






作者丨白乌鸦@知乎 (已授权)
来源丨https://zhuanlan.zhihu.com/p/540726540
编辑丨极市平台
导读
本文将介绍一个无需前置条件即可自动着色的算法,实现了目前最好的着色效果,性能在所有指标上打败了标准的CNN colorization方法以及Google在ICLR2021提出的方法。

论文过段时间会挂到实验室主页上,代码很快也会开源。
实验室主页:https://ci.idm.pku.edu.cn/
模型介绍
我们造了一个自动着色的Transformer模型,以color tokens作为辅助,实现了目前最好的着色效果。这里说的color tokens来自于经典工作《colorful image colorization》(CIC)中量化ab color space的思路,我们将每个格子都当做一个token,借助position embedding得到格子之间的位置关系,从而获得color token的颜色相对关系(离得远的色差大,否则小),从而设计一系列模块来引导color token监督着色。
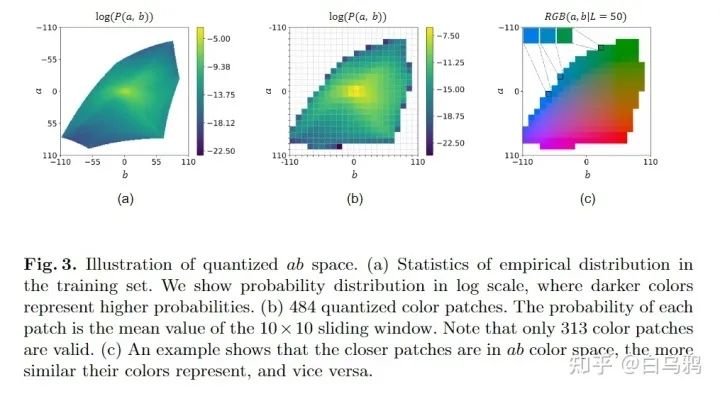
这里可视化一下我们的Pipeline,可以看到基本上不需要对transformer结构做太多魔改,只需要依靠我们设计的Luminance-selecting module, Color Attention和Color query等模块,依靠ab color space中颜色分布的先验知识,就可以实现好的着色性能。
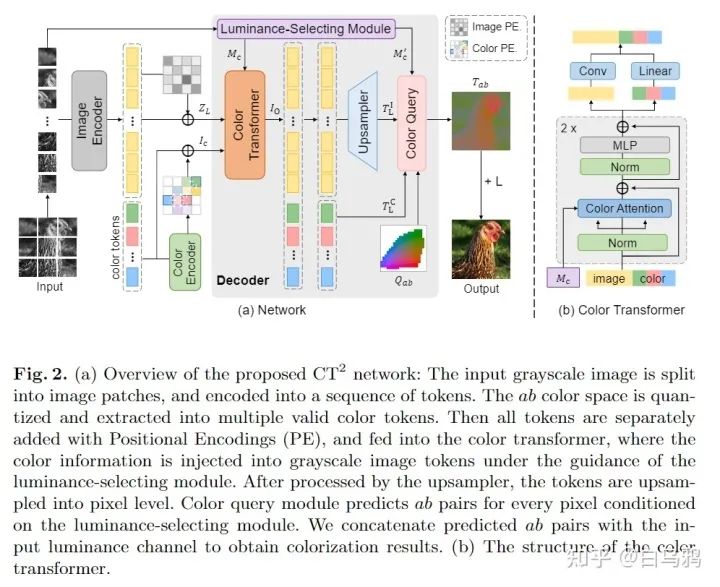
我们的模型不需要任何前置条件(例如目标检测主要着色物体,或者先用inversion GAN生成个参考图像),就能生成正确颜色语义和丰富饱和度的图像。因为没有前置条件的需求,所以使用场景更广(例如不受限于检测器可以检测的目标的类别,以及GAN可以生成的图像的类别)。

实验结果
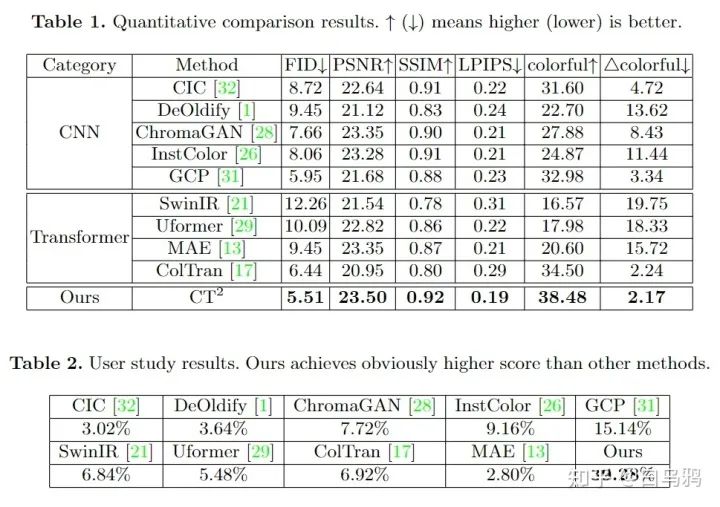
下面是我们的分数和user study,我们对比了标准的CNN colorization方法,以及Google在ICLR2021提出的第一个colorization transformer,最终性能在所有指标上都打过了他们;我们额外比较了一些热门的图像修复算法,但显然专门为colorization设计的算法性能更优;我们还比较了著名的预训练模型MAE,并把colorization当做他的一个下游任务来finetune,但他在这个任务上看起来也不是很聪明的样子。
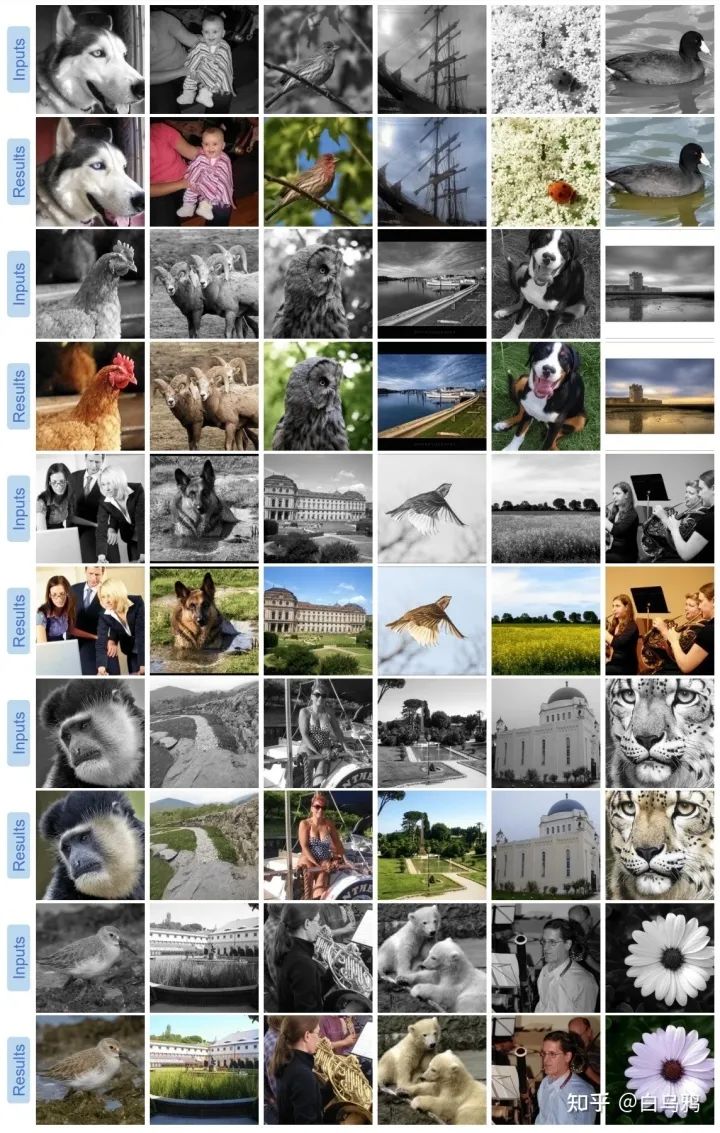
下面展示一些修复老照片的结果

然后是一些灰白图像上色的结果


推荐阅读
欢迎加入DLer-顶会论文分享交流群!
大家好,这是顶会论文分享群里,群里会第一时间发布CVPR、ECCV、ICCV、NIPS、AAAI、ICML、ICLR的论文解读和交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!















 1374
1374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









