






需要完整代码和论文私信我

摘 要
在施工场景中,正确有效的检测工人佩戴安全帽是工地安全重要的一环。基于人工检测安全帽佩戴情况,既耗时耗力,监管效率也不高。为了降低因为安全帽佩戴问题导致的施工问题,本文采用目标检测算法中的YOLOv3算法进行安全帽佩戴检测,另外YOLOv3的骨干网络DarkNet53在ImageNet的图像分类任务中取得了很好的效果,因此Darknet53也将作为特征提取网络,辅佐实现安全帽佩戴检测。
关键词:安全帽佩戴检测;目标检测;YOLOv3;特征提取;DarkNet53
Abstract
In the construction scene, it is an important part of the construction site safety to correctly and effectively check that workers wear safety helmets. It is time-consuming and labor-intensive, and the supervision efficiency is not high based on manual inspection of helmet wearing. In order to reduce the construction problems caused by helmet wearing problems, this paper uses YOLOv3 algorithm among the target detection algorithms to detect helmet wearing. In addition, the backbone network of YOLOv3, DarkNet53, has achieved good results in ImageNet's image classification task, so Darknet53 will also be used as a feature extraction network to help realize helmet wearing detection.
Keywords: safety helmet wearing test; Target detection; YOLOv3; Feature extraction; DarkNet53
1背景及意义............................................................................................ 1
2基于深度学习的目标检测......................................................................... 1
3 基于DarkNet53的YOLOv3模型............................................................ 2
3.1特征提取模型................................................................................ 2
3.2 YOLOv3模型................................................................................ 3
3.3 YOLOv3的迁移学习...................................................................... 5
4实验...................................................................................................... 6
4.1数据集介绍.......................................................................................... 6
4.2实验过程............................................................................................. 6
4.2.1环境配置.................................................................................... 6
4.2.2数据预处理................................................................................. 7
4.2.3模型训练.................................................................................... 7
4.2.4评估标准.................................................................................... 7
4.2.5实验结果.................................................................................... 8
5可视化界面........................................................................................... 10
6总结.................................................................................................... 11
参考文献................................................................................................. 11
1背景及意义
随着社会的发展,安全问题越来越受到公众的关注。佩戴安全帽可以减少高空坠物对头部的伤害,保护施工人员的人身安全。安全帽的佩戴是安全施工的重要组成部分。现阶段安全帽检测的主要方法仍是人工巡检,费时费力,检测效率较低。近年来,随着计算机视觉的发展,无人值守的智能安全帽检测方法因其成本低、效率高而受到越来越多的关注。施工人员戴安全帽是安全生产的重要组成部分。为保证工人的生命安全,克服传统人工检查费时的缺点,采用无人值守的智能安全帽检测方法是未来的发展趋势。
深度学习以其较高的精度和鲁棒性成为目标检测的研究热点之一。目前,基于深度学习的目标检测算法多在图像上放置不同大小的锚帧,通过回归和分类锚帧实现目标检测。回归框主要分为两类:两阶段和一阶段。Faster RCNN和Mask RCNN两级检测器通过RPN过滤掉区域提案后,进一步提取特征,对回归框进行微调和分类,用于目标检测。
安全帽佩戴检测是计算机视觉在工业安全领域应用的一个典型场景。本文使用PaddleX进行yolov3_ Darknet53迁移学习训练。YOLOv3算法使用的骨干网为Darknet53。在ImageNet的图像分类任务中,Darknet53取得了较好的结果。因此本文采用Darknet53作为特征提取网络,实现Yolov3的目标检测,并将其用于智能安全帽检测实验。
2基于深度学习的目标检测
基于深度学习的目标检测算法主要分为两类:一类是以RCNN系列算法为代表的、“两步走”的基于候选区域的目标检测算法,一类是以YOLO、SSD为代表的、“一步走”的基于回归的目标检测算法。
基于候选区域的目标检测算法从理论上来讲比基于回归的目标检测算法精准度更高,以Faster-RCNN为代表,基于候选区域的目标检测算法由卷积层(convolutionlayers)、区域候选网络(Region Proposal Networks,RPN)、感兴趣区域池化层(ROI Pooling)、分类层(Classification)四部分组成。卷积层由一组基础的卷积层、激活层和池化层组成,用来提取特征,产生后续所需要的特征图;区域候选网络主要用于生成区域候选框;感兴趣区域池化层负责收集特征图和区域候选框,将信息综合起来进行后续类别的判断;最后一层分类层,根据区域候选网络综合的信息进行目标类别的判定,同时修正候选框的位置。总的来说,Faster-RCNN首先采用RPN网络产生候选框,之后再对候选框进行位置的修定和目标的分类。由于其复杂的网络构成,检测速度相对来说比较慢一点。
基于回归的目标检测算法真正意义上实现了端到端的训练,以YOLO为代表,基于回归的目标检测算法一次性完成目标的分类与定位,整个网络结构只由卷积层组成,输入的图像只经过一次网络,所以基于回归的目标检测算法更快。改进版的YOLOv3, 不论在速度上还是在精度上都到达了较先进的水平。
3 基于DarkNet53的YOLOv3模型
3.1特征提取模型
基于卷积的深度神经网络模型有许多,比如AlexNet、VGG、GoogleNet、ResNet以及 DenseNet等模型。为避免模型优化中网络加深出现退化的问题,YOLOv3的作者借鉴了残差块(Resial block)的思想形成了Darknet53网络结构。而本文选择的也是DarkNet系列的DarkNet53模型作为特征提取模型。Darknet 深度学习框架是由 Joseph Redmon 提出的一个用 C语言和 CUDA编写的开源神经网络框架,Joseph Redmon即是YOLO之父。DarkNet支持CPU 和 GPU(CUDA / cuDNN)计 算 ,且 支 持 OpenCV 和OpenMP,同时框架结构清晰,源代码查看、修改方便。另一方面,Darknet 拥有友好的 Python 接口,通过调用 Python 库函数,能够使用 Python 直接对训练好的weight 格式的模型进行调用。基于上述 Darknet 框架的优点 ,选 择Darknet53作为本次实验的深度学习特征提取模型,其网络结构如图3-1所示。
DarkNet53该网络包括了 5 个 Stage 单元(每个单元中都包含有重复结构的残差单元,分别重复重复1 次、2 次、8 次、8 次、4 次),共 53 层,网络结构相对复杂。该网络模型结合了深度残差网络 ResNet 和DarkNet19 的特点,分类精确度可与最先进的分类器相媲美,而且浮点运算更少,速度更快。例如 Dark⁃Net53 比 ResNet101 性能更好,而且分类速度更快,这主要是因为 ResNet101 的层数太多,从而增加了运算成本。不过在没有 GPU 的低配备的设备中运行,由于模型参数较大,该网络运行速度与轻量型网络相比还是比较慢。

图3-1 Darknet53网络结构图
3.2 YOLOv3模型
YOLOv3网络由三部分组成,特征提取网络Darknet53和多尺度预测FPN及检测网络YOLO Head。其中Darknet53没有使用池化层,而是借鉴残差网络(residual network,ResNet)的结构形成跳跃连接对输入的图片特征提取,YOLOv3算法的卷积块大多采用卷积层(convolution layers)后跟批标准化层(batch normalization,BN)和激活函数(Leaky ReLu)的模式来加速收敛避免梯度消失。输入图像经过一个普通卷积模块(Conv2D+BN+Leaky Relu)后,使用步长为2大小为3×3卷积进行5次下采样,如图3-2部分所示,保留每次卷积后的layer,且分别在每一次下采样后使用1×1和3×3大小的卷积核再次进行卷积操作。将此次连续卷积后的结果和保留的layer相加。5次下采样后图片的高和宽不断压缩变成13×13,通道数不断扩张变成1024×1024,这5次下采样使用残差块的结构堆叠起来,残差块结构如图3-2所示,每个残差块的拼接次数依次是1、2、8、8、4。
为了检测出不同尺寸的物体,YOLOv3借鉴SSD的特征金字塔(feature pyramid network,FPN)结构进行多尺度检测,选取后面3个32倍、16倍、8倍(13×13、26×26、52×52)的特征层预测物体,为了更好的利用深层语义特征信息,将最后一个特征尺度(13×13)用线性插值的方式上采样与前面一个特征层进行拼接,这样可以在较低层特征上获得深层特征的信息检测尺寸较小的物体,保证检测的效果。依次如此,直到和52×52大小的特征层拼接。YOLOv3是一个经典、高效的网络,在目标检测领域有良好的表现力。

图3-2 YOLOv3网络结构
另外,CBL指的是YOLOv3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成、Res unit指的是借鉴Resnet网络中的残差结构,让网络可以构建的更深、ResX是由一个CBL和X个残差组件构成,是YOLOv3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。其中上图还涉及到了张量拼接和张量相加的情况,张量拼接会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。每个ResX中包含1+2×X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2×1)+(1+2×2)+(1+2×8)+(1+2×8)+(1+2×4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测YOLOv3中,去掉FC层,不过为了方便称呼,仍然把YOLOv3的主干网络叫做Darknet53结构。
我们一般将YOLOv3模型分开三个部分,Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络、Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层、Head:对图像特征进行预测,生成边界框并预测类别,如下图3-3所示。其中有特征输入、特征提取、NECK以及预测部分。Neck是目标检测框架中承上启下的关键环节。它对Backbone提取到的重要特征,进行再加工及合理利用,有利于下一步head的具体任务学习,如分类、回归等常见的任务。

图3-3 YOLOv3结构组成
Neck的选择有许多,如图3-4所示,而在YOLOv3中选择的是上下采样,使用的是SSD的思想。

图3-4 目标检测中Neck选择
3.3 YOLOv3的迁移学习
如果将每一个网络从头到尾进行训练,直到其能应用于实际工程任务,那么有两个条件是必要的。一是大量的训练数据集,二是有不进入、反向传播的验证集。前者是训练网络性能,得到更深层、有效的图像特征;后者是为了防止过拟合现象,避免出现训练集精度变高而实际任务精度变低的情况。
YOLOv3是全卷积网络,用于特征提取部分的卷积层更需要大量的样本训练,才能提取到更易于分类的深层特征。为了将YOLOv3网络应用于安全帽识别任务,第一步就是得到上述两类数据。本次实验采用的是公开的标注好的安全帽Helmet Detection数据集,共5000张,同时采用到迁移学习的方法训练卷积神经网络。
由于YOLOv3已经Image- Net上试验过千分类任务,因此YOLOv3网络的每个节点,实际上均已经过参数训练。因此,可以将ImageNet的分类数据集作为源域。首先,在YOLOv3的每个参数点载入这些参数。这是因为使用ImageNet数据集训练完分类网络后,卷积核的权值经过训练,已经具备了可以提取泛化特征的能力。然后,使用模式识别的微调的方式,冻结网络层的绝大部分,只对最后几层(尤其是最后用于将特征向量转化成概率输出softmax层)启用反向传播,进行节点参数的数据更新。这是为了让最后几层的深度卷积层提取特定任务下的深层特征,从而使得YOLOv3可以应用于本次任务。对于本次实验而言,所希望提取的特征信息就是安全帽以及其相关像素点的计算机视觉特征。
4实验
4.1数据集介绍
数据集来自公开的安全帽Helmet Detection数据集,总共分为两类,分别为“head”和“helmet”,其中未佩戴安全帽的人使用“head”来表示,而佩戴安全帽的人用“helmet”标记,其中包含了5000张已经标注好的规格大小都为415×416的图片以及对应的标签xml文件,xml文件中记录了对应图片的标注框的个数、边界值以及类别,即如图4-1所示。本次数据集以7:2:1比例分别划分3500张为训练集,1000张为验证集以及500张为测试集。

图4-1 标签信息
4.2实验过程
4.2.1环境配置
本次实验用的是百度飞桨提供的A100 40G的GPU服务器进行模型训练。需要配置paddlehub 1.6.2、 paddlepaddle 2.2.2 、paddlex 1.1.1的环境。
4.2.2数据预处理
对训练集和验证集的数据进行随机混合、扭曲、伸缩、裁剪、改变大小以及水平翻转等数据增强操作,最后统一进行归一化处理。
4.2.3模型训练
YOLOv3使用了DarkNet-53框架,其中实验参数使用了YOLOv3官网上提供的权重参数作为网络训练的初始化参数,并进行微调使的网络检测效果达到最优,部分实验参数设置如表4-1所示。
表4-1 神经网络参数设置表
| 参数名 | 参数值 |
| 学习率 | 0.000125 |
| 迭代次数 | 270 |
| 批次大小 | 8 |
| 学习率减小步长 | 30 |
4.2.4评估标准
在本次目标检测实验中,当IOU取值大于等于0.5时,若检测框中有一个目标,标记为TP,反之则标记为FP,当IOU取值小于0.5时,若检测框内中有一个目标,标记为FN,反之则标记为TN。由这4项可求得训练样本的召回率(Recall)与准确率(Precision),其中计算公式为:
Precision=TPTP+FP=TPall detections

(4.1)
Precision=TPTP+FN=TPall ground_truths

(4.2)
通过设置目标的置信度阈值,得到数组满足条件的Precision值和Recall值。由Precision值和Recall值组合而成的准确率-召回率曲线(即P-R曲线)的面积,代表训练样本中各类目标的平均精度(AP),mAP则指所有类别的平均精度求和除以类别数目,目标检测网络的检测效果常以mAP作为主要的评估指标,公式为:
AP=111r∈{0,0.1,...,1}ρinterp(r)

(4.3)
其中,
ρinterp(r)=maxr:r≥rρ(r)

(4.4)
mAP=1ni=0nAPI

(4.5)
4.2.5实验结果
在训练了11个小时,迭代了270个epoch之后,训练趋于稳定,所得到的损失函数走势图以及mAP走势图分别如图4-2和图4-3所示。loss从20072减小至6.3303,mAP从57.866增加至60.484。

图4-2 损失函数曲线图

图4-3 mAP曲线图
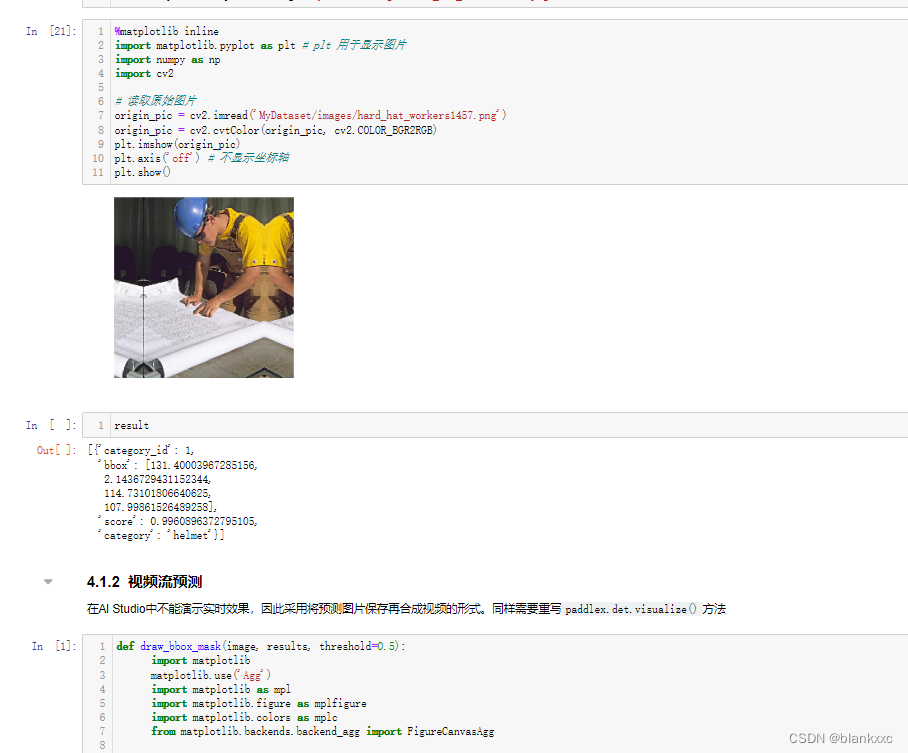
检测效果分为单张图片预测和视频流预测,单张图片预测效果如图4-4所示。




图4-4 单张图片检测效果图
视频流预测其实也就是将视频的每一帧进行提取,同时进行预测,并存储为单张图片,如图4-5所示,再将这一张张预测完的图片重新合成视频,从而达到对视频流数据的一个检测效果。对视频的检测测效果如图4-6所示。

图4-5 视频分解成图片并预测


图4-6 视频检测效果
5可视化界面
本次可视化界面用到PyQt5库来搭建。PyQt是一个用于创建GUI应用程序跨平台工具包,它将Python与Qt库融为一体。也就是说,PyQt允许使用Python语言调用Qt库中API。
由于目前最新的PyQt版本是5.X,所以习惯上称PyQt为PyQt5。如下图5-1是交互界面。

图5-1 GUI交互界面
点击”选择图片”按钮,加载要检测的图片。

点击“检测”按钮,即可对加载的图片进行预测并显示在结果图,以及显示检测耗时。

6总结
本次实验主要通过YOLOv3的目标检测算法来检查施工人员在施工过程中安全帽的佩戴与否。在数据集的处理上,利用到了数据增强,包括随机水平翻转、随机伸缩和随机截取等。在网络模型的构建上,主要用DarkNet53作为特征提取模型来提取图片特征,同时也利用YOLOv3在Image- Net完成过的大型的多分类任务,因此可以利用在ImageNet数据集的预训练模型来对本次安全帽检测作一个迁移学习,通过微调已经具备提取泛化特征能力的模型,达到更快地学习到安全帽特征的能力。在模型上,主要借助于百度飞桨提供的A100 40G的GPU环境进行实现,以及利用paddlepaddle深度学习框架进行模型的构建和训练。在模型评估上则是用到了mAP指标来评价模型的优劣,经过11个多小时的训练,mAP最终达到60.48。在检测效果上则是分为单张图片检测和视频流检测,都能够较好的检测出人是否有佩戴好安全帽。最后则利用pyqt5搭建了GUI界面实现一个简单的人机交互界面。
参考文献
[1]唐勇,巫思敏.YOLOv3在安全帽佩戴检测中的应用[J].现代信息科技,2021,5(23):88-91+95.DOI:10.19850/j.cnki.2096-4706.2021.23.023.
[2]张成. 基于深度学习的安全帽检测系统的设计与实现[D].河北科技大学,2020.DOI:10.27107/d.cnki.ghbku.2020.000501.
[3]张占康.YOLOV3算法的安全帽检测[J].电子世界,2021(16):37-38.DOI:10.19353/j.cnki.dzsj.2021.16.017.
[4]王珩.基于YOLOv3的安全帽佩戴检测方法研究[J].自动化仪表,2021,42(02):63-67.DOI:10.16086/j.cnki.issn1000-0380.2020040064.
[5]梁思成,徐志明,宋毅.YoloV3算法在安全帽检测中的应用[J].智能计算机与应用,2020,10(09):1-5.
[6]黄林泉,蒋良卫,高晓峰.改进YOLOv3的实时性视频安全帽佩戴检测算法[J].现代计算机,2020(30):32-38+43.
[7]朱晓春,王欣,马国力,陈子涛,吴裕祥.改进YOLO v3算法的安全帽佩戴检测[J].南京工程学院学报(自然科学版),2020,18(04):23-26.DOI:10.13960/j.issn.1672-2558.2020.04.005.
[8]马小陆,王明明,王兵.YOLOv3在安全帽佩戴检测中的应用研究[J].河北工程大学学报(自然科学版),2020,37(04):78-86.
[9]郝存明,朱继军,张伟平.基于深度学习的安全帽检测方法研究[J].河北省科学院学报,2018,35(03):7-11.DOI:10.16191/j.cnki.hbkx.2018.03.002.
[10]林俊,党伟超,潘理虎,白尚旺,张睿.基于YOLO的安全帽检测方法[J].计算机系统应用,2019,28(09):174-179.DOI:10.15888/j.cnki.csa.007065.















 3287
3287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









