






关于文本分类的调查:从浅层到深层学习
文本分类是自然语言处理中最基本和最重要的任务。由于深度学习取得了空前的成功,在过去十年中,该领域的研究激增。文献中提出了许多方法、数据集和评估指标,提出了对全面和更新调查的需求。本文通过回顾 1961 年至 2020 年最先进的方法填补了空白,重点关注从浅层到深度学习的模型。我们根据涉及的文本和用于特征提取和分类的模型创建文本分类的分类法。然后我们详细讨论这些类别中的每一个,处理支持预测测试的技术发展和基准数据集。本次调查还提供了不同技术之间的综合比较,以及确定各种评估指标的优缺点。最后,我们总结了关键影响、未来的研究方向和研究领域面临的挑战。
Introduction
文本分类——为文本指定预定义标签的过程——是许多自然语言处理 (NLP) 应用程序中必不可少且重要的任务,例如情感分析 [1][2] [3]、主题标签 [4] [ 5] [6],问答 [7] [8] 和对话行为分类 [9]。在信息爆炸的时代,人工对大量文本数据进行处理和分类既费时又具有挑战性。此外,人工文本分类的准确性很容易受到疲劳和专业知识等人为因素的影响。希望使用机器学习方法来自动化文本分类过程,以产生更可靠和更少主观的结果。此外,这还有助于提高信息检索效率,并通过定位所需信息来缓解信息过载问题。
图 1 给出了文本分类过程的流程图,在浅层和深度分析的指导下。文本数据不同于数字、图像或信号数据。它需要仔细处理 NLP 技术。第一个重要步骤是为模型预处理文本数据。浅层学习模型通常需要通过人工方法获取好的样本特征,然后用经典的机器学习算法对其进行分类。因此,该方法的有效性在很大程度上受到特征提取的限制。然而,与浅层模型不同,深度学习通过学习一组用于将特征直接映射到输出的非线性变换,将特征工程集成到模型拟合过程中。主要文本分类方法的示意图如图 2 所示。从 1960 年代到 2010 年代,基于浅层学习的文本分类模型占主导地位。浅层学习是指基于统计的模型,例如朴素贝叶斯 (NB) [10]、K 最近邻 (KNN) [11] 和支持向量机 (SVM) [12]。与早期的基于规则的方法相比,该方法在准确性和稳定性方面具有明显优势。然而,这些方法仍然需要进行特征工程,这既费时又费钱。此外,他们通常忽略文本数据中的自然顺序结构或上下文信息,这使得学习单词的语义信息变得具有挑战性。自 2010 年代以来,文本分类逐渐从浅层学习模型转变为深度学习模型。与基于浅层学习的方法相比,深度学习方法避免了人工设计规则和特征,自动为文本挖掘提供语义上有意义的表示。因此,大多数文本分类研究工作都是基于 DNN,这是一种计算复杂度高的数据驱动方法。很少有工作关注浅层学习模型来解决计算和数据的局限性。
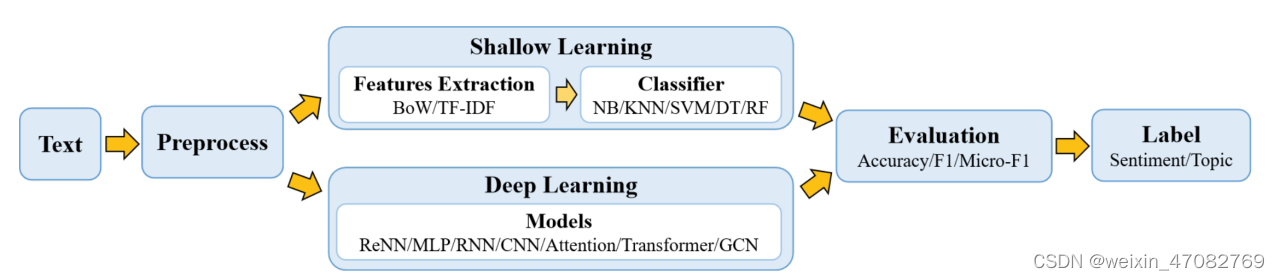
图 1. 每个模块中经典方法的文本分类流程图。提取浅层模型的基本特征至关重要,但特征可以由 DNN 自动提取。
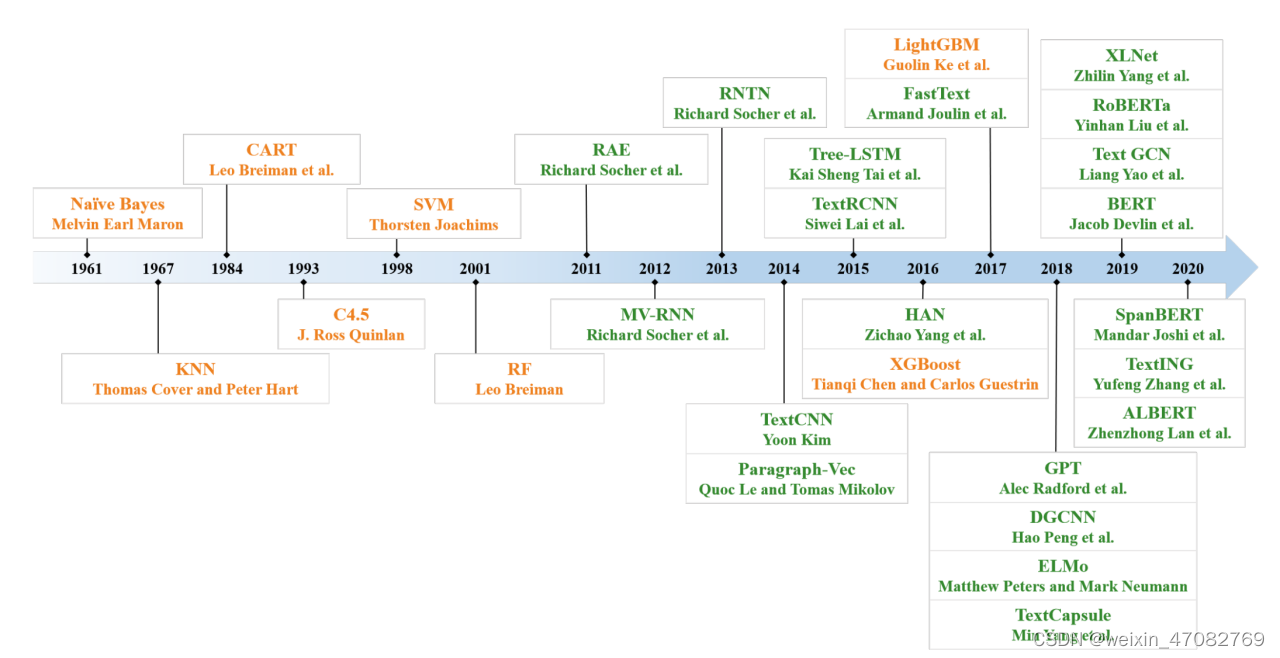 图 2. 1961 年至 2020 年主要文本分类方法示意图。2010 年之前,几乎所有现有方法都基于浅层模型(橙色);自 2010 年以来,该领域的大部分工作都集中在深度学习方案(绿色)上。
图 2. 1961 年至 2020 年主要文本分类方法示意图。2010 年之前,几乎所有现有方法都基于浅层模型(橙色);自 2010 年以来,该领域的大部分工作都集中在深度学习方案(绿色)上。
1.1 Major Differences and Contributions
在文献中,Kowsari 等人。 [13] 调查了不同的文本特征提取、降维方法、文本分类的基本模型结构和评估方法。 Minaee 等人。 [14] 回顾了最近基于深度学习的文本分类方法、基准数据集和评估指标。与现有的文本分类调查不同,我们将现有模型从浅层到深度学习与近年来的工作相结合。浅层学习模型强调特征提取和分类器设计。一旦文本具有设计良好的特征,就可以通过训练分类器快速收敛。 DNN 可以自动执行特征提取,无需领域知识也能很好地学习。然后,我们给出了单标签和多标签任务的数据集和评估指标,并从数据、模型和性能的角度总结了未来的研究挑战。此外,我们在四个表格中总结了各种信息,包括经典浅层和深度学习模型的必要信息、DNN 的技术细节、主要数据集的主要信息以及不同应用下最先进方法的一般基准。总之,本研究的主要贡献如下:
• 我们介绍了文本分类的过程和发展,并在表 1 中总结了经典模型在出版年份方面的必要信息,包括地点、应用、引用和代码链接。
• 我们根据模型结构对主要模型(从浅层到深度学习模型)进行综合分析和研究。我们总结了经典或更具体的模型,并在表 2 中主要概述了基本模型、指标和实验数据集方面的设计差异。
• 我们介绍了目前的数据集,并给出了主要评估指标的制定,包括单标签和多标签文本分类任务。我们在表 3 中总结了主要数据集的必要信息,包括类别数、平均句子长度、每个数据集的大小、相关论文和数据地址。
• 我们在表 5 中总结了经典模型在基准数据集上的分类准确度得分,并通过讨论文本分类面临的主要挑战和本研究的主要影响来总结调查。
1.2 Organization of the Survey
调查的其余部分安排如下。第 2 节总结了与文本分类相关的现有模型,包括浅层学习和深度学习模型。第 3 节介绍了主要数据集以及单标签和多标签任务的汇总表和评估指标。然后,我们在第 4 节中给出了经典文本分类数据集中领先模型的定量结果。最后,我们在第 6 节总结文章之前,在第 5 节中总结了深度学习文本分类的主要挑战。
表1. 文本分类的主要模型的必要信息,引文的统计时间为 2020年6月8日。
2. TEXT CLASSIFICATION METHODS
文本分类是指从原始文本数据中提取特征,并根据这些特征预测文本数据的类别。在过去的几十年中,已经提出了许多用于文本分类的模型,如表 1 所示。我们将文本分类的主要模型的主要信息(包括地点、应用、引用和代码链接)制成表格。该表中的应用包括情感分析(SA)、主题标签(TL)、新闻分类(NC)、问答(QA)、对话行为分类(DAC)、自然语言推理(NLI)和事件预测(EP) .对于浅层学习模型,NB [10] 是第一个用于文本分类任务的模型。此后,提出了通用分类模型,如 KNN、SVM [12] 和 RF [15],它们被称为分类器,广泛用于文本分类。最近,XGBoost [16] 和 LightGBM [17] 可以说具有提供出色性能的潜力。对于深度学习模型,TextCNN [18] 在这些模型中的引用次数最多,其中首次引入 CNN 模型来解决文本分类问题。虽然 BERT [19] 不是专门为处理文本分类任务而设计的,但考虑到它在众多文本分类数据集上的有效性,它在设计文本分类模型时已被广泛采用。
2.1 浅层学习模型
浅层学习模型加速了文本分类,提高了准确性,扩大了浅层学习的应用范围。
- 首先是对训练浅层学习模型的原始输入文本进行预处理,一般包括分词、数据清洗和数据统计。
- 然后,文本表示旨在以一种对计算机来说更容易并最大限度地减少信息损失的形式来表达预处理文本,例如词袋(BOW)、N-gram、词频-逆文档频率(TF-IDF)[ 93]、word2vec [94] 和 GloVe [95]。
- BOW 的核心是用字典大小的向量表示每个文本。向量的个体值表示与其在文本中的固有位置相对应的词频。
- 与BOW相比,N-gram考虑了相邻词的信息,通过考虑相邻词来构建字典。
- TF-IDF [93] 使用词频并反转文档频率来对文本建模。
- word2vec [94] 使用局部上下文信息来获取词向量。
- GloVe [95]——具有局部上下文和全局统计特征——在词-词共现矩阵中的非零元素上进行训练。
- 最后,根据选定的特征将表示的文本输入分类器。在这里,我们详细讨论了一些有代表性的分类器:
2.1.1 基于 PGM 的方法
概率图形模型(PGM)表达了图形中特征之间的条件依赖性,例如贝叶斯网络[96]、隐马尔可夫网络[97]。这些模型是概率论和图论的结合。
- 朴素贝叶斯 (NB) [10] 是基于应用贝叶斯定理的最简单且使用最广泛的模型。 NB算法有一个独立的假设:当目标值已经给定时,特征x=[x1,x2,····,xn]之间的条件是独立的(见图3)。 NB算法主要是利用先验概率来计算后验概率。由于其结构简单,NB 被广泛用于文本分类任务。虽然特征独立的假设有时并不实际,但它大大简化了计算过程并且性能更好。为了提高较小类别的性能,Schneider [98] 通过计算训练集和相应类别之间的 KL-divergence [99] 提出了一种特征选择评分方法,用于多项式 NB 文本分类。戴等。 [100] 提出了一种名为朴素贝叶斯迁移分类(NBTC)的迁移学习方法来解决训练集和目标集之间的不同分布。它使用 EM 算法 [101] 在目标集上获得局部最优后验假设。
- 隐马尔可夫模型 (HMM) 是一种马尔可夫模型,假设是隐藏状态中的马尔可夫过程 [97]。它适用于顺序文本数据,通过重新设计模型结构有效降低算法复杂度。 HMM 在假设存在单独的进程 Y 并且其行为取决于 X 的情况下运行。可达到的学习目标是通过观察 Y 来了解 X,同时考虑状态依赖性(见图 3)。为了考虑文本页面之间的上下文信息,Frasconi 等人。 [102] 将文本重塑为页面序列,并利用文本中页面之间的顺序关系用于多页文本。然而,这些方法对域文本没有很好的性能。受此启发,Yi 等人。 [103] 使用先验知识——主要源于专业主题词汇集医学主题词 (MeSH) [104]——来执行医学文本分类任务。
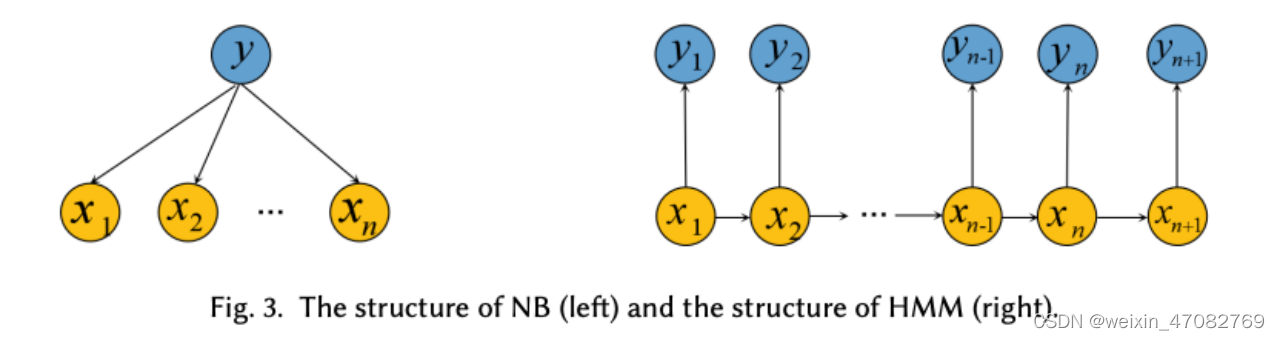
图3. NB的结构(左)和HMM的结构(右)。
2.1.2 基于 KNN 的方法
K 最近邻 (KNN) 算法 [11] 的核心是通过在 k 最近标记样本上找到样本最多的类别来对未标记样本进行分类。它是一个简单的分类器,无需构建模型,可以通过快速获取 k 个最近邻居的过程来降低复杂性。图 4 展示了 KNN 的结构。通过估计中间距离,我们可以找到接近要分类的特定文本的 k 个训练文本。因此,文本可以分为 k 个训练集文本中最常见的类别。然而,由于模型时间/空间复杂度与数据量呈正相关关系,KNN 算法在大规模数据集上花费的时间异常长。为了减少所选特征的数量,Soucy 等人。 [105] 提出了一种没有特征加权的 KNN 算法。它设法找到相关的特征,通过使用特征选择来建立单词的相互依赖性。当数据分布极度不均匀时,KNN 倾向于对数据较多的样本进行分类。提出了邻域加权 K 近邻 (NWKNN) [106] 以提高不平衡语料库的分类性能。它为小类别中的邻居施加了显着的权重,而为大类别中的邻居施加了较小的权重。
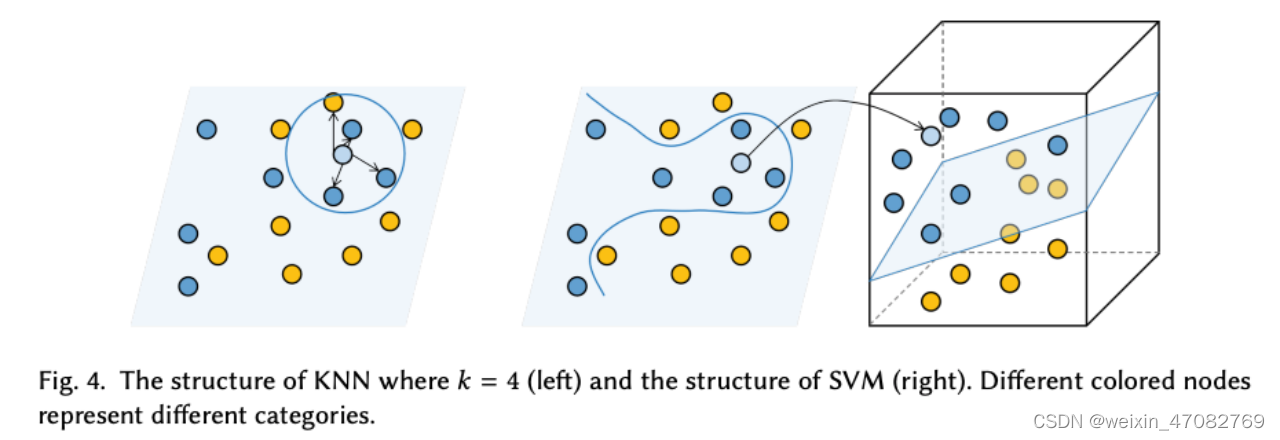
图4. k=4的KNN的结构(左)和SVM的结构(右)。不同颜色的结点 代表不同的类别。
2.1.3 基于 SVM 的方法
Cortes 和 Vapnik 提出支持向量机 (SVM) [107] 来解决模式识别的二元分类问题。 Joachims [12] 首次使用 SVM 方法进行文本分类,将每个文本表示为一个向量。如图 4 所示,基于 SVM 的方法将文本分类任务转化为多个二元分类任务。
在此背景下,SVM在一维输入空间或特征空间构造一个最优超平面,使超平面与两类训练集的距离最大化,从而达到最佳的泛化能力。目标是使类别边界沿垂直于超平面方向的距离最大。等价地,这将导致最低的分类错误率。构造最优超平面可以转化为二次规划问题,求得全局最优解。选择合适的核函数对于保证支持向量机能够处理非线性问题并成为鲁棒的非线性分类器至关重要。为了分析 SVM 算法学习的内容和适合的任务,Joachims [108] 提出了一种理论学习模型,将统计特征与 SVM 的泛化性能相结合,使用定量方法分析特征和收益。 Transductive Support Vector Machine (TSVM) [109] 被提议用于减少特定测试集的错误分类,并使用考虑特定测试集的一般决策函数。它使用先验知识来建立更合适的结构并更快地学习。
2.1.4 基于 DT 的方法
决策树 (DT) [110] 是一种受监督的树结构学习方法——反映了分而治之的思想——并且是递归构建的。它学习析取表达式并且对带有噪声的文本具有鲁棒性。如图 5 所示,决策树通常可以分为两个不同的阶段:树构建和树修剪:
- 它从根节点开始,对数据样本(由实例集组成,具有多个属性)进行测试,并根据不同的结果将数据集划分为不同的子集。
- 数据集的一个子集构成一个子节点,决策树中的每个叶节点代表一个类别。构建决策树是为了确定类和属性之间的相关性,进一步利用它来预测未知即将到来的类型的记录类别。决策树算法生成的分类规则简单明了,剪枝策略也有助于减少噪声的影响。
然而,它的局限性主要来自于处理爆炸式增长的数据量时效率低下。更具体地说:
- ID3[111]算法在选择每个节点时使用信息增益作为属性选择准则——用于选择每个分支节点的属性,然后选择具有最大信息增益值的属性成为当前节点的判别属性。
- 基于 ID3,C4.5 [24] 学习获取从属性到类的映射,从而有效地将未知实体分类为新类别。基于DT的算法通常需要针对每个数据集进行训练,效率较低。因此,约翰逊等人。 [112] 提出了一个基于 DT 的符号规则系统。该方法将每个文本表示为一个向量,该向量由文本中每个单词的频率计算得出,并从训练数据中归纳出规则。学习规则用于对与训练数据相似的其他数据进行分类。此外,为了降低 DT 算法的计算成本,快速决策树 (FDT) [113] 使用双管齐下的策略:预选特征集并在不同数据子集上训练多个 DT。来自多个 DT 的结果通过数据融合技术组合,以解决不平衡类的情况。
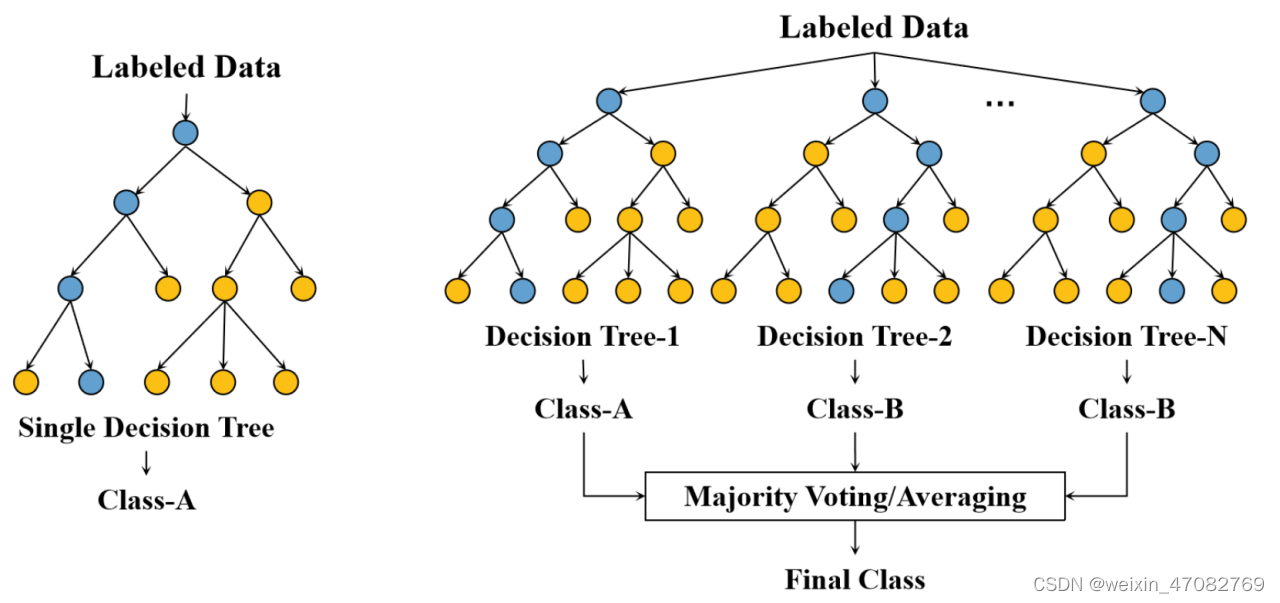
图5. DT的结构(左)和RF的结构(右)。蓝色的节点代表决策路线的节点。决策路线的节点。
2.1.5 基于集成的方法
集成算法旨在聚合多个算法的结果以获得更好的性能和解释。传统的集成算法是引导聚合,例如随机森林 (RF) [15],增强算法,例如 AdaBoost [26] 和 XGBoost [16] 以及堆栈。 Bootstrap 聚合方法训练多个没有强依赖性的分类器,然后聚合它们的结果。例如,RF [15] 由多个树分类器组成,其中所有树都取决于独立采样的随机向量的值(如图 5 所示)。值得注意的是,RF 中的每棵树共享相同的分布。 RF的泛化误差依赖于每棵树的强度和树与树之间的关系,并随着森林中树数的增加而收敛到一个极限。在基于提升的算法中,所有标记数据都使用相同的权重进行训练,以最初获得较弱的分类器。然后根据分类器的先前结果调整数据的权重。训练过程将通过重复这些步骤继续进行,直到达到终止条件。与 bootstrap 和 boosting 算法不同,基于堆栈的算法将数据分解为 n 个部分,并使用 n 个分类器以级联方式计算输入数据——上游分类器的结果将作为输入馈入下游分类器。一旦达到预定义的迭代次数,训练将终止。集成方法可以从多棵树中捕获更多特征。但是,它对短文本帮助不大。受此启发,Bouaziz 等人。 [114] 将数据丰富与 RFs 中的语义结合起来进行短文本分类,以克服上下文信息稀疏和不足的缺陷。在集成算法中,并非所有分类器都学得很好。需要为每个分类器赋予不同的权重。为了区分森林中树木的贡献,Islam 等人。 [115]利用语义感知随机森林(SARF)分类器,选择与同一类特征相似的特征,用于提取特征并产生预测值。
概括。浅层学习方法是机器学习的一种。它从数据中学习,这些数据是对预测值的性能很重要的预定义特征。然而,特征工程是一项艰巨的工作。在训练分类器之前,我们需要收集知识或经验来从原文中提取特征。浅层学习方法基于从原始文本中提取的各种文本特征来训练初始分类器。对于小数据集,在计算复杂度的限制下,浅层学习模型通常比深度学习模型表现出更好的性能。因此,一些研究人员研究了针对数据较少的特定领域的浅层模型设计。
2.2 深度学习模型
表2. 基于不同模型的基本信息。Trans:Transformer。时间:训练时间
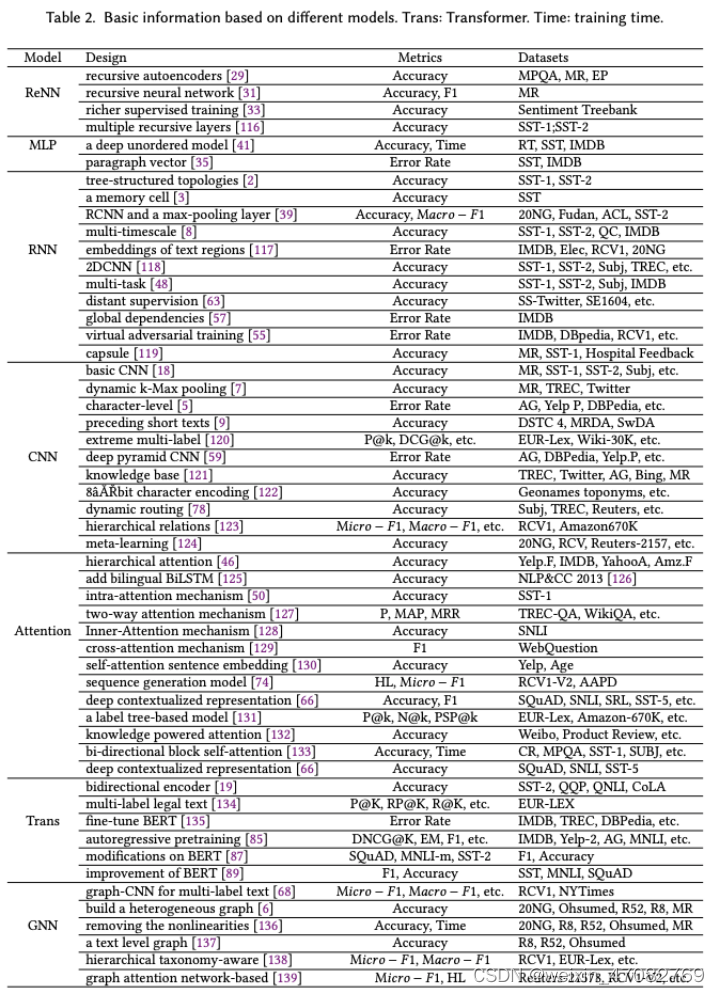
DNNs 由模拟人脑的人工神经网络组成,可以自动从数据中学习高级特征,在语音识别、图像处理和文本理解方面取得了比浅层学习模型更好的效果。应对输入数据集进行分析以对数据进行分类,例如单标签、多标签、无监督、不平衡的数据集。根据数据集的特征,将输入的词向量送入DNN进行训练,直到达到终止条件。训练模型的性能通过下游任务验证,例如情感分类、问答和事件预测。我们在表 2 中展示了多年来的一些 DNN,包括与相应的基本模型、评估指标和实验数据集不同的设计。
如表 2 所示,前馈神经网络和递归神经网络是用于文本分类任务的前两种深度学习方法,与浅层学习模型相比,它们提高了性能。然后,CNN、RNN 和注意机制用于文本分类。许多研究人员通过改进 CNN、RNN 和注意力,或模型融合和多任务方法来提高不同任务的文本分类性能。 Bidirectional Encoder Representations from Transformers (BERT) [19] 的出现,它可以生成上下文词向量,是文本分类和其他 NLP 技术发展的一个重要转折点。许多研究人员研究了基于 BERT 的文本分类模型,该模型在包括文本分类在内的多项 NLP 任务中取得了优于上述模型的性能。此外,一些研究人员研究基于 GNN [6] 的文本分类技术来捕获文本中的结构信息,这是其他方法无法替代的。在这里,我们按结构对 DNN 进行分类,并详细讨论一些具有代表性的模型:
2.2.1 基于 ReNN 的方法
浅层学习模型在每个任务的设计特征上花费大量时间。递归神经网络(ReNN)可以在没有特征设计的情况下自动递归地学习文本的语义和语法树结构,如图 6 所示。我们给出了一个基于 ReNN 的模型的例子:
- 首先,将输入文本的每个单词作为模型结构的叶节点。
- 然后使用权重矩阵将所有节点组合成父节点。
- 权重矩阵在整个模型中共享。
- 每个父节点与所有叶节点具有相同的维度。
- 最后,将所有节点递归聚合成一个父节点来表示输入文本来预测标签。
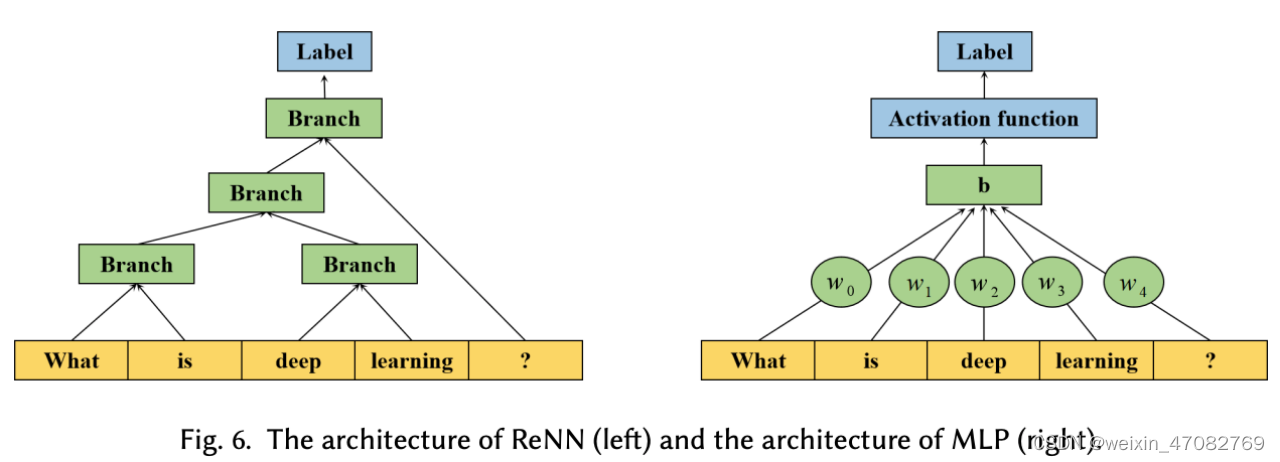
图6. ReNN的结构(左)和MLP的结构(右)
与浅层学习模型相比,基于 ReNN 的模型提高了性能,并且由于排除了用于不同文本分类任务的特征设计而节省了人工成本。递归自动编码器 (RAE) [29] 用于预测每个输入句子的情感标签分布,并学习多词短语的表示。为了学习每个输入文本的组合向量表示,矩阵向量递归神经网络 (MV-RNN) [31] 引入了 ReNN 模型来学习短语和句子的表示。它允许输入文本的长度和类型不一致。 MV-RNN 为构造的解析树上的每个节点分配一个矩阵和一个向量。此外,递归神经张量网络(RNTN)[33]被提出具有树结构来捕获句子的语义。它输入不同长度的短语,并通过解析树和词向量来表示这些短语。解析树上更高节点的向量由基于相等张量的组合函数估计。对于RNTN,构建文本树的时间复杂度高,在树结构内表达文档之间的关系复杂。随着 DNN 的深度增加,性能通常会得到改善。因此,Irsoy 等人。 [116] 提出了一种深度递归神经网络(DeepReNN),它堆叠了多个递归层。它由二进制解析树构建,并学习语言中不同的组合性观点.
2.2.2 基于 MLP 的方法
多层感知器(MLP)[140],有时通俗地称为“vanilla”神经网络,是一种简单的神经网络结构,用于自动捕获特征。如图 6 所示,我们展示了一个三层 MLP 模型:它包含一个输入层、一个在所有节点都具有激活函数的隐藏层和一个输出层。
每个节点连接一个特定的权重 wi 。它将每个输入文本视为一个词袋,与浅层学习模型相比,它在许多文本分类基准上都取得了高性能。一些研究小组针对文本分类任务提出了一些基于 MLP 的方法。段落向量(Paragraph-Vec)[35]是最流行和使用最广泛的方法,类似于连续词袋(CBOW)[94]。它通过采用无监督算法获得具有各种输入长度的文本的固定长度特征表示。与CBOW相比,它增加了一个通过矩阵映射到段落向量的段落标记。该模型通过该向量与单词的三个上下文的连接或平均值来预测第四个单词。段落向量可以作为段落主题的记忆,作为段落函数插入到预测分类器中。
2.2.3 基于循环神经网络的方法
循环神经网络 (RNN) 由于通过循环计算捕获长程依赖性而被广泛使用。 RNN 语言模型学习历史信息,考虑适合文本分类任务的所有单词之间的位置信息。我们用一个简单的样本展示了一个用于文本分类的 RNN 模型,如图 7 所示:
- 首先,每个输入词使用word embedding技术由一个特定的向量表示。
- 然后,嵌入词向量被一个一个地输入到 RNN 单元中。
- RNN 单元的输出与输入向量具有相同的维度,并被送入下一个隐藏层。
- RNN 在模型的不同部分共享参数,并且每个输入词具有相同的权重。
- 最后,输入文本的标签可以通过隐藏层的最后一个输出来预测。
为了降低模型的时间复杂度并捕获上下文信息,Liu 等人。 [48] 引入了一个模型来捕捉长文本的语义。它一个一个地解析文本,是一个有偏见的模型,使得后面的输入比前者更有利,并降低了捕获整个文本的语义效率。为了对具有长输入序列的主题标记任务进行建模,提出了 TopicRNN [57]。它通过潜在主题捕获文档中单词的依赖关系,并使用 RNN 捕获局部依赖关系,使用潜在主题模型捕获全局语义依赖关系。虚拟对抗训练(VAT)[141] 是一种适用于半监督学习任务的有用正则化方法。宫户等。 [55] 将对抗性和虚拟对抗性训练应用于文本字段,并将扰动应用于词嵌入而不是原始输入文本。该模型提高了词嵌入的质量,并且在训练过程中不易过拟合。胶囊网络 [142] 使用由一层中的一组神经元组成的胶囊之间的动态路由来捕获特征之间的关系。王等。 [119] 提出了一种用于情感分类任务的具有简单胶囊结构的 RNN-Capsule 模型。
在RNN的反向传播过程中,权重是通过梯度调整的,通过导数的连续乘法计算得到。如果导数非常小,连续相乘可能会导致梯度消失问题。 Long Short-Term Memory (LSTM) [143],RNN 的改进,有效缓解了梯度消失问题。它由一个存储任意时间间隔值的单元和三个控制信息流的门结构组成。门结构包括输入门、遗忘门和输出门。 LSTM分类方法可以更好地捕获上下文特征词之间的联系,利用遗忘门结构过滤无用信息,有利于提高分类器的总捕获能力。 Tree-LSTM [2] 将 LSTM 模型的序列扩展到树结构。对于Tree-LSTM模型,可以通过LSTM遗忘门机制遗忘对结果影响不大的整棵子树。
自然语言推理 (NLI) 通过测量每对句子之间的语义相似性来预测一个文本的含义是否可以从另一个文本中推断出来。为了考虑反方向的其他粒度匹配和匹配,Wang 等人。 [144] 提出了一种名为双边多视角匹配(BiMPM)的 NLI 任务模型。它通过 BiLSTM 编码器对输入句子进行编码。然后,编码后的句子在两个方向上进行匹配。结果由另一个 BiLSTM 层聚合在固定长度的匹配向量中。最后,结果由全连接层评估.
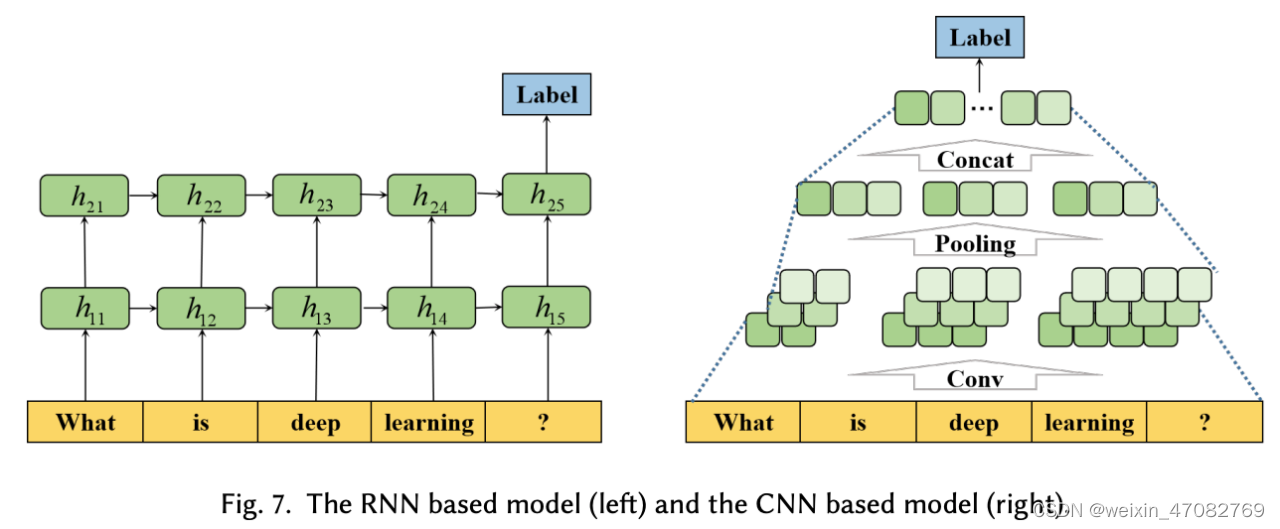
图7. 基于RNN的模型(左)和基于CNN的模型(右)
2.2.4 基于 CNN 的方法
卷积神经网络 (CNN) 被提出用于图像分类,具有可以提取图片特征的卷积滤波器。与 RNN 不同,CNN 可以同时将不同内核定义的卷积应用于序列的多个块。因此,CNN 用于许多 NLP 任务,包括文本分类。对于文本分类,需要将文本表示为类似于图像表示的向量,并且可以从多个角度过滤文本特征,如图7所示。首先,将输入文本的词向量拼接成矩阵。然后将该矩阵送入卷积层,该层包含多个不同维度的滤波器。最后,卷积层的结果经过池化层,将池化结果拼接起来,得到文本的最终向量表示。类别由最终向量预测。
为了尝试将 CNN 用于文本分类任务,Kim 引入了一种无偏的卷积神经网络模型,称为 TextCNN [18]。它可以通过一层卷积更好地确定最大池化层中的判别短语,并通过保持词向量静态来学习除词向量之外的超参数。仅对标记数据进行训练对于数据驱动的深度模型来说是不够的。因此,一些研究人员考虑利用未标记的数据。约翰逊等人。 [145] 提出了一种基于双视图半监督学习的文本分类 CNN 模型,该模型首先使用未标记的数据训练文本区域的嵌入,然后训练标记数据。 DNN 通常具有更好的性能,但它增加了计算复杂度。受此启发,提出了一种深度金字塔卷积神经网络 (DPCNN) [59],通过提高网络深度来提高计算精度。 DPCNN 比 ResNet [146] 更具体,因为所有的快捷方式都是非常简单的身份映射,没有任何维度匹配的复杂性。
根据文本的最小嵌入单元,嵌入方法分为字符级、词级和句子级嵌入。字符级嵌入可以解决词汇外 (OOV) 词。词级嵌入学习词的句法和语义。此外,句子级嵌入可以捕捉句子之间的关系。受这些启发,Nguyen 等人。 [147] 提出了一种基于字典的深度学习方法,通过构建语义规则和深度 CNN 为字符级嵌入增加词级嵌入的信息。亚当斯等。 [122] 提出了一种称为 MGTC 的字符级 CNN 模型,用于对编写的多语言文本进行分类。 TransCap [148] 被提议将句子级语义表示封装到语义胶囊中并传输文档级知识。
基于 RNN 的模型捕获序列信息以学习输入词之间的依赖关系,而基于 CNN 的模型从卷积核中提取相关特征。因此,一些作品研究了这两种方法的融合。 BLSTM-2DCNN [118] 将双向 LSTM (BiLSTM) 与二维最大池化相结合。它使用 2D 卷积对矩阵的更有意义的信息进行采样,并通过 BiLSTM 更好地理解上下文。此外,薛等人。 [149] 提出 MTNA,BiLSTM 和 CNN 层的组合,以解决方面类别分类和方面术语提取任务。
2.2.5 基于注意力的方法
CNN 和 RNN 在与文本分类相关的任务上提供了出色的结果。然而,这些模型不够直观,可解释性差,尤其是在分类错误方面,由于隐藏数据的不可读性,无法解释。基于注意力的方法成功地用于文本分类。 Bahdanau 等人。 [150]首先提出了一种可用于机器翻译的注意力机制。受此启发,Yang 等人。 [46] 引入了层次化注意力网络 (HAN),通过使用文本的信息量极大的成分来获得更好的可视化效果,如图 8 所示。HAN 包括两个编码器和两个级别的注意力层。注意力机制让模型对特定的输入给予不同的关注。它首先将基本词聚合成句子向量,然后将重要句子向量聚合成文本向量。通过两个attention层次,可以了解到每个词和句子对分类判断的贡献有多大,有利于应用和分析。注意力机制可以提高文本分类的可解释性,使其受到欢迎。还有一些其他基于注意力的作品。
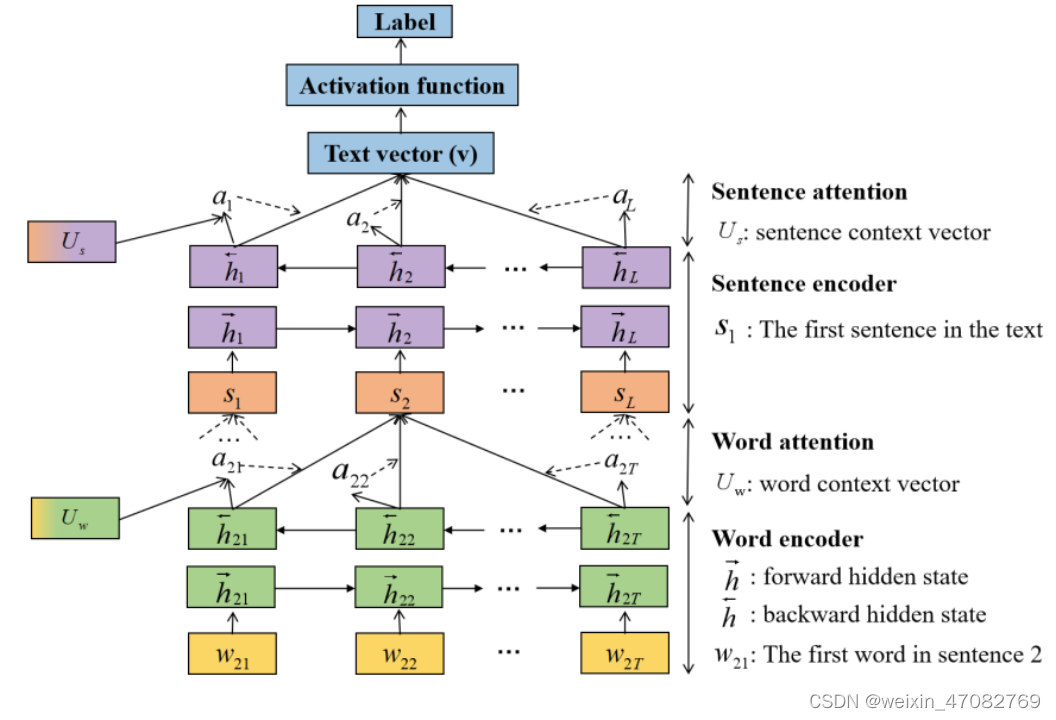 图8. 分层注意网络
图8. 分层注意网络
LSTMN [50] 被提议从左到右逐步处理文本,并通过记忆和注意力进行表面推理。王等。 [151] 通过探索方面和输入句子之间的联系,提出了一种基于注意力的 LSTM 神经网络。 BI-Attention [125] 被提议用于跨语言文本分类以捕获双语长距离依赖关系。胡等。 [152] 提出了一种基于类别属性的注意力机制,用于解决包含少射电荷的各种电荷数量不平衡问题。
Self-attention [153] 通过在句子之间构建 K、Q 和 V 矩阵来捕获句子中单词的权重分布,这些矩阵可以捕获对文本分类的长期依赖性。我们举一个self-attention的例子,如图9所示。每个输入词向量ai可以表示为三个n维向量,包括qi、ki和vi。经过self-attention后,输出向量bi可以表示为
。可以并行计算所有输出向量。林等。 [130] 使用源标记自注意力来探索句子表示任务中每个标记对整个句子的权重。为了捕获远程依赖关系,双向块自注意网络 (Bi-BloSAN) [133] 使用块内自注意网络 (SAN) 对按序列分割的每个块和块间 SAN 输出.
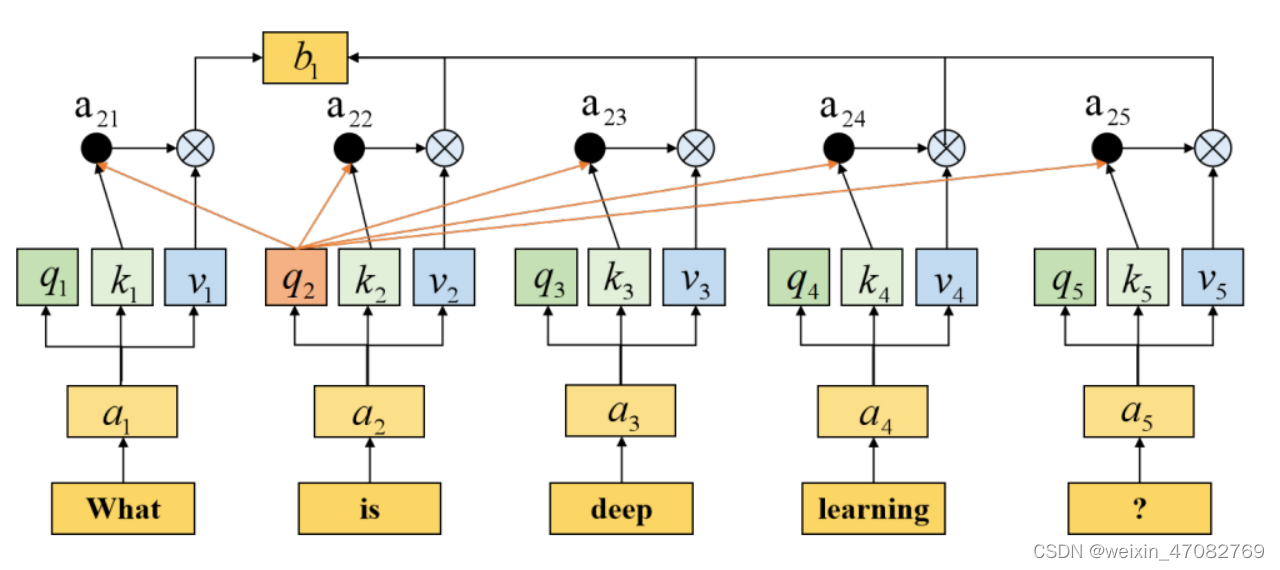
图9. 一个自我注意的例子
基于方面的情感分析 (ABSA) 将文本分解为多个方面,并为每个方面分配一个情感极性。情绪极性可分为积极、中性和消极两种类型。提出了一些基于注意力的模型来识别针对基于方面的情感任务的特定方面的细粒度意见极性。 ATAE-LSTM [151] 可以通过注意机制根据输入集中在每个句子的不同部分。 MGAN [80] 提出了一种细粒度的注意机制和粗粒度的注意机制来学习上下文和方面之间的词级交互。为了捕捉 QA 任务的每个问题和候选答案之间的复杂语义关系,Tan 等人. [154] 引入 CNN 和 RNN,并通过使用受问题上下文影响的简单单向注意机制来生成答案嵌入。注意力捕捉问题和答案嵌入之间的依赖关系。提取式 QA 可以看作是文本分类任务。它输入一个问题和多个候选答案,并对每个候选答案进行分类以识别正确答案。此外,具有双向注意机制的 AP-BILSTM [127] 可以学习问题和每个候选答案之间的权重,以获得每个候选答案对问题的重要性。
2.2.6 基于transformer的方法
预训练语言模型可有效学习全局语义表示并显着提升 NLP 任务,包括文本分类。它一般采用无监督的方法自动挖掘语义知识,然后构建预训练目标,让机器学习理解语义。如图 10 所示,我们给出了 ELMo [66]、OpenAI GPT [155] 和 BERT [19] 之间模型架构的差异。 ELMo [66] 是一种深度语境化的词表示模型,很容易集成到模型中。它可以对单词的复杂特征进行建模,并为各种语言上下文学习不同的表示。它使用双向 LSTM 根据上下文词学习每个词嵌入。 GPT [155] 采用有监督的微调和无监督的预训练来学习一般表示,这些表示对许多 NLP 任务的适应性有限。此外,目标任务的领域不需要与未标记的数据集相似。 GPT算法的训练过程通常包括两个阶段。首先,神经网络模型的初始参数是通过未标记数据集上的建模目标学习的。然后我们可以使用相应的监督目标来适应目标任务的这些参数。谷歌提出的 BERT 模型 [19] 通过联合调节每一层的左右上下文来预训练未标记文本的深度双向表示,显着提高了 NLP 任务(包括文本分类)的性能。通过仅添加一个额外的输出层来为多个 NLP 任务(例如 SA、QA 和机器翻译)构建模型来对其进行微调。与这三种模型相比,ELMo 是使用 LSTM 的基于特征的方法,而 BERT 和 OpenAI GPT 是使用 Transformer 的微调方法。此外,ELMo 和 BERT 是双向训练模型,而 OpenAI GPT 是从左到右训练的。因此,BERT 得到了更好的结果,它结合了 ELMo 和 OpenAI GPT 的优点。
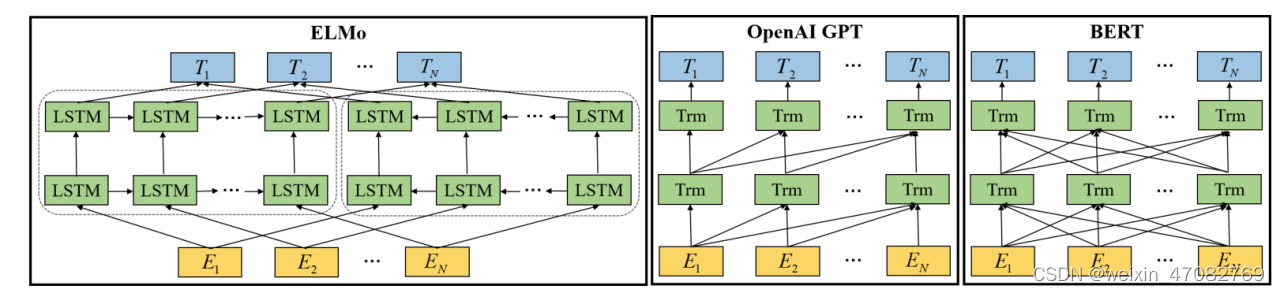
图10. 预训练模型架构的差异[19],包括BERT、OpenAI GPT和ELMo。Ei代表第i个输入的嵌入。Trm代表变换器块。Ti代表第i个输入的预测标签。
基于 Transformer 的模型可以在不考虑适用于大规模数据集的顺序信息的情况下进行并行计算,使其在 NLP 任务中很受欢迎。因此,一些其他作品用于文本分类任务并获得出色的性能。 RoBERTa [87] 采用动态掩蔽方法,每次生成掩蔽模式,并将序列输入模型。它使用更多数据进行更长时间的预训练,并估计各种基本超参数的影响和训练数据的大小。 ALBERT [89] 使用双参数简化方案。一般来说,这些方法采用无监督目标函数进行预训练,包括下一句预测、掩码技术和排列。这些基于单词预测的目标函数展示了学习单词依赖和语义结构的强大能力[156]。 XLNet [85] 是一种广义自回归预训练方法。它最大化整个因式分解顺序排列的预期可能性,以学习双向上下文。此外,它可以通过自回归公式克服 BERT 的弱点,并将 Transformer-XL [157] 的思想整合到预训练中。
2.2.7 基于 GNN 的方法
像 CNN 这样的 DNN 模型在规则结构上表现出色,而不是在任意结构图上。一些研究人员研究了如何在任意结构化的图上进行扩展 [158] [159]。随着图神经网络 (GNN) 的日益受到关注,基于 GNN 的模型通过对句子的句法结构进行编码,在语义角色标记任务 [160]、关系分类任务 [161] 和机器翻译任务 [162] 中获得了出色的性能。它将文本分类转化为图节点分类任务。我们展示了一个用于文本分类的 GCN 模型,其中包含四个输入文本,如图 11 所示。首先,将四个输入文本和文本中的单词(定义为节点)构造成图结构。图节点由粗黑边连接,表示文档-词边和词-词边。每个词-词边的权重通常表示它们在语料库中的共现频率。然后,单词和文本通过隐藏层表示。最后,可以通过图形预测所有输入文本的标签。
基于 GNN 的模型可以学习句子的句法结构,这使得一些研究人员研究使用 GNN 进行文本分类。 DGCNN [68] 是一种将文本转换为词图的图形 CNN,具有使用 CNN 模型学习不同级别语义的优势。姚等。 [6] 提出了文本图卷积网络(TextGCN),它为整个数据集构建异构词文本图并捕获全局词共现信息。为了使基于 GNN 的模型能够支持在线测试,Huang 等人。 [137] 为每个具有全局参数共享的文本构建图形,而不是语料库级别的图形结构,以帮助保存全局信息并减轻负担。 TextING [163] 为每个文档构建单独的图形,并通过 GNN 学习文本级单词交互,以有效地为新文本中的晦涩单词生成嵌入。
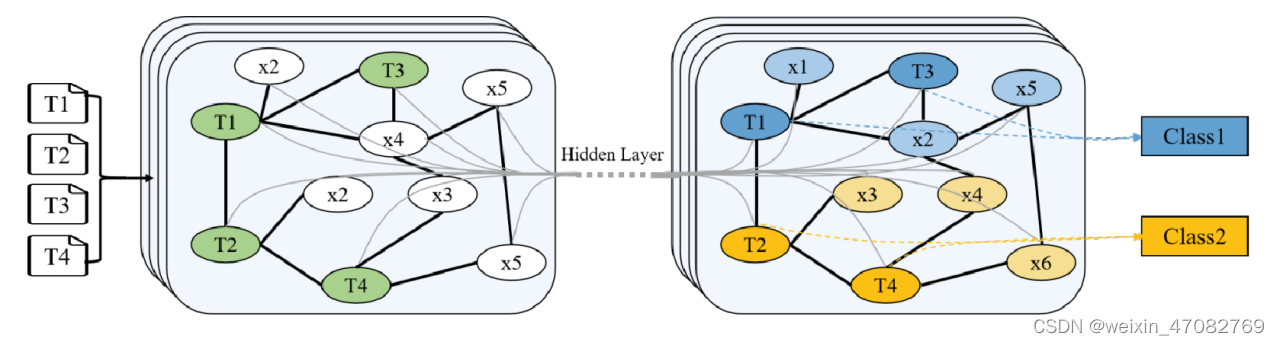
图 11. 基于 GCN 的模型。黑色粗体边缘是图中的文档-单词边缘和单词-单词边缘。
图注意网络 (GAT) [164] 通过关注其邻居来使用屏蔽的自注意层。因此,提出了一些基于 GAT 的模型来计算每个节点的隐藏表示。具有双层注意机制的异构图注意网络(HGAT)[165]学习当前节点中不同相邻节点和节点类型的重要性。该模型在图上传播信息并捕获关系以解决半监督短文本分类的语义稀疏性问题。 MAGNET [139] 被提出来捕获基于 GAT 的标签之间的相关性,它学习标签之间的关键依赖关系并通过特征矩阵和相关矩阵生成分类器。
事件预测(EP)可分为生成事件预测和选择性事件预测(也称为脚本事件预测)。 EP,指本次评论中的脚本事件预测,根据现有事件上下文推断后续事件。与其他文本分类任务不同,EP 中的文本由一系列连续的子事件组成。提取此类子事件之间关系的特征至关重要。 SGNN [76] 被提议通过构建事件图来更好地利用事件网络信息来对事件交互进行建模并学习更好的事件表示。该模型充分利用了 EP 任务的密集事件连接。
2.2.8 其他
除了上述所有模型外,还有一些其他个别模型。在这里,我们介绍一些令人兴奋的模型。
- 连体神经网络。孪生神经网络[166]也称为孪生神经网络(Twin NN)。它利用相等的权重,同时使用两个不同的输入向量协同工作来计算可比较的输出向量。穆勒等人。 [167] 提出了由一对可变长度序列组成的 LSTM 网络的连体改编。该模型用于估计文本之间的语义相似性,超过了精心制作的特征和提出的更高复杂度的神经网络模型。该模型进一步表示使用神经网络的文本,其输入是从大量数据集中单独学习的词向量。为了解决医学领域的不平衡数据分类问题,Jayadeva 等人。 [168] 使用 Twin NN 模型从巨大的不平衡语料库中学习。目标函数实现了对应类具有非平行决策边界的双 SVM 方法,并降低了双神经网络的复杂性,优化了特征映射以更好地区分类。虚拟对抗训练 (VAT)。深度学习方法需要许多额外的超参数,这增加了计算的复杂性。
- VAT [169],基于局部分布平滑度的正则化可以用于半监督任务,只需要少量的超参数,可以直接解释为鲁棒优化。宫户等。 [55]使用VAT有效提高模型的鲁棒性和泛化能力以及词嵌入性能。
- 强化学习 (RL)。 RL 通过最大化累积奖励来学习给定环境中的最佳动作。张等。 [170] 提供了一种 RL 方法,通过学习与任务相关的结构来建立结构化的句子表示。该模型具有 Information Distilled LSTM (ID-LSTM) 和 Hierarchical Structured LSTM (HS-LSTM) 表示模型。 IDLSTM 通过选择与任务相关的基本词来学习句子表示,而 HS-LSTM 是用于建模句子表示的两级 LSTM。
- 情感分类任务的 QA 风格。将情感分类任务视为 QA 任务是一个有趣的尝试。沉等。 [171] 创建高质量的注释语料库。提出了一个三级层次匹配网络来考虑问题和答案之间的匹配信息。
- 外部常识性知识。由于事件本身的信息不足以区分 EP 任务的事件,Ding 等人。 [172]认为从原文中提取的事件缺乏共同知识,例如事件参与者的意图和情感。该模型提高了股票预测、EP等的效果。
- 量子语言模型。在量子语言模型中,单词和单词之间的依赖关系通过基本的量子事件来表示。张等。 [173] 设计了一种受量子启发的情感表示方法来学习主观文本的语义和情感信息。通过向嵌入层输入密度矩阵,提高了模型的性能。
概括。深度学习由复杂度更高的神经网络中的多个隐藏层组成,可以在非结构化数据上进行训练。深度学习架构可以直接从输入中学习特征表示,无需太多人工干预和先验知识。然而,深度学习技术是一种数据驱动的方法,通常需要海量数据才能实现高性能。虽然基于自我注意的模型可以为 DNN 带来一些单词间的可解释性,但与浅层模型相比不足以解释它为何以及如何运作良好。
3 数据集和评估指标
3.1 数据集
表3. 数据集的汇总统计。C:目标类的数量。L: 平均句子长度。N: 数据集大小。
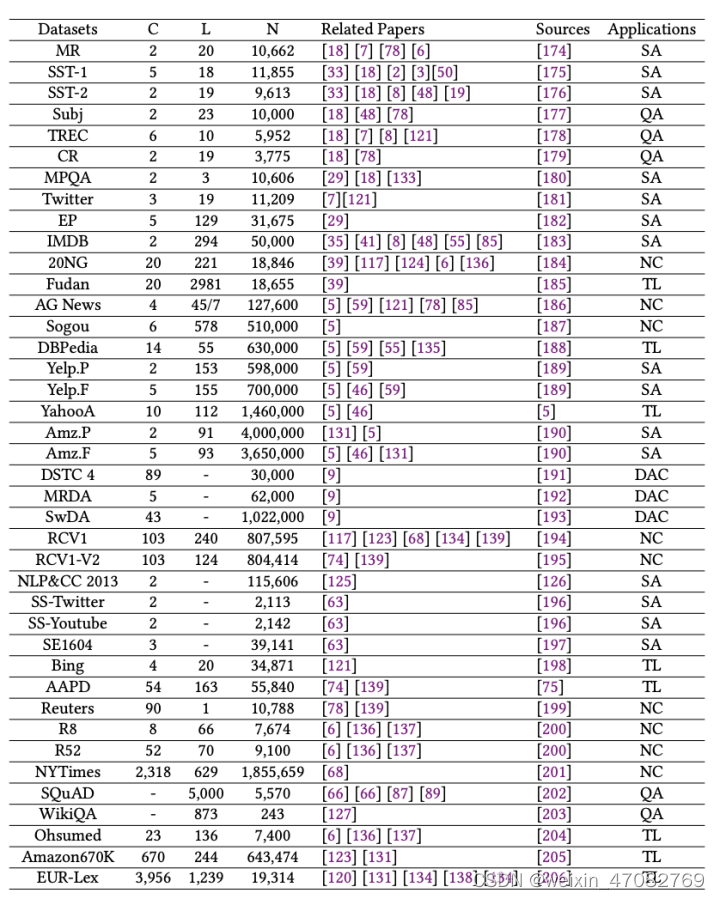
用于文本分类的标记数据集的可用性已成为该研究领域快速发展的主要推动力。在本节中,我们从领域方面总结了这些数据集的特征,并在表 3 中给出了概述,包括类别数量、平均句子长度、每个数据集的大小、相关论文、访问的数据源和应用程序。
- Sentiment Analysis(SA)。 SA是对带有情感色彩的主观文本进行分析推理的过程。区别于分析文本客观内容的传统文本分类,从文本中获取是否支持特定观点的信息至关重要。 SA 可以是二元的或多类的。 Binary SA就是把文本分为两类,包括positive和negative。多类 SA 将文本分类为多级或细粒度标签。 SA 数据集包括 MR、SST、MPQA、IMDB、Yelp、AM、Subj [177]、CR [179]、SS-Twitter、SS-Youtube、Twitter、SE1604、EP 等。在这里,我们详细介绍了几个主要数据集。
- Movie Review (MR)。MR [207] [174] 是一个电影评论数据集,每个评论对应一个句子。语料库有 5,331 个正面数据和 5,331 个负面数据。通过随机拆分进行的 10 折交叉验证通常用于测试 MR。
- Stanford Sentiment Treebank (SST)。 SST [175] 是 MR 的扩展。它有两类。具有五个类别的细粒度标签的 SST-1。它分别有 8,544 个训练文本和 2,210 个测试文本。此外,SST-2 有 9,613 个带有二进制标签的文本,分为 6,920 个训练文本、872 个开发文本和 1,821 个测试文本。
- 多视角问答 (MPQA)The Multi-Perspective Question Answering MPQA [208] [180] 是一个意见数据集。它有两个类别标签和一个意见极性检测子任务的 MPQA 数据集。 MPQA 包括从各种新闻来源的新闻文章中提取的 10,606 个句子。应该注意的是,它包含 3,311 个正文本和 7,293 个负文本,每个文本都没有标签。
- IMDB 评论。 IMDB 评论 [183] 是为电影评论的二元情感分类而开发的,每个类别中的数量相同。它可以平均分为训练组和测试组,每组 25,000 条评论。
- Yelp Reviews评论。 Yelp 评论 [189] 总结自 2013 年、2014 年和 2015 年的 Yelp 数据集挑战。该数据集有两个类别。其中的 Yelp-2 用于消极和积极情绪分类任务,包括 560,000 个训练文本和 38,000 个测试文本。 Yelp-5 用于检测细粒度的情感标签,在所有类别中有 650,000 个训练文本和 50,000 个测试文本。
- Amazon Reviews亚马逊评论 (AM)。 AM [5] 是通过收集亚马逊网站产品评论 [190] 形成的流行语料库。该数据集有两个类别。具有两个类的 Amazon-2 包括 3,600,000 个训练集和 400,000 个测试集。 Amazon-5 有五个类别,包括 3,000,000 条和 650,000 条用于训练和测试的评论。
- News Classification新闻分类 (NC)。新闻内容是最重要的信息来源之一,对人们有着至关重要的影响。 NC系统方便用户实时获取重要知识。新闻分类应用主要包括:识别新闻主题,根据用户兴趣推荐相关新闻。新闻分类数据集包括20NG、AG、R8、R52、搜狗等。在这里,我们详细介绍了几个主要数据集。
- 20 Newsgroups (20NG)。 20NG [184] 是一个新闻组文本数据集。它有 20 个类别,每个类别的数量相同,包括 18,846 篇文本。
- AG News (AG)。 AG News [5] [186] 是学术界新闻的搜索引擎,选择了四个最大的类别。它使用每个新闻的标题和描述字段。 AG 包含 120,000 个训练文本和 7,600 个测试文本。
- R8 and R52。 R8和R52是两个子集,是路透社[199]的子集。 R8[200]有8个类别,分为2189个测试文件和5485个训练课程。 R52 有 52 个类别,分为 6,532 个训练文件和 2,568 个测试文件。
- Sogou News搜狗新闻(Sogou)。搜狗新闻 [135] 结合了两个数据集,包括 SogouCA 和 SogouCS 新闻集。每个文本的标签是 URL 中的域名。主题标签 (TL)。主题分析试图通过定义复杂的文本主题来获得文本的含义。主题标注是主题分析技术的重要组成部分之一,旨在为每个文档分配一个或多个主题以简化主题分析。主题标签数据集包括 DBPedia、Ohsumed、EUR-Lex、WOS、PubMed 和 YahooA。在这里,我们详细介绍了几个主要数据集。
- DBpedia。 DBpedia [188] 是使用维基百科最常用的信息框生成的大规模多语言知识库。它每月发布 DBpedia,在每个版本中添加或删除类和属性。 DBpedia 最流行的版本有 14 个类别,分为 560,000 个训练数据和 70,000 个测试数据。
- Ohsumed。 Ohsumed [204] 属于 MEDLINE 数据库。它包括 7,400 篇文章和 23 个心血管疾病类别。所有文本都是医学摘要,并被标记为一个或多个类别。
- Yahoo answers (YahooA)。 YahooA [5] 是一个有 10 个类别的主题标签任务。它包括 140,000 个训练数据和 5,000 个测试数据。所有文本包含三个元素,分别是问题标题、问题上下文和最佳答案。
- Question Answering(QA)。 QA 任务可以分为两种类型:抽取式 QA 和生成式 QA。提取式 QA 为每个问题给出多个候选答案,以选择哪个是正确答案。因此,文本分类模型可用于提取式 QA 任务。本文讨论的QA都是extractive QA。问答系统可以应用文本分类模型来识别正确答案并将其他人设置为候选者。问答数据集包括 SQuAD、MS MARCO、TREC-QA、WikiQA 和 Quora [209]。在这里,我们详细介绍了几个主要数据集。
- Stanford Question Answering Dataset (SQuAD)。 SQuAD [202] 是一组从维基百科文章中获得的问答对。 SQuAD 有两个类别。 SQuAD1.1 包含 536 对 107,785 个问答项。 SQuAD2.0 将 SQuAD1.1 中的 100,000 个问题与人群工作者以类似于可回答问题的形式面临的 50,000 多个无法回答的问题相结合 [210]。
- MS MARCO。 MS MARCO [211] 包含问题和答案。问题和部分答案是通过 Bing 搜索引擎从实际的网络文本中抽取的。其他人是生成性的。它用于开发微软发布的生成式 QA 系统。
- TREC-QA。 TREC-QA [178] 包括 5,452 个训练文本和 500 个测试文本。它有两个版本。 TREC-6包含6个类别,TREC-50有50个类别。
- WikiQA。 WikiQA数据集[203]包含没有正确答案的问题,需要评估答案。
- 自然语言推理 (NLI)。 NLI 用于预测是否可以从一个文本中推断出另一个文本的含义。释义是 NLI 的一种通用形式。它使用测量句子对语义相似性的任务来决定一个句子是否是另一个句子的解释。 NLI 数据集包括 SNLI、MNLI、SICK、STS、RTE、SciTail、MSRP 等。这里我们详细介绍几个主要数据集。
- The Stanford Natural Language Inference斯坦福自然语言推理 (SNLI)。 SNLI [212] 通常应用于 NLI 任务。它包含 570,152 个人工注释的句子对,包括训练集、开发集和测试集,注释分为三类:中性、蕴含和矛盾。
- Multi-Genre Natural Language Inference 多类型自然语言推理 (MNLI)。 Multi-NLI [213] 是 SNLI 的扩展,包含更广泛的书面和口头文本类型。它包括 433,000 个由文本蕴含标签注释的句子对。
- Sentences Involving Compositional Knowledge (SICK)。 SICK [214] 包含近 10,000 个英语句子对。它由中性、蕴含和矛盾的标签组成。
- Microsoft Research Paraphrase微软研究释义 (MSRP)。 MSRP [215] 由句子对组成,通常用于文本相似性任务。每对都由二进制标签注释,以区分它们是否是释义。它分别包括 1,725 个训练集和 4,076 个测试集。
- Dialog Act Classification (DAC)。对话行为根据语义、语用和句法标准描述对话中的话语。 DAC 根据对话的意义类别标记一段对话,并帮助了解说话者的意图。就是根据dialog给一个label。在这里,我们详细介绍了几个主要数据集,包括 DSTC 4、MRDA 和 SwDA。
- 对话状态跟踪挑战 4 (DSTC 4)。 DSTC 4 [191] 用于对话行为分类。它有89个培训班,24,000个培训文本和6,000个测试文本。
- ICSI 会议记录器对话法 (MRDA)。 MRDA [192] 用于对话行为分类。它有 5 个训练班,51,000 个训练文本,11,000 个测试文本和 11,000 个验证文本。
- Switchboard Dialog Act (SwDA)。 SwDA [193] 用于对话行为分类。它有43个训练班,1,003,000个训练文本,19,000个测试文本和112,000个验证文本。
- Multi-label datasets多标签数据集。在多标签分类中,一个实例有多个标签,每个标签只能取多个类别中的一个。有许多基于多标签文本分类的数据集。包括Reuters, Education, Patent, RCV1, RCV1-2K, AmazonCat-13K, BlurbGenreCollection, WOS-11967, AAPD等。这里我们详细介绍几个主要的数据集。
- Reuters news路透社消息。路透社 [200] [199] 是路透社金融新闻服务中广泛使用的文本分类数据集。它有90个训练班,7769个训练文本,3019个测试文本,包含多标签和单标签。还有一些路透社的数据子集,比如R8、BR52、RCV1、RCV1-v2。
- Patent Dataset专利数据集。专利数据集是从 USPTO 1 获得的,它是一个专利系统,包含美国专利的文本细节,如标题和摘要。它包含在现实世界中授予的 100,000 项美国专利,具有多个层次类别。
- 路透社语料库第一卷 (RCV1) 和 RCV1-2K。 RCV1 [194] 是从 1996-1997 年的路透社新闻文章中收集的,人工标记了 103 个类别。它分别包含 23,149 个训练文本和 784,446 个测试文本。 RCV1-2K 数据集具有与 RCV1 相同的特征。然而,RCV1-2K 的标签集已经扩展了一些新标签。它包含 2456 个标签。
- 科学网 (WOS-11967)。 WOS-11967 [216] 是从科学网抓取的,由已发表论文的摘要组成,每个示例都有两个标签。它更浅,但范围更广,课程总数更少。
- Arxiv 学术论文数据集 (AAPD)。 AAPD [75] 是计算机科学领域的一个大型数据集,用于来自网站 2 的多标签文本分类。它有 55,840 篇论文,包括摘要和相应的主题,总共有 54 个标签。目的是根据摘要预测每篇论文对应的主题。
- 其他。还有一些用于其他应用程序的数据集,例如 Geonames 地名、Twitter 帖子等。
3.2 评估指标
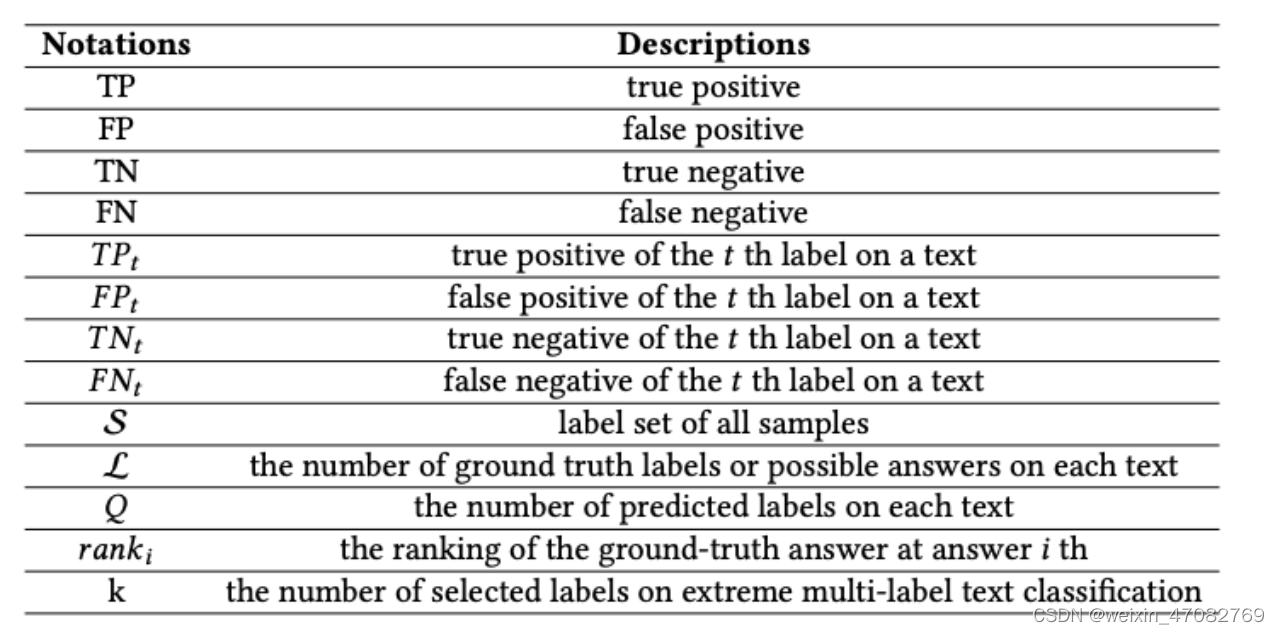
在评估文本分类模型方面,aAcuracy和F1 分数是评估文本分类方法最多的指标。后来,随着分类任务难度的增加或某些特定任务的存在,评估指标得到了改进。例如,P@K、Micro-F1等评估指标用于评估多标签文本分类性能,而MRR通常用于评估QA任务的性能。在表 4 中,我们给出了评估指标中使用的符号。
表4. 评价指标中使用的记号
3.2.1 单标签指标
单标签文本分类将文本划分为最有可能应用于 NLP 任务的类别之一,例如 QA、SA 和对话系统 [9]。对于单标签文本分类,一篇文本只属于一个目录,可以不考虑标签之间的关系。这里我们介绍一些用于单标签文本分类任务的评估指标。
- Accuracy and Error Rate。准确性和错误率是文本分类模型的基本指标。准确率和错误率分别定义为
- Precision, Recall and F1,无论标准类型和错误率如何,这些都是用于不平衡测试集的重要指标。例如,大多数测试样本都有一个类标签。 F1 是 Precision 和 Recall 的调和平均值。定义的准确性、召回率和 F1
当Accuracy、F1和Recall值达到1时,就会得到想要的结果,反之,当这些值都变成0时,得到最差的结果。对于多类分类问题,可以分别计算每个类的precision和recall值,进而分析个体和整体的表现。
- Extract Match精确匹配 (EM)。 EM 是 QA 任务的指标,用于测量与所有真实答案精确匹配的预测。它是 SQuAD 数据集上使用的主要指标。
- Mean Reciprocal Rank平均倒数等级 (MRR)。 MRR 通常用于评估排序算法在 QA 和信息检索 (IR) 任务上的性能。 MRR 定义为
- Hamming-loss(HL)。HL [217] 评估错误分类的实例标签对的分数,其中省略了相关标签或预测了不相关标签。
3.2.2 多标签指标
与单标签文本分类相比,多标签文本分类将文本划分为多个类别标签,类别标签的数量是可变的。这些指标是为单标签文本分类而设计的,不适用于多标签任务。因此,有一些指标是为多标签文本分类而设计的。
- Macro - F1。 Micro - F 1 [218] 是一种考虑所有标签的整体准确性和召回率的措施。 Micro − F 1 定义为:
- Macro - F1。Macro − F 1 计算所有标签的平均 F 1 。与 Micro - F1 对每个示例设置均匀权重不同,Macro - F 1 对平均过程中的所有标签设置相同的权重。形式上,Macro − F 1 被定义为
除了上述评价指标外,还有一些基于等级的评价指标用于 极端多标签分类任务,包括P@K和NDCG@K。
- Precision at Top K (P@K)。P@K是顶部K的精度。对于P@K,每个文本有 一组L个地面真实标签
,,按概率递减的顺序排列.
. k处的精度为
- Normalized Discounted Cummulated Gains (NDCG@K)
4 定量结果
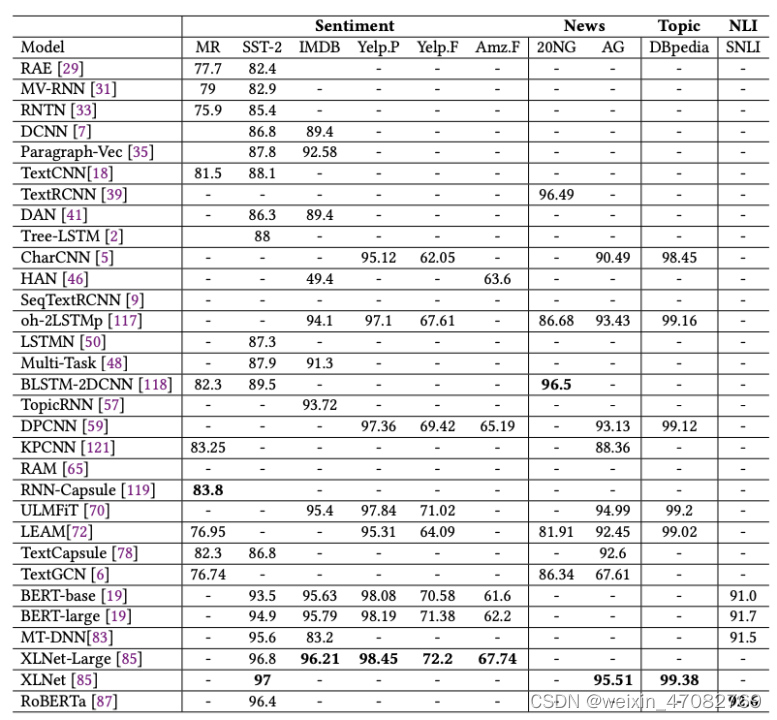
在本节中,我们将主要模型在分类准确率评估的经典数据集上的性能制成表格,如表 5 所示,包括 MR、SST-2、IMDB、Yelp.P、Yelp.F、Amazon.F、 20NG、AG、DBpedia 和 SNLI。我们可以看到,基于 BERT 的模型在大多数数据集上都获得了更好的结果,这意味着如果你需要实现文本分类任务,你可以首先尝试基于 BERT 的模型,除了 MR 和 20NG,它们还没有在基于 BERT 的模型上进行过实验。 RNN-Capsule [119] 在 MR 上获得最好的结果,BLSTM-2DCNN [118] 在 20NG 上获得最好的结果。
表5. 基于深度学习的文本分类模型在主要数据集上的准确度,按分类准确度评估(以出版年份为标准)。粗体字是最准确的。
5 未来的研究挑战
文本分类——作为高效的信息检索和挖掘技术——在管理文本数据中起着至关重要的作用。它利用自然语言处理、数据挖掘、机器学习等技术,自动分类和发现不同的文本类型。文本分类以多种类型的文本作为输入,预训练模型将文本表示为一个向量。然后将向量送入DNN进行训练,直到达到终止条件,最后由下游任务验证训练模型的性能。现有模型已经显示出它们在文本分类中的实用性,但仍有许多可能的改进有待探索。
虽然一些新的文本分类模型反复刷了大部分分类任务的准确率指标,但并不能说明模型是否像人类一样从语义层面“理解”了文本。而且,随着噪声样本的出现,小样本噪声可能导致决策置信度发生大幅变化,甚至导致决策逆转。因此,模型的语义表示能力和鲁棒性需要在实践中得到证明。此外,以词向量为代表的预训练语义表示模型往往可以提高下游NLP任务的性能。现有关于上下文无关词向量迁移策略的研究还比较初步。因此,我们从数据、模型和性能的角度得出结论,文本分类主要面临以下挑战。
5.1 数据
对于文本分类任务,无论是浅层学习还是深度学习方法,数据对于模型性能都是必不可少的。主要研究的文本数据包括多章、短文本、跨语言、多标签、少样本文本。针对这些数据的特点,现有的技术挑战如下:
- Zero-shot/Few-shot learning。当前的深度学习模型过于依赖大量标记数据。这些模型的性能在零样本或少样本学习中受到显着影响。
- The External Knowledge。众所周知,输入到 DNN 中的有益信息越多,其性能就越好。因此,我们认为添加外部知识(知识库或知识图谱)是提升模型性能的有效方式。尽管如此,如何添加以及添加什么仍然是一个挑战。
- 多标签文本分类任务。多标签文本分类需要充分考虑标签之间的语义关系,模型的嵌入和编码是一个有损压缩的过程。因此,如何在训练过程中减少层次语义的损失,保留丰富复杂的文档语义信息,仍然是一个有待解决的问题。具有许多术语的特殊域。
- 特定领域的文本,如金融和医学文本,包含许多特定的词或领域专家可理解的俚语、缩写等,这使得现有的预训练词向量难以处理。
5.2 模型
大多数现有的浅层和深度学习模型结构都被尝试用于文本分类,包括集成方法。 BERT 学习一种语言表示,可用于微调许多 NLP 任务。主要方法是增加数据,提高计算能力,设计训练程序以获得更好的结果。如何在数据和计算资源与预测性能之间进行权衡,值得研究。
5.3 性能
浅层模型和深层模型在大多数文本分类任务中都能取得较好的性能,但其结果的抗干扰能力有待提高。如何实现深度模型的解释也是一个技术挑战。
- 模型的语义鲁棒性。近年来,研究人员设计了许多模型来增强文本分类模型的准确性。然而,当数据集中存在一些对抗性样本时,模型的性能会显着下降。因此,如何提高模型的鲁棒性是当前的研究热点和挑战。
- 模型的可解释性。 DNN 在特征提取和语义挖掘方面具有独特的优势,并在文本分类任务中取得了优异的成绩。然而,深度学习是一种黑盒模型,训练过程难以复现,隐含语义和输出可解释性较差。它使得模型的改进和优化,失去了明确的指导方针。此外,我们无法准确解释为什么模型会提高性能。
6 结论
本文主要介绍了现有的文本分类任务模型,从浅层学习到深度学习。首先,我们用一个汇总表介绍了一些主要的浅层学习模型和深度学习模型。浅层模型主要通过改进特征提取方案和分类器设计来提高文本分类性能。相比之下,深度学习模型通过改进表示学习方法、模型结构以及额外的数据和知识来提高性能。然后,我们介绍了带有汇总表和单标签和多标签任务评估指标的数据集。此外,我们在经典文本分类数据集的不同应用下,在汇总表中给出了领先模型的定量结果。最后,我们总结了文本分类未来可能的研究挑战。

















 2201
2201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









