







这篇会更加详细的讲解Index&Retrieval&Generation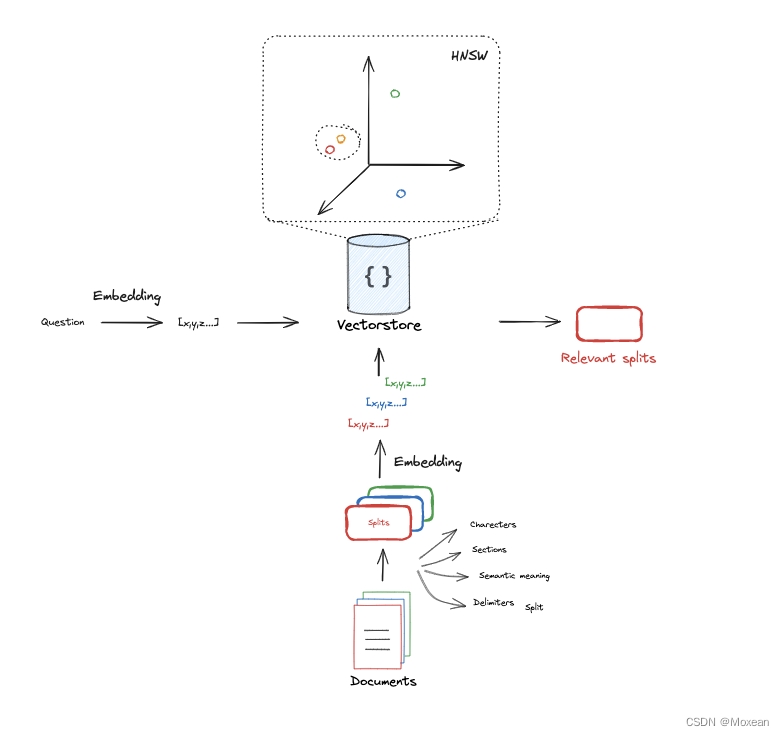
Index
索引是一种数据结构,允许高效地检索相关文档。这里使用的是向量空间模型,将文档和查询表示为向量,使用openai的text-embedding-3-large获取嵌入。然后使用cosine相似度进行检索。
TEST
Step one
首先与上一篇笔记一样,配置好环境https://blog.csdn.net/weixin_47059517/article/details/139845420
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = '<https://api.smith.langchain.com>'
os.environ['LANGCHAIN_API_KEY'] = '<填你的lang-chain的API-Key>'
os.environ["OPENAI_API_BASE"] = '<填你的openai的API>'
os.environ['OPENAI_API_KEY'] = '<填你的openai的API-Key>'
然后我们使用一个文档和question进行测试
# Documents
question = "What kinds of pets do I like?"
document = "My favorite pet is a cat."
Step two
使用Text embedding models将这两个文本转化成嵌入
from langchain_openai import OpenAIEmbeddings
embd = OpenAIEmbeddings()
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)
len(query_result)
Step three
写一个Cosine similarity函数,以实现找到最相似的嵌入
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
Indexing
Step one
加载数据集,这里使用langchain_community提供的数据
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("<https://lilianweng.github.io/posts/2023-06-23-agent/>",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
Step two
对数据集进行切片,对数据集进行切片是提高检索和生成任务性能的关键步骤。通过将大块文档分割成小片段,可以显著提升系统的响应速度、精度和处理能力,同时也有助于内存管理和并行处理。切片策略需要根据具体应用场景和数据特点进行调整,以达到最佳效果。
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
Step three
获取嵌入并建立索引
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
Retrieval
检索最相似的文档"What is Task Decomposition?"
docs = retriever.get_relevant_documents("What is Task Decomposition?")
print(docs)
得到:[Document(page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\\nComponent One: Planning#\\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\\nTask Decomposition#\\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'source': '<https://lilianweng.github.io/posts/2023-06-23-agent/>'})]
Generation
将问题结合检索到的信息来生成答案
Step one
设置prompt
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# Prompt
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
prompt
得到结果:ChatPromptTemplate(input_variables=['context', 'question'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template='Answer the question based only on the following context:\\n{context}\\n\\nQuestion: {question}\\n'))])
Step two(分解版)
LLM初始化
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
生成Chain
# Chain
chain= prompt| llm
运行Chain
# Run
chain.invoke({"context":docs,"question":"What is Task Decomposition?"})
chain
反馈的答案:AIMessage(content='Task decomposition is the process of breaking down a complicated task into smaller and simpler steps, making it more manageable for an autonomous agent to handle. This can be achieved through techniques such as Chain of Thought and Tree of Thoughts, as well as simple prompting or task-specific instructions.', response_metadata={'token_usage': {'completion_tokens': 54, 'prompt_tokens': 331, 'total_tokens': 385}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_811936bd4f', 'finish_reason': 'stop', 'logprobs': None}, id='run-ff8ff8c6-cc31-44ec-973e-6a99659129ff-0', usage_metadata={'input_tokens': 331, 'output_tokens': 54, 'total_tokens': 385})
其中content:
'Task decomposition is the process of breaking down a complicated task into smaller and simpler steps, making it more manageable for an autonomous agent to handle. This can be achieved through techniques such as Chain of Thought and Tree of Thoughts, as well as simple prompting or task-specific instructions.'
即为答案
Step three(langchain有个集成版本)
from langchain import hub
prompt_hub_rag = hub.pull("rlm/rag-prompt")
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
直接得到: 'Task decomposition is the process of breaking down a complicated task into smaller and simpler steps, making it more manageable for an autonomous agent to handle. This can be achieved through techniques such as Chain of Thought and Tree of Thoughts, as well as simple prompting or task-specific instructions.'















 6541
6541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









