







Spark 由 Scala 语言开发,所以同样可以在本地环境学习 Spark,搭建 Spark 环境,可参考:Spark 初识+环境搭建
学习 Spark 之前,还是要完成 Scala 的环境搭建,可参考:Scala 初识+环境搭建
本文用到的部分算子(方法)可在 Scala 常用算子 中找到使用方法。
版本说明:
JDK:1.8
Maven:3.8.2
Scala:2.12.15
Spark:3.1.2
创建Maven项目
搭建 Maven 环境,可参考:无!(🙈 忘了写了,自行搜索吧 )
1️⃣ Step1:添加依赖(使用对应自己的版本)
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
🌈 Maven依赖可在 Maven 中搜索 spark core 找到对应自己版本!
2️⃣ Step2:为本项目添加 Scala SDK 全局库
可参考:Scala 初识+环境搭建
3️⃣ Step3:瞄眼目录结构,本文用到的是WorkCount(另一个用于集群使用,可见: )
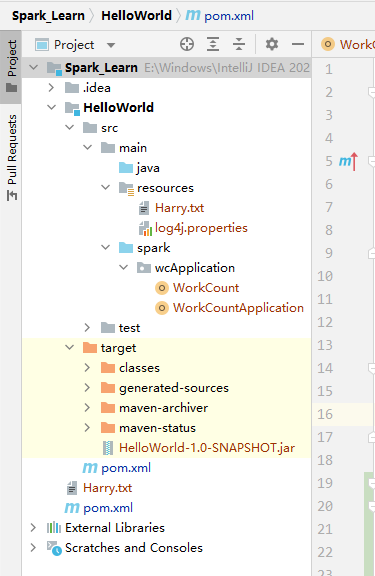
WordCount
🌈 RDD 为弹性分布式数据集,下面暂且称为‘集合’
1. 操作步骤
1️⃣ Step1:创建 Spark 的上下文对象,SparkContext 对象相当于 Spark Core 的程序入口。
// 创建 Spark 的上下文对象,打开 Spark 连接
val sc: SparkContext = new SparkContext()
2️⃣ Step2:按照指定的路径,一行一行读取数据,放在 RDD 类型的集合对象 linesRdd 当中
// 读取文件数据
val linesRdd: RDD[String] = sc.textFile(path)
3️⃣ Step3:将 linesRdd 中的每行数据进行分词操作,利用扁平化的map根据空字符切割;返回新的 RDD 集合
// 将文件中的每行数据进行分词
val wordsRdd: RDD[String] = linesRdd.flatMap(_.split("\\s+"))
4️⃣ Step4:格式化文本内容,将单词先转小写,再将其中的特殊字符替换为空白字符;返回新的 RDD 集合
// 格式化文本内容
val wordRdd1: RDD[String] = wordsRdd.map(_.toLowerCase.replaceAll("\\W", ""))
5️⃣ Step5:将每个单词映射为二元组形式,原单词当作键,以1作为值;返回新的 RDD 集合,泛型为二元组(Tuple2)
// 转换数据结构
val wordRdd2: RDD[(String, Int)] = wordsRdd.map((_, 1))
6️⃣ Step6:根据二元组的key(第一个参数)进行聚合,每次取到相同key的value,进行+操作,最终按照二元组的 value(第二个参数)进行排序(false代表降序,为true时表示升序);返回新的 RDD 集合,泛型为二元组
// 将单词进行聚合
val wordCountRdd: RDD[(String, Int)] = wordRdd2.reduceByKey(_ + _).sortBy(_._2, false)
7️⃣ Step7:当最终的结果收集并输出
// 将聚合的结果采集到内存中,打印输出
wordCountRdd.collect().foreach(println)
2. 测试并修改
测试时为了看到输出日志,可在项目的
resources下添加log4j.properties配置文件;log4j.rootLogger = error,stdout log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
2.1 配置运行模式
具体的操作步骤如上,试运行,看输出结果:
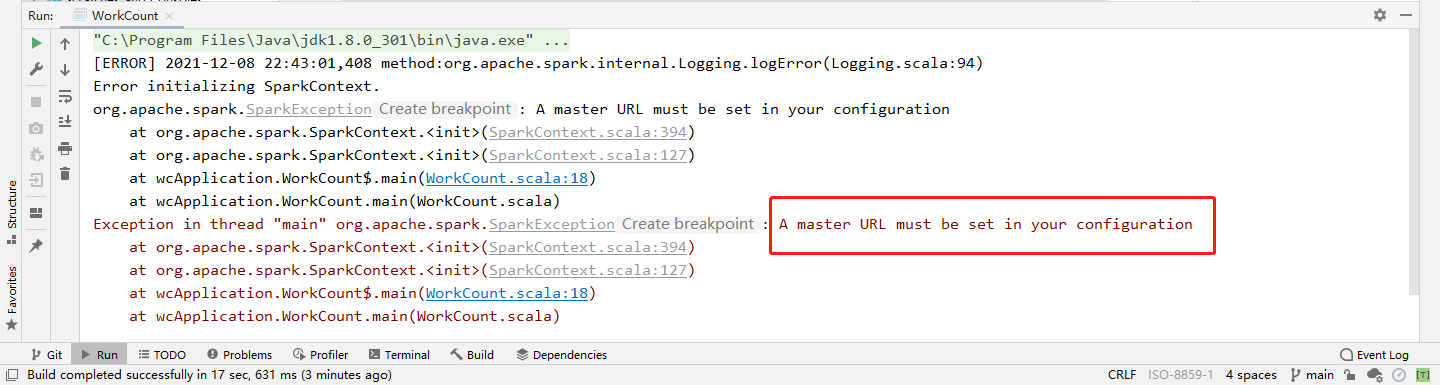
报错为:A master URL must be set in your configuration
原因:运行 Spark 程序,需要设置主节点的 URL,及需要指定运行的位置
处理方法:
- 本地时:将模式配置为
local[n],n 表示配置的 CPU 核心数,*可表示为全部使用 - 集群时:将模式配置为主节点的 URL,比如
spark://node1:7077
修改项目:添加如下配置,并将配置对象(SparkConf)当作 SparkContext 构造时的参数。
val SparkConf = new SparkConf()
.setMaster("local[2]")
val sc: SparkContext = new SparkContext(SparkConf)
2.2 配置应用名称
再次运行!继续看输出:
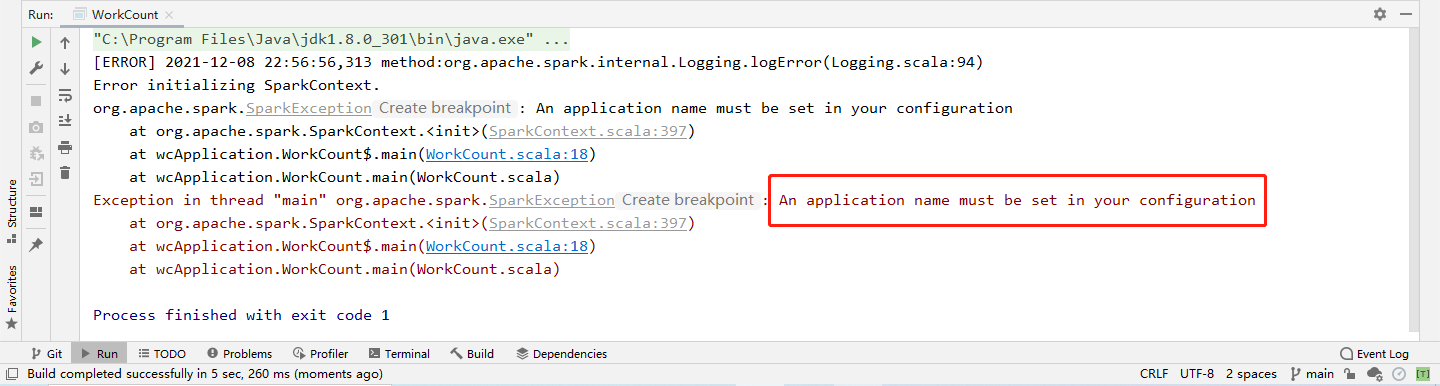
报错为:An application name must be set in your configuration
原因:运行 Spark 程序,需要指定程序名称
处理方法:在配置对象中添加配置程序名称
修改项目:在上一步基础上,添加如下配置,并将配置对象(SparkConf)当作 SparkContext 构造时的参数。
val SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("")
val sc: SparkContext = new SparkContext(SparkConf)
3. 运行程序
查看输出:
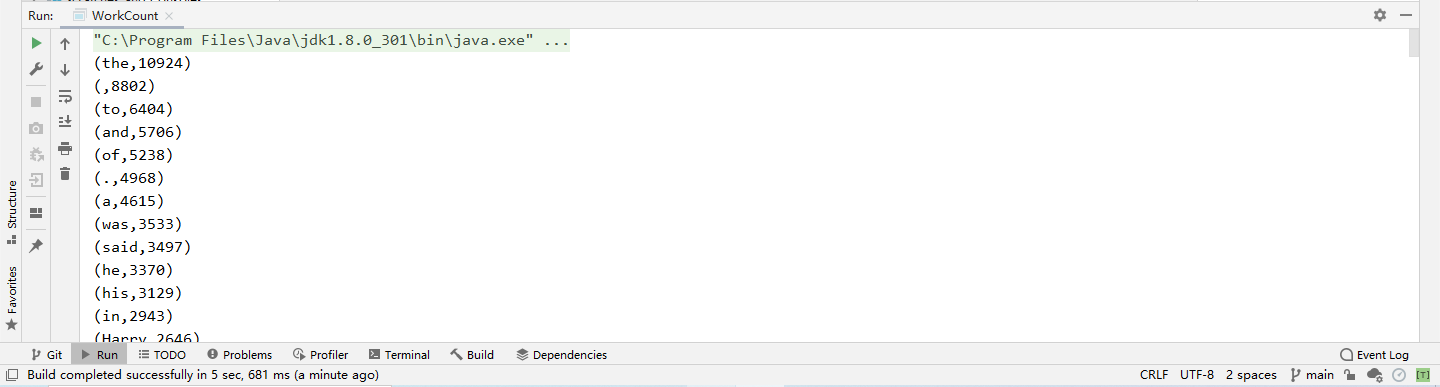
完工!
4. 完整代码
object WorkCount {
val path = "E:\\Windows\\IntelliJ IDEA 2021.2.2\\Project\\Hadoop\\Spark\\Spark_Learn\\HelloWorld\\src\\main\\resources\\Harry.txt"
def main(args: Array[String]): Unit = {
// 创建 Spark 运行配置文件
val SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("WorkCount")
// 创建 Spark 的上下文对象,打开 Spark 连接
val sc: SparkContext = new SparkContext(SparkConf)
// 读取文件数据
val linesRdd: RDD[String] = sc.textFile(path)
// 将文件中的每行数据进行分词
val wordsRdd: RDD[String] = linesRdd.flatMap(_.split("\\s+"))
// 格式化文本内容
val wordRdd1: RDD[String] = wordsRdd.map(_.toLowerCase.replaceAll("\\W", ""))
// 转换数据结构
val wordRdd2: RDD[(String, Int)] = wordsRdd.map((_, 1))
// 将单词进行聚合
val wordCountRdd: RDD[(String, Int)] = wordRdd2.reduceByKey(_ + _).sortBy(_._2, false)
// 将聚合的结果采集到内存中,打印输出
wordCountRdd.collect().foreach(println)
// 可以将结果存储到文件
// wordCountRdd.saveAsTextFile("wordCountRES")
// 关闭 Spark 连接,可省略
// sc.stop()
}
}
















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











