






1 SENet存在的缺点: 在输入特征图H(C×H×W),对其空间使用简单粗暴的全局平均池化,直接把空间位置上所有的信息平均池化为一个信息,即得到H1(C×1×1),这样的话,即破坏了空间上的位置信息,又会导致部分纹理细节信息丢失,可能会使最终的提取的特征出现模糊,空间纹理细节信息不明显。

2 而CANet解决SENet存在的缺点,主要从水平方向(X方向)和竖直方向(Y方向)出发,分别对其进行水平方向的池化操作,竖直方向上的池化操作,这样做的话,可以将空间位置信息嵌入到通道注意力中,会使空间位置信息得到保留,可以使网络能够在更大的区域上进行相应的注意力。相应的图如下:
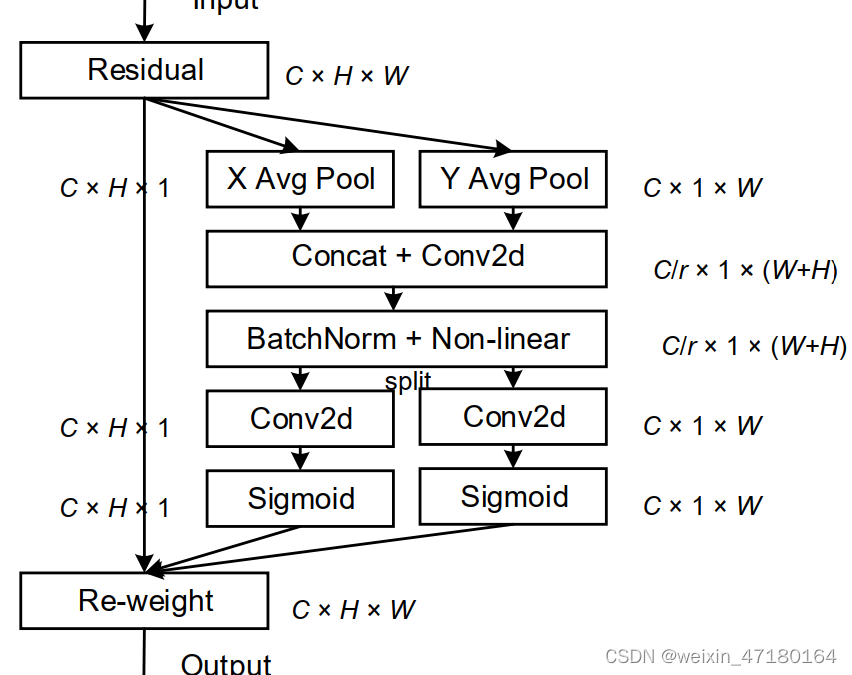
步骤:输入特征图H(C×H×W),其分别经过水平方向一维平均池化操作(x(W)),竖直方向一维平均池化操作(y(H))。
水平方向操作后得到H1(C×H×1),竖直方向操作后得到H2(C×1×W),然后竖直方向的维度转换后得到H22(C×W×1),将其水平和竖直方向得到的特征图从空间维度拼接得到H3(C×(H+W)×1),后面经过和SENet类似的操作,既是使用1×1卷积降维和激活函数,即得到

然后使用Split分离空间维度,得到H31(C×H×1)和维度转换后的H32(C×1×W),之后分别使用1×1卷积升维和激活函数,分别得到

最后将其得到的两个注意力权重值![]() ,
,![]() 与输入特征图H相乘,得到生成最终的带有不同权重的特征图。
与输入特征图H相乘,得到生成最终的带有不同权重的特征图。
位置注意力CANet 的Pytorch代码实现为
#开发时间:2023/12/3 21:38
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp=64, oup=64, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x) #[n,c,h,1] x方向的w平均池化
print('1',x_h.shape)
x_w = self.pool_w(x) #[n,c,1,w] x反向的h平均池化
print('2', x_w.shape)
x_w = x_w.permute(0, 1, 3, 2) #第三维和第四维互换后的[n,c,w,1]
print('3', x_w.shape)
y = torch.cat([x_h, x_w], dim=2) #第三维拼接即为[n,c,h+w,1]
print('4', y.shape)
y = self.conv1(y) #通道数降低操作,[n,c/32和8比大小,大的留下,h+w,1]
y = self.bn1(y) #批归一化操作
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2) #[n,c/32和8比大小,大的留下, 1,w] 相当于还原回来原来的四维
a_h = self.conv_h(x_h).sigmoid() #[n,c,h,1] 将8个通道还原到原来的维度
print('5', a_h.shape)
a_w = self.conv_w(x_w).sigmoid() #[n,c,1,w] #将8个通道还原到原来的维度
print('6', a_w.shape)
out = identity * a_w * a_h #[n,c,h,w]
return out
x = torch.randn(1,64,16,16)
model = CoordAtt()
y = model(x)
print(y.shape)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









