







SparrowRecys——推荐模型
一、协同过滤
协同过滤算法就是协同大家的反馈、评价、意见对海量的信息进行过滤,筛选出用户感兴趣的信息。
“协同”过滤算法:让用户考虑与自己兴趣相似用户的意见,预测第一步就是找到与用户兴趣相似的Top n 用户,n为超参数,综合top n个用户对物品的评价,得出用户的意见。
那么怎么找出相似用户呢即top n用户?
计算用户相似度:
用户对商品的评价可以看做是一个偏好矩阵,偏好矩阵的每一个行向量可以看做是用户embedding向量。
最常用的方法是余弦相似度:
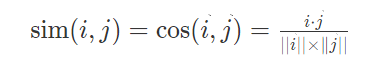
夹角与相似性成反比,夹角越小,相似性越大。
还有其他的方法衡量相似性:比如欧式距离、马氏距离、曼哈顿距离。距离越近(值越小),相似度越大。
实际推荐环境中用户偏好矩阵往往是稀疏的,需要对空缺值进行处理,不能简单设置为0或者某个特定的值,导致最后相似度计算不够准确。因此为了解决稀疏偏好矩阵的问题,矩阵分解算法弥补了协同过滤算法的缺点。
基于ALS推荐系统
计算用户之间相似度后,根据相似度大小进行排序,取出前n个相似用户。得到n个相似用户后怎么计算用户对“商品”的评分呢?
在“目标用户与其相似用户喜好相似”前提下,将目标用户与相似用户之间相似度作为权重,相似用户对商品的评分与权重相乘再除以整个相似度之和即可得到评分。
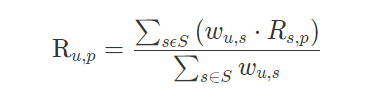
二、矩阵分解
协同过滤算法固然很好,但在用户偏好矩阵稀疏情况下寻找相似用户过程并不准确,矩阵分解主要过程:先分解协同过滤生成的用户偏好矩阵,生成用户和物品的隐向量,再通过用户和物品隐向量之间相似性进行推荐。
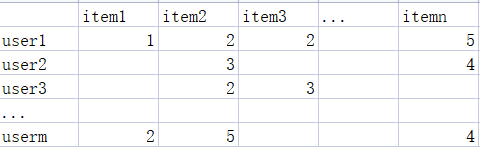
矩阵分解示意图:

用户隐向量是用户矩阵的行向量,物品隐向量为物品矩阵的列向量。

矩阵分解方法有很多,这里介绍下Basic MF,其将评分矩阵R分解为用户矩阵U和物品矩阵S,通过不断的迭代训练使得U和S乘积越来越接近真实R。
怎么让U和S乘积越来越接近R呢?定义损失函数:
 让
让
通过梯度下降让损失函数的损失越来越小。
推荐系统中矩阵分解
理清协同过滤和矩阵分解算法流程:
协同过滤:
- 第一步:先计算与目标用户兴趣爱好相似的相似用户
- 第二步:通过相似用户对商品的评分得到目标用户对商品的评分
- 第三步:根据评分高低推荐给目标用户商品,决定到底给目标用户推荐“电子书”,“游戏机”还是其他商品。
矩阵分解: - 第一步:将用户偏好矩阵分解为用户向量和物品向量
- 第二步:再利用用户向量和物品向量进行推荐
三、Embedding+MLP
Embedding+MLP结构非常经典,如图所示,从上到下分为5层,分别为
- feature层:feature层组成部分有数字特征、类别特征
- Embedding层:类别特征生成One-Hot向量再生成embedding向量。
- stacking层:将数字特征和embedding向量进行拼接。
- MLP层:拼接后的embedding向量送入MLP网络中
- score层:score层就是一个二分类问题

代码实战:
1.特征种类
类别特征:
- movieid
- userid
- moviegenre
- usergenre
数值特征:
- releaseYear
- movieRatingCount
- movieAvgRating
- movieRatingStddev
- userRatingCount
- userAvgReleaseYear
- userReleaseYearStddev
- userAvgRating
- userRatingStddev
电影风格value放入vocabulary里:
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary', 'Sci-Fi', 'Drama', 'Thriller', 'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
电影风格特征字典:key为特征名,value为电影风格:GENRE_FEATURES = { 'userGenre1': genre_vocab, 'userGenre2': genre_vocab, 'userGenre3': genre_vocab, 'userGenre4': genre_vocab, 'userGenre5': genre_vocab, 'movieGenre1': genre_vocab, 'movieGenre2': genre_vocab, 'movieGenre3': genre_vocab }
2.类别特征转为OneHot向量再变为embeding向量:
电影风格moviegenre:
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
#生成one-hot向量
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
#生成10维的embedding
emb_col = tf.feature_column.embedding_column(cat_col, 10)
#将'userGenre1','userGenre2','userGenre3','userGenre4','userGenre5',
#'movieGenre1','movieGenre2', 'movieGenre3'生成embedding,一共8个embedding(10维))
categorical_columns.append(emb_col)
将’userGenre1’,‘userGenre2’,‘userGenre3’,‘userGenre4’,‘userGenre5’,‘movieGenre1’,‘movieGenre2’, 'movieGenre3’生成embedding,一共8个embedding(10维))
debug看看categorical_column:

- movieid
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
categorical_columns.append(movie_emb_col)
1001是什么,电影有1001部,假设movieid为340,经过onehot处理后得到movid为340的onehot向量低340为1,其他维为0.
debug:movie_emb_col被添加进categorical_column中

- userid
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
categorical_columns.append(user_emb_col)
debug:user_emb_col被添加进categorical_columns.
30001为用户总数目
数字特征
numerical_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
debug:数字特征被添加进numeric_column里。

3.模型model
将特征送入model:
数值特征和类别特征要进行concate,即将numeric_column和categorical_columns进行concate,再送入MLP里。
tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns),
MLP网络结构:
model = tf.keras.Sequential([
tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
损失函数用的是二分类的交叉熵损失函数。
四、Wide&Deep
- wide侧让模型具有较强的记忆能力,记忆能力理解为模型直接学习1历史数据中物品或特征的共现频率,看了A电影的用户经常喜欢看电影B,因为A所以B式的规则非常直接也非常有价值。wide侧向量往往维度很高,很稀疏。
- deep侧让模型具有较强的泛化性能。泛化性能指的是模型对于新鲜样本、以及从未出现过的特征组合能力。
事实上,我们学过的矩阵分解算法,就是为了解决协同过滤“泛化能力”不强而诞生的。因为协同过滤只会“死板”地使用用户的原始行为特征,而矩阵分解因为生成了用户和物品的隐向量,所以就可以计算任意两个用户和物品之间的相似度了。这就是泛化能力强的另一个例子。

wide侧的crossed_feature:将用户已好评电影与当前评价电影组成一个交叉特征,让模型记住“喜欢电影A的用户,也会喜欢电影B”这样的规则。
# cross feature between current movie and user historical movie
rated_movie = tf.feature_column.categorical_column_with_identity(key='userRatedMovie1', num_buckets=1001)
crossed_feature = tf.feature_column.indicator_column(tf.feature_column.crossed_column([movie_col, rated_movie], 10000))
deep部分没有太多变化,只要将wide侧和deep侧拼接起来送入模型即可。
deep = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)(inputs)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
# wide part for cross feature
wide = tf.keras.layers.DenseFeatures(crossed_feature)(inputs)
both = tf.keras.layers.concatenate([deep, wide])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(both)
model = tf.keras.Model(inputs, output_layer)
有时间吧crossed_feature怎么把两个1000维的向量cross成10000维,还是随机设置一个数字10000。
五、NeuralCF
NeuralCF是对矩阵分解进行改进,矩阵分解得到的用户embedding向量和物品embedding向量往往直接进行内积计算相似性。
反向传播的过程?
将矩阵分解网络化与Embedding+MLP和Wide&Deep比较,发现矩阵分解在Embedding以上操作过于简单。因此NeuralCF用一个多层神经网络代替简单点积操作,提高模型拟合能力。

双塔模型
双塔模型是对NeuralCF的扩展,NeuralCF蕴含了一个非常重要的思想:把模型分为用户侧模型和物品侧模型两部分,然后把这两部分联合起来产生最后的预测得分。
双塔模型定义:物品侧模型+用户侧模型+互操作层(点积或者MLP网络)。
NeuralCF将用户ID作为用户塔的输入,将物品ID作为物品塔的输入。也可以将其他用户和物品相关特征放入用户塔和物品塔,比如Youtube的双塔模型。
双塔模型优点:模型不需要上线,只需要预存物品塔和用户塔的输出,在线上实现互操作层。
# neural cf model arch two. only embedding in each tower, then MLP as the interaction layers
def neural_cf_model_1(feature_inputs, item_feature_columns, user_feature_columns, hidden_units):
item_tower = tf.keras.layers.DenseFeatures(item_feature_columns)(feature_inputs)
user_tower = tf.keras.layers.DenseFeatures(user_feature_columns)(feature_inputs)
interact_layer = tf.keras.layers.concatenate([item_tower, user_tower])
for num_nodes in hidden_units:
interact_layer = tf.keras.layers.Dense(num_nodes, activation='relu')(interact_layer)
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(interact_layer)
neural_cf_model = tf.keras.Model(feature_inputs, output_layer)
return neural_cf_model
# neural cf model architecture
model = neural_cf_model_1(inputs, [movie_emb_col], [user_emb_col], [10, 10])
把物品侧的 Embedding 和用户侧的 Embedding 存起来,就可以进行线上服务了。但如果我们把一些场景特征,比如当前时间、当前地点加到用户侧或者物品侧,那我们还能用这种方式进行模型服务吗?为什么?
不可以,因为如有地点或者时间这种波动比较大的特征就不能用预存embedding来表示当前的用户或者当前的物品了。例如外卖推荐,在公司和家时用户的embedding应该是不同的。或者新闻网站早晨和晚上的也应该不同
为什么用户id用作one-hot编码,不使用数值特征:用户id 1761 和用户id 1881,如果是数值特征说明他们两个是有可比性的,但其实并没有,我们需要id类的特征来单独表达他们这两个用户的行为特点。

六、DeepFM模型
为什么会有DeepFM模型:wide&deep、Embedding+MLP、NeuralCF等没有利用特征组合和特征交叉的能力,模型对于特征组合和特征交叉的学习能力决定了模型对于未知特征组合样本的预测能力。
MLP层和特征交叉的区别:
MLP层是把特征concate成一个向量送入网络中,像一个黑盒子一样让在自己在里面捯饬和进行碰撞,而特征交叉是有意的利用先验知识加入特征交叉的模型结构,比如**“用户喜欢的电影风格”,“电影本身的风格”**,这两个特征具有明显的相关性,利用这样的相关性肯定会对模型起到正向的效果。我记得在wide&deep里面也是有将“用户好评电影”和“用户当前观看电影”组成一个交叉特征。

DeepFM利用了Wide&Deep组合模型的思想
-
用FM层代替了Wide侧
-
Deep侧还是采用多层神经网络
特征交叉方法 -
内积:也称点积,两个向量进行点积运算最后得到是实数值。
-
NFM(神经网络因子分解机):两两特征交叉池化层即先采用元素积操作将两个长度相同的向量维相乘得到元素积向量,得到两两特征向量元素积操作后,最后输入到神经网络中得到预测得分。
疑问:如果进行特征交叉的embedding向量维度不同呢?
几乎不可以,必须维度相同,那么左特征交叉的方式呢?debug代码看看。
特征交叉一般采用用户侧和物品侧特征进行交叉。
代码:
- 用户id、movieid、用户喜欢电影风格、电影本身风格,进行特征交叉。
product_layer_item_user = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_emb_layer])
product_layer_item_genre_user_genre = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_genre_emb_layer])
product_layer_item_genre_user = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_emb_layer])
product_layer_user_genre_item = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_genre_emb_layer])
最后将FM部分和deep部分进行concate,输入到sigmoid神经元得到预估分数。
七、DIN模型
一般模型都会将用户行为embedding进行叠加操作,叠加操作是将所有历史行为一视同仁·没有任何重点的叠加起来,并不符合我们购物的习惯。
DIN模型在用户行为上加了个激活单元即给与用户历史行为不同的权重,这个权重就是用户对历史商品的注意力得分。
激活单元计算:把用户历史行为商品embedding、候选广告商品embedding,与它们的外积结果连接起来形成一个向量,再输入给激活单元的MLP层,最终会生成一个注意力权重。
向量外积:输出的是一个向量。














 5726
5726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









