






来源:Jack Cui
一、ChatTTS-ui
ChatTTS-ui 可以在网页端使用ChatTTS的功能,并提供API接口。

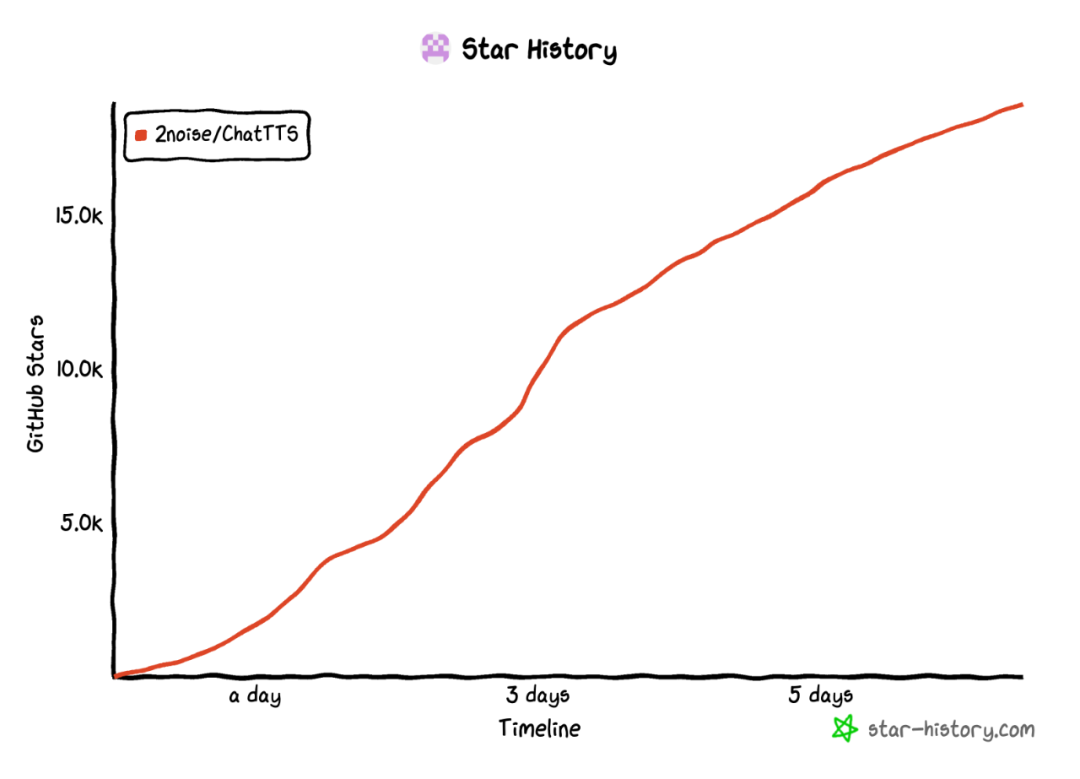
相信不少小伙伴已经关注到这款功能强大的TTS模型了。ChatTTS是一个语音生成模型,用于解决LLM对话任务。目前模型支持中英双语。它可以为对话生成响应,可以被集成到各个应用中。一周就爆涨了 18K+ 的 Star。
ChatTTS 使用了大量数据进行训练,大约有1000万小时的中文和英文数据。不过开源出来的是一个没有那么多数据的版本,因为作者团队使用了大量互联网数据进行训练,如果全部开源,可能会导致一些不必要的麻烦。
我们平时接触到的语音朗读,无非是短视频的小说分享,背景放个地铁跑酷或是解压小视频,生成小说文字的朗读。再有,也就是ChatGPT的这种语音生成。无一例外,我们可以用一个词概括——莫得感情。
而ChatTTS最核心的突破,就是它真的可以生成正常人讲话的语音语调!第一次听的时候,真的愣了一下才反应过来,的确非常真实。另外,你可以通过prompt提示想要的情绪,例如大笑、悲伤,ChatTTS可以生成带情绪,甚至是带笑声的语音。一句话里同时包含中文和英文,也是不在话下。
项目可以直接在本地部署,以下是一个最简单的使用示例:
git clone https://github.com/2noise/ChatTTS
pip install torch ChatTTS
import torch
import ChatTTS
from IPython.display import Audio
chat = ChatTTS.Chat()
chat.load_models()
texts = ["你好,这是一个使用示例!"]
wavs = chat.infer(texts, use_decoder=True)而这个ui项目则是直接将ChatTTS的功能集成到了网页端,有点类似于SD的WebUI,用户可以直接使用打包好的压缩包一键启动,非常方便。
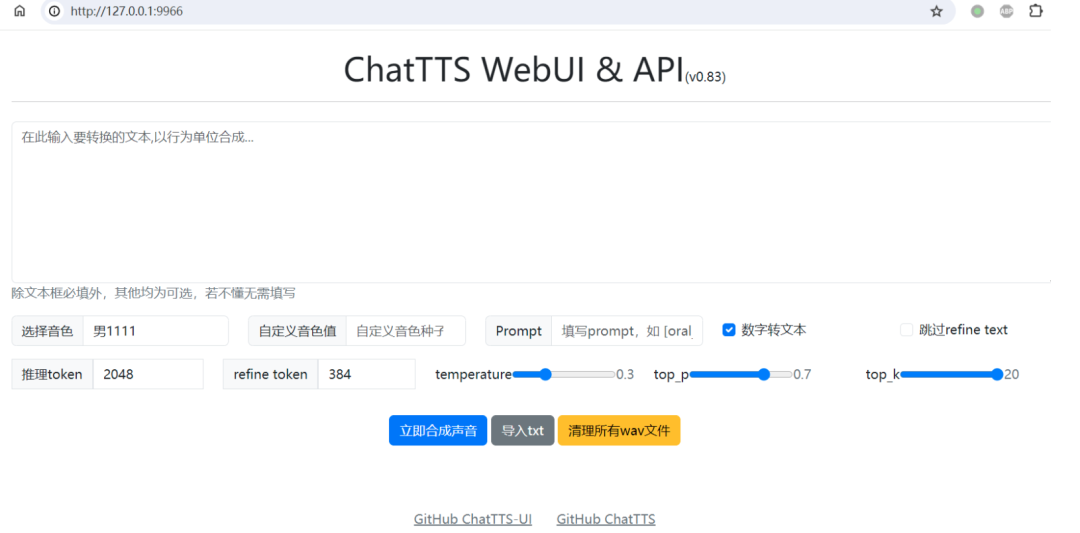
作者制作了一个简单的用户界面,在界面上你可以很轻松的调试你想控制的参数,随后接入的ChatTTS就会直接帮你生成音频了。
感兴趣的小伙伴,可以自行部署体验一下这个功能强大的模型。
项目地址:
https://github.com/2noise/ChatTTS
https://github.com/jianchang512/ChatTTS-ui
二、Omost
Omost 项目旨在将 LLM 模型的编码能力转换为图像生成能力。主要的作用,仍然是图像生成,但更为精细。
这个项目的取名很有意思,Omost与单词almost同音,意为大体上,几乎。也就是说,只要使用了Omost,你的图像生成大体就完成了。另一层含义来说,"O" 代表 "omni",与多模态相关。
那么,Omost相比起一般的AI画图,有什么优点呢?我们先来看看这个demo: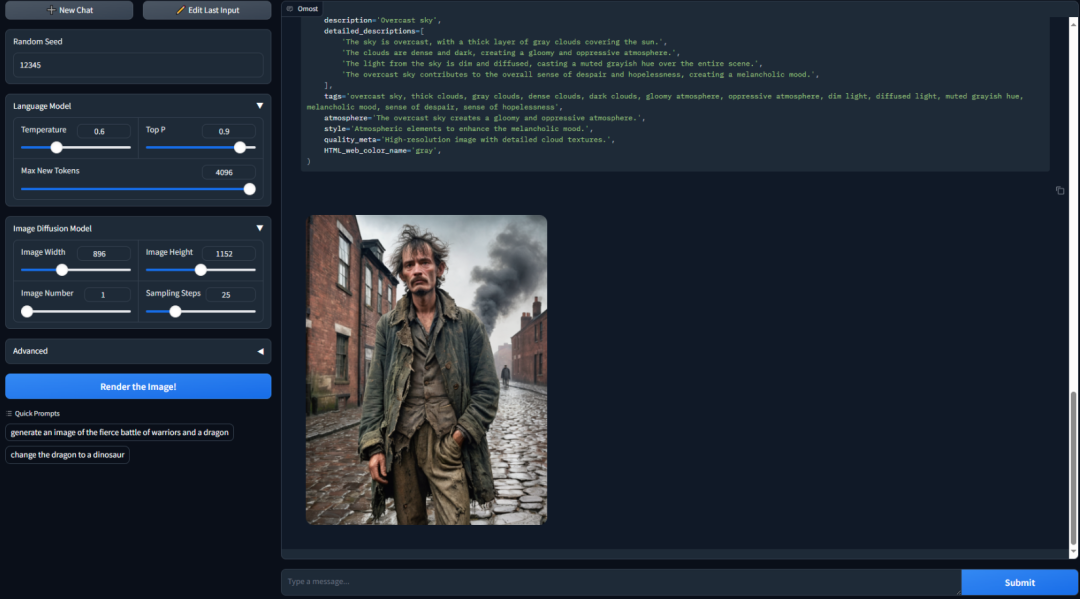
提示词大致是:a ragged man wearing a tattered jacket in the nineteenth century.
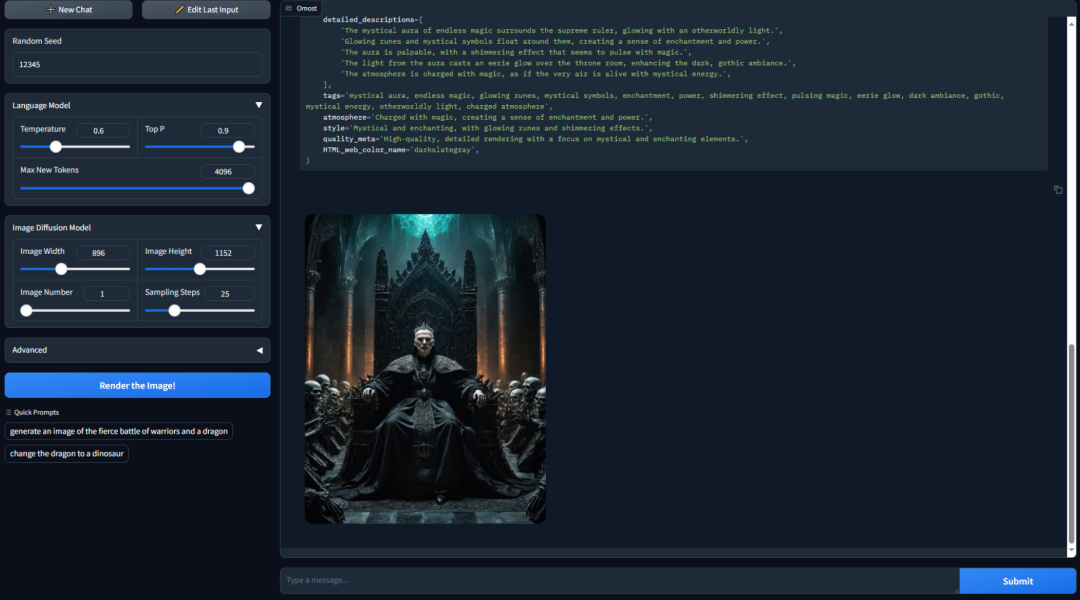
生成的效果看起来还是挺不错的,但根据这么简单的一个prompt,如何才能生成这么精细的画面?实际上,我们可以在输入中提供很多很多的细节提示,控制Omost制作出我们想要的图像。
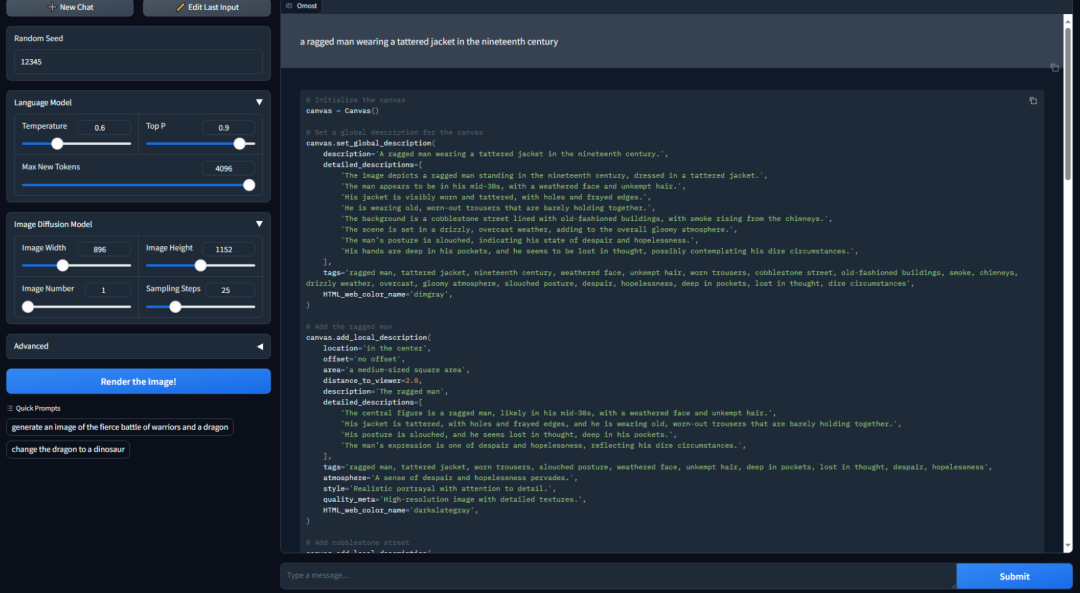
这张图上给出了很多细节,可以看到这些细节描述都被呈现在了输出结果图上。Omost允许LLM通过描述图像的不同部分来生成图像,全局描述用于描述整个图像的主题和背景,局部描述用于描述图像中的特定部分或对象。二者结合,我们可以高度精细化控制生成细节。
当前,项目提供三种模型以及它们的量化版本:
omost-llama-3-8b
omost-dolphin-2.9-llama3-8b
omost-phi-3-mini-128k

项目在本地可以直接部署:
git clone https://github.com/lllyasviel/Omost.git
cd Omost
conda create -n omost python=3.10
conda activate omost
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
python gradio_app.py不过,作者团队还说到,在部分GPU使用的情况下,项目可能会出现问题,而遇到这种情况,可以直接使用 Huggingface 在线体验。
在线体验地址:
https://huggingface.co/spaces/lllyasviel/Omost
项目地址:
https://github.com/lllyasviel/Omost
三、MusePose
看到这个名字是不是倍感熟悉?Muse 开源系列的最后一个模块,终于来了!
MusePose 是一个姿态驱动的图像到视频生成框架,专注于虚拟人类的生成,能够在给定的姿态序列下,生成参考图像中的人类角色的舞蹈视频。配合上MuseV和MuseTalk,可以实现端到端的虚拟人类生成,包括全身运动和互动能力。
这个项目测重于Pose,那我们就来谈谈姿态引导吧。
姿态引导是 MusePose 的关键技术之一,通过给定的姿态序列,模型能够生成参考图像中的人物在这些姿态下的动画。具体实现方式包括:
姿态对齐算法 (Pose Alignment Algorithm):该算法将任意舞蹈视频的姿态与任意参考图像对齐,确保生成的视频中的人物动作与输入姿态序列一致。
姿态序列生成:通过姿态对齐算法,生成参考图像人物在不同时间步的姿态序列,这些姿态序列用作生成视频的输入。
Muse系列的框架我们先前也有介绍过,作为这一系列的收官之作,我们已经可以通过几个框架的配合使用,生成效果非常棒的虚拟人视频了。感兴趣的小伙伴,可以体验看看。
项目地址:
https://github.com/TMElyralab/MusePose
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!
















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









