






随着视频生成技术的不断进步,可控跳舞视频合成也逐渐成为一项非常有吸引力的任务,受到了很多研究者的关注。给定一张参考人物图像和一段人体姿态序列,该任务旨在生成遵循给定的条件的时序连续且高保真的视频。
最近,来自华中科技大学、阿里巴巴、中国科学技术大学的研究团队提出了一种名为 UniAnimate 的全新框架,通过统一视频扩散模型来实现高效且长时的跳舞视频生成。该框架克服了目前可控跳舞视频合成领域高效性和保真度瓶颈,性能优于 MagicAnimate、Animate Anyone、Champ 等,为使用者带来了更广泛的应用前景。

论文地址:
https://arxiv.org/abs/2406.01188
项目主页:
https://unianimate.github.io/
Github地址:
https://github.com/ali-vilab/UniAnimate
传统的跳舞视频合成技术通常采样类似于 ControlNet 的范式,需要一个额外的参考模型来对齐身份图像和主干视频分支,这增加了优化负担和模型参数。另外,生成的视频通常时间较短,限制了实际应用的可能性。
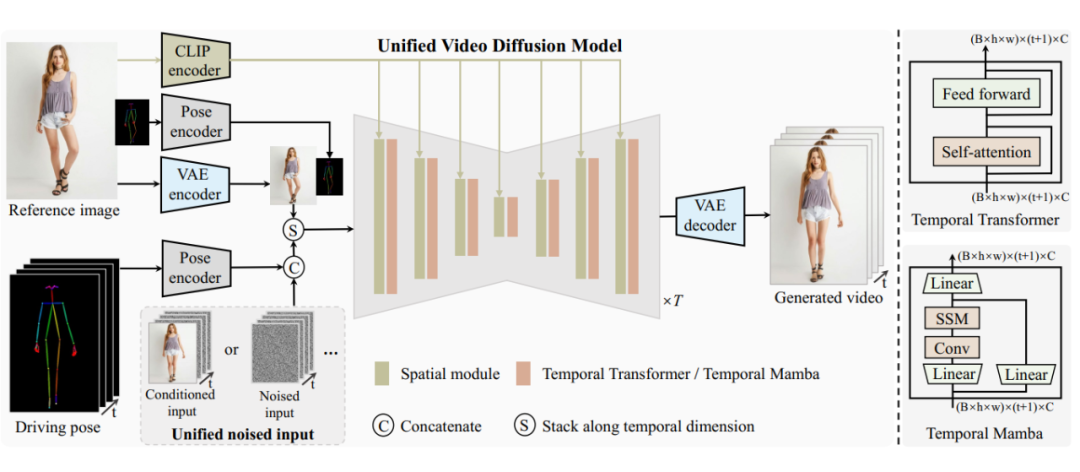
为了解决这些问题,UniAnimate 采用了一种统一的架构。不同于之前的方法采用 ControlNet-like 的架构,需要额外的 ReferenceNet 来编码参考图像表观特征来进行表观对齐。
UniAnimate 框架首先将参考图像、姿势指导和噪声视频映射到特征空间中,然后利用统一的视频扩散模型(Unified Video Diffusion Model)同时处理参考图像与视频主干分支表观对齐和视频去噪任务,实现高效特征对齐和连贯的视频生成。另外,引入了参考图像的姿态图作为额外的参考条件,促进网络学习参考姿态和目标姿态之间的对应关系,实现良好的表观对齐。
其次,研究团队还提出了一种统一的噪声输入,其支持随机噪声输入和基于第一帧的条件噪声输入,随机噪声输入可以配合参考图像和姿态序列生成一段视频,而基于第一帧的条件噪声输入(First Frame Conditioning)则以视频第一帧作为条件输入延续生成后续的视频。通过这种方式,推理时可以通过把前一个视频片段(segment)的最后一帧当作后一个片段的第一帧来进行生成,并以此类推在一个框架中实现长视频生成。
最后,为了进一步高效处理长序列,研究团队探索了基于状态空间模型(Mamba)的时间建模架构,作为原始的计算密集型时序 Transformer 的一种替代。实验发现基于时序 Mamba 的架构可以取得和时序 Transformer 类似的效果,但是需要的显存开销更小。
实验结果:
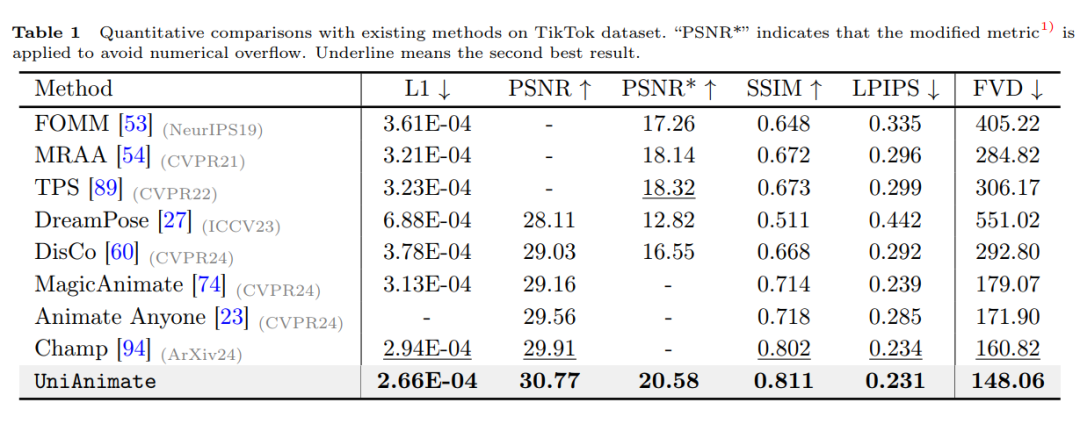
上表展示了 UniAnimate 方法和现有的先进方法在 TikTok 数据集上的对比,UniAnimate 方法在图片指标如 L1、PSNR、SSIM、LPIPS 上和视频指标 FVD 上都取得了最好的结果,说明了 UniAnimate 可以生成高保真的结果。

和现有方法的定性对比实验也可以看出,相比于 MagicAnimate、Animate Anyone,提出的 UniAnimate 方法可以生成更好的连续结果,没有出现明显的 artifacts,表明了 UniAnimate 的有效性。
最后来看下 UniAnimate 的生成视频:
1. 基于合成图片进行跳舞视频生成:
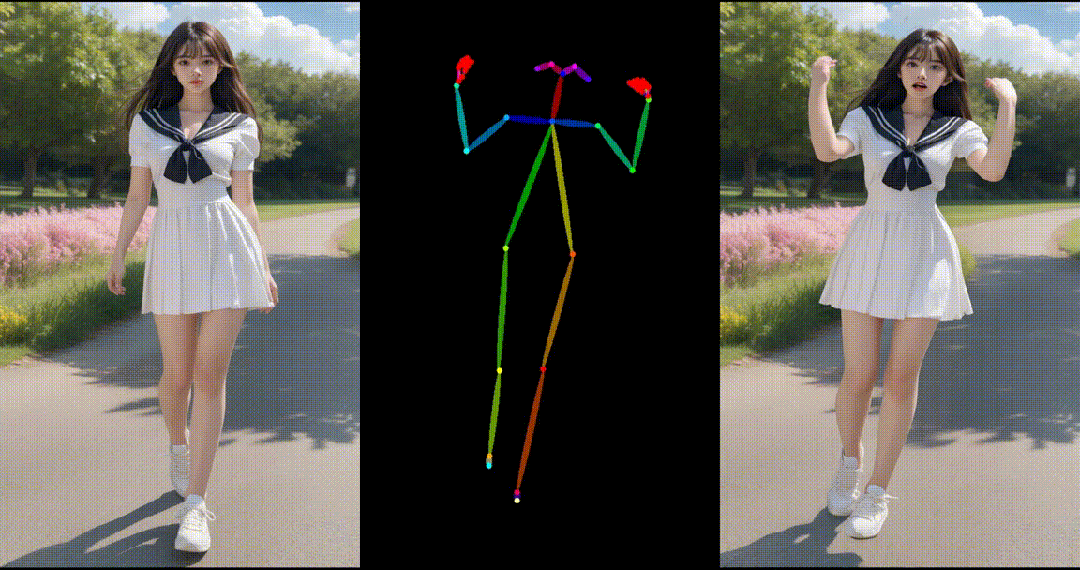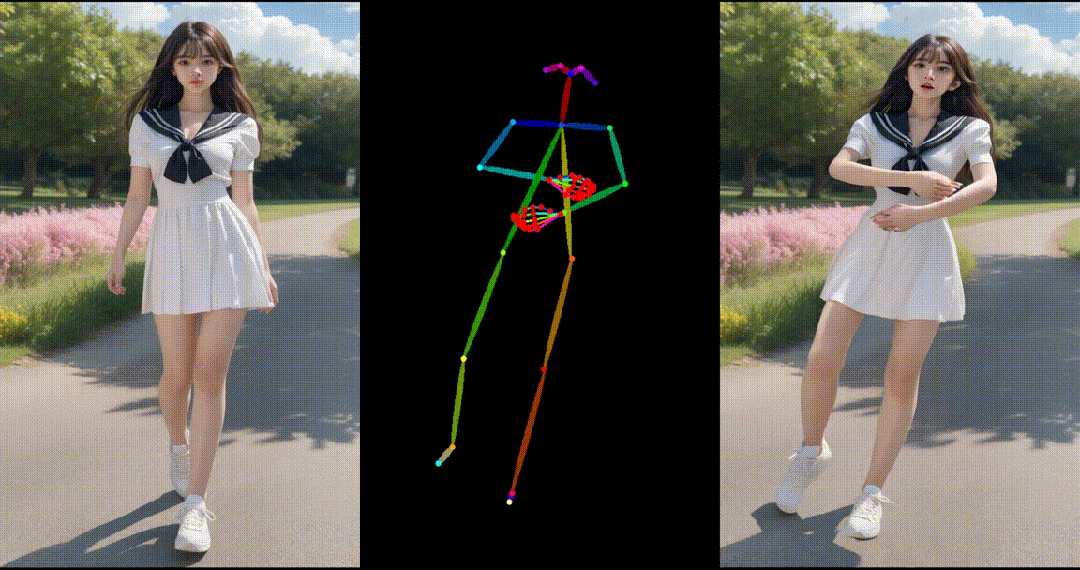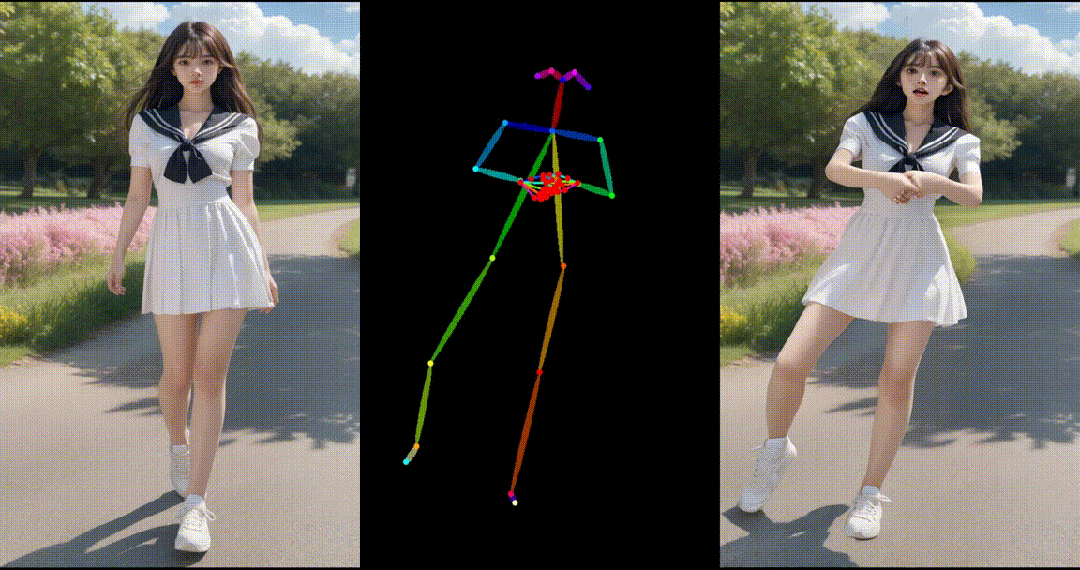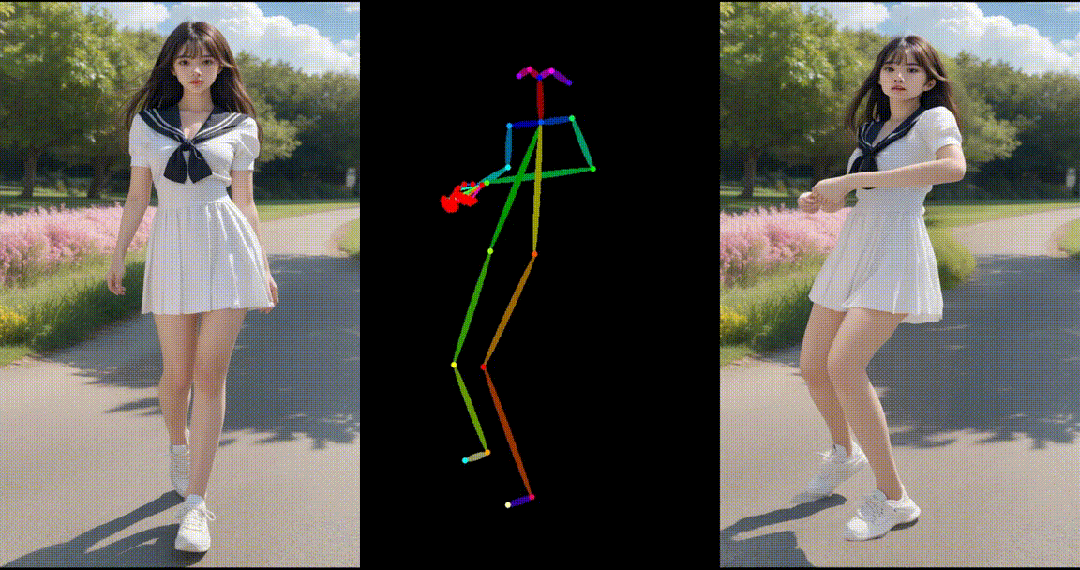
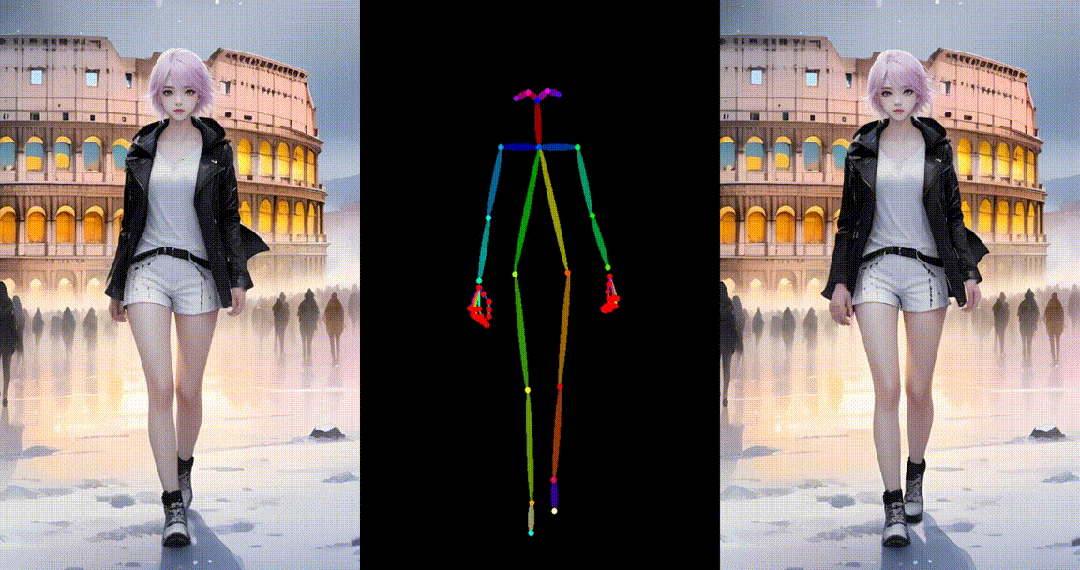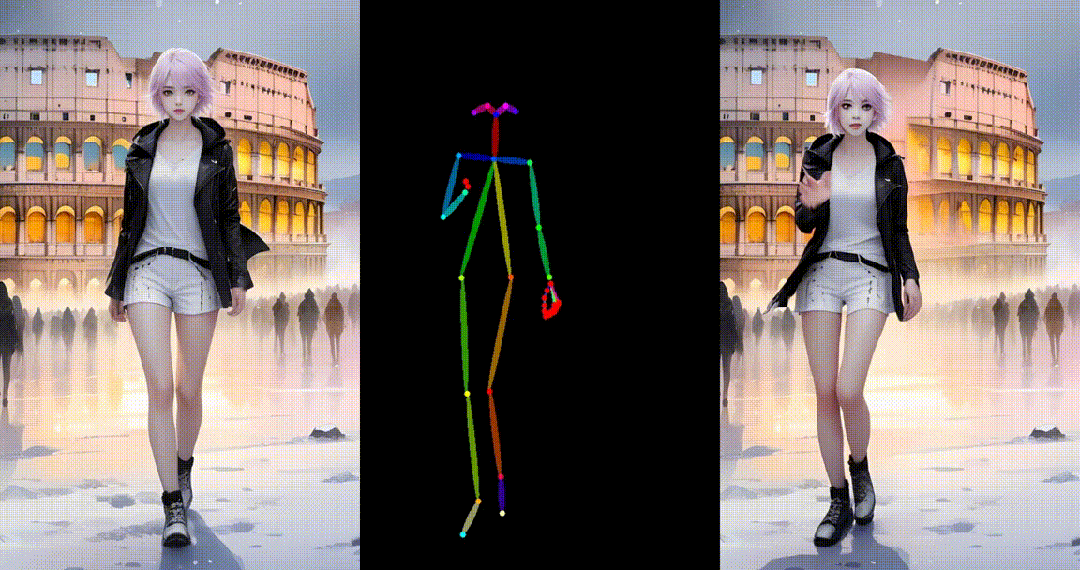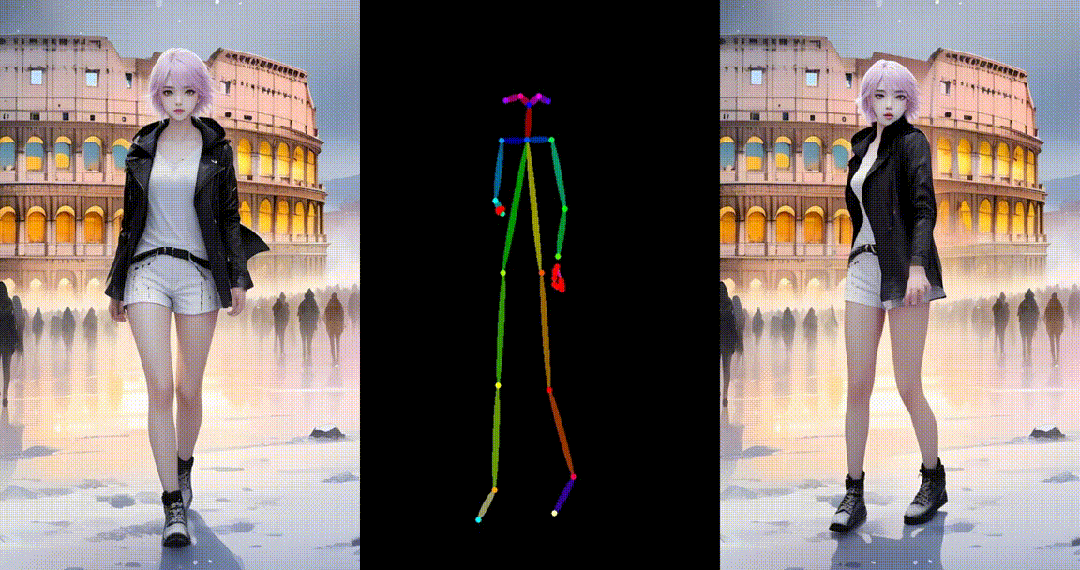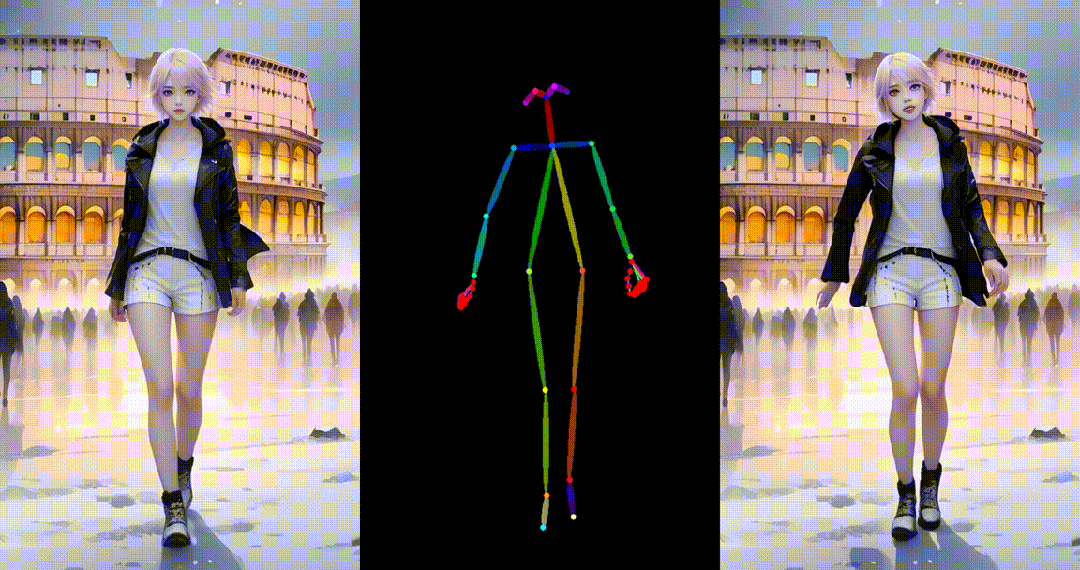
2. 基于真实图片进行跳舞视频生成:
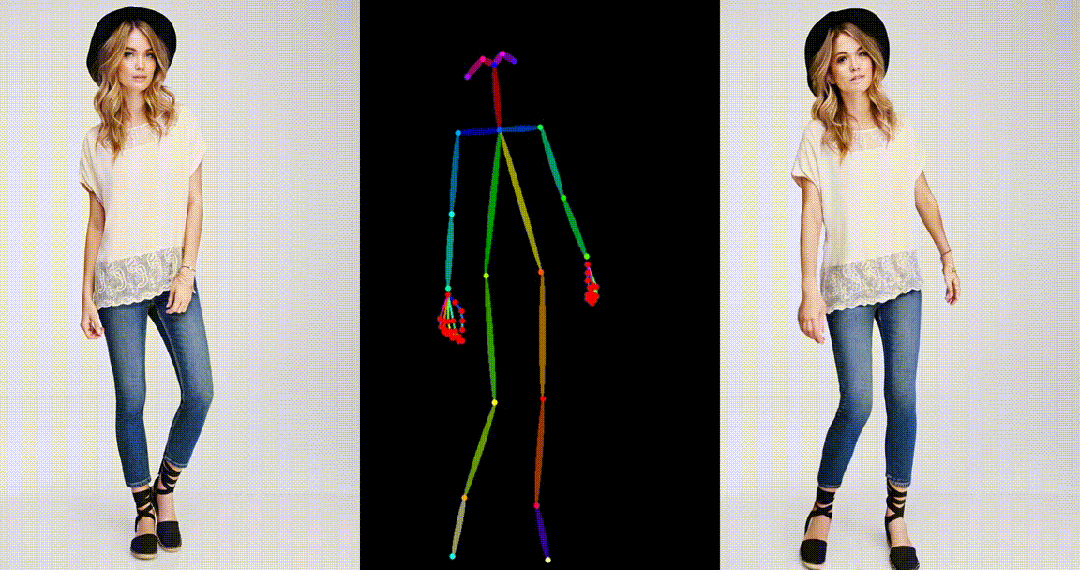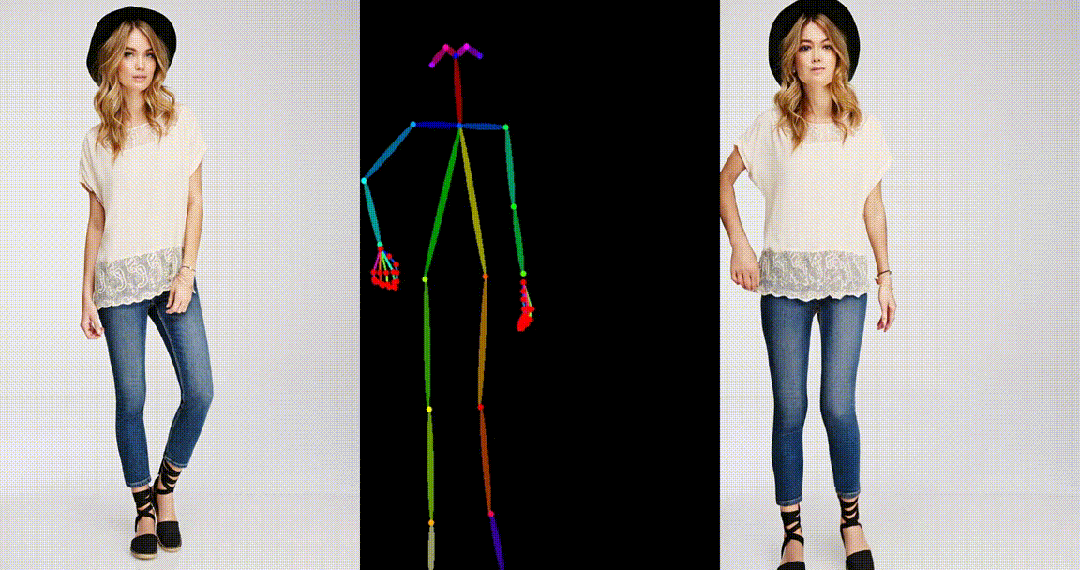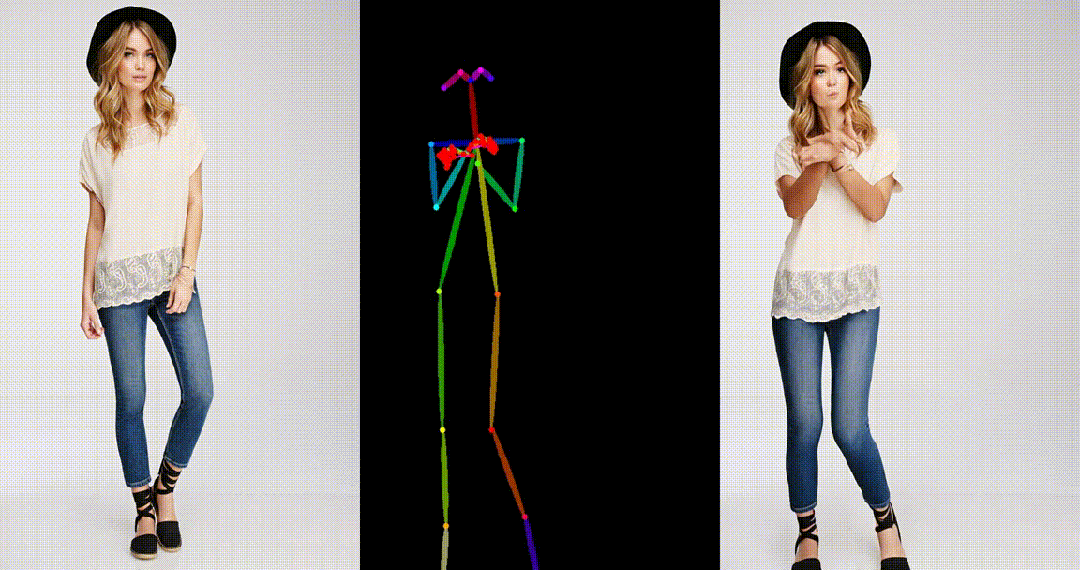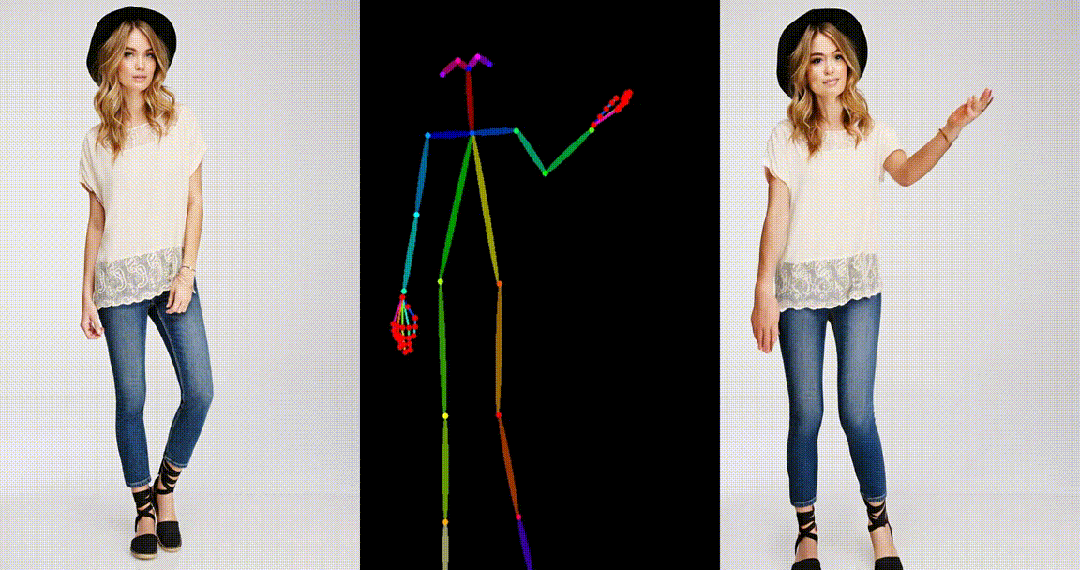

3. 基于粘土风格图片进行跳舞视频生成:

4. 马斯克跳舞:
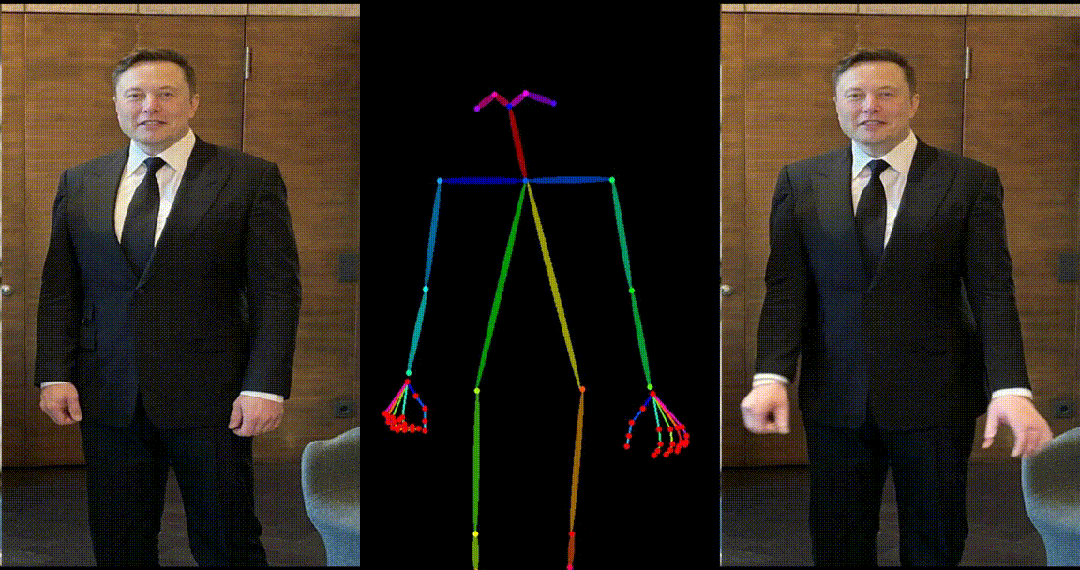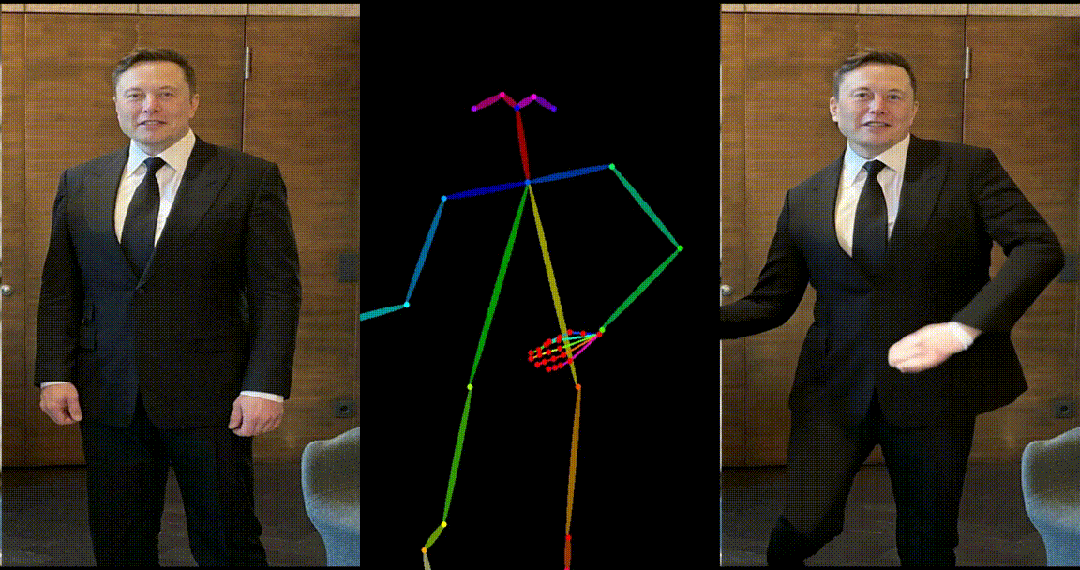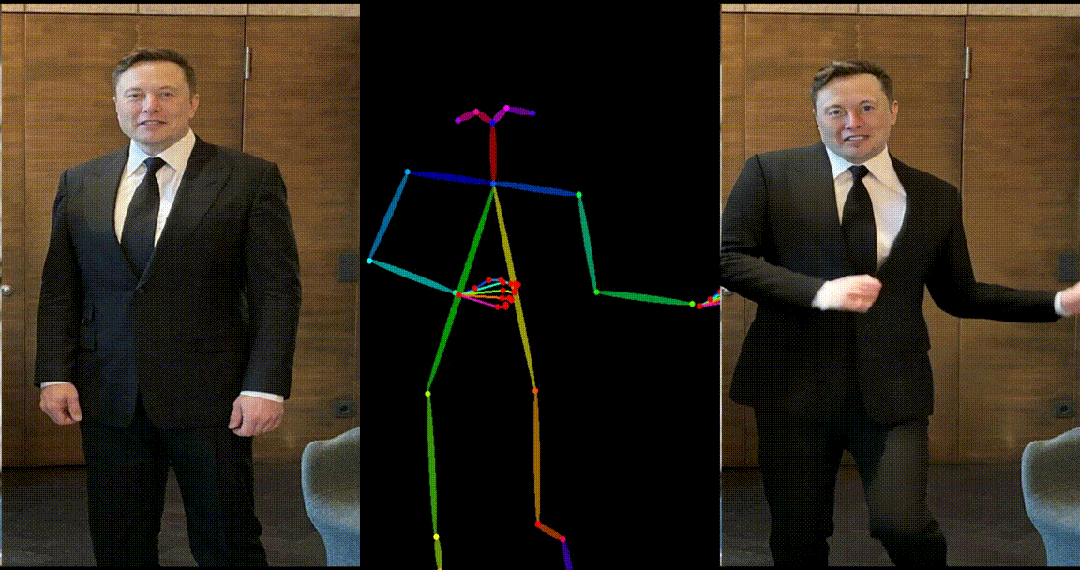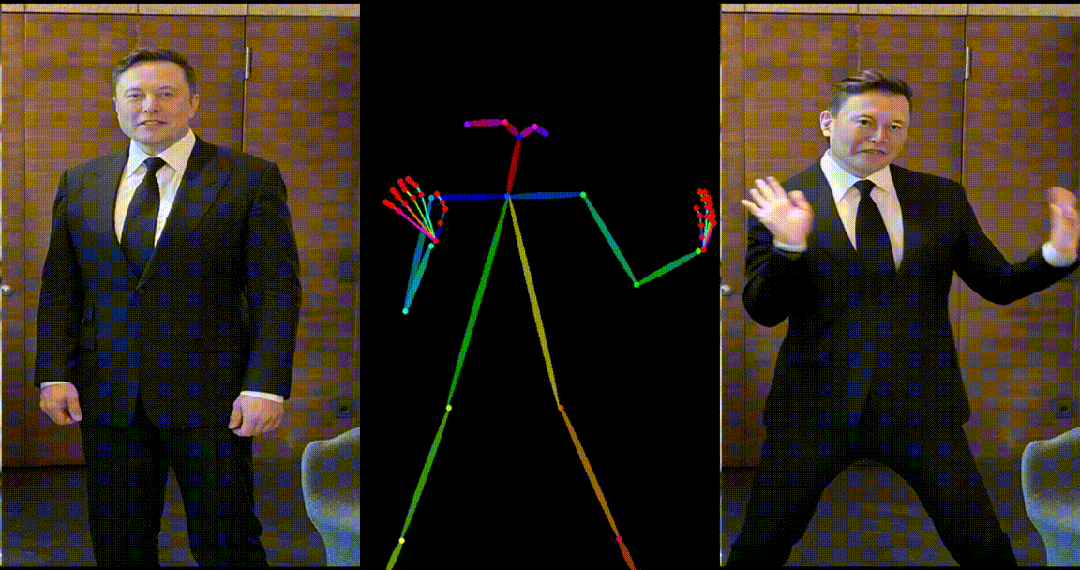
5. 基于其他跨域图片进行跳舞视频生成:
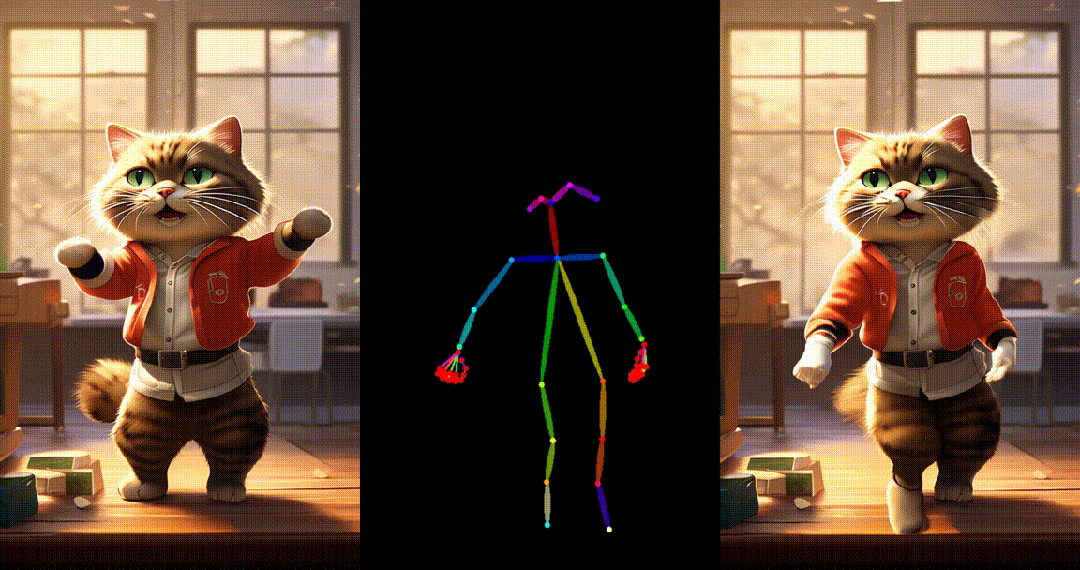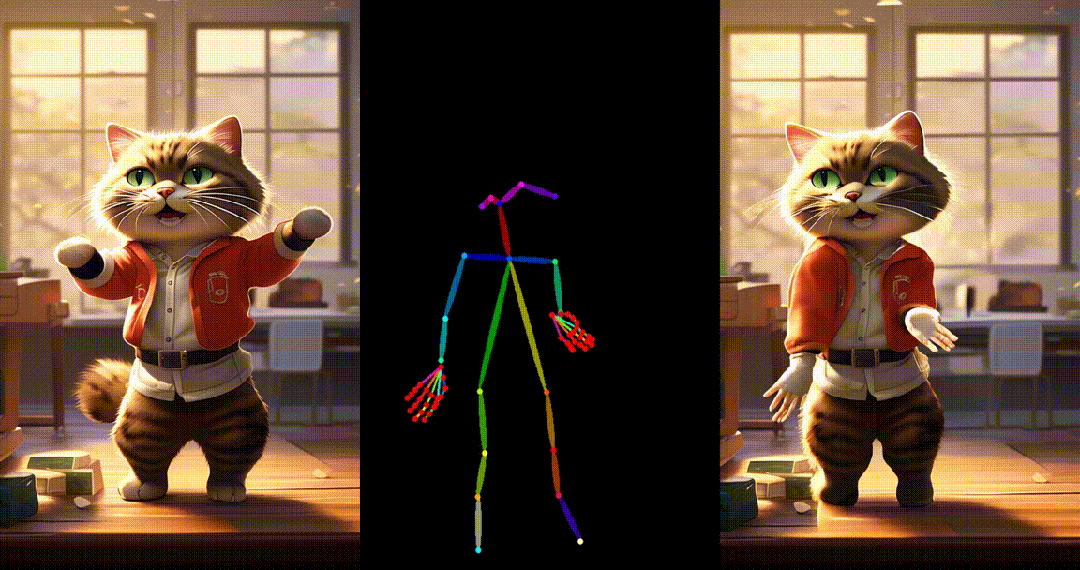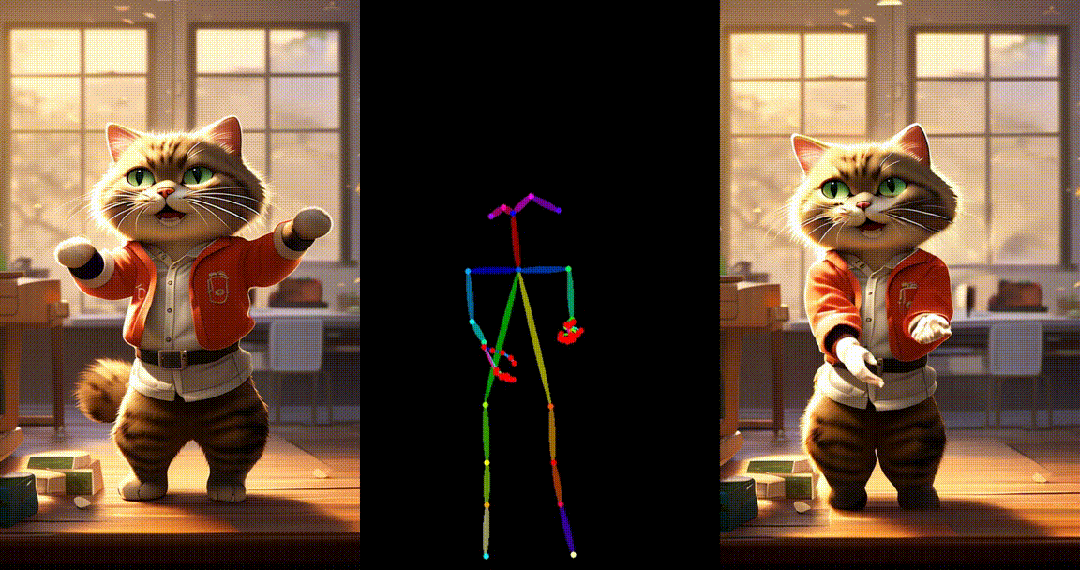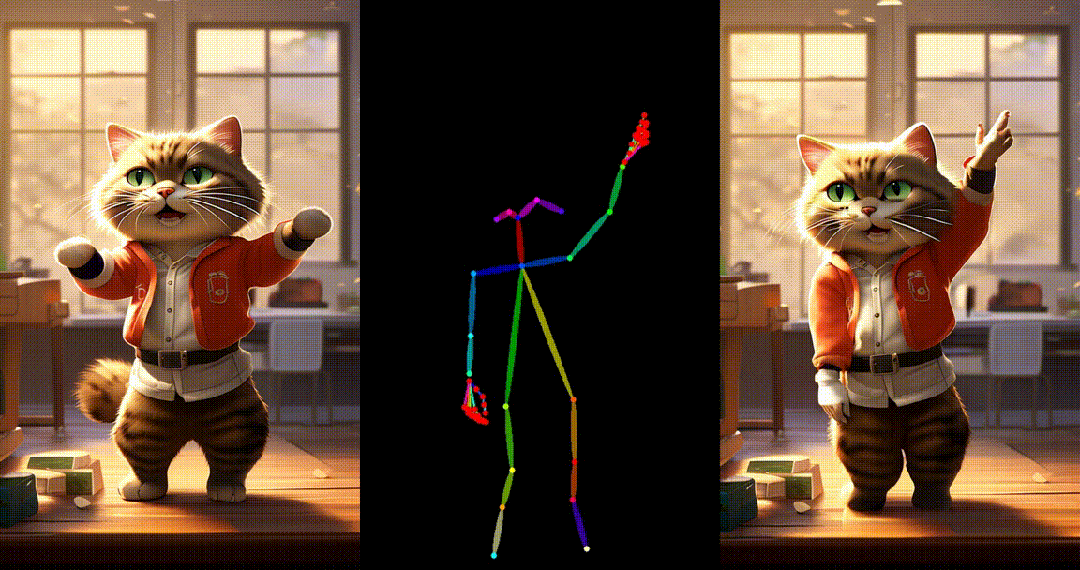
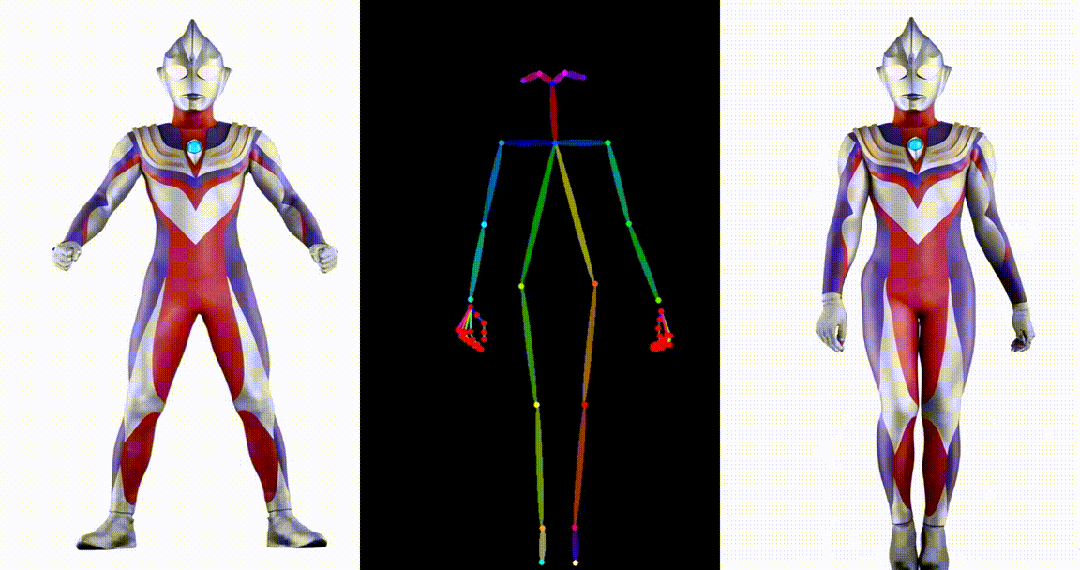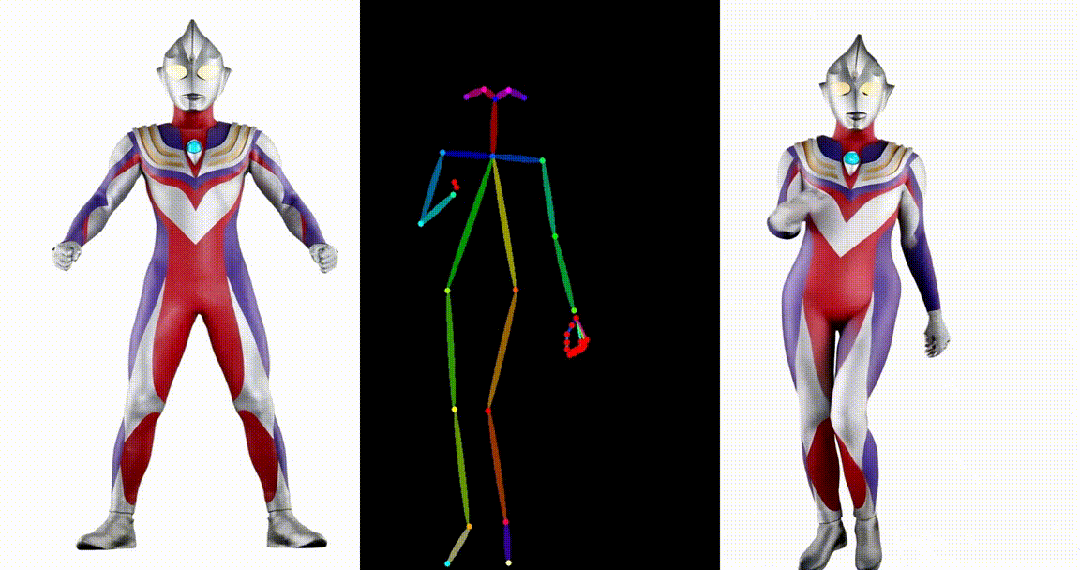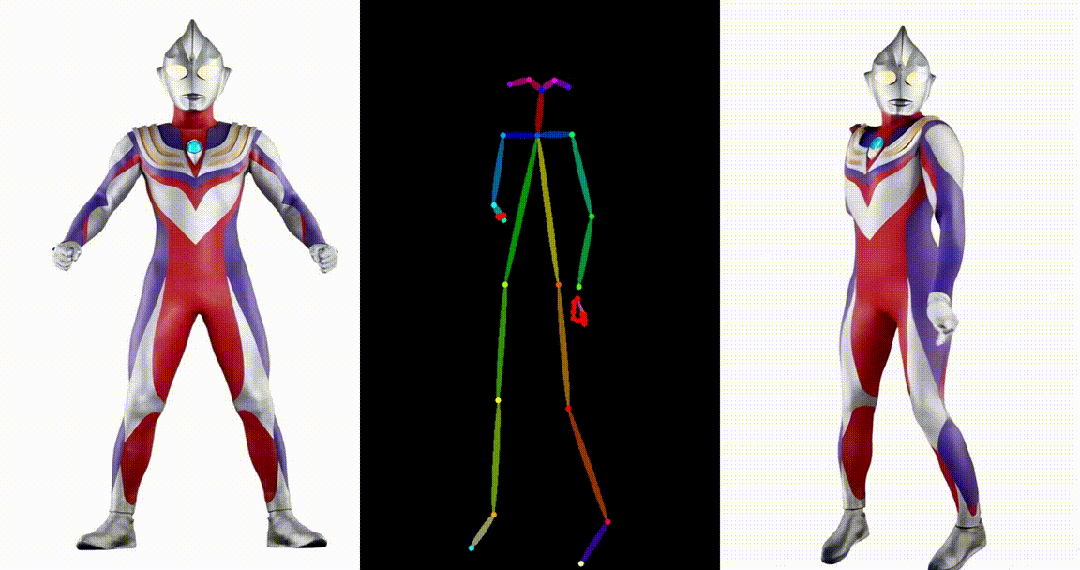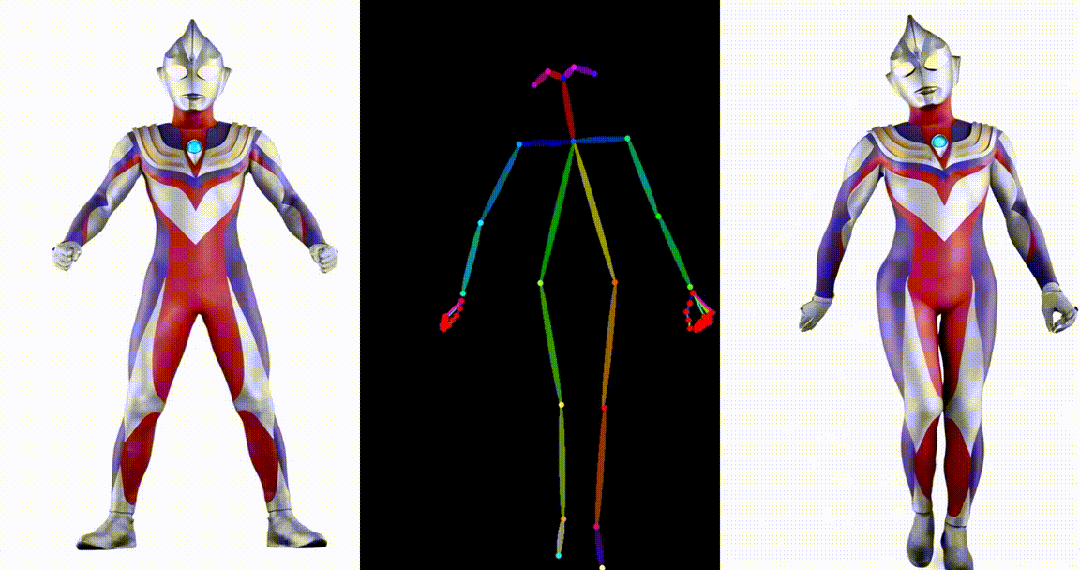
6. Yann LeCun跳舞:

可以看出 UniAnimate 可以针对不同领域来源的图片,生成高质量且连续的视频结果。获取更多高清视频示例和一分钟时长的生成视频请参考论文的项目主页:
https://unianimate.github.io/
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









