







1、数据结构介绍
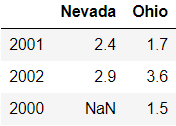
字典传入DataFrame:如果嵌套字典被赋值给DataFrame,它会将字典的键作为列,内部字典的键作为索引
pop = {'Nevada':{2001:2.4, 2002:2.9},
'Ohio':{2000:1.5, 2001:1.7, 2002:3.6}}
frame = pd.DataFrame(pop)
frame
输出
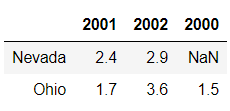
同时,可以将使用类似Numpy语法对DataFrame进行转置操作(调换行和列)
frame.T
输出
python索引对象可以包含重复标签,与集合不同
labels = pd.Index(['foo','foo','bar','bar'])
labels
输出Index(['foo', 'foo', 'bar', 'bar'], dtype='object')
2、基本功能
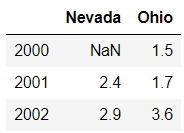
如果你想重新排序索引,可以使用reindex,它是创建一个符合新索引的新对象,还可以同时改变行索引与列索引。
frame2 = frame.reindex([2000,2001,2002])
frame2
输出
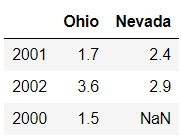
改变列索引:
frame.reindex(columns=['Ohio','Nevada'])
输出
很多函数,例如drop,会修改series,DataFrame的尺寸或形状,这些方法直接操作原对象而不返回新对象,如果使用inplace属性,它会在原数据基础上清除被删除的数据。
frame.drop(2001,axis=0,inplace=True)
frame
输出

pandas的loc与iloc区别,前者可以使用轴标签、整数标签,后者只能使用整数标签。
import numpy as np
data = pd.DataFrame(np.arange(16).reshape(4,4),
index=['Ohio', 'Colorado', 'Utah', 'NewYork'],
columns=['one','two','three','four'])
data.loc[:'Utah', 'two']
输出

对于iloc:
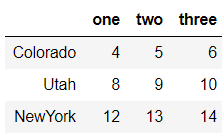
data.iloc[:,:3][data['three']>5]
输出
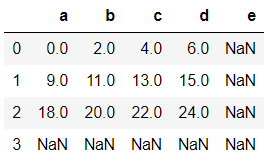
当轴标签在一个对象中存在,在另一个对象中不存在时,并且你想将轴标签少的对象的缺失值填充为0时。
df1 = pd.DataFrame(np.arange(12.).reshape(3,4),
columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape(4,5),
columns=list('abcde'))
df1+df2#如果直接相加是不行的
如果直接相加,则结果如下:
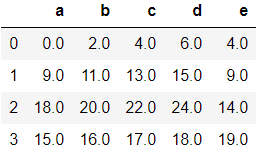
想解决这种问题,可以对df1采用add方法
df1.add(df2, fill_value=0)
#sub减法,div除法,floordiv整除,mul乘法,pow幂次方
输出
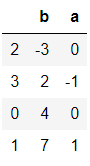
如果想要针对某一或全部索引排序可以使用sort_values
frame4 = pd.DataFrame({'b':[4,7,-3,2], 'a':[0,1,0,-1]})
frame4.sort_values(by='b')
输出
对于rank函数的应用,我查找到了CSDN博主「justinlonger」写的文章,我感觉他分析的比书上讲的详细,原文链接:https://blog.csdn.net/justinlonger/article/details/90646111
value_counts用法
data1 = pd.DataFrame({'Qu1':[1,3,4,3,4],
'Qu2':[2,3,1,2,3],
'Qu3':[1,5,2,4,4]})
result = data1.apply(pd.value_counts).fillna(0)
result
输出
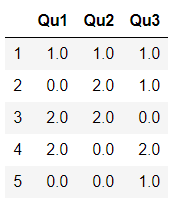
结果中的行标签是所有列中出现的不同值,数值则是这些不同值在每个列中出现的次数
以上是我对于第五章的Pandas包入门认为重要的知识点总结,希望以后这篇博客对自己以及对你有所帮助。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









