







 Redis 的持久化包括RDB快照和AOF日志,RDB在指定时间间隔生成数据快照,AOF记录每次写操作。事务支持简单原子性,通过multi-exec实现。发布订阅提供消息广播,Stream 结构支持消息队列,支持消费者组、持久化和消息确认。Redis 还提供了慢查询日志、Pipeline 提升性能、lua脚本增强功能。
Redis 的持久化包括RDB快照和AOF日志,RDB在指定时间间隔生成数据快照,AOF记录每次写操作。事务支持简单原子性,通过multi-exec实现。发布订阅提供消息广播,Stream 结构支持消息队列,支持消费者组、持久化和消息确认。Redis 还提供了慢查询日志、Pipeline 提升性能、lua脚本增强功能。
Redis高级特性
慢查询
许多存储系统(例如 MySQL)提供慢查询日志帮助开发和运维人员定位系统 存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时 间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的 详细信息)记录下来,Redis 也提供了类似的功能。
Redis 客户端执行一条命令分为如下 4 个部分:
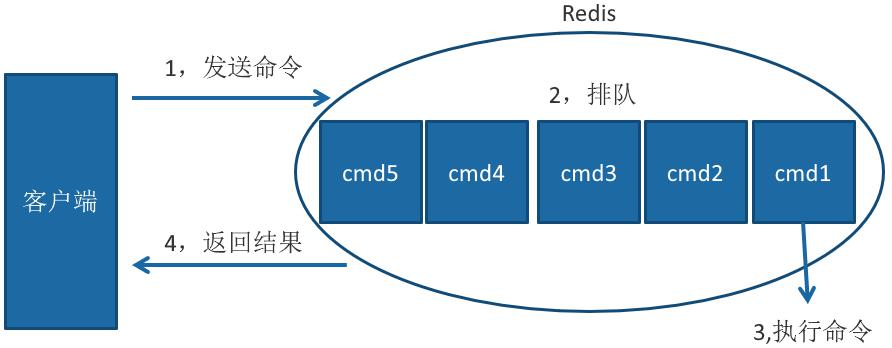
1)发送命令 2)命令排队 3)命令执行 4)返回结果
需要注意,慢查询只统计步骤 3)的时间,所以没有慢查询并不代表客户端 没有超时问题。
慢查询配置
对于任何慢查询功能,需要明确两件事:多慢算慢,也就是预设阀值怎么设 置?慢查询记录存放在哪?
Redis 提供了 slowlog-log-slower-than 和 slowlog-max-len 配置来解决这两个问 题。slowlog-log-slower-than 就是那个预设阀值,它的单位是微秒(1 秒= 1000 毫 秒= 1 000 000 微秒),默认值是 10 000,假如执行了一条“很慢”的命令(例如 keys *),如果它的执行时间超过了 10 000 微秒,也就是 10 毫秒,那么它将被记 录在慢查询日志中。
如果 slowlog-log-slower-than=0 表示会记录所有的命令, slowlog-log-slower-than<0 对于任何命令都不会进行记录。
slowlog-max-len 用来设置慢查询日志最多存储多少条,并没有说明存放在哪。 实际上 Redis 使用了一个列表来存储慢查询日志,slowlog-max-len 就是列表的最 大长度。当慢查询日志列表被填满后,新的慢查询命令则会继续入队,队列中的 第一条数据机会出列。
虽然慢查询日志是存放在 Redis 内存列表中的,但是 Redis 并没有告诉我们 这里列表是什么,而是通过一组命令来实现对慢查询日志的访问和管理。
慢查询操作命令
获取慢查询日志
slowlog get [n]
参数 n 可以指定查询条数。
获取慢查询日志列表当前的长度 slowlog len
慢查询日志重置 slowlog reset,实际是对列表做清理操作
慢查询建议
慢查询功能可以有效地帮助我们找到 Redis 可能存在的瓶颈,但在实际使用 过程中要注意以下几点:
slowlog-max-len 配置建议;建议调大慢查询列表,记录慢查询时 Redis 会对 长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔 除的可能,例如线上可设置为 1000 以上。
slowlog-log-slower-than 配置建议:默认值超过 10 毫秒判定为慢查询,需要根 据 Redis 并发量调整该值。由于 Redis 采用单线程响应命令,对于高流量的场景, 如果命令执行时间在 1 毫秒以上,那么 Redis 最多可支撑 OPS 不到 1000。因此对 于高 OPS 场景的 Redis 建议设置为 1 毫秒或者更低比如 100 微秒。
慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户 端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会 导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有 对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况 下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行 slow get 命令将慢查询日志持久化到其他存储中。
Pipeline
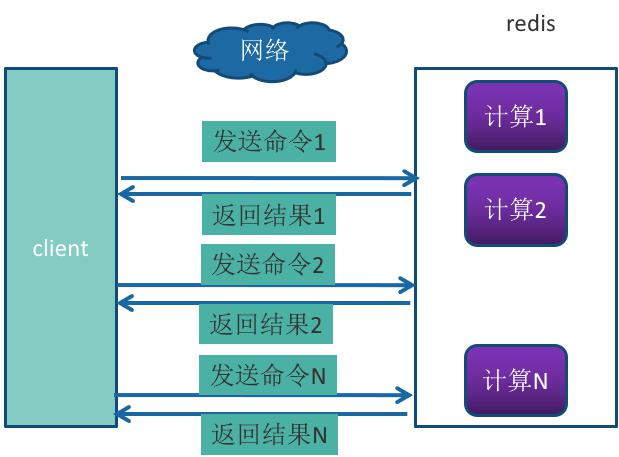
Redis 提供了批量操作命令(例如 mget、mset 等),有效地节约 RTT。但大部 分命令是不支持批量操作的,例如要执行 n 次 hgetall 命令,并没有 mhgetall 命 令存在,需要消耗 n 次 RTT。Redis 的客户端和服务端可能部署在不同的机器上。 例如客户端在本地,Redis 服务器在阿里云的广州,两地直线距离约为 800 公里, 那么 1 次 RTT 时间=800 x2/ ( 300000×2/3 ) =8 毫秒,(光在真空中传输速度为每秒 30 万公里,这里假设光纤为光速的 2/3 ),那么客户端在 1 秒内大约只能执行 125 次 左右的命令,这个和 Redis 的高并发高吞吐特性背道而驰。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis 命令进行组装, 通过一次 RTT 传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端, 没有使用 Pipeline 执行了 n 条命令,整个过程需要 n 次 RTT。
使用 Pipeline 执行了 n 次命令,整个过程需要 1 次 RTT。
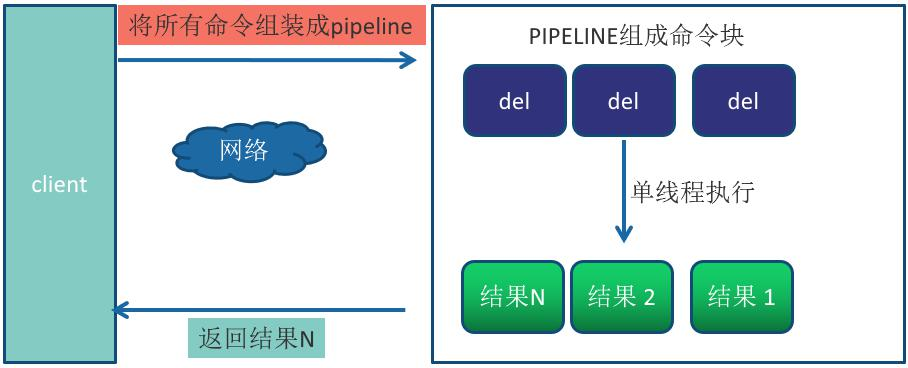
Pipeline 并不是什么新的技术或机制,很多技术上都使用过。而且 RTT 在不 同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢。 Redis 命令真正执行的时间通常在微秒级别,所以才会有 Redis 性能瓶颈是网络 这样的说法。
redis-cli 的–pipe 选项实际上就是使用 Pipeline 机制,但绝对部分情况下,我 们使用 Java 语言的 Redis 客户端中的 Pipeline 会更多一点。
代码示例
@Component
public class RedisPipeline {
@Autowired
private JedisPool jedisPool;
public List<Object> plGet(List<String> keys) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
Pipeline pipelined = jedis.pipelined();
for (String key : keys) {
pipelined.get(key);
}
return pipelined.syncAndReturnAll();
} catch (Exception e) {
throw new RuntimeException("执行Pipeline获取失败!", e);
} finally {
jedis.close();
}
}
public void plSet(List<String> keys, List<String> values) {
if (keys.size() != values.size()) {
throw new RuntimeException("key和value个数不匹配!");
}
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < keys.size(); i++) {
pipelined.set(keys.get(i), values.get(i));
}
pipelined.sync();
} catch (Exception e) {
throw new RuntimeException("执行Pipeline设值失败!", e);
} finally {
jedis.close();
}
}
}
事务
Redis 提供了简单的事务功能,将一组需要一起执行的命令放到 multi 和 exec 两个命令之间。multi(['mʌlti]) 命令代表事务开始,exec(美[ɪɡˈzek])命令代表事务结 束,如果要停止事务的执行,可以使用 discard 命令代替 exec 命令即可。
它们之间的命令是原子顺序执行的,例如下面操作实现了上述用户关注问题。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd u:a:follow ub
QUEUED
127.0.0.1:6379> sadd u:b:fans ua
QUEUED
127.0.0.1:6379>
可以看到 sadd 命令此时的返回结果是 QUEUED,代表命令并没有真正执行, 而是暂时保存在 Redis 中的一个缓存队列(所以 discard 也只是丢弃这个缓存队列 中的未执行命令,并不会回滚已经操作过的数据,这一点要和关系型数据库的 Rollback 操作区分开)。如果此时另一个客户端执行 sismember u:a:follow ub 返 回结果应该为 0。
127.0.0.1:6379> sismember u:a:follow ub
(integer) 0
只有当 exec 执行后,用户 A 关注用户 B 的行为才算完成,如下所示 exec 返 回的两个结果对应 sadd 命令。
127.0.0.1:6379> exec
1) (integer) 1
2) (integer) 1
另一个客户端:
127.0.0.1:6379> sismember u:a:follow ub
(integer) 1
如果事务中的命令出现错误,Redis 的处理机制也不尽相同。
1 命令错误
例如下面操作错将 set 写成了 sett,属于语法错误,会造成整个事务无法执 行,key 和 counter 的值未发生变化:
127.0.0.1:6379> sett txkey v
(error) ERR unknown command `sett`, with args beginning with: `txkey`, `v`,
127.0.0.1:6379> incr txcount
QUEUED
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> mget txkey txcount
1) (nil)
2) (nil)
127.0.0.1:6379>
127.0.0.1:6379> unwatch ##还需要执行unwatch
OK
2 运行时错误
例如用户 B 在添加粉丝列表时,误把 sadd 命令写成了 zadd 命令,这种就是 运行时命令,因为语法是正确的:
127.0.0.1:6379> sadd u:c:follow ub
QUEUED
127.0.0.1:6379> zadd u:b:fans 1 uc
QUEUED
127.0.0.1:6379> exec
127.0.0.1:6379> ismember u:c:follow
1) (integer) 1
可以看到 Redis 并不支持回滚功能,sadd u:c:follow ub 命令已经执行成功,开 发人员需要自己修复这类问题。
有些应用场景需要在事务之前,确保事务中的 key 没有被其他客户端修改过, 才执行事务,否则不执行(类似乐观锁)。Redis 提供了 watch 命令来解决这类问 题。
客户端 1:
127.0.0.1:6379> set testwatch redis
OK
127.0.0.1:6379> watch testwatch
OK
127.0.0.1:6379> mutil
127.0.0.1:6379> multi
OK
客户端 2:
127.0.0.1:6379> append testwatch java
(integer) 9
客户端 1 继续:
127.0.0.1:6379> append testwatch c++
QUEUED
127.0.0.1:6379>
127.0.0.1:6379> exec
(nil) ## 是nil
127.0.0.1:6379> get testwatch
"redisjava"
可以看到“客户端-1”在执行 multi 之前执行了 watch 命令,“客户端-2” 在“客户端-1”执行 exec 之前修改了 key 值,造成客户端-1 事务没有执行(exec 结果为 nil)。
Redis 客户端中的事务使用代码参见:
@Component
public class RedisTransaction {
public final static String RS_TRANS_NS = "rts:";
@Autowired
private JedisPool jedisPool;
public List<Object> transaction(String... watchKeys) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
if (watchKeys.length > 0) {
/*使用watch功能*/
String watchResult = jedis.watch(watchKeys);
if (!"OK".equals(watchResult)) {
throw new RuntimeException("执行watch失败:" + watchResult);
}
}
Transaction multi = jedis.multi();
multi.set(RS_TRANS_NS + "testa1", "a1");
multi.set(RS_TRANS_NS + "testa2", "a2");
multi.set(RS_TRANS_NS + "testa3", "a3");
List<Object> execResult = multi.exec();
if (execResult == null) {
throw new RuntimeException("事务无法执行,监视的key被修改:" + Arrays.toString(watchKeys));
}
System.out.println(execResult);
return execResult;
} catch (Exception e) {
throw new RuntimeException("执行Redis事务失败!", e);
} finally {
if (watchKeys.length > 0) {
if (jedis != null) {
jedis.unwatch();/*前面如果watch了,这里就要unwatch*/
}
}
if (jedis != null) {
jedis.close();
}
}
}
}
Pipeline 和事务的区别
简单来说,
1、pipeline 是客户端的行为,对于服务器来说是透明的,可以认为服务器无 法区分客户端发送来的查询命令是以普通命令的形式还是以 pipeline 的形式发送 到服务器的;
2、 而事务则是实现在服务器端的行为,用户执行 MULTI 命令时,服务器会将 对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行 的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行 EXEC 命令 为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次 执行。
3、应用 pipeline 可以提服务器的吞吐能力,并提高 Redis 处理查询请求的能 力。但是这里存在一个问题,当通过 pipeline 提交的查询命令数据较少,可以被 内核缓冲区所容纳时,Redis 可以保证这些命令执行的原子性。然而一旦数据量 过大,超过了内核缓冲区的接收大小,那么命令的执行将会被打断,原子性也就 无法得到保证。因此 pipeline 只是一种提升服务器吞吐能力的机制,如果想要命 令以事务的方式原子性的被执行,还是需要事务机制,或者使用更高级的脚本功 能以及模块功能。
4、可以将事务和 pipeline 结合起来使用,减少事务的命令在网络上的传输 时间,将多次网络 IO 缩减为一次网络 IO。
Redis 提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的 回滚特性,同时无法实现命令之间的逻辑关系计算,当然也体现了 Redis 的“keepit simple”的特性,下一小节介绍的 Lua 脚本同样可以实现事务的相关功能,但是 功能要强大很多。
Lua
Lua 语言是在 1993 年由巴西一个大学研究小组发明,其设计目标是作为嵌入 式程序移植到其他应用程序,它是由 C 语言实现的,虽然简单小巧但是功能强大, 所以许多应用都选用它作为脚本语言,尤其是在游戏领域,暴雪公司的“魔兽世 界”,“愤怒的小鸟”,Nginx 将 Lua 语言作为扩展。Redis 将 Lua 作为脚本语言 可帮助开发者定制自己的 Redis 命令。
Redis 2.6 版本通过内嵌支持 Lua 环境。也就是说一般的运用,是不需要单 独安装 Lua 的。
在 Redis 使用 LUA 脚本的好处包括:
1、减少网络开销,在 Lua 脚本中可以把多个命令放在同一个脚本中运行;
2、原子操作,Redis 会将整个脚本作为一个整体执行,中间不会被其他命令 插入。换句话说,编写脚本的过程中无需担心会出现竞态条件;
3、复用性,客户端发送的脚本会存储在 Redis 中,这意味着其他客户端可 以复用这一脚本来完成同样的逻辑
Lua 入门
安装 Lua
Lua 在 linux 中的安装
到官网下载 lua 的 tar.gz 的源码包
wget http://www.lua.org/ftp/lua-5.3.6.tar.gz
tar -zxvf lua-5.3.6.tar.gz
``wget http://www.lua.org/ftp/lua-5.3.6.tar.gz `
2、tar -zxvf lua-5.3.6.tar.gz
进入解压的目录:
cd lua-5.3.6/
make linux
make install (需要在 root 用户下)
如果报错,说找不到 readline/readline.h, 可以 root 用户下通过 yum 命令安 装
yum -y install libtermcap-devel ncurses-devel libevent-devel readline-devel
安装完以后再 make linux / make instal
最后,直接输入 lua 命令即可进入 lua 的控制台:
[root@localhost lua-5.3.6]# lua
Lua 5.3.6 Copyright (C) 1994-2020 Lua.org, PUC-Rio
>
Lua 基本语法
Lua 学习起来非常简单,当然再简单,它也是个独立的语言,自成体系,如果工作中有深研 Lua 的需要,可以参考《Lua 程序设计》,作者 罗伯拖·鲁萨利姆斯奇 (Roberto Ierusalimschy)。

现在我们需要:print(“Hello World!”)
> print("hello world!")
hello world!
或者编写一个 Lua 脚本(退出lua命令窗口)
[root@localhost mylua]# vim hello.lua
print("hello world!")
[root@localhost mylua]# lua hello.lua
hello world!
注释
两个减号是单行注释: –
多行注释
--[[
注释内容
注释内容
--]]
标示符
Lua 标示符用于定义一个变量,函数获取其他用户定义的项。标示符以一个 字母 A 到 Z 或 a 到 z 或下划线 _ 开头后加上 0 个或多个字母,下划线,数 字(0 到 9)。
最好不要使用下划线加大写字母的标示符,因为 Lua 的语言内部的一些保留 字也是这样的。
Lua 不允许使用特殊字符如 @, $, 和 % 来定义标示符。 Lua 是一个区分 大小写的编程语言。因此在 Lua 中 lua与 Lua是两个不同的标示符。
关键词
以下列出了 Lua 的保留关键词。保留关键字不能作为常量或变量或其他用 户自定义标示符:
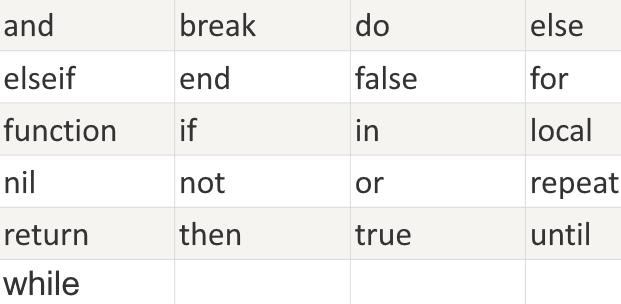
同时一般约定,以下划线开头连接一串大写字母的名字(比如 _VERSION) 被保留用于 Lua 内部全局变量。
全局变量
在默认情况下,变量总是认为是全局的。
全局变量不需要声明,给一个变量赋值后即创建了这个全局变量,访问一个 没有初始化的全局变量也不会出错,只不过得到的结果是:nil。
> print(b)
nil
如果你想删除一个全局变量,只需要将变量赋值为 nil。这样变量 b 就好像 从没被使用过一样。换句话说, 当且仅当一个变量不等于 nil 时,这个变量即存 在。
> b = 1234
> print(b)
1234
> b = nil
Lua 中的数据类型
Lua 是动态类型语言,变量不要类型定义,只需要为变量赋值。 值可以存储 在变量中,作为参数传递或结果返回。
Lua 中有 8 个基本类型分别为:nil、boolean、number、string、userdata、 function、thread 和 table。
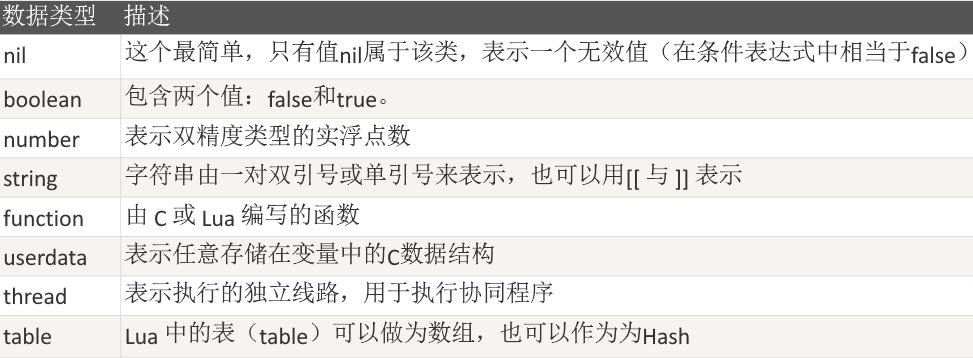
我们可以使用 type 函数测试给定变量或者值的类型。
> type([[lua]])
string
> type(2)
number
Lua 中的函数
在 Lua 中,函数以 function 开头,以 end 结尾,funcName 是函数名,中间 部分是函数体:
function funcName ()
--[[函数内容 --]]
end
比如定义一个字符串连接函数:
function contact(str1,str2)
return str1..str2
end
print(contact("hello"," Mark"))
Lua 变量
变量在使用前,需要在代码中进行声明,即创建该变量。
编译程序执行代码之前编译器需要知道如何给语句变量开辟存储区,用于存 储变量的值。
Lua 变量有:全局变量、局部变量。
Lua 中的变量全是全局变量,那怕是语句块或是函数里,除非用 local 显式 声明为局部变量。局部变量的作用域为从声明位置开始到所在语句块结束。
变量的默认值均为 nil。
local local_var = 6
Lua 中的控制语句
循环控制
Lua 支持 while 循环、for 循环、repeat…until 循环和循环嵌套,同时,Lua 提 供了 break 语句和 goto 语句。
for 循环
Lua 编程语言中 for 语句有两大类:数值 for 循环、泛型 for 循环。
数值 for 循环
Lua 编程语言中数值 for 循环语法格式:
for var=exp1,exp2,exp3 do
<执行体>
end
var 从 exp1 变化到 exp2,每次变化以 exp3 为步长递增 var,并执行一次 “执行体”。exp3 是可选的,如果不指定,默认为 1。
泛型 for 循环
泛型 for 循环通过一个迭代器函数来遍历所有值,类似 java 中的 foreach 语句。Lua 编程语言中泛型 for 循环语法格式:
–打印数组 a 的所有值
a = {"one", "two", "three"}
for i, v in ipairs(a) do
print(i, v)
end
i 是数组索引值,v 是对应索引的数组元素值。ipairs 是 Lua 提供的一个迭代 器函数,用来迭代数组。
tbl3={age=18,name='mark'} -- 这是数组,不是"对象"
for i, v in pairs(tbl3) do
print(i,v)
end
while 循环
while(condition)
do
statements
end
a=10
while(a<20)
do
print("a= ",a) a=a+1
end
if 条件控制
Lua 支持 if 语句、if…else 语句和 if 嵌套语句。
if(布尔表达式) then
--[ 在布尔表达式为 true 时执行的语句 --]
end
if(布尔表达式) then
--[ 布尔表达式为 true 时执行该语句块 --]
else
--[ 布尔表达式为 false 时执行该语句块 --]
end
Lua 运算符
算术运算符
+ 加法
- 减法
* 乘法
/ 除法
% 取余
^ 乘幂
- 负号
关系运算符
== 等于
~= 不等于
> 大于
< 小于
>= 大于等于
<= 小于等于
逻辑运算符
and
逻辑与操作符
or
逻辑或操作符
not
逻辑非操作符
说明:
lua拼接字符串时–, “a” +1会失败,因为会将a转化成数字进行运算
Lua 其他特性
Lua 支持模块与包,也就是封装库,支持元表(Metatable),支持协程(coroutine), 支持文件 IO 操作,支持错误处理,支持代码调试,支持 Lua 垃圾回收,支持面 向对象和数据库访问,更多详情请参考对应书籍。
Java 对 Lua 的支持
目前 Java 生态中,对 Lua 的支持是 LuaJ,是一个 Java 的 Lua 解释器,基 于 Lua 5.2.x 版本。
maven 坐标
<dependency>
<groupId>org.luaj</groupId>
<artifactId>luaj-jse</artifactId>
<version>3.0.1</version>
</dependency>
参考代码
Lua函数
public class LuaFunctions {
public static void main(String[] args) throws Exception {
LuaFunctions luaFunctions = new LuaFunctions();
String luaFileName = luaFunctions.getClass()
.getClassLoader()
.getResource("func.lua")
.toURI()
.getPath();
Globals globals = JsePlatform.standardGlobals();
LuaValue luaObj = globals.loadfile(luaFileName).call();
/*调用无参lua函数*/
LuaValue helloSimple = globals.get(LuaValue.valueOf("helloSimple"));
helloSimple.call();
//System.out.println("result---"+result);
/*调用有返回,无参数的lua函数*/
LuaValue hello = luaObj.get(LuaValue.valueOf("hello"));
String result2 = hello.call().toString();
System.out.println("result2---" + result2);
/*调用返回一个lua对象的lua函数*/
LuaValue getObj = luaObj.get(LuaValue.valueOf("getObj"));
LuaValue hTable = getObj.call();
//解析返回来的table,这里按照格式,一个个参数去取
String userId = hTable.get("userId").toString();
LuaTable servicesTable = (LuaTable) CoerceLuaToJava.coerce(hTable.get("services"), LuaTable.class);
List<String> servciesList = new ArrayList<>();
for (int i = 1; i <= servicesTable.length(); i++) {
int length = servicesTable.get(i).length();
StringBuilder service = new StringBuilder();
for (int j = 1; j <= length; j++) {
service.append("-" + servicesTable.get(i).get(j).toString());
}
servciesList.add(service.toString());
}
System.out.println("getObj-userId:" + userId);
System.out.println("getObj-servcies:" + servciesList);
/*传入一个java对象到lua函数*/
LuaValue readObj = luaObj.get(LuaValue.valueOf("readObj"));
LuaValue luaValue = new LuaTable();
luaValue.set("userId", "11111");
String userIdIn = readObj.invoke(luaValue).toString();
System.out.println("readObj-userIdIn:" + userIdIn);
}
}
测试代码
public class TestLuaJ {
public static void main(String[] args) {
String luaStr = "print 'hello,world!'";
Globals globals = JsePlatform.standardGlobals();
LuaValue chunk = globals.load(luaStr);
chunk.call();
}
}
Redis 中的 Lua
eval 命令
命令格式
EVAL script numkeys key [key ...] arg [arg ...]
命令说明
1)script 参数:是一段 Lua 脚本程序,它会被运行在 Redis 服务器上下 文中,这段脚本不必(也不应该)定义为一个 Lua 函数。
2)numkeys 参数:用于指定键名参数的个数。
3)key [key …] 参数: 从 EVAL 的第三个参数开始算起,使用了 numkeys 个键(key),表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以 在 Lua 中通过全局变量 KEYS 数组,用 1 为基址的形式访问(KEYS[1],KEYS[2]···)。
4)arg [arg …]参数:可以在 Lua 中通过全局变量 ARGV 数组访问,访问 的形式和 KEYS 变量类似(ARGV[1],ARGV[2]···)。
示例
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
在这个范例中 key [key …] 参数的作用不明显,其实它最大的作用是方便我 们在 Lua 脚本中调用 Redis 命令
Lua 脚本中调用 Redis 命令
主要记住 call() 命令即可:
eval “return redis.call(‘mset’,KEYS[1],ARGV[1],KEYS[2],ARGV[2])” 2 key1 key2 first second
eval "return redis.call('set',KEYS[1],ARGV[1])" 1 key1 newfirst
evalsha 命令
但是 eval 命令要求你在每次执行脚本的时候都发送一次脚本,所以 Redis 有 一个内部的缓存机制,因此它不会每次都重新编译脚本,不过在很多场合,付出 无谓的带宽来传送脚本主体并不是最佳选择。
为了减少带宽的消耗,Redis 提供了 evalsha 命令,它的作用和 EVAL 一样, 都用于对脚本求值,但它接受的第一个参数不是脚本,而是脚本的 SHA1 摘要。
这里就需要借助 script 命令。
script flush :清除所有脚本缓存。
script exists :根据给定的脚本校验,检查指定的脚本是否存在于脚本缓存。
script load :将一个脚本装入脚本缓存,返回 SHA1 摘要,但并不立即运行它。
script kill :杀死当前正在运行的脚本
这里的 SCRIPT LOAD 命令就可以用来生成脚本的 SHA1 摘要
script load “return redis.call(‘set’,KEYS[1],ARGV[1])”
redis-cli 执行脚本
可以使用 redis-cli 命令直接执行脚本,这里我们直接新建一个 lua 脚本文 件,用来获取刚刚存入 Redis 的 key1 的值,vim redis.lua,然后编写 Lua 命令:
test.lua
local value = redis.call('get','key1')
return value
然后执行
./redis-cli -p 6880 --eval …/scripts/test.lua
也可以
./redis-cli -p 6880 script load “$(cat …/scripts/test.lua)”
但是想要直接在 redis 的命令提示符里加载脚本文件是不行的
Java 客户端使用 Lua 脚本
基于redis的一个限流功能:
/*基于redis的一个限流功能*/
@Component
public class RedisLua {
public final static String RS_LUA_NS = "rlilf:";
/*第一次使用incr对KEY(某个IP作为KEY)加一,如果是第一次访问,
使用expire设置一个超时时间,这个超时时间作为Value第一个参数传入,
如果现在递增的数目大于输入的第二个Value参数,返回失败标记,否则成功。
redis的超时时间到了,这个Key消失,又可以访问
local num = redis.call('incr', KEYS[1])
if tonumber(num) == 1 then
redis.call('expire', KEYS[1], ARGV[1])
return 1
elseif tonumber(num) > tonumber(ARGV[2]) then
return 0
else
return 1
end
* */
public final static String LUA_SCRIPTS =
"local num = redis.call('incr', KEYS[1])\n" +
"if tonumber(num) == 1 then\n" +
"\tredis.call('expire', KEYS[1], ARGV[1])\n" +
"\treturn 1\n" +
"elseif tonumber(num) > tonumber(ARGV[2]) then\n" +
"\treturn 0\n" +
"else \n" +
"\treturn 1\n" +
"end";
@Autowired
private JedisPool jedisPool;
public String loadScripts(){
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
String sha =jedis.scriptLoad(LUA_SCRIPTS);
return sha;
} catch (Exception e) {
throw new RuntimeException("加载脚本失败!",e);
} finally {
jedis.close();
}
}
public String ipLimitFlow(String ip){
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
String result = jedis.evalsha("9ac7623ae2435baf9ebf3ef4d21cde13de60e85c",
Arrays.asList(RS_LUA_NS+ip),Arrays.asList("60","2")).toString();
return result;
} catch (Exception e) {
throw new RuntimeException("执行脚本失败!",e);
} finally {
jedis.close();
}
}
}
发布和订阅
Redis 提供了基于“发布/订阅”模式的消息机制,此种模式下,消息发布者 和订阅者不进行直接通信,发布者客户端向指定的频道( channel)发布消息,订阅 该频道的每个客户端都可以收到该消息。
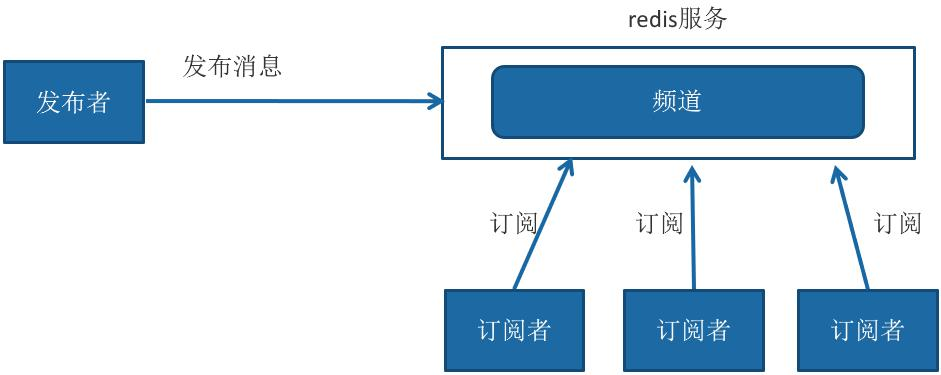
操作命令
Redis 主要提供了发布消息、订阅频道、取消订阅以及按照模式订阅和取消 订阅等命令。
发布消息
publish channel message
订阅消息
subscribe channel [channel …]
订阅者可以订阅一个或多个频道,如果此时另一个客户端发布一条消息,当前订阅者客户端会收到消息。
如果有多个客户端同时订阅了同一个频道,都会收到消息。
有关订阅命令有两点需要注意:
客户端在执行订阅命令之后进入了订阅状态,只能接收 subscribe、 psubscribe,unsubscribe、 punsubscribe 的四个命令。
取消订阅
unsubscribe [channel [channel …]]
客户端可以通过 unsubscribe 命令取消对指定频道的订阅,取消成功后,不 会再收到该频道的发布消息。
按照模式订阅和取消订阅
psubscribe pattern [pattern. …]
punsubscribe [pattern [pattern …]]
这个p不是publish,而是pattern
除了 subcribe 和 unsubscribe 命令,Redis 命令还支持 glob 风格的订阅命令 psubscribe 和取消订阅命令 punsubscribe,
查询订阅情况
查看活跃的频道
pubsub channels [pattern]
Pubsub 命令用于查看订阅与发布系统状态,包括活跃的频道(是指当前频 道至少有一个订阅者),其中[pattern]是可以指定具体的模式
查看频道订阅数
pubsub numsub channel
查看模式订阅数
pubsub numpat
使用场景和缺点
需要消息解耦又并不关注消息可靠性的地方都可以使用发布订阅模式。
PubSub 的生产者传递过来一个消息,Redis 会直接找到相应的消费者传递 过去。如果一个消费者都没有,那么消息直接丢弃。如果开始有三个消费者,一 个消费者突然挂掉了,生产者会继续发送消息,另外两个消费者可以持续收到消 息。但是挂掉的消费者重新连上的时候,这断连期间生产者发送的消息,对于这 个消费者来说就是彻底丢失了。
所以和很多专业的消息队列系统(例如 Kafka、RocketMQ)相比,Redis 的发 布订阅很粗糙,例如无法实现消息堆积和回溯。但胜在足够简单,如果当前场景 可以容忍的这些缺点,也不失为一个不错的选择。
正是因为 PubSub 有这些缺点,它的应用场景其实是非常狭窄的。从 Redis5.0 新增了 Stream 数据结构,这个功能给 Redis 带来了持久化消息队列
Redis Stream
Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的 支持多播的可持久化的消息队列,作者声明 Redis Stream 地借鉴了 Kafka 的设计。
Stream 总述
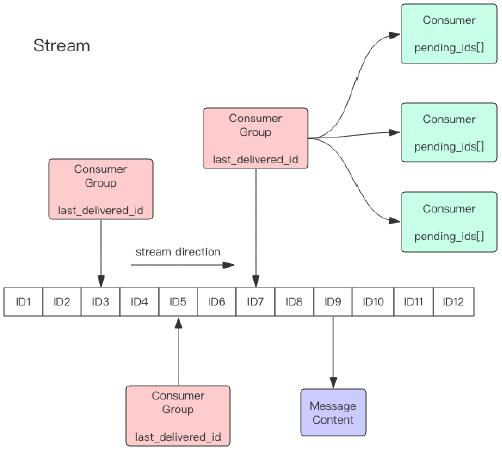
Redis Stream 的结构如上图所示**,每一个Stream都有一个消息链表,将所有加入的消息都串起来**,每个消息都有一个唯一的 ID 和对应的内容。消息是持久化的, Redis 重启后,内容还在。
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用xadd指令追加消息时自动创建。
每个 Stream 都可以挂多个消费组,每个消费组会有个游标last_delivered_id在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个 Stream 内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从 Stream 的某个消息 ID 开始消费,这个 ID 用来初始化last_delivered_id变量。
` 每个消费组 (Consumer Group) 的状态都是独立的,相互不受影响。也就是说同一份 Stream 内部的消息会被每个消费组都消费到。
同一个消费组 (Consumer Group) 可以挂接多个消费者 (Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者有一个组内唯一名称。
消费者 (Consumer) 内部会有个状态变量pending_ids,它记录了当前已经被客户端读取,但是还没有 ack的消息。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
消息 ID 的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第 5 条消息。消息 ID 可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的 ID 要大于前面的消息 ID。
消息内容就是键值对,形如 hash 结构的键值对,这没什么特别之处。
常用操作命令
生产端
xadd 追加消息
xdel 删除消息,这里的删除仅仅是设置了标志位,不会实际删除消息。
xrange 获取消息列表,会自动过滤已经删除的消息
xlen 消息长度
del 删除 Stream
xadd streamtest * name mark age 18
127.0.0.1:6379> xadd streamtest * name xx age 18
"1641020605232-0"
127.0.0.1:6379> xadd streamtest * name oo age 18
"1641020610921-0" # 第二次添加
* 号表示服务器自动生成 ID,后面顺序跟着一堆 key/value
1626705954593-0 则是生成的消息 ID,由两部分组成:时间戳-序号。时间戳时毫秒级单位,是生成消息的Redis服务器时间,它是个64位整型。序号是在这个毫秒时间点内的消息序号。它也是个64位整型。
为了保证消息是有序的,**因此Redis生成的ID是单调递增有序的。**由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
强烈建议使用Redis的方案生成消息ID,因为这种时间戳+序号的单调递增的ID方案,几乎可以满足你全部的需求。但ID是支持自定义的。
xrange streamtest - +
127.0.0.1:6379> xrange streamtest - +
其中-表示最小值 , + 表示最大值
或者我们可以指定消息 ID 的列表:
xrange streamtest - 1641020610921-0
127.0.0.1:6379> xrange streamtest - 1641020610921-0
127.0.0.1:6379> xrange streamtest 1641020605232-0 +
xdel streamtest 1641020610921-0
xlen streamtest
127.0.0.1:6379> xlen streamtest
(integer) 2
127.0.0.1:6379> xdel streamtest 1641020610921-0 # 删除单个id
(integer) 1
del streamtest 删除整个 Stream
127.0.0.1:6379> del streamtest
(integer) 1
消费端
单消费者
虽然Stream中有消费者组的概念,但是可以在不定义消费组的情况下进行 Stream 消息的独立消费,当 Stream 没有新消息时,甚至可以阻塞等待。Redis 设计了一个单独的消费指令xread,可以将 Stream 当成普通的消息队列 (list) 来使用。使用 xread 时,我们可以完全忽略消费组 (Consumer Group) 的存在,就好比 Stream 就是一个普通的列表 (list)。
xread count 1 streams stream2 0-0
表示从 Stream 头部读取1条消息,0-0指从头开始
xread count 2 streams stream2 1626710882927-0
也可以指定从streams的消息Id开始(不包括命令中的消息id)
xread count 1 streams stream2 $
$代表从尾部读取,上面的意思就是从尾部读取最新的一条消息,此时默认不返回任何消息
应该以阻塞的方式读取尾部最新的一条消息,直到新的消息的到来
xread block 0 count 1 streams stream2 $
block后面的数字代表阻塞时间,单位毫秒
一般来说客户端如果想要使用 xread 进行顺序消费,一定要记住当前消费到哪里了,也就是返回的消息 ID。下次继续调用 xread 时,将上次返回的最后一个消息 ID 作为参数传递进去,就可以继续消费后续的消息。
消费组
创建消费组
Stream 通过xgroup create指令创建消费组 (Consumer Group),需要传递起始消息 ID 参数用来初始化last_delivered_id变量。
xgroup create stream2 cg1 0-0
表示从头开始消费
xgroup create stream2 cg2 $
$ 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略
现在我们可以用xinfo命令来看看stream2的情况:
xinfo stream stream2
xinfo groups stream2
消息消费
有了消费组,自然还需要消费者,Stream 提供了 xreadgroup 指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息 ID。
它同 xread 一样,也可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的PEL(正在处理的消息) 结构里,客户端处理完毕后使用 xack 指令通知服务器,本条消息已经处理完毕,该消息 ID 就会从 PEL 中移除。
xreadgroup GROUP cg1 c1 count 1 streams stream2 >
> 号表示从当前消费组的 last_delivered_id 后面开始读,每当消费者读取一条消息,last_delivered_id 变量就会前进
然后设置阻塞等待
xreadgroup GROUP cg1 c1 block 0 count 1 streams stream2 >
如果同一个消费组有多个消费者,我们还可以通过 xinfo consumers 指令观察每个消费者的状态
xinfo consumers stream2 cg1
我们确认一条消息
xack stream2 cg1 1626751586744-0
# xack允许带多个消息id
基于pub/sub消息队列
/**
* 基于PUBSUB的消息中间件的实现
*/
@Component
public class PSVer extends JedisPubSub {
public final static String RS_PS_MQ_NS = "rpsm:";
@Autowired
private JedisPool jedisPool;
@Override
public void onMessage(String channel, String message) {
System.out.println("Accept " + channel + " message:" + message);
}
@Override
public void onSubscribe(String channel, int subscribedChannels) {
System.out.println("Subscribe " + channel + " count:" + subscribedChannels);
}
public void pub(String channel, String message) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.publish(RS_PS_MQ_NS + channel, message);
System.out.println("发布消息到" + RS_PS_MQ_NS + channel + " message=" + message);
} catch (Exception e) {
throw new RuntimeException("发布消息失败!");
}
}
public void sub(String... channels) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.subscribe(this, channels);
} catch (Exception e) {
throw new RuntimeException("订阅频道失败!");
}
}
}
测试用例
@SpringBootTest
public class TestPSVer {
@Autowired
private PSVer psVer;
@Test
void testSub(){
psVer.sub(PSVer.RS_PS_MQ_NS+"psmq", PSVer.RS_PS_MQ_NS+"psmq2");
}
@Test
void testPub(){
psVer.pub("psmq","msgtest");
psVer.pub("psmq2","msgtest2");
}
}
基于Stream消息队列
/**
* 实现消费组消费,不考虑单消费者模式
*/
@Component
public class StreamVer {
public final static String RS_STREAM_MQ_NS = "rsm:";
public final static int MQ_INFO_CONSUMER = 1;
public final static int MQ_INFO_GROUP = 2;
public final static int MQ_INFO_STREAM = 0;
@Autowired
private JedisPool jedisPool;
/**
* 发布消息到Stream
*/
public StreamEntryID produce(String key, Map<String, String> message) {
try (Jedis jedis = jedisPool.getResource()) {
StreamEntryID id = jedis.xadd(RS_STREAM_MQ_NS + key, StreamEntryID.NEW_ENTRY, message);
System.out.println("发布消息到" + RS_STREAM_MQ_NS + key + " 返回消息id=" + id.toString());
return id;
} catch (Exception e) {
throw new RuntimeException("发布消息失败!");
}
}
/**
* 创建消费群组,消费群组不可重复创建
*/
public void createCustomGroup(String key, String groupName, String lastDeliveredId) {
Jedis jedis = null;
try {
StreamEntryID id;
if (lastDeliveredId == null) {
lastDeliveredId = "0-0";
}
id = new StreamEntryID(lastDeliveredId);
jedis = jedisPool.getResource();
/*makeStream表示没有时是否自动创建stream,但是如果有,再自动创建会异常*/
jedis.xgroupCreate(RS_STREAM_MQ_NS + key, groupName, id, false);
System.out.println("创建消费群组成功:" + groupName);
} catch (Exception e) {
throw new RuntimeException("创建消费群组失败!", e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
/**
* 消息消费
*/
public List<Map.Entry<String, List<StreamEntry>>> consume(String key, String customerName, String groupName) {
try (Jedis jedis = jedisPool.getResource()) {
/*消息消费时的参数*/
XReadGroupParams xReadGroupParams = new XReadGroupParams().block(0).count(1);
Map<String, StreamEntryID> streams = new HashMap<>();
streams.put(RS_STREAM_MQ_NS + key, StreamEntryID.UNRECEIVED_ENTRY);
List<Map.Entry<String, List<StreamEntry>>> result
= jedis.xreadGroup(groupName, customerName, xReadGroupParams, streams);
System.out.println(groupName + "从" + RS_STREAM_MQ_NS + key + "接受消息, 返回消息:" + result);
return result;
} catch (Exception e) {
throw new RuntimeException("消息消费失败!", e);
}
}
/**
* 消息确认
*/
public void ackMsg(String key, String groupName, StreamEntryID msgId) {
if (msgId == null) {
throw new RuntimeException("msgId为空!");
}
try (Jedis jedis = jedisPool.getResource()) {
System.out.println(jedis.xack(key, groupName, msgId));
System.out.println(RS_STREAM_MQ_NS + key + ",消费群组" + groupName + " 消息已确认");
} catch (Exception e) {
throw new RuntimeException("消息确认失败!", e);
}
}
/*
检查消费者群组是否存在,辅助方法
* */
public boolean checkGroup(String key, String groupName) {
try (Jedis jedis = jedisPool.getResource()) {
List<StreamGroupInfo> xinfoGroupResult = jedis.xinfoGroup(RS_STREAM_MQ_NS + key);
for (StreamGroupInfo groupinfo : xinfoGroupResult) {
if (groupName.equals(groupinfo.getName())) {
return true;
}
}
return false;
} catch (Exception e) {
throw new RuntimeException("检查消费群组失败!", e);
}
}
/**
* 消息队列信息查看
*/
public void MqInfo(int type, String key, String groupName) {
try (Jedis jedis = jedisPool.getResource()) {
if (type == MQ_INFO_CONSUMER) {
List<StreamConsumersInfo> xinfoConsumersResult = jedis.xinfoConsumers(RS_STREAM_MQ_NS + key, groupName);
System.out.println(RS_STREAM_MQ_NS + key + " 消费者信息:" + xinfoConsumersResult);
for (StreamConsumersInfo consumersinfo : xinfoConsumersResult) {
System.out.println("-ConsumerInfo:" + consumersinfo.getConsumerInfo());
System.out.println("--Name:" + consumersinfo.getName());
System.out.println("--Pending:" + consumersinfo.getPending());
System.out.println("--Idle:" + consumersinfo.getIdle());
}
} else if (type == MQ_INFO_GROUP) {
List<StreamGroupInfo> xinfoGroupResult = jedis.xinfoGroup(RS_STREAM_MQ_NS + key);
System.out.println(RS_STREAM_MQ_NS + key + "消费者群组信息:" + xinfoGroupResult);
for (StreamGroupInfo groupinfo : xinfoGroupResult) {
System.out.println("-GroupInfo:" + groupinfo.getGroupInfo());
System.out.println("--Name:" + groupinfo.getName());
System.out.println("--Consumers:" + groupinfo.getConsumers());
System.out.println("--Pending:" + groupinfo.getPending());
System.out.println("--LastDeliveredId:" + groupinfo.getLastDeliveredId());
}
} else {
StreamInfo xinfoStreamResult = jedis.xinfoStream(RS_STREAM_MQ_NS + key);
System.out.println(RS_STREAM_MQ_NS + key + "队列信息:" + xinfoStreamResult);
System.out.println("-StreamInfo:" + xinfoStreamResult.getStreamInfo());
System.out.println("--Length:" + xinfoStreamResult.getLength());
System.out.println("--RadixTreeKeys:" + xinfoStreamResult.getRadixTreeKeys());
System.out.println("--RadixTreeNodes():" + xinfoStreamResult.getRadixTreeNodes());
System.out.println("--Groups:" + xinfoStreamResult.getGroups());
System.out.println("--LastGeneratedId:" + xinfoStreamResult.getLastGeneratedId());
System.out.println("--FirstEntry:" + xinfoStreamResult.getFirstEntry());
System.out.println("--LastEntry:" + xinfoStreamResult.getLastEntry());
}
} catch (Exception e) {
throw new RuntimeException("消息队列信息检索失败!", e);
}
}
}
测试用例
@SpringBootTest
public class TestStreamVer {
@Autowired
private StreamVer streamVer;
private final static String KEY_NAME = "testStream";
private final static String GROUP_NAME = "testgroup";
@Test
void testProduce(){
Map<String,String> message = new HashMap<>();
message.put("name","Mark");
message.put("age","18");
streamVer.produce(KEY_NAME,new HashMap<>(message));
streamVer.MqInfo(StreamVer.MQ_INFO_STREAM,KEY_NAME,null);
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,null);
}
@Test
void testConsumer(){
if (!streamVer.checkGroup(KEY_NAME,GROUP_NAME)){
streamVer.createCustomGroup(KEY_NAME,GROUP_NAME,null);
}
List<Map.Entry<String, List<StreamEntry>>> results = streamVer.consume(KEY_NAME,"testUser",GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_CONSUMER,KEY_NAME,GROUP_NAME);
for(Map.Entry<String, List<StreamEntry>> result:results ){
for(StreamEntry entry:result.getValue()){
streamVer.ackMsg(KEY_NAME,GROUP_NAME,entry.getID());
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_CONSUMER,KEY_NAME,GROUP_NAME);
}
}
}
@Test
void testAck(){
streamVer.ackMsg(KEY_NAME,GROUP_NAME,null);
streamVer.MqInfo(StreamVer.MQ_INFO_GROUP,KEY_NAME,GROUP_NAME);
streamVer.MqInfo(StreamVer.MQ_INFO_CONSUMER,KEY_NAME,GROUP_NAME);
}
}
几种消息队列实现的总结
基于List的 LPUSH+BRPOP 的实现
足够简单,消费消息延迟几乎为零,但是需要处理空闲连接的问题。
如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常,所以在编写客户端消费者的时候要小心,如果捕获到异常,还有重试。
其他缺点包括:
做消费者确认ACK麻烦,不能保证消费者消费消息后是否成功处理的问题(宕机或处理异常等),通常需要维护一个Pending列表,保证消息处理确认;不能做广播模式,如pub/sub,消息发布/订阅模型;不能重复消费,一旦消费就会被删除;不支持分组消费。
基于Sorted-Set的实现
多用来实现延迟队列,当然也可以实现有序的普通的消息队列,但是消费者无法阻塞的获取消息,只能轮询,不允许重复消息。
PUB/SUB,订阅/发布模式
优点:
典型的广播模式,一个消息可以发布到多个消费者;多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息;消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息。
缺点:
消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回;不能保证每个消费者接收的时间是一致的;若消费者客户端出现消息积压,到一定程度,**会被强制断开,导致消息意外丢失。**通常发生在消息的生产远大于消费速度时;可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务。
消息队列问题
从我们上面对Stream的使用表明,Stream已经具备了一个消息队列的基本要素,生产者API、消费者API,消息Broker,消息的确认机制等等,所以在使用消息中间件中产生的问题,这里一样也会遇到。
Stream 消息太多怎么办?
要是消息积累太多,Stream 的链表岂不是很长,内容会不会爆掉?xdel 指令又不会删除消息,它只是给消息做了个标志位。
Redis 自然考虑到了这一点,所以它提供了一个定长 Stream 功能。在 xadd 的指令提供一个定长长度 maxlen,就可以将老的消息干掉,确保最多不超过指定长度。
消息如果忘记 ACK 会怎样?
Stream 在每个消费者结构中保存了正在处理中的消息 ID 列表 PEL,如果消费者收到了消息处理完了但是没有回复 ack,就会导致 PEL 列表不断增长,如果有很多消费组的话,那么这个 PEL 占用的内存就会放大。所以消息要尽可能的快速消费并确认。
PEL 如何避免消息丢失?
在客户端消费者读取 Stream 消息时,**Redis 服务器将消息回复给客户端的过程中,客户端突然断开了连接,消息就丢失了。**但是 PEL 里已经保存了发出去的消息 ID。待客户端重新连上之后,可以再次收到 PEL 中的消息 ID 列表。不过此时 xreadgroup 的起始消息 ID 不能为参数>,而必须是任意有效的消息 ID,一般将参数设为 0-0,表示读取所有的 PEL 消息以及自last_delivered_id之后的新消息。
死信问题
如果某个消息,不能被消费者处理,也就是不能被XACK,**这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。**此时该消息的delivery counter(通过XPENDING可以查询到)就会累加,当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法,注意,这个命令并没有删除Pending中的消息,因此查看Pending,消息还会在,可以在执行执行XDEL之后,XACK这个消息标识其处理完毕。
Stream 的高可用
Stream 的高可用是建立主从复制基础上的,它和其它数据结构的复制机制没有区别,也就是说在 Sentinel 和 Cluster 集群环境下 Stream 是可以支持高可用的。不过鉴于 Redis 的指令复制是异步的,在 failover 发生时,Redis 可能会丢失极小部分数据,这点 Redis 的其它数据结构也是一样的。
分区 Partition
Redis 的服务器没有原生支持分区能力,如果想要使用分区,那就需要分配多个 Stream,然后在客户端使用一定的策略来生产消息到不同的 Stream。
Stream小结
Stream 的消费模型借鉴了 Kafka 的消费分组的概念,它弥补了 Redis Pub/Sub 不能持久化消息的缺陷。但是它又不同于 kafka,Kafka 的消息可以分 partition,而 Stream 不行。如果非要分 parition 的话,得在客户端做,提供不同的 Stream 名称,对消息进行 hash 取模来选择往哪个 Stream 里塞。
所以总的来说,如果在工作中已经使用了Redis,在业务量不是很大,而又需要消息中间件功能的情况下,可以考虑使用Redis的Stream功能。但是如果并发量很高,还是以专业的消息的中间件,比如RocketMQ、Kafka等来支持业务更好。
持久化
Redis虽然是个内存数据库,但是Redis支持RDB和AOF两种持久化机制,将数据写往磁盘,可以有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
RDB (Redis Database)
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发。
触发机制
手动触发分别对应save和 bgsave命令:
**save命令:**阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
**bgsave命令:**Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
显然bgsave命令是针对save阻塞问题做的优化。因此Redis内部所有的涉及RDB的操作都采用bgsave的方式。
除了执行命令手动触发之外,Redis内部还存在自动触发RDB 的持久化机制,
例如以下场景:
1) 使用save相关配置**,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。**
2)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
3) 执行debug reload命令重新加载Redis 时,也会自动触发save操作。
4)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
bgsave执行流程
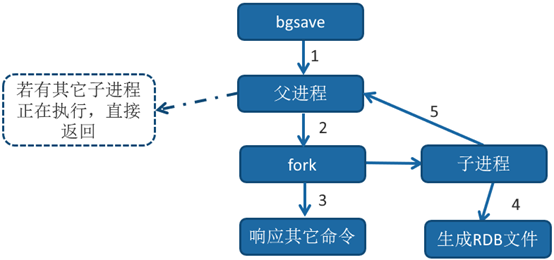
-
执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程存在,bgsave命令直接返回。
-
父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过info stats命令查看latest_fork_usec选项,可以获取最近一个 fork操作的耗时,单位为微秒。
- 父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
-
子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。
-
进程发送信号给父进程表示完成,父进程更新统计信息,具体见info Persistence下的rdb_*相关选项。
127.0.0.1:6379> info Persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1641024206
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:2478080
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
RDB文件
RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配置指定。可以通过执行config set dir {newDir}和config set dbfilename (newFileName}运行期动态执行,当下次运行时RDB文件会保存到新目录。
Redis默认采用LZF算法对生成的RDB文件做压缩处理,压缩后的文件远远小于内存大小,默认开启,可以通过参数config set rdbcompression { yes |no}动态修改。
虽然压缩RDB会消耗CPU,但可大幅降低文件的体积,**方便保存到硬盘或通过网维示络发送给从节点,**因此线上建议开启。
如果 Redis加载损坏的RDB文件时拒绝启动,并打印如下日志:
# Short read or 0OM loading DB. Unrecoverable error,aborting now.
这时可以使用Redis提供的redis-check-dump工具检测RDB文件并获取对应的错误报告。
RDB的优缺点
RDB的优点
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景。
比如每隔几小时执行bgsave备份,并把 RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
AOF (Append Only File)
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。理解掌握好AOF持久化机制对我们兼顾数据安全性和性能非常有帮助。
使用AOF
开启AOF功能需要设置配置:appendonly yes,默认不开启。AOF文件名通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同RDB持久化方式一致,通过dir配置指定。AOF的工作流程操作:命令写入( append)、文件同步( sync)、文件重写(rewrite)、重启加载( load)。
流程

- 所有的写入命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务器重启时,可以加载AOF文件进行数据恢复。了解AOF工作流程之后,下面针对每个步骤做详细介绍。
命令写入
AOF命令写入的内容直接是RESP文本协议格式。例如set hello world这条命令,在AOF缓冲区会追加如下文本:
* 3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n
1 ) AOF为什么直接采用文本协议格式?
**文本协议具有很好的兼容性。**开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免了二次处理开销。文本协议具有可读性,方便直接修改和处理。
2)AOF为什么把命令追加到aof_buf中? (所以并不能保证一定同步)
Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制。
# appendfsync always
appendfsync everysec
# appendfsync no
always
命令写入aof_buf后调用系统fsync操作同步到AOF文件,fsync完成后线程返回命令fsync同步文件。
everysec
写人aof_buf后调用系统write操作,write完成后线程返回。操作由专门线程(默认值)每秒调用一次fsync命令。
no
写入aof_buf后调用系统write操作,不对AOF文件做fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长30秒。
TIPS:系统调用write和fsync**说明
*write操作会触发延迟写(delayed write)机制。Linux在内核提供页缓冲区用来提高硬盘IO性能。write**操作在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制,例如:**缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,*缓冲区内数据将丢失。
*fsync针对单个文件操作(比如AOF文件),做强制硬盘同步,fsync**将阻塞直到写入硬盘完成后返回,*保证了数据持久化。
很明显,配置为always时,每次写入都要同步AOF 文件,在一般的SATA 硬盘上,Redis只能支持大约几百TPS写入,显然跟Redis高性能特性背道而驰,不建议配置。
配置为no,由于操作系统每次同步AOF 文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
配置为everysec,是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性。理论上只有在系统突然宕机的情况下丢失1秒的数据。(严格来说最多丢失1秒数据)
重写机制
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制压缩文件体积。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
重写后的AOF 文件为什么可以变小?有如下原因:
1)进程内已经超时的数据不再写入文件。
2)**旧的AOF文件含有无效命令,**如set a 111、set a 222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush listc可以转化为: lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。
AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF文件可以更快地被Redis加载。
AOF重写过程可以手动触发和自动触发:
手动触发:直接调用bgrewriteaof命令。
自动触发:根据auto-aof-rewrite-min-size和 auto-aof-rewrite-percentage参数确定自动触发时机。
auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认为64MB。
auto-aof-rewrite-percentage:代表当前AOF 文件空间(aof_currentsize)和上一次重写后AOF 文件空间(aof_base_size)的比值。
当触发AOF重写时,内部做了哪些事呢?
流程说明:
1)执行AOF重写请求。
如果当前进程正在执行AOF 重写,请求不执行并返回如下响应:
ERR Background append only file rewriting already in progress
如果当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再执行,返回如下响应:
Background append only file rewriting scheduled
2)父进程执行fork创建子进程,开销等同于bgsave过程。
3.1)主进程fork操作完成后,继续响应其他命令。所有修改命令依然写入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF 机制正确性。
3.2)由于fork操作运用写时复制技术,子进程只能共享fork操作时的内存数据。由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部分新数据,防止新AOF文件生成期间丢失这部分数据。
4)子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1)新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息,具体见info persistence下的aof_*相关统计。
5.2)父进程把AOF重写缓冲区的数据写入到新的AOF 文件。
5.3)使用新AOF 文件替换老文件,完成AOF重写。
重启加载
AOF和 RDB 文件都可以用于服务器重启时的数据恢复。redis重启时加载AOF与RDB的顺序是怎么样的呢?
1,当AOF和RDB文件同时存在时,优先加载AOF
2,若关闭了AOF,加载RDB文件
3,加载AOF/RDB成功,redis重启成功
4,AOF/RDB存在错误,启动失败打印错误信息
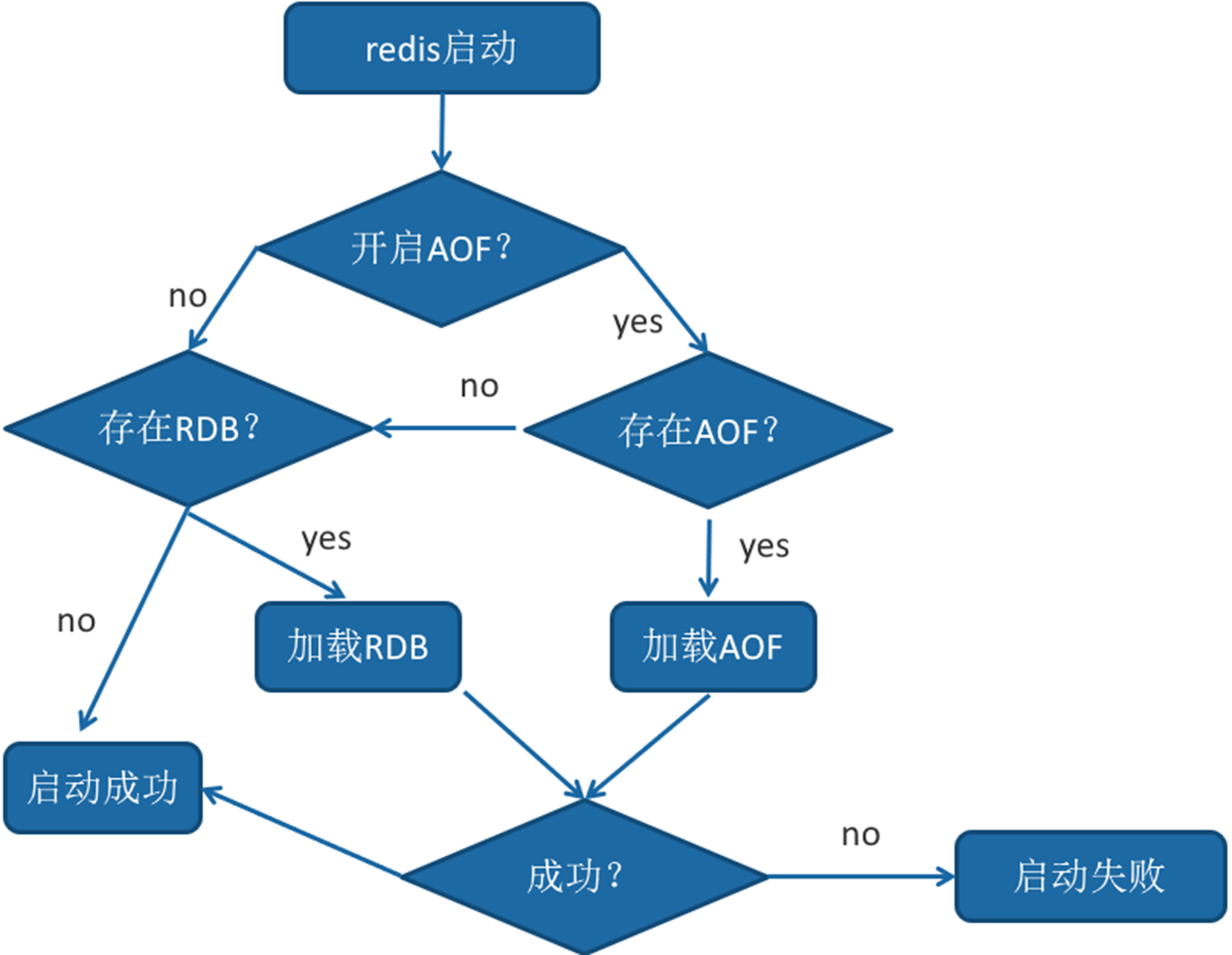
文件校验
加载损坏的AOF 文件时会拒绝启动,对于错误格式的AOF文件,先进行备份,然后采用redis-check-aof --fix命令进行修复,对比数据的差异,找出丢失的数据,有些可以人工修改补全。
AOF文件可能存在结尾不完整的情况,比如机器突然掉电导致AOF尾部文件命令写入不全。Redis为我们提供了aof-load-truncated配置来兼容这种情况,默认开启。加载AOF时当遇到此问题时会忽略并继续启动。
持久化问题
fork操作
当Redis做RDB或AOF重写时,**一个必不可少的操作就是执行fork操作创建子进程,对于大多数操作系统来说fork是个重量级操作。**虽然fork创建的子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表。例如对于10GB的Redis进程,需要复制大约20MB的内存页表,因此fork操作耗时跟进程总内存量息息相关,如果使用虚拟化技术,特别是Xen虚拟机,fork操作会更耗时。
fork耗时问题定位:对于高流量的Redis实例OPS可达5万以上,如果fork操作耗时在秒级别将拖慢Redis几万条命令执行,对线上应用延迟影响非常明显。正常情况下fork耗时应该是每GB消耗20毫秒左右。可以在info stats统计中查latest_fork_usec指标获取最近一次fork操作耗时,单位微秒。
名词解释: OPS: operation per second 每秒操作次数
如何改善fork操作的耗时:
1)优先使用物理机或者高效支持fork操作的虚拟化技术
2)控制Redis实例最大可用内存,fork耗时跟内存量成正比,线上建议每个Redis实例内存控制在10GB 以内。
- 降低fork操作的频率,如适度放宽AOF自动触发时机,避免不必要的全量复制等。
scan
Redis提供了两个命令遍历所有的键,分别是keys和scan。
keys
用来全量遍历键,用法很简单
keys pattern
遍历所有的键, pattern直接使用星号即可,pattern使用的是glob风格的通配符:
*代表匹配任意字符。
?代表匹配一个字符。
[]代表匹配部分字符,例如[1,3]代表匹配1,3,[1-10]代表匹配1到10的任意数字。
\x用来做转义,例如要匹配星号、问号需要进行转义。
比如匹配以u,v开头,紧跟:,然后任意字符串的所有键:
keys [u,v]😗
但是如果考虑到Redis 的单线程架构就不那么美妙了,如果Redis包含了大量的键,执行keys命令很可能会造成Redis 阻塞,所以一般建议不要在生产环境下使用keys命令。但有时候确实有遍历键的需求该怎么办,可以在以下三种情况使用:
在一个不对外提供服务的Redis 从节点上执行,这样不会阻塞到客户端的请求,但是会影响到主从复制,有关主从复制我们将在第6章进行详细介绍。
如果确认键值总数确实比较少,可以执行scan命令。使用scan命令渐进式的遍历所有键,可以有效防止阻塞。
scan
Redis 从2.8版本后,提供了一个新的命令scan,它能有效的解决keys命令存在的问题。和 keys命令执行时会遍历所有键不同,scan采用渐进式遍历的方式来解决 keys命令可能带来的阻塞问题,但是要真正实现keys的功能,需要执行多次scan。可以想象成只扫描一个字典中的一部分键,直到将字典中的所有键遍历完毕。scan的使用方法如下:
scan cursor [match pattern] [count number]
cursor是必需参数,实际上cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
Match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的模式匹配很像。
Count number是可选参数,它的作用是表明每次要遍历的键个数,默认值是10,此参数可以适当增大。
除了scan 以外,Redis提供了面向哈希类型、集合类型、有序集合的扫描遍历命令,解决诸如hgetall、smembers、zrange可能产生的阻塞问题,对应的命令分别是hscan、sscan、zscan,它们的用法和scan基本类似,请自行参考Redis官网。
渐进式遍历可以有效的解决keys命令可能产生的阻塞问题,但是scan并非完美无瑕,如果在scan 的过程中如果有键的变化(增加、删除、修改),那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说scan并不能保证完整的遍历出来所有的键,这些是我们在开发时需要考虑的。
键的迁移
有时候我们只想把部分数据由一个Redis迁移到另一个Redis(例如从生产环境迁移到测试环境),Redis发展历程中提供了move、dump +restore、migrate三组迁移键的方法,它们的实现方式以及使用的场景不太相同,下面分别介绍。
move
move key db
move命令用于在Redis内部进行数据迁移,Redis内部可以有多个数据库,这里只需要知道Redis内部可以有多个数据库,彼此在数据上是相互隔离的,move key db就是把指定的键从源数据库移动到目标数据库中,但多数据库功能不建议在生产环境使用,所以这个命令知道即可。
dump + restore
dump key
restore key ttl value
dump + restore 可以实现在不同的Redis实例之间进行数据迁移的功能,整个迁移的过程分为两步:
1)在源Redis 上,dump命令会将键值序列化,格式采用的是RDB格式。
2)在目标Redis 上,restore命令将上面序列化的值进行复原,其中ttl参数代表过期时间,如果ttl=0代表没有过期时间。
有关dump + restore有两点需要注意:第一,整个迁移过程并非原子性的,而是通过客户端分步完成的。第二,迁移过程是开启了两个客户端连接,所以dump的结果不是在源Redis和目标Redis 之间进行传输。
migrate
migrate host port key |"" destination-db timeout [copy] [replace] [keys key [key ...]]
migrate命令也是用于在Redis实例间进行数据迁移的,实际上migrate命令就是将dump,restore,del三个命令进行组合,从而简化了操作流程。migrate命令具有原子性,而且从Redis 3.0.6版本以后已经支持迁移多个键的功能,有效地提高了迁移效率,migrate在水平扩容中起到重要作用。
整个过程和dump + restore基本类似,但是有3点不太相同:
第一,整个过程是原子执行的,不需要在多个Redis实例上开启客户端的,只需要在源Redis上执行migrate命令即可。
第二,migrate命令的数据传输直接在源Redis和目标Redis上完成的。
第三,目标Redis完成restore后会发送OK给源Redis,源Redis接收后会根据migrate对应的选项来决定是否在源Redis上删除对应的键。
下面对migrate的参数进行逐个说明:
host:目标 Redis的IP地址。
port:目标 Redis的端口。
keyl “”:在Redis 3.0.6版本之前,migrate只支持迁移一个键,所以此处是要迁移的键,但 Redis 3.0.6版本之后支持迁移多个键,如果当前需要迁移多个键,此处为空字符串""。
destination-db :目标Redis的数据库索引,例如要迁移到0号数据库,这里就写0。
timeout:迁移的超时时间(单位为毫秒)。
[replace] :如果添加此选项,migrate不管目标Redis是否存在该键都会正常迁移进行数据覆盖。
[ keys key [ key …]]:迁移多个键,例如要迁移key1、key2、key3,此处填写“keys key1 key2 key3”。
现在我们假设有两个Redis,下源Redis使用6379端口,目标Redis使用6380端口,现要将源Redis 的键hello迁移到目标Redis中,会分为如下几种情况:
情况1:源Redis有键hello**,目标Redis****没有:**
migrate 127.0.0.1 6380 hello 0 1000OK
情况2:源Redis和目标Redis****都有键hello:
如果migrate命令没有加replace选项会收到错误提示,如果加了replace会返回OK表明迁移成功。
情况3:源Redis没有键hello**。如下所示,**此种情况会收到nokey 的提示
情况4:源Redis执行如下命令完成多个键的迁移
migrate 127.0.0.1 6380 "" 0 5000 keys key1 key2 key3
Redis-benchmark
redis-benchmark可以为Redis做基准性能测试,它提供了很多选项帮助开发和运维人员测试Redis的相关性能,下面分别介绍这些选项。
1.-c
-c (clients)选项代表客户端的并发数量(默认是50).
2.-n
-n (num)选项代表客户端请求总量(默认是100 000 )。
例如redis-benchmark -c 100 -n 20000代表100各个客户端同时请求Redis,一共执行20 000次。redis-benchmark 会对各类数据结构的命令进行测试,并给出性能指标:


















 2715
2715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











