







ppt来自李宏毅老师的视频
在讲transformer之前需要了解一下rnn和attention的知识
rnn缺点:
不容易并行化计算,要一个一个字符输入

方法1:用CNN代替
将整体序列输入,使用filter获取信息,为了获得长序列的关系可以使用多层CNN

方法2:self-attention
将每个输入向量分别乘以不同矩阵获得不同的向量

接下来用q对k做attention,即输入q和k输出匹配分数,注意q和k维度相同
scaled dot-product attention:具体是将q和k点乘除以二者的维度

将输出的相似度通过softmax

将softmax后的值和对应v相乘,求和后获得最终的输出

这里就可以理解,v是存储输入信息的,最终输出b考虑到不同的输入信息a,考虑权值大小取决于q和k的匹配
同理求其余的输出

平行计算:
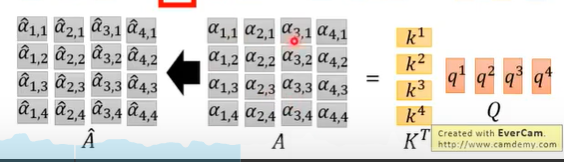
将输入拼接成一个矩阵和权重矩阵相乘,可以获得所有的kqv

计算相似度时,将k拼接后和对应q相乘:
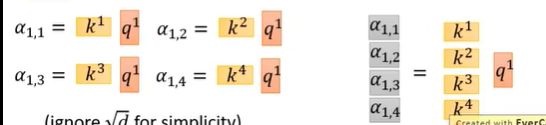
也可以将q拼接
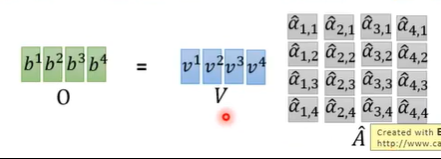
最后平行计算b:
接下来梳理一下输入到输出的流程:
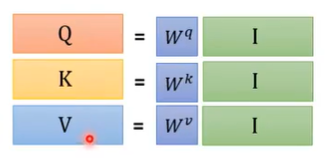
首先是输入乘以权重矩阵获得qkv向量
计算q和k相似度,并通过softmax后,和V相乘获得输出:

变型multi-head self-attention:
将kqv分成多个,每次获得多个输出向量
最后对多个向量进行矩阵乘法改变大小。

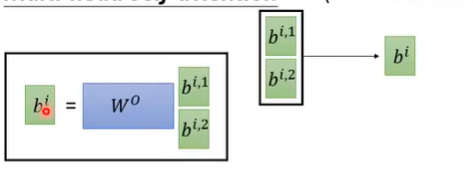
改进:
positional encoding:
self-attention没有考虑到位置信息,因为最终输出考虑了所有序列,因此给每个位置设置一个独特的向量e,输入向量要加上对应位置向量,并且位置向量不是从数据中学到的。
位置向量可以用独热表示,第i个输入对应i-1为1其余为0

self-attention的使用:
取代rnn模型,并行化计算效率更高
transformer模型:
总体框架

流程:
输入a加上位置向量后,通过multi-head的attention获得另一个序列b,然后再将输入和输出相加获得b’
再进行layer normalization或者是batch normalization

decoder的输入是上一个时间步的输出,注意attention使用了mask,对已经产生的序列进行attend
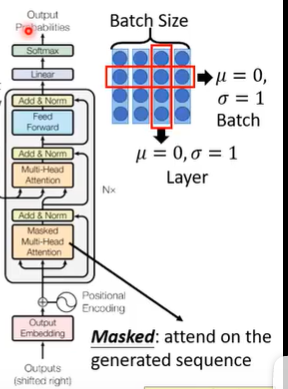
transformer可以代替seq2seq模型















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









