







1. Spark 初识
1.1 Spark 是什么
Apache Spark 是基于内存的快速、通用、可扩展的大数据统一分析引擎。
1.2 Spark 核心模块
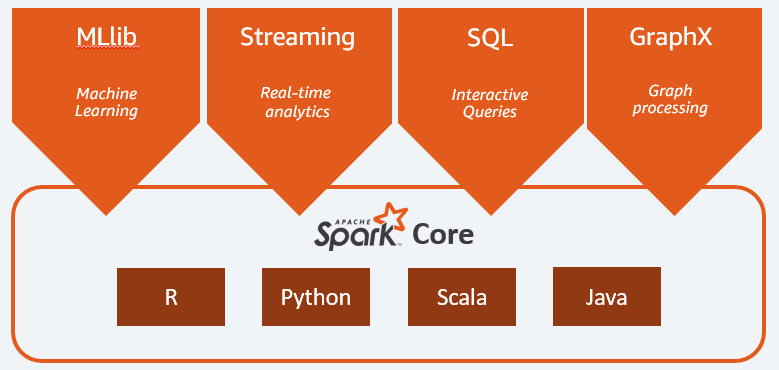
Spark Core:
Spark Core 提供了 Spark 的核心功能。它要负责任务调度、内存管理、故障恢复、计划安排、分配与监控作业,以及和存储系统进行交互。可以通过为 Java、Scala、Python 或 R 构建的应用程序编程接口 (API) 使用 Spark Core。在此之上扩展的功能包括 Spark MLlib、Spark Streaming、Spark SQL、Spark Graph X。Spark Core 中包含了对弹性分布式数据集(RDD,resilient distribute dataset)的API定义。
Spark SQL:
Spark SQL 提供低延迟交互式查询的分布式查询引擎,其速度最高可比 MapReduce 快 100 倍。我们可以使用 SQL、Hive等查询语言来查询数据,Spark SQL 支持多种数据源,比如 Hive 表、Parquent、JSON 等。
Spark Streaming:
Spark Streaming 是利用 Spark Core 的对实时数据进行流式计算的组件,提供了操作数据流的API,并且与 ADD API 高度对应。
Spark GraphX:
Spark GraphX 是构建在 Spark 之上的分布式图形处理框架。
Spark MLlib:
Spark 包含 MLlib,提供了常见的机器学习程序库,包括分类、回归、聚类、协同过滤,还提供模型评估、数据导入等额外的功能。
集群管理器:
Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算,为了实现这样地功能,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos 以及 Spark 自带地一个建议调度器(独立调度器)。
1.3 Spark 特点
Simple(易用):
Spark 支持 Java、Python 及 Scala 的 API,提供了近百种高级算子,是用户可以快速构建不同的应用。Spark 支持交互式的 Python 和 Scala 的 shell,可以非常方便的在这些 shell 中使用 Spark 集群来验证解决问题的分发。
Fast(快速):
与 Hadoop 的 MauReduce 相比,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。Spark 实现了高效的 DAG(driected acyclic graph)执行引擎,可以通过基于内存处理来高校处理数据流,计算中间结果存在于内存中。
Scalable(可扩展):
Spark 可以非常方便地于其他地开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Unified(通用):
Spark 提供了统一的解决方案,Spark 可以使用批处理,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。不同类型的处理都可以在同一个应用中无缝对接。
1.4 Spark 优势
1、Spark 和 Hadoop 的根本差异是多个作业之间的数据通信问题:Spark 多个作业之间数据通信基于内存,Hadoop 是基于磁盘。
2、Spark Task 的启动时间快,Spark 次啊用fork线程方式,Hadoop 采用创建新的进程方式。
3、Spark 只在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间数据交互都要依赖于磁盘交互。
4、Spark 的缓存机制比 HDFS 的缓存机制高校。
2. 环境搭建
版本说明:
Linux: CentOS-7
Hadoop: Hadoop-2.7.7
JDK: jdk1.8
1️⃣ Step1:下载压缩包
官网下载地址:https://spark.apache.org/downloads.html
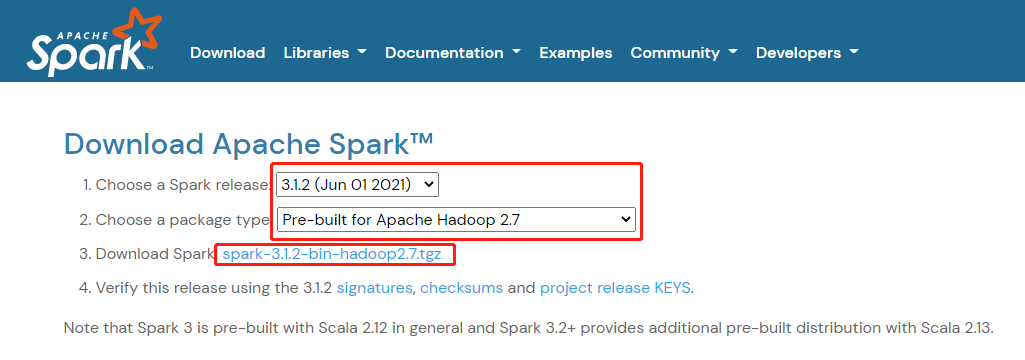
2️⃣ Step2:上传压缩包至服务器,并解压。
tar -zxvf xxxx
3️⃣ Step3:配置 spark-envs.sh 配置文件。
1、进入到 Spark 解压后的目录内,进入到 conf 目录中。
2、将 spark-env.sh.template 复制一份并更名为 spark-env.sh
cp spark-env.sh.template spark-env.sh
3、进入 spark-env.sh 文件中,键入 i 到插入模式,进行配置
vim spark-env.sh
# 配置hadoop集群的配置文件目录,目的是让Spark可以读取到HDFS数据
HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
# 配置Spark集群主节点的主机名和端口
SPARK_MASTER_HOST=node1
# Spark任务提交时的服务端口
SPARK_MASTER_PORT=7077
# SparkMaster WebUI 端口
SPARK_MASTER_WEBUI_PORT=8080
# 配置Java home
JAVA_HOME=/opt/jdk1.8
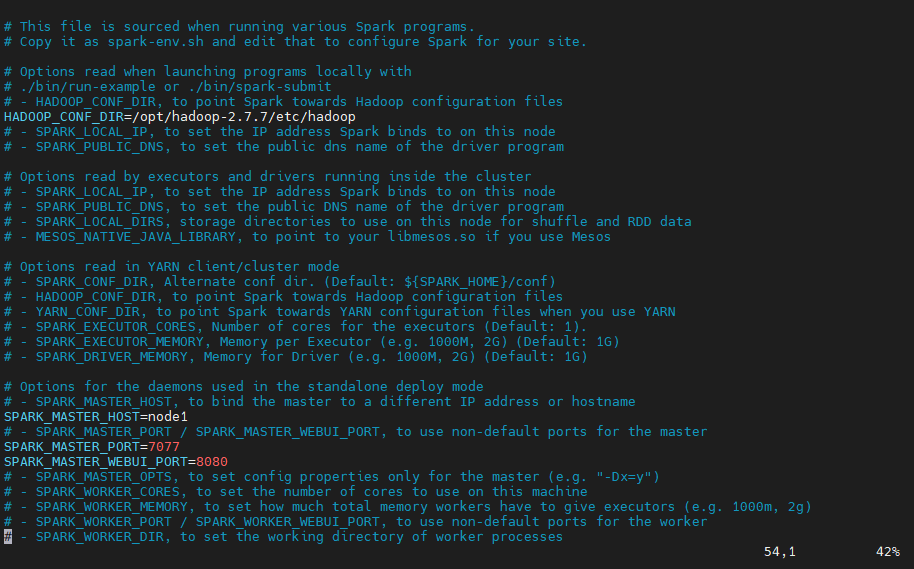

4、保存(键入 ESC)并退出(键入 :wq)
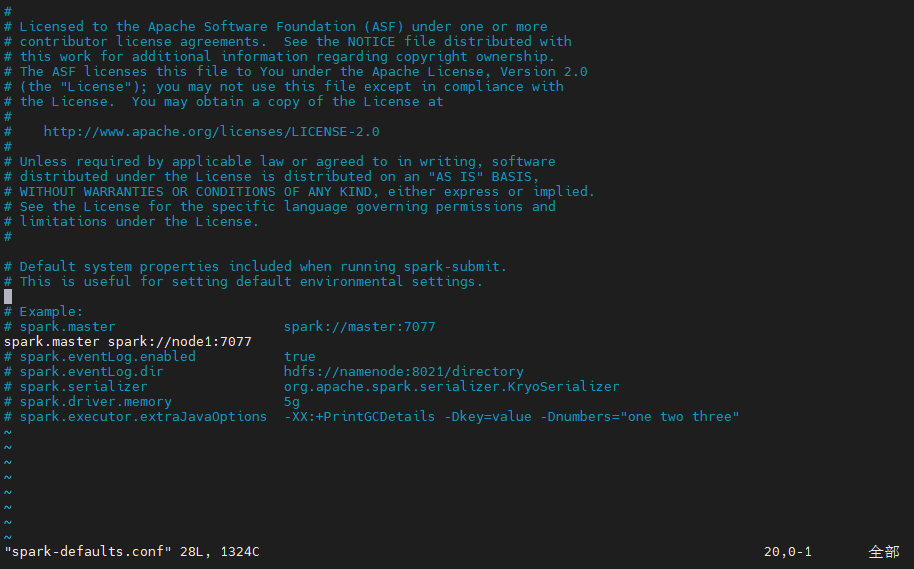
4️⃣ Step4:配置 spark-defaults.conf 配置文件,保存并退出!
2、将 spark-defaults.conf.template 复制一份并更名为 spark-defaults.conf,并进行配置
# Spark master节点的配置
spark.master spark://node1:7077
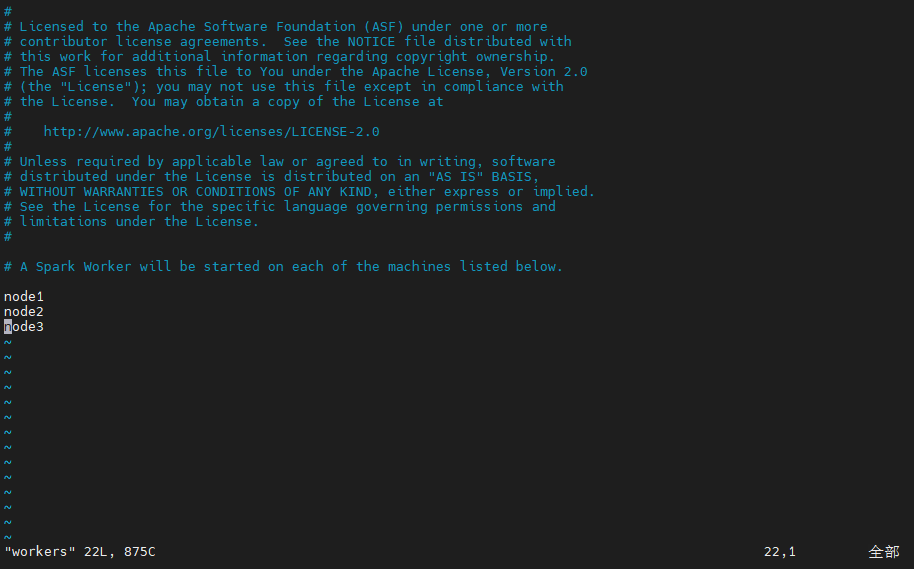
5️⃣ Step5:配置 workers 配置文件,将Hadoop使用的三台服务器的主机名添加其中,保存并退出!
node1
node2
node3
6️⃣ Step6:修改 Spark 启动、停止的脚本名称。
1、进入到 Spark 根目录的 sbin 目录中,
2、将 start.sh 修改为 start-spark.sh
3、将 stop.sh 修改为 stop-spark.sh
这里修改启动、停止的脚本名称是因为,原名与 Hadoop 的相关启动、停止脚本名称相冲突!
7️⃣ Step7:向其他两台服务器(node2、node3)分发安装包。
scp -rq /opt/spark-3.1.2 node2:/opt/
scp -rq /opt/spark-3.1.2 node3:/opt/
8️⃣ Step8:在三台服务器上分别修改环境变量。
echo 'export SPARK_HOME=/opt/spark-3.1.2' >> /etc/profile
echo 'export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH' >> /etc/profile
source /etc/profile
9️⃣ Step9:运行 Spark。
start-spark.sh

1️⃣ 0️⃣ Step10:Window下,在 web 端根据 8080 端口查看 Spark 状态。
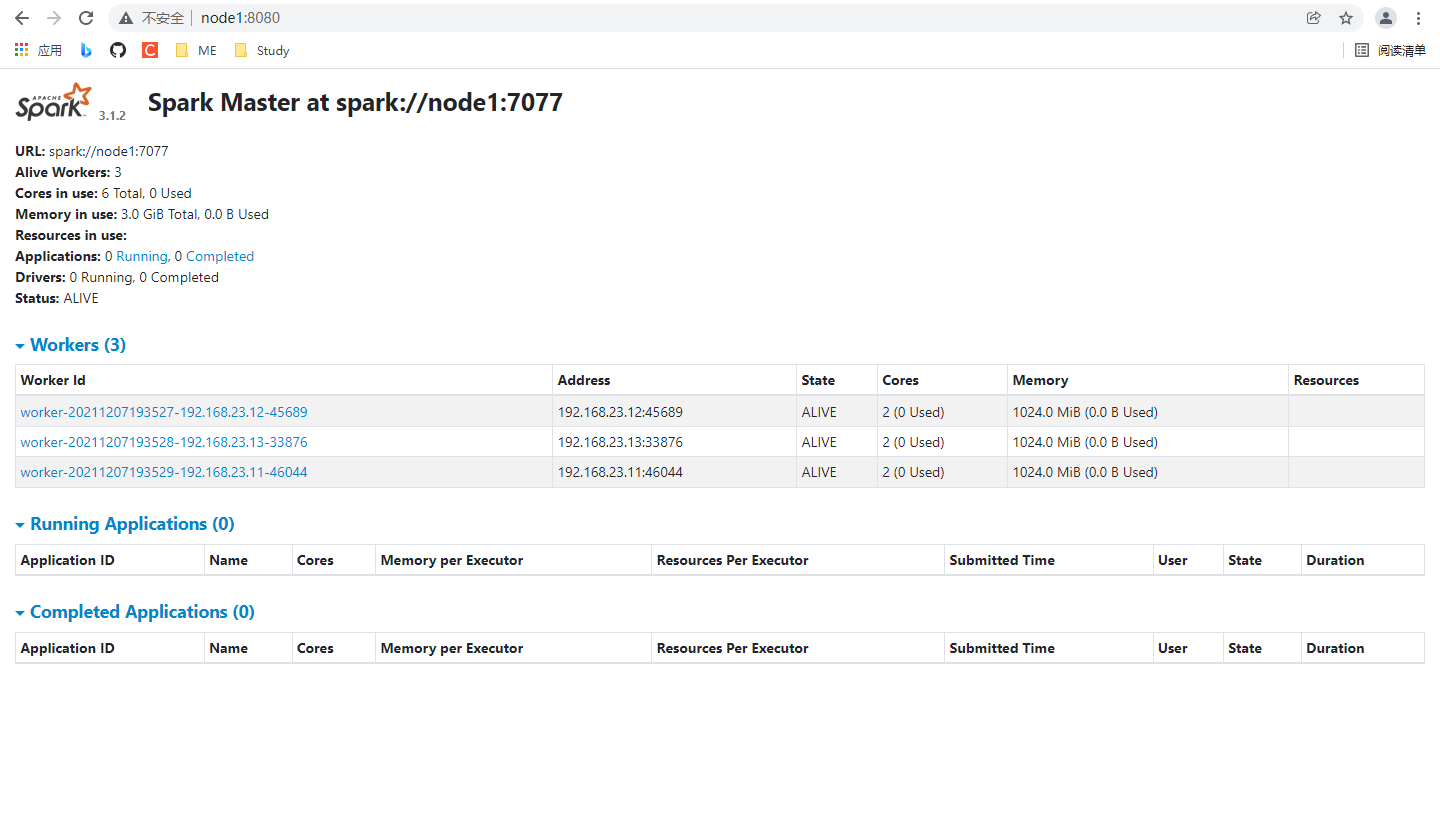
⚠️ 上面是使用主机名加端口号访问网页,因为我在 Window 下配置了相关映射,如果没有配,使用主机IP就是了!
1️⃣ 1️⃣ Step11:使用 jps 查看进程状态。
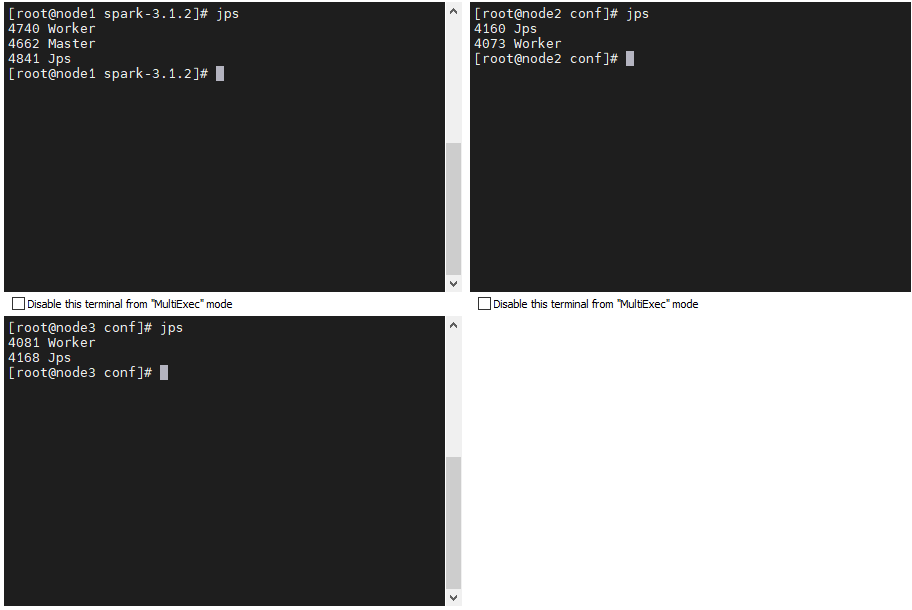
🌟 完工!!!
3. 扩展
实际应用中一般某些步骤,只需在一台服务中就可以完成,所以为避免重复的命令在多台服务器进行操作,我们可以使用脚本完成相关的实现。
比如会用到:
- 安装包分发
- 查看多态服务器进程
3.1 使用脚本实现分发
1️⃣ Step1:新建 shell 脚本,比如我命名为 sscp ,添加如下内容:
说明:
1、实现文件分发,需要获取对应的主机名,我的主机列表可以在
/etc/hosts中找到。2、
hostname将命令放在 ` 中表示命令,用以获取当前主机名。3、
grep node实现过滤,指留下包含node字样的行 ,比如某条结果为:192.168.xx.xx node2。4、
awk '{print $2}'截取出主机名5、
grep -v $HOSTNAME过滤掉当前主机名6、
${1}、${2}为传入的参数,第一个参数表示需要分发的文件,第二个参数表示需要分发到其他主机上的目录
#!/bin/bash
HOSTNAME=`hostname`
HOSTS=`cat /etc/hosts | grep node | awk '{print $2}' | grep -v $HOSTNAME`
for HOST in $HOSTS
do
echo "正在将${1}发送到${HOST}的${2}"
scp -rq $1 $HOST:$2
echo "发送完成"
done
2️⃣ Step2:配置环境变量,将当前脚本的所在目录(绝对路径)添加到环境变量中。
3️⃣ Step3:测试命令,新建文件,分发

3.2 使用脚本实现多台服务器的进程查看
大致步骤同上!j脚本命名为 jpsall
#!/bin/bash
HOSTS=`cat /etc/hosts | grep node | awk '{print $2}'`
for HOST in $HOSTS;do
echo "------- jsp in ${HOST} -------"
ssh $HOST /opt/jdk1.8/bin/jps | grep -v Jps
done

















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











