






来源:新智元
英伟达高级科学家Jim Fan认为,2024年将是AI视频年。
我们已经见证,AI视频生成领域在过去一年里发生的巨变,RunWay的Gen-2、Pika的Pika 1.0等工具实现了高保真度、一致性。
与此同时,扩散模型彻底改变了图像到图像(I2I)的合成,现已逐渐渗透到视频到视频(V2V)的合成中。
不过,V2V合成面临的难题是,如何去维持视频帧之间时间连贯性。
来自得克萨斯大学奥斯汀分校和Meta GenAI团队成员,提出了一个能够保持一致性的V2V合成框架——FlowVid。
它通过利用空间条件和源视频中的时间光流信息,实现了合成的高度一致性。

论文地址:https://arxiv.org/abs/2312.17681
研究人员通过对第一帧进行光流变换编码,并将其作为在扩散模型中的辅助参考。
这样,模型就可以通过编辑第一帧使用任何流行的I2I模型,并将这些编辑效果传递到连续的帧中,实现视频合成。
值得一提的是,最新方法仅需1.5分钟,就能生成一段4秒,每秒30帧、分辨率为512×512的视频。
与此同时,FlowVid能够无缝与现有I2I模型配合,支持多种修改方式,包括风格化、物体替换和局部编辑。
网友将其称为,改编游戏规则的新论文。
一起看看,FlowVid在视频到视频合成上的强大效果。
演示

原始视频

Prompt:a woman wearing headphones, in flat 2d anime
提示:一位戴着耳机的女性,2D动画风格

Prompt:a Greek statue wearing headphones
提示:一尊戴着耳机的希腊雕塑

原始视频

Prompt:a Chinese ink painting of a panda eating bamboo
提示:一幅熊猫吃竹子的中国水墨画

Prompt:a koala eating bamboo
提示:一只正在吃竹子的考拉

原始视频

Prompt:A pixel art of an artist's rendering of an earth in space
提示:一幅以像素画风格呈现的地球在太空中的艺术绘制

Prompt:An artist's rendering of a Mars in space
提示:一幅太空中的火星的艺术绘制
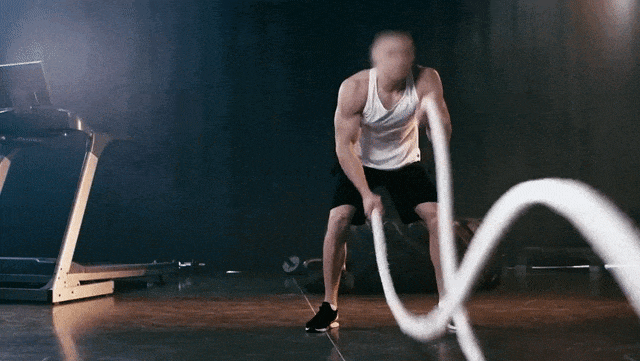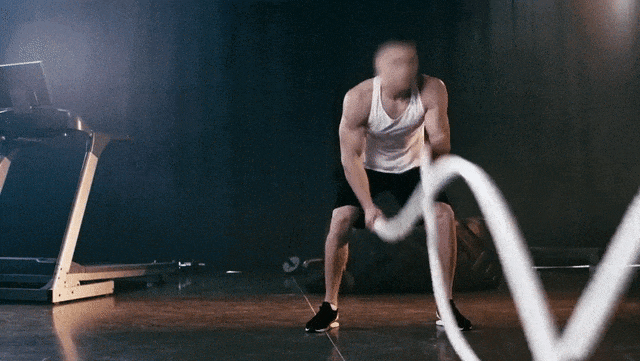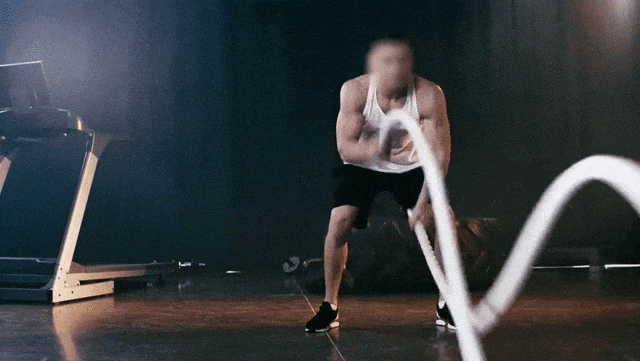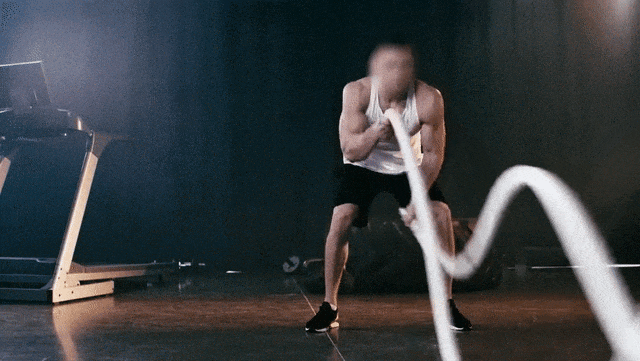
原始视频
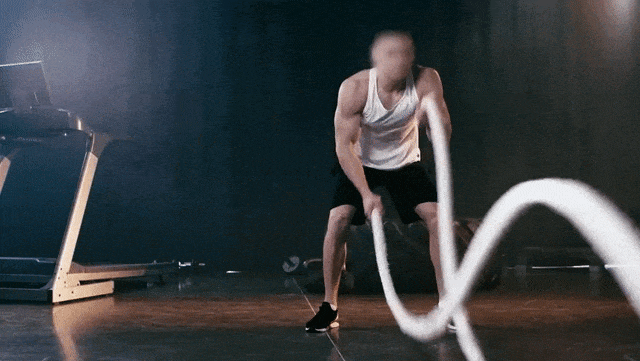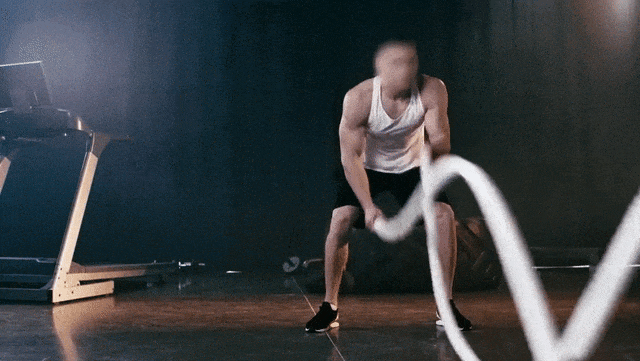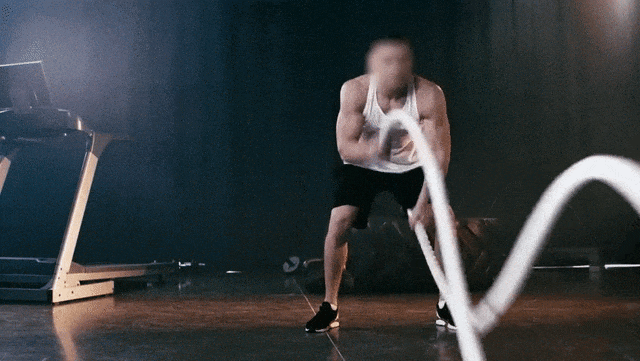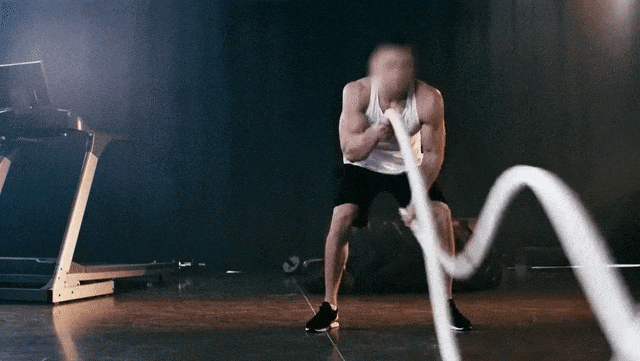
Prompt:Ukiyo-e Art a man is pulling a rope in a gym
提示:一幅浮世绘风格的作品,描绘了一名男子在健身房拉绳子

Prompt:A gorilla is pulling a rope in a gym
提示:一只大猩猩在健身房拉绳子

原始视频

Prompt:A shirtless man is doing a workout in a park, with the Egyptian pyramids visible in the distance
提示:一位光着上身的男士在公园锻炼,背景是遥远的埃及金字塔

Prompt:Batman is doing a workout in a park
提示:蝙蝠侠在公园锻炼
控制不完美「光流」,实现视频合成一致性
视频到视频(V2V)合成仍然是一项艰巨的任务。与静态图像相比,视频多了一个额外的时间维度。
由于文本的模糊性,有无数种方法可以编辑帧,使其与目标提示保持一致。但是,在视频中直接应用I2I模型,往往会在帧与帧之间产生令人不满意的像素闪烁。
也就是说,会出现不一致的现象。
为了提高视频中各帧之间的连贯性,有研究者尝试了一种方法——通过时空注意力机制,同时对多个视频帧进行编辑。
这种方法确实有所改进,但并没有完全实现我们想要的帧与帧之间的流畅过渡。其问题在于,视频中的运动只是在注意力模块中被隐式地保留下来。
另外,还有研究使用了视频中的显式光流引导(explicit optical flow guidance)。
具体来说,就是利用光流来确定视频帧之间像素点的对应关系,从而实现两帧之间像素级别的映射。随后,再用来生成遮挡物的掩码,以便进行图像修复,或者创建一个基准帧。
然而,如果光流估计不准确,这种严格的对应关系就会引发各种问题。

在最新的这篇论文中,研究人员尝试在利用光流技术的优势的同时,解决光流估计中存在的不足。
具体来说,FlowVid将首帧的图像通过光流扭曲来匹配后续的帧。这些经过扭曲处理的帧会保持与原始帧相同的结构,但会包含一些被遮挡的区域(灰色),如图2(b)所示。
如果使用光流作为严格的约束条件,比如对被遮挡的区域进行图像修复,那么不精确的腿部位置估计将持续存在。
研究人员试图将额外的空间条件(如图2(c)中的深度图)与时序条件结合起来。因为在空间条件下,腿的位置是正确的。
因此,空间-时间条件可以纠正不完美的光流,从而得到图2(d)中一致且准确的结果。

视频扩散模型FlowVid
对于视频到视频的生成,给定一个输入视频的n帧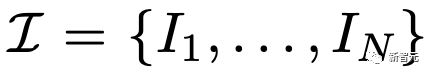 和一个文本提示符
和一个文本提示符 ,目标是将其转换为一个新的视频
,目标是将其转换为一个新的视频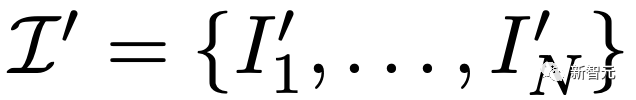 ,该视频遵循提示符
,该视频遵循提示符 ,同时保持跨帧的一致性。
,同时保持跨帧的一致性。
论文中,研究人员在膨胀空间(inflated spatial)控制I2I模型的基础上,建立了一个视频扩散模型。
我们训练该模型使用空间条件(如深度图)和时间条件(流扭曲视频)来预测输入视频。
在生成过程中,研究人员采用了编辑-传播过程:
- 使用流行的I2I模型编辑第一帧。
- 使用训练好的模型在整个视频中编辑内容。

这种解耦设计允许研究人员采用自回归机制:当前批的最后一帧可以是下一批的第一帧,从而能够生成更长的视频。
FlowVid整体流程如下图:
(a)训练:首先从输入视频中获取空间条件(预测深度图)和估计光流。
对于所有帧,使用光流从第一帧开始进行扭曲。经过光流扭曲后的视频结构预计与输入视频相似,但会有一些遮挡区域(标记为灰色,放大后效果更佳)。
研究人员使用空间条件c和光流信息f训练视频扩散模型。
(b)生成:用现有的I2I模型编辑第一帧,并利用输入视频中的光流得到光流扭曲编辑后的视频。这里,光流条件和空间条件共同指导输出视频的合成。

效果碾压SOTA
研究人员对25个DAVIS视频集和115个人工设计的测试用例进行了用户研究。
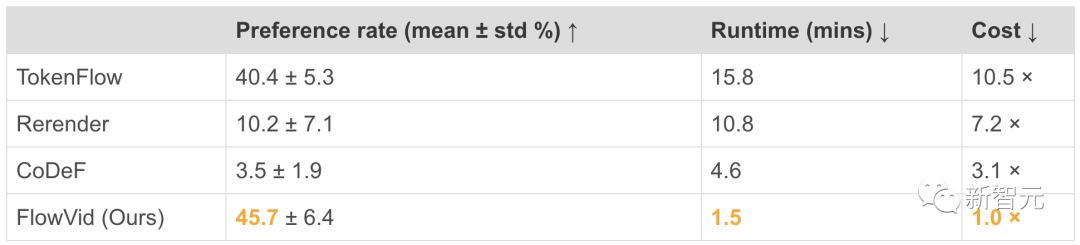
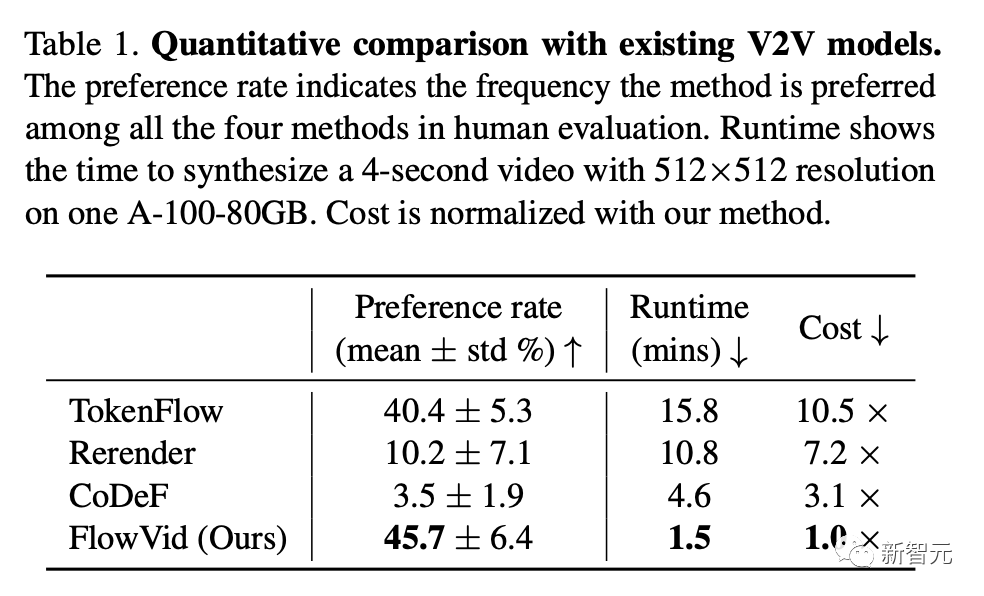
其中,偏好率是在人类评估中该方法被选择的频次。运行时间是指在一台配备了A100 80GB显卡的计算机上,合成一个分辨率为512x512、时长为4秒的视频所需的时间。而成本则是以FlowVid为基准进行归一化处理之后得到的。
如下是与代表性的V2V的模型进行的定性比较。
FlowVid方法在及时对齐,以及整体视频质量方面脱颖而出。
看得出,直接将ControNet应用于每帧,还是会出现明显的闪烁,比如海盗的衣服和老虎的皮毛上。
CoDeF在输入视频中运动量较大时,会产生明显模糊的输出结果,比如人的手和老虎的脸,这些区域较为明显。
而Rerender经常无法捕捉大动作,比如桨的运动。此外,编辑过的老虎腿的颜色往往会与背景融为一体。

一个海盗在湖上划船

一幅老虎行走的油画

一位身着圣诞老人服装的女生站在雪景中,平面2D动画
在定量比较中,研究人员选择了与CoDeF、 Rerender和TokenFlow三个模型进行了对比。
如下表所示,FlowVid获得了45.7%的偏好率,大大优于CoDeF (3.5%)、 Rerender (10.2%)和TokenFlow (40.4%)。
此外,研究人员还在表1中比较了与现有方法的运行效率。因为视频长度不同,处理时间也不同。
这里,使用的是120帧的视频(4秒视频,30 FPS ),分辨率设置为512×512。
研究人员通过两次自回归评估生成31个关键帧,然后使用RIFE对非关键帧进行插值。
实验结果得出总的运行时间,包括图像处理、模型操作和帧插值,大约是1.5分钟。
这显著快于CoDeF(4.6分钟)、 Rerender(10.8分钟)和TokenFlow(15.8分钟),分别是它们的3.1倍,7.2倍和10.5倍。
消融实验
此外,研究人员还进行了颜色校准和条件类型的消融实验。
当评估过程自第一组数据逐步进行到第七组时,未经颜色校准的结果呈现灰色(图中)。而采用了FlowVid的颜色校准方法后,结果显得更为稳定(图右)。

一个男人在火星上跑步
Canny边缘检测提供了更细致的控制手段(适用于风格化处理),而深度图则赋予了更高的编辑灵活性(适用于物体替换)。

局限性
当然,FlowVid依然存在一定的局限性,具体包括:
编辑后的视频第一帧与原始视频第一帧在结构上不匹配(如上面的大象视频所示),以及快速运动导致的明显遮挡问题(如下面的芭蕾舞女视频所示)。


作者介绍
论文一作Feng Liang是得克萨斯大学奥斯汀分校的博士生。
此前,他于2019年获得清华大学的硕士学位,2016年获得华中科技大学的学士学位。
他的研究兴趣集中在高效机器学习(Efficient Machine Learning)、多模态学习(Multimodal Learning)及其应用领域。

通讯作者Bichen Wu是Meta GenAI的研究员。
在此之前,他于2019年获得加利福尼亚大学伯克利分校的博士学位,2013年获得清华大学的学士学位。

参考资料:
https://huggingface.co/papers/2312.17681
https://arxiv.org/abs/2312.17681
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









