







Stream
什么是Stream?
Java8最值得学习的特性就是Lambda表达式和Stream API,如果有python或者javascript的语言基础,对理解Lambda表达式有很大帮助,因为Java正在将自己变的更高(Sha)级(Gua),更人性化。--------可以这么说lambda表达式其实就是实现SAM接口的语法糖。
Java8中,Collection新增了两个流方法。分别是Stream()和parallelStream()
Java8中添加了一个新的接口类Stream,相当于高级的Iteratpr。它可以通过Lambda表达式对集合进行大批量数据操作。或者各种非常便利,高效的聚合数据操作。
为什么要使用Stream?
总结一下本人最常用的场景。在工作中我们经常需要操作数据库。往往会出现一个方法中就需要对一个表的数据进行多次访问。例如我一个方法要做三次数据库操作。一次要计算总条数(count),一次要查询数据(select *),一次要对某些数据查询并进行累加(sum)等等。
三次都操作数据库不是不可以。但是过于频繁的访问数据库,无疑会增加网络传输的消耗,也会增加MySQL服务器的压力。那么,我们的目就转移到了,如何在减少与数据库访问的情况下完成这些业务逻辑。
此时,我们可以用将要查询的数据全部从数据库中获取到一个集合中,在这个集合中,根据不同的条件,过滤出我们想要的数据。如何高效的用代码在集合中过滤出我们想要的数据呢?
Java8之前,我们通常是通过for循环或者Iterator迭代来重排序合并数据,又或者通过重新定义Collections.sorts的Comparator方法来实现。这两种方式对于大数据量系统来说,效率并不是很理想。
Stream的聚合操作与数据库SQL的聚合操作sorted,filter,map等类似。我们在应用层就可以高效地实现类似数据库SQL的聚合操作了。而在数据操作方面,Stream不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
Stream简单例子之筛选查询
如果我们需要从一个list中根据某个条件筛选查询,不使用Stream的方式如下:

需要6行代码完成。
使用Stream改进后:
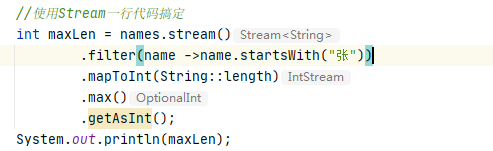
Stream操作API
官方将Stream中的操作分为两大类:终结操作和中间操作。
中间操作会返回一个新的流,一个流可以后面跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个流操作使用。这类操作都是惰性化的(lazy),也就是说,仅仅调用到这个类,还没有开始流的遍历(其实就是给接下来的终结操作先加入条件)。而真正的流遍历是在终结操作开始的时候才真正开始执行。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作。无状态是指元素的处理不受之前元素的影响。有状态是指该操作需要在之前的操作的基础上继续执行。
终结操作是指返回最终的结果。一个流只能有一个终结操作。当这个操作执行后,这个流就被用”光”了,无法再被操作。所以这必定是这个流的最后一个操作。终结操作才会开始进行流的遍历,并且生成结果。
终结操作又可以分为短路与非短路。
短路是指遇到某些符合条件的元素就可以得到最终结果。
非短路是指必须处理完所有元素才能得到最终结果。操作分类详情如下:
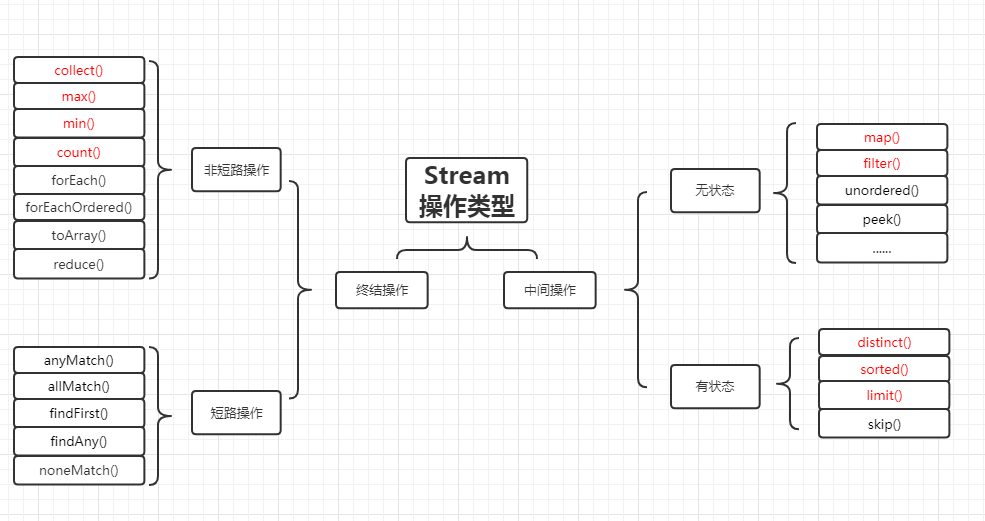
因为Stream操作类型非常多,总结一下常用的:
1. mapToXXX():将流中的原本类型的元素挨个加工变为XXX类型元素,常搭配sum()使用。
2. filter():对流中的元素进行遍历筛选,流下符合条件的数据组成新的流。
3. limit():返回指定数量的流元素。返回的是Stream里前n个元素。
4. skip():将指定数量的元素从流程排除,剩下的元素组成新的流并返回。
5. sorted():将流中的元素按自然排序进行排序。
6. distinct():将流中的元素去重后输出。
7. map():将流中的元素进行再次加工形成一个新的流(常用的有整个流留的小写转大写,以及List<Object>转其中某个元素List<Integer>)
8. peek():与map类似,但与map的区别是它相当于在操作的时候生成一个新的流,并且该操作不会影响到原本流的执行结果。因此基本用于debug。
9. collect():就整个流进行集合转换(转为list,set,map等)
Stream的底层实现
Stream操作叠加
一个Stream的各个操作是由处理管道组装。并统一完成数据处理的。
我们知道Stream有中间操作和终结操作,那么对于一个写好的Stream处理代码来说,中间操作是通过AbstractPipeline生成了一个中间操作Sink链表。当我们调用终结操作时,会生成一个最终的ReducingSink。通过这个ReducingSink触发之前的中间操作,从最后一个ReducingSink开始,递归产生一个Sink链。因此说Stream是惰性化的。如下图所示:

Stream的peek()和map()的区别
刚开始使用Stream的时候,看定义没懂peek是什么意思。看代码感觉用法和map很像。那么二者之间的区别是什么呢?
现有如下代码:
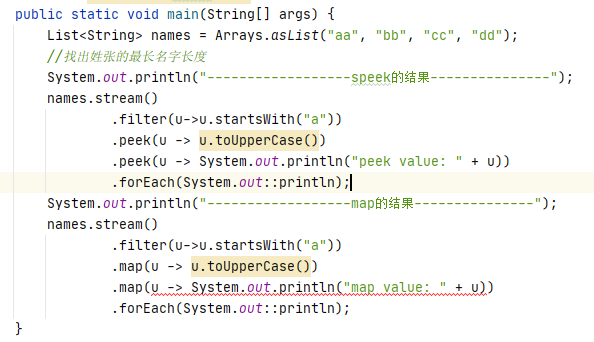
可以看到我们map()在执行打印时编译会报错,这是为什么呢?

从peek方法中,我们看到形参是Consumer。Consumer是没有返回值的,它只是对Stream中的元素进行某些操作。但是操作之后并不会影响整个流的数据。因此后续打印返回的依旧是原来的元素。

可以看到map方法中,形参是Function。Function是返回值的。所以经过map中间操作的流都会收到该操作影响。
而又由于它们各自的特性,打印操作这种无法返回值的就交给peek来处理。而大小写转换这种操作就交给map来处理。
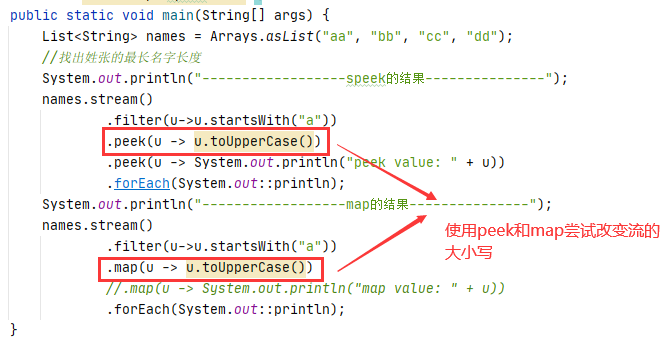
因此,我们常常使用peek作为中间操作的”debug”。
Stream的其它案例
现有一个List
按性别分组

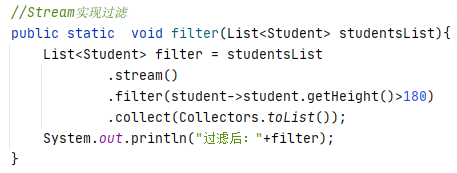
按身高过滤
按身高求和

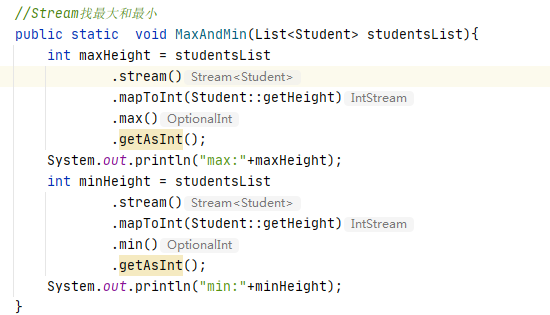
按身高找最大最小值
Stream的性能
需求
我们写三个方法,寻找list的最小值。来对比他们的执行效率。
常规迭代

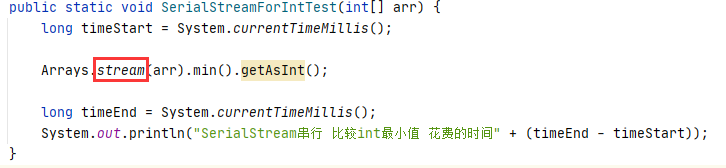
串行Stream
- 🔲
并行Stream
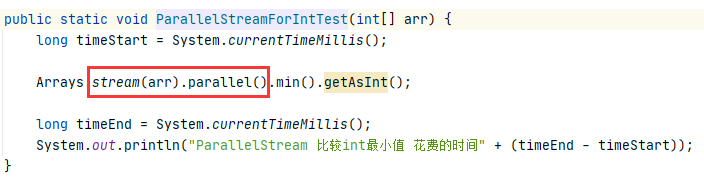
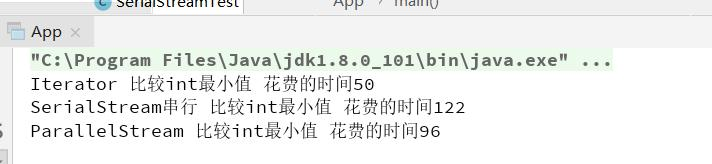
list中100个元素效率对比


解释原因
1. 常规的迭代代码简单,越简单的代码执行效率越高。
2. Stream串行迭代,使用了复杂设计,导致执行效率低。所以性能最低。
3. Stream并行迭代,使用了Fork-Join线程池,所以效率比Stream串行高。但还是比常规迭代慢。
list一个亿元素(使用默认CPU核心数)
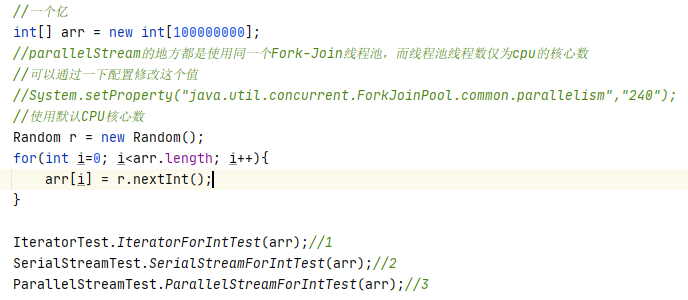

解释原因
1. Stream 并行迭代 使用了 Fork-Join 线程池, 而线程池线程数为 cpu 的核心数(我
的电脑为 12 核),大数据场景下,能够利用多线程机制,所以效率比 Stream 串行迭代快,同时多线程机制切换带来的开销相对来说还不算多,所以对比常规迭代还是要快(虽然设计和代码复杂)
2. 常规迭代代码简单,越简单的代码执行效率越高。
3. Stream 串行迭代,使用了复杂的设计,导致执行速度偏低。所以是性能最低的。
list一个亿元素(使用默认CPU=2)
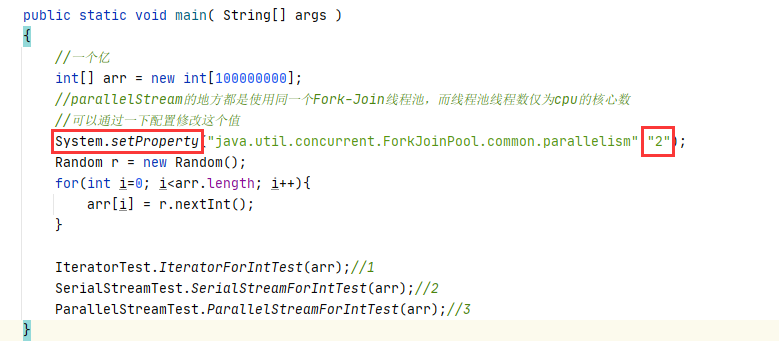

解释原因
Stream 并行迭代 使用了 Fork-Join 线程池,大数据场景下,虽然利用多线程机制,但是线程池线程数为 2,我们的Forkjoin体现的分而治之的思想,将任务划分为多份。如果线程数只有2个,任务数大于CPU核心数,就会发生任务对CPU资源的争夺(2个争抢的太厉害了)。所以对比常规迭代还是要慢(虽然用到了多线程技术)
list一个亿元素(使用默认CPU=240)
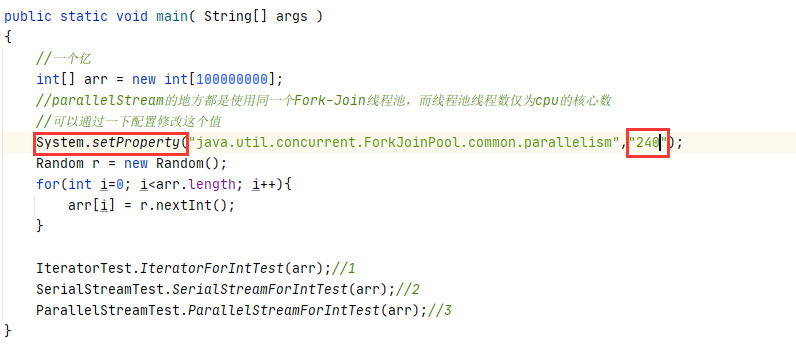
解释原因
Stream 并行迭代 使用了 Fork-Join 线程池, 而线程池线程数为 240,大数据场景下,虽然利用多线程机制,但是线程太多,线程的上下文切换成本过高,所以导致了执行效率反而没有常规迭代快。
Spliterator与Iterator的性能对比
此二者都是集合遍历器。在jdk1.8版本后出现了Spliterator。
二者的区别就是一个Iterator是顺序遍历,而Spliterator是并行遍历,常常搭配Stream使用,也就是我们上述案例。这两个迭代器的性能往往由底层决定。和机器CPU性能,核心数密不可分。在生产环境下我们要想使用更加合适高效的迭代器,往往需要我们实际压测得出最终方案。
如何合理使用 Stream?
我们可以看到:在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;而在大数据循环迭代中, parallelStream(合理的线程池数上)有一定的优势。
但是由于所有使用并行流 parallelStream 的地方都是使用同一个 Fork-Join 线程池(当并行的Stream操作变多时,这个设置很难控制),而线程池线程数仅为 cpu 的核心数。切记,如果对底层不太熟悉的话请不要乱用并行流 parallerStream(尤其是你的服务器核心数比较少的情况下)。
另外如果对线程池CPU核心数配置感兴趣的朋友,可以了解一下CPU密集型数据以及IO密集型数据下线程池的创建。
















 2675
2675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











