee/Atrous Convolution)是一种特殊的卷积算子,针对卷积神经网络在下采样时图像分辨率降低、部分信息丢失而提出的卷积思路,通过在卷积核中添加空洞以获得更大的感受野。模型的结构可见下图,它主要是在 ResNet-101 的 Block3 和 Block4 中将部分卷积层替换为空洞卷积率等于 2 的空洞卷积,由此实现了特征分辨率保持不变。并将 Block4 的输出进一步输入 ASPP模块中,使用不同空洞卷积率的卷积核对特征进行并行的多尺度提取。最后将多尺度特征融合后使用 1 × 1 的卷积输出最后的分割结果。

图2-2 DeepLabV3模型结构图
最后一个代表模型即是PSPNet,PSPNet 将对上下文信息的提取分为两部分,一部分为细节上下文信息的提取,主要从主干网络提取的深层特征获得。另一部分为全局上下文信息,主要通过作者设计的金字塔池化模块(Pyramid Pooling Module, PPM)获得。金字塔池化模块基于扩大感受野的思想设计,共使用了 4 个不同的金字塔尺度提取全局上下文信息。我们首先需要对输入图像进行 CNN 提取深层特征,这里使用的是用空洞卷积改进过的 ResNet 主干网络。随后将主干网络提取的特征输入设计的金字塔池化模块,得到融合了多尺度上下文信息的输出特征。最后再经过一个卷积层将输出特征转化为代表每个像素预测结果的得分图,其中PSPNet模型的详细介绍可见下一章节。
3、PSPNet介绍
PSPNet(Pyramid Scene Parsing Network)模型的提出是因为基于FCN的模型的主要问题是缺乏合适的策略来利用全局场景中的类别线索分割结果不够精细并且没有考虑上下文,即FCN模型注重的是图像的分辨率恢复问题,而PSPNet模型即是关注考虑上下文,获得图像的全局的视野。PSPNet模型主要是通过利用不同大小的池化来增大感受野的(Receptive Field),通过增大感受视野从而达到考虑上下文信息的目的。
在PSPNet中,它提出了一个金字塔模块(Pyramid Pooling),它是为了进一步减少不同子区域间上下文信息的丢失,包含不同尺度、不同子区域间的信息可以在深层神经网络的最终层特征图上构造全局场景先验信息,金字塔模块的结构示意图可见如下。其中Pyramid Pooling主要是进行以下操作。
① 将输入为 NCHW 特征图变成4个 HW 不同的特征图(1x1、2x2、3x3、6x6);
② 通过 1x1 的卷积给4个不同的特征图进行降维;
③ 将4个不同的特征图通过上采样变为输入特征图大小;
④ 将输入特征图和4个经过上采样后的特征图进行拼接。

图3-1 Pyramid Pooling结构图
我们将特征提取的卷积神经网络部分与其他的全连接部分和金字塔模块(Pyramid Pooling)进行结合,就是本文所使用的PSPNet模型的结构,具体模型结构可见下图。

图3-2 PSPNet模型结构图
4、数据介绍
人体解析任务是将在图像中捕获的人分割成多个语义上一致的区域,例如身体部位和衣物,而身体部位可以分为左臂、右臂、左腿和右腿等,衣物可以分为帽子、头发、手套、太阳镜、上衣、连衣裙、外套、袜子、裤子、连身裤、围巾和裙子等。而一般相关的语义分割数据集,还会给出一个图像背景的标签,即图像前后景中的后景。例如可见下图(图片来自于《Deep Human Parsing with Active Template Regression》),很清楚且完整的给出人体解析中的一般的分割种类,包含了人体部位与衣物的种类。

图4-1人体解析分割种类示意图
目前公开且实验较多的人体解析数据集一般为下表中的数据集,具体可见如下表。
表4-1人体解析数据集
| 数据集 | 人数/张 | 图像总数 | 分割种类 |
| Fashionista | 1 | 685 | 56 |
| Person-Part | 2.2 | 3533 | 7 |
| ATR | 1 | 17700 | 18 |
| LIP | 1 | 50462 | 20 |
| MHP | 3 | 4980 | 19 |
| CIHP | 3.4 | 38,280 | 20 |
其中,人数/张指的是每张图片中,一般含有的人数个数,而分割种类指的是图片中可以分割种类的类数,比如人的左手与右手可以作为两个分割种类。
本文所使用的数据集是上表中的LIP数据集,它发布于 2017 年,是目前人体解析任务中规模最大的数据集,共计包含 50462 张图像,20 个类别。LIP 广泛取自各种场景,且包含各种丰富的人体姿态、拍摄视角以及遮挡条件。因此 LIP 数据集应用场景更普遍且更具挑战性。图片数据中一共有20个语义分割种类,分别是:标签: 0.背景 1.帽子 2.头发 3.手套 4.太阳镜 5.上衣 6.连衣裙 7.外套 8.袜子 9.裤子 10.连身裤 11.围巾 12.裙子 13.面对 14.左臂 15.右臂 16.左腿 17.右腿 18.左脚鞋 19.右脚鞋。在论文《Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing》中,它提到ATR数据集中的图像大小固定,仅包含户外站立的人实例;Person-Part数据集中的图像也具有较低的可扩展性,仅包含6个粗标签;LIP数据集中的图像具有较高的外观变异性和复杂性。数据集图片对比可见下图(图片来自于论文)。

图4-2 多种数据集对比
我们下载得到的数据集一共分类两个文件夹,其中一个为原图文件夹,一个为分割图文件夹,两个文件夹的部分图片可见下图。其中,我们原图文件夹中的图片尺寸大小与图片名字均与分割图片中的一一对应,图片尺寸大小都是相同的,但是原图文件中的图片格式均为JPG,而分割文件夹中的图片都是PNG的图片格式。

图4-3原图文件夹

图4-4分割图文件夹
我们单独将同一组原图与分割图片提出来对比,可见下图,左边的为数据集图片原图,右边的图片为数据集图片的分割图片(稍微暗),我们仔细查看还是可以看得出来右边的图片是左边图片进行人体部位和衣物进行分割的图片,有着人体多个部位和衣物的轮毂与不同着色的区域。


图4-5原图与分割图对比
我们使用Python定义图片读取与显示的函数,对图片数据进行读取与显示,我们设置让不同部位之间的颜色变得更加显著,可以更加清晰查看数据原图与分割图片之间的联系,详情可见下图所示。我们可以看到在该图中,只有背景、头发、人脸、连衣裙、左手、右手、左腿、右腿、左以及右鞋10个类别标签。

图4-6原图与分割图对比(显著对比)
5、设计实验
5.1实验环境
AI Studio是基于百度深度学习平台飞桨的人工智能学习与实训社区,提供在线编程环境、免费GPU算力、海量开源算法和开放数据,帮助开发者快速创建和部署模型。本文用到了一个框架:PaddlePaddle,PaddlePaddle是百度研发的开源开放的深度学习平台,有全面的官方支持的工业级应用模型,涵盖自然语言处理、计算机视觉、推荐引擎等多个领域,并开放多个领先的预训练中文模型。PaddlePaddle同时支持稠密参数和稀疏参数场景的大规模深度学习并行训练,支持千亿规模参数、数百个几点的高效并行训练,也可提供深度学习并行技术的深度学习框架。
本次实验的环境配置可见下表。
表5-1环境配置
| 软/硬件 | 版本信息 |
| 操作系统 | Windows 10专业版 |
| 笔记本 | 飞行堡垒七 |
| 编程语言 | Python3.7 |
| 框架版本 | PaddlePaddle 2.0.2 |
| 运行平台 | AI studio的高级版 网址:aistudio.baidu.com |
| 运行配置 | CPU:2核 RAM:16GB GPU:v100 显存:16GB 磁盘:100GB |
| 其他依赖库 | Paddle、Numpy、Cv2 |
| 安装PaddlePaddle :python -m pip install paddlepaddle-gpu==2.2.1 -i https://mirror.baidu.com/pypi/simple | |
5.2数据增强
精确的人体解析模型需要具备强大的语义特征学习能力,同时拥有更好的鲁棒性,并能够有效的应对人体部位遮挡、姿态变化、拍摄角度、图片颜色纹理等因素带来的挑战,所以在本文的实验中我们对原始数据以及分割图片数据进行数据增强的处理,数据集增强主要是为了减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景,满足人体解析模型的需求。
数据增强可以分为,有监督的数据增强和无监督的数据增强方法,其中有监督的数据增强又可以分为单样本数据增强和多样本数据增强方法,无监督的数据增强分为生成新的数据和学习增强策略两个方向。有监督数据增强,即采用预设的数据变换规则,在已有数据的基础上进行数据的扩增。它包含单样本数据增强和多样本数据增强。其中单样本又包括几何操作类,颜色变换类等。几何变换类即对图像进行几何变换,包括翻转、旋转、移位、裁剪、变形、缩放等各类操作,一般情况下翻转和旋转不改变图像的大小,而裁剪会改变图像的大小。
本文实验图片数据是面对语义分割任务,所以所有图像和标签要进行相同的数据增强操作,主要是进行图片旋转、图片裁剪和填充的处理,具体可见下下图,上述提到裁剪会改变图像的大小,下图的最后一行很明显看到数据增强前后的图像尺寸不一致。



图5-1数据增强前后图片
5.3评估指标
人体解析常用的评价指标有三种分别是:像素准确率(Pixel Accuracy,PA)、平均像素准确率(Mean Pixel Accuracy,MPA)和平均交并比(Mean Intersection over Union,MIoU)。
像素准确率 PA是指在图像中正确分类的像素数量占总像素数量的比值,数学表达式可见如下
PA=1npii1n1npij#1

其中pii

表示第i种类别被正确分类为第i种类别的像素数量,pij

表示第i种类别被分类为第j种类别的像素数量,n为类别总数。
平均像素准确率 MPA 是基于像素准确率的基础上综合各种类的评价指标,其表示图像中所有类别的像素精度的平均值,其数学表达式可见如下
MPA=1n1npii1npii1n1npij#2

平均交并比 MIoU,即每一种类别的预测区域与标记区域的交集比上预测区域与标记区域的并集,然后综合所有类别取平均值。数学表达式可见如下
IoU=TPTP+TN+FN#3

其中 TP 表示分类结果为真的正样本,说明被预测的为正样本,预测的结果为真。TN 表
示分类结果为真的负样本,说明被预测为负样本,预测的结果真。FN 表示假的负值,说明被预测为负样本,但预测的结果为假。下图可以直观的解释,预测集合和标记集合的交集为 TP,标记集合的补集为 FN,预测集合的补集为 TN。

图5-2交互图
MIoU 则为图像所有类别的 IoU

的均值,数学表达式可见如下
MIoU=1ni=1nIoUi#4

其中i为第i个类别,n为类别总数。本文实验所使用到到模型评估指标正是上述所提到的MioU指标。
5.4模型构建
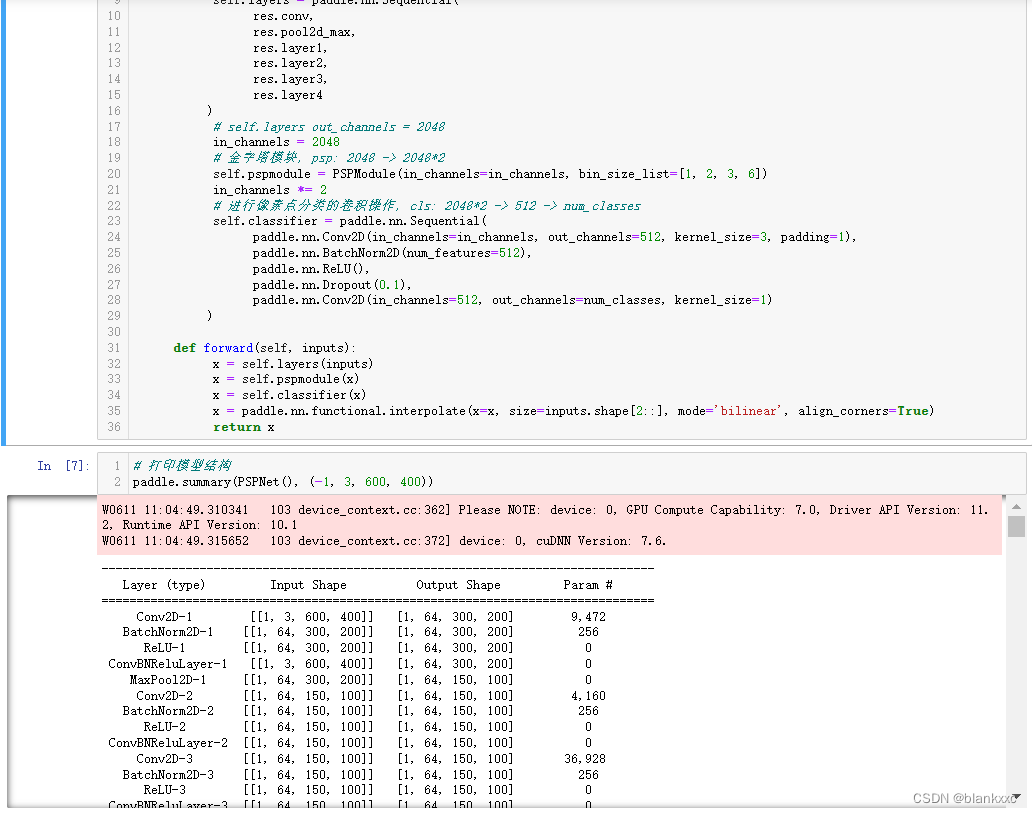
本文的PSPNet模型的特征提取的卷积神经网络部分选择使用空洞卷积改进过的 ResNet50 主干网络模型,其大致结构可见下图。它包括了卷积核大小为7x7,卷积核通道数为64,步长为2的卷积操作、池化核大小为3x3,步长为2的最大池化层、16个 BottleneckBlock (4种,个数分别为3,4,6,3)、全局平均池化和全连接层。

图5-3 ResNet50结构图
PSPNet模型的特征提取由上述经过空洞卷积的ResNet50模型负责,我们还需要定义实现金字塔模块(Pyramid Pooling),将两部分进行结合得到完整的PSPNet模型。由于本文所使用的图像数据是分割种类为20分类的语义图片,所以我们还需要将模型的分类类别数目设置为20。模型的整个参数情况可见下表。
表5-2 模型参数
| 模型可训练参数 | 模型不可训练参数 | 模型总参数 | 模型大小(MB) |
| 46,562,964 | 116,480 | 46,679,444 | 4101.02 |
5.5实验结果
本文实验是基于AI studio平台实现的,我们使用上述构建的PSPNet模型对17706张原始图片和17706张分割图片进行训练和验证,我们设置20分类类别,使用Adam优化器,学习率设置为0.001,使用CrossEntropyLoss损失函数,使用MioU作为模型的分割评估指标,设置Batch_size为4,模型的迭代次数Epochs为45,需要花费27个小时。
模型的训练效果可见下图,其中模型训练的训练过程中,验证集得到的最高MioU为74.3%,效果较好。


图5-4 模型训练效果
我们直接查看模型预测到的效果图与真实标签的图片进行对比分析,具体详情可见下图。通过第一行图片的对比,我们可以看到label标签的图片在下半身的脚部分打标签的效果不好,腿区域的分割标签不完整,可是右边预测得到的图片完美的将腿部分的分割效果预测出来了,这归功于我们上述提到PSPNet模型利用不同大小的池化增大自身的增大感受野,来获得上下文的信息。但是第一行图片的预测效果没有把人的手臂部分进行分割出来,这有可能是因为图中人手臂的颜色与衣服的太相似了。在第二行图片中,模型预测得到的分割图片与真实的分割类别标签图片几乎一致。而在第三行图片中人物真实的分割图片在人物的左肩上多描绘了一部分,可是模型预测得到的分割图片中完美的把人体左肩的轮廓进行分割出来了,说明模型的训练效果还是非常好的,观察细微的话我们还可以发现模型还把人物穿的鞋子的鞋带进行分割出来了,只是分割的效果并不完整。



图5-5 模型测试效果
我们选择一幅来自网上的图片使用模型进行人体解析,来进一步测试模型的训练效果,具体可见下图。图片中的人物和衣物被完好得分割出来了。

图5-6 模型测试效果
但是我们使用模型预测人体部位和衣物的颜色非常相似的图片时,模型的人体解析分割图片的效果就不太好了,可见下图。我们可以看到右边预测的分割图片在人物的膝盖下有一部分的分割错误的区域,对比原图我们可以发现该区域是图像中人物的影子,它的颜色与人物中裙子的颜色非常相似。

图5-7 模型测试效果
我们再对比一张本地保存的图片,在该图片中使用模型预测得到分割图片效果非常差,具体可见下图,很大的一个原因可能是因为图片中的相邻的人体部位和衣物之间的像素大小非常接近。

图5-8 模型测试效果
6、结论
PSPNet的提出,是因为有些的分割错误就是因为卷积的感受野远远小于理论值,没有利用全局信息,因此该作者提出了金字塔池化来聚合不同尺度的信息,实现更好的分类效果。即利用池化操作获得不同尺寸的特征图,再经过卷积、上采样等操作,最终聚合相关信息。PSPNet模型是属于图像语义分割中基于上下文信息提取的方法,此类方法的目标在于捕捉丰富的上下文关系,从而更好的解决多尺度的目标预测。
目前语义分割主要针对如何恢复原有的分辨率、如何尽可能的增大感受野和如何处理多尺度问题等问题进行研究,FCN模型就是主要针对恢复图像原油的分辨率,而本文使用的PSPNet主要是实现增大感受野和处理多尺度的功能。
本文基于LIP数据集,使用经过空洞卷积处理过的ResNet50模型作为特征提取模型,实现PSPNet模型,使用该模型对LIP数据集进行训练以及预测分割,模型达到的MIoU指标达到了74.3%。我们使用训练得到的PSPNet模型来自网上的图片进行语义分割,取得的效果也较好,但因图片中相邻的人体部位与衣物之间的像素值大小接近,会容易导致模型分割得到的人体解析图片效果会比较差。
7、参考文献
[1] 刘尚旺,张杨杨,蔡同波,等. 基于改进PSPnet的无人机农田场景语义分割[J]. 灌溉排水学报,2022,41(4):101-108. DOI:10.13522/j.cnki.ggps.2021406.
[2] 高丹,陈建英,谢盈. A-PSPNet:一种融合注意力机制的PSPNet图像语义分割模型[J]. 中国电子科学研究院学报,2020,15(6):518-523. DOI:10.3969/j.issn.1673-5692.2020.06.005.
[3] 王嘉,张楠,孟凡云,等. 基于金字塔场景分析网络改进的语义分割算法[J]. 计算机工程与应用,2021,57(19):220-227. DOI:10.3778/j.issn.1002-8331.2006-0366.
[4] 罗文劼,倪鹏,张涵,等. 多阶段双路人体解析网络[J]. 计算机工程与应用,2020,56(20):146-151. DOI:10.3778/j.issn.1002-8331.1908-0061.
[5] 邵杰,黄茜,曹坤涛. 基于深度学习的人体解析研究综述[J]. 电子科技大学学报,2019,48(5):641-654. DOI:10.3969/j.issn.1001-0548.2019.05.001.
[6] 黄茜. 基于深度学习的人体解析[D]. 四川:电子科技大学,2021.
[7] 李世超. 基于深度学习的人体解析[D]. 四川:电子科技大学,2021.
[8] 赵翰琳. 基于深度学习的人体解析[D]. 山东:山东大学,2020.
[9] 卢煜坤. 姿态估计与人体解析联合学习[D]. 辽宁:大连理工大学,2020.
[10] 倪鹏. 基于深度卷积神经网络的人体解析方法研究[D]. 河北:河北大学,2020.
[11] 李原,李燕君,刘进超,等. 基于改进Res-UNet网络的钢铁表面缺陷图像分割研究[J]. 电子与信息学报,2022,44(5):1511-1520. DOI:10.11999/JEIT211350.
[12] 赵先琼,邓志强,邓朝晖,等. 基于深度学习的TBM密集岩碴片图像分割[J]. 哈尔滨工程大学学报,2022,43(3):399-406. DOI:10.11990/jheu.202010042.
[13] 黄禹康,熊凌,刘洋,等. 基于改进U-Net网络的吹氩图像分割方法[J]. 高技术通讯,2022,32(1):50-56. DOI:10.3772/j.issn.1002-0470.2022.01.006.
[14] 李鸿翔,王晓丽,阳春华,等. 基于GAN–UNet的矿石图像分割方法[J]. 控制理论与应用,2021,38(9):1393-1398. DOI:10.7641/CTA.2021.00558.
[15] 何志明. 图像分割综述[J]. 山东工业技术,2016(22):226. DOI:10.16640/j.cnki.37-1222/t.2016.22.197.
[16] 赵春燕,闫长青,时秀芳. 图像分割综述[J]. 中国科技信息,2009(1):42-43. DOI:10.3969/j.issn.1001-8972.2009.01.023.
[17] 辛月兰. 基于图割的图像分割综述[J]. 微型电脑应用,2012,28(9):1-5,8. DOI:10.3969/j.issn.1007-757X.2012.09.001.
[18] 黄旭,张世义,李军. 图像分割技术研究综述[J]. 装备机械,2021(2):6-9. DOI:10.3969/j.issn.1662-0555.2021.02.002.
[19] J. Long, E. Shelhamer, T. Darrell. Fully convolutional networks for semantic segmentation[C].Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA,USA, 2015, 3431-3440
8、附录
1、代码,建议直接点击HTML文件的代码,可以直接查看。在code and data文件夹中。

2、数据

3、部分参考文献

4、绘制模型结构图的Visio文件,论文中的全部模型结构图均使用Visio进行绘制,论文中的图片格式为emf格式。


















 3681
3681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









