








05|深入浅出索引(下) | 八九. | 思维导图(新) | ProcessOn
密码:arNL
一.回表
1.概念:二级索引,即非聚簇索引的叶子节点存储的是主键的值,我们根据二级索引查询时,
两次用到了索引的值,二级索引去拿主键索引的值的过程就是回表
二.覆盖索引
1.概念:指的就是我们如果只是根据条件搜寻主键的话,我们的目标是搜寻主键,相当于正常的
回表,我们就少了一个步骤,那就不需要回表(不需要再根据主键去搜寻了)
2.由于覆盖索引可以减少树的搜索次数,显著提高查询性能,所以使用覆盖索引是一个常用的性能优化手段
(即下面所讲的中: 联合索引覆盖其他单独的索引)
(即下面所讲的中: 联合索引覆盖其他单独的索引)
三.最左前缀原则
1.联合索引
 2.最左前缀原则
2.最左前缀原则
1.问题
如果每一种查询都要设计一个索引,索引是不是太多了?
我们不需要为一个次数很少的查询建立一个单独的索引
2.索引的重用(我觉的就是覆盖索引,重新使用)
1.B+树这种索引结构,可以利用索引的"最左前缀",来定位记录的
2.在建立索引的时候,如何安排索引内的字段顺序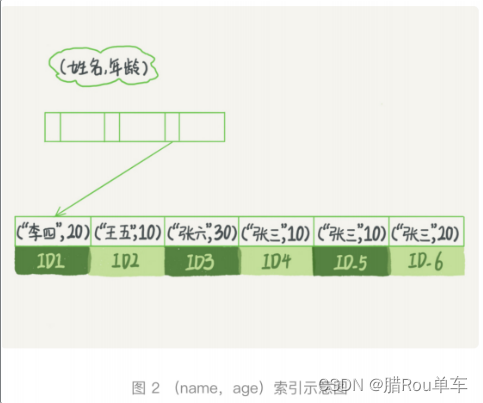
第一个原则:如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是
优先考虑采用的
比如说当前已经有了(a,b)这个联合索引后,一般就不需要单独在a上建立索引了

第二个原则:空间。
比如上面这个情况。name字段是比age字段大的,
那最好是建立一个(name,age)和一个(age)的但字段索引
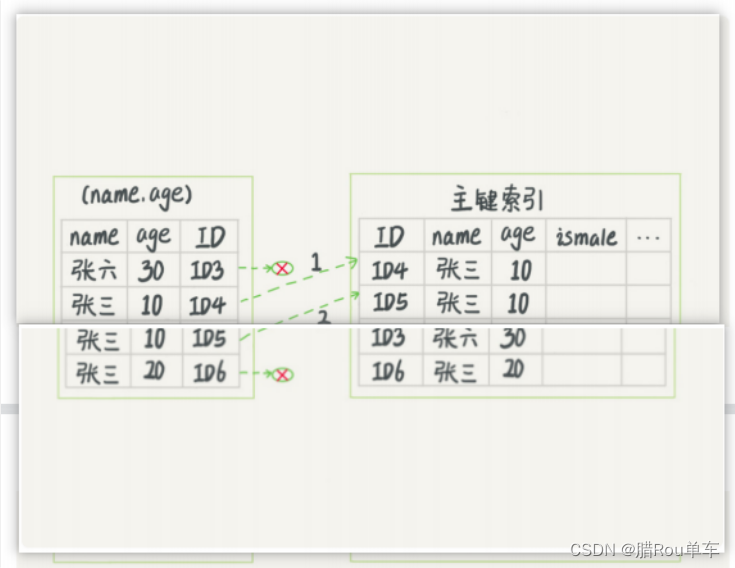
四.索引下推
1.概念
这指的是一个过程,就是根据联合索引去查询语句的过程
2.例子
名字中第一个字是张,而且年龄是10岁的所有男孩

mysql5.6之前,没有进行索引下推优化(每个虚线代表回表一次)

mysql5.6之后,没有进行索引下推优化
InnoDB在来拟合索引的内部就判断了age是否等于10,对于不等于10的数据,就直接判断跳过
InnoDB在来拟合索引的内部就判断了age是否等于10,对于不等于10的数据,就直接判断跳过
五.扩展
1.
业务中:InnoDB引擎所以占了很大的一部分,可能你的文件之后10g,但是你的索引有30g,因为你插入一个数据,每个索引都要去维护这个数据
2.
树高取决于数据行数和N
1.数据行数就是每个子节点(页page)中的数据大小
2.还有索引:非叶子节点,索引太大也会创建新的子节点,不是叶子节点

3.


4.
5.

















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











