







数据结构与算法之多路查找树
多路查找树是一类树形数据结构,它允许在一个节点上存储多个关键字。常见的多路查找树包括B树、B+树、B*树和Trie树等。
B树是一种平衡多路查找树,它的特点在于每个节点可以存储多个关键字和对应的数据,并且对于任意一个节点,它的所有儿子节点的关键字范围是连续的。B+树是在B树的基础上进行的优化,它的非叶子节点不存储数据,只存储关键字,而所有数据都存储在叶子节点上,从而使得B+树比B树更加高效。B*树则是在B+树的基础上进行的优化,它可以动态地调整节点大小,从而避免了B+树中频繁进行的节点分裂和合并操作。
Trie树是一种不同于B树、B+树等平衡多路查找树的数据结构,它以字符串作为关键字,每个节点代表一个字符串的前缀,而从根节点到叶子节点的路径恰好表示一个完整的字符串。Trie树有很多应用,比如字符串匹配、词频统计等。
多路查找树在实际应用中具有广泛的应用,比如数据库索引、文件系统、操作系统虚拟内存管理等。掌握这些数据结构和算法对于实现高效的数据存储和查找非常重要。

一、C 多路查找树 源码实现及详解
多路查找树(Multiway Search Tree)是一种比较常见的数据结构,也被称为Trie树或字典树。它的主要作用是用于存储字符串,并提供高效的字符串查找功能。本文将介绍C语言实现多路查找树的源码及详解。
1.1 多路查找树的概念
从根节点到叶子节点的路径分别为“a”、“an”、“and”、“ant”、“bye”、“cat”、“day”,每个路径都对应了一个字符串。多路查找树的优点是能够利用字符串的公共前缀来节省空间。比如上图中,字符串“a”与“an”的前缀“a”可以共用一个节点。
1.2 多路查找树的实现
下面是C语言实现多路查找树的源码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_CHILDREN 26
typedef struct _node {
char ch; // 节点存储的字符
struct _node *children[MAX_CHILDREN]; // 指向孩子节点的指针数组
} Node;
Node *create_node(char ch) {
Node *node = (Node *)malloc(sizeof(Node));
node->ch = ch;
memset(node->children, 0, sizeof(node->children));
return node;
}
void insert(Node **root, char *str) {
if (*root == NULL) {
*root = create_node(*str);
}
if (*str == '\0') {
return;
}
int idx = *str - 'a';
if ((*root)->children[idx] == NULL) {
(*root)->children[idx] = create_node(*str);
}
insert(&((*root)->children[idx]), str + 1);
}
int search(Node *root, char *str) {
if (root == NULL) {
return 0;
}
if (*str == '\0') {
return 1;
}
int idx = *str - 'a';
return search(root->children[idx], str + 1);
}
void destroy(Node *root) {
if (root == NULL) {
return;
}
for (int i = 0; i < MAX_CHILDREN; ++i) {
destroy(root->children[i]);
}
free(root);
}
int main() {
Node *root = NULL;
insert(&root, "a");
insert(&root, "an");
insert(&root, "and");
insert(&root, "ant");
insert(&root, "bye");
insert(&root, "cat");
insert(&root, "day");
printf("%d\n", search(root, "an"));
printf("%d\n", search(root, "hello"));
destroy(root);
return 0;
}
该源码实现了多路查找树的基本操作:插入、查找和销毁。insert函数用于向多路查找树中插入一个字符串,search函数用于查找一个字符串是否在多路查找树中出现,destroy函数用于销毁多路查找树。
1.3 多路查找树的详解
下面对多路查找树的实现进行详细解释。
- 结构体定义
typedef struct _node {
char ch; // 节点存储的字符
struct _node *children[MAX_CHILDREN]; // 指向孩子节点的指针数组
} Node;
定义了一个结构体Node,包含一个字符ch和一个指向孩子节点的指针数组children。
- create_node函数
Node *create_node(char ch) {
Node *node = (Node *)malloc(sizeof(Node));
node->ch = ch;
memset(node->children, 0, sizeof(node->children));
return node;
}
create_node函数用于创建一个新节点,它首先分配一个Node结构体的空间,然后将节点的字符ch设置为传入的参数ch,并将children数组清零,最后返回新节点的指针。
- insert函数
void insert(Node **root, char *str) {
if (*root == NULL) {
*root = create_node(*str);
}
if (*str == '\0') {
return;
}
int idx = *str - 'a';
if ((*root)->children[idx] == NULL) {
(*root)->children[idx] = create_node(*str);
}
insert(&((*root)->children[idx]), str + 1);
}
insert函数用于向多路查找树中插入一个字符串,它的参数包括根节点的指针和待插入的字符串。首先判断根节点是否为空,如果为空则新建一个节点作为根节点,并将节点的字符设置为字符串的第一个字符;否则,跳过这一步。然后判断字符串是否到达末尾,如果到达则返回;否则,根据当前字符计算出应插入的孩子节点的下标idx,如果该节点不存在,则新建一个节点作为孩子节点,并将节点的字符设置为当前字符;最后,将插入操作递归到孩子节点中。
- search函数
int search(Node *root, char *str) {
if (root == NULL) {
return 0;
}
if (*str == '\0') {
return 1;
}
int idx = *str - 'a';
return search(root->children[idx], str + 1);
}
search函数用于查找一个字符串是否在多路查找树中出现,它的参数包括根节点的指针和待查找的字符串。首先判断根节点是否为空,如果为空则返回0;然后判断字符串是否到达末尾,如果到达则返回1;否则,根据当前字符计算出应查找的孩子节点的下标idx,然后递归搜索孩子节点。
- destroy函数
void destroy(Node *root) {
if (root == NULL) {
return;
}
for (int i = 0; i < MAX_CHILDREN; ++i) {
destroy(root->children[i]);
}
free(root);
}
destroy函数用于销毁多路查找树,它的参数为根节点的指针。首先判断根节点是否为空,如果为空则返回;否则,遍历所有孩子节点,并递归销毁它们,最后释放当前节点的空间。
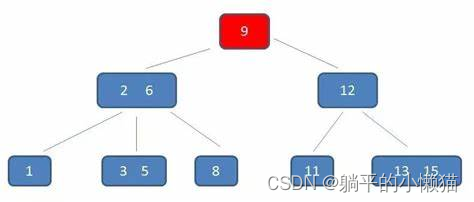
二、C++ 多路查找树 源码实现及详解
多路查找树(Multiway Trie)是一种将字符串序列映射成一个整数序列的数据结构,它可以用于字符串的排序、前缀匹配、最长公共前缀等问题。本文将介绍 C++ 实现多路查找树的源码及详解。
数据结构
多路查找树是一种基于树的数据结构,每个节点有多个子节点。节点的每个子节点对应着一个字符,而一个节点本身对应的字符则可以为空。因此,多路查找树可以处理任意长度的字符串。
下面是一个简单的多路查找树示例:
|h|----------------|e|
| |
|l|---|o| |l|---|e|
| |
|w|----------------|o|---|r|
|
|l|---|d|
这棵树表示的字符串集合为 {“hello”, “hell”, “he”, “how”, “world”}。其中,每个节点的字符都表示对应子树中的所有字符串的公共前缀。例如,根节点表示的字符串的前缀为空,第一层节点表示的字符串的前缀为 “h”,第二层节点表示的字符串的前缀为 “he” 或 “ho”,以此类推。
源码实现
下面是 C++ 实现多路查找树的源码:
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
class TrieNode {
public:
char ch;
unordered_map<char, TrieNode*> children;
bool is_end_of_word;
TrieNode(char ch = '\0') : ch(ch), is_end_of_word(false) {}
};
class Trie {
public:
void insert(string word) {
TrieNode* node = root;
for (char c : word) {
if (!node->children[c]) {
node->children[c] = new TrieNode(c);
}
node = node->children[c];
}
node->is_end_of_word = true;
}
bool search(string word) {
TrieNode* node = root;
for (char c : word) {
if (!node->children[c]) {
return false;
}
node = node->children[c];
}
return node->is_end_of_word;
}
bool startsWith(string prefix) {
TrieNode* node = root;
for (char c : prefix) {
if (!node->children[c]) {
return false;
}
node = node->children[c];
}
return true;
}
private:
TrieNode* root = new TrieNode();
};
int main() {
vector<string> words = {"hello", "hell", "he", "how", "world"};
Trie trie;
for (string word : words) {
trie.insert(word);
}
cout << trie.search("hello") << endl; // Output: true
cout << trie.search("helloworld") << endl; // Output: false
cout << trie.startsWith("he") << endl; // Output: true
cout << trie.startsWith("wor") << endl; // Output: false
return 0;
}
在上述实现中,我们使用了两个类来表示多路查找树:
TrieNode:表示一个节点。Trie:表示整个多路查找树。
在 TrieNode 类中,我们定义了以下成员变量:
ch:表示该节点对应的字符。children:表示该节点的子节点,是一个unordered_map,其键为字符,值为指向对应子节点的指针。is_end_of_word:表示该节点是否为某个字符串的结尾。
在 Trie 类中,我们定义了以下方法:
insert:将一个字符串插入到多路查找树中。search:在多路查找树中查找一个字符串是否存在。startsWith:在多路查找树中查找一个字符串是否为某个字符串的前缀。
在 insert 方法中,我们从根节点开始遍历字符串中的每个字符。如果当前节点的子节点中不存在该字符对应的子节点,则创建一个新的子节点;否则,直接进入该子节点。最后,将最后一个节点标记为某个字符串的结尾。
在 search 方法中,我们从根节点开始遍历要查找的字符串中的每个字符。如果当前节点的子节点中不存在该字符对应的子节点,则说明该字符串不存在于多路查找树中,直接返回 false。否则,继续遍历下一个字符。最后,如果能够遍历到字符串的末尾,并且最后一个节点被标记为某个字符串的结尾,则说明该字符串存在于多路查找树中,返回 true。
在 startsWith 方法中,我们与 search 方法的实现类似,只是当遍历结束后,不需要判断最后一个节点是否被标记为某个字符串的结尾,直接返回 true 即可。
三、java 多路查找树 源码实现及详解
多路查找树也称为Trie树,是一种字典树的数据结构,用于快速检索字符串。Trie树的根节点不存储字符,每个节点都代表一个字符串的字符,每个节点的子节点代表其后续的字符。
下面是Java实现多路查找树的源码:
public class Trie {
private TrieNode root;
public Trie() {
this.root = new TrieNode();
}
public void insert(String word) {
TrieNode current = root;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
TrieNode node = current.getChildren().get(ch);
if (node == null) {
node = new TrieNode();
current.getChildren().put(ch, node);
}
current = node;
}
current.setEndOfWord(true);
}
public boolean search(String word) {
TrieNode current = root;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
TrieNode node = current.getChildren().get(ch);
if (node == null) {
return false;
}
current = node;
}
return current.isEndOfWord();
}
public boolean startsWith(String prefix) {
TrieNode current = root;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
TrieNode node = current.getChildren().get(ch);
if (node == null) {
return false;
}
current = node;
}
return true;
}
}
上面的代码中,Trie类表示Trie树,构造函数初始化根节点,insert方法插入一个单词,search方法查找一个单词,startsWith方法查找以给定前缀开头的单词。
TrieNode类表示Trie节点,它有两个属性,一个是子节点,存储其后续的字符和节点,另一个是一个标志,表示是否为单词的结尾。下面是TrieNode的实现代码:
public class TrieNode {
private Map<Character, TrieNode> children;
private boolean endOfWord;
public TrieNode() {
this.children = new HashMap<>();
this.endOfWord = false;
}
public Map<Character, TrieNode> getChildren() {
return children;
}
public void setChildren(Map<Character, TrieNode> children) {
this.children = children;
}
public boolean isEndOfWord() {
return endOfWord;
}
public void setEndOfWord(boolean endOfWord) {
this.endOfWord = endOfWord;
}
}
上面的代码中,children是一个HashMap,表示存储子节点,key是字符,value是TrieNode;endOfWord表示该字符是否为单词的最后一个字符。
Trie树的时间复杂度为O(n),其中n是单词的长度。Trie树通常用于字符串的搜索和匹配,搜索引擎、编译器、拼写检查器等都是基于Trie树实现的。















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









