






1.Redis单线程vs多线程
Redis的工作线程是单线程,但整体的Redsi是多线程的。Redis4之后开启了多线程机制,用于IO多路复用以及异步删除、持久化(fork子进程)等。但是Redis命令的执行依旧是由主线程串行执行的,因此在多线程下操作 Redis 不会出现线程安全的问题。
- Redis目前的瓶颈不在于主线程,而主要在于网络带宽以及内存。
IO多路复用
Redis提前创造多个线程用处处理网络IO,将耗时的IO操作采用多线程执行,解析出请求命令后再由主线程串行执行,提高主线程执行的效率。

Redis6、7将网络数据读写、请求协议解析通过多个IO线程的来处理,对于真正的命令执行来说,仍然是单线程的。
多线程的开启
1.设置io-thread-do-reads配置项为yes,表示启动多线程。
2。设置线程个数。关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。
Redis为什么快?
1.Redis是内存操作
2.数据结构简单,查找和操作的时间复杂度多在O(1)
3.多路复用和非阻塞IO:多个IO线程监听多个socket连接,主线程主要负责串行处理请求,减少了线程切换的开销以及IO阻塞。
IO多路复用+epoll函数使用 先粗略了解,后续详细解释。
2.BigKey
2.1 MoreKey
环境准备
在后端服务停机状态下,Redis插入大量数据方法:
1.利用Linux Bash生成插入大量数据的Redis命令
2.利用Redis 管道命令插入数据
方法
key * 在大量key情况下非常耗时,且Redis执行为单线程,会导致业务的崩溃。
利用scan命令,基于游标,每次读取一部分key,类似于mysql的limit。
SCAN 返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标。
第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
2.2 BigKey
多大算大?
BigKey一般由于日积月累的累计。String的value在10KB以上就是bigkey,集合元素个数超过5000个就是bigkey
BigKey的危害
1.会导致集群服务器的内存不均,迁移困难
2.超时删除
3.网络流量阻塞
如何统计bigkey?
1.在服务外执行:redis-cli --bigkeys 给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
2.memory usage 来计算键值的字节数
如何删除?
1.String
一般用del,如果过于庞大使用unlink
2.hash
使用hscan,逐步获取一部分键值对,再使用hdel逐个删除这次扫描到的field

list、set、zset都使用类似的方法,结合自己的scan及对应的删除集合元素的命令来逐步删除,最后再整个删除。
BigKey调优
修改配置文件中的一些参数
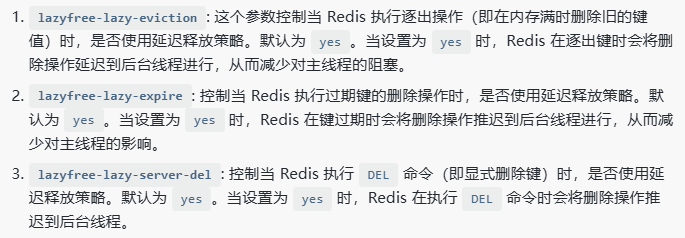
3.缓存双写一致性
读写缓存中的写操作有两种策略,同步直写与异步缓写。
若想要保证缓存与数据库中的数据一致性,就要采取同步直写策略。在更新完数据库后同步写redis缓存。
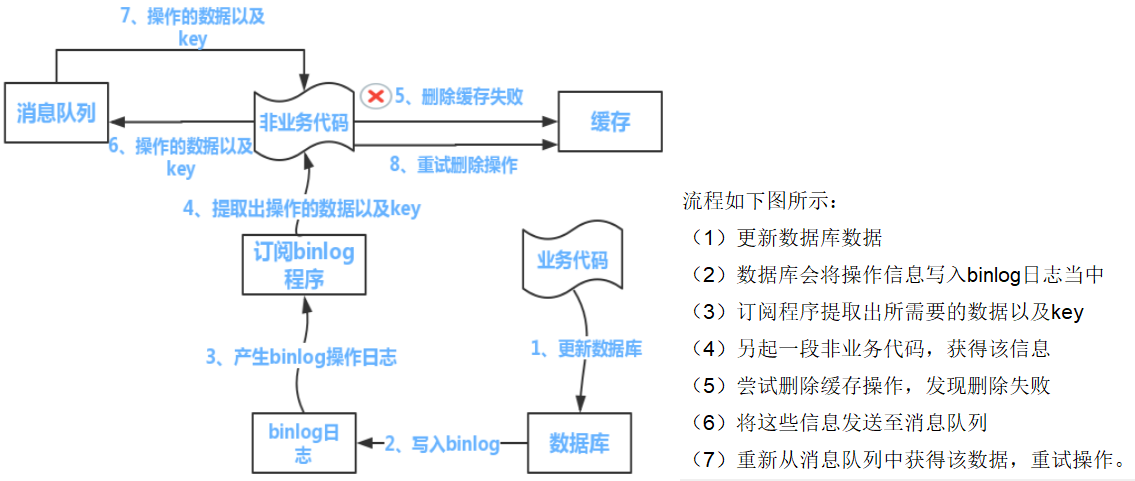
若允许redis与数据库数据延迟一致,如物流信息等,可借助kafka等消息中间件,订阅sql的binlog,利用kafka实现redis的重写重试。
3.1双检加锁
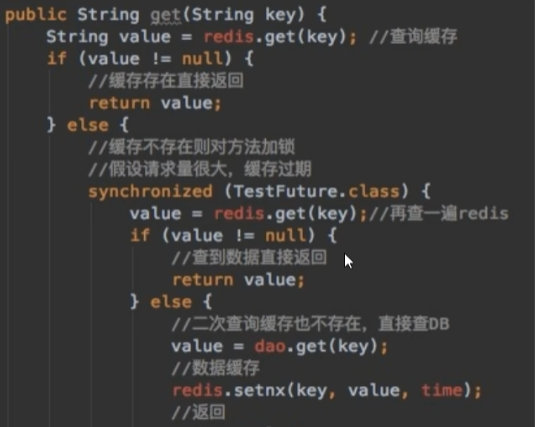
先判断缓存是否命中,若未命中,再加锁,二次判断缓存是否命中,若仍然未命中,再读取数据库并写回redis。
在高并发下,可以减少对同一不存在的key导致的数据库的IO,且尽量保证了数据的一致性。
3.2双写一致性
- 不可能保证数据的强一致性,只能保证最终一致性。
- 一般会将数据库信息作为数据底单,若出现不一致,以数据库数据为准。
- 若服务可停机,挂牌报错,停机后单线程对redis进行数据重写。
3.3更新策略
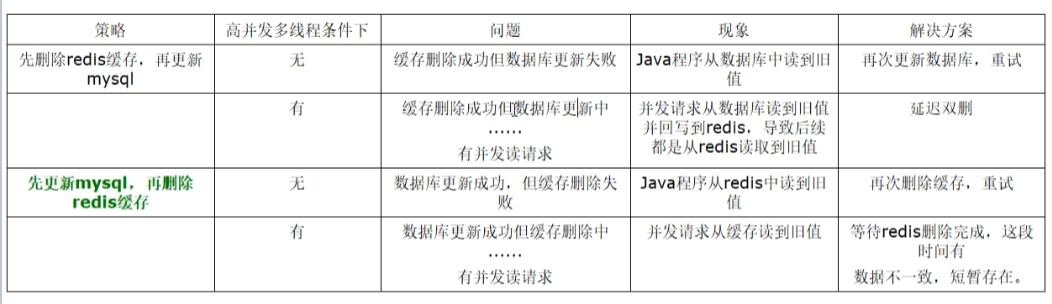
- 1.先更新数据库,再更新缓存
问题1:若数据库更新成功,redis更新失败,会导致数据不一致
问题2:线程1更新数据库值100,线程2更新数据库值80,线程2更新redis值80,线程1更新redis值100,导致数据不一致。 - 2.先更新缓存,再更新数据库。
问题1:一般将数据库信息作为数据底单,若redis写成功数据库写失败会导致数据库的信息不是最新的。
问题2:多线程下很容易导致数据不一致。 - 3.先删除缓存,再更新数据库。
问题:删除缓存后,若更新数据库还未完成,就有新的线程读取数据库旧值并重写回redis,会导致数据不一致。
解决:延时双删。先删除缓存,再更新数据库,再等待一段时间,再次删除缓存。
在等待的这段时间内,要保证查到旧值的线程重写回了redis,这样第二次删除才有意义。
缺点:1.在延时双删的过程中,很可能读到旧值。2.等待的这段时间不好确定。太长很降低性能,太短无效。 - 4.先更新数据库,再删除缓存。
建议使用这种方法
问题1:若在删除之前查询命中,读到的就是旧值。
问题2:若删除缓存失败,则redis中都是旧值。
解决问题2:消息中间件

总结
3.3 工程案例
问题:redis如何知道mysql有变动?
1.在业务逻辑中,mysql变动完成后删除redis的缓存,并在查询时采用双检加锁,防止mysql压力过大。
2.延时双删
3.利用中间件canal,监测mysql的binlog日志的变动,并将该变动同步到redis
3.3.1 mysql的主从复制
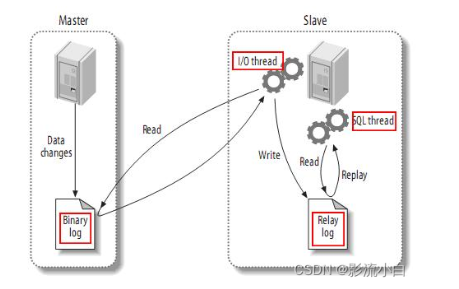
MySQL的主从复制将经过如下步骤:
1、当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
2、salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
3、同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
4、slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
5、salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地写入,使得其数据和主服务器保持一致;
6、最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
3.3.2 canal工作原理
Canal的工作原理主要基于MySQL的binlog(binary log)机制。MySQL的binlog记录了所有对数据库进行更改的SQL语句,这些日志可以用于数据恢复、主从复制等。Canal通过模拟MySQL的从库(slave),读取并解析这些binlog,从而实现对数据库变更的监听和捕获。以下是Canal的工作原理的详细步骤:
- 模拟MySQL Slave:
Canal伪装成MySQL的从库,通过MySQL的主从复制协议连接到MySQL的主库(master)。通过这种方式,Canal能够像MySQL的从库一样,从主库获取binlog日志。 - 读取Binlog:
一旦连接成功,Canal开始从MySQL主库读取binlog日志。MySQL主库会将所有的binlog事件(如INSERT、UPDATE、DELETE等)发送给Canal。 - 解析Binlog:
Canal接收到binlog日志后,会对这些日志进行解析。解析的内容包括表名、操作类型(INSERT、UPDATE、DELETE)、变更的数据等。 - 数据处理和过滤:
Canal可以根据用户的配置,对解析后的数据进行处理和过滤。用户可以指定只监听特定的数据库或表,或者对数据进行特定的转换和处理。 - 数据推送:
解析和处理后的数据可以通过多种方式推送给订阅者。常见的推送方式包括发送到消息队列(如Kafka、RabbitMQ)、写入到其他数据库(如Elasticsearch、HBase)等。 - 确认和回滚:
Canal支持对处理后的数据进行确认(ack)和回滚(rollback)。如果数据处理成功,Canal会发送ack确认,表示这批数据已经成功处理。如果数据处理失败,可以进行回滚,重新处理这批数据。 - 高可用性和容错:
Canal支持集群模式,可以通过多个Canal实例提供服务,增加系统的可用性和稳定性。Canal还支持断点续传,即使Canal服务重启,也可以从上次中断的地方继续读取binlog。
通过上述步骤,Canal实现了对MySQL数据库变更的实时监听和捕获,并将变更数据推送给订阅者,从而实现数据同步、缓存更新、搜索引擎索引更新等功能。
3.3.4 环境准备
- 配置mysql
确保你的MySQL实例已经开启了binlog,并且binlog的格式为ROW。(修改mysql的my.cnf或my.ini)
2.mysql中新增canal用户
DROP USER IF EXISTS 'canal'@'%';
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';
FLUSH PRIVILEGES;
- 下载canal并配置
canal.instance.master.address:MySQL服务器地址和端口。
canal.instance.dbUsername 和 canal.instance.dbPassword:用于连接MySQL的用户名和密码。
canal.instance.connectionCharset:数据库的字符集,通常为UTF-8。
canal.instance.tsdb.enable:是否启用表结构历史记录功能,建议开启。
- 启动canal
在Canal的根目录下,运行bin/startup.sh脚本启动Canal服务 - 编写canal客户端代码
5.1 添加依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
5.2 yml文件
# ========================alibaba.druid=====================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.druid.test-while-idle=false
5.3 jedis工具类(通过jedis连接池获取与redis的连接)
package com.atguigu.canal.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/*
redis工具类 使用jedis连接redis
*/
public class RedisUtils
{
public static final String REDIS_IP_ADDR = "192.168.186.128";
public static final String REDIS_pwd = "111111";
public static JedisPool jedisPool;
//静态代码块,初始化连接池
static {
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPool=new JedisPool(jedisPoolConfig,REDIS_IP_ADDR,6379,10000,REDIS_pwd);
}
//获取Jedis对象
public static Jedis getJedis() throws Exception {
if(null!=jedisPool){
return jedisPool.getResource();
}
throw new Exception("Jedispool is not ok");
}
}
5.4 业务类
package com.atguigu.canal.biz;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.atguigu.canal.utils.RedisUtils;
import redis.clients.jedis.Jedis;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/*
redis mysql 双写一致性代码
*/
public class RedisCanalClientExample {
public static final Integer _60SECONDS = 60;
// redis地址
public static final String REDIS_IP_ADDR = "192.168.186.128";
//redis插入数据方法
private static void redisInsert(List<Column> columns) {
JSONObject jsonObject = new JSONObject();
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
try (Jedis jedis = RedisUtils.getJedis()) {
jedis.set(columns.get(0).getValue(), jsonObject.toJSONString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
// redis删除数据方法
private static void redisDelete(List<Column> columns) {
JSONObject jsonObject = new JSONObject();
for (Column column : columns) {
jsonObject.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
try (Jedis jedis = RedisUtils.getJedis()) {
jedis.del(columns.get(0).getValue());
} catch (Exception e) {
e.printStackTrace();
}
}
}
// redis更新数据方法
private static void redisUpdate(List<Column> columns) {
JSONObject jsonObject = new JSONObject();
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
try (Jedis jedis = RedisUtils.getJedis()) {
jedis.set(columns.get(0).getValue(), jsonObject.toJSONString());
System.out.println("---------update after: " + jedis.get(columns.get(0).getValue()));
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
//获取变更的row数据
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error,data:" + entry.toString(), e);
}
//获取变动类型
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.INSERT) {
redisInsert(rowData.getAfterColumnsList());
} else if (eventType == EventType.DELETE) {
redisDelete(rowData.getBeforeColumnsList());
} else {//EventType.UPDATE
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
// 主方法
public static void main(String[] args) {
System.out.println("---------O(∩_∩)O哈哈~ initCanal() main方法-----------");
//=================================
// 创建链接canal服务端
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(REDIS_IP_ADDR,
11111), "example", "", "");
int batchSize = 1000;
//空闲空转计数器
int emptyCount = 0;
System.out.println("---------------------canal init OK,开始监听mysql变化------");
try {
connector.connect();
//connector.subscribe(".*\\..*");
connector.subscribe("atguigu_jdbc.t_user");
connector.rollback();//回滚到未进行ack确认的地方,确保从最后一个未确认的位置开始获取数据。
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
System.out.println("我是canal,每秒一次正在监听:" + UUID.randomUUID().toString());
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//计数器重新置零
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("已经监听了" + totalEmptyCount + "秒,无任何消息,请重启重试......");
} finally {
connector.disconnect();
}
}
}
3.3.5 面试题
1、如果我想实现mysql有了更改后,立即同步到redis,如何实现?
2、如果我能容许一定的旧值读取,应当用何种双写一致性策略降低数据最终不一致的风险到最低?
两问答案一致
答:要实现MySQL有更新后立即同步到Redis,可以采用消息队列结合Canal的方式。首先,通过Canal监听MySQL的binlog,一旦数据库有变更,Canal即可捕获这些变更事件。然后,将这些变更事件发送到消息队列(如Kafka、RabbitMQ等)中。最后,编写一个消费者程序从消息队列中读取这些变更事件,并根据事件内容更新Redis缓存。
相比于延时双删,这种方式的优点是能够实现近乎实时的数据同步,同时通过消息队列解耦了数据库变更事件的捕获与缓存更新操作,提高了系统的稳定性和扩展性。此外,即使Redis更新操作失败,也可以通过消息队列中的事件重新触发更新操作,增强了数据同步的可靠性。
4.布隆过滤器
布隆过滤器用于在大量数据中快速判断某个key是否在库中存在,使用场景例如黑白名单校验、解决缓存穿透等。
4.1 定义
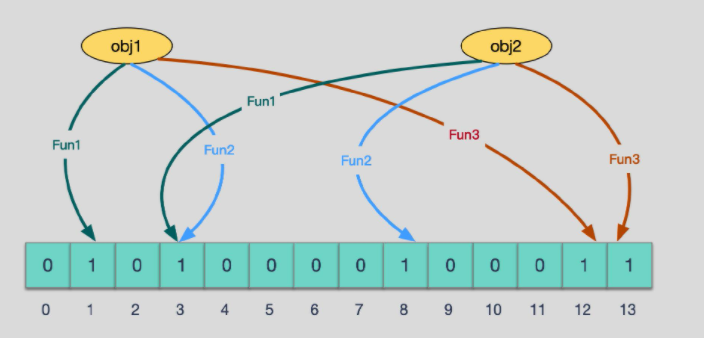
布隆过滤器,bloom filter,本质上是初始值均为0的bitmap,通过将已知存在的key经过多个hash函数并对bitmap长度取余后得到的索引位置1来标记该key的存在。由于hash冲突的出现,布隆过滤器不支持删除操作,且有一定的误判率。
判定有,不一定有,判定无,则一定无。
4.2 解决缓存穿透
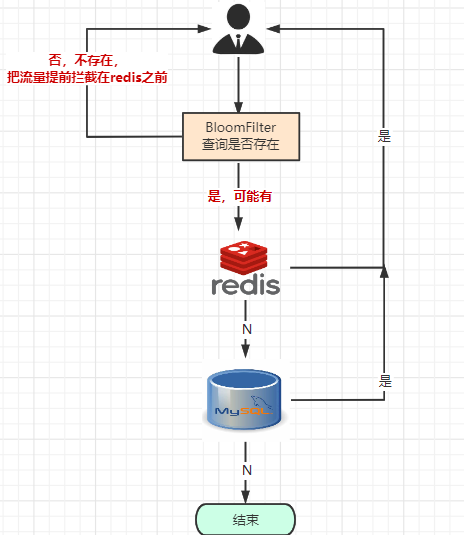
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则再查询Mysql数据库。
布谷鸟过滤器,解决了布隆过滤器不能删除的问题(简单了解)
5.缓存预热、穿透、击穿、雪崩
5.1 缓存预热
利用@PostConstruct初始化数据
@PostConstruct注解标注方法,当Bean都加载到容器之后,会自动执行Bean中有@PostConstruct注解的方法。
5.2 缓存雪崩
对于后端开发人员,缓存雪崩主要指redis中有大量的key同时失效,导致mysql的压力过大。
- 预防+解决
1.key设置为永不过期或在过期时间基础上增加一个随机事件,使得错峰过期
2.多缓存结合预防雪崩,redis+ehcache本地缓存
3.服务降级
4.用aliyun数据库redis版
5.3 缓存穿透
若有一条数据,redis与mysql都不存在,而黑客故意大量查询不存在的key,会导致mysql的崩盘。
5.3.1 解决方案:
1.空对象缓存
定义一个约定的缺省值,若redis不存在该key,mysql也查不到的话,也让redis存入刚刚查不到的key并将值设为缺省值(设置过期时间)并保护mysql。
缺陷:若每次攻击的key不同,仍然会导致redis失效,mysql的崩盘,redis中存放大量无用数据。
可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。
2.guava过滤器
谷歌实现的布隆过滤器,减少与redis的耦合,并简化开发。
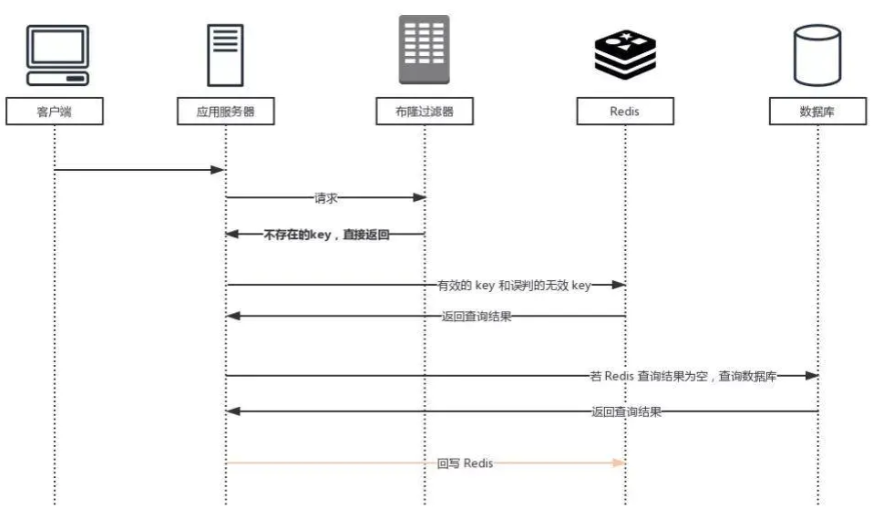
guava过滤器实战:
1.添加依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
2.测试类helloworld
@Test
public void testGuavaWithBloomFilter()
{
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100,0.03);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
}
3.实际使用时,在项目启动时,应该在缓存预热阶段就将guava过滤器的白名单准备好。
4.创建布隆过滤器的三个参数:键的动态部分的数据类型,数据量,可接受的误判率,guava过滤器会根据参数设置合适大小的bitmap以及合适个数的哈希函数。
5.4 缓存击穿
和缓存穿透不同,缓存击穿指某热点key正好失效,而此时大量请求涌入redis,查询不到从而打爆mysql。
预防
1.互斥更新,双检加锁,当热key失效,因为互斥锁的存在,只有第一条会走mysql,其余会在等待锁释放后再次走缓存。
2.多缓存,差异化失效时间

主要业务逻辑:
@Service
@Slf4j
public class JHSTaskService
{
public static final String JHS_KEY="jhs";
public static final String JHS_KEY_A="jhs:a";
public static final String JHS_KEY_B="jhs:b";
@Autowired
private RedisTemplate redisTemplate;
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
private List<Product> getProductsFromMysql() {
List<Product> list=new ArrayList<>();
for (int i = 1; i <=20; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
@PostConstruct
public void initJHSAB(){
log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List<Product> list=this.getProductsFromMysql();
//先更新B缓存
this.redisTemplate.delete(JHS_KEY_B);
this.redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list);
this.redisTemplate.expire(JHS_KEY_B,20L,TimeUnit.DAYS);
//再更新A缓存
this.redisTemplate.delete(JHS_KEY_A);
this.redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list);
this.redisTemplate.expire(JHS_KEY_A,15L,TimeUnit.DAYS);
//间隔一分钟 执行一遍(真实时间为更新周期)
try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
log.info("runJhs定时刷新双缓存AB两层..............");
}
},"t1").start();
}
}
@RestController
@Slf4j
@Api(tags = "聚划算商品列表接口")
public class JHSProductController
{
public static final String JHS_KEY_A="jhs:a";
public static final String JHS_KEY_B="jhs:b";
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping(value = "/pruduct/findab",method = RequestMethod.GET)
@ApiOperation("防止热点key突然失效,AB双缓存架构")
public List<Product> findAB(int page, int size) {
List<Product> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(JHS_KEY_A, start, end);
if (CollectionUtils.isEmpty(list)) {
log.info("=========A缓存已经失效了,记得人工修补,B缓存自动延续5天");
//用户先查询缓存A(上面的代码),如果缓存A查询不到(例如,更新缓存的时候删除了),再查询缓存B
this.redisTemplate.opsForList().range(JHS_KEY_B, start, end);
//if B缓存失效,TODO 走DB查询
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
}
总结
6.分布式锁
若后端业务服务是分布式多台不同的JVM,单机的线程锁synchronized不再起作用,此时需要分布式锁。
1.分布式锁的必要特性

手写分布式锁
版本1
利用setnx实现分布式锁
@Service
@Slf4j
public class InventoryService
{
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String port;
public String sale()
{
String retMessage = "";
//锁名
String key = "zzyyRedisLock";
//锁值,随机的id+线程id
String uuidValue = IdUtil.simpleUUID()+":"+Thread.currentThread().getId();
//利用setnx实现分布式锁,若存在会返回set成功,返回true
//若分布式锁的redis微服务宕机,而锁没有释放,则无法解锁,需要给锁加入过期时间
//给锁加过期时间必须为原子操作,否则还未加过期时间就宕机,未解决问题
while(!stringRedisTemplate.opsForValue().setIfAbsent(key, uuidValue,30L,TimeUnit.SECONDS)){
//暂停20毫秒(否则cpu压力过大!)
try { TimeUnit.MILLISECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
}
try
{
//1 查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//2 判断库存是否足够
Integer inventoryNumber = result == null ? 0 : Integer.parseInt(result);
//3 扣减库存
if(inventoryNumber > 0) {
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(--inventoryNumber));
retMessage = "成功卖出一个商品,库存剩余: "+inventoryNumber;
System.out.println(retMessage);
}else{
retMessage = "商品卖完了,o(╥﹏╥)o";
}
}finally {
// 释放锁
//若线程1的业务在过期时间内未完成,此时锁过期释放,线程2拿到锁,此时容易导致线程1释放线程2的锁
//解决:只允许删除自己的锁,不允许删除别人的锁
if(stringRedisTemplate.opsForValue().get(key).equalsIgnoreCase(uuidValue)){
stringRedisTemplate.delete(key);
}
}
return retMessage+"\t"+"服务端口号:"+port;
}
}
版本2
版本1问题:finally中的判断与删除非原子操作,未解决问题
解决:lua脚本保证原子性
finally {
// 将判断+删除自己的合并为lua脚本保证原子性
String luaScript =
"if (redis.call('get',KEYS[1]) == ARGV[1]) then " +
"return redis.call('del',KEYS[1]) " +
"else " +
"return 0 " + //当前的锁不是我的锁,不能删除
"end";
stringRedisTemplate.execute(new DefaultRedisScript<>(luaScript, Boolean.class), Arrays.asList(key), uuidValue);
}
lua脚本helloworld
EVAL “lua脚本” keysnum key1 key2… arg1 arg2 arg3…
lua脚本:
// lua脚本必须有return
//set get
"redis.call('SET', KEY[1], ARGV[1]) return redis.call('GET', KEY[1])"
// if else(必须有then)
"if (redis.call('get',KEYS[1]) == ARGV[1]) then " +
"return redis.call('del',KEYS[1]) " +
"else " +
"return 0 " +
"end"
版本3
版本2已经很好了,但不支持可重入,对于一些业务逻辑要求无法满足
setnx只能解决是否存在,无法解决可重入的问题,所以使用hset,锁名不变,field为uuid+线程id,值为获取锁的次数,获取一次+1.释放一次-1,当值为0时即可释放,实现可重入。
结合工厂设计模式,添加分布式锁工厂组件,定义获取不同类型的分布式锁的方法,将随机的uuid指放在锁工厂中(所有不同线程拿到的uuid是一样的,但是线程id不同),因为若每次加锁都生成一个不同的uuid,则对锁的+1-1时无法定位到同一个值。
//分布式锁工厂
@Component
public class DistributedLockFactory
{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private String lockName;
private String uuidValue;
public DistributedLockFactory()
{
this.uuidValue = IdUtil.simpleUUID();//UUID
}
public Lock getDistributedLock(String lockType)
{
if(lockType == null) return null;
if(lockType.equalsIgnoreCase("REDIS")){
lockName = "zzyyRedisLock";
return new RedisDistributedLock(stringRedisTemplate,lockName,uuidValue);
} else if(lockType.equalsIgnoreCase("ZOOKEEPER")){
//TODO zookeeper版本的分布式锁实现
return new ZookeeperDistributedLock();
} else if(lockType.equalsIgnoreCase("MYSQL")){
//TODO mysql版本的分布式锁实现
return null;
}
return null;
}
}
//分布式锁,实现Lock接口
public class RedisDistributedLock implements Lock
{
private StringRedisTemplate stringRedisTemplate;
private String lockName;
private String uuidValue;
private long expireTime;
public RedisDistributedLock(StringRedisTemplate stringRedisTemplate, String lockName,String uuidValue)
{
this.stringRedisTemplate = stringRedisTemplate;
this.lockName = lockName;
this.uuidValue = uuidValue+":"+Thread.currentThread().getId();
this.expireTime = 30L;
}
@Override
public void lock()
{
this.tryLock();
}
@Override
public boolean tryLock()
{
try
{
return this.tryLock(-1L,TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException
{
if(time != -1L)
{
expireTime = unit.toSeconds(time);
}
String script =
"if redis.call('exists',KEYS[1]) == 0 or redis.call('hexists',KEYS[1],ARGV[1]) == 1 then " +
"redis.call('hincrby',KEYS[1],ARGV[1],1) " +
"redis.call('expire',KEYS[1],ARGV[2]) " +
"return 1 " +
"else " +
"return 0 " +
"end";
System.out.println("lockName: "+lockName+"\t"+"uuidValue: "+uuidValue);
while (!stringRedisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), uuidValue, String.valueOf(expireTime)))
{
try { TimeUnit.MILLISECONDS.sleep(60); } catch (InterruptedException e) { e.printStackTrace(); }
}
return true;
}
@Override
public void unlock()
{
String script =
"if redis.call('HEXISTS',KEYS[1],ARGV[1]) == 0 then " +
"return nil " +
"elseif redis.call('HINCRBY',KEYS[1],ARGV[1],-1) == 0 then " +
"return redis.call('del',KEYS[1]) " +
"else " +
"return 0 " +
"end";
System.out.println("lockName: "+lockName+"\t"+"uuidValue: "+uuidValue);
Long flag = stringRedisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), uuidValue, String.valueOf(expireTime));
if(flag == null)
{
throw new RuntimeException("没有这个锁,HEXISTS查询无");
}
}
//=========================================================
@Override
public void lockInterruptibly() throws InterruptedException
{
}
@Override
public Condition newCondition()
{
return null;
}
}
//业务代码
@Service
@Slf4j
public class InventoryService
{
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String port;
@Autowired
private DistributedLockFactory distributedLockFactory;
public String sale()
{
String retMessage = "";
Lock redisLock = distributedLockFactory.getDistributedLock("redis");
redisLock.lock();
try
{
//1 查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//2 判断库存是否足够
Integer inventoryNumber = result == null ? 0 : Integer.parseInt(result);
//3 扣减库存
if(inventoryNumber > 0) {
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(--inventoryNumber));
retMessage = "成功卖出一个商品,库存剩余: "+inventoryNumber;
System.out.println(retMessage);
this.testReEnter();
}else{
retMessage = "商品卖完了,o(╥﹏╥)o";
}
}catch (Exception e){
e.printStackTrace();
}finally {
redisLock.unlock();
}
return retMessage+"\t"+"服务端口号:"+port;
}
private void testReEnter()
{
Lock redisLock = distributedLockFactory.getDistributedLock("redis");
redisLock.lock();
try
{
System.out.println("################测试可重入锁####################################");
}finally {
redisLock.unlock();
}
}
}
版本4
版本2,3的问题:若在业务未完成时锁过期,则会出现双线程持一把锁的现象,版本2只是解决了锁的误删,而为解决误操作(如超卖)问题。
解决:自动续期,设置定时任务,每1/3过期时间查看业务是否完成,若未完成,就将过期时间更新。
public class RedisDistributedLock implements Lock
{
private StringRedisTemplate stringRedisTemplate;
private String lockName;//KEYS[1]
private String uuidValue;//ARGV[1]
private long expireTime;//ARGV[2]
public RedisDistributedLock(StringRedisTemplate stringRedisTemplate,String lockName,String uuidValue)
{
this.stringRedisTemplate = stringRedisTemplate;
this.lockName = lockName;
this.uuidValue = uuidValue+":"+Thread.currentThread().getId();
this.expireTime = 30L;
}
@Override
public void lock()
{
tryLock();
}
@Override
public boolean tryLock()
{
try {tryLock(-1L,TimeUnit.SECONDS);} catch (InterruptedException e) {e.printStackTrace();}
return false;
}
//加锁的
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException
{
if(time != -1L)
{
this.expireTime = unit.toSeconds(time);
}
// 若key不存在,则加锁,若存在且为我的锁,则+1
String script =
"if redis.call('exists',KEYS[1]) == 0 or redis.call('hexists',KEYS[1],ARGV[1]) == 1 then " +
"redis.call('hincrby',KEYS[1],ARGV[1],1) " +
"redis.call('expire',KEYS[1],ARGV[2]) " +
"return 1 " +
"else " +
"return 0 " +
"end";
System.out.println("script: "+script);
System.out.println("lockName: "+lockName);
System.out.println("uuidValue: "+uuidValue);
System.out.println("expireTime: "+expireTime);
// 若未获取锁,则等待50ms
while (!stringRedisTemplate.execute(new DefaultRedisScript<>(script,Boolean.class), Arrays.asList(lockName),uuidValue,String.valueOf(expireTime))) {
TimeUnit.MILLISECONDS.sleep(50);
}
//重新设置过期时间(续费)
this.renewExpire();
return true;
}
/**
*干活的,实现解锁功能
*/
@Override
public void unlock()
{
//锁不存在,return nil,锁存在,则-1,若-1后==0,则删除锁
String script =
"if redis.call('HEXISTS',KEYS[1],ARGV[1]) == 0 then " +
" return nil " +
"elseif redis.call('HINCRBY',KEYS[1],ARGV[1],-1) == 0 then " +
" return redis.call('del',KEYS[1]) " +
"else " +
" return 0 " +
"end";
// nil = false 1 = true 0 = false
System.out.println("lockName: "+lockName);
System.out.println("uuidValue: "+uuidValue);
System.out.println("expireTime: "+expireTime);
Long flag = stringRedisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName),uuidValue,String.valueOf(expireTime));
if(flag == null)
{
throw new RuntimeException("This lock doesn't EXIST");
}
}
//设置定时任务,每10s
private void renewExpire()
{
// 若当前线程持有的锁仍存在,则重新设置过期时间(续费)
String script =
"if redis.call('HEXISTS',KEYS[1],ARGV[1]) == 1 then " +
"return redis.call('expire',KEYS[1],ARGV[2]) " +
"else " +
"return 0 " +
"end";
new Timer().schedule(new TimerTask()
{
@Override
public void run()
{
//递归调用,若仍存在则再次续费
if (stringRedisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName),uuidValue,String.valueOf(expireTime))) {
renewExpire();
}
}
},(this.expireTime * 1000)/3);
}
//===下面的redis分布式锁暂时用不到=======================================
@Override
public void lockInterruptibly() throws InterruptedException
{
}
@Override
public Condition newCondition()
{
return null;
}
}
@Service
@Slf4j
public class InventoryService
{
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Value("${server.port}")
private String port;
@Autowired
private DistributedLockFactory distributedLockFactory;
public String sale()
{
String retMessage = "";
Lock redisLock = distributedLockFactory.getDistributedLock("redis");
redisLock.lock();
try
{
//1 查询库存信息
String result = stringRedisTemplate.opsForValue().get("inventory001");
//2 判断库存是否足够
Integer inventoryNumber = result == null ? 0 : Integer.parseInt(result);
//3 扣减库存
if(inventoryNumber > 0) {
stringRedisTemplate.opsForValue().set("inventory001",String.valueOf(--inventoryNumber));
retMessage = "成功卖出一个商品,库存剩余: "+inventoryNumber;
System.out.println(retMessage);
//暂停几秒钟线程,为了测试自动续期
try { TimeUnit.SECONDS.sleep(120); } catch (InterruptedException e) { e.printStackTrace(); }
}else{
retMessage = "商品卖完了,o(╥﹏╥)o";
}
}catch (Exception e){
e.printStackTrace();
}finally {
redisLock.unlock();
}
return retMessage+"\t"+"服务端口号:"+port;
}
private void testReEnter()
{
Lock redisLock = distributedLockFactory.getDistributedLock("redis");
redisLock.lock();
try
{
System.out.println("################测试可重入锁####################################");
}finally {
redisLock.unlock();
}
}
}
小总结



7.Redis五大类型源码
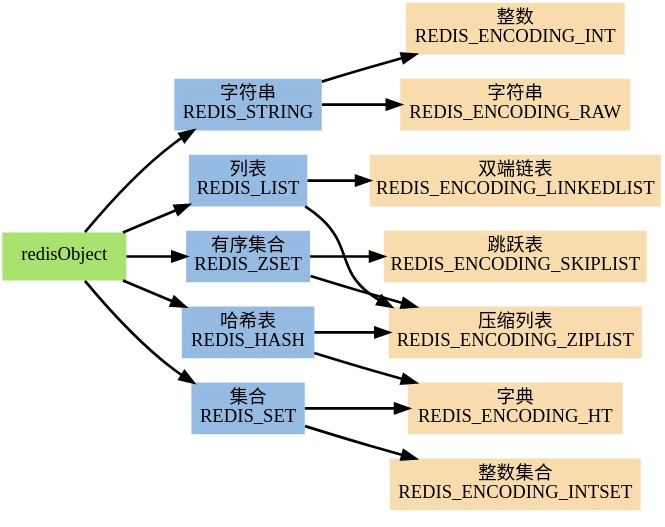
RedisObject
Redis数据库是一个全局哈希表,每一个键值对会被定义为一个DictEntry,key 是字符串,但是 Redis 没有直接使用 C 的字符数组,而是存储在redis自定义的 SDS中。value 存储在redisObject 中。
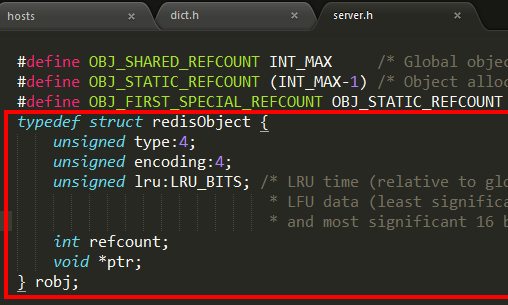
- 1 4位的type表示具体的数据类型
- 2 4位的encoding表示该类型的物理编码方式,同一种数据类型可能有不同的编码方式。
- 3 lru字段表示当内存超限时采用LRU算法清除内存中的对象。
- 4 refcount表示对象的引用计数。
- 5 ptr指针指向真正的底层数据结构的指针。
相关命令:
object encoding key 返回key对应value的编码方式
debug object key (需要在配置文件中开启,enable-debug-command 的值,no改为local)
7.1 String
Redis内部会根据用户给出的不同的键值使用不同的编码更格式,自适应的选择较优的方式。
String对应的三大编码格式:
-
1.int:当存储的字符串是一个整数值,大小在LONG_MAX 范围内,将redisobject 的 ptr 指针(刚好8字节64位)直接指向(存储)数据(享元模式)

-
2.embstr:当字符串的长度小于44 字节,总的redisobject 的长度占用是最多是64字节(redis分配内存时不会产生内存碎片),会使用empstr 编码,此时object 的head(RedisObject) 与sds(ptr指向的位置) 是连续的内存空间,申请内存时可以一次性申请所需要内存,效率更高;如果超过 44 字节会转为 raw 编码格式;

-
3.row:基于动态字符串(sds) 实现,存储数据的最大上限为512mb;此时 ptr 是指向 sds 数据对象的指针; sds 对象指向独立的内存空间,使用raw 存储时需要分别申请redisobject 和sds 的内存空间;
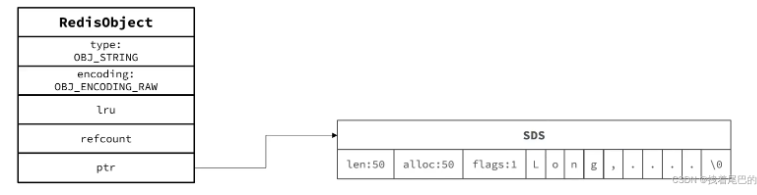
SDS简单动态字符串
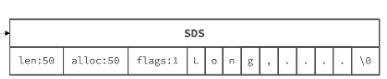
标记了开始位置,字符串长度,以及结束符。
7.2 Hash
ziplist压缩链表
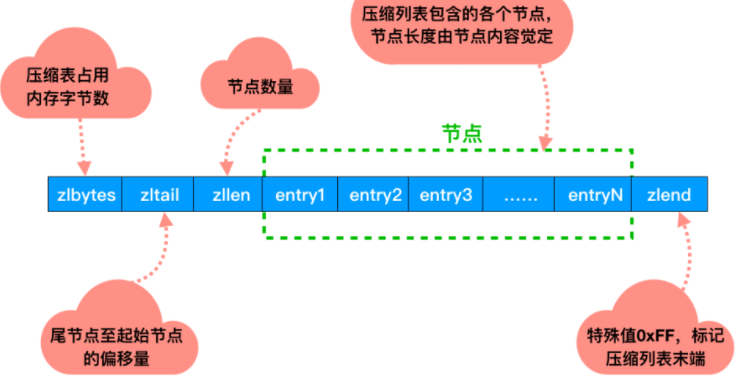
压缩列表zlentry节点结构:每个zlentry由前一个节点的长度、encoding和entry-data三部分组成

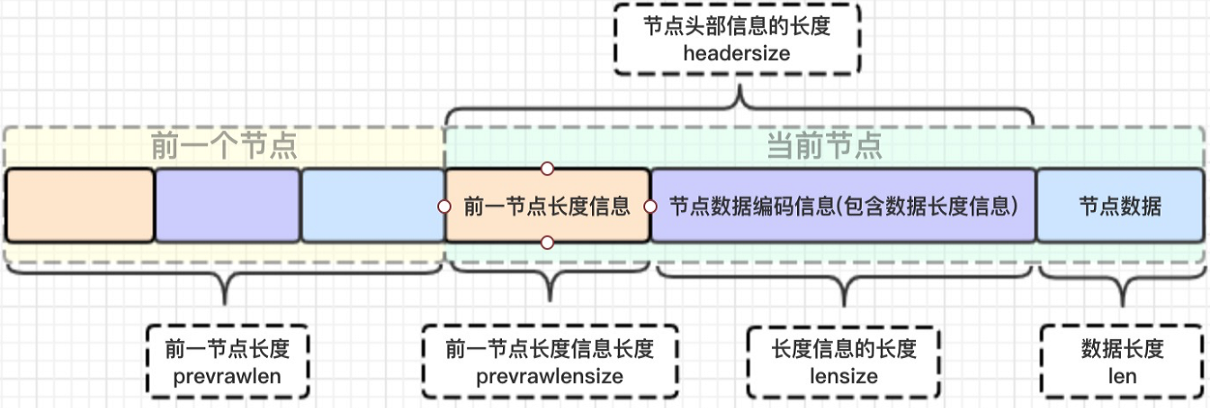
前节点:(前节点占用的内存字节数)表示前1个zlentry的长度,privious_entry_length有两种取值情况:1字节或5字节。取值1字节时,表示上一个entry的长度小于254字节。虽然1字节的值能表示的数值范围是0到255,但是压缩列表中zlend的取值默认是255,因此,就默认用255表示整个压缩列表的结束,其他表示长度的地方就不能再用255这个值了。所以,当上一个entry长度小于254字节时,prev_len取值为1字节,否则,就取值为5字节。记录长度的好处:占用内存小,1或者5个字节
enncoding:记录节点的content保存数据的类型和长度。
content:保存实际数据内容
- 优点
1.牺牲读取的性能,获得高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度更费内存。这是典型的“时间换空间”。
2.链表在内存中,一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题。如果知道了当前的起始地址,因为entry是连续的,entry后一定是另一个entry,想知道下一个entry的地址,只要将当前的起始地址加上当前entry总长度。如果还想遍历下一个entry,只要继续同样的操作。
3.可以直接拿到链表长度 - 缺点
1.连锁更新
压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。当压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,造成压缩列表性能的下降。
listpack紧凑链表
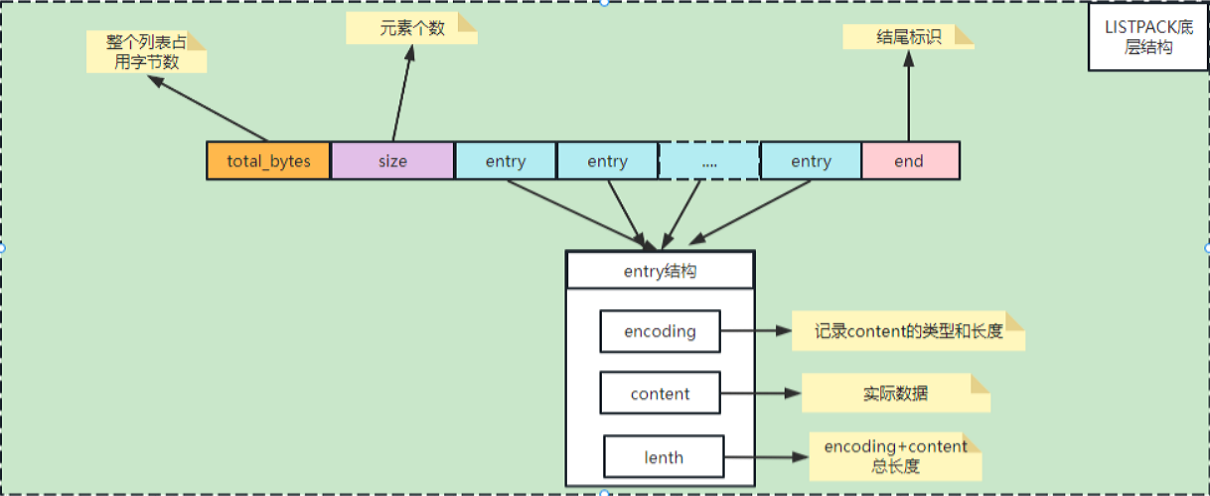
和ziplist 列表项类似,listpack 列表项也包含了元数据信息和数据本身。不过,为了避免ziplist引起的连锁更新问题,listpack 中的每个列表项
不再像ziplist列表项那样保存其前一个列表项的长度。
转换关系


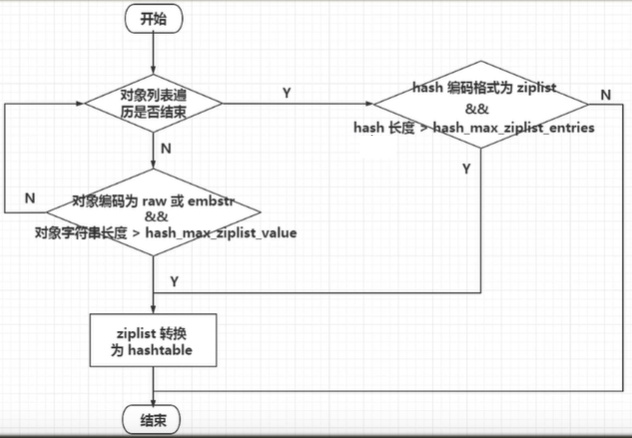
在redis7开始,舍弃ziplist,使用listpack
当hash集合满足上图设置值时,redis6使用ziplist存储,redis7采用listpack存储,当任意条件被破坏,将自动转为hashtable,且不能向下转型。
list
redis6之前,qucikList是由zipList和双向链表linkedList组成的混合体。它将linkedList按段切分,单个节点使用zipList来紧凑存储,多个zipList之间使用双向指针串接起来。quickList中每个ziplist节点可以存储多个元素,quickList内部默认单个zipList长度为8k字节,即list-max-ziplist-size为 -2,超出了这个阈值,就会重新生成一个zipList来存储数据。quickList中可以使用压缩算法对zipList进行进一步的压缩,这个算法就是LZF算法,可以通过配置文件配置压缩配置项。
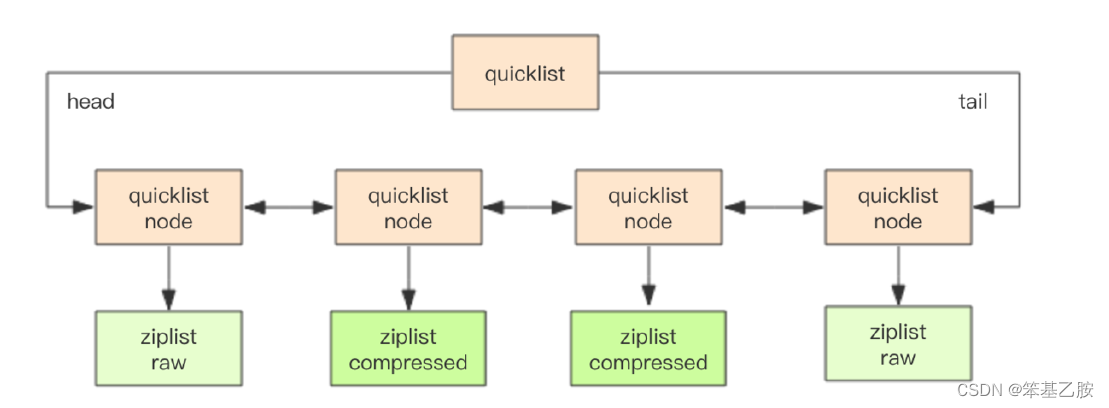
redis7开始,舍弃ziplist,使用listpack,其余部分一致。
Set
set对应两种编码方式,intset和hashtable
若元素都是int类型的数据,且满足对应的大小的要求,则采用对应的intset编码(RedisObject的ptr指针指向intset)。
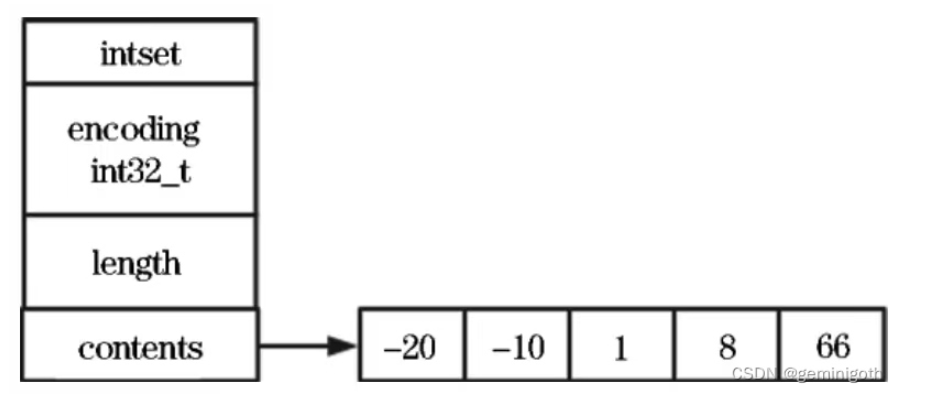
整数集合是有序的。当Redis集合类型的元素都是整数并且它们的值限制在64位(bit)表示的有符号整数范围之内时,使用该结构来存储。增删改查就是数组的增删改查,但是会保证set的非重复性以及是否需要扩容等。
当插入一个非数字时,数据结构从IntList转变为HashTable。
当元素数量超过512时,数据结构从IntList转变为HashTable。
Zset
skiplist跳表
skiplist是一种以空间换取时间的结构。
由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找,提取多层关键节点,就形成了跳跃表,but由于索引也要占据一定空间的,所以,索引添加的越多,空间占用的越多。
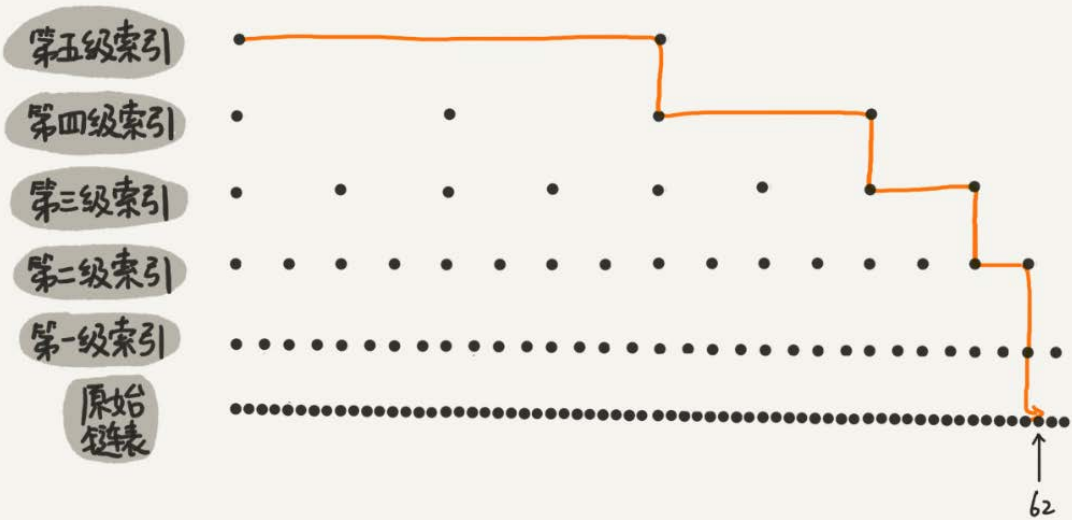
缺点:
维护成本相对要高,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1)
but新增或者删除时需要把所有索引都更新一遍,为了保证原始链表中数据的有序性,我们需要先找到要动作的位置,这个查找操作就会比较耗时最后在新增和删除的过程中的更新,时间复杂度也是O(log n)。
Zset的构成
当元素个数小于128且每个元素长度小于64字节时,使用listpack(ziplist),当不满足某个条件时,使用skiplist(map+skiplist)
map用来存储member到score的映射,这样就可以在O(1)时间内找到member对应的分数
skiplist按从小到大的顺序存储分数
skiplist每个元素的值都是[score,value]对
跳表的最底层是有序的链表,所以可以实现有序输出,同时map可以快速定位到member对应的节点,以及member的非重复性。
基本操作
1.查找
对于zrangebyscore命令:score作为查找的对象,在跳表中跳跃查询,遍历score在min与max之间的skiplist底层对应的节点。
2.插入
在map中查找value是否已存在,如果存在现需要在skiplist中找到对应的元素删除,再在skiplist做插入
插入过程也是用score来作为查询位置的依据,和skiplist插入元素方法一样。并需要更新value->score的map
3.删除
从map中找到value所对应的score,然后再在跳表中搜索这个score,value对应的节点,并删除
8.IO多路复用
阻塞与非阻塞的讨论对象是调用者,重点在于在等待返回结果的过程中是否能做其他操作。
https://blog.csdn.net/wangbuhu/article/details/125920083?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-2-125920083-blog-104455192.235%5Ev43%5Epc_blog_bottom_relevance_base7&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-2-125920083-blog-104455192.235%5Ev43%5Epc_blog_bottom_relevance_base7&utm_relevant_index=5
多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,
变成了一次系统调用 + 内核层遍历这些文件描述符。
epoll是现在最先进的IO多路复用器,Redis、Nginx,linux中的Java NIO都使用的是epoll。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。
1、一个socket的生命周期中只有一次从用户态拷贝到内核态的过程,开销小
2、使用event事件通知机制,每次socket中有数据会主动通知内核,并加入到就绪链表中,不需要遍历所有的socket
在多路复用IO模型中,会有一个内核线程不断地去轮询多个 socket 的状态,只有当真正读写事件发送时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有真正有读写事件进行时,才会使用IO资源,所以它大大减少来资源占用。多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。 采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈















 2610
2610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









