







一、慢查询
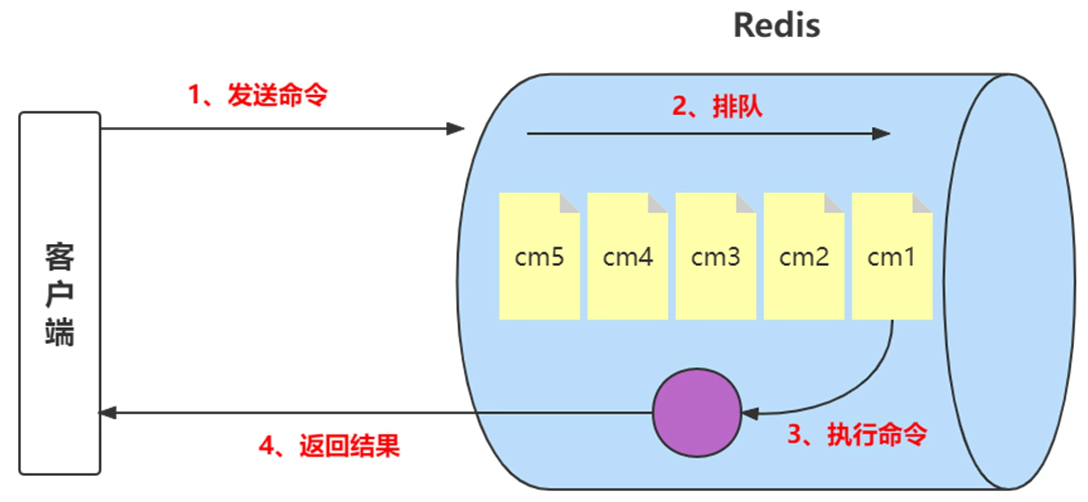
1、redis的命令执行流程
说明:在第3步运行时间超过10ms的时候记录为慢查询;
2、redis的慢查询
多慢算慢? ---> 超出阈值算慢
3、慢查询配置
10000微秒 --> 10毫秒;
动态设置:
4、慢查询操作命令
查询慢查询记录:slowlog get count
清空慢查询链表:slowlog reset

5、慢查询分析
单元素操作快
范围操作慢
统计操作快
不同数据结构时间复杂度分析:

二、PipeLine
1、什么是PipeLine?
RTT:往返时间,数据花在网络上的时间;
将所有的指令组装成pipeline,减少RTT;节约网络开销做批量处理;
2、注意事项:
pipeline设置的时候不宜设置的太大
redis使用pipeline的时候,内核输入输出的缓冲区为4K ~ 8K
单个TCP报文的最大值为1460 byte(1500 - IP头20 - TCP头20)
建议pipeline最大长度不超过1460 byte
三、事务
1、什么是事务?
都执行或者都不执行
Redis的事务是弱事务
不推荐使用Redis做事务
只有语法错误的时候才会做回滚,非法操作不会做回滚
2、命令
| 命令 | 作用 |
| multi | 开启事务 |
| exec | 提交事务 |
3、Watch机制
是一个监控机制,监控某个key
CAS:乐观锁
使用watch关键字监控某个key,如果在事务提交前这个key被其他客户端修改,那么当前客户端的事务会失败
4、pipeline和事务的区别
pipeline是客户端行为,在客户端将多个命令组装到pipeline中,发送给redis后做批处理
事务是一个特殊的命令,在提交之前不会正真执行
pipeline可以使用multi命令开启事务
四、Lua
1、什么是Lua?
本质是一个脚本语言,类似存储过程
2、使用Lua的好处
减少网络开销:可以将多个命令放到一个脚本中
原子操作:redis会将lua脚本作为整体执行(redis执行命令是单线程)
复用性:redis可以存储客户端发送的lua脚本,客户端可以复用脚本
3、命令
一个演示命令:
eval "return redis.call('mset',KEYS[1],ARGV[1],KEYS[2],ARGV[2])" 2 key1 key2 first second
解析:
eval:基础命令
redis.call:使用脚本调用redis指令
“2” :标识key的个数,剩下的就是value
script load “...” 命令可以保存一个脚本
返回一个SHA1的标识
使用【evalsha + 标识】调用脚本
五、redis + Lua语言实现限流
lua脚本可以设置某个用户在固定时间的固定访问次数
常用限流算法
1、固定窗口算法
在固定时间限制固定访问次数
弊端:可以在临界时间时,短时间内通过两份最大请求数量
例如:59s ~ 60s 时进入100个请求,60s ~ 61s 时进入100个请求,这时在2s内进入了200个请求
2、滑动窗口算法
让服务端在同一时间段内只接收count次请求,让客户端在接收响应后才向后滑动窗口
3、漏桶算法
放请求
先有一个桶,桶的容量是固定的
请求来了先放到桶中,桶满的时候就溢出,丢弃请求
桶底有个小洞,慢慢流出请求到服务端
4、令牌桶算法
取令牌
先有一个桶,桶的容量是固定的,用来存放令牌
以固定速率向桶中放令牌,桶满了就不放了
请求过来时先去桶中取若干个令牌,取到就执行,取不到就被限流
可以提前在桶里放多个令牌,来应对服务刚启动时过来了多个请求
5、桶限流缺点
时间复杂度高
六、发布 订阅
Redis不单纯干缓存,提供了许多即插即用的功能
1、结构图:
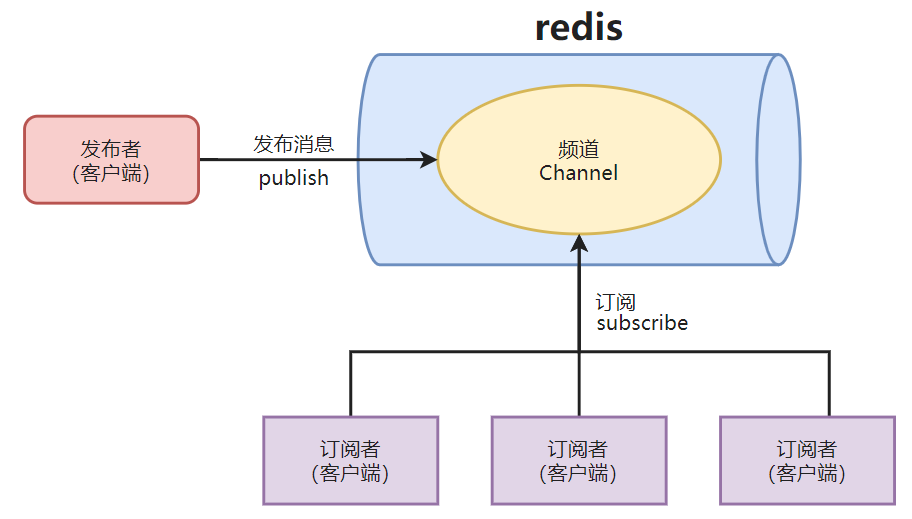
2、命令
| 命令 | 作用 | 返回值 |
| publish channel message | 向channel频道发布消息(message) | 返回订阅该频道的客户端个数 |
| subscribe channel1 | 订阅channel频道的消息 | 具体消息 |
| pubsub channels c* | 查看当前所有频道 | |
| pubsub numsub channel | 查看订阅channel频道的订阅者 | 第一个是channel名称 后面是订阅者个数 |
3、特点
发送即忘原则
七、Stream
1、是一个数据结构,用于消息中间件
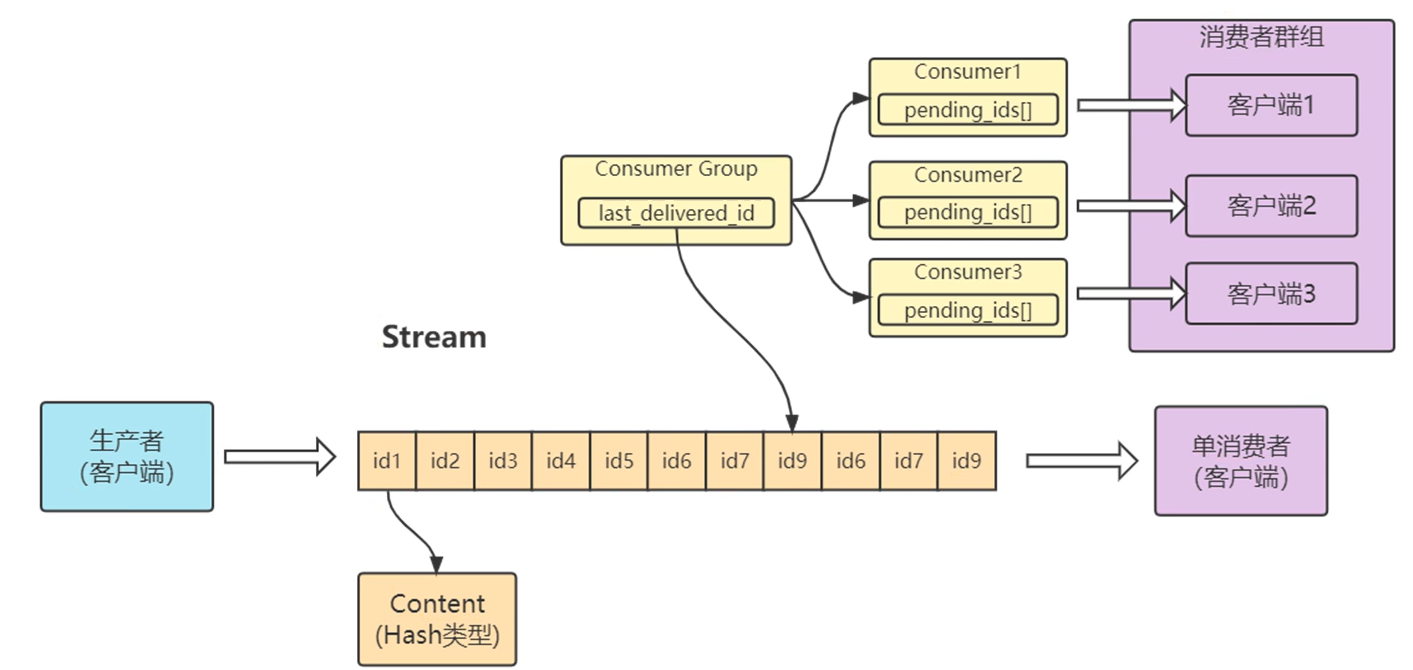
2、结构
消息id结构:毫秒-自增 // 一个毫秒内自增
id = 0-0 :从头开始
id = $ :从尾部开始
3、命令
| 命令 | 作用 |
| xadd stream1 * key value ... | 生产一个消息,* 是采用redis自带的消息id |
| xrange stream1 start end | 消费一个消息队列的消息 参数是start end start: -:代表最早的; id:消息id之后的 end: +:代表最晚的; 消息id之前的 |
| xlen stream1 | 查询消息个数 |
| xdel stream1 id1 ... | 删除特定id的消息 |
4、单消费者
类似于一个list结构,一端放消息,一端取消息;
| 命令 | 作用 |
| xread count 10 streams stream1 id | 从stream1读取消息 count 10:本次读取10条 streams:读取消息类型 stream1:消息队列的key id:从哪条消息开始读取(不包括id对应的这条消息) |
| xread block 0 count 1 streams stream1 $ | 起一个消息监听,有新消息就打印 block 0:一直阻塞(大于0就是阻塞多少毫秒) $ :获取当前最新的消息 读取到一个消息后,解除阻塞,打印消息 |
5、群组消费者
分布式系统中消息中间件的三大作用:
解耦
异步执行
削峰填谷(流量削峰)
场景:订单系统并发量高(10W) --> 持久层系统并发量低(1000)
方案:消费端需要一个群组增加并发量
| 命令 | 作用 |
| xgroup create stream1 consumerGroup1 0-0 | 创建一个消费者群组 xgroup create 组合命令激活命令提示 stream1 目标消息队列名称 consumerGroup1 群组名称 0-0:指定从id=-0-0的消息开始消费(从头消费) 任何消息的id都是 数字-数字(默认时间戳-自增id) |
| xgroup create stream1 consumerGroup3 $ | 创建一个消费者群组 $ :指定从将来最新的消息开始消费,舍弃掉之前的所有消息; |
| xinfo stream stream1 | 查询某个stream的详细信息 xinfo stream 组合命令激活命令提示 stream1 目标消息队列的名称 |
| xreadgroup group consumerGroup1 consumer1 count 1 block 0 streams stream1 > | 使用群组消费一条消息 xreadgroup 激活命令提示 group consumerGroup1 键值对,指定使用哪个群组 consumer1 指定一个消费者 count 1 键值对,指定消费几条消息 block 0 键值对,如果消费到消息就阻塞,一旦消费到就解除阻塞; streams stream1 键值对,指定消费哪个消息队列 > 打印符号 |
| xinfo consumers stream1 consumerGroup1 | 查询某个stream的群组信息 xinfo consumers 组合命令激活命令提示 stream1 消息队列名称 consumerGroup1 群组名称 |
| xack stream1 consumerGroup1 id | ack确认 xack 激活命令提示 stream1 消息队列名称 consumerGroup1 消费群组名称 id 确认哪条消息 |
八、群组结构
1、创建
在同一个群组中,每接入一个客户端,就对应地创建一个消费者实例
2、消息发送
消息队列会将消息自动投递到它的所有群组中
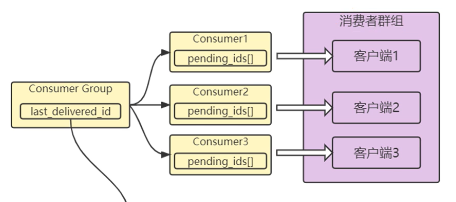
3、群组详情:
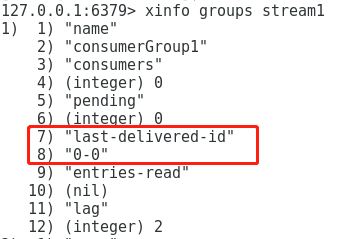
群组有一个属性:last_delivered_id,标识了当前群组从消息队列的哪一条消息开始消费
这个属性是保存在redis的数据结构中的
4、消费者(群组成员)详情
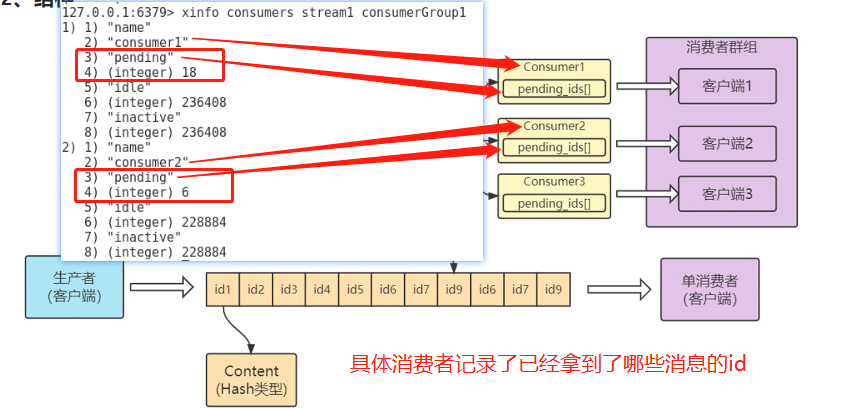
具体消费者有个pending数组,这个数组记录了该消费者消费过的消息id
一旦消费者挂掉,可以通过pending数组回溯
5、ack确认
确定好了消费者消费了哪些消息后,还需要进行确认
确认后,具体消费者的pending数组就不再记录该条消息
6、问题
stream消息数量过多会怎样?
一个消息队列最大消息数量 maxlen = 1024,增加一个时,会删除最早的一个;
忘记ack确认怎么办?
PEL:会到消费者的pending数组查找自动确认;
PEL如何避免消息丢失?
故障转移:XCLAIM
死信问题:
任何消费者都消费不了的消息;
需要手动消除:xdel命令;
Stream的高可用?
主从复制,哨兵集群;
异步执行,可能出现少量消息丢失;
分区Partition?
手动设计;
九、key 与 value 的数据结构组织
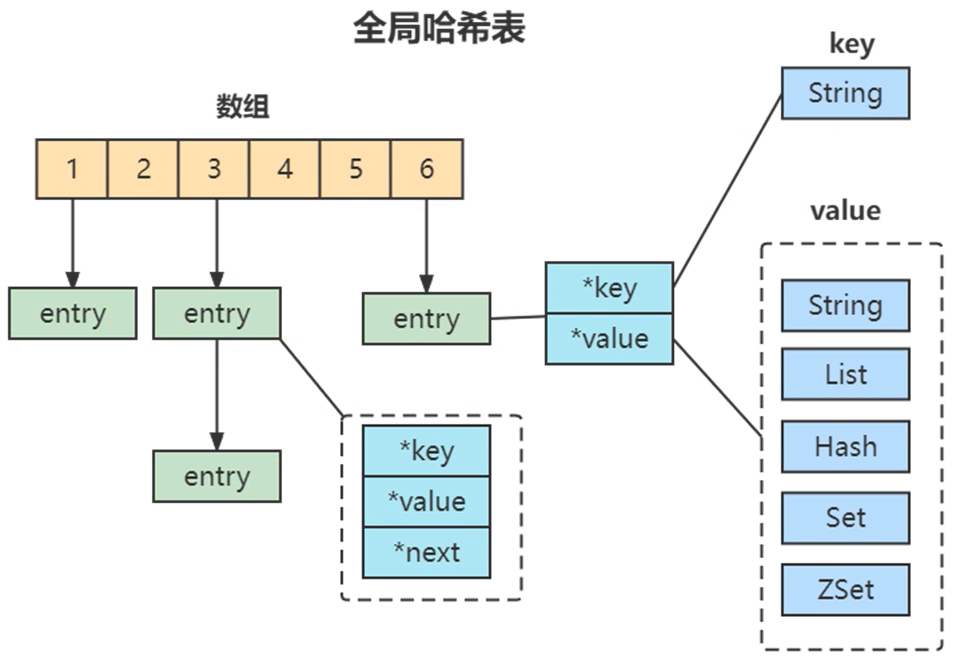
1、全局哈希表
数组 + 链表 :链表每个节点保存键值对
键:String
值:String,List,Hash,Set,ZSet
2、Hash冲突和HashMap一样
3、链表解决Hash冲突
4、ReHash问题
导致IO阻塞,卡顿
Hash表扩容
初始化第二张Hash表,扩容后从第一个hash表迁移到第二个hash表
先rehash完全部数据,再执行后面的请求;阻塞时间长
渐进式Rehash
每次来一个新请求的时候,会捎带着做一次rehash
分摊阻塞时间,让用户“无感”阻塞
5、结构图















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









