






 文章介绍了如何处理波斯语字符的编码规则,特别关注Unicode编码,包括确定字符的Unicode代码点、创建字库映射、处理字母变形规则以及实现连写时的像素填充方法。
文章介绍了如何处理波斯语字符的编码规则,特别关注Unicode编码,包括确定字符的Unicode代码点、创建字库映射、处理字母变形规则以及实现连写时的像素填充方法。
我之前一直在网上查找关于波斯语的编码规则,为的是通过编码规则来确定我下载的波斯语字母在FLASH字库中的位置,但是依然无法进行正确的波斯语字母显示,因为波斯语字母不同于英文字母有专门的ASCII字符集,且它的字母顺序并不连续,通过字母判断其码值并查找字母在字库中的位置比较麻烦。后来我在网站上提问得到一些提示:可以使用映射的方法通过该字母来确定存储在FLASH中的位置。
对于波斯语的编码规则,最常用的是Unicode编码。Unicode为波斯语中的每个字符分配一个唯一的数字代码点,以便在计算机系统中进行统一处理。目前最新版本的Unicode标准为UTF-8,它支持几乎所有的字符,并且在互联网上广泛使用。
1. 生成波斯语字库,将字库下载至FLASH中,下载字库和偏移地址参考上一篇文章。
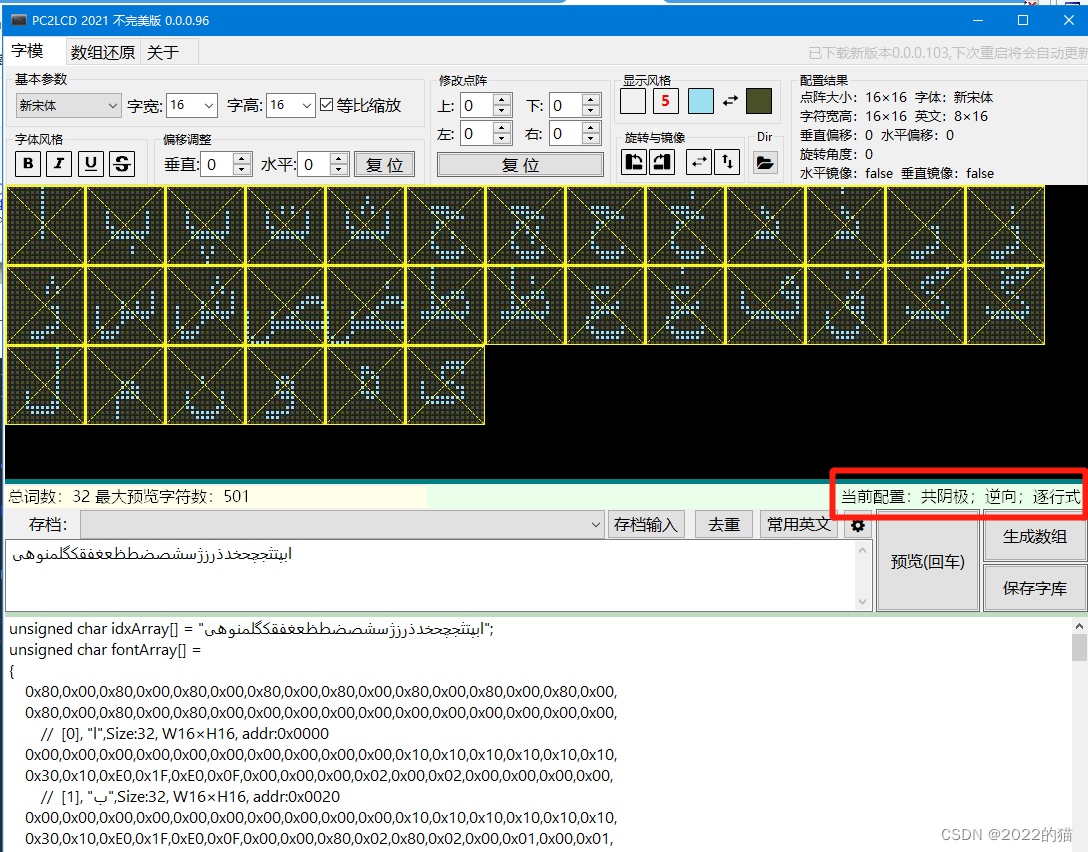
2.确定波斯语中每个字符的Unicode代码点。
下图是波斯语的原型字母和变形后的字母的代码点,空格部分表示不变形
波斯语字母表 (空白表示不变型)
Hex 是字符的Unicode编码
原型Hex 独立Hex 后(左)Hex 前(右)Hex 在内Hex
ا 0627 ﺍ FE8D ﺎ FE8E
ب 0628 ﺏ FE8F ﺐ FE90 ﺑ FE91 ﺒ FE92
ت 062A ﺕ FE95 ﺖ FE96 ﺗ FE97 ﺘ FE98
ث 062B ﺙ FE99 ﺚ FE9A ﺛ FE9B ﺜ FE9C
ج 062C ﺝ FE9D ﺞ FE9E ﺟ FE9F ﺠ FEA0
ح 062D ﺡ FEA1 ﺢ FEA2 ﺣ FEA3 ﺤ FEA4
خ 062E ﺥ FEA5 ﺦ FEA6 ﺧ FEA7 ﺨ FEA8
د 062F ﺩ FEA9 ﺪ FEAA
ذ 0630 ﺫ FEAB ﺬ FEAC
ر 0631 ﺭ FEAD ﺮ FEAE
ز 0632 ﺯ FEAF ﺰ FEB0
س 0633 ﺱ FEB1 ﺲ FEB2 ﺳ FEB3 ﺴ FEB4
ش 0634 ﺵ FEB5 ﺶ FEB6 ﺷ FEB7 ﺸ FEB8
ص 0635 ﺹ FEB9 ﺺ FEBA ﺻ FEBB ﺼ FEBC
ض 0636 ﺽ FEBD ﺾ FEBE ﺿ FEBF ﻀ FEC0
ط 0637 ﻁ FEC1 ﻂ FEC2 ﻃ FEC3 ﻄ FEC4
ظ 0638 ﻅ FEC5 ﻆ FEC6 ﻇ FEC7 ﻈ FEC8
ع 0639 ﻉ FEC9 ﻊ FECA ﻋ FECB ﻌ FECC
غ 063A ﻍ FECD ﻎ FECE ﻏ FECF ﻐ FED0
ف 0641 ﻑ FED1 ﻒ FED2 ﻓ FED3 ﻔ FED4
ق 0642 ﻕ FED5 ﻖ FED6 ﻗ FED7 ﻘ FED8
ل 0644 ﻝ FEDD ﻞ FEDE ﻟ FEDF ﻠ FEE0
م 0645 ﻡ FEE1 ﻢ FEE2 ﻣ FEE3 ﻤ FEE4
ن 0646 ﻥ FEE5 ﻦ FEE6 ﻧ FEE7 ﻨ FEE8
ه 0647 ﻩ FEE9 ﻪ FEEA ﻫ FEEB ﻬ FEEC
و 0648 ﻭ FEED ﻮ FEEE
پ 067E ﭖ FB56 ﭗ FB57 ﭘ FB58 ﭙ FB59
چ 0686 ﭺ FB7A ﭻ FB7B ﭼ FB7C ﭽ FB7D
ژ 0698 ﮊ FB8A ﮋ FB8B
ک 06A9 ﮎ FB8E ﮏ FB8F ﮐ FB90 ﮑ FB91
گ 06AF ﮒ FB92 ﮓ FB93 ﮔ FB94 ﮕ FB95
ی 06CC ﯼ FBFC ﯽ FBFD 也可以使用Python编程语言的ord()函数来获取波斯语字符的Unicode代码点,或者通过代码点来获取这个字母
3.这是一个映射函数的例子:将每个字母与其在字库中的位置对应起来,然后找到该字母后返回对应的位置。
wchar_t是Unicode字符的数据类型,注意wchar_t数据类型的书写方式,在字符串数组前面加上字符'L',使用该数据类型,波斯语占一个字节。
int position_buf[]={0x0000,0x0020,0x0040};
wchar_t[] letter_buf= L"ابپ";
struct Letter_Position
{
wchar_t letter;
u16 position;
};
Letter_Position Le_Po[SIZE];
void letter_put_position(wchar_t letter_buf[],u16 position_buf[])
{
int index = 0;
while (index < 3)
{
Le_Po[index].letter= letter_buf[index];
Le_Po[index].position = position_buf[index];
index++;
}
}
int get_position(wchar_t value)
{
int i;
for (i = 0; i < 3; i++)
{
if (Le_Po[i].letter==value)
{
return Le_Po[i].position;
}
}
return -1;
}4.显示多个不变形的波斯语字母在屏幕上
比如字母”ا”在数组letter_buf中的0位置,他在字库中的位置,也就是position_buf中的0位置--0x000。
屏幕显示函数可以参考上一篇笔记的中文显示。
uint8_t Farsi_BUF[32];
void LCD_FLASH_FARSI_NoDeform(uint16_t x, uint16_t y, wchar_t *fa, uint16_t backColor, uint16_t pointColor)
{
int i,j;
//将wchar_t强转成char类型,字符所占字节会从一个变成两个。因为我使用的编译器无法识别出wcslen,所以这里我进行了强制转换。
int len_fa=strlen((char *)fa)>>1;
letter_put_position(letter_buf,position);//将字母和在字库中的位置对应
for(j=len_fa-1;j>=0;j--)//从右往左显示
{
for (i = 0; i < FARSI_SIZE; i++)
{
if (fa[j] == farsi_proto[i])
{
LCD_FLASH_FARSI_ADD(i,letter_buf);
LCD_FLASH_FARSI_Show(x, y, backColor, pointColor);//显示函数
x+=16;
}
}
}
}
void LCD_FLASH_FARSI_ADD(int num,wchar letter_buf[])
{
int result,addr;
result=get_position(letter_buf[num]);//通过代码点获取字母在FLASH中的位置
printf("代码点=0x%x 位置%d=0x%x\n",letter_buf[num],num,result);
addr= FLASH_FARSI_ADD+result; //FLASH_FARSI_ADD是波斯语字库在flash中的起始地址
FLASH_ReadData(Farsi_BUF,addr,32); //16x16的点阵所占空间是32
}注意添加保存波斯语使用的数据类型是wchar_t,头文件#include "wchar.h"。编译器的字符集为UTF-8。
5.多个波斯语字母变形规则
波斯语遵循从右往左、连写变形的规则。
判断是否是连接前面的,采用判断该字符前一个字符的判定方法,看前一个字符是否在集合behind_deform中。如果在,则是有连接前面的。集合1如下:
int behind_deform[]={
0628,062A,062B,62C,062D,062E,0633,0634,0635,0636,0637,0638,0639,063A,0641,0642,0644,
0645,0646,0647,067E,0686,06A9,06AF};//"بتثجحخسشصضطظعغفقلمنهپچکگ"
判断是否是连接后面的,采用判断该字符后一个字符的判定方法,看后一个字符是否在集合front_deform中。如果在,则是有连接后面的。集合2如下:
int front_deform[]={
0627,0628,062A,062B,062C,062D,062E,062F,0630,0631,0632,0633,0634,0635,0636,0637,0638,0639,063A,0641,0642,0644,06450646,0647,0648,067E,0686,0698,06A9,06AF,06CC};
//"ابتثجحخدذرزسشصضطظعغفقلمنهوپچژکگی"
当该字母满足同时连接前面和后面时,字母进行中间变形。
这里我是通过字母原型去判断是否连接了前面或者后面,同查找一个字母,根据字母所在的数组位置对应其在字库中的位置,但是需要注意的是,连接前面和中间都连接时,部分字母是不进行变形的,所以对应的地址是不同的。
6.多个波斯语字母连写变形
实现变形还有连写,这里的连写方式我是通过填充像素点时只填充有效点阵(亮点),将前后连接的方式。字母取模是16x16,同中文。
 点阵格式是阴码(亮点为1),扫描方式为逐列式,取模走向是逆向(低位在前)。
点阵格式是阴码(亮点为1),扫描方式为逐列式,取模走向是逆向(低位在前)。
求出点阵前后为0x0的列数:因为使用的是逐列式一列下来有两个字节,判断该列的两个字节是否都为0x0,如果都为0,则空的列数+1。
最后填充点阵时,只考虑列中有一个不为0x0的点阵。
start_byte = front_blank * col_byte;//前面的空列数*一个列的字节
end_byte = dot_size - behind_blank * col_byte;/一个字所占空间大小-后面的空列数*一个列的字节
for(i = start_byte; i < end_byte; i++)
{
font_fill[len++] = flash_farsi[font+i];//只填充不是空点阵的列的字节
}7.最终效果

如果对连写的方法有更好的建议欢迎评论。

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









