







Thoughts
PCN和HPCC大致发表于同一时间,两篇论文风格不同,读过PCN再重新审视HPCC,个人觉得HPCC有的地方道理没有讲的非常透彻 。当然,HPCC的出发点不同,阿里应该是想运用INT这个技术改善拥塞控制。PCN中指出的三大基本问题:PFC干扰拥塞识别、拥塞流减速太慢、增速算法慢而不灵活,实际上HPCC借助于INT提供的更精确的信息也在解决这三个问题。 通过控制 inflight 接近 B×T,HPCC也能接近PCN在一个RTT内减到合适速率的效果(特别是Incast场景下)。HPCC增速算法采用的先线性增再乘性增,其实与PCN中先缓慢再激进的增速策略不谋而合。
无论是PCN还是HPCC,二者因为需要获取更多信息来进行拥塞控制(PCN需要交换机根据PAUSE信息标记数据包,接收端采集接收速率,HPCC直接需要全网部署INT技术收集txBytes、timestamp等),都需要对fabric进行较大改动。
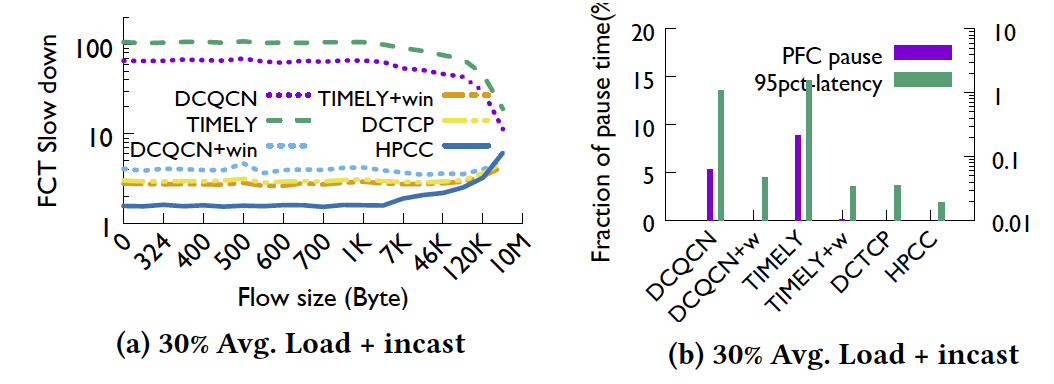
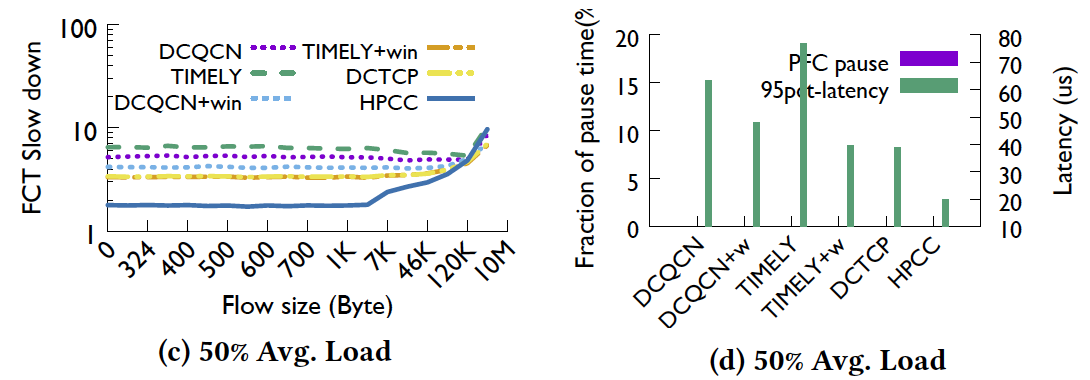
这里放两张论文中的结果图,可以看到其实DCTCP,这种根据队长利用multi-bit信息去做速率调整的协议本身在无损网络中性能并不很差(不考虑kernel bypass),甚至超过DCQCN和Timely很多(小流),论文认为是由于DCTCP的窗口相当于一定程度上限制了inflight bytes。笔者认为,一方面,HPCC相当于把队列长度阈值设成了零,其他拥塞控制协议队列阈值均大于零,其中DCTCP的阈值比DCQCN小得多,对小流来说显然队列长度十分影响latency;另一方面DCQCN与DCTCP相比,DCTCP是根据拥塞程度进行细粒度调整,而DCQCN是根据一个周期内有无拥塞进行调整,这方面也可能造成性能差距。 DCQCN等加了inflight bytes 的限制后性能能够得到很大提升,可见基于 inflight bytes 的速率控制具有很大优势。
HPCC的 trade-off 也可以在图中看出。Load 50% 时,HPCC, the residual capacity is (95%−load×(1+INToverhead)) which is 36.1%. So at 50% load the long flows are 1.24 times slower with HPCC than with other schemes. INT 的 overhead 对长流影响较大,the long flow slowdown is inversely proportional to the residual capacity of the network.
github地址:https://yi-ran.github.io/2020/04/27/HPCC-SIGCOMM-2019/















 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









