







查询转换是一组专注于重写和/或修改问题以进行检索的方法
本篇介绍5种Query Transformations的方法
- Multi Query(part-1)
- RAG-Fusion(part-1)
- Decompositon(part-2)
- Step back(part-2)
- HyDE(part-2)
-
 准备工作
准备工作
首先我们要把环境配好,参考这篇https://blog.csdn.net/weixin_47059517/article/details/139845420
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = '<https://api.smith.langchain.com>'
os.environ['LANGCHAIN_API_KEY'] = '<填你的lang-chain的API-Key>'
os.environ["OPENAI_API_BASE"] = '<填你的openai的API>'
os.environ['OPENAI_API_KEY'] = '<填你的openai的API-Key>'
Index
将上一篇笔记的index环节(加载数据集、切片、索引)加进来,这里就不做解释啦,详细看之前的笔记
#### INDEXING ####
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("<https://lilianweng.github.io/posts/2023-06-23-agent/>",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings(model="text-embedding-3-large"))
retriever = vectorstore.as_retriever()
Multi Query
工作流:
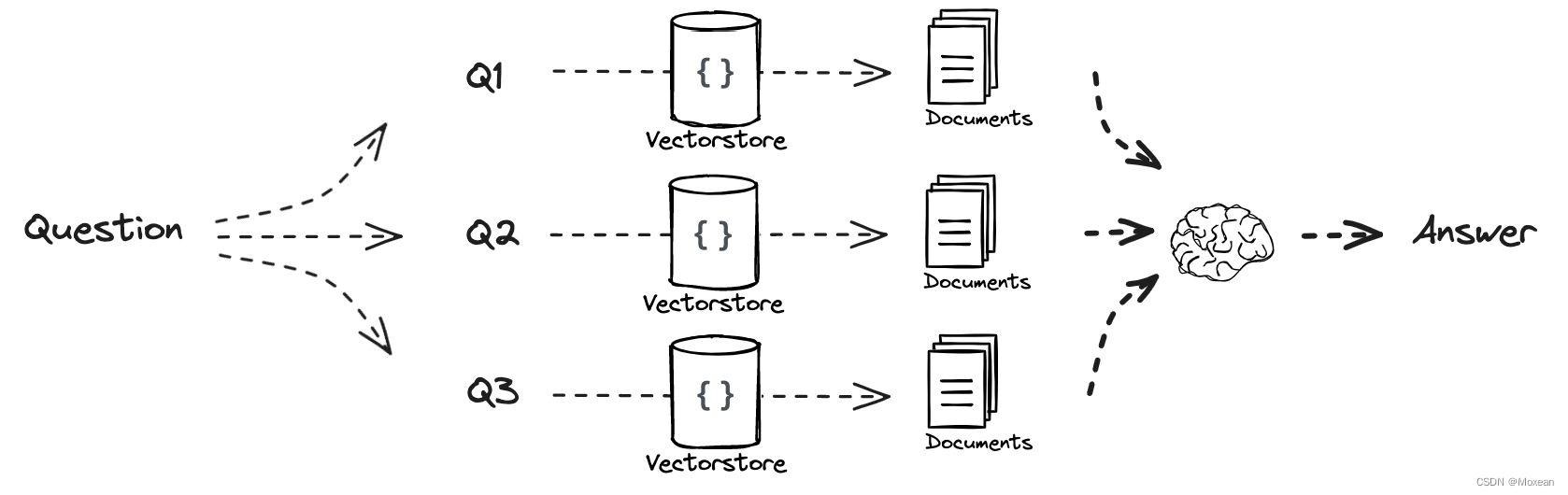
Prompt
Step one
从不同的方面理解用户的问题,其中template为:‘’你是一个人工智能语言模型助理。您的任务是生成给定用户问题的五个不同版本,以从矢量数据库中检索相关文档。通过对用户问题生成多个视角,您的目标是帮助用户克服基于距离的相似性搜索的一些限制。提供这些用换行符分隔的备选问题。原始问题:{question}‘’
from langchain.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\\n"))
)
Step two
制作retrieval_chain并将question注入获取相关文档,其中get_unique_union()将5个问题得到的文档去重
from langchain.load import dumps, loads
def get_unique_union(documents):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
docs
Step three
最后,将获得的文档整合,并注入文档和question到final_rag_chain以获得最后的答案
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
获得答案:Task decomposition for LLM agents involves breaking down complex tasks into smaller, more manageable subgoals. This process enables the LLM-powered autonomous agent system to handle intricate tasks efficiently by dividing them into steps that it can tackle sequentially or in parallel. Task decomposition methods include techniques like Chain of Thought (CoT) and Tree of Thoughts, which help transform large tasks into multiple simpler tasks or explore multiple reasoning possibilities at each step. Additionally, LLM agents can utilize task-specific instructions or human inputs to further refine the decomposition process tailored to specific domains or tasks.
RAG-Fusion
工作流:
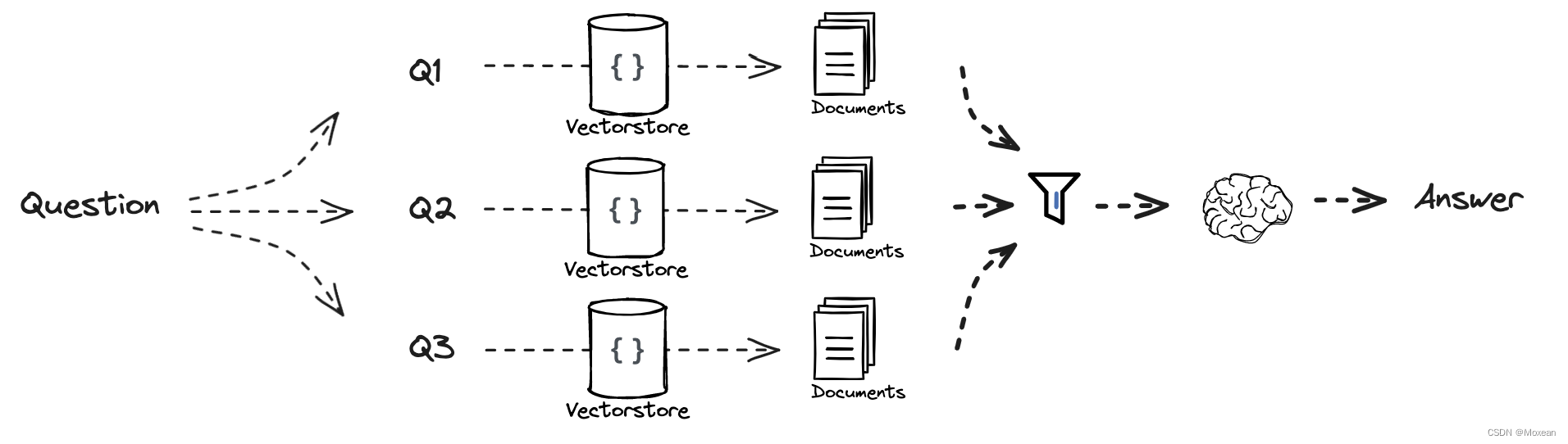
Prompt
Step one
根据问题生成多个相似的问题,其中template为:‘’您是一个有用的助手,可以根据单个输入查询生成多个搜索查询。生成多个与{question}相关的搜索查询‘’
from langchain.prompts import ChatPromptTemplate
# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \\n
Generate multiple search queries related to: {question} \\n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_rag_fusion
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\\n"))
)
Step two
制作retrieval_chain并将question注入获取相关文档,其中reciprocal_rank_fusion()将多个问题得到的文档进行评分,得到的结果重复的越多得分越高,重要性越高。
from langchain.load import dumps, loads
def reciprocal_rank_fusion(results, k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
docs = retrieval_chain_rag_fusion.invoke({"question": question})
len(docs)
Step three
最后,将获得的文档整合,并注入文档和question到final_rag_chain以获得最后的答案
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain_rag_fusion,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
得到结果:Task decomposition for LLM (large language model) agents is the process of breaking down complex tasks into smaller and simpler subtasks or steps. This allows the agent to more effectively handle and solve complex tasks by dividing them into manageable components. Task decomposition can be done using simple prompting techniques, task-specific instructions, or with human inputs.















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









