






一、项目来源(下载两个工程包)
https://gitcode.net/mirrors/yhenon/pytorch-retinanet?utm_source=csdn_github_accelerator
感谢大佬的博客分享~~~
【目标检测实战学习】从零开始制作并训练自己的VOC数据集,并使用Retinanet进行目标检测_vocdevkit_trash_Bill~QAQ~的博客-CSDN博客
用标注工具labeling标注自己的数据集参考链接:
学习记录:win10系统labeling标注工具的使用以及前期anaconda环境搭建完整版_小跑遨游宇宙的博客-CSDN博客
二、参考上面博客,重新合并工程包,对照正文(完整版)下载可直接使用。
百度网盘连接地址:
链接:https://pan.baidu.com/s/17T714hdoCOqMG08F11lpBg
提取码:7dj5正文中出现训练不显示的问题,有可能是cuda10.0版本低了???不得而知,反正换了一台电脑cuda11.3版本就成功了,流程是一样的,主要注意的就是pytorch安装对应cuda、python版本,上一篇博客有提到过。
三、正文(完整版)
1、打开Anaconda Prompt(Anaconda3),创建环境cuda10.0+python3.7+pytorch1.2.0
conda create -n mbjc python==3.7 #创建环境 python版本:3.7 环境名称:mbjc conda activate mbjc #激活环境 环境名称:mbjc conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch #安装pytorch显示安装成功!
2、修改 labelImg-master文件夹中data文件夹的predefined_classes.txt,类别我这里只要检测行人,只保留了person一个类,然后在labelImg-master文件夹中,打开终端。安装能够使用标注工具labeling的依赖项
-----------激活先前创建的环境----------- D:\pytorch-retinanet-master\labelImg-master>conda activate mbjc ---------输入下面代码安装环境依赖------- (mbjc) D:\pytorch-retinanet-master\labelImg-master>conda install pyqt=5 (mbjc) D:\pytorch-retinanet-master\labelImg-master>conda install -c anaconda lxml (mbjc) D:\pytorch-retinanet-master\labelImg-master>pyrcc5 -o libs/resources.py resources.qrc --------------打开labeling-------------- (mbjc) D:\pytorch-retinanet-master\labelImg-master>python labelImg.py
3、对数据进行增强,这里就使用mosaic方法为例。我们把上图的jpg_original和label_original两个文件夹复制到D:\pytorch-retinanet-master\object-detection-augmentation-main\VOCdevkit_Origin\VOC2007文件夹中
接着在D:\pytorch-retinanet-master\object-detection-augmentation-main\VOCdevkit\VOC2007文件夹中创建jpg_final和label_final两个新文件夹,用来存储数据增强后的图片以及标签
打开D:\pytorch-retinanet-master\object-detection-augmentation-main文件夹中的generate_mosaic.py,对其做部分修改
Out_Num 表示利用mosaic生成多少组图片,修改数据增强后的图片数目,自行修改
修改路径中的文件夹名称,注意原始图片和标签 以及 数据增强后的图片和标签
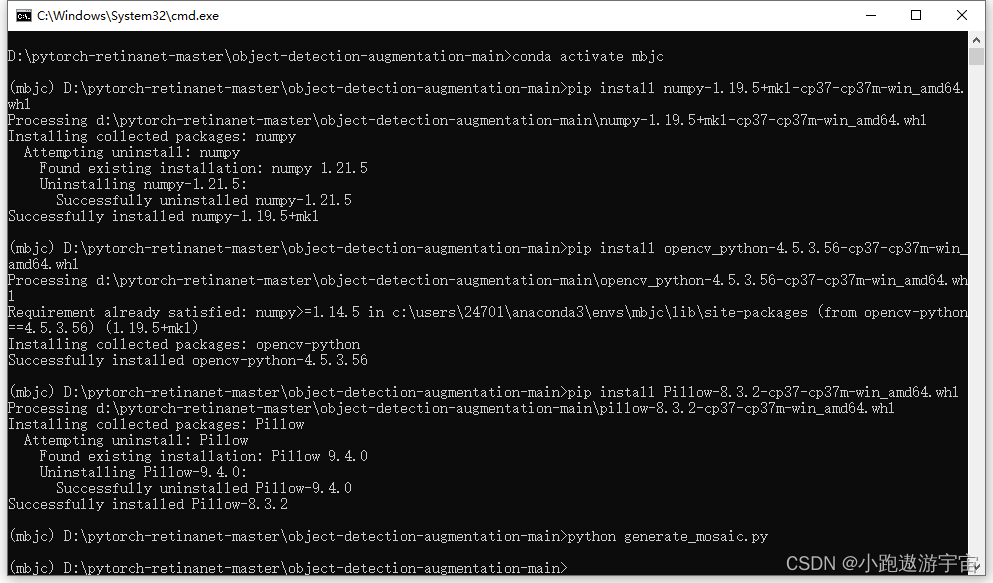
修改之后,在D:\pytorch-retinanet-master\object-detection-augmentation-main文件夹中打开cmd窗口,激活环境,安装能够运行generate_mosaic.py的依赖包。提前准备这些安装包
激活环境后安装依赖包(需要和python3.7版本对应),安装很快,命令语句:
conda activate mbjc pip install numpy-1.19.5+mkl-cp37-cp37m-win_amd64.whl pip install opencv_python-4.5.3.56-cp37-cp37m-win_amd64.whl pip install Pillow-8.3.2-cp37-cp37m-win_amd64.whl python generate_mosaic.py
接着在D:\pytorch-retinanet-master\object-detection-augmentation-main\VOCdevkit\VOC2007文件夹中会分别产生20张数据增强后的照片以及对应的标签,随便打开一张处理后的照片,发现以拼图的方式展现了。
4、划分训练集,测试集。首先将jpg_final和label_final两个文件夹复制粘贴到D:\pytorch-retinanet-master算法文件夹中,注意huafenshujuji.py中的路径位置
在该文件夹中打开cmd终端,激活环境
会产生三个.csv文件,train.csv、val.csv、class.csv
train.csv和val.csv分别存储了训练集和测试集的图像信息,class.csv存储了类的信息,也就是标签的目录,这里只有person一个类
5、开始训练,打开train.py
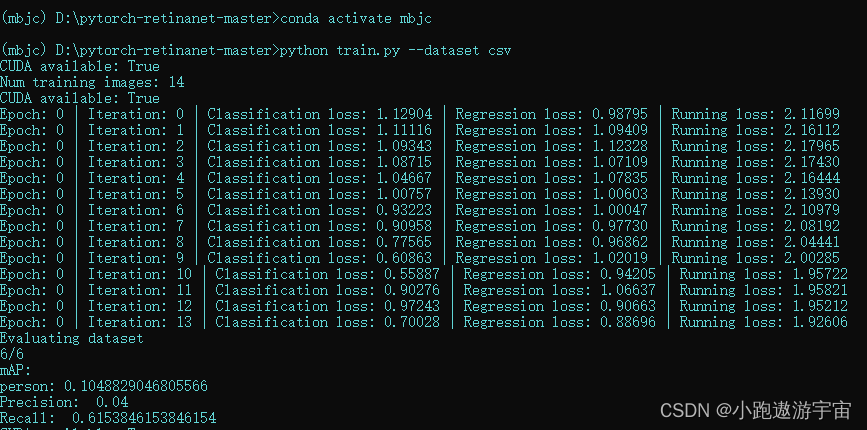
这里为了演示,就把epoch改成了5,训练时间少一点
提前下载好预训练权重resnet50-19c8e357.pth(在工程包里,已经下载好)
安装一些依赖包(都已经下载好,放在工程包里)
pip install opencv_python-4.5.3.56-cp37-cp37m-win_amd64.whl pip install pycocotools_windows-2.0-cp37-cp37m-win_amd64.whl conda install scikit-image开始训练(注意三个.csv所在的路径):
然后开始训练 python train.py --dataset csv
找了半天原因没找到为什么。。。。。。哭了啊
行,方法总比困难多,去实验室找另一台电脑重新创建一个环境,需要查看电脑的cuda版本再安装环境。cuda13.1+python3.7+pytorch1.10.0
conda create -n mbjc python==3.7 #创建环境 python版本:3.7 环境名称:mbjc conda activate mbjc #激活环境 环境名称:mbjc conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge pip install opencv_python-4.5.3.56-cp37-cp37m-win_amd64.whl pip install pycocotools_windows-2.0-cp37-cp37m-win_amd64.whl conda install scikit-image python train.py --dataset csv
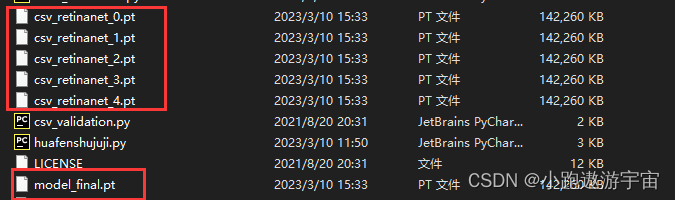
一下子就跑出来了,D:\pytorch-retinanet-master文件夹中多了训练权重文件,在最终完成后还会生成一个最终的权重文件,我们要使用的就是这个model_final.pt
6、开始验证
在visualize.py代码中做如下修改
注意权重文件model_final.pt 的所在位置
输入验证集val.csv的图片内容
然后开始验证 python visualize.py --dataset csv,可以直接可视化出检测结果,由于训练次数少,检测效果并不好。这里只是演示一下整个复现的流程。








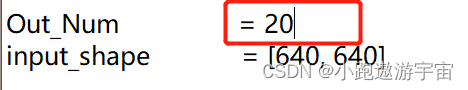











总结:pytorch安装对应cuda、python版本,上一篇博客讲解过。














 3901
3901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









