






Redis7
https://www.bilibili.com/video/BV13R4y1v7sP/?p=1&vd_source=c1e82f2c861119afab65688242bdf6f3 尚硅谷-阳哥
Remote Dictionary Server,远程字典服务,C语言编写的、高性能(在内存工作)的Key-Value数据库,是MySQL数据库的“带刀护卫”,可以减少MySQL的的IO,提高性能。
Redis操作手册: http://www.redis.net.cn
1.Redis10大数据类型
key的类型统一为字符串,10大数据类型指value的数据类型。
1.String(字符串)
string是redis最基本的类型,一个key对应一个value。
string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象 。
2.List(列表)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双端链表.
3.Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
4.Set(集合)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是 intset 或者 hashtable。
Redis 中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
5.zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
6.Redis GEO
主要用于存储地理位置信息,并对存储的信息进行操作,包括添加地理位置的坐标。获取地理位置的坐标。计算两个位置之间的距离。
根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
7.HyperLogLog
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的。
8.redis位图(bitmap)
由0和1状态表现的二进制位的bit数组
9.redis位域(bitfield)
通过bitfield命令我们可以一次性对多个比特位域进行操作。
10.redis流(bitmap)
Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失.(想要替代MQ)
其中1-5类比较常用,尤其是string。
1.1 Redis键(key)

1.2 数据类型命令
- 命令不区分大小写,而key区分大小写。
- help@数据类型 获取原生命令及用法。如help@string。
1.3 String相关命令
1.set key value

//例子:
//将k1设置为v1并返回原本的值
set k1 v1 get
//设置过期时间为60s
set k1 v1 px 60000
set k1 v1 nx 60
//键k1不存在时设置,存在则不设置
set k1 v1 nx
//键k1存在时更改,不存在时不设置
set k1 v1 xx
// 更改k1的value并保留原过期时间
set k1 v1 keepttl
2.同时设置/获取多个键值
MSET k1 v1 k2 v2
MGET k1 k2
//MSETNX,不存在则设置,注意:这是原子操作,若成功都成功,若失败都失败
MSETNX k1 v1 k3 v3
3.获取/设置指定区间内的值
类似于substring。
//获取k1的value的start位到end位
getrange k1 start end
//从k1的value的第offset位开始覆盖为v2
setrange k1 offset v2
4.数字的增减
set k1 10
// k1值增加1
incr k1
// k1值增加10
incrby k1 10
// k1值减少1
decr k1
// k1值减少10
decrby k1 10
5.获取字符串长度与内容追加
strlen k1
append k1 v2
6.分布式锁
后续再补充,先了解
setnx 不存在则设置值
setex key 过期时间 value //将设置值与过期时间并为原子操作
7.getset
与 set k1 v1 get 相同
1.4 List相关命令
list,单key多value,双端队列,支持左插入尾插入,索引操作等
//左插入,(与插入顺序相反)
lpush key v1 v2 v3
// rpush 尾插
//从左向右取第start到end位元素
lrange key start end
// lpop,rpop 左弹出,右弹出
//index key i 取索引为i的元素
//llen 获取列表长度
//lrem key N v 删除N个值为v的元素
//ltrim key start end 将key截取start到end位并赋值给自身
//rpoplpush list1 list2 list1右弹出并在list2上左插入
//lset key index value 将索引为index的元素值修改为value
//linsert key before/after v1 v2 在列表中已有值v1的前/后插入新值v2
1.5 Hash相关命令
hash 类型,单个key对应一个hashmap
//插入,其中value为hashmap,
hset key field1 v1 field2 v2
// hget key field
// hmget key field1 field2
//hgetall key 遍历key对应的整个hashmap
//hdel key field 删除
//hlen key 获得hashmap的长度
//hexists key field 返回1/0 代表是否存在这个域
//hkeys/hvals key 返回hashmap所有的域名/值
//hincrby key field num 整型的域值增加num
//hincrbyfloat key field num 浮点型的域值增加num
//hsetnx key field 不存在则赋值,存在则无效
场景举例: 用户名为key,field为商品id,值为数量
1.6 Set相关命令
单值多value,无重复
单个集合相关命令
//添加元素(自动去重)
sadd key v1 v2 v3
//遍历集合中的所有元素
smembers key
//判断元素是否在集合中
sismember key v
//删除元素
srem key v1 v2
//获取集合的元素个数
scard key
//随机展示num个元素(不删除),num默认为1
srandmember key num
//随机弹出num个元素并删除
spop key num
//将key1中已存在的v1迁移到key2中(key1中会删除v1)
smove key1 key2 v1
集合运算
//差集,取属于key1但不属于key2的
sdiff key1 key2
//并集
sunion key1 key2
//交集
sinter key1 key2
//返回num个集合求交集后的基数(去重后的个数)
sintercard numkeys key1 key2 key3...
//加上可选参数limit,限制返回值的大小,最大为v
sintercard numkeys key1 key2 key3... limit v
- 场景:
1.抽奖小程序:sadd增加抽奖人员,spop key num随机弹出获奖人员
2.朋友圈相同好友点赞,QQ可能认识的朋友等
1.7 Zset相关命令
Zset,可排序集合,在集合的基础上为每一个元素增加了分数,按分数进行排序。
其底层实现利用哈希表和跳表。
哈希表用于存储 ZSET 中每个成员的分数(score)。每个成员的值(member)作为哈希表的键,分数(score)作为哈希表的值。
利用哈希表可以实现成员的快速查找、更新已经成员的插入与删除等。
跳表用于维护有序集合的排序和范围查询。跳表的节点按分数排序,支持按分数范围的快速检索和遍历。二者针对不同的指令配合工作。
//添加元素
zadd key socre1 v1 score2 v2
//将成员的分数增加指定的增量。如果成员不存在,则先添加它,初始分数为增量值(increment)。
ZINCRBY key increment member
//功能:返回有序集合中指定区间内的成员,按分数从小到大排序。WITHSCORES 选项还会返回成员的分数。
ZRANGE key start stop [WITHSCORES]
//示例:
ZRANGE myzset 0 -1 WITHSCORES
//功能:返回有序集合中指定分数范围内的成员,按分数从小到大排序。WITHSCORES 选项还会返回成员的分数。LIMIT 选项可以限制结果集的数量。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
//示例:
ZRANGEBYSCORE myzset 1 2 WITHSCORES LIMIT 0 2
//功能:返回有序集合中指定分数范围内的成员,按分数从大到小排序。WITHSCORES 选项还会返回成员的分数。LIMIT 选项可以限制结果集的数量。
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
//示例:
ZREVRANGEBYSCORE myzset 2 1 WITHSCORES LIMIT 0 2
//功能:返回成员的分数。如果成员不存在,则返回 nil。
ZScore key member
//示例:
ZSCORE myzset "one"
//功能:计算有序集合中指定分数范围内的成员数量。
ZCOUNT key min max
//示例:
ZCOUNT myzset 1 2
//功能:删除一个或多个成员。
ZREM key member [member ...]
//示例:
ZREM myzset "one" "two"
//功能:返回有序集合中的成员数量。
ZCARD key
//功能:从有序集合中弹出分数最小的一个或多个成员,并返回它们。如果指定 count,则弹出 count 个成员。
ZPOPMIN key [count]
//
功能:从有序集合中弹出分数最大的一个或多个成员,并返回它们。如果指定 count,则弹出 count 个成员。
ZPOPMAX key [count]
//从2个有序集合中弹出分数最小/大的num个数,count是可选参数
ZMPOP 2 zset1 zset2 min/max count num
//获取member的下标
zrank zset member
//获取member的逆序下标
zrevrank zset member
2.Redis持久化
Redis是一个内存数据库,其数据全部存储在内存中。如果进程退出或服务器出现问题,如宕机或断电,不进行持久化操作,存储在内存中的数据将会丢失。Redis提供了两种主要的持久化方式:RDB和AOF。
2.1 RDB持久化
在指定条件下,将内存中的全量数据保存为dump.rdb文件,在重启redis时读取dump.rdb文件将数据恢复。
配置文件
- save seconds changes //配置AOF自动触发的频率
- dir /path //配置文件保存路径
- dbfilename name //配置文件名
触发方式
- 1.自动触发
满足指定条件即自动触发RDB持久化
执行flush操作,也会触发RDB持久化,生成空的dump.rdb文件
redis shutdown指令也会触发一次rdb,保存当前内存中的数据
所以要对dump.rdb文件进行备份并分机隔离,若服务宕机可进行物理恢复。 - 2.手动触发
save:在主程序中执行,阻塞主进程直至持久化工作完成,若数据过大会导致redis服务长时间阻塞,线上禁止使用。
bgsave:在后台异步进行快照操作,不阻塞主进程,而是fork一个子进程(完全复制当前主进程的数据)进行持久化操作,完成后覆盖原dump.rdb文件。
特点
性能比AOF高,rdb文件加载速度比aof文件快得多,适合大规模数据恢复
可以按照业务进行定时备份
会丢失最近一次快照后到宕机前的数据
内存数据全量同步会导致IO量太大影响服务器性能
主进程fork时数据被克隆会导致接近两倍的膨胀以及服务的瞬间延迟
检查修复dump.rdb文件
redis-check-rdb
lastsave 获取最后一次成功执行快照的事件戳
禁用快照
save “”
2.2 AOF持久化
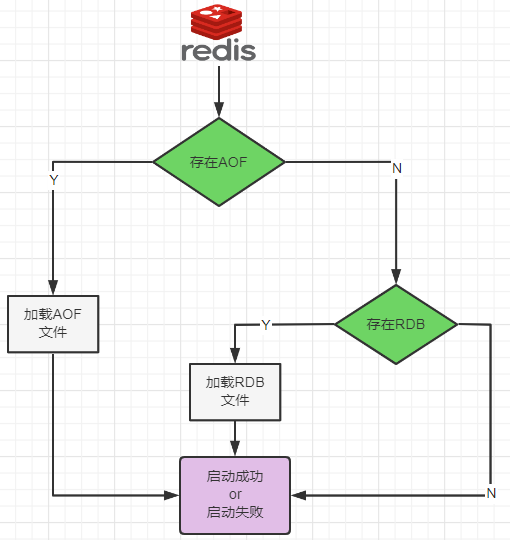
AOF,append only file,以日志的形式记录每一个变更(写/删)操作,保存为appendonly.aof文件,只允许追加文件但不能改写文件,redis启动之初会读取该文件从而重新构建数据库。相比于rdb,aof的性能低但能够更好的保护数据不丢失
优秀博客:https://blog.csdn.net/qq_43437874/article/details/140015896
工作流程
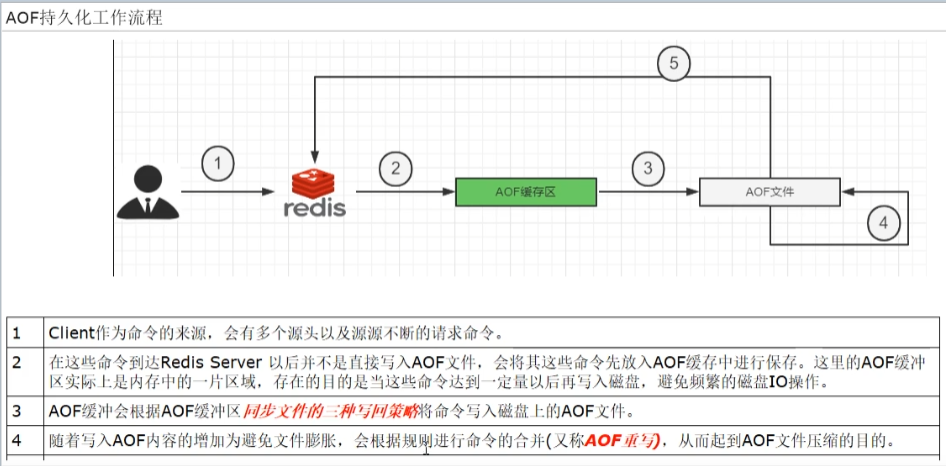
三种写回策略
默认为每秒写回

AOF配置
appendonly yes
appenddirname aofdir 在dir的路径下创建aofdir文件夹,将最终的aof相关文件放在此文件夹中
redis7:mutilpart AOF,包含三个文件,base基本文件,incr增量文件,manifest清单文件,在aof持久化操作中起到不同的作用。
异常修复
若在aof持久化过程中宕机导致aof文件错误
redis-check-aof --fix aof.1.incr.aof 修复错误的aof文件,从而使redis能正常启动
重写机制
AOF文件的内容压缩,只保留可以恢复最终数据的指令。
1:在重写开始前,redis会创建一个“重写子进程”,这个子进程会读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
2:与此同时,主进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
3:当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中
4:当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中
5:重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
- aof重写机制的触发方式
1.自动触发
满足配置中的auto-aof-rewrite-percentage 100及 auto-aof-rewrite-min-size 64MB两个条件时会自动触发
即当前aof文件增大了一倍且文件大于64MB时
2.手动触发
bgrewriteaof指令
小总结

RDB-AOF混合持久化
RDB和AOF可以共存,且以AOF为主导。RDB更适合用于备份大数据库,AOF不断变化不好备份,但数据更为完整。
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件未尾。
RDB镜像做全量持久化,AOF做增量持久化
先使用RDB进行快照存储,然后使用AOF持久化记录所有的写操作,当重写策略满足或手动触发重写的时候,将最新的数据存储为新的RDB记录。这样的话,重启服务的时候会从RDB和AOF两部分恢复数据,既保证了数据完整性,又提高了恢复数据的性能。简单来说:混合持久化方式产生的文件一部分是RDB格式,一部分是AOF格式。---->
AOF包括了RDB头部+AOF混写
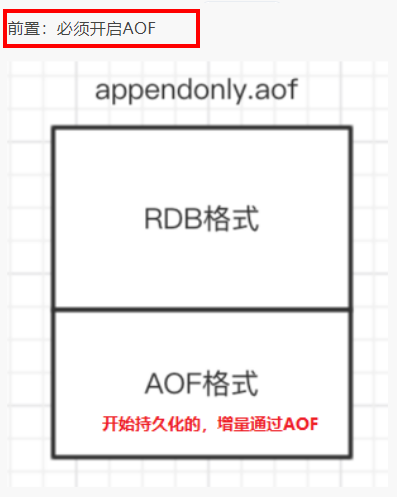
数据恢复加载流程
开启方式
aof-use-rdb-preamble yes
纯缓存模式
save “”
appendonly no
在禁用RDB与AOF情况下,仍能够使用bgsave、bgwriteaof等指令生成对应文件。
3.Redis事务
Redis事务可以一次执行多个命令,是一组命令的集合。一个事务中的所有命令都会被序列化,按顺序串行执行,不会被加塞。
MULTI 开启事务
指令1、指令2...
//DISCAED 放弃事务
EXEC 触发事务,开始执行
- 若在事务定义时候给出错误指令导致事务队列出错,队列中所有指令全部失效。
- 若事务开始执行,只有错误指令会失败,正确指令依然会执行,不能执行回滚。
watch监控
Redis使用Watch来提供乐观锁定,若在提交时发现watch的key版本不是最新的,则无法提交。
指令:watch key
若在事务开启期间,有别的指令修改了watch的key,则整个事务在提交时会返回nil,全部指令都未执行。
一旦执行了EXEC触发事务,之前的watch都会失效
客户端连接丢失,watch全部失效
4.Redis管道
可以利用管道进行批量命令的执行,但是管道不具备原子性,若其中有命令出错,不会影响其余前后命令的执行。
执行事务时,会阻塞其他命令的执行,而管道不会。
管道组装的命令不能过多,否则会影响服务器的性能。
5.Redis复制
主从复制,master以写为主,slave只能读不能写,当master数据变更,会将其自动异步同步到slave服务器上,完成读写分离。数据备份、水平扩容等功能。
Redis配置
- 配从不配主
在slave服务器中主要配置两项:master的ip和端口、masterrauth(密码)。
三大命令:
info replication 查看节点的主从关系与配置信息
replicaof 主库ip 主库端口 在运行期间以命令形式"拜码头",若已连接别的主数据库,则会断开原数据库且删除数据后连接新的主数据库
slaveof no one 停止与其他数据库的连接,转为主数据库
Redis主从复制问题
- 1.从机不能执行写操作
- 2.从机首次连接会将主机信息全部复制,后续动态复制
- 3.主机宕机后,从机一直等待,数据保留
- 4.主机重启后,主从关系仍然存在
- 5.从机宕机后重启,依然能够重新复制完整的主机数据
- 6.命令只有当次生效,配置永久生效
- 7.薪火相传:从机也可作为下一台从机的主机,可同步数据,但仍然不能进行写操作。
复制原理与工作流程

缺点
1.复制延时,信号衰减。主复制到从需要时间,若从机过多会影响主机性能,网络抖动会导致从机接收到新数据过慢。
2.master挂了,需要人工干预,手动重启。
6.Redis哨兵
Redis哨兵巡查监控后台master主机是否正常运行,如果故障了根据投票数自动将某一从库转换为新主库,继续对外服务,实现无人值守运维。
Redis哨兵要用哨兵集群,部署在多台服务器上,不存放数据,只做监控。
重点参数
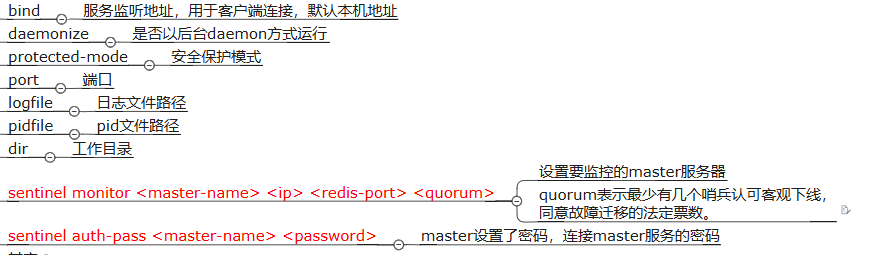
运行流程与选举原理
- 1.单个哨兵向master发送心跳包后,在一定时间内未收到合法回复,则主观下线,并将该信息发送给其他哨兵。配置文件中设置了时间长度,默认30s。
- 2.若master主观下线的数量达到设置值(一般是哨兵个数的一半),则认为master客观下线。
- 3.各个哨兵利用Raft算法选出leader,由leader执行故障迁移。
- 4.故障迁移的三个步骤:1)在slave中选出新master,执行salve no one 2)其余slave成为新master的slave 3)老master也设置为新master的slave
- 5.所有的配置都会被哨兵写进配置文件中进行持久化。
Raft算法简介
每个哨兵都有三个状态,跟随者,中立者,领导者。初始均为中立者,且会向其他哨兵发送想要成为领导者的请求,若接收请求的哨兵是此时中立者,则为请求发送者投票并成为跟随者,若接收请求的哨兵是此时跟随者则不投票。等所有哨兵都发送完请求后,票数最多的哨兵即为领导者。
基本思路就是先到先得。
新master选举规则
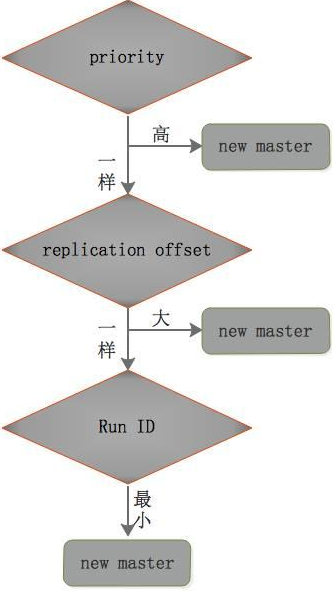
其中priority为配置值,offset为数据偏移量,标识了谁的数据更全。
使用建议
- 哨兵应为集群,保证高可用
- 个数应为奇数,硬件配置要接近
- 哨兵在发现故障及故障迁移过程中,数据无法写入,会导致数据的丢失。---->Redis集群
7.Redis集群
哨兵的所有服务器都保存了全量数据,而单个服务器无法承载过大的数据量,所以可以采取集群的方案。
Redis集群提供支持多个master,每个master都可以有一个或多个slave,而master与slave的分配一般由Redis自行决定,不建议固定。
集群Cluster自带哨兵的故障转移机制,当master宕机,它的slave会自动接替master的位置,对于客户端而言,只需连接集群中任意一个可用节点即可,无需关注该节点的角色,槽位负责分配到各个节点,由对应的集群来负责维护节点、插槽、数据之间的关系。
分片-槽位slot
将整个数据空间分为16384个槽位,每台master负责一部分槽位。数据具体存放于集群中的哪一台master由槽位映射函数决定。
slot的槽位映射一般分为三种方案,1)哈希取余分区,缺点为扩容不便。2)一致性哈希算法分区。采取哈希环,每个master映射到环上的某个点,只存储环中顺时针相邻两个节点上的数据,扩容时只影响新加入节点在环上相邻的节点数据,但是容易产生数据倾斜问题。
3)哈希槽分区。Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis先对key使用crc16算法算出一个结果然后用结果对16384求余数[ CRC16(key) % 16384],这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。
为什么redis集群的最大槽数是16384?
(1)因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,其中包含槽位信息,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
(2)redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots/N很高的话(N表示节点数),bitmap的压缩率就很低。
集群配置流程
-
- 为每个redis示例服务写配置信息
bind 0.0.0.0
daemonize yes //脱离终端,后台运行
protected-mode no //非保护模式,允许非本机ip访问
port 6381
logfile "/myredis/cluster/cluster6381.log"
pidfile /myredis/cluster6381.pid //指定一个文件路径,用于存储 Redis 进程的进程 ID,帮助你管理 Redis 实例的生命周期,并进行进程监控。
dir /myredis/cluster //用于指定 Redis 数据文件的存储目录
dbfilename dump6381.rdb
appendonly yes
appendfilename "appendonly6381.aof"
requirepass 111111 //本机密码
masterauth 111111 //master密码
cluster-enabled yes //启用集群
cluster-config-file nodes-6381.conf
//Redis 集群中的每个节点会将集群状态信息保存到指定的文件中。这些信息对于集群的正常运行是必要的,因为它们帮助节点之间同步集群状态。
//当 Redis 节点启动时,它会检查 cluster-config-file 指定的文件是否存在。
//文件生成:如果文件不存在,Redis 会创建一个新的配置文件,并在集群的运行过程中更新这个文件,以保持集群状态的最新信息。
//信息存储:Redis 在运行期间会定期更新这个文件,以确保它包含最新的集群配置信息。如果 Redis 进程意外终止或重启,集群状态信息会从这个文件中恢复。
//所以该文将无需手动配置,Redis能够自动的完成配置与更新。
cluster-node-timeout 5000 //配置节点的故障检测时间,影响集群的容错能力和自动故障转移行为。
-
- 通过配置文件启动集群中所有的redis实例,启动时要加参数-c,开启路由!
-
- 构建集群关系
redis-cli -a password --cluster create : : … --cluster-replicas 。其中,:, :等表示各个Redis节点的IP地址和端口号,表示每个主节点对应的从节点数量。
- 构建集群关系
- 4.查看集群状态。
cluster nodes : 列出集群当前已知的所有节点以及相关信息。
cluster info

INFO replication :用于获取与复制相关的统计信息和状态,检查主节点和从节点的复制状态。
主从容错切换
主节点宕机后,slave会自动顶替成为master,原master重启后会成为新master的slave。
可手动调整节点的从属关系:cluster failover,会调整为故障前的主从关系
不保证数据的强一致性,在slave上位过程中会产生写丢失。
主从扩容
1.新建redis配置文件并启动实例。
2.将新的master接入集群
redis-cli -a 密码 --cluster add-node 自己的ip:端口号 集群介绍人ip:端口号
3.重新分配槽号
redis cli -a 密码 --cluster reshard ip:端口号
执行后输入要移动的槽数量以及移向他的master在集群中的id
4.为新master分配slave
redis-cli -a 密码 --cluster add-node 从机ip:端口号 主机ip:端口号 --cluster-slave --cluster-master-id 主机在集群中的id
主从缩容
1.获得要缩容的节点id
2.删除其中的从节点
命令:redis-cli -a 密码 --cluster del-node ip:从机端口 从机节点ID
3.将要删除的主机槽号分配给别的主机
redis cli -a 密码 --cluster reshard ip:端口号(要接受的主机)
执行后输入要移动的槽数量以及移向他的master在集群中的id(要删除的主机)
4.删除槽位为0的那个节点(槽位为0会自动的成为别的节点的slave)
命令:redis-cli -a 密码 --cluster del-node ip:端口 节点ID
集群常用命令
1.不在同一台主机上的键不能使用mget更批处理命令,若有此需求可使用通配符解决。
2.一些常用命令
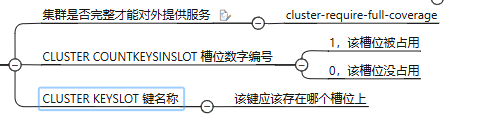
8.SpringBoot集成Redis
集成RedisTemplate
连接单机
1.写yml文件配置redis相关信息
2.写配置类,配置RedisTemplate的序列化器
3.在业务中利用RedisTemplate调用相关api进行CURD
连接集群
对于Java服务端,仅需要改写yml文件即可连接redis集群
spring.redis.password=111111
# 获取失败 最大重定向次数
spring.redis.cluster.max-redirects=3
//连接池中最大可分配连接数量
spring.redis.lettuce.pool.max-active=8
//获取连接时的最大等待时间。-1为无限等待
spring.redis.lettuce.pool.max-wait=-1ms
//定义连接池中最大空闲连接数。若大于此值会关闭多余的连接
spring.redis.lettuce.pool.max-idle=8
//spring.redis.lettuce.pool.min-idle,若大于此值,不会主动创建新的空闲连接
spring.redis.lettuce.pool.min-idle=0
//配置集群的ip:端口
spring.redis.cluster.nodes=所有节点ip:端口
// 支持集群拓扑动态感应刷新,自适应拓扑刷新是否使用所有可用的更新,默认false关闭
// 此项若不配置,若某一master宕机,而服务端感知不到,则操作可能会一直一直等待直至响应超时报错
spring.redis.lettuce.cluster.refresh.adaptive=true
// 定时刷新 2s后连接不上会刷新节点拓扑图
spring.redis.lettuce.cluster.refresh.period=2000















 2304
2304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









