






前向传播

根据公式
st = tanh (Uxt + Wst-1 + ba)
ot = softmax(Vst + by )
m = 3 词的个数 n = 5
import numpy as np
import tensorflow as tf
# 单个cell 的前向传播过程
# 两个输入,x_t,s_prev,parameters
def rnn_cell_forward(x_t,s_prev,parameters):
"""
单个cell 的前向传播过程
:param x_t: 当前T时刻的序列输入
:param s_prev: 上一个cell的隐藏层状态输入
:param parameters: cell中参数,字典
:return: 隐层输出 s_next,out_pred,cache
"""
# 取出参数
U = parameters["U"]
W = parameters["W"]
V = parameters["V"]
ba = parameters["ba"]
by = parameters["by"]
# 根据公式计算
# 隐层输出计算
s_next = np.tanh(np.dot(U,x_t) + np.dot(W,s_prev) + ba)
# 计算cell的输出
out_pred = tf.nn.softmax(np.dot(V,s_next) + by)
# 记录每层的值,用于反向传播计算使用
cache = (s_next,s_prev,x_t,parameters)
return s_next,out_pred,cache
if __name__ == '__main__':
# forward
np.random.seed(1)
# 定义该cell的输入
x_t = np.random.randn(3, 1,)
s_prev = np.random.randn(5, 1)
# 定义参数
W = np.random.randn(5, 5)
U = np.random.randn(5, 3)
V = np.random.randn(3, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(3, 1)
parameters = {"U": U, "W": W, "V": V, "ba": ba, "by": by}
s_next, out_pred, caches = rnn_cell_forward(x_t, s_prev, parameters)
print("s_next = ", s_next)
print("s_next.shapr = ", s_next.shape)
print("out_pred =", out_pred)
print("out_pred.shape = ",out_pred.shape)
单个cell反向传播
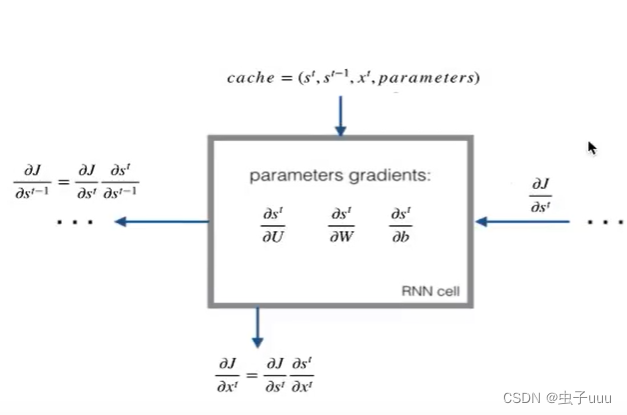
根据图我们能够知道需要计算的梯度变量有哪些
ds_next:表示当前cell的损失对输出s的导数
dtanh:表示当前cel的损失对激活函数的导数
dx_t:表示当前cell的损失对输入xt的导数。
dU:表示当前cell的损失对U的导数
ds_prev:表示当前cell的损失对上一个cell的输入的导数
dW:表示当前cell的损失对W的导数
dba:表示当前cell的损失对dba的导数
表示公式:

def rnn_cell_forward(x_t,s_prev,parameters):
"""
单个cell 的前向传播过程
:param x_t: 当前T时刻的序列输入
:param s_prev: 上一个cell的隐藏层状态输入
:param parameters: cell中参数,字典
:return: 隐层输出 s_next,out_pred,cache
"""
# 取出参数
U = parameters["U"]
W = parameters["W"]
V = parameters["V"]
ba = parameters["ba"]
by = parameters["by"]
# 根据公式计算
# 隐层输出计算
s_next = np.tanh(np.dot(U,x_t) + np.dot(W,s_prev) + ba)
# 计算cell的输出
out_pred = tf.nn.softmax(np.dot(V,s_next) + by)
# 记录每层的值,用于反向传播计算使用
cache = (s_next,s_prev,x_t,parameters)
return s_next,out_pred,cache
def rnn_cell_backward(ds_next, cache):
"""
对单个cell进行反向传播
:param ds_next: 当前隐层输出结果相对于损失的导数
:param cache: 每个cell的缓存
:return:gradients
"""
# 获取缓存值
(s_next, s_prev, x_t, parameters) = cache
print(type(parameters))
# 获取参数
U = parameters["U"]
W = parameters["W"]
# V = parameters["V"]
# ba = parameters["ba"]
# by = parameters["by"]
# 计算tanh的梯度通过对s_next
dtanh = (1 - s_next ** 2) * ds_next
# 计算U的梯度值
dx_t = np.dot(U.T, dtanh)
dU = np.dot(dtanh, x_t.T)
# 计算W的梯度值
ds_prev = np.dot(W.T, dtanh)
dW = np.dot(dtanh, s_prev.T)
# 计算b的梯度
dba = np.sum(dtanh,axis=1,keepdims= 1)
# 梯度字典
gradients = {"dtanh" : dtanh,"dx_t": dx_t, "ds_prev": ds_prev, "dU": dU, "dW": dW, "dba": dba}
return gradients
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









