







刚开始学习反向传播算法的时候一脸懵逼,吴恩达教授在讲解这一章节的时候省略了一大段公式的推导,所以导致自己看不懂直接给出的式子到底什么意思,经过了两天的学习,到处查找资料,终于比较弄懂了。
- 代价函数

我们回顾逻辑回归问题中我们的代价函数为:
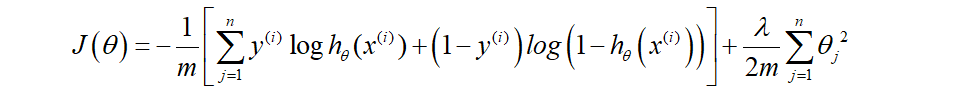
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量,但是在神经网络中,我们可以有很多输出变量,我们的是一个维度为k的向量,并且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,
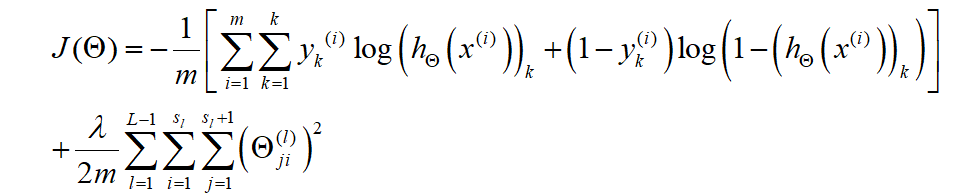
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出k个预测,然后在利用循环在k个预测中选择可能性最高的一个,将其与y中的实际数据进行比较。
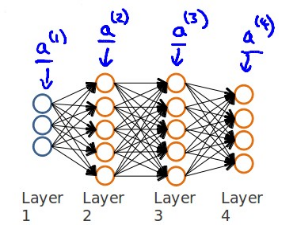
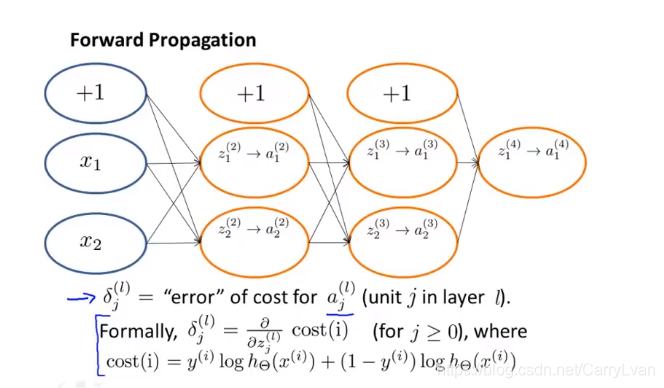
计算神经网络预测结果的时候我们采用了一种正向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层的h(x)
现在,为了计算代价函数的偏导数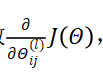
我们需要采用一种反向传播算法,也就是首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。 以一个例子来说明反向传播算法。
前向传播

首先计算最后一层的误差
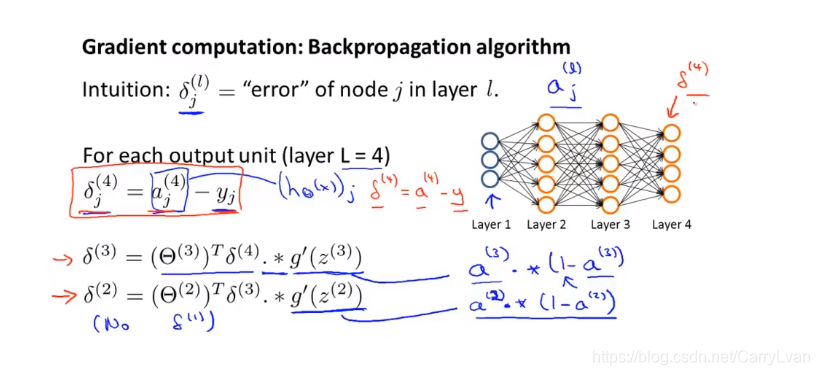
接下来我们看一下δ ( 3 ) \delta^{(3)}δ
(3)
的推导过程:
代价函数对于z的偏导
代价函数关于所计算出的中间项 z 的偏导数,它所衡量的是:为了影响这些中间值,我们所需要改
变神经网络中的权重的程度。


因为第一层是输入变量,不存在误差。我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了,假设,即我们不做任何正则化处理时有: 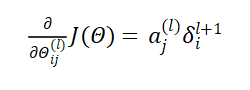
-
随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。
我们通常初始参数为正负e之间的随机值,假设我们要随机初始一个尺寸为10×11的参数矩阵,代码如下:
Theta1 = rand(10, 11) * (2*eps) – eps
综合起来
小结一下使用神经网络时的步骤:
网络结构:第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
第一层的单元数即我们训练集的特征数量。
最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
参数的随机初始化
利用正向传播方法计算所有的hx
编写计算代价函数J 的代码
利用反向传播方法计算所有偏导数
利用数值检验方法检验这些偏导数
使用优化算法来最小化代价函数
反向传播算法代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from scipy.io import loadmat
from sklearn.preprocessing import OneHotEncoder
data = loadmat('E:\machine studdy\Coursera-ML-AndrewNg-Notes-master\code\ex4-NN back propagation/ex4data1.mat')
X=data['X']
print(X.shape)
y=data['y']
#第一个维度代表了行数
weight = loadmat("E:\machine studdy\Coursera-ML-AndrewNg-Notes-master\code\ex4-NN back propagation/ex4weights.mat")
theta1, theta2 = weight['Theta1'], weight['Theta2']
"""sample_idx = np.random.choice(np.arange(data['X'].shape[0]), 100)
sample_images = data['X'][sample_idx, :]
fig, ax_array = plt.subplots(nrows=10, ncols=10, sharey=True, sharex=True, figsize=(12, 12))
for r in range(10):
for c in range(10):
ax_array[r, c].matshow(np.array(sample_images[10 * r + c].reshape((20, 20))).T,cmap=matplotlib.cm.binary)
plt.xticks(np.array([]))
plt.yticks(np.array([]))
plt.show()"""
def sigmoid(z):
return 1/(1+np.exp(-z))
#前向传播
def forward_propagate(X,theta1,theta2):
a1=np.insert(X,0,values=np.ones(X.shape[0]),axis=1)
z2=a1 * theta1.T
a2=sigmoid(z2)
a2 = np.insert(a2, 0, values=np.ones(X.shape[0]), axis=1)
z3=a2 * theta2.T
h=sigmoid(z3)
return a1,z2,a2,z3,h
X=np.matrix(X)
a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2)
"""print("-------")
print(a1.shape) #5000,401
print(z2.shape) #(5000, 25)
print(a2.shape) #5000,26
print(z3.shape) #(5000, 10)
print(h.shape) #5000,10"""
#代价函数
def costfunction(theta1,theta2,input_size,hidden_size,num_labels,X,y,learning_Rate):
m=X.shape[0]
X=np.matrix(X)
y=np.matrix(y)
a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2)
J=0
for i in range(m):
first_term=np.multiply(-y[i,:],np.log(h[i,:]))
second_term = np.multiply((1 - y[i, :]), np.log(1 - h[i, :]))
J += np.sum(first_term - second_term)
J=J/m
return J
encoder = OneHotEncoder(sparse=False)
y_onehot = encoder.fit_transform(y)
print(y_onehot.shape)
# 初始化设置
input_size = 400
hidden_size = 25
num_labels = 10
learning_rate = 1
#初始代价函数
print(costfunction(theta1,theta2,input_size,hidden_size,num_labels,X,y_onehot,learning_rate))
#正则化代价函数防止过拟合的问题
def costReg(theta1, theta2, input_size, hidden_size, num_labels, X, y, learning_rate):
m = X.shape[0]
X = np.matrix(X)
y = np.matrix(y)
# run the feed-forward pass
a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2)
# compute the cost
J = 0
for i in range(m):
first_term = np.multiply(-y[i, :], np.log(h[i, :]))
second_term = np.multiply((1 - y[i, :]), np.log(1 - h[i, :]))
J += np.sum(first_term - second_term)
J = J / m
# add the cost regularization term 增加正则项 第1行到最后一行,第一列开始
J += (float(learning_rate) / (2 * m)) * (np.sum(np.power(theta1[:, 1:], 2)) + np.sum(np.power(theta2[:, 1:], 2)))
return J
print(costReg(theta1,theta2,input_size,hidden_size,num_labels,X,y_onehot,learning_rate))
# 反向传播的实现
#首先计算sigmoid的导数
def sigmoid_gradient(z):
return np.multiply(sigmoid(z), (1 - sigmoid(z)))
# np.random.random(size) 返回size大小的0-1随机浮点数
params = (np.random.random(size=hidden_size * (input_size + 1) + num_labels * (hidden_size + 1)) - 0.5) * 0.24
#反向传播
def backprop(params,input_size,hidden_size,num_labels,X,y,learning_Rate):
m = X.shape[0]
X = np.matrix(X)
y = np.matrix(y)
# run the feed-forward pass
a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2)
#矩阵化初试的theta
thetaone = np.matrix(np.reshape(params[:hidden_size * (input_size + 1)], (hidden_size, (input_size + 1))))
thetatwo=np.matrix(np.reshape(params[hidden_size*(input_size+1):],(num_labels,(hidden_size+1))))
J=0
#初始化偏导数的矩阵
delta1 = np.zeros(theta1.shape) # (25, 401)
delta2 = np.zeros(theta2.shape) # (10, 26)
for i in range(m):
first_term=np.multiply(-y[i:],np.log(h[i,:]))
second_term = np.multiply((1 - y[i, :]), np.log(1 - h[i, :]))
J+=np.sum(first_term+second_term)
J=J/m
#执行反向传播
''' print(a1.shape) #5000,401
print(z2.shape) #(5000, 25)
print(a2.shape) #5000,26
print(z3.shape) #(5000, 10)
print(h.shape) #5000,10
'''
for t in range(m):
a1t=a1[t,:] #每一个x
z2t=z2[t,:] #第一次转换后的每一个x ,向量的形式
a2t=a2[t,:] #转化后输出的X
ht = h[t, :] # (1, 10) 所有输出的值
yt = y[t, :] # (1, 10) 样本中y的值
d3t=ht-yt #最后一层的误差 (1, 10)
z2t = np.insert(z2t, 0, values=np.ones(1)) # (1, 26)
d2t = np.multiply((thetatwo.T * d3t.T).T, sigmoid_gradient(z2t)) # (1, 26)
delta1=delta1+d2t[:,1:].T * a1t
#为什么这个不用上面那样? 可能是由于上面那个是矩阵
delta2=delta2+d3t.T * a2t
delta1=delta1/m
delta2=delta2/m
return J, delta1, delta2
#正则化神经网络反向传播
def bacakpropReg(params,input_size,hidden_size,num_labels,X,y,learningRate):
m = X.shape[0]
X = np.matrix(X)
y = np.matrix(y)
a1,z2,a2,z3,h=forward_propagate(X,theta1,theta2)
#初始化矩阵权重
thetaone=np.matrix(np.reshape(params[:hidden_size*(input_size+1)],(hidden_size,(input_size+1))))
thetatwo=np.matrix(np.reshape(params[hidden_size*(input_size+1):],(num_labels,(hidden_size+1))))
#开始执行反向传播,首先正向传播
J=0
delta1=np.zeros(theta1.shape)
delta2=np.zeros(theta2.shape)
for i in range(m):
first_term = np.multiply(-y[i:], np.log(h[i, :]))
second_term = np.multiply((1 - y[i, :]), np.log(1 - h[i, :]))
J += np.sum(first_term + second_term)
J = J / m
#正则化
J += (float(learning_rate) / (2 * m)) * (np.sum(np.power(theta1[:, 1:], 2)) + np.sum(np.power(theta2[:, 1:], 2)))
for t in range(m):
a1t = a1[t, :] # (1, 401)
z2t = z2[t, :] # (1, 25)
a2t = a2[t, :] # (1, 26)
ht = h[t, :] # (1, 10)
yt = y[t, :] # (1, 10)
d3t=ht-yt
z2t = np.insert(z2t, 0, values=np.ones(1)) # (1, 26)
d2t = np.multiply((thetatwo.T * d3t.T).T, sigmoid_gradient(z2t)) # (1, 26)
delta1 = delta1 + (d2t[:, 1:]).T * a1t
delta2 = delta2 + d3t.T * a2t
delta1 = delta1 / m
delta2 = delta2 / m
delta1[:,1:]=delta1[:,1:]+(thetaone[:,1:]*learning_rate)/m
delta2[:,1:]=delta2[:,1:]+(thetatwo[:,1:]*learning_rate)/m
# unravel the gradient matrices into a single array
#将梯度矩阵分解为单个数组 拼接的函数
grad = np.concatenate((np.ravel(delta1), np.ravel(delta2)))
return J, grad
J,grad=bacakpropReg(params,input_size,hidden_size,num_labels,X,y_onehot,learning_rate)
#print(grad.shape) #10285 所有参数的偏导数
from scipy.optimize import minimize
fmin = minimize(fun=bacakpropReg, x0=(params), args=(input_size, hidden_size, num_labels, X, y_onehot, learning_rate),
method='TNC', jac=True, options={'maxiter': 250})
print(fmin)
print("123")















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









